基于注意力的毫米波雷达与视觉融合方法*
2021-08-06杨猛,沈韬,曾凯
杨 猛,沈 韬,曾 凯
(昆明理工大学,云南 昆明 650500)
0 引 言
毫米波雷达与视觉传感器融合是一种准确感知车辆周围环境的低成本方式。按照融合层次分类,主要有数据层、特征层和决策层3种融合方法,这3种融合方法各有优势和不足。
数据层融合通常是在空间上的融合,主要分为两步:先是利用毫米波雷达点云产生感兴趣区域(Region of Interest,ROI);视觉传感器再对ROI进行检测,验证是否存在障碍物[1-3]。这种融合方法只检测有毫米波雷达信息的区域,可以明显地缩小视觉传感器检测区域,提高视觉检测效率。但由于毫米波雷达分辨率较低,难以检测横截面积较小的物体,会漏检行人、自行车等小物体。
决策层融合通常是分别将毫米波雷达与视觉预测的结果进行融合,产生最终的预测结果[4-6]。但是这种融合方法需要分别计算各个传感器的检测结果,计算成本太高,并且很难建立两种检测结果的概率分布模型。
特征层融合是目前研究较多的方法,主要是将雷达的一些信息作为通道特征,附加在图像特征通道上,利用卷积神经网络学习点云与视觉图像之间的关系,提取两者的特征进行融合[7-10],然而这种融合方法存在特征权重难以分配的问题。
通过分析毫米波雷达与视觉融合存在的问题。本文从空间和通道两个维度考虑,提出一种基于空间软注意力(Spatial Soft Attention,SA)的数据层融合和基于通道注意力权重学习(Channel Attention Weight Learning,CAL)的特征层融合的混合融合方法,用于毫米波雷达与视觉融合检测障碍物,并将该方法命名为“RVF-SCA”。