基于棋盘空间的中文命名实体识别研究
2021-08-05李国安张灿豪
李国安 张灿豪
(1.上海壹账通金融科技有限公司,上海 200000;2.深圳壹账通智能科技有限公司,广东 深圳 518000)
0 概述
命名实体识别(Named Entity Recognition,NER)是指提取文本中特定信息的方法,常见有提取人名、地名、公司、职位、合同以及金额等。NER技术在自然语言处理中应用广泛,例如知识图谱、关系抽取、智能问答以及信息搜索等,是处理自然语言的基础任务之一。通常,NER处理方法是将其视作序列标注任务,标注出每个字对应的实体类别。主流标注方法是区分每个字属于实体类别中的某种状态,例如B-LOC表示第一个地址文字,E-LOC表示最后一个地址文字,字母O表示非实体,典型的有BIO标注法、BIOE标注法和BIOES标注法等。近年来NER以预训练模型为基础,融合多特征、两阶段识别,但是一直没有改变命名实体标注割裂的问题。典型的标注序列BIOE的NER方法是将任务看作多分类问题,多个类别之间割裂了相互关系,而且难以处理嵌套问题,而位置、实体两阶段NER方法存在配对偏差和误差传播的问题。该文提出棋盘空间标注命名实体的方法,棋盘空间的每个标记点都表示唯一一个命名实体,是对命名实体的直接标注方法,解决了实体间接标注的关系割裂、配对和误差传播等问题。
1 相关研究
随着神经网络的发展,NER任务得到了越来越好的效果。文献[1]基于长短期记忆神经网络LSTM提出了LSTMCRF,由于其优异的表现,许多数据集将其作为NER任务的基线。2018年,文献[2]BERT预训练模型的问世几乎夺取了当时所有NLP任务的SOTA,对于CoNLL-2003英文NER任务来说,在未使用CRF的情况下达到了92.8的水平。BERT的出现改变了NLP模型的发展方向,行业内的人士纷纷开展预训练模型的相关研究,随后相继出现了XLNET、RoBERTa、GPT-2、GTP-3和Switch-Transformer等一系列拥有更大规模的训练数据、参数和算力要求的预训练模型,NLP效果也得到进一步提升,中文NER任务开始引进预训练模型来增强文字表意能力,并不断向模型中加入先验知识。有些学者结合了知识图谱增强了预训练模型的背景知识,文献[3]中的FLAT模型在BERT的基础上融入了分词特征,还有研究学者在BERT的基础上增加了词性特征。当实体类别很多时出现了分别识别实体位置和实体类别的两阶段方法。文献[4]中的Cascade模型在BERT的基础上设计了两阶段预测模型,该模型取得了较好的效果。
2 棋盘空间
由下围棋向棋盘落子时得到启发,棋盘为19×19方阵,落子时棋子的颜色是某个类别,如果把棋盘的横纵坐标看作文字中实体的始末位置,那么黑子表示属于该类别,白子表示非该类,多张棋盘表示不同的类别,这样就将棋盘扩展到三维空间,形成一个命名实体识别的棋盘空间,如图1所示。

图1 棋盘空间标注示意图
对于类别数量为dm、文本长度为dt的棋盘空间S∈Rdm×dt×dt,输入输入长度为n的文本t=[t1,t2,…,tn]和标注列表[{起始1,结束1,类别1},…,{起始i,结束j,类别m}],棋盘空间标注满足公式(1)。

3 模型
3.1 整体结构
长度为n的文本编码后生成token序列t=[t1,t2,…,tn],ti∈Rdt,任意i∈[1,n],dt为token深度,预训练模型输出序列h=[h1,h2,…,hn],其中hi∈Rdh,dh为文字嵌入深度,适配层将序列h线性变换切分成2个关联矩阵Q∈Rdm×dt×dt和K∈Rdm×dt×dt,结合位置编码计算每个位置的相似性系数。NER模型结构如图2所示,其中Sm(i,j)为类别m中位置(i,j)点的分类,Pm为类别m的正样本,Nm为类别m的负样本,[CLS]和[SEP]为预训练模型的特殊标识符,分别表示文本开始和文本分隔,类别为m的查询矩阵Qm=[q1,q2,…,qn],度量矩阵Km=[k1,k2,…,kn],相似性矩阵Sm=[s1,s2,…,sn],qi、ki和si分别为矩阵Qm、Km和Sm的向量,任意i∈[1,n]。

图2 棋盘空间标注的NER模型结构
3.2 适配层
适配层是将预训练模型的输出H∈Rh×n变换到目标维度Q∈Rm×n×n和K∈Rm×n×n,如图3所示。首先H保持文字长度n不变,将文字嵌入维度h变换为m×2n,即变换输出矩阵A=WH+b,其中A∈RdA×n,权重W∈RdA×h,偏置b∈RdA×n,dA=m×2n。接着将A按照dA轴切分成类别数m份,每一份中再切分为两等份,分别定义为未位置编码的查询矩阵Q和度量矩阵K。

