基于GPU加速的脉冲多普勒雷达信号处理
2021-08-06冯建周赵仁良冷佳旭
龚 昊,刘 莹,冯建周,赵仁良,冷佳旭
(1.中国科学院大学计算机科学与技术学院,北京 100089;2.中国科学院大学数据挖掘与高性能计算实验室,北京 100089;3.燕山大学信息科学与工程学院,河北 秦皇岛 066004)
1 引言
雷达信号处理算法的高性能加速是现代雷达技术中至关重要的一环。传统的雷达信号处理技术包括数字信号处理器DSP、现场可编程逻辑阵列FPGA和专用集成电路ASIC等[1 - 3],虽然这些技术已经得到了大量的应用,但是它们都属于专用设备,具有开发周期长、调试难度大等缺点,在开发和测试过程中需要耗费大量的资源。而GPU属于通用设备,随着NVIDIA、AMD等GPU厂商芯片技术的快速发展,CPU-GPU异构计算体系结构已经走进了千家万户,CUDA的出现更是大大简化了程序员和科学家们对GPU进行编程的难度,基于CUDA的GPU开发环境逐步发展为成熟的货架产品。
与CPU相比,GPU的众核结构特别适合处理雷达信号这种大规模数据[4 - 6],它的出现让雷达信号处理领域焕发了生机。国内外关于使用GPU加速脉冲多普勒雷达这种目标探测雷达的研究比较少[7 - 19],大部分研究成果都集中在SAR成像这种对实时性要求高的情景之中。文献[8]针对脉冲多普勒雷达信号处理中的脉冲压缩环节,采用FFTW(Fastest Fourier Transform in the West)和CUFFT(CUDA Fast Fourier Transform library)2种实现方式进行了性能基准测试,并分析了时域脉冲压缩和频域脉冲压缩2种实现方式的性能差异。虽然实验结果表明频域脉冲压缩可以取得更好的性能收益,但是并没有针对脉冲压缩模块进行有针对性的性能提升与优化。文献[11]研究了脉冲多普勒雷达中恒虚警率算法的GPU实现,虽然文中的方法降低了算法的复杂度,提高了并行性,但是总的计算量并没有减少,提升空间有限。文献[14]提出了一种基于GPU共享内存的恒虚警率算法,虽然使用共享内存可以优化程序的效率,但还是不可避免地引入了过多的重复运算。文献[15]研究了脉冲压缩模块在不同数据处理规模和结构下,GPU硬件上的计算资源分布与基于CPU平台的加速性能之间存在相关性,并基于实证数据提出了一种基于GPU的资源优化配置方法。但是,在大部分情况下,脉冲压缩只是整个雷达信号处理系统中的一个流程,对其资源的过度倾向势必会影响到其他模块。