首先,采用文献[7]的投影方法和文献[10]雷达空间信息增强方法,把雷达点云投影到与视觉图像一致的垂直平面上,再把平面点云延伸为垂直直线,增强毫米波雷达点云的空间信息。其次,在数据层利用毫米波雷达空间信息为视觉传感器确定重点检测区域并突出重点检测区域特征,形成空间上的软注意力,解决了因毫米波雷达特性引起的小物体检测效果不佳的问题。最后,在特征层利用通道注意力权重学习方法,对毫米波雷达与视觉特征的权重进行合理分配,解决两者权重难以分配的问题。RVF-SCA融合方法能够充分利用毫米波雷达和视觉传感器,提升在各光照场景下检测障碍物的效果。
1 RVF-SCA模型结构
本章介绍基于空间软注意力的数据层融合和通道注意力权重学习的特征层融合的网络结构。本文提出的网络融合结构是建立在RetinaNet[11]框架上,并用改进的VGG16[12]进行特征提取。如图1所示,该结构包含基于空间软注意力的数据层融合模块,基于通道注意力权重学习的特征层模块和RetinaNet模块。
在数据层,先增强毫米波雷达图像,再分别用R-Block0和V-Block0提取毫米波雷达空间信息和视觉信息。然后通过SA的融合方法,在早期为视觉传感器在空间上确定重点检测区域并突出重点检测区域的特征。
在特征层,先通过V-Block1提取确定过重点检测区域的视觉图像的特征,后与R-Block1提取的雷达特征进行级联。
在特征通道上用CAL方法分配毫米波雷达与视觉的特征权重。最后利用RetinaNet进行融合特征的提取和分类,并且损失函数和RetinaNet中的一致。
1.1 基于空间软注意力的数据层融合
