基于神经网络的空气质量预测研究
2021-08-06何法虎梁健涛
何法虎,梁健涛
(华北理工大学人工智能学院,唐山063200)
0 引言
近几年来,我国的大气环境质量日趋下降,我国在保护环境方面面临着巨大的压力[1]。基于神经网络的空气质量的预测打破传统的空气质量监测,能预测短时间内的空气质量,为环境保护部门提供预警信息,有效及时地处理环境污染问题。
20世纪以来,国外环境部门最初是通过站点的监测数据对污染源进行分析,判定污染源的排放量来对空气质量进行研究。后来利用统计学方法对监测站点收集的数据进行分析,进行空气质量的预测。统计学方法预测空气质量需要大量的实际站点采集的数据,而且对数据的稳定性要求比较高。随着互联网时代的发展已经神经网络的不断改进,使用神经网络对空气质量进行预测也成为国外研究者的主要方法[2]。
因为空气质量数据具有时间序列的特性,所以在文中使用了具有时间序列特性的传统的循环神经网络RNN、长短期记忆网络(LSTM)和门控单元(GRU)进行空气质量数据的预测。通过均方根误差和R方的分来判定模型的拟合程度,根据几种神经网络模型预测的结果,选取一种预测空气质量合适的神经网络进行应用。
1 算法实现
1.1 神经网络模型介绍
在文中使用了循环神经网络对空气质量数据进行分析研究,首先介绍的是最基本的循环神经网络RNN。循环神经网络在处理和预测具有时间序列特性的数据方面有着较强的处理能力。空气质量数据具有时间序列的特性,当前时刻的信息与前一个或几个时刻的信息有较大的关联[3],所以选择循环神经网络在处理空气质量数据。RNN循环神经网络的隐藏层的输入不仅来自输入层,还来自于过去时刻的隐藏层。RNN循环神经网络的基本结构如图1所示。
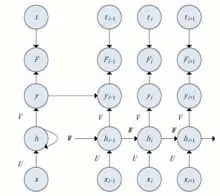
图1 RNN循环神经网络结构图
h为隐藏状态,y为可选择使用的输出,两者构成了RNN循环神经网络。V为隐藏状态h到输出y之间的权重矩阵,W作为上一个时间点的隐藏状态hi-1与当前时间点的隐藏状态hi之间的权重,U表示当前时刻的输入x与当前隐藏状态h之间的权重,Fi和ti表示逐步的损失和训练的结果。RNN循环神经网络的隐藏层的更新如公式(1)所示。

在公式(1)中,f表示非线性激活函数,xi为当前时刻的输入,hi-1为上一时刻的隐藏状态。在本文中使用的非线性激活函数为Sigmoid[4]。Sigmoid激活函数是一个将输入转化为0-1之间的输出的函数,其表达式为公式(2)。

基本循环神经网络RNN由于是一个循环体的不断循环,所以容易发生梯度爆炸的情况。为了减小这种梯度爆炸发生的概率,研究者们提出了RNN的变体模型为长短期记忆网络(LSTM)。在长短期记忆网络LSTM中,加入了输入门、遗忘门和输出门三种门控结构来控制上一时刻信息的保留程度[5]。LSTM的基本结构如图2所示。
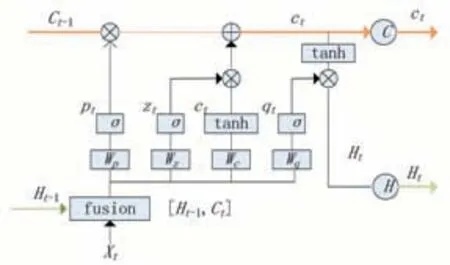
图2 LSTM基本结构图
遗忘门综合当前时刻的输入Xt与上一时刻的输出Ht-1来考虑信息的有效性。遗忘门首先会生成一个矢量f=sigmoid(Wf[Ht-1,Xt]),然后与隐藏层的上一刻状态Ct-1相乘,如果值接近于1,大量的信息都是有效的,能够被保留使用,如果值接近0,则代表信息是无效的,被遗忘门遗弃不被使用。
输入门的作用就是补充并更新循环体的最新信息。首先将上一时刻的输出信息Ht-1与当前时刻的输入Xt通过矩阵相加,传递到Sigmoid函数[6],然后将这两个信息再次传递到tanh函数中,得到的结果与遗忘门的结果共同构成新的隐藏层状态Ct。通过这两个门可以确定哪些信息有效哪些信息被遗弃。
输出门用于生成当前时刻的输出Ht。各个门的公式如下所示:
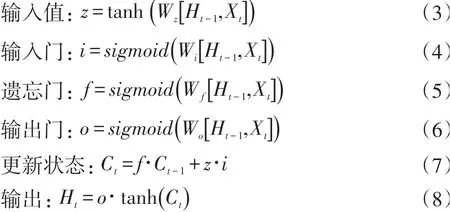
其中Wz、Wi、Wf和Wo表示每个结构体上的权重参数。
GRU模型是LSTM的变体,能够解决时间序列的长时依赖性问题。本文通过对比LSTM和GRU在所选数据上的准确度来选择适合的模型。GRU模型中只有两个门:更新门和重置门。更新门的作用相当于LSTM网络中遗忘门和输入门的结合,可以决定哪些信息有效,需要被模型保留,哪些信息无效需要被遗弃[7]。公式为:

1.2 实验过程
实验方案采用理论与实践相结合的方式,环境质量数据是从中国环境监测总站实时发布的空气质量数据获得。利用Python中数据分析技术对获取的数据进行清理与整合,结合神经网络模型相关理论方法,确定总体方案,建立神经网络模型,实现空气质量的预测。技术路线包括Python开发环境的搭建,数据的预处理,数据分析,神经网络模型的训练和评估四个主要阶段。
(1)Python开发环境的搭建:本实验所采用的开发环境为Python,安装实验中所需要的各种工具包,并搭建TensorFlow学习框架。这个框架可以为应用程序提供灵活的计算图,建立神经网络的结构,并能直观地对网络模型的结构进行灵活的操作。
(2)数据的预处理:数据集的质量直接影响模型的训练的速度和效力。数据的预处理包括:数据的读取,数据缺失值的处理,异常值的处理,以及各个属性的表现形式。
(3)数据分析:数据预处理之后,对数据进行分析,主要分析各个污染物浓度随时间的变化规律和各个污染物之间的关联关系。
(4)神经网络模型的训练和评估:将经过处理的空气质量数据分为训练数据和测试数据。建立神经网络模型,并用训练集训练该模型,找到损失函数最小的最优模型参数,在测试集上对最优函数的性能进行评估,并且通过测试集对模型的泛化能力进行评估。
2 实验结果分析
在数据进行预处理与分析之后,我首先选择了几种简单的模型进行了预训练,分别是随机森林、梯度提升树、XGBoost回归模型和神经网络回归模型[8]。使用Python中Sklearn工具库进行了模型的训练得出每个模型的R方得分,具体模型的R方得分见表1所示。
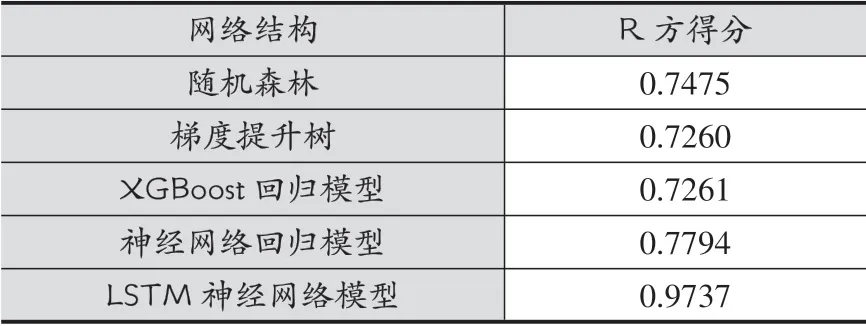
表1 普通模型R方得分
在初步的使用LSTM模型进行训练,得到的R方得分为0.9737。在LSTM模型训练时,损失函数公式为:

为了避免过拟合,一种常用的方法就是正则化。通过在损失函数中加入映射模型复杂程度的参数,提高模型的泛化能力[9]。假设模型的损失函数为J(θ),R(w)代表了模型的复杂程度。
正则化表达式有L1正则化和L2正则化两种[10],L1正则化公式为:

L2正则化公式为:

为了防止过拟合,加入L2正则化项为:
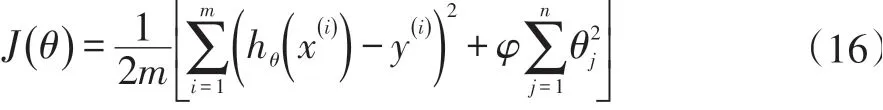
其中φ是一个L2范数的参数,训练模型中加入了L2正则化方法来解决过拟合问题。图3为训练数据和测试数据损失函数图。
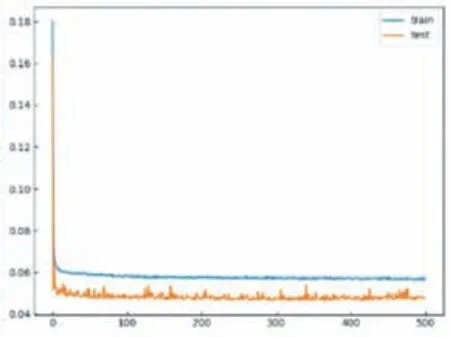
图3实验损失函数图
图3 可以看出,损失值在100步以前下降特别快,在100步到500步之间有轻微的波动,500步以后趋于平稳,模型收敛,训练完成。
3 结语
本文提出了使用神经网络进行空气质量的预测,空气质量的预测在实际生活中有很重要的意义,人们的日常生活和健康都与空气质量的好坏有直接的关系。在近几年,研究者们对空气质量的不断研究,给出了可行的解决方案,我国的空气质量得到了很大的改善。因为空气质量数据具有一定的时间序列的特性,在本文中选择了循环神经网络。循环神经网络在解决时间序列数据时具有选择性,预防梯度爆炸的情况发生。在文中给出了基于神经网络模型的空气质量预测的实验验证,分析在具有时间序列的空气质量数据中使用循环神经网络具有一定的优势。该算法可用于解决实际工作中的一些相关问题,具有一定的实际意义。
