基于二元与三元模型相结合的句法规则层次化分析算法
2021-08-06张海玲邵玉斌贾继康杜庆治
张海玲,邵玉斌,贾继康,龙 华,杜庆治
(昆明理工大学信息工程与自动化学院,云南 昆明 650500)
1 引言
随着信息时代的潮流发展,人们对自然语言处理NLP(Natural Language Processing)的研究也更加如火如荼。 NLP是一个交叉学科,涉及的技术范畴众多,例如语音合成与识别、句法分析和语言模型[1 - 3]等,现已广泛集成到Web和移动应用程序中,帮助实现人与计算机之间的自然交互,显然已是信息社会中不可或缺的一部分。句法分析是自然语言处理中的关键技术之一,其基本任务是确定句子所包含的句法单位和这些句法单位之间的依存关系。宾州中文树库CTB(Chinese TreeBank)[4]的发布,不但为汉语句法分析提供了一个公共的训练、测试平台,也促进了句法分析的发展,使得句法分析成为自然语言处理应用的关键因素,在机器翻译、问答系统、信息检索与抽取和语音识别等领域都有重要的应用价值[5]。
句法分析的研究主要有基于统计和规则的方法[6,7]。由于语种的特点,特别是汉语,大部分句法分析的研究都处在字、词、语块的阶段,在语句成分方面的研究甚少[8]。虽然目前已有多个原本为英语制定的句法分析模型被移植到CTB上来[9],但是还存在以下问题:中文不具有诸如英语、法语等其他语言那样严格意义的形态变化[10,11],忽略了汉语的局限性及特点。若针对某一类语料构建句法分析器,那么该句法分析器对该类型句子的句法分析效果较为显著[12],但若用该句法分析器对通用语料进行句法分析,其效果就会大打折扣。
从句子成分角度来看,无论是独立语,还是具有修饰成分的句子,句法分析研究都是从字、词角度实现。若从局部出发[13],而不是对整个句子进行层次化分析,就会存在一定的局限性。因此,本文提出了一种实现层次化分析句子成分的算法,该算法首先使用海量的真实文本作为数据集,进行目标测试;其次,以分词及词性标注为前提,根据语法和统计制定的语言规则为基础,实现二、三元词结合的句法分析模型。综合来说该算法既保留了二元、三元的规则特性,又对语言规则进行了更全面的融合且有效提高了层次化分析准确率,相比较从字、词的研究角度出发的基于RNN(Recurrent Neural Network)的中文二分结构句法分析方法的序列标注模型[14]和词汇化模型[15],准确率均有明显提升,为未来关于句法分析的研究提供了比较新颖的思路。
2 规则和句法层次化定义及词性最优模型
2.1 句法层次化定义及表示
设S=[w1,w2,w3,…,wi-1,wi,wi+1,…,wn],其中S表示由n个词元有序组合而成的句子,字符wi表示S的第i个词元,wi具有表1中的某个词性。