空间软注意力的具体实现方法如图2所示,首先在R-Block0使用3×3和5×5的卷积核,初步提取毫米波雷达的多尺度空间信息;其次把提取的毫米波雷达空间信息映射到视觉图像的所有通道上,与经过V-Block0处理之后的视觉图像相乘,得到空间特征矩阵,确定重点检测空间(这一步做法类似于传统数据级融合的确定ROI);最后空间特征矩阵与V-Block0提取的视觉信息进行像素级相加,增强视觉重点检测空间特征。这种基于SA的数据层融合方法能够有效地利用毫米波雷达不受天气影响的特性,提供障碍物准确的空间信息,增强目标特征,同时又利用视觉传感器提高了行人、自行车等小物体的检测效果。本文通过与基线模型和传统的数据级融合进行对比实验验证了提出的SA融合方式,在行人等小物体的检测精度和召回率都有明显的优势。
可以把空间软注意力实现的步骤总结如下:
(1)计毫米波雷达图像二维矩阵为N,图像矩阵为C;
(2)将毫米波雷达的雷达图像二维矩阵N与图像矩阵C进行点乘,得到矩阵H:
(3)将矩阵H与图像矩阵C进行元素级相加得到M:
1.2 基于通道注意力权重学习的特征层融合
为了充分利用毫米波雷达信息,本文在特征层提取了毫米波雷达的特征,并与视觉特征进行级联。同时为了合理地分配毫米波雷达与视觉传感器在全局信息的权重,本文提出以通道的方式对两者的权重进行分配,在特征层中加入了挤压、激励(Squeeze and Excitation,SE)[13]通道注意力权重学习的方式学习各通道权重。