本文提出了一套完整的脉冲多普勒雷达信号处理GPU并行化方法。通过对脉冲多普勒雷达信号处理程序进行热点测试来分析程序的性能瓶颈并进行针对性优化。本文的贡献主要体现在以下几点:(1)针对大规模雷达数据并行所造成的线程过度利用问题,提出了一种利用网格跨步并行技术[20]优化雷达信号处理的方法。该方法能有效地解决GPU创建和撤销线程所造成的时间开销,提高硬件资源利用率。(2)针对大规模雷达数据所造成的数据传输开销,提出了一种利用多流异步处理技术加速脉冲多普勒雷达信号处理的方法。该方法能显著降低大规模雷达数据的数据传输延迟,减小性能瓶颈。(3)针对恒虚警率CFAR(Constant False-Alarm Rate)算法中存在的冗余计算问题,提出了一种使用并行扫描来进行算法模块数据预处理的方法。该方法能有效地避免重复计算,对于大规模的数据有明显优势。(4)设计了对比实验,从性能测试和误差分析等多角度来评估并行算法的准确性和实时性。
2 脉冲多普勒雷达信号处理算法分析
2.1 脉冲多普勒雷达信号处理流程
如图1所示,脉冲多普勒雷达信号处理包含脉冲压缩模块、动目标显示模块、动目标检测模块和恒虚警率模块4个基本功能模块。
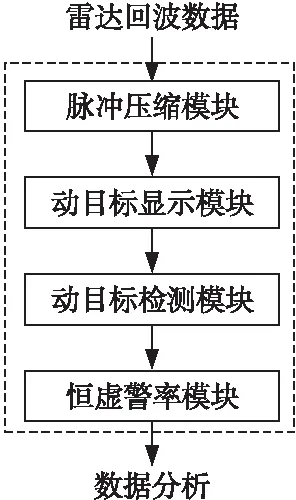
Figure 1 Flow chart of pulse Doppler radar signal processing图1 脉冲多普勒雷达信号处理流程图
2.2 热点测试
将采样率设置为1 GHz,产生40个雷达脉冲,总的采样点数为9 600 000,对CPU程序利用Intel VTune进行热点测试,结果如表1所示。
回波信号仿真模块包括产生线性调频信号和产生模拟回波信号2个部分,是程序中最耗时的部分。但是,它并不属于真正的雷达信号处理系统的一部分,它是为了方便进行算法测试而实现的,在实际应用中这部分会被来自Rapid I/O等高速接口的真实数据所替代。

Table 1 CPU program hotspot test
初始化和内存释放这2个步骤在整个程序的生命周期中只需要进行一次,而脉冲压缩模块、动目标显示模块、动目标检测模块和恒虚警率模块这4部分是雷达信号处理系统的核心,需要进行针对性的加速。其中脉冲压缩模块和恒虚警率模块是雷达信号处理系统中耗时最多的2个部分,本文将对这2个部分进行算法并行性分析。
2.3 算法并行性分析
2.3.1 脉冲压缩模块
脉冲压缩模块的作用是将信号的宽脉冲压缩成窄脉冲,从而提高信号的探测距离和距离分辨率,其最终目的是提高信号的信噪比。脉冲压缩的本质是计算回波信号对匹配滤波器的冲激响应。
脉冲压缩模块需要计算匹配滤波系数,它的计算方法是将原始线性调频信号进行左右翻转变换之后取共轭复数,其表达式如式(1)所示:
h(t)=s*(-t)
(1)
其中,h(t)为系统冲激响应函数,s*(t)为线性调频信号复共轭。