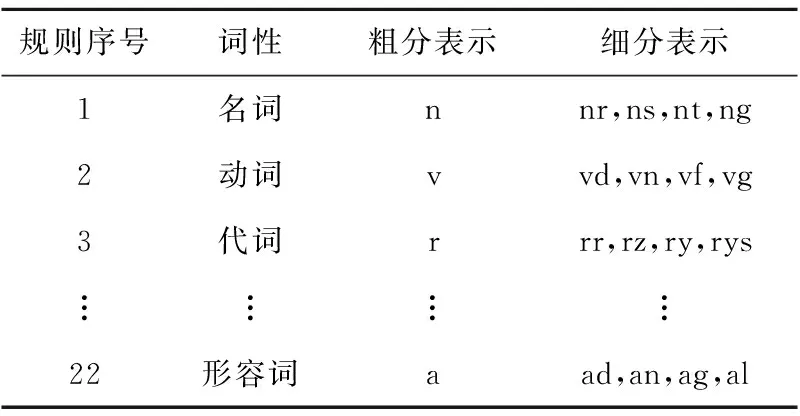
Table 1 part-of-speech tag set
其中,第2~4列分别表示词性、词性粗分以及细分表示。nr,vd,rr和ad依次表示:人名、副动词、人称代词和形容词性惯用语。
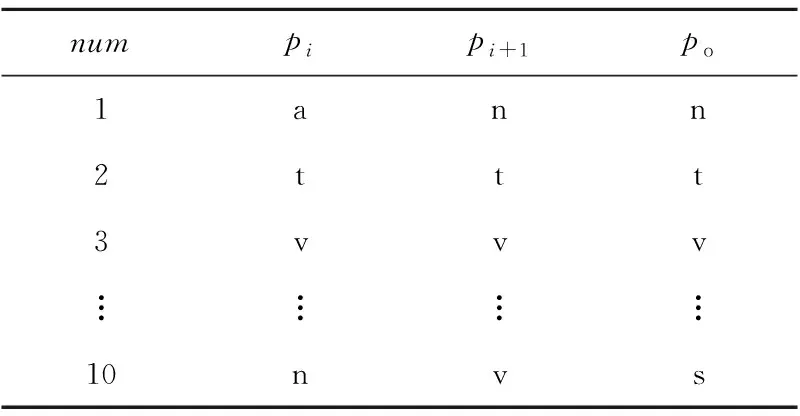
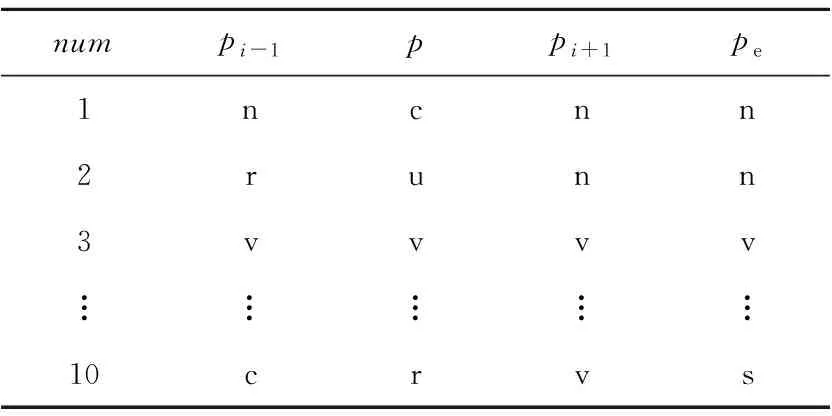
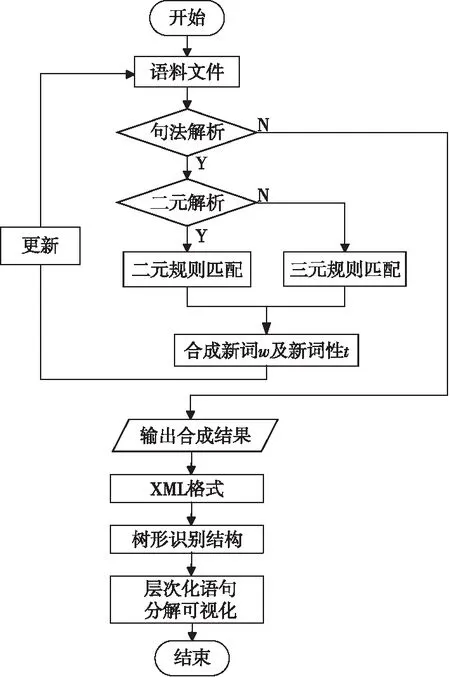
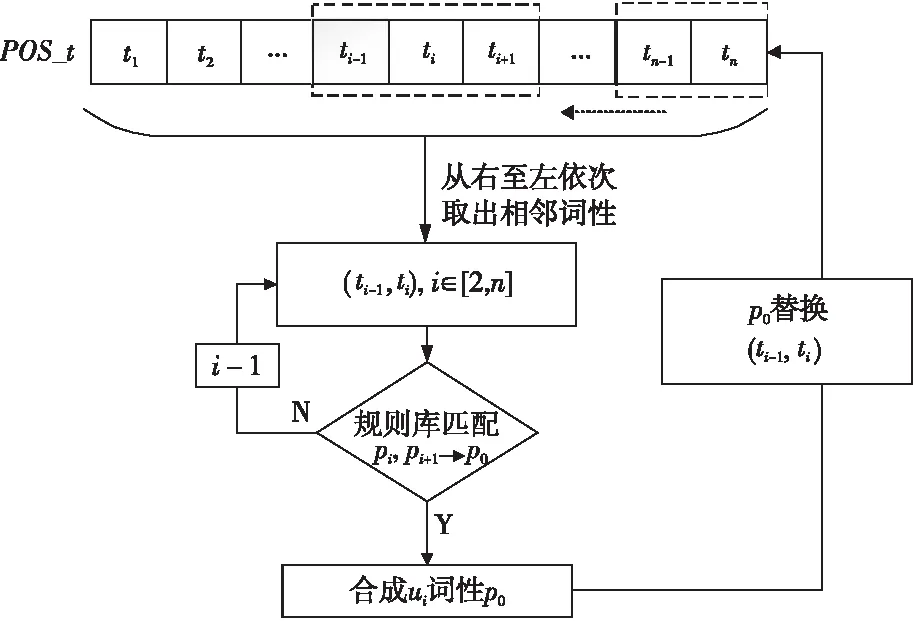
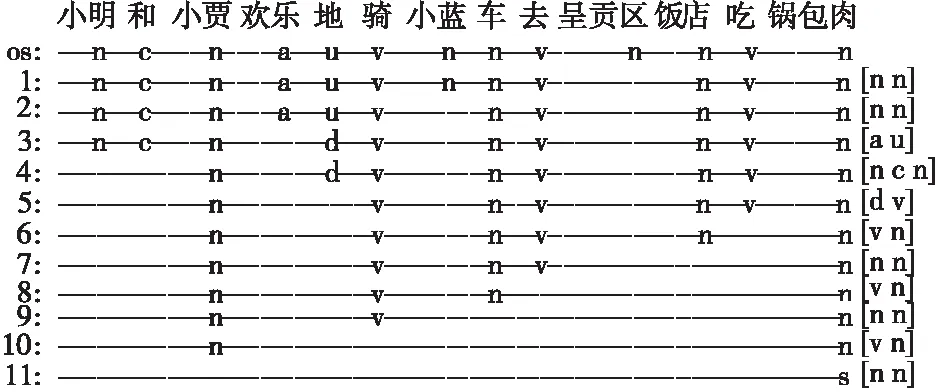
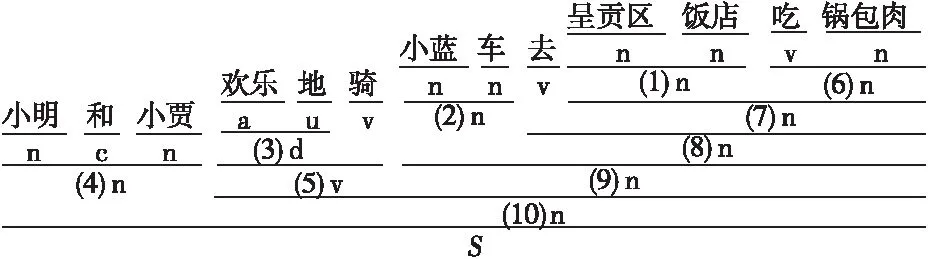
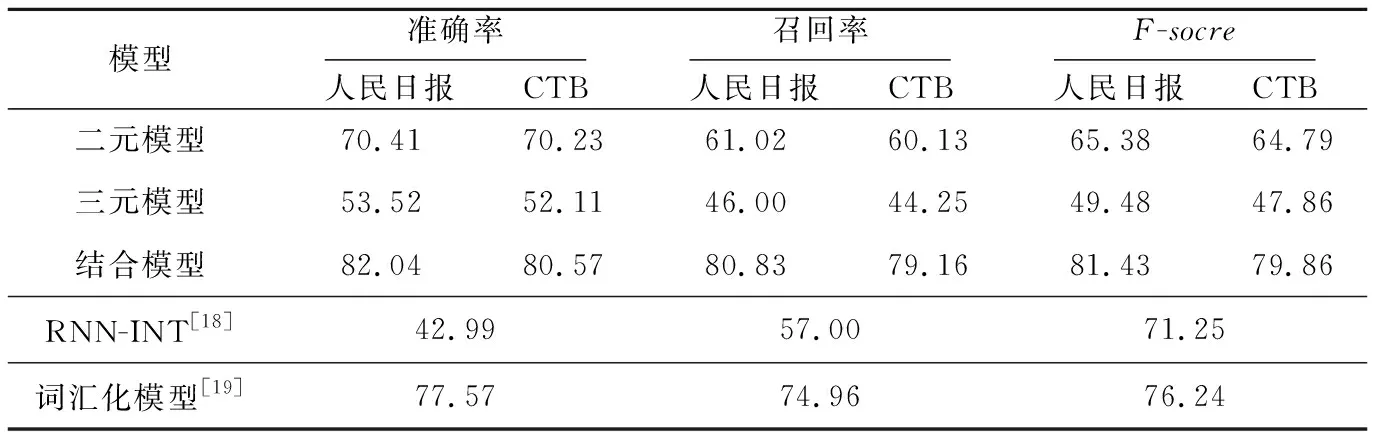
按照句法合成规则,将句子S通过S1→S2→…→Si迭代合成,最终得到最优合成结果Si,其中0≤i 具体句子的层次化分析,如图1所示。 Figure 1 Hierarchical analysis diagram图1 合成示意图 图1中,Source为原始句子及其词性,Target为目标合成句子及其词性。第i+1步是在第i步的基础上合成的,例如,第2步是在第1步基础上利用规则[n n],将“邓小平”与“同志”合成得到“邓小平同志”。 在制定句法规则时将采用中国科学院计算技术研究所汉语词性标记集[16],其共计99个词性标记(22个一类,66个二类,11个三类)。为了在制定规则时能够实现有效性及合理性,即采用词性标记集作为规则需要,词性标记集如表1所示。 在句子S=[w1,w2,…,wi-1,wi,wi+1,…,wn]中,词元wi具有表1中的某个词性。例如:(wi|ti)表示wi的词性为ti。 S中相邻的2个词(wi,wi+1)记为一个二元词单元ui,所在位置不可颠倒,即(wi,wi+1)≠(wi+1,wi)。由于汉语词通常具有多类词性,根据汉语词性标记集可对一个词进行多种词性划分,而在统计方法中,以条件概率来判定词语划分和词性标注结果。中文词汇与其对应词性的最佳组合为: (1) 其中,W=[w1,…,wn]表示n个词元组成的有序序列,T=[t1,…,tn]表示与W相对应的词性序列。