量子生成模型*
2021-08-05孙太平吴玉椿2郭国平2
孙太平 吴玉椿2)† 郭国平2)3)
1) (中国科学技术大学, 中国科学院量子信息重点实验室, 合肥 230026)
2) (合肥综合性国家科学中心人工智能研究院, 合肥 230088)
3) (合肥本源量子计算科技有限责任公司, 合肥 230026)
近年来, 很多基于生成模型的机器学习算法, 如生成对抗网络、玻尔兹曼机、自编码器等, 在数据生成、概率模拟等方面有广泛的应用. 另一方面, 融合量子计算和经典机器学习的量子机器学习算法也不断被提出.特别地, 量子生成模型作为量子机器学习的分支, 目前已有很多进展. 量子生成算法是一类量子-经典混合算法, 算法中引入参数量子线路, 通过执行参数线路得到损失函数及其梯度, 然后通过经典的优化算法来优化求解, 从而完成对应的生成任务. 与经典生成模型相比, 量子生成模型通过参数线路将数据流映射到高维希尔伯特空间, 在高维空间中学习数据的特征, 从而在一些特定问题上超越经典生成模型. 在中等规模含噪声的量子体系下, 量子生成模型是一类有潜力实现量子优势的量子机器学习算法.
1 引 言
在经典计算领域, 生成模型被广泛应用于各个领域, 如图像生成[1]、语音合成[2]、药物设计[3]、图像转换[4]等. 近来已有对经典生成模型的量子版本的研究, 如量子生成对抗网络[5,6]、量子玻恩机[7,8]、量子玻尔兹曼机[9-12]、量子自编码器[13-15]以及量子贝叶斯网络[16]等.
量子生成模型是受经典机器学习模型启发, 使用量子计算机来改进经典模型中的生成步骤, 以完成数据生成、概率模拟任务的一类算法.
这类算法的主要步骤是, 通过量子线路生成量子态, 用量子态观测结果构建损失函数, 再通过经典的优化算法进行迭代优化, 从而得到最优的参数变量集合以完成相应的生成任务. 因此, 这些算法被统称为量子-经典混合算法. 这种量子-经典混合的闭环优化思想始于变分量子算法[17], 即通过量子计算机和参数化量子门操作集合获得分子的量子态表示, 测量分子模型对应的哈密顿量的期望值, 以此作为目标函数进行变分优化.
量子相位估计[18]在大数分解[18]、HHL[19]等被证明有量子优势的算法上具有广泛的应用, 但基于以下原因相位估计算法无法在当前的计算体系下有效实现: 1) 当前硬件体系多集中于单量子门和两比特纠缠门的实现, 相位估计用到的受控幺正门(c-Uj)必须分解为基本门的组合, 此过程会显著降低受控幺正门的保真度; 2) 相位估计用到的量子傅里叶逆变换需要O(n2) (n为量子比特个数)数量级的量子门, 使得深层量子线路的态保真度无法达到量子计算要求. 量子计算体系的噪声不可避免, 当前只有中等规模的量子比特、无法实现有效的量子纠错[20]技术, 这使量子-经典混合算法受到广泛关注.
尽管已有多种量子生成任务在真实量子芯片上完成, 如利用量子生成对抗网络进行图像生成与识别[21], 但对于参数量子线路(Parameterized Quantum Circuit, PQC, 见附录)的表示能力与经典网络相比是否具有优势还缺少理论的结果.Du等[22]尝试从内在的线路结构出发证明其结论,而经典深度学习神经网络和量子线路的比较还没有结论. 同样的, 量子生成网络作为量子机器学习的一部分, 如何将经典数据转化为量子态、如何从测量结果获取经典信息仍需要更直观更普适的方法.
本文主要分析一些常见量子生成模型的优势和劣势, 并对其扩展性展开讨论. 量子生成模型的分类与经典生成模型类似, 是以任务为导向的. 量子生成模型基本沿袭与之对应的经典生成模型的命名, 如量子生成对抗网络是使用量子线路来完成经典生成对抗任务的一种量子生成模型. 对于利用量子体系特有的性质以完成生成任务的, 如量子玻恩机, 则是用量子专有的玻恩测量命名. 还有一些模型保留了原作者的命名方式, 归并在“其他生成模型”这一节进行介绍. 一些量子生成模型如量子生成对抗网络、量子玻恩机、量子自编码器等用到的参数量子线路, 在附录里会有详细的介绍. 通过对这些模型的比较, 可以从不同角度理解量子生成模型的构建思路, 以此为不同的计算任务构建与之适应的计算模型提供启发.