如图3所示,雷达数据在R-Block1经过3×3和5×5的卷积核,以及MaxPooling,提取多尺度特征,再与V-Block1提取的空间融合特征进行级联融合。在级联后用SE通道注意力权重学习的方法来学习各通道权重。通过挤压、激励操作,对多模态融合特征的各通道的依赖性进行建模,以通道权重的形式学习毫米波雷达与视觉图像在融合特征的权重。通过消融实验证明了CAL的有效性。
输入的多模态融合特征经过特征提取Ftr后得到维度为H×W×C的特征图U,其中H为特征图高度,W为特征图宽度,C为通道数。通道注意力机制通过通道特征权重提取、通道权重更新和权重映射3个步骤实现。
(1)通道特征权重提取。对H×W×C的特征图,在每个通道上对特征图的空间维度进行压缩,转换成维度为1×1×C的特征图,通道数保持不变。
式中:uc为输入特征的第c个通道特征;(i, j)对应融合特征每个像素点的位置,对输入的融合特征进行平均池化,得到输出特征zc。
(2)通道权重更新。融合特征经全连接层(Fully Connected,FC)进行通道信息融合,通过训练学习获得归一化权重,该权重表是对各个通道特征的依赖程度。
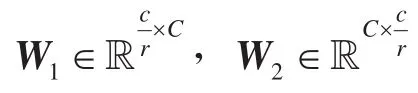
(3)权重映射。将上述归一化后的输出权重值与原输入特征图进行逐通道加权,得到经权重映射后的通道特征。
2 实 验
本章通过实验验证RVF-SCA网络的可行性。本文采用CRF-Net的训练策略,从nuScenes[14]多模态数据集中按6∶2∶2的比例取出晴天、雨天和夜间的混合场景进行训练,总共是20 480个雷达-视觉对。在tensorflow框架实现本文提出的RVFSCA网络模型,并在具有16 GB显存的Telsa V100上训练模型。训练时输入图片的大小为360×640,设置学习率为0.000 1,训练20个Epoch。分别测试晴天、雨天和夜间的检测效果。