计算冲激响应有2种方法,分别是时域处理和频域处理。对于时域处理,直接计算回波信号对匹配滤波系数的离散卷积即可,如式(2)所示:
s0(t)=h(t)⊗sr(t)
(2)
其中,s0(t)为脉冲压缩结果,sr(t)为回波信号。
对于频域处理,先对回波信号和匹配滤波器的系数进行傅里叶变换,然后将这2种信号在频域进行点乘,如式(3)所示:
S0(f)=FFT{h(t)⊗sr(t)}=H(f)·Sr(f)
(3)
其中,S0(f)为脉冲压缩结果频谱,H(f)为系统函数频谱,Sr(f)为回波信号频谱。
在这一过程中可以对H(f)进行频域加窗,加窗之后的频率响应输出峰值会变小,信噪比也有一定的提升,将点乘的结果再进行傅里叶逆变换即可得到脉冲压缩的结果,如式(4)所示:
s0(t)=IFFT(S0(f))
(4)
时域处理和频域处理这2种方法都可以进行脉冲压缩,但是频域处理可以在计算过程中对频域响应加窗。时域脉冲压缩的计算效率不高,频域脉冲压缩相比较于时域脉冲压缩具有更好的并行性。
在脉冲压缩模块中,多个脉冲可以同时进行脉冲压缩,彼此之间不存在数据相关。对于单个脉冲来说,所涉及的操作也仅有FFT、IFFT和复数乘法这几个基本算子。虽然脉冲压缩算法是程序的瓶颈,但是在GPU并行化的基础上可提升优化的程度有限。
2.3.2 恒虚警率模块
恒虚警率模块也叫做CFAR模块,用于在信号处理的结果中判定目标。CFAR模块会根据每一个采样点周围的幅度信息确定一个门限,超过这个门限的采样点会被判决为目标。图2展示了恒虚警率模块的工作原理。

Figure 2 Schematic diagram of of CFAR module图2 恒虚警率模块原理图
恒虚警率模块主要由平方率检波和杂波功率估计并判决这2个部分组成。其中平方律检波部分是针对单个采样点的变换过程,不存在与其他采样点数据的相互依赖。而杂波功率估计并判决部分在计算每一个采样点的门限值时需要用到相邻采样点的幅度信息,这就在并行之后的算法中引入了归约与扫描计算。能否妥善处理算法中的归约计算是制约算法性能提升的关键。
3 基于GPU的脉冲多普勒雷达信号处理算法并行化技术
3.1 基于网格跨步并行的细粒度并行化
GPU的并行度是有限的,其并行度由硬件执行模型来决定。以Maxwell架构为例,每个SM(Streaming Multiprocessor)单元上最多可调度2个尺寸为1 024的线程块,当线程块数量远大于所有SM单元上可调度的线程块数量时,就需要频繁地进行线程的激活和撤销,造成了不必要的时间开销。基于网格跨步并行的细粒度并行算法如算法1所示。
算法1基于网格跨步并行的细粒度并行算法
输入:雷达回波信号。
输出:雷达信号处理结果。
Step1初始化核函数网格尺寸和线程块尺寸。
