多尺度深度监督的高度近视萎缩病变分割方法
2021-08-06曾增峰环宇翔郑立荣
曾增峰,环宇翔,邹 卓,郑立荣
(复旦大学信息科学与工程学院微纳系统中心,上海 201203)
1 引言
由于眼底相机的成像能够清晰地显示眼底组织信息,并在眼底图像上较好地显示出病变,而广泛应用于眼科医学成像领域。从眼底图像中精确地分割出高度近视萎缩病变,是现代科学技术辅助诊断高度近视及手术规划的关键步骤。然而,可靠而精确地分割高度近视萎缩病变在眼底图像分割的研究中还存在以下问题:
(1)不同个体的眼底图像质量良莠不齐,萎缩病变形状、大小有很大差异;
(2)萎缩病变与相邻组织之间边界较为模糊,难以区分。
存在该问题的图像如图1所示[1]。针对上述问题,如何提升算法的分割精度是医学图像科研人员所面临的极具挑战性的任务[2]。为此,本文将提出一种基于灰度变换的眼底图像优化算法。
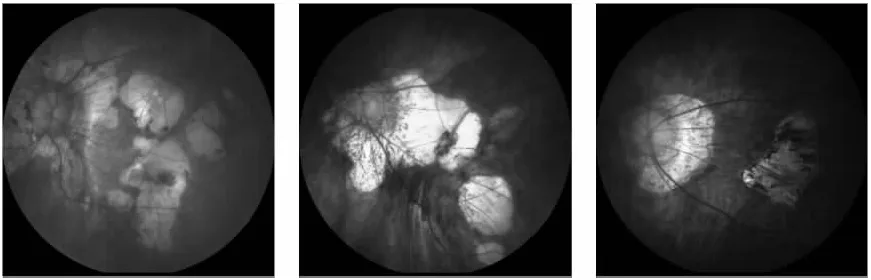
Figure 1 Fundus image display图1 眼底图像展示
目前,深度学习已经被广泛应用到解决计算机视觉和医学图像语义分割等领域的众多问题。Long等[3]提出了一个基于全卷积神经网络FCN(Fully Convolutional Network)的图像语义分割方法,该方法用1×1的卷积层代替全连接层,使得网络可以接受任意尺寸的输入图像,并通过反卷积使得经过多次卷积缩小的特征图能够恢复到原始图像尺寸大小,同时更好地保留图像空间信息。Ronneberger等[4]、Drozdzal等[5]和Çiçek等[6]对U-Net分割方法做了详细的描述和论证,并列举了各自方法的优缺点和原理差异。通过上述3个文献可以得出,现有U-Net结构所应用的方法都是使用2D卷积层和2D转置卷积层建立下采样层和上采样层组合的对称结构,可在下采样层和上采样层之间添加跳跃连接操作来提升分割精度,并能够在卷积层中添加2D注释断层图进行3D医学图像疾病分割。Chen等[7]用膨胀卷积核代替经典的卷积核,解决了下采样降低特征图大小和网络参数较多的问题。在图像中目标特征与背景差异明显情况下,上述分割方法可以取得不错的分割效果,但当特征差异不明显时,分割精度则有待提高。另外,深度学习算法一般要对图像进行预处理,预处理结果的好坏会直接影响分割精度。
受深度学习在多学科交叉领域取得丰硕研究成果的启发,研究人员将其应用到了医学图像处理与分析中。在实践的过程中,针对医学图像中的不同任务,深度学习方法均获得了较好的结果。大多数的分割方法往往需要一定的知识和经验积累,采用一些复杂的预处理操作和其他辅助方法,如K-means[8]、支持向量机[9]等,但这些方法不能充分利用图像中丰富的语义信息。为了更好地辅助医生对高度近视进行诊断与治疗,拓展深度学习和医疗技术结合的应用前景,本文提出了一种具有多尺度深度监督的高度近视萎缩病变分割方法,可以较好地解决上述问题,完成高度近视萎缩病变眼底图像的精准分割。