2 量子生成模型
2.1 量子生成对抗网络
经典的生成对抗网络[23](generative adversarial Network, GAN)被视为深度学习中的前沿进展. GAN在生成图像[1]、语音[2]、文本[24]等方面具有非常广泛的应用. 经典生成对抗网络是一类有两个玩家的博弈游戏, 一个是生成器(generator), 记为G, 另一个为鉴别器(discriminator), 记为D. 对于已存在的源数据→x~pdata, 生成器G生成新的数据以逼近真实的源数据分布, 使D无法区分数据的来源; 而鉴别器D对每个输入数据给出真或假的决策概率, 以最大程度地区分这两类数据.
如果G产生的数据足够逼近目标数据, D无论对于何种输入数据, 都有50%的几率误判, 这时生成对抗网络就达到了Nash平衡点. 设真实的源数据标签为1, 由G产生的数据标签为0, D输出(0,1)间的概率值, 那么生成对抗网络的损失函数可以被定义为:

生成对抗网络的训练策略是, 更新其中一方的参数时, 另一方的参数保持不变. 对于上述的损失函数模型, 优化任务为 m inθGmaxθDL(D,G). 采用经典神经网络构建的GAN模型, 可以用反向传播算法来实现梯度计算.
量子的生成对抗网络[5,21,25,26](quantum GAN,QGAN)基本保留了经典生成对抗模型的特征, 不同之处在于量子生成对抗网络用到的数据集既可以是量子的也可以是经典的, 而且可选择地, 生成器与鉴别器也可以为经典神经网络或参数量子线路.
对于数据是量子的, 生成器与鉴别器也都是量子的情况, Dallaire-Demers等[5]提出了这样的QGAN模型: 源数据的概率分布模型为pR(x) , 由某个未知(有可能很复杂)的过程R生成. 由参数θG确定的生成器G生成新的数据样本, 由参数θD确定的鉴别器D识别这两类数据. 用标签λ指定源数据中的类别,, 考虑噪声|z〉 , 可以按照(1)式定义与参数有关的损失函数L(θD,θG) , 这里D的输入是R(|λ〉) 或G(θG,|λ,z〉)) :

其中含φ的项是调整源数据和生成部分占整体的比例. 一般取Dallaire-Demers等构建的量子生成对抗网络线路图如图1所示.
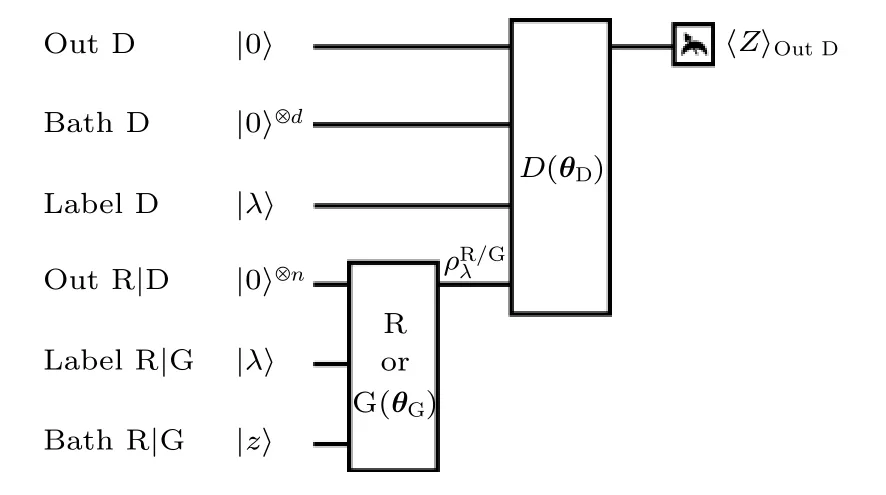
图1 量子生成对抗网络结构[5]Fig. 1. The general structure of QGAN[5].
量子生成对抗网络的任务就是通过参数优化来实现 m inθGmaxθDL(θD,θG) , 从而得到最接近于源数据概率分布的分布模型与鉴别模型. 量子线路的梯度可以用数值差分[27]、参数位移法则[27]、以及Hadamard test线路[5]来求. Dallaire-Demers在数值模拟上实现了源数据为|0〉,|1〉 两个量子态的生成对抗任务.