Step2主机端调用核函数。
Step3对每一个GPU线程:
Step3.1计算当前线程在网格中的索引;
Step3.2计算当前线程块在网格中的跨度;
Step3.3对每一个分配给当前线程的任务:
Step3.3.1计算雷达回波信号处理结果。
当使用传统方法时需要启用更多的线程块才能完成大规模的计算任务,但是当硬件资源不充裕时,这种方法会造成额外的时间开销,线程块会被频繁地调用。因此,在CUDA编程中应尽可能增加每一个线程的计算量,减少核函数调用的次数。图3展示了数据元素数量大于网格中线程数的情况。图3中下半部分的深色方块代表当前活跃的线程,在这种情况下要想完成计算任务需要唤醒足够多的线程块。
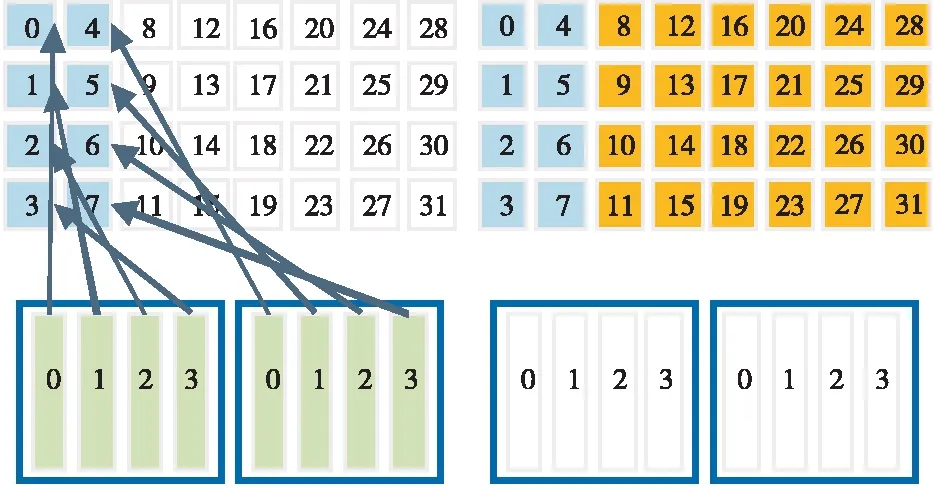
Figure 3 Schematic diagram of the number of data elements is greater than the number of threads in the grid图3 数据元素数量大于网格中线程数示意图
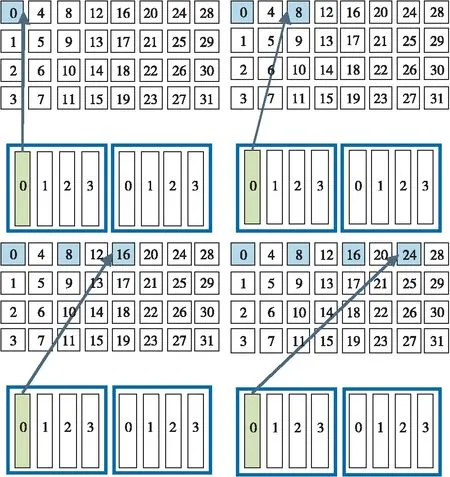
Figure 4 Schematic diagram of single-thread grid striding parallism图4 单线程网格跨步并行示意图
图4所示的网格跨步并行可以很好地解决该问题。对于单个线程而言,在网格跨度循环中,线程计算的第1个元素使用threadIdx.x+blockIdx.x*blockDim.x得出。其中,threadIdx.x表示线程块内线程索引,blockIdx.x表示网格内线程块索引,blockDim.x表示线程块内线程数。然后,线程会按网格中的线程数blockDim.x*gridDim.x向前推进,其中gridDim.x表示网格内线程块数,直到其数据索引超出数据元素的数量为止。
图5展示了当所有线程均按照网格跨步并行的方式运作时,所有计算元素均被覆盖的情况。
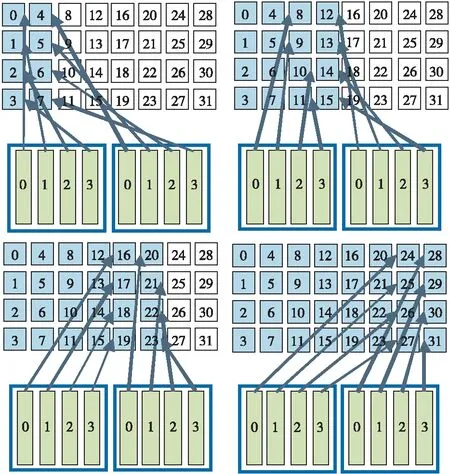
Figure 5 Schematic diagram of all threads grid striding parallism图5 所有线程网格跨步并行示意图
网格跨步并行所使用的核函数尺寸是固定的,一般根据具体的硬件执行模型来设定而不会根据数据规模自动调整。对于每一个线程而言,它会持续进行运算,当所有的运算结束之后线程才会被撤销。
网格跨步并行还可灵活分配核函数对GPU的利用率,当以多线程形式控制GPU完成工作时,GPU会被每一个线程以CUDA流的方式管制。GPU的计算资源是有限的,它并不能保证所有CUDA流的线程块同时运行,必须减小同一时刻每一个CUDA流上核函数对GPU的占有率才能实现多流计算的真正并行。