由条件概率公式可得: (2) 式(2)中分母P(S)与词元序列、词性序列无关,为常数,故可省略,式(2)即可简化为: [Wbest,Tbest]=arg maxP(W,T,S) (3) 由于求解句子S的最优词元和词性的组合,即为求解每一部分的最优词元W和词性T的组合,进一步可得: (4) 由式(4)可知,如何计算概率P(W,T)是分词和词性标注问题的关键,根据一阶马尔科夫过程[17]的性质可得: P(W,T)=P(T)P(W|T)= P(t1,t2,…,tn)P(w1,w2,…,wn|t1,t2,…,tn)≈ (5) 由于词的词性同上下文中的词及其词性都有密切联系,即根据式(5)可得: P(W,T)=P(T)P(W|T)= P(t1,t2,…,tn)P(w1,w2,…,wn|t1,t2,…,tn)= P(t1,t2,…,tn,w1,w2,…,wn)= (6) 为了在层次化分解过程中能够获取当前唯一词性,需要进一步实现适当的线性平滑,对式(6)进行变形: P(ti,wi|ti-1,wi-1)= P(t1|ti-1,wi-1)·P2(wi|ti-1,wi-1,ti) (7) 实现线性插值平滑: P(ti,ti-1,wi-1)= λ1P(ti|ti-1,wi-1)+(1-λ1)P(ti-1,ti) (8) P(wi,ti-1,wi-1,ti)= λ21P(wi|ti-1,wi-1,t1)+(1-λ21)· [λ22(P(wi|ti-1,ti)+(1-λ22)P(wi|ti))] (9) 其中, (10) 通过极大似然估计法获取概率P(x|y),从而选择更为恰当的合成词性,其中λ1,λ21,λ22为平滑参数,P(ti,wi|ti-1,wi-1)是根据前一个词及词性实现对当前的词及词性的概率估计。 在NLP领域中,分词和词性标注是一项基础且重要的任务。在分词和词性标注正确的情况下,可进行句法分析。例如,S=[我|n,是|v,中国|n,人|n],通过P(x|y)=count(中国,人)/count(人)进行概率估计,根据ui=(wi,wi+1),从而(中国|n,人|n)=(中国人|n),即得到一个新合成词ui为“中国人”,词性ti为名词,其中合成词是通过2.1节所描述的句法规则实现合成。若出现S=[我|n,是|v,中|v,国|n,人|n]分词和词性标注不准确的情况,则会出现“是中”“国人”这样的新合成词,从而对句法分析造成影响。但是,目前分词和词性标注技术已较为成熟,可以忽略这种极少数的情况。 为了实现句法合成规则制定的有效性和简易性,所有词性类别都将以给定词性标注集中的粗分表示作为词性标记,最终得到由词和词性组成的句子S,如下所示: S=[w1|t1,w2|t2,…,wi-1|ti-1,wi|ti, wi+1|ti+1,…,wn|tn] 根据对汉语句法分析的研究和理解,以及句式结构之间的相关性[18,19],本文将提炼出的词性标记集和语言之间的常见规则集合结合到一起,构建出表2所示的二元句法规则库。