Lloyd等[6]讨论了当数据是量子的, 鉴别器是量子或经典的, 生成器是经典的量子生成对抗模型. Lloyd所述的量子数据是通过对一个量子体系进行固定的测量得到的数据分布. 根据量子优越性[19]的表述, 经典的生成器不能有效地匹配量子数据分布, 或者更准确地, 除非有指数的资源可用,经典的生成器无法模拟量子数据的分布pR(x). 对于数据是经典的, 生成器和鉴别器都是量子的情况, Lloyd通过对比得出, 经典的生成器和鉴别器在计算梯度时需要O(N2) 个比特和O(N2) 步时间(N是经典数据的维度), 而量子的生成器和鉴别器在计算协方差矩阵时, 如果矩阵是低秩和稀疏的,需要O(logN) 个量子比特和O(poly(logN)) 个逻辑门操作.
Zeng等[26]结合量子玻恩机构建了经典数据-量子生成器-经典鉴别器的量子生成对抗模型, 实现条带图(bars and stripes, BAS)[8,16,26,28]的概率生成与识别(见第2节). 类似的, Situ等[29]将BAS图的每个点都编码至量子比特上, 通过参数量子线路构建的生成器生成量子态, 测量结果输入至经典神经网络构建的鉴别器, 也实现了BAS图的生成.Zouful等[25]通过测量量子态在计算基上的投影,将其转化为数据对应的概率, 以此为基础构建生成对抗网络, 实现了对数正态分布、双峰高斯分布等概率分布的学习和生成. 值得注意的是, 连续数据被截断并舍入到临近整数值, 所以该模型仍是离散数据的概率学习模型.
随着量子硬件操控水平的提高, 在量子芯片上实现量子生成对抗网络已经有相关的工作. Hu[30]等利用超导量子体系首次实现了具有量子数据、量子生成器、量子鉴别器的量子生成对抗网络的实验验证, 生成保真度高达98.8%. 在Hu的实验中, 量子数据为单比特量子态, 生成器参数为量子门旋转角度. 在优化D或G时采用梯度下降算法, 量子系统的操控和测量通过FPGA(field programmable gate arrays)实现, 线路梯度通过经典计算机估算得到. 该实验对于NISQ体系下的量子机器学习优势的探索具有重要意义. 此外, Huang等[21]通过将测量量子生成器得到的数据作为经典图像灰度值, 完成了手写数字集0和1的生成对抗任务, 为量子比特资源受限条件下经典数据的生成提供了一个思路.
2.2 量子玻恩机
量子玻恩机[7,8](quantum circuit Born machine,QCBM)是基于波函数的概率解释的一种模型. 量子玻恩机将概率分布编码至初态上, 把量子态在计算基上的投影作为数据的概率. 量子玻恩机是一种隐式的生成模型, 因为我们实际上并不需要知道这个纯态的密度矩阵, 而只需要知道叠加态振幅的模值. 这样的设定对量子线路的结构限制也更少, 所以一般被认为具有更强的表示能力.
对目标概率分布 π (x) 进行采样得到数据集D={x}, QCBM通过参数量子线路把初态|0〉 演化为|ψθ〉 , 并在计算基上的测量得到生成数据x~pθ(x)=|〈x|ψθ〉|2的概率分布. 训练目标是让模型的概率分布pθ接近真实数据分布 π (x). QCBM采用所谓的MMD(Maximum Mean Discrepancy)损失函数:
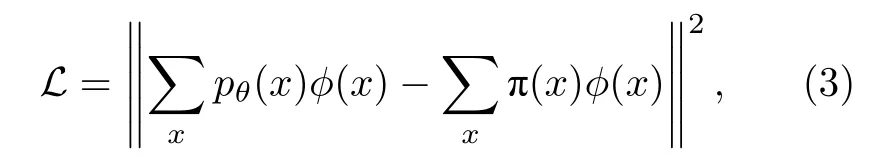
其中φ将x映射到高维Hilbert空间. 进一步地,定义核函数K(x,y)=φ(x)Tφ(y) , (3)式即可避免在高维空间中进行运算, 等价于