2 相关网络结构介绍
2.1 V-Net
Milletari等[10]提出了只需要少量数据就可训练的V-Net,并将Dice 相似系数作为损失函数。研究表明,V-Net只需少量的医学图像数据就能够得到不错的分割精度,并且网络的训练速度很快,因此广泛应用于医学图像分割领域。在医学图像语义分割的应用中,V-Net能够做到端对端训练、像素对像素的分类,即便没有对数据集进行预处理,也可以取得较好的分割效果,可见其具有很好的医学图像特征空间表征能力。V-Net网络结构及其特征学习过程如图2所示。
V-Net的网络结构由下采样路径和上采样路径组成,并且整个网络都使用全0补齐方式的卷积使图像的输入尺寸和输出尺寸一致。
图2左边的下采样路径是十分经典的卷积神经网络,它是由卷积块结构组成的,每个卷积块结构中均有多个卷积,类似ResNet[11]网络中使用残差结构来解决深度学习梯度消失的问题,卷积层中卷积核大小均为5×5,采用PReLU作为激活函数,采用卷积核的步数来控制特征图尺寸的大小。每一次卷积块操作后特征图的通道数量都翻倍,但是特征图尺寸减半。
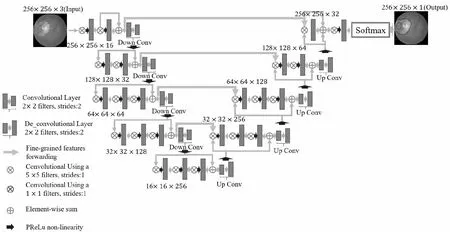
Figure 2 V-Net图2 V-Net
图2右边的上采样路径的每一个卷积块之前都是反卷积块,除了第1个反卷积块不改变特征图的通道数量,其余的反卷积块都使特征图的通道数量减半并使特征图尺寸加倍。将反卷积的结果与下采样路径中对应大小的特征图拼接起来,组成跳跃拼接的结构。对拼接后的特征图进行多次5×5的卷积运算,其类似下采样路径中的卷积块。上采样路径中的最后1层的卷积核大小为1×1,其将特征图的32个通道转化为分类个数,例如本文将图像分割分为前景和背景,所以分类个数为2[12]。
V-Net结构与 U-Net结构十分类似,看起来呈V形状,故称之V-Net。通过对比V-Net和U-Net的网络结构可以得出,两者主要差别为V-Net在上采样和下采样的每个阶段都采用了ResNet的短路连接方式,其相当于在U-Net中引入了ResBlock,可以在一定程度上解决深度网络退化问题,缓解梯度弥散问题,即残差连接使得信息前后向传播更加顺畅。同时,现有研究表明V-Net性能更好,并且V-Net具有的上述结构与优点,十分适合本文的眼底图像分割任务,为此本文将改进原有V-Net的网络结构来优化分割任务。
2.2 特征金字塔网络
Lin等[13]提出一种特征金字塔网络FPN(Feature Pyramid Networks),其大概结构如图3所示。

Figure 3 Feature pyramid networks图3 特征金字塔网络
FPN左边的下采样路径是典型的深度卷积神经网络,通过卷积操作使得特征图大小保持不变或者减半。FPN右边的上采样路径的每一步都采用反卷积,使得特征图尺寸保持不变或者加倍。反卷积结果与上采样中对应大小一致的特征图拼接起来。