其中,pi,pi+1表示符合二元词性规则的初始词性,po表示二元合成词性。 Table 2 Binary syntactic synthesis rule base 根据图1所述合成方式,获取二元词ui的词性。例如num=3时,pi=v,pi+1=v,则po=v,即二元词词性为动词。(pi,pi+1)满足句法合成规则: ui=(wi,wi+1) (11) Pt=(ti,ti+1) (12) Pt为二元词ui的词性合成结果。ui的新词性记为: (ui|Pt)=(wi|ti,wi+1|ti+1) (13) Pt由二元词性(ti,ti+1)决定,根据表2中的二元规则库和图2所述的匹配过程合成,Pt=po。 对句子S实现层次化分析合成: S=[w1|t1,w2|t2,w3|t3,…,wn|tn] S1=[w1|t1,w2|t2,u1|t′1,…,wn|tn], u1=(w3,w4) S2=[w1|t1,w2|t2,u1|t′1,…,u2|t2,…,wn|tn], u2=(w10,w11) S3=[w1|t1,u3|t′3,…,u2|t′2,…,wn|tn], u3=(u1,w2) ⋮ Si=[…,u3|t′3,…,u2|t′2,…,ui|t′i,…], ui=(wi,wi+1) ⋮ (14) 句子词元按照倒序的原则,规则库按照自顶向下的方法进行解析。句子S匹配合成得到ui,新的Si再次遍历规则库进行下一次的匹配合成,其中ui可能还会与相邻字符wi实现匹配,直至规则库中无可匹配规则为止。 按照S′=[wn|tn,wn-1|tn-1,…,wi|ti,…,w1|t1]的顺序扫描S′实现: [wn|tn,wi|ti,…,w1|t1](pi,pi+1)=Si (15) 式(15)是针对式(14)的一个说明,表示依据表2中的句法合成规则,实现按照倒序原则对S′和规则库中所对应的词性进行交互,实现规则匹配。如若倒序过程中,句子中词元的词性与规则库中的po属性相同,则输出第i次合成句子的结果Si。在Si基础上再通过匹配规则进行合成,输出Si+1: […,u3|t′3,…,ui|t′i,…](pi,pt+1)=Si+1 (16) 其中,Si为第i(1≤i≤n)次合成句子成分结果,Si+1是在Si合成的基础上再依据表2的合成规则,按照图1所述方式实现合成,直到没有规,则可匹配则合成结束。 三元句法合成规则库与二元的构建原则类似,如表3所示。 Table 3 Ternary syntactic sythesis rule base 其中,pi-1,pi和pi+1表示符合三元词性规则的初始词性,pe表示三元合成词性。