实验采用的评估指标与主流目标检测评估一致。本文使用平均精度均值(Mean Average Precision,mAP)、平均召回率均值(Mean Average Recall,AR)、平均召回率(Average Recall,AR)和平均精度(Average Precision,AP)作为评价指标。
2.1 雷达直线高度对检测效果的影响
为了测试增强雷达空间信息在不同光照条件下对检测效果的影响,以及寻找最佳的雷达直线高度(Radar Linear Height,RH),本文在不同光照条件下做了不同高度的雷达直线的对比实验,如表1所示。
在现实场景中,公路上常见物体高度普遍在1~3 m之间。本文为了对比在不同光照环境下,不同RH对检测效果的影响,在0~3.5 m的高度范围内,每间隔0.5 m做了一组对比实验。从表1中可以看出:在1.5~3.0 m的RH范围内,各种光照条件下的检测效果达到最佳,在3.5 m的RH下检测效果已经开始下降,这与公路上常见的物体高度保持一致。在RH为1.5~3.0 m范围内,本文提出的RVF-SCA方法相比于基线模型在晴天的场景下能够提高2.0%~2.6%的mAP和12.1%~13.3%的mAR;在雨天场景下能够提高1.7%~2.2%的mAP和1.8%~3.7%的mAR;在夜间条件下提高了0.5%~2.3%的mAP和1.7%~3.7%的mAR。总体上提高了检测精度和召回率,减少了漏检。
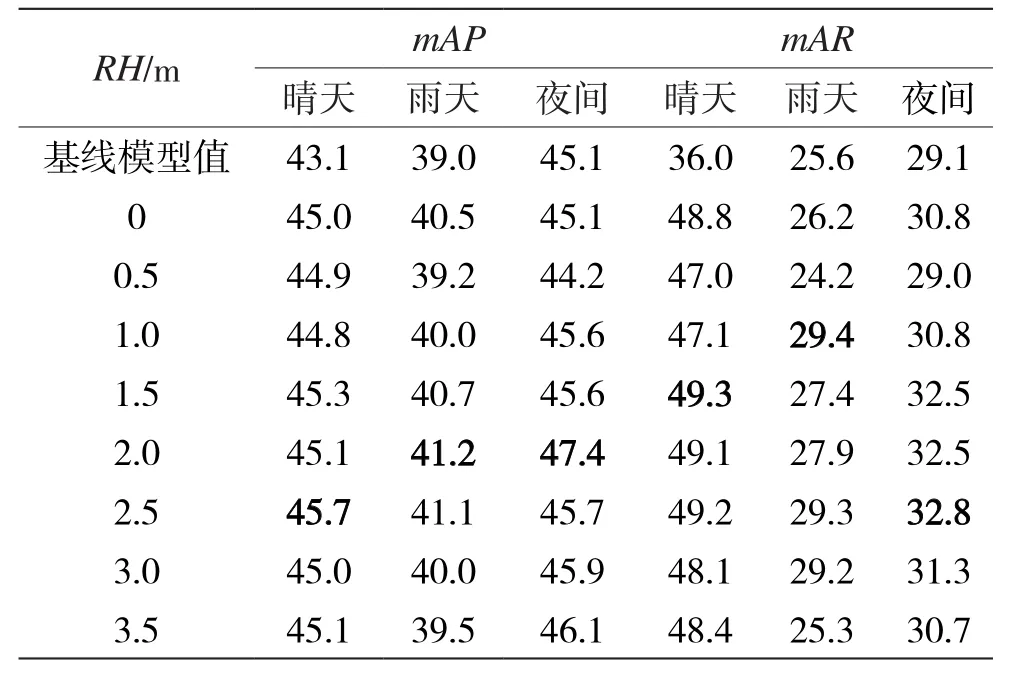
表1 在不同RH和不同光照条件下RVF-SCA融合网络检测障碍物的mAP和mAR