3.2 基于多CUDA流的粗粒度并行化
GPU的计算资源是有限的,而核函数一般使用尽可能多的计算资源以达到最佳效率,这就意味着2个控制流的计算不会重叠,虽然网格跨步并行可以灵活分配每一个控制流的计算量,但是这样做并不能使GPU持续保持较高的利用率。
CUDA并行计算由CPU和GPU配合完成,在GPU计算时CPU可以以同步的形式等待GPU的计算结果,也可以进行和GPU没有数据相关的计算,这样就可以重叠CPU和GPU的计算,提高程序运行效率。
CPU和GPU的数据流和控制流通信必须经过PCIE总线,这是CUDA程序最大的性能瓶颈。当内存以锁页内存的形式进行分配时,可以避免操作系统请求分页管理将内存以页面的形式换出到磁盘,从而为内存和显存之间异步的数据传输创造条件,主机端与设备端之间异步的数据传输可以与计算重叠起来,以隐藏数据传输延迟。
如图6所示的多CUDA流并发是粗粒度并行方案。图6中H2D代表主机端到设备端的数据传输,D2H代表设备端到主机端的数据传输。多CUDA流并发的重要用途是重叠数据传输和计算的时间,无论是主机端向设备端的数据传输,还是设备端向主机端的数据传输,都可以进行重叠;无论是CPU计算的时间,还是GPU计算的时间,都可以进行重叠。重叠可以增加程序的吞吐量,更进一步地降低延迟。
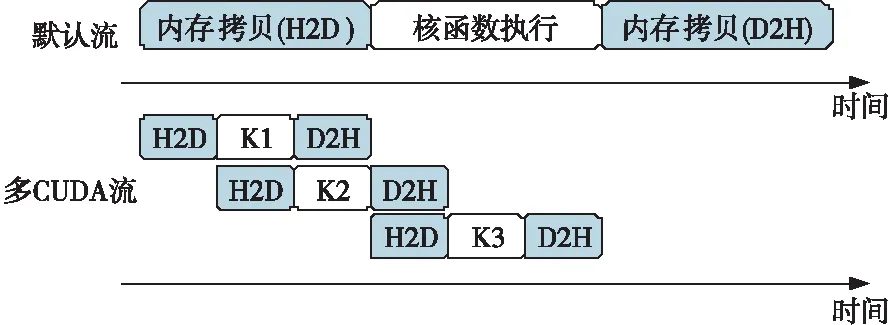
Figure 6 Multi-CUDA stream concurrency图6 多CUDA流并发
3.3 基于并行扫描的数据预处理
在恒虚警率模块中,对于每一个采样点都要完成一次求和运算。采用并行扫描的方法进行预处理可以避免重复运算。在每一次求和运算中,涉及到的数据元素数量非常少,只有几十个数据元素参与归约。而采样点的数据量非常庞大,甚至能够达到吉比特数量级。扫描是一种典型的以空间换时间的方法,当有内存空间可复用时,扫描能够带来很好的收益,如式(5)所示:
sum(i)=sum(i-1)+a(i)
(5)
其中,sum(i)为扫描处理结果,a(i)为采样点数据。
扫描预处理的时间复杂度为O(n),其中n表示参与并行扫描运算的数据元素个数。当需要获取子区间之和时,可以使用式(6)通过O(1)的时间复杂度计算得出。
ans(l,r)=sum(r)-sum(l-1)
(6)
以上展示了串行扫描的方法。当使用CPU完成扫描预处理时,必然会造成主机端和设备端之间的内存传输。Blelloch算法[21]是一种在设备端计算扫描的方法,该算法分为Reduce和Down-Sweep 2个过程。
