基于时序集成森林的股票多类别预测研究
2021-08-06王平飞
王平飞
(四川大学计算机学院,成都610065)
0 引言
股票市场可以带来高收益率,如何合理预测股票的走势,获得最大的收益一直是业界学者探索的方向。但由于股票数据存在噪声,影响因素颇多,预测过程较为复杂。人工智能技术的发展为股票预测研究提供了新的思路,各种机器学习算法如SVM、BP、随机森林[1-3]以及深度学习算法LSTM、LSTM-CNN-CBAM、LSTM-AdaBoost[4-6]等算法相继在股票收盘价预测中得到了应用,但是以上模型均是针对股票的收盘价进行预测,虽然取得了较好的结果,但是仍然存在误差,并且预测的结果也存在滞后性,加上投资人普遍更关心涨跌的趋势。针对这一情况,夏阳雨新提出了基于LSTM的股票多类别预测模型[7],包振山在LSTM收盘价预测模型的基础上使用GA算法对股票的涨跌信号进行判定,提出了基于LSTM-GA的股票涨跌预测模型[8]。
本文对长短记忆网络(LSTM)、随机森林(RF)和集成森林进行了深入研究,提出了一种基于时序集成森林的混合股票多类别预测模型,该模型首先使用LSTM和随机森林进行收盘价的预测,再将预测的收盘价与前一天预测的收盘价进行对比得到涨跌信号,再使用集成森林对LSTM输出的时序特征和涨跌信号进行分类,得到最终的股票涨跌趋势。结合了LSTM提取时序特征的能力和随机森林的回归能力以及集成森林强大的分类能力,最后使用平安银行股票数据进行了验证,实验结果表明本文提出的股票预测模型精度更高。
1 股票预测模型框架
1.1 方法总体架构
本文中提出的股票预测模型总共有3个步骤。
(1)数据获取及处理。利用Tushare财经接口包下载平安银行股票数据000001.sz,并将其归一化到(0,1)之间。
(2)LSTM-RF股票收盘价预测,并将预测的结果与前一天的预测结果对比得到涨跌信号。
(3)集成森林股票涨跌判定。将LSTM训练完成后输出的时序特征数据输入随机森林训练。训练完成后对测试数据进行预测。如图1所示。
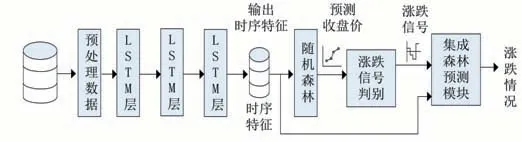
图1 股票预测模型
1.2 LSTM时序特征提取


其中C t是当前时刻LSTM的控制单元状态矩阵,W c是更新权重矩阵,b c是更新的偏执矩阵,Ht是当前LSTM在t时刻的输出。
1.3 随机森林预测算法
随机森林可用于解决分类和回归问题,当用于回归时,每一棵决策树就是一棵回归树(CART),通过最小均方差来进行划分,对于需要划分的特征A,可以取到一个任意的划分点s将数据集划分为两个部分,这里记为D1和D2,通过迭代使得划分后得到的数据集的各自的均方差最小,也就是满足式(6)。