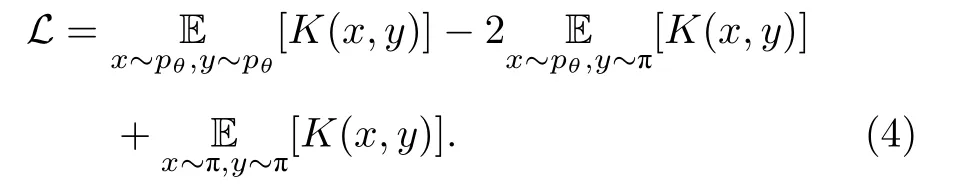
核函数可以取为高斯形式:K(x,y)=直接计算上述损失函数的梯度比较困难, 但可以证明, 下式无偏地等价于梯度:
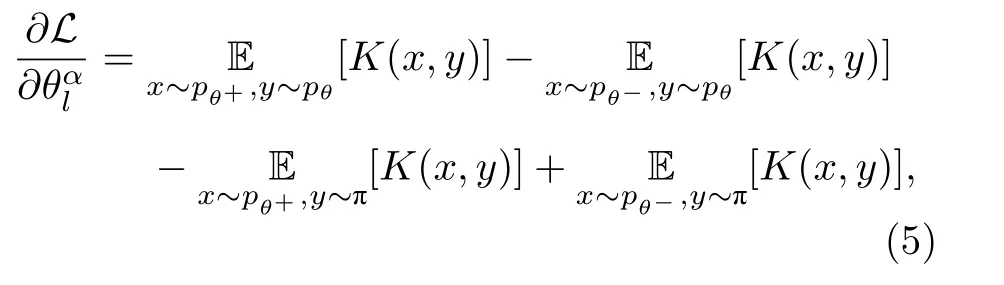
其中pθ+(x) 和pθ-(x) 是在参数下 的模型输出概率,是参数空间的第 (l,α) 个单位矢量(α和l分别表示迭代的步数与当前迭代的第l个参数的下标).
对所有量子比特进行测量, 会得到计算基上的概率分布. 源数据被映射为经典的比特流数据, 与量子态的计算基一一对应. 这种映射是一种同构,源数据空间和映射空间一样大, 因此数据集的数据必须是有限的. 对于N个数据的集合, 需要n~O(log(N))个量子比特. 而生成线路中所用的量子门个数一般为O(poly(n)).
量子玻恩机是一种隐式生成模型, 模型本身并不涉及经典数据的特征维度, 甚至不涉及数据本身的形态. 在量子体系中不需要考虑数据的原本面貌是什么. 无论是图片、数字还是文字, 都会被编码为经典比特流数据. 一旦数据同构的方式确定了,基于量子线路的优化体系就与原本的数据形态无关了.
利用量子玻恩机进行概率分布的学习和生成在条带图(bars and stripes, BAS)[8,16,26,28]任务中取得很好的结果, 对于理想的无误差测量, 量子玻恩机生成真实数据分布的比率为95.7%[8]. 此外通过对量子玻恩机的非计算基测量, 可以得到更多的信息, 这种方法可用来生成先验概率分布, 如经典生成对抗网络的先验分布[31]. Cheng等[32]还从信息熵的角度比较了量子玻恩机与受限玻尔兹曼机[33,34], 为理解基于概率的生成模型和基于能量的生成模型提供了一个新的视角. Coyle等[35]提出一种量子玻恩机的子类—量子伊辛玻恩机—并引入量子核函数[36]来讨论量子学习优势.
2.3 量子玻尔兹曼机
与前述模型不同, 量子玻尔兹曼机[9-12](quantum Boltzmann machine, QBM)需要一种专用的量子计算机—量子退火机.
经典的玻尔兹曼机被广泛用作机器学习的基础工具, 例如深度信念网络[37,38]和深度玻尔兹曼机[37,39]. 玻尔兹曼机是二进制数节点构成的概率生成网络, 由可见节点和隐藏节点组成, 记为za,a=1,2,···,N, 其中N是总节点数. 这里为了和后面的量子生成模型保持一致, 取za∈{+1,-1}而不是za∈{+1,0}. 为区别可见节点和隐藏节点, 我们分别记为zν,zi. 同时用向量符号v,h,z=(v,h) 表示可见态、隐藏态和组合态. 在物理上其能量可以用伊辛模型表示:

其中ba,wab是在训练的过程中进行需要优化的参数. 定义负对数相似度损失函数:

其中观测到可见态h的概率为边际分布Pv=那么玻尔兹曼机的任务就是优化哈密顿量的参量θ∈{ba,wab}, 使边际分布尽可能接近真实的数据分布这样就可以用梯度的方法来优化玻尔兹曼机:

其中 〈 ···〉 和 〈 ···〉v分别为对自由变量的玻尔兹曼均值以及对可见变量的玻尔兹曼均值.是双重均值. 这样我们就得到更新法则:

关于如何估算等式右边的两项均值, 在机器学习领域已经有较多的方案, 其中一个简化的玻尔兹曼机模型—称之为受限玻尔兹曼机(restricted Boltzmann machine, RBM)—已经成功的应用于实例[40].