不同种类物体的高度不同,本文研究了不同RH对不同种类物体在不同光照条件下检测效果的影响。在一些场景下一些种类的物体出现次数过少,而不能表示实际的检测效果。因此本文只统计了出现次数较多的物体作为研究对象。晴天场景下,选择了行人、自行车、大巴、汽车、摩托和卡车作为研究对象;雨天场景下选择了行人、大巴、汽车、拖车和卡车作为研究对象;夜间场景下,选择行人、大巴、汽车、摩托和卡车作为研究对象。通过实验结果表2、表3可以总结出:在光线条件较好的情况下,不同高度物体的检测效果与不同RH有一定的相关性,RH越接近物体的高度,检测的精度和召回率越高。
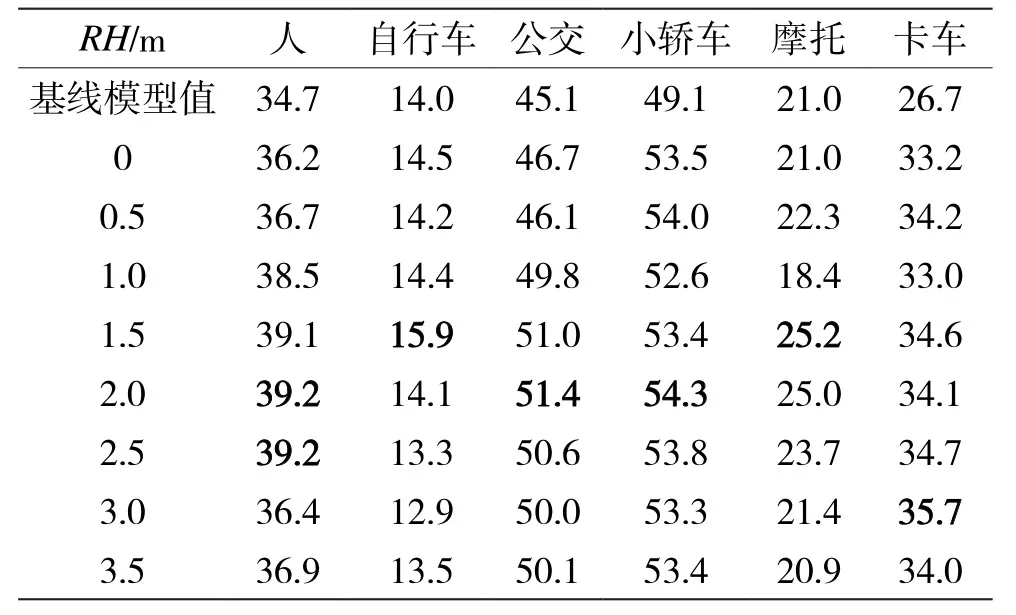
表2 晴天场景下,RVF-SCA在不同RH下检测各类障碍物的AP
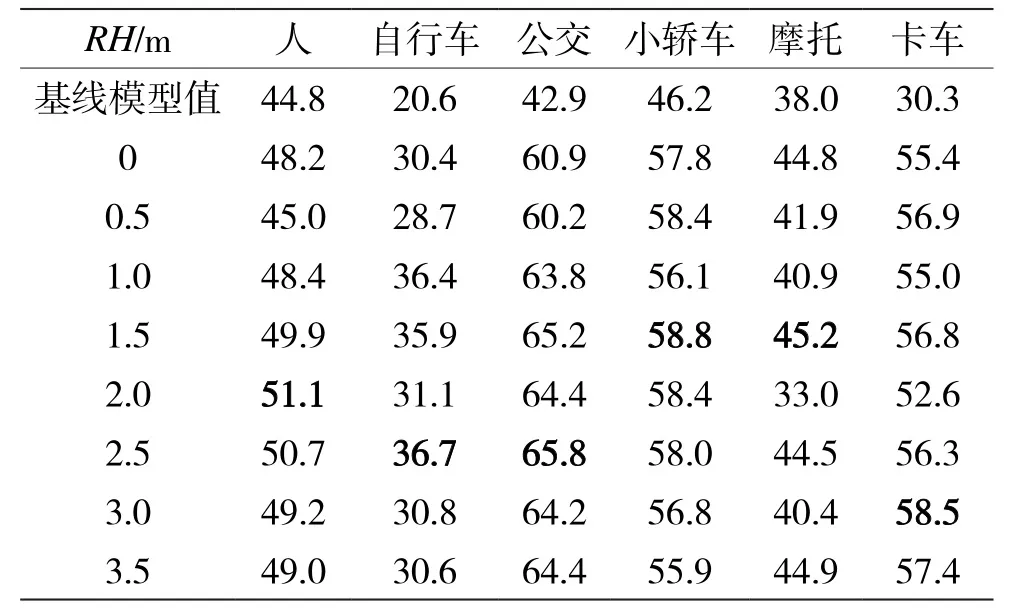
表3 晴天场景下,RVF-SCA在不同RH下检测各类障碍物的AR
在光照强度较低的雨天情况下,雨滴在一定程度上会遮挡视觉传感器,挡风玻璃上的雨滴和雨痕也会因反光、折射等改变障碍物的局部或整体特征,造成图像失真。雨天整体光照条件与光照条件良好的场景有一定的相似性,视觉传感器在大部分情况下基本能够检测到障碍物的整体轮廓。但训练测试时雷达直线高度受一些失真图像影响,造成最佳RH与真实物体高度有一些差距。
从表4、表5中可以看出,在雨天场景下,各类物体的AP和AR比与晴天场景下低。雷达空间信息增强条件下RVF-SCA方法能够有效地提高不同物体的检测精度和召回率,但受雨滴和图像失真的影响,最佳的RH与物体真实高度有一定的差距。