图7展示了Reduce过程,该过程是使用相邻配对实现的并行归约,为Down-Sweep过程准备了数据。Reduce过程利用所有线程计算出了所有2的整数次幂索引值的和。

Figure 7 Reduce process图7 Reduce过程
图8展示了Down-Sweep过程,该过程是Reduce过程的逆过程。图8中实线箭头代表求和运算,虚线箭头代表赋值运算。

Figure 8 Down-Sweep process图8 Down-Sweep过程
该并行算法的阶跃时间复杂度为O(2 logn),工作时间复杂度为O(n)。
4 实验与评估
本文所使用的测试数据为仿真线性调频信号,具体参数如表2所示。
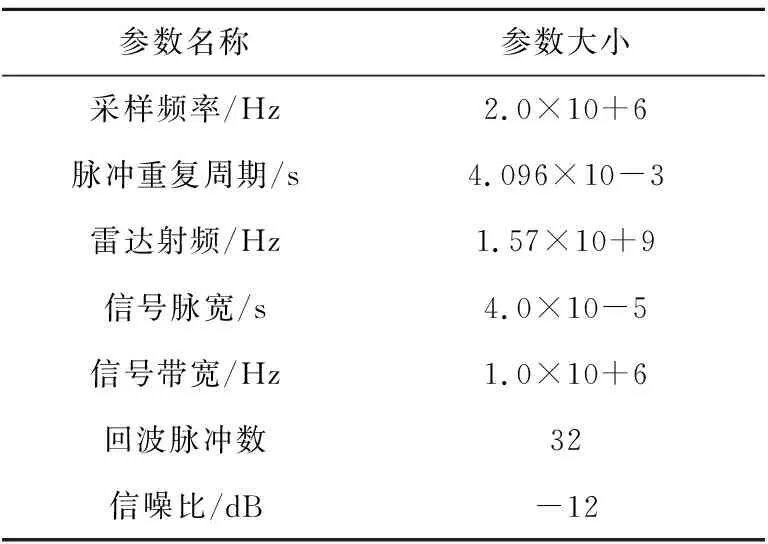
Table 2 Radar simulation signal parameters
4.1 性能测试
CPU实现中的傅里叶变换操作使用了FFTW3.5加速库,GPU实现中的傅里叶变换操作使用了cuFFT10.2加速库。测试所使用的CPU和GPU配置如下所示:
(1)CPU:Intel Core i7-6700HQ。Intel Core i7-6700HQ CPU基于Skylake架构,具有4个物理核心,超线程8线程。它含有2个FMA(Fused Multiply-Add)单元,可同时发射2条256 bit融合乘加指令。Skylake架构的单精度浮点执行单元数的计算公式为:
2(融合乘加指令)× 2(FMA单元数)× 8(1条指令可以处理256/32=8个单精度浮点数)= 32
Intel Core i7-6700HQ CPU的理论单精度峰值浮点运算能力计算公式为:
2.6 GHz (默认主频,超频3.5 GHz) × 32(单精度浮点执行单元数)× 4(物理核心数)= 332.8 GFlop/s = 0.3328 TFlop/s = 0.3328万亿次浮点计算
(2)GPU:NVIDIA GeForce GTX 950M。NVIDIA GeForce GTX 950M GPU基于Maxwell架构,它含有5个SM单元,每个SM单元包含了128个CUDA核心,其理论单精度峰值浮点运算能力计算公式为:
1124 MHz(GPU Boost主频)× 640(CUDA核心数量)× 2(单个时钟周期内能处理的浮点计算次数)= 1438.72 GFlop/s = 1.43872 TFlop/s = 1.43872万亿次浮点计算
不同型号的CPU的物理核心数差异很大。在实践中往往通过比较单核CPU和GPU的性能来衡量加速效果的优劣。
4.1.1 网格跨步并行实验结果