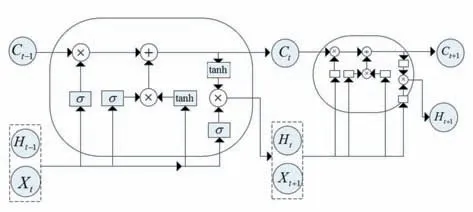
图2 LSTM模型

式中的c1和c2分别是划分的两个数据集D1和D2的输出均值,通过这个原则进行反复迭代,直到误差到达设定范围内或者是达到迭代次数,算法结束,最后的输出值就是所有决策树的均值[10-11],具体的算法1所示。
算法1随机森林回归算法
输入:LSTM提取的时序特征数据
输出:股票预测的最高价
步骤一:利用Bootstrap算法对LSTM提取时序特征后的样本进行重抽样,得到k组新的样本集{θ1,θ2…θk}。
步骤二:利用上一步划分得到的k组样本分别构建决策树{{T(x,θ1)},{T(x,θ2)}…{T(x,θk)}}。
步骤三:从样本的M维特征中抽取m个作为节点的分裂特征集,并保持m在随机森林形成中不变。
步骤四:对于给定的数据样本X=x下,根据每棵决策树的观测值{Y1…Y k}得到单棵决策树的预测值
步骤五:对每个决策树的权重取平均值,其中X=X i(i∈{1,2,…n}),t=(1,2,…k),进一步得到每个观测值
1.4 集成森林分类算法
集成森林是由多个RF层间级联构成的一个森林层,每一层的输出就是一组预测值,在训练的过程中会使用测试集判定该层的输入是否满足收敛条件,如果不满足就会将输出向量与初始输入数据相连接作为下一层的输入[12],具体的模型如图3所示,samples为预处理后的数据向量,输入第1个森林层后,4个森林分别估计所有样本的类别概率,然后将其作为输出向量与原始样本数据进行拼接,并作为下一层的输入向量,直至达到预设的循环次数或收敛条件为止。最后,对输出层的向量求均值,将输出概率最大的类别作为预测的样本类别。
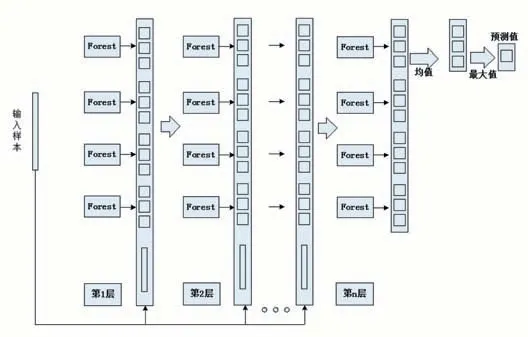
图3 集成森林原理图
在本文的股票多类别预测中,集成森林用来进行最终的涨跌分类,输入为LSTM输出的时序特征和涨跌信号模块输出的初步涨跌类别,输出为股票最终的涨跌类别。
2 实验结果及分析
2.1 数据预处理
本文实验使用的数据为平安银行股票数据,包含了2001年至2020年共4675条股票数据,每条数据包含了ts_code(股票代码)、trade_date(交易日期)、open(开盘价)、high(最高价)、low(最低价)、close(收盘价)、pre_close(前一天收盘价)、change(价格变动)、pct_chog(价格波动百分比)、vol(成交量)、amount(成交金额)共11个指标,部分数据如图4所示。
由于每个指标的量纲的影响,比如收盘价,最高价和交易数量之间的统计量级之间存在较大差异,为了消除不同指标的量纲的影响,在训练之前进行了预处理,将数据归一化到(0,1)之间,归一化的公式如式(7)所示[5]。