由于特征金字塔网络能够从不同尺度图像提取语义信息,充分利用低层特征和高层特征,本文将其运用到V-Net中组成具有多尺度融合功能的MS-V-Net(Multi-Scale V-Net),即在V-Net的网络结构上改变一些连接,在增加少量参数计算量的情况下提高网络分割精度。
2.3 深度监督网络
Lee 等[14]提出一种深度监督网络DSN(Deeply-Supervised Nets),其大概结构如图4所示。
DSN左边的不同卷积块引入了分类目标函数,对多个连续卷积块学习到的信息特征提供直接监督,不像传统的深度卷积网络主要依赖最后分类层计算预测误差再进行反向传播来指导前面层的学习,该网络中每个卷积块之间形成紧密监督的形式。
由于深度监督网络能够对前面层的学习起到监督作用,从而保证整个网络的学习效果,本文将其运用到在MS-V-Net中组成具有多尺度深度监督功能的MSS-V-Net(Multi-Scale Supervised V-Net),即在MS-V-Net的网络结构上添加多个目标函数来提高网络的分割精度。
Figure 4 Deeply-supervised nets图4 深度监督网络
3 眼底图像的优化算法
由于不同个体的眼底图像质量差异较大及因萎缩病变与相邻组织之间边界较为模糊等问题,现有大部分眼底图像优化算法[15 - 17]对眼底图像的局部采用对比度增强、色彩校正和直方图均衡化等方法,尽管这些方法具有一定的作用,但结果仍不令人满意。另外,可以使用美图秀秀、GIMP和PhotoShop等图像处理软件,人工处理以达到图像优化的效果,但是该方法需要耗费巨大人力,并且效率十分低下。况且不同人员对像素敏感性差异较大,修图效果存在差别,无法保证图像效果一致,这对于深度学习是一个巨大障碍。为解决上述问题,本文构建眼底图像的优化算法,旨在使眼底图像组织结构清晰、质量风格统一。
3.1 算法原理
为了更好地描述算法原理,本文定义中央区域和非中央区域2个概念:
定义1图像灰度直方图的灰度值分布区间中间区段对应像素坐标点的区域为中央区域CA (Central Area)。
定义2图像灰度直方图的灰度值分布区间非中间区段对应像素坐标点的区域为非中央区域N-CA(Non-Central Area)。
根据定义1和定义2,眼底图像的优化算法如算法1所示:
算法1眼底图像的优化算法
输入:待优化图像。
输出:优化后图像。
步骤1调整图像局部区域的灰度:
在输入待优化图像后,首先需要分离眼底图像的 RGB 颜色通道,并获取它们各自的灰度直方图。其次,将眼底图像的眼底区域作为感兴趣区域,并保证只在该区域进行操作。最后,在每个颜色通道的灰度直方图中提取感兴趣区域,并对其中央区域的灰度值进行灰度变换。灰度变换公式如式(1)所示:
(1)
其中,Ao和At分别为变换前后对应坐标点的灰度值,Qo和Qt分别为变换前后图像的灰度极小值,Co和Ct为变换前后图像的对比度,CEC为通道C的灰度变换权重系数。
步骤2平衡图像全部区域的亮度:
经过调整眼底图像中央区域的灰度后,由于非中央区域的灰度值没有经过任何处理,导致中央区域和非中央区域的灰度值会存在较大差异,为此,首先用中央区域灰度值的最大值和最小值替换非中央区域灰度值的最大值和最小值。其次,对整幅图像的所有像素点的灰度值叠加平衡值(Oa),该值为实验经验值。最后,将优化后的3个颜色通道的灰度图像融合成彩色的眼底图像。
3.2 实验结果及分析
本节实验数据由2部分构成,即公开数据集Grand Challenge of PALM[1]和Grand Challenge of ODIR2019[18]。本节实验环境为:Windows 10 64位操作系统,CPU i5-9300H,软件编程环境为Anaconda Spyder-Python 3.6。
在眼底图像的优化算法实验过程中,关键步骤所包含的重要参数设置为:B、G、R通道对应的Oa、CEC、Qt、Co分别为38,0.9,0,64; 90,1.0,0,200; 180,0.9,112,240。
实验结果如图5所示。从图5中可以看出,图5b为在经过算法步骤1后的图像,可以看出该图像相对于原始图像已经达到一定的优化效果,但是由于还未对非中央区域的灰度最大值和最小值进行替换,图像较为深红并略显失真。图5c为经过算法步骤2后的图像,眼底图像已经变得组织结构清晰、质量风格统一。2个步骤处理后的图像相对于图5a原始图像呈现出较好的图像质量。

Figure 5 Image optimization display图5 图像优化展示
图6展示了病理性高度近视的3幅眼底图像优化前后对比。可以看出,优化算法明显提高了图像质量的一致性,使得眼底图像较为清晰地显示多种生理结构,具体表现为眼底边缘轮廓更为清晰,主要是清除了眼底的黑色边缘,更清晰地显示眼底中的血管、视神经盘等组织结构,并且使萎缩病变与相邻组织之间边界的区别较为明显。

Figure 6 Before and after image optimization图6 图像优化前后对比
由此可以得出,该算法为优化眼底图像提供了一种较为新颖的方法,具有提高眼底图像的可读性和统一眼底图像色调及清晰显示眼底组织的作用。
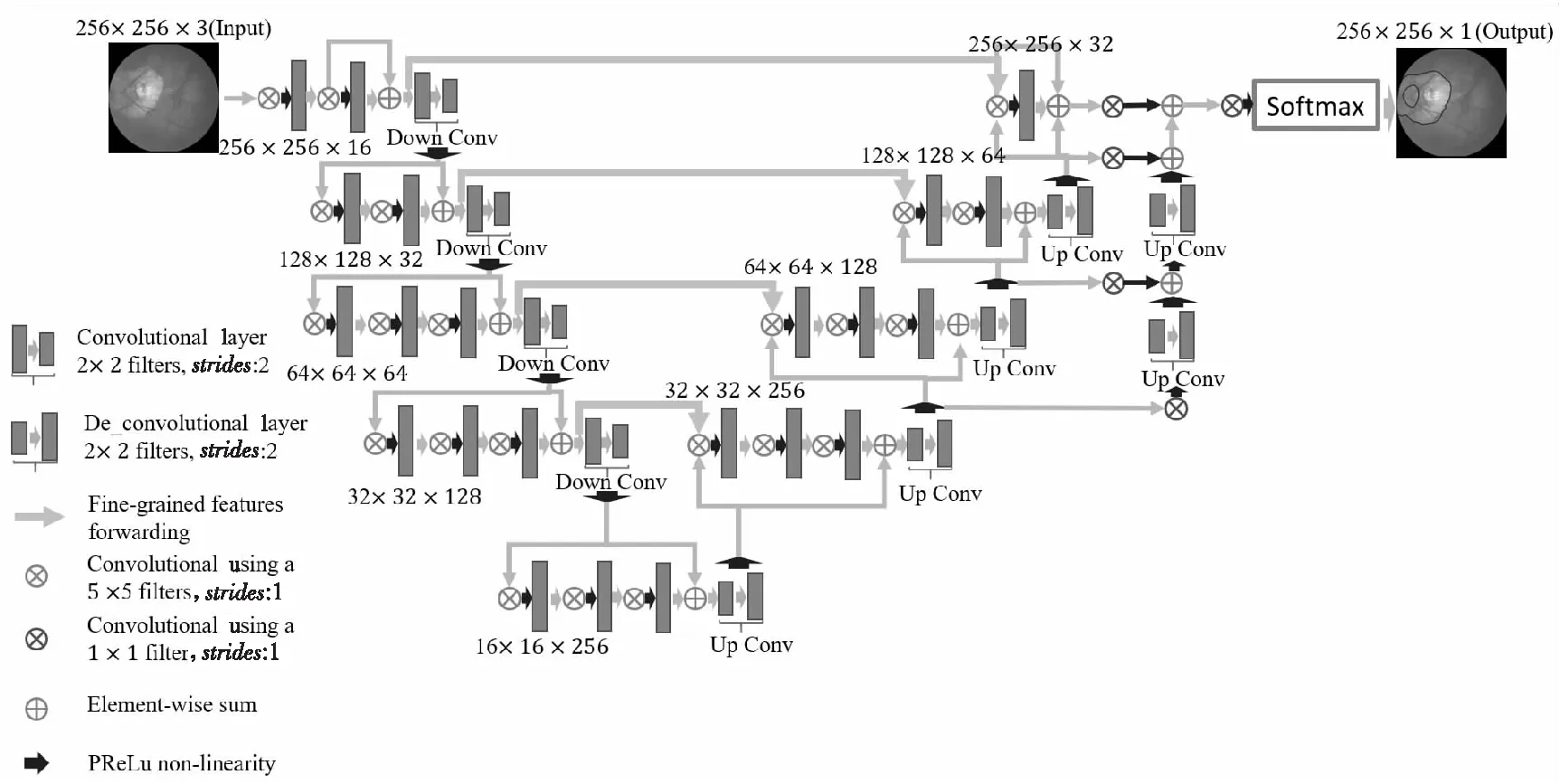
Figure 7 MS-V-Net图7 MS-V-Net
4 基于V-Net的MSS-V-Net
传统方法需要较为复杂的图像预处理,如需要预先用形态学提取高度近视病变特征等操作,这些预处理导致网络分割效果偏差较大。为此,本文研究多尺度深度监督条件下的高度近视病变分割算法,相对于传统的分割方法具有较大优势,深度学习方法只需提供分割标签就能够自动学习并取得较好的分割结果。
4.1 MS-V-Net
如图7所示,相对于V-Net网络结构,可以看出MS-V-Net网络在V-Net网络上采样路径中,额外增加了一条上采样路径,即MS-V-Net包括2条上采样路径。第1条上采样路径为原始V-Net网络的上采样路径;第2条上采样路径为多尺度上采样路径,其是由第1条上采样路径所引申出来的。在第2条上采样路径的反卷积之前都需要对第1条上采样路径的特征图进行1×1的卷积;再将反卷积结果与第1条上采样路径中对应大小一致的特征图拼接起来,并且为了消除拼接操作可能导致的混叠效应,需要对拼接后的特征图进行卷积操作;最终经过Softmax函数进行像素分类,从而可以分割出萎缩病变区域。