根据表3所述句法合成规则,S=[w1,w2,w3,…,wi-1,wi,wi+1,…,wn]满足: vt=(wi-1,wi,wi+1) (17) Pt=(ti-1,ti,ti+1) (18) 其中,相邻的3个词(wi-1,wi,wi+1)记为一个三元词vt。Pt为词单元vt的词性合成结果,即Pt=pe。根据式(11)~式(13)所述原则,合成的新词元vt具有新的词性,记为: (wi-1|ti-1,wi|ti,wi+1|ti+1)=(vt|Pt) (19) 句子S层次化分析满足: S1=[v1|t′1,…,wi|ti,…,wn|tn], v1=(w1,w2,w3) S2=[v1|t′1,…,v2|t′2,…,wn|tn], v2=(w10,w11,w12) ⋮ Si=[v1|t′1,…,v2|t′2,…,vt|t′t], vt=(wi-1,wi,wi+1) ⋮ (20) 在层次化分析过程中,句法解析同二元过程,即句子词元按照倒序的原则,规则库按照自顶向下的方法进行解析,而并非依据字符下标i升序。按照三元规则库实现匹配,输出Si,产生新的合成词vt,再次依据规则匹配输出,一直到没有可匹配规则为止,其中0≤i (ti-1,ti,ti+1)=Pt=pe (21) 其中ti-1,ti,ti+1是3个连续词元各自的词性。扫描S′则需要满足: [wn|tn,…,wi|ti,…,w1|t1] (pi-1,pi,pi+1)=Si (22) 句子解析过程中判断匹配是否满足Pt,如若倒序过程中满足Pt等于pe,即符合三元规则,输出第i次合成句子成分的结果Si,在最新合成句子成分结果的基础上继续进行合成,直到没有可匹配的合成规则,合成结束。其中0≤i 3.3.1 算法分析及流程 本文利用句法中词性间的紧密联系性,对句法规则进行了总结和统计,首先提出了二元和三元的层次化模型。但是,由于中文本身的复杂性和语义多变性,独立的二元或者三元模型在进行汉语句法结构分析时具有一定的局限性,效果不佳,为了更好地适应句式成分,于是本文提出了二元词与三元词相结合的模型,进而实现层次化句法分析。具体流程如图2所示。 Figure 2 Diagram of hierarchical statement analysis algorithm 图2 层次化语句分析算法流程图 二元和三元规则匹配的具体流程如图3所示。根据表2和表3的规则库文件,实现由pi,pi+1或pi-1,pi,pi+1匹配合成得到po或pe。其中,POS_t是由句子S=[w1,…,wi-1,wi,wi+1,…,wn]获取的词性序列[t1,t2,…,ti-1,ti,ti+1,…,tn-1,tn],对该序列从右至左依次获取词性,对连续词元的词性进行规则库匹配,合成新的ui的词性,再对原词性序列进行替换,直至遍历完POS_t。 Figure 3 Rule matching diagram图3 规则匹配示意图 3.3.2 层次化解析 具体算法描述如算法1所示。 