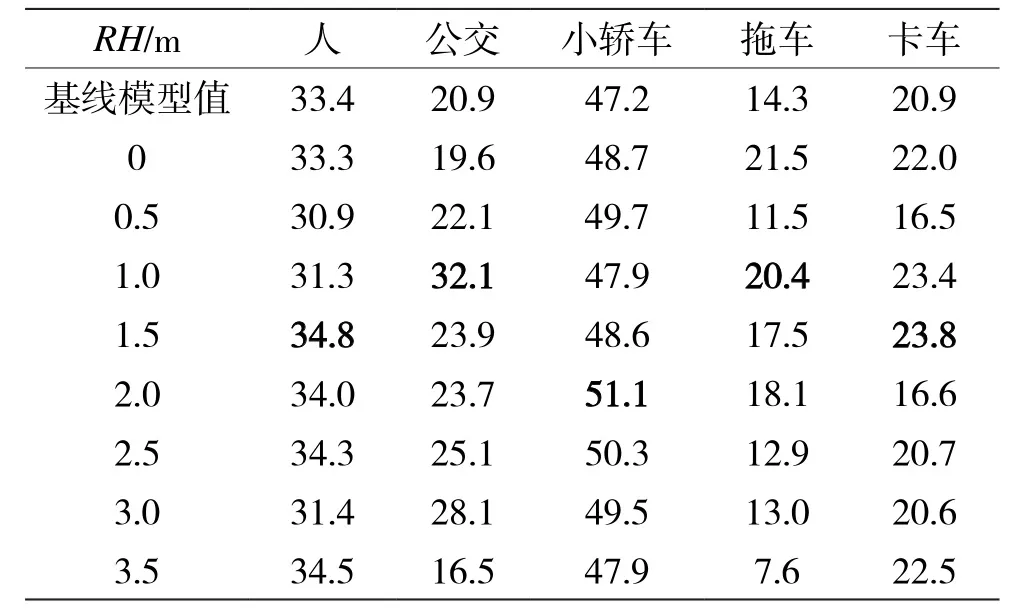
表4 雨天场景下,RVF-SCA在不同RH下检测各类障碍物的AP
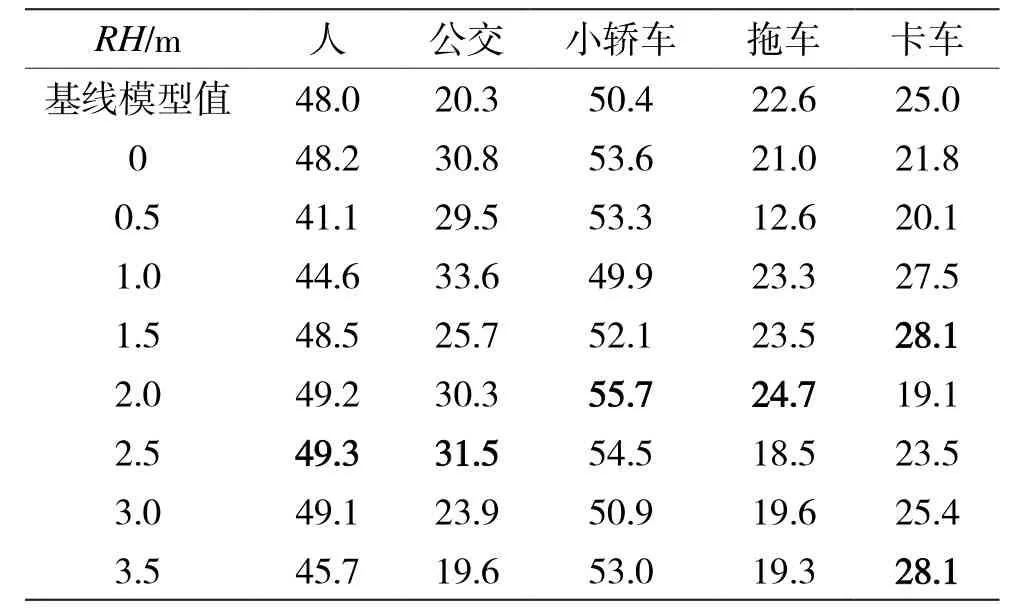
表5 雨天场景下,RVF-SCA在不同RH下检测各类障碍物的AR
在夜间场景下,光照条件只有车灯和路灯,与白天完全不同。同一物体的全局特征与光照条件较好的晴天场景下的全局特征有一定的差异,尤其对于车辆等本身具有亮度且能够反射光照的物体。受光照变化的影响,车灯和后视镜等局部特征会更加明显,在训练测试时这些局部特征的权重会增加。
从实验结果表6、表7中可以看出:适当地增强毫米波雷达空间信息能够增强夜间的检测效果,但对于车辆的最佳检测效果的RH更加接近车灯和后视镜等局部特征的高度,而不是车辆的高度。当RH接近物体高度时,不是最佳的检测效果,但与最佳检测效果相差很小。因此对于夜间物体的检测,最佳RH与物体的局部特征相关性更高(如表4所示)。
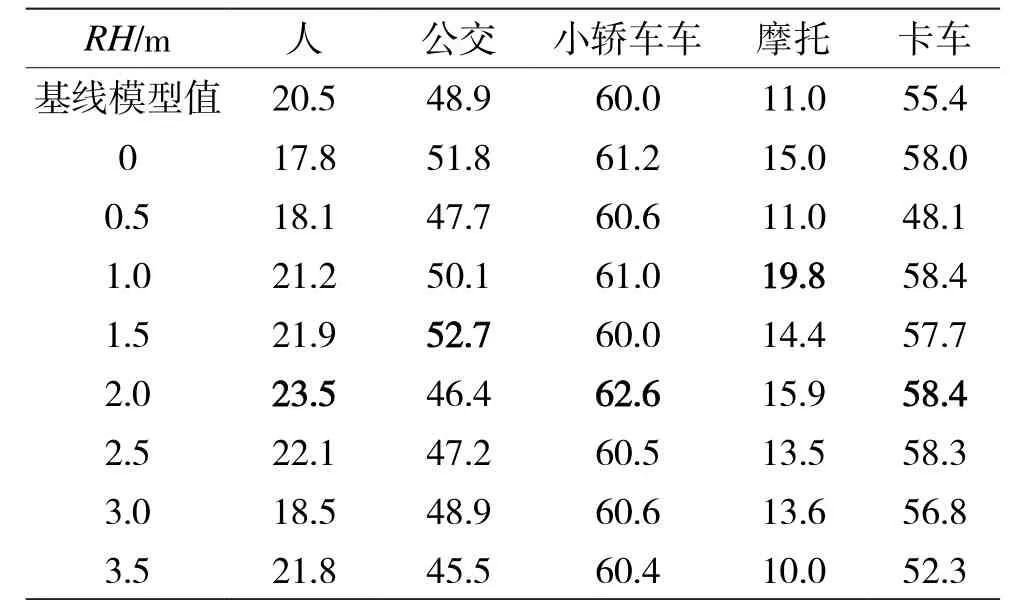
表6 夜间场景下,RVF-SCA在不同RH下检测各类障碍物的AP
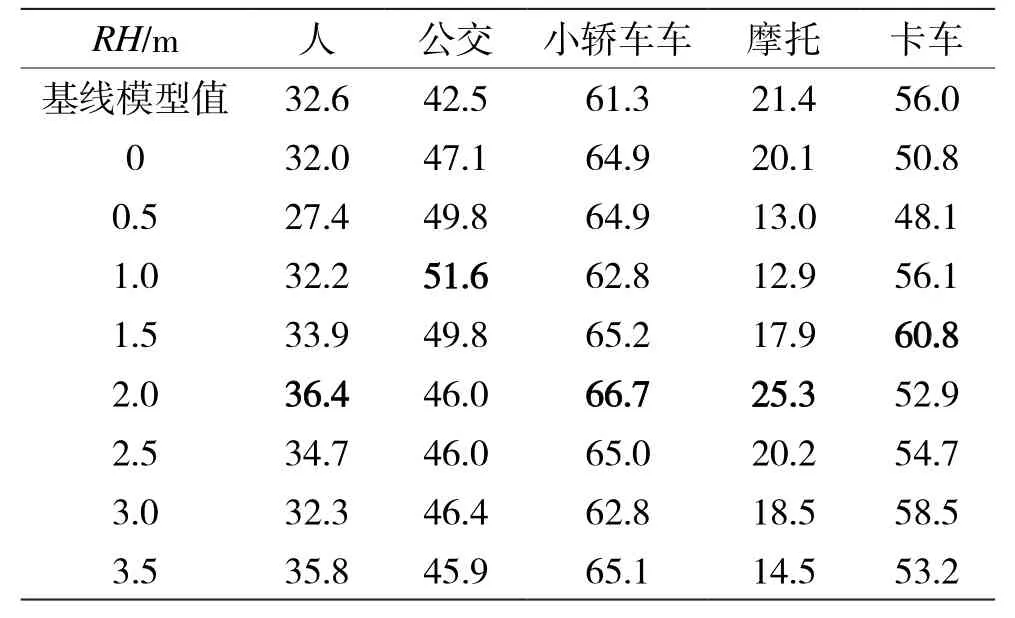
表7 夜间场景下,RVF-SCA在不同RH下检测各类障碍物的AR
2.2 消融实验
为了验证本文提出RVF-SCA方法的有效性,分别测试了在不同光照条件下RH为0 m和雷达直线2.5 m高度下的SA和通CAL对检测效果的影响。