在测试阶段,同V-Net网络一样采用最后一层的分割结果作为预测结果。
4.2 MSS-V-Net
由2.3节的深度监督思想可知,卷积神经网络前面层学习效果越好越有利于后面层提取信息特征,即前面层提取特征越丰富,则越能够保证后面层具有稳健的学习能力。如图8所示,在第2条上采样路径的每个阶段引入Softmax目标函数,即每个阶段都将进行语义分割,3个Softmax目标函数分别对应3个Dice损失函数,实现多个损失函数共同调整模型的目的,能够提升模型的泛化能力和鲁棒性。
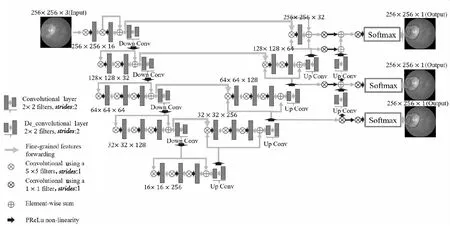
Figure 8 MSS-V-Net 图8 MSS-V-Net
具体来说,MSS-V-Net利用多尺度特征融合后每个阶段信息引入分类目标函数进行不同尺度的语义分割,每个阶段形成紧密监督的形式,训练过程中实现了在不同多尺度层独立预测的功能。
训练过程包含3个Dice损失函数,重要性权重分别设置为0.2,0.2和0.6,但是只监控最后一层分类输出的Dice数值,并只保证该数值达到最大才存储权重模型。
实验经验表明,在测试阶段最后层的结果特征提取能力最强,前面层只是起到辅助提取特征的作用,并监督最后一层达到较好的分割结果。因此,本文采用最后层的分割结果作为MSS-V-Net的预测结果。
对于MSS-V-Net结构,引入深层监督目标函数主要有以下2个方面的作用:
(1)深度监督可以起到正则项的作用,提升网络对重要信息特征的判别性。
(2)深度监督的作用可以理解为一定程度上解决了深度学习中的梯度消失和梯度爆炸等问题,提高了深度学习网络对重要信息特征的泛化能力。
5 实验及评估标准
5.1 实验平台
本文实验环境为:Windows 10 64位操作系统,使用NVIDIA GeForce GTX 1060Ti 显卡,核心频率为2.30 GHz,显存为6 GB,软件编程环境为Python 3.6,cuDNN神经网络GPU加速库,基于TensorFlow后端的Keras深度学习框架。
5.2 评价指标
定义3文献[10]已经证明,Dice损失函数能够更好地处理前景和背景像素数目之间存在严重不平衡的情况,所以本文采用Dice作为评价指标,其定义如式(2)所示:
(2)
其中,P和G分别表示预测结果和金标准标签;ΔP和ΔG分别表示P和G包含的闭合区域;N(·)表示区域中的像素总数;Smooth=1,具有防止除0的作用。Dice(·)的值越大表示算法的分割精度越高。
定义4盒图是一种用作显示一组数据分散情况资料的统计图,能够直观显示数据离散程度,如图9所示。

Figure 9 Box-plot图9 盒图