根据当日股票收盘价与前一天的收盘价格波动的百分比,将股票的涨跌情况分成了2个类别,其中涨幅大于等于0为涨,小于等于0为跌,用2位的二进制数据对4中涨跌情况类别进行表示,具体的如表1所示。
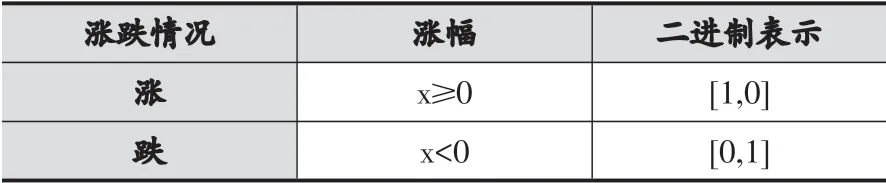
表1 涨跌情况二进制表示
2.2 实验参数设置
LSTM模型中承担提取时序特征的角色,实验中设定了三层的LSTM来提取时序特征,每一层LSTM的节点数均设定为128,每一层LSTM之间设定一个参数位0.1的dropout层,激活函数选用ReLU,时间窗口的大小设定为10。
随机森林在模块中承担着对LSTM提取时序进行收盘价拟合的角色,实验中将决策树的棵树nTree取值为30,损失函数选用Gini,其余参数采用默认参数。
集成森林在模型中负责最终的涨跌类别判定,实验中将每次输入的特征数量设定为80,决策树数量设定为20,具体的参数如表2所示。
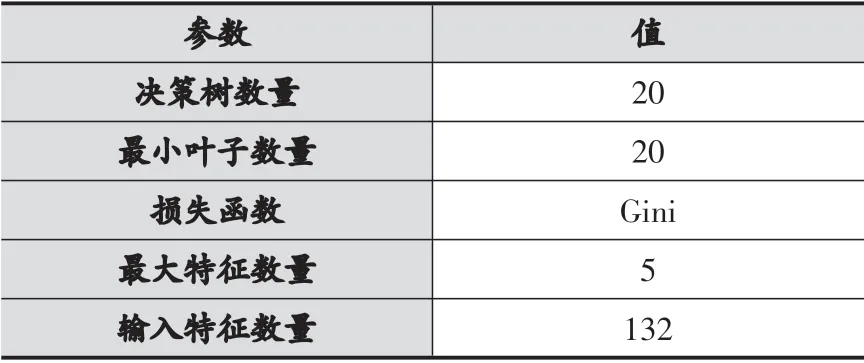
表2 集成森林参数设定
2.3 实验评价标准
本文采用分类准确率、精确率和各涨跌类别的F分数作为评价指标[14],具体如式(8)-式(10)所示:

2.4 实验结果分析
实验中使用的数据集为平安银行股票数据,按照8:2的比例分成训练集和测试集,首先使用训练集进行LSTM-RF模块训练,训练完成后对股票的收盘价进行预测,在测试集上的验证结果如图5所示。
从图5中不难看出本文的LSTM-RF收盘价预测模块在测试集上表现出了很大的优势,预测值与实际值几乎完全重合。
LSTM-RF模块训练完成后通过涨跌信号判别模块,将当前数据样本的预测值与其一天样本的预测值对比,得到涨跌信号,涨跌信号的划分如表2所示。然后将训练集的涨跌信号与LSTM输出的训练集样本的时序特征输入集成森林进行训练,训练完成后对测试集进行涨跌情况预测,实验结果如表4所示。

图4 股票数据
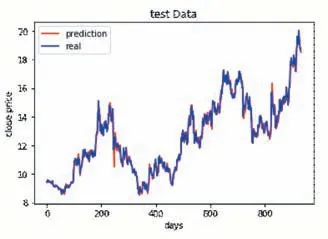
图5 LSTM-RF测试集真实值和预测值对比
从表4中可以看出本文算法LSTM-RF-DF在对各类别样本的检测率(Recall)、精确度(Precision)、和f1分数三个指标上均优于传统的LSTM算法和改进后的LSTM-RF算法,对涨跌两类样本的检测率均达到了70%以上。传统的LSTM和LSTM-RF两种算法对样本的识别很不平衡,LSTM对涨类别预测准确率为63%,但对跌样本的预测准确率进36%,二者相差27%,LSTM-RF虽然准确率有了一定的提高,但是仍然表现出这种不平衡性。本文算法在LSTM-RF算法基础上使用的集成森林对LSTM-RF的预测结果进行了二次判定,不仅在三个指标上均优于另外两种算法,而且对两类样本的检测准确率仅相差5%,对样本识别的平衡度远远高于另外两种算法。