几乎所有的核函数都可以使用网格跨步并行进行优化。为了体现网格跨步并行的性能优势,本文以核函数运算量最大的CFAR模块为例来进行网格跨步并行的对比测试。使用不同的策略在32个雷达脉冲,每个雷达脉冲8 192个采样点的条件下分别进行3次测试,结果如表3所示。
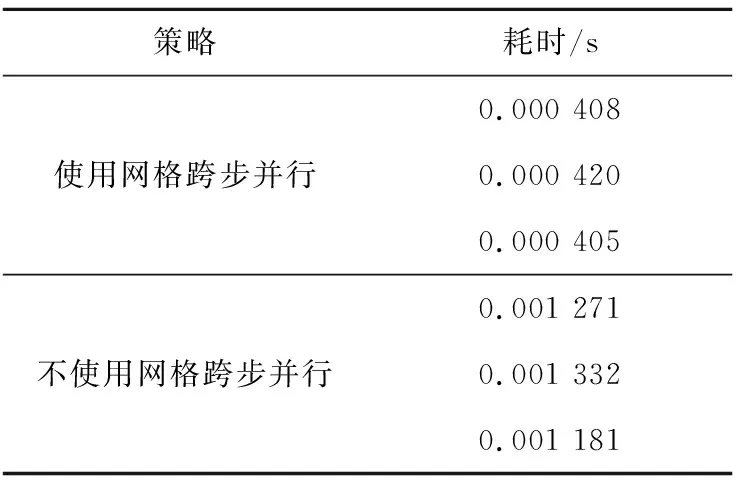
Table 3 Experiment results of grid striding parallism
GPU运算时间分为数据传输时间和内核时间2部分,在本算法中数据传输时间对加速比有显著的影响。本文所统计的时间为这2部分时间之和,网格跨步并行的优化效果只体现在内核时间上。本实验采用了较小的数据量,以更好地体现网格跨步并行的性能提升结果。
4.1.2 多CUDA流并发实验结果
以整个雷达信号处理流程来进行多CUDA流并行的对比测试,在测试中使用1 GHz的采样率,产生40个雷达脉冲,总采样点数为9 600 000,调用脉冲压缩、MTI(Moving Target Indication)、MTD(Moving Target Detection)和CFAR模块100次来模拟算法模块实时工作的情况。由于显存容量的限制,本实验中CUDA流的最大数量为8。在不同的CUDA流数量下进行实验得到的实验结果如表4所示。
在理想情况下多CUDA流并行最多可取得近3倍的速度提升,那是从主机端到设备端的数据传输、从设备端到主机端的数据传输和GPU运算这三者的时间完全重叠的情况。进行不同的任务数据传输和计算所占的比重不同,在本实验中数据传输所占的比重不到1/10,并不能达到理想的时间重叠效果,多CUDA流并行的性能提升只有12%。
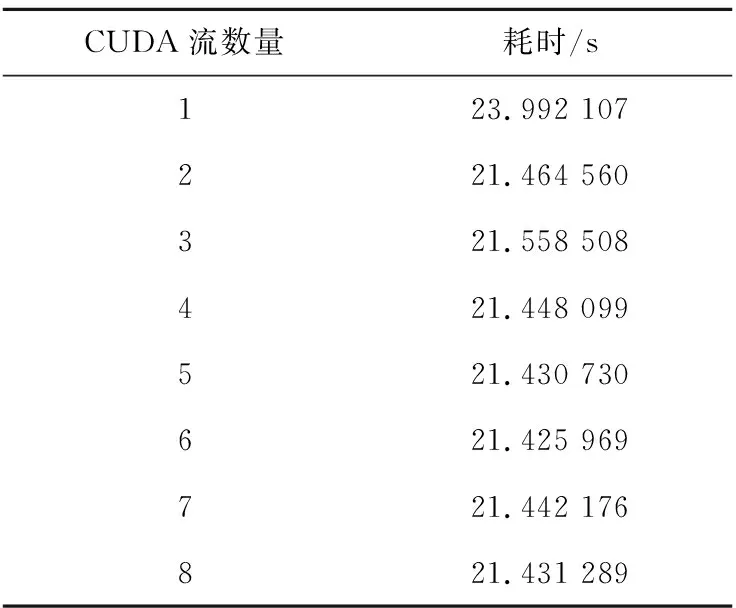
Table 4 Experiment results of multi-CUDA stream parallism
4.1.3 并行扫描预处理实验结果
通过调整采样率来增大数据规模,针对CFAR模块采用非并行扫描和并行扫描2种策略,分别设计程序并进行实验,结果如表5所示。
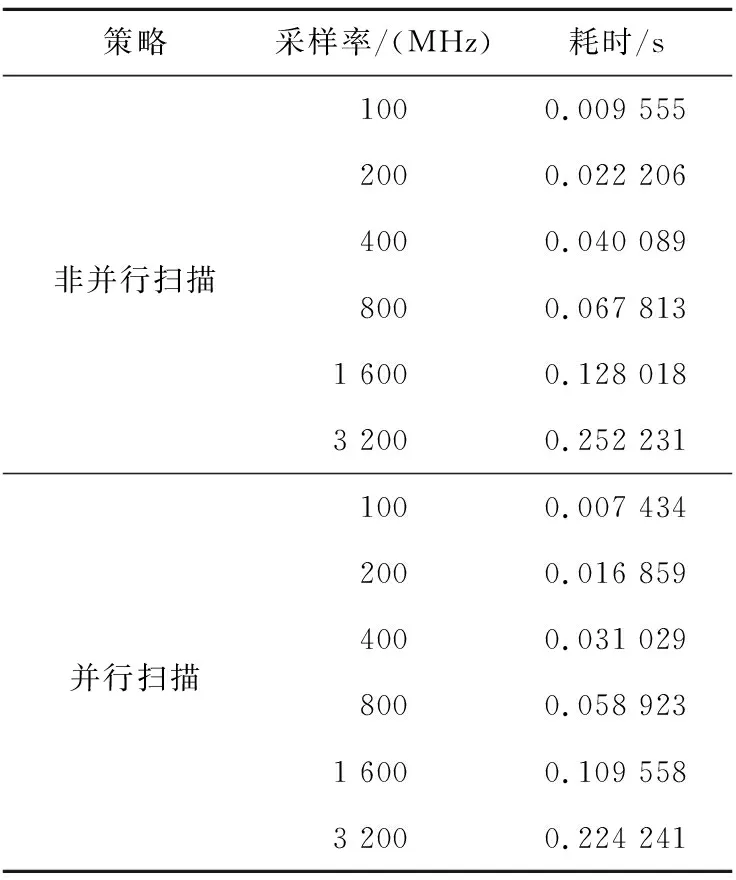
Table 5 Experiment results of parallel scan preprocessing
并行扫描通过对数据的预处理减少了CFAR模块中门限计算时的重复计算,从根本上提升了算法的工作效率。
4.1.4 不同硬件平台性能测试加速比