其中,Q1和Q3之间的距离称为四分位数极差(IQR),定义为:
IQR=Q3-Q1
(3)
在分析数据的过程中,借助盒图可以有效地识别数据的特性[19]:
(1)盒图的下端点是第1个四分位数,上端点是第3个四分位数,盒的长度是第3个四分位数和第1个四分位数的极差IQR。
(2)盒内的线标记了第2个四分位数,即中位数。
(3)盒外的2条线(亦称作胡须)延伸到最小观测值和最大观测值。
本文用盒图作为评价指标衡量测试数据集的Dice分布情况,在处理Dice观测值时,盒图能够绘制出可能的离群点[20]。
5.3 实验过程
实验采用随机挑选的方法将数据集划分为训练集(260幅)、验证集(30幅)和测试集(35幅)。在调整超参数时,参考相关文献及实践经验,从训练集随机抽取一份小规模数据集对超参数进行大致的网络探索,以节省模型参数调整的时间。本文的参数设置为:Adam优化算法,基本学习率为0.000 1,Mini-batch为4,权重衰减因子为0.000 01,最大迭代次数为90次。
尽管深度学习分割网络降低了数据预处理难度,只需批量输入图像数据,就能够自动学习萎缩病变特征,达到分割的目的。但是,由于训练深度学习网络需要较多图像数据,并为了避免过拟合,本文采用以下3种数据增广方法来扩增高度近视数据集:
(1)翻转。本文采用水平翻转的数据扩增方法。
(2)图像亮度调整。将随机生成的亮度值叠加到原始图像的像素值上。
(3)旋转和尺度变换。在一定角度之间随机地选择一个角度进行旋转和对图像坐标做尺度变换。
为了更好地说明MSS-V-Net模型的图像语义分割效果,3个模型分别在原始数据集和优化数据集上进行6组对比实验。
在训练过程中,每个epoch都用验证集对模型进行评估,并只保留Dice相似系数值最大的模型作为最终模型。
5.4 实验结果及分析
在本文的实验过程中,训练集和验证集的Dice损失函数,在每个模型训练的初始阶段存在较大的差异,但是最终模型都达到收敛状态且收敛时Dice值相差不大,无法判断模型好坏。为此,本实验主要用测试集判定模型的泛化能力。
在测试集上,分别采用V-Net、MS-V-Net和MSS-V-Net提取原始图像和优化图像的轮廓并计算Dice的盒图作为评价指标。
图10a和图10i为原始图像,图10e和图10m为标签,图10b~图10d分别为V-Net、MS-V-Net和MSS-V-Net对原始图像1的分割结果,图10j~图10l分别为V-Net、MS-V-Net和MSS-V-Net对原始图像2的分割结果,图10f~图10h分别为V-Net、MS-V-Net和MSS-V-Net对优化图像1的分割结果,图10n~图10p分别为V-Net、MS-V-Net和MSS-V-Net对优化图像2的分割结果。从图10可以看出,MSS-V-Net和MS-V-Net的分割结果相较于V-Net的分割结果,更好地拟合了高度近视萎缩病变的轮廓,存在较少的误分割闭连通轮廓,初步验证了MSS-V-Net在高度近视萎缩病变分割上的可行性和有效性。