算法1基于二元与三元模型相结合的句法规则层次化分析算法 输入:语句S=[w1|t1,…,wi|ti,…,wn|tn]。 输出:可视化的语句层次化分析。 步骤1按照从右至左的顺序提取(ti,ti+1); 步骤2按自顶向下的方式遍历二元规则文件; 步骤4如若二元规则文本与S不匹配,则按照ti+1titi-1倒序方式遍历三元规则文件; 步骤5三元规则文本和S进行匹配; 步骤7如若S与三元规则不匹配,则输出Si-1,其中Si-1表示上一步合成的结果; 步骤8继续解析Si/Si-1; 步骤9循环步骤2~步骤8,判别Si/Si-1是否能继续被合成; 步骤10将Si/Si-1转换为XML格式; 步骤11将XML格式转化为可识别目录树形格式文本。 其中,在句式中能合成的二元词汇普遍多于三元词汇,所以算法设计先遍历二元规则,在层次化语句分析过程中,利用分词和词性标注模型获取句子中每个词元的当前最新词性,并对其进行标注,例如中文句: S=[小明|n,和|c,小贾|n 欢乐|a 地|u 骑|v,小蓝|n,车|n,去|v,呈贡区|n,饭店|n,吃|v,锅包肉|n] 图4所示为该中文句的具体的层次化解析过程。 Figure 4 Statement decomposition example图4 语句解析示例 将整个层次化语句解析过程转化为能够被识别的树形结构格式,进而实现语句解析可视化结果,如图5所示。 Figure 5 Hierarchical statement parsing visualization example图5 层次化语句解析可视化示例 本文实验采用了1998年人民日报的语料和CTB数据集(部分),其中人民日报选择22 565个句子,CTB数据集选择10 362个句子,按照程序兼容性格式处理后作为实验测试语料。通过二元和三元词相结合的层次化分析方法实现语句的分析合成。 语句分析评价指标主要有:准确率P、召回率R和F-score,如式(23)~式(25)所示: (23) (24) (25) 其中,A为系统反馈的正确的解析结果个数;B为系统反馈的错误的解析结果个数;C为文本中总的句子个数。 通过二元、三元以及二者相结合改进模型的3种方式,分别对语料文件逐句处理,若句子最终合成结果为S,则将该句子记为系统反馈正确的解析结果;否则,记为系统反馈的错误的解析结果。若句子包含不可识别的词性或标点符号,则表示系统反馈不能解析该句子。 为验证本文方法的准确率及适用性,将实验分为3组进行。首先对语料进行选取和预处理操作,然后分别构建二元模型、三元模型以及结合模型,对3种模型进行实验,最终得到如表4所示的实验结果。 