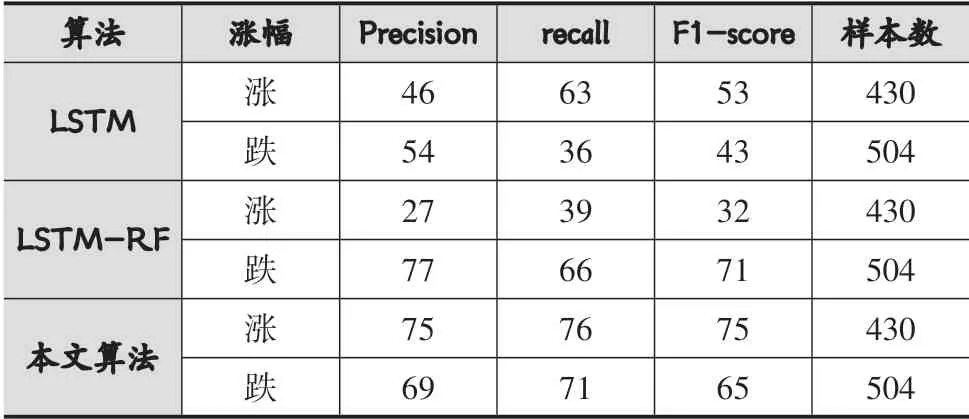
表4 三种算法二分类预测结果/%
图6和图7给出了三种算法在整体的检测准确率和平均精确度,平均f1分数三个指标上的对比,结果表明,本文算法在整体的预测准确率和精确度乃至发分数三个指标上仍然表现出了优势,在整体的预测准确率这一指标上高出另外两种算法20%,进一步体现了本文算法的优势。

图6 三种算法的2类别预测准确率对比
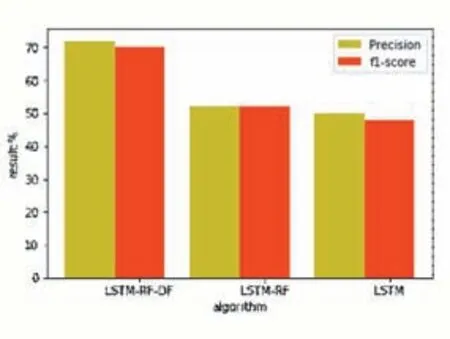
图7 三种算法的2类别预测平均精确度和f分数对比
为了进一步验证本文提出算法的优势,将股票的收盘价涨幅分成了4个类别进行实验验证(其中大于3%为大涨,0到3%之间为小涨,-3%到0之间为小跌,小于-3%为大跌),得到的结果如表7-表7所示。
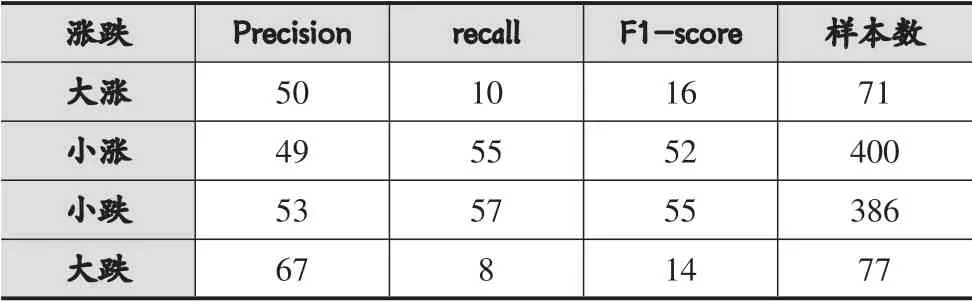
表5 LSTM-RF-DF算法预测/%
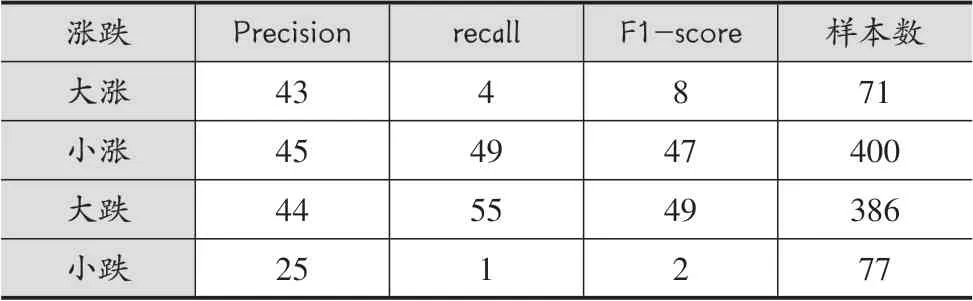
表6 LSTM-RF算法预测/%
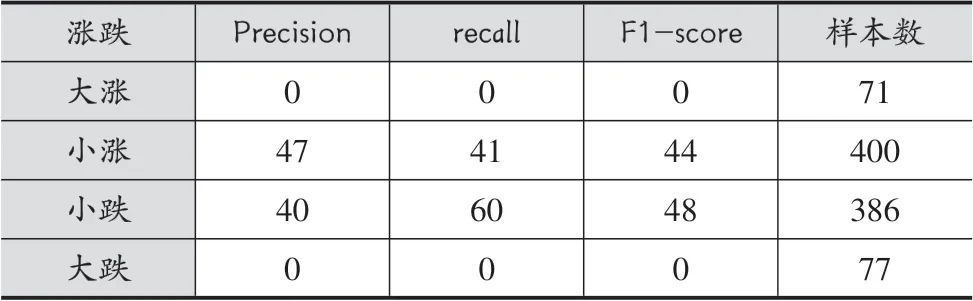
表7 LSTM算法预测/%
实验结果表明,4类别预测的精度明显低于2类别预测,由此也可以看出股票的价格波动并非仅仅收到某些指标的影响,但是在4类别预测上原始的LSTM算法表现出了很大的劣势,大涨和大跌两个类别完全无法识别。而LSTM-RF算法在一定程度上对大跌和大涨由识别能力,但准确率均没超过5%。本文算法在LSTM-RF的基础上使用集成森林对预测结果进行了二次判定,在对大跌的检测率上比LSTM-RF增加了7%,大涨的检测率上增加了6%。此外,在精确度和f分数两个指标结果也表明本文算法优于LSTM-RF和原始的LSTM算法。
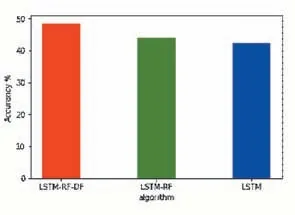
图8 三种算法的4类别预测准确率对比
3 结语
本文结合了LSTM提取时序特征的能力、随机森林算法强大的拟合能力以及集成森林的多类别预测优势,提出了基于时序集成森林的股票多类别预测模型,该算法首相将原始股票数据输入LSTM模块,得到股票数据的时序特征,然后利用RF预测收盘价,并根据收盘价预测出股票的涨幅,与LSTM输出的时序特征一起作为集成森林的输入,最终得到股票下一天的涨跌情况。最后在平安银行股票数据上进行了二分类预测和4分类预测,得到的结果均表明本文算法优于原始的LSTM算法和LSTM-RF算法。下一步将考虑情感因素对股价的印象,搭建出更加完善的股票预测模型。