量子玻尔兹曼机的出发点是使用作为物理实体的量子比特来替代经典的比特或节点. 然而不同的是, 量子力学体系的哈密顿量是 2N×2N维的矩阵. 而且量子力学算符大多是不对易的, 这对于求解梯度十分不便. 横场伊辛模型的哈密顿量形式为:
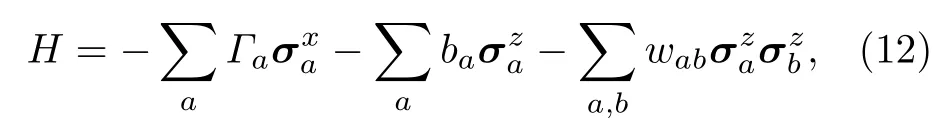
其中I,σz,σx为泡利矩阵, 下标a表示作用于第a个量子比特. 与经典玻尔兹曼机类似, 定义配分函数和密度矩阵分别为:Z=Tr[e-H],ρ=Z-1e-H. 对于给定的可见态 |v〉 , 可定义边际分布Pv=Tr[Λvρ],Λv=|v〉〈v|⊗Ih. 其 中Ih为 作 用在隐藏变量的单位阵.
那么类似地, 可以得到量子损失函数和对应梯度为:
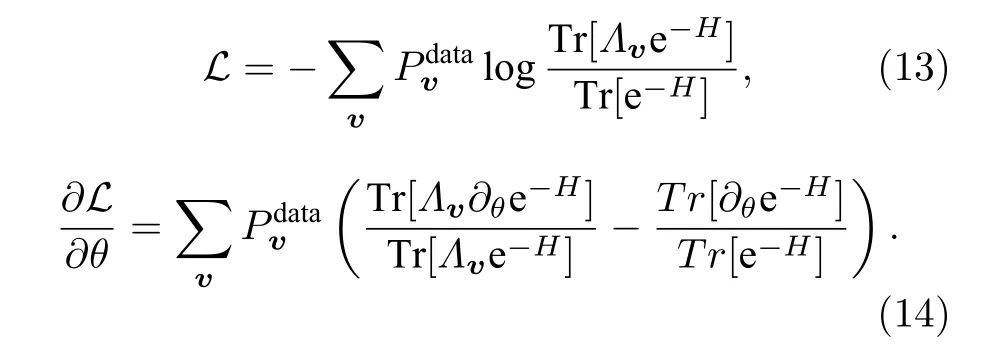
然而H和∂θH并不对易, 也就是e-H∂θH. 这样在求解期望值的时候就会十分困难. 尽管Amin[9]通过分析的方法估算除了损失函数的界, 在一些特定的条件下可以估算损失函数的梯度, 但与前述量子生成模型相比, 参数更新的成本已然增加了.
尽管如此, 量子玻尔兹曼机仍然可以用来完成监督学习任务, 可以生成概率分布, 可以进行鉴别学习. Amin等[9]用量子玻尔兹曼机实现了伯努利分布的概率生成. Kieferová[12]用量子玻尔兹曼机设计了一种生成模型用以实现部分的量子态层析,并且除非BQP=BPP, 经典计算机无法有效地模拟其训练过程. Dorband[41]在D-wave量子退火机上演示了量子玻尔兹曼机的构建过程. 但是, 相较于其他量子生成模型, 量子玻尔兹曼机带来的近似误差是难以避免的, 同时也难以说明相较于经典版本的优势所在.
2.4 量子自编码器
在经典的数据处理中, 通过机器学习中的自编码器可以将数据从一个高维空间缩减到低维空间.经典的自编码模型可以概括为: 通过参数化的神经网络来训练一个数据集, 其数据维度为 (n+k) , 得到擦除k个特征或维度的新数据, 如果这些数据可以通过解码器(神经网络)重新生成接近于原数据的一组新数据, 那么留下的n维数据被称为压缩数据. 这个过程被称为数据压缩. 数据压缩对于处理稀疏特征数据集或高维数据集是十分直观和有效的手段. 受此启发, 量子自编码器[13-15](quantum autoencoder)被设计为量子态压缩的工具.