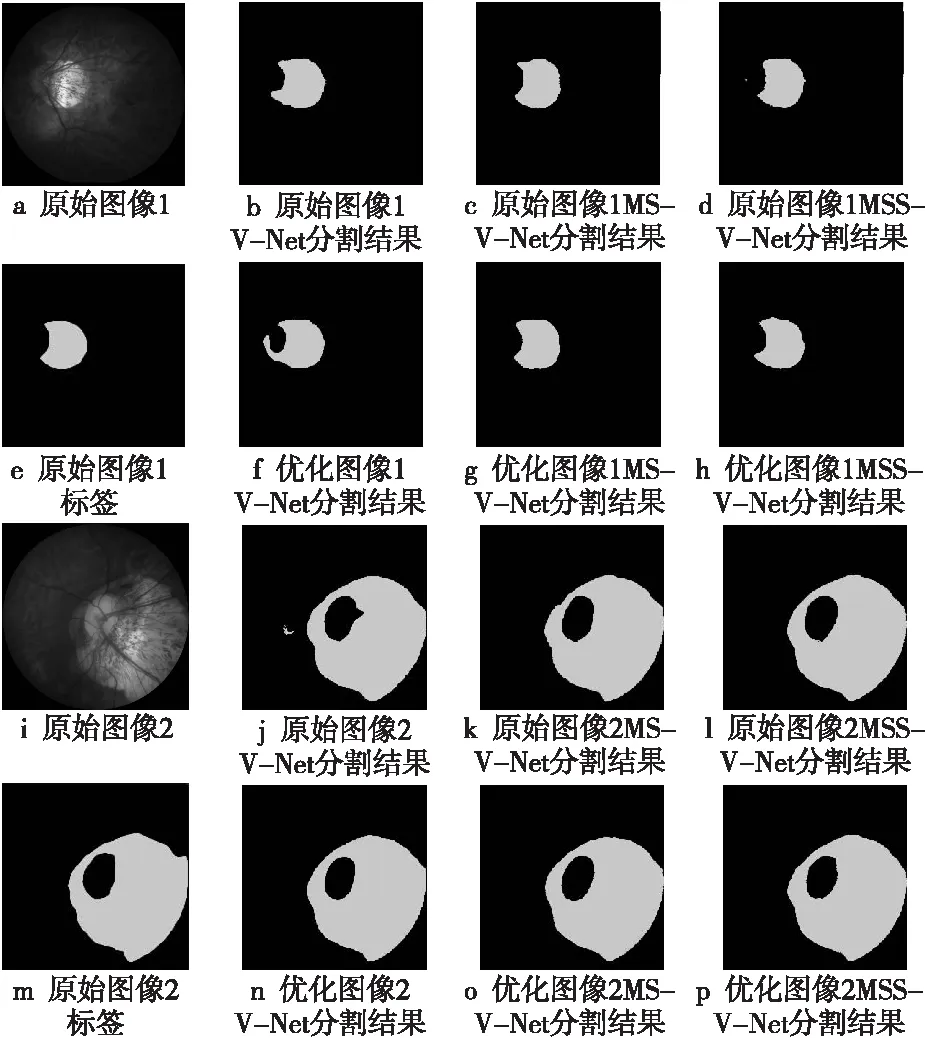
Figure 10 Segmentation results on the data set图10 数据集上的分割结果
利用统计学评价指标来分析模型的分割精度。由图11可知,只有MSS-V-Net和MS-V-Net在优化数据的情况下不存在离群点,V-Net在原始数据集、优化数据集上分别有1,3个离群点,MSS-V-Net、MS-V-Net在原始数据集上均有2个离群点。图11中V-Net、MS-V-Net和MSS-V-Net的Dice盒图都呈现中位数变大,盒子长度变短,上下间隔变小,盒外的2条线长度变短的趋势。可知,总体上MSS-V-Net 和MS-V-Net 的鲁棒性均高于V-Net的,并且MSS-V-Net 也比MS-V-Net 具有更好的泛化能力和分割精度。
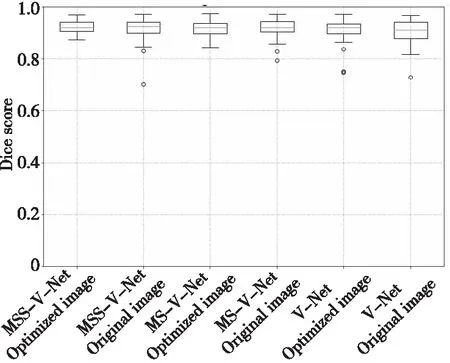
Figure 11 Box-plot of Dice图11 Dice盒图
值得一提的是,分割结果可能存在一些零散分割区域,这包括2种情况:(1)这些区域并不是病变区域;(2)这些区域依附在主体的分割病变区域上,大概率这些离散区域本身就是病变区域。这2种情况的零散分割区域能够相互抵消,导致了即使经过消除实验,Dice相似系数值也相差无几,消除实验的作用在该任务中显得微乎其微,因此本文只分析原始分割结果数据作为结论。
综上可知,MS-V-Net网络能够更细粒度地利用上采样过程中的低层特征和高层特征的语义信息,通过融合这些信息特征提升网络分割精度。MSS-V-Net通过在不同融合层引入多个分类目标函数,实现对连续融合层学习到的信息特征提供直接监督,不像传统的深度卷积网络主要依赖最后层计算预测误差再进行反向传播来指导前面层的学习。
6 结束语
在计算机辅助高度近视的诊断与治疗的系统中,图像分割系统能够预测到高度近视病变严重程度,供医生进一步确认患者病情,这些工作不仅提高了诊断效率和精确度,而且还提供了病变筛查的可行措施。本文采用具有多尺度深度监督思想的模型来分割高度近视萎缩病变眼底图像区域。该模型不需要人工提取病变信息特征,只需利用分割网络强大的信息表征能力进行自动学习,即可直接获得分割结果。针对图像分割问题,该模型与原始的V-Net相比,充分地利用了眼底图像丰富的语义信息,更为有效地适应病理性高度近视的复杂特征,且具有强大的自主学习能力、泛化能力和鲁棒性等优点。值得一提的是,本文提出的图像优化算法无需复杂的处理工作,就能够获得结构清晰、风格统一的眼底图像,并使模型可以获得相对较好的分割精度。
更为重要的是,作者使用多尺度深度监督方法参加Grand Challenge-KiTS19 Challenge[21]竞赛,在分割CT图像的肾脏与肿瘤的任务中,取得了第7名[22]的比赛成绩[23],虽然不是针对眼底图像的相关疾病分割的竞赛,但是也一定程度上证明了本文方法的可行性和有效性。