在RH为0 m和2.5 m的情况下测试了SA与CAL对检测结果的影响。实验结果表明,在2.5 m的RH下,RVF-SCA的检测效果比基线模型有了明显提升,尤其是召回率。晴天场景下分别提高了2.6%的mAP和13.2%的mAR;雨天场景下mAP和mAR分别提高了2.1%和3.7%;夜间场景下mAP和mAR分别提高了0.6%的和3.7%,如表8、表9所示。检测效果如图4所示。同时从实验结果可以看出SA大幅度提高检测效果,CAL学习能够提高0.1%~1.5%的mAP。在同样的模型下,增强雷达空间位置信息的检测效果比不增强的检测效果更好。
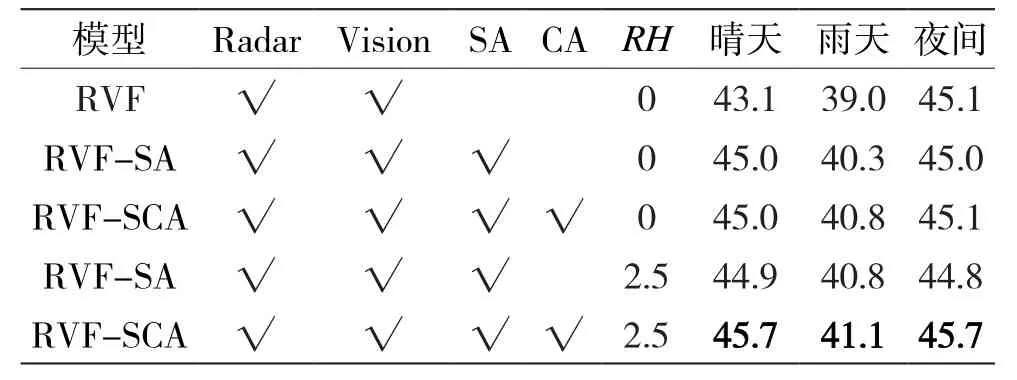
表8 在RH为0 m和2.5 m的不同光照条件下,基线模型分别加入SA和CAL检测各类障碍物的mAP
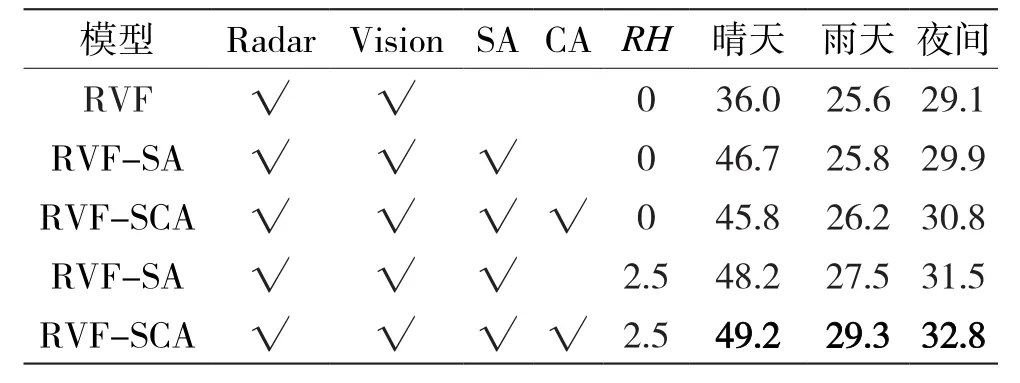
表9 在RH为0 m和2.5 m的不同光照条件下,基线模型分别加入SA和CAL检测各类障碍物mAR
3 结 语
本文提出了一种基于空间软注意力与通道注意力权重学习融合(RVF-SCA)检测障碍物的方法。与其他融合方法相比,本文从空间和通道两个维度进行融合。首先采用雷达空间信息增强的方法,增强了毫米波雷达空间信息;其次在空间上,利用毫米波雷达的空间信息与视觉图像进行空间信息融合,在不忽略其他检测空间的同时突出了视觉重点检测区域,解决了因毫米波雷达特性导致的小物体检测效果不佳;最后在通道上,将提取的雷达特征和空间融合特征进行级联,利用通道注意力学习在融合的通道上进行建模,对两种传感器特征的权重进行合理地分配,进一步增强检测效果。通过消融实验,证明本文提出的RVF-SCA方法能够有效地提高在晴天、雨天和夜间等场景下的检测效果。