Romero等[13]提出的量子自编码器与经典类似: 记{pi,|ψi〉AB}是 (n+k) 个量子比特上的纯态集合, 子系统A和子系统B分别占有n和k个比特. 记Uθ为作用在 (n+k) 个比特上的幺正算符,其中θ={θ1,θ2,···}是参数集合, 以及|a〉B′为k比特寄存器的参考纯态. 通过经典的优化方式, 我们希望平均保真度函数取得最大值:
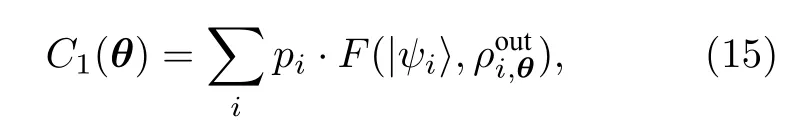

其中ψiAB=|ψi〉〈ψi|AB, 以及aB′=|a〉〈a|B′.
量子自编码器的核心在于, 如果想要有效地压缩量子态, 必须保证态|ψi′〉=Uθ|ψi〉AB是A, B两个子系统的直积态. 即当下式成立时, 才有C1=1 :

对输出态进行量子态层析以确定其密度矩阵是非常困难的. 可以证明测量B和B'寄存器的态保真度等价于AB寄存器初态和末态的保真度(我们称B寄存器输出态为冗态). 这样, 可以定义另一种平均保真度C2(θ) ,
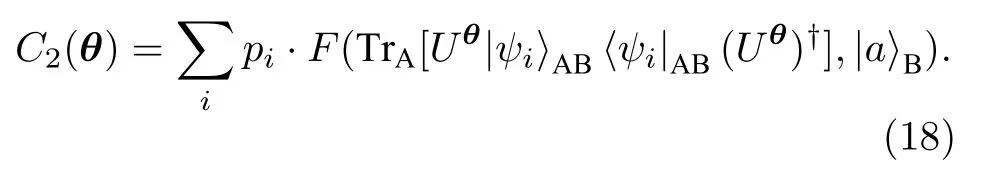
实际上求两个态的保真度, 有一种SWAP测试线路可以完成[42].
通过参数量子线路来构建作用于AB系统的幺正变换, 并通过SWAP测试线路得到保真度信息. 取损失函数为L=-log(1-C2) , 采用经典方式进行优化, 可以得到保真度最高的参数线路, 这样就实现了数据压缩.
如图2所示, 量子态压缩模型可以由以下步骤来构建: 第一, 制备初态|ψi〉 和参考态 |a〉 , 并假设制备是有效的; 第二, 构建参数线路, 初态在幺正算符U下演化; 第三, 通过SWAP测试得到冗态和参考态之间的保真度.

图2 量子自编码器的训练示意图, 其中 p 表示变量, 摘自[13]Fig. 2. Schematic representation of the hybrid scheme for training a quantum autoencoder where p represents variables, image from[13].
量子自编码器在氢分子态的应用是一个成功的例证[13]. 其方法是用4 qubits来模拟氢分子, 通过变分量子求解器(VQE)求出对于固定原子间距的量子态, 以此作为量子自编码器的输入态. 氢分子的态并非占满了4 bit的希尔伯特空间, 这就为量子态压缩提供了可能. 直观上看, 量子态压缩的过程就像在整个希尔伯特空间中将若干子空间碎片像拼图一样拼接成紧密的空间. 量子自编码器在量子加法器方面也有一定的应用[14], 这种加法器用以实现将两个相同比特数的量子子系统编码到一个新的子空间. Ding等[43]借助超导量子体系在实验上验证了量子加法器的可行性, 实验保真度与理论值一致.
Pepper等[44]采用了Romero等[13]提出的量子自编码器框架, 不同的是, 其数据压缩任务是将多维量子比特(qutrit,|ψ〉=α|0〉+β|1〉+γ|2〉(已归一化))压缩为二维量子比特(qubit)态. 通过光量子实验体系, Pepper等在实验上实现了qutrits的压缩, 并且证明了这样的实验优化系统对扰动是鲁棒的. Bondarenko等[45]注意到经典数据通过经典自编码器可以有效地去除噪声, 因此量子自编码器同样有类似的作用. 通过构建以自旋翻转噪声和任意幺正门噪声为主的GHZ含噪声量子态, Bondarenko等验证了量子自编码器在量子数据去噪方面的作用.