表6整理了不同硬件平台上和不同采样率下算法CPU实现和GPU实现所消耗的时间之比。实验结果显示,程序在PC机上达到了10倍左右的加速比,在嵌入式设备中达到了42倍左右的加速比。对于PC机来说,GPU运算能力是CPU运算能力的4.3倍;对于嵌入式设备来说,GPU运算能力是CPU运算能力的2.5倍,无论是哪种情况,加速比都超过了计算能力差距,这说明针对GPU的性能优化取得了很好的效果。
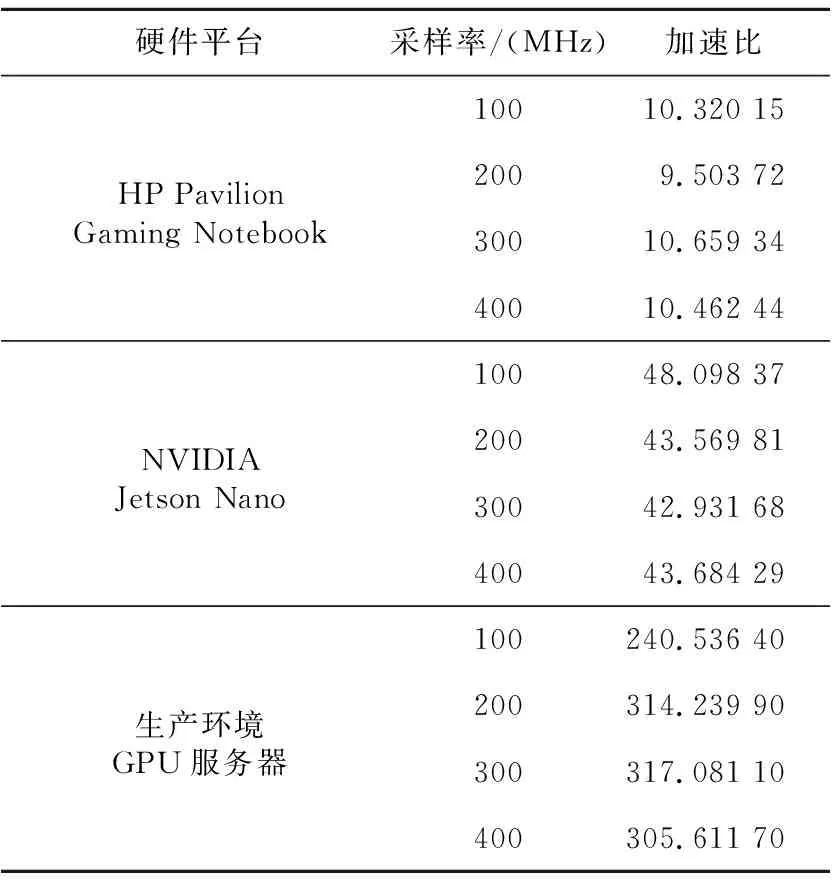
Table 6 Acceleration ratio of performance test
本次测试使用的PC机是HP Pavilion Gaming Notebook,其CPU和GPU的性能差距较小,其中NVIDIA GeForce GTX 950M是移动定制版,显存带宽为28.8 GB/s,较低的峰值浮点运算能力和显存带宽使得其在性能方面无法与桌面级显卡相媲美。
在生产环境部署时使用的CPU为双路Intel Xeon E5-2683 v3,每一路CPU都具有14个物理核心,其理论峰值浮点运算能力为896 GFlop/s。生产环境使用的GPU为NVIDIA GeForce GTX 1080 Ti,其理论峰值浮点运算能力为11 339.78 GFlop/s,显存带宽为484.44 GB/s,较大的性能差距使得算法在生产环境上能够获得更加出色的加速比。

Figure 9 Stage result error analysis图9 阶段结果误差分析
4.2 误差分析
图9展示了算法CPU实现和GPU实现的相对误差,其中脉冲压缩模块的绝对误差小于3.5×10-5,动目标显示模块绝对误差小于4.5×10-5,动目标检测模块绝对误差小于6×10-4。从雷达信号处理中间结果的误差分析图中可以看出,相比于CPU实现,GPU实现具有极高的精度。
图10展示了CFAR模块的结果对比情况,图10中横纵坐标分别表示目标的距离信息和速度信息。从图10中可以看到,使用CPU和GPU处理的结果其距离信息和速度信息完全相同,表明GPU实现产生了正确的结果。
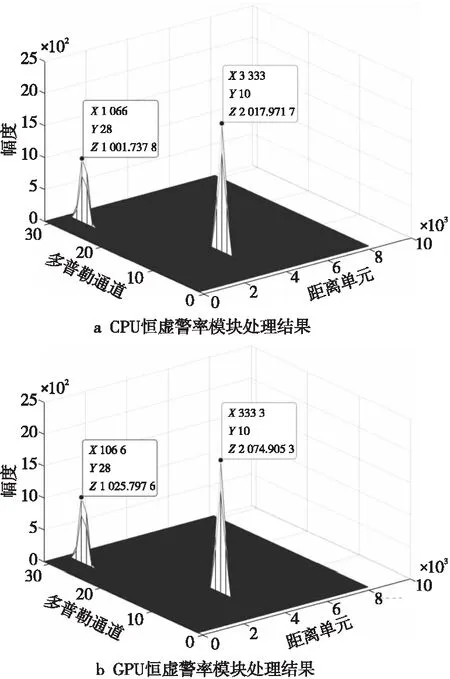
Figure 10 Comparison of CFAR results图10 CFAR结果对比
5 结束语
本文提出了一种基于GPU加速的脉冲多普勒雷达信号处理方法,通过网格跨步并行、多CUDA流并发和并行扫描等多种优化策略来实现加速。本文提出的方法既满足了雷达信号处理大吞吐量和高实时性的要求,又充分发挥了GPU设备众核并行的优势。本文所阐述的方法最终在生产环境上达到了300倍的加速比。
致谢:
本文研究得到国家自然科学基金(71671178)、中国科学院大学优秀青年教师科研能力提升重点项目以及总装备部装备预先研究基金项目的支持。同时,感谢北京雷鹰科技有限公司对本文研究提供的帮助和支持。