通过二元规则模型,在人民日报语料上所获取的准确率、召回率分别为70.41%,61.02%;通过三元规则模型语句分析所获取的准确率、召回率分别为53.52%,46.00%,造成未能成功解析语句的主要原因有: (1) 对于准确率评判规则的定义不够全面,导致反馈分析结果比较单一。 (2) 二元和三元规则的设定未能较全覆盖语料,导致层次化分解结果出现误差。 (3) 三元规则合成的结果值偏低,是由于语料中涉及连词的部分并不很多,且三元规则基数小于二元规则基数,所以合成难度较大。 Table 4 Experimental results of statement hierarchical analysis 4) 由于语料库中词性种类偏多,在解析过程中可能未识别未登录词性,从而导致无法进行句法识别分析。 在改进模型中,在人民日报语料和CTB语料上的准确率、召回率分别是82.04%,80.83%和80.57%,79.16%,与其他模型相比明显提高。而从字、词的研究角度出发的较新的句法分析文献[18,19]中提出的基于RNN的中文二分结构句法分析方法中的RNN-INT模型和基于词汇化模型的汉语句法分析,其准确率分别为42.99%,77.57%。本文算法在文献[18,19]的基础上进一步提高了句法分析识别的准确率,同时本文所提方法是一种较新颖的句式结构研究方法。从实验结果可以看出,只要获取词元的词性和定义的层次化语句合成规则能够满足语料需求,同时评判结果的指标足够全面,实验最终得到的语句解析的准确率也就会相应提高。 在自然语言研究中,依存句法的发展始终受到汉语自身特点的限制。由于目前关于句法分析的研究大部分是从字、词角度出发的,准确率相对而言不够高,而从句式结构角度出发的研究相对较少,所以本文基于海量的人民日报语料,通过由语法和统计得出的语言规则,从而实现了中文的语句分析和区别于依存句法可视化句法树分析,准确率达到82.04%,效果比较理想。本文所提方法相较于已有的依存句法方法更为灵活、新颖,对之后进一步进行文本校对、机器翻译和信息抽取等工作具有很好的参考价值。 由于中文本身的复杂性和语义多变性等特点,使得对汉语进行句法分析研究较为困难,而本文提出的在语言规则下的句法分析算法,能够针对句式成分,在层次化分析过程中得到有效、良好的效果。但是,随着社会的发展,很多词都会潜移默化地产生额外的词性,若作为句法分析基础工作的分词和词性标注不够准确,则会增加句法分析的难度。后续需要对本文方法做进一步完善。
2.2 词元结合规则及词性最优模型

3 句法合成的依存关系模型构建
3.1 二元层次化模型构建
3.2 三元层次化模型构建
3.3 二、三元结合层次化模型构建


4 实验设计与结果分析
4.1 实验设计
4.2 结果与分析
5 结束语