如何判断量子态能否通过量子自编码器有效压缩一直受到关注, Huang等[46]在理论上论证了实现有效量子自编码态压缩的条件, 并证明了若输入数据的最大线性无关向量的个数不超过隐变量空间(压缩后的低维空间)的维度, 那么量子自编码器就可以无损地将高维数据压缩至低维. Huang等利用量子光学体系在实验上验证了其理论的结果. 此外Cao等[47]提出可在量子退火机上运行、通过噪声辅助的绝热模型, 同样可以完成量子自编码任务. 同时, 对量子态压缩的探索也使得量子梯度消失的现象—也即贫瘠高原的现象—得到进一步的研究[48].
2.5 其他生成模型
从前述量子生成模型可以看出, 经典机器学习给我们带来了很多启发. 类似地, 经典领域中因子图(factor graph)可以作为概率生成模型, Gao等[49]提出了一种量子生成模型(quantum generative model, QGM), 并证明此模型可以高效地表示任意因子图. 并且通过理论证明至少存在一些特定的概率分布, 可以被QGM有效表示, 但不能被任意具有多项式量级变量的因子图有效表示. 如果多项式层次作为Pvs. NP问题的泛化是不塌缩的话,QGM相对于经典的因子图具有指数优势.
同时, 除了QGM的表示能力和泛化能力,Gao等[49]还提出了一种通用的量子学习算法, 该算法利用张量网络、对多体纠缠量子态的父哈密顿量(parent Hamiltonian)构建、以及递归的量子相位估计进行学习. 显然希望这种算法对任意问题都能在多项式时间内解决是不现实的, 但作者证明了至少存在一些问题, QGM相对于任意经典算法均有指数加速的效果, 前提是假设量子计算机不能被经典计算机有效地模拟.
直观地理解QGM中的指数加速效果: 机器学习中的生成模型旨在通过寻找潜在的概率分布, 对自然界任意的数据生成过程进行建模. 由于自然界受量子力学定律支配, 用经典生成模型中的概率分布对真实世界中的数据进行建模具有很大的局限性. Gao等[49]提出的QGM模型, 用一个多体纠缠量子态的概率幅对数据的相关性进行参数化. 因为量子概率幅的相干性产生的现象比经典的复杂得多, QGM才有可能在特定情况下实现性能的显著提升. QGM使用图态|G〉 表示, 由m个量子比特与图G构成. 如图3所示.

图3 经典和量子生成模型 (a) 因子图表示; (b)张量网络态表示; (c)量子生成模型定义[49]Fig. 3. Classical and quantum generative models: (a) Illustration of a factor graph; (b) illustration of a tensor network state;(c) QGM definition[49].
Gao[50]有另一篇工作同样旨在发掘量子相关性在生成模型中的作用. 其中比较了经典贝叶斯网络顺序模型与对应的一维张量网络, 展示了矩阵直积态(matrix product states, MPSs)比经典机器学习模型有更强的表示能力. 因为一维模型可以在经典计算机上被有效模拟, Gao等采用数值模拟的方式测试了真实数据集的生成, 发现MPS生成能力比经典模型有提升. 此结果为理解基于MPS的机器学习算法提供了新的视角, 因为有一类张量网络子类不能有效地被经典计算机模拟, 但是可以在量子计算机上构建, 这就使得在机器学习中的生成模型框架下量子优势是可能存在的.
除以上的量子生成模型外, 还有基于贝叶斯理论提出量子贝叶斯线路[16]. 这种量子线路引入辅助比特表示先验概率分布, 通过受控操作传递给数据比特寄存器. 这样可以极大地规避参数量子线路中出现的生成概率不均匀的问题.
3 量子生成模型展望
随着量子计算机硬件的不断发展, 量子生成模型也不只在量子虚拟机上得到实现, 基于真实量子芯片的生成模型受到了广泛的关注, 但是量子生成模型存在的问题仍待解决.
首先, 量子生成模型是否可以生成任意概率分布的数据? 对于连续变量的数据, 量子生成模型还无法像经典神经网络一样有效地生成. 同时, 数据是量子还是经典的决定了生成模型的选取. 对于经典数据, 利用MPQCs或MPSs生成量子态, 对量子态的测量得到了量子信息的经典统计结果. 如何更有效地生成量子态以及如何从量子态读取更多信息一直受到关注, 不同的量子生成模型给出了不同的策略, 然而对于任意连续变量数据的生成还需要进一步的探索.
其次, 量子生成模型作为量子机器学习的一部分, 如何体现量子计算的优势, 仍然是一个开放性问题. 对量子线路的表示能力的研究为我们提供了一个思路, 但是对于不同的生成模型很难给出统一的表示能力定义. 而Gao等[49,50]从量子相关性出发, 直观上将量子内在相关性的参数化来实现经典生成模型无法模拟的任务, 说明了量子优势在机器学习领域中的存在性.
对于量子生成模型, 还需要进一步探索. 在量子领域, 量子生成模型提供了NISQ体系下可执行的算法, 在机器学习领域, 它引入了量子计算和量子信息的理念, 使机器学习算法突破经典计算的瓶颈成为可能.
感谢中国科学技术大学薛程博士和赵健博士的讨论.
附录A 参数量子线路
量子计算机遵循量子力学定律进行逻辑运算和信息存取. 而量子力学体系区别于经典体系之处在于, 由于叠加态和纠缠态的存在, 相同位数的量子数据比经典数据有着指数强的表示能力. 将量子信息转化为经典信息需要对量子态进行测量.
量子计算的基本计算单位是量子比特(qubit), 单比特量子叠加态记为|ψ〉=α|0〉+β|1〉 (已归一化). 根据玻恩的几率解释, 对单比特量子态进行测量, 得到0态的概率为|α|2, 得到1态的概率为|1〉. 对于多量子比特系统, 根据量子力学体系的完备性, 量子态可在计算基上展开, 由|Φ〉=测得任意态 |i〉 的概率为|ai|2. 对于泡利算符σi,i∈{0,x,y,z}, 其期望值可以通过算符的谱来计算, 即其中λj为本征值,|ψj〉为本征态. 对于一个更复杂的哈密顿量H, 我们总能将其分解为若干泡利算符的直积, 再分别求出各个部分的期望值,即m∈{0,x,y,z},αi,j,k...m为泡利基的实系数.
通过测量量子态在计算基上的投影或哈密顿量的期望值得到的经典数据, 其处理策略也根据量子生成模型的不同而有各式的差异. 如对于量子玻恩机, 量子测量得到的数据被映射为数据集的概率分布, 显然这样对于小型数据集或稀疏数据集有表示优势. 而对于量子生成对抗网络, 测量得到的数据可直接作为生成数据以混淆源数据.
量子生成模型的核心在于利用量子计算机生成量子态,对量子态进行测量得到经典的有效信息. 如何有效地生成量子态, 是我们面临的首要问题. 参数量子线路(PQC)为这一问题提供了一个思路.
参数量子线路一般由若干单量子门和多量子纠缠门组合得到, 单量子门可以是任意单比特幺正门US(θ) , 常用的有泡利旋转门多量子门一般采用UCZ=|0〉〈0|⊗I+|1〉〈1|⊗σz,UCNOT=|0〉〈0|⊗I+|1〉〈1|⊗σx等两比特门. 单量子门和多量子门交替的结构极大地提高了态的纠缠能力, 扩展了态的表示空间.
记量子线路的参数为θ, 则参数量子线路可以用U(θ)表示. 若要保证参数量子线路是有效的, 其参数总量和线路深度都有相应的限制. 一般设定参数的总量是多项式级的,即n~O(poly(N)) , 其中n为参数个数,N为量子比特个数.同时线路的深度也设为多项式级的, 即L~O(poly(N)).
如何使参数量子线路有更强的表示能力一直受到关注.最直观的方式是增加参数量子线路的深度, 构成MPQCs(multiple parameterized quantum circuits). 然而MPQCs的线路深度至多为多项式级的才能满足有效性要求, 也即图A1中的PQC模块数是常数级的, 不随量子比特数目增长. 而且由于量子噪声的存在, 增加PQC的模块数会极大地影响量子态的保真度, 所以在真实的任务中往往会限制PQC的模块数. 除此之外还可以通过非计算基补充测量的方式, 来获取更多的数据信息, 这种方法在QCAAN线路[31]中被提到.

图 A1 参数量子线路示意图Fig. A1. Illustration of MPQCs.
对经典神经网络的表示能力的研究是一项非常重要的课题, 参数量子线路的表示能力直接关系到其能否体现量子优越性. Du等[22]证明了在多项式层次结构保持的前提下, 具有O(poly(N)) 个门的参数量子线路, 其表示能力比具有O(poly(N)) 个参数的经典玻尔兹曼机要强. 尽管如此, 参数量子线路和经典神经网络的直接比较还有一些困难, 如何定义对量子和经典体系均适用的表示能力指标, 以及参数量子线路能否体现量子的优越性, 仍是开放性的问题.