图3 适配层处理流程
为了便于表述,对类别m的查询矩阵记作q=[q1,q2,…,qn],其中向量qi∈Rn,度量矩阵记作k=[k1,k2,…,kn],其中向量ki∈Rn。
3.3 位置编码
对于NER任务来说,文字的位置信息和方向信息都是十分重要的。文献[5] Transformer-XL和文献[6] TENER论述了原生的Transformer绝对位置编码会在计算中丢失位置信息,这使绝对位置编码不适用于NER任务。BERT等绝对位置编码的预训练模型是在词嵌入层将词向量和绝对位置编码向量按位相加,并在大规模预料上训练而得到的,如果改变位置编码方式,则该模型需要重新训练;那么如何在不重新训练BERT的前提下将相对位置信息显式地添加上去呢?可以将BERT输出的词向量扩展至词向量函数,该词向量函数需要具备2个特性:1)位置无关的偏置转换性。2)有界性。在实数域内同一个词在不同位置的词向量是一样的,无法达到建模位置信息的目的,因此使用复数域[7]来表示向量值函数,对于词向量hj到相对位置pos的词向量变换函数、f(j,pos)如公式(2)所示。
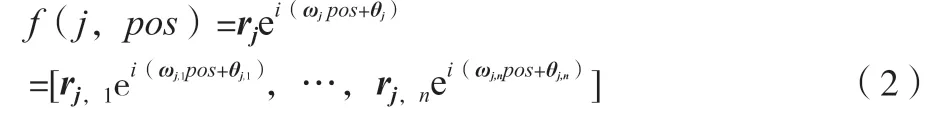
式中:ωj,n为ωj的向量展开;θj,n为θj的向量展开;rj,n为rj的向量展开;i为虚数;rj为振幅向量;ωj为角频率向量;θj为相位角向量。

3.4 相似性系数
预训练模型是按照完形填空的方式,在最大化上下文语境情况下的掩码单词的概率,在训练过程中不断调整单词表征向量在上下文语句空间中的参数,以最大化单词和上下文的共现概率,在高阶产生共现关系。据此,对于类别m的相似性系数Sm(i,j)可以使用位置编码后的向量qi和kj的内积表示,定义如公式(4)所示。
式中:Re为实部;Im为虚部;i为起始位置;j为结束位置;z为临时变量;fpe(.,i)、fpe(.,j)为位置向量。
结合中文特点,文字顺序是单向的,没有“倒背如流”式的标注,所以实体始末位置要求i≤j,对于i>j的情况置为极大负数-inf。
3.5 损失
棋盘空间为稀疏矩阵,正负样本存在较大的不平衡,该文采取的优化目标为正类相似度的最小值min≥某阈值λ,并且负类样本相似度的最大值max≤该阈值λ,如公式(5)所示。
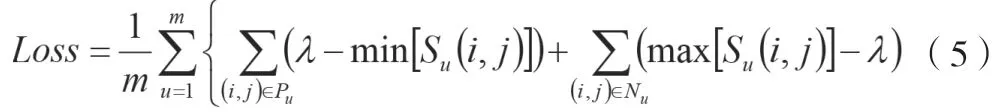
式中:Loss为损失;m为实体类别数量;γ为分割面,是训练中的超参数;Pu为实体类别u的正样本;Nu为实体类别u的负样本;Su(i,j)为从i开始到j结束的文本区间属于实体类别u的相似度。对数幂指数求和函数有如公式(6)和公式(7)所示的相似性。
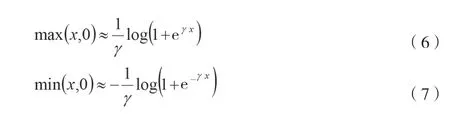
式中:γ为正实数,γ值越大相似性越强。
对公式(5)中求和的2个部分内容分别引入2个超参数[8],得到损失函数如公式(8)所示。

式中:α,β为比例因子,是训练时的超参数。
3.6 模型输出
模型输出棋盘空间S∈Rdm×dt×dt,根据损失函数的定义,棋盘空间中满足Sm(i,j)>γ条件的点表示从起始位置i到结束位置j的文字片段为实体类型m。
4 试验
4.1 数据集
该文采用CLUENER2020[9]数据集,该数据是在清华大学开源的文本分类数据集THUCTC的基础上,选出部分数据进行细粒度命名实体标注,类别有地址、书名、公司、游戏、政府、电影、姓名、组织、职位和景点共10类,训练集有10 748条文本,验证集有1 343条文本。
4.2 评价指标
该文采用macro-F1指标。
4.3 试验环境
试验计算机为Thinkpad P71笔记本电脑,具体配置见表1。

表1 试验环境
4.4 训练参数
最大序列长度为64,批次大小(batch_size)为16,学习率(learning_rate)为2e-5,丢弃比率(dropout_rate)为0.1,轮次(epoch)为40,优化器为Adam,α,β和λ为1。由于显卡限制,该文以BERT-base和NEZHA-base[10]为基础,2个中文预训练模型分别由哈工大[11]和华为开源提供。
4.5 结果
随着训练epoch的增加模型损失Loss逐渐收敛,训练集上的F1指标逐渐增加,如图4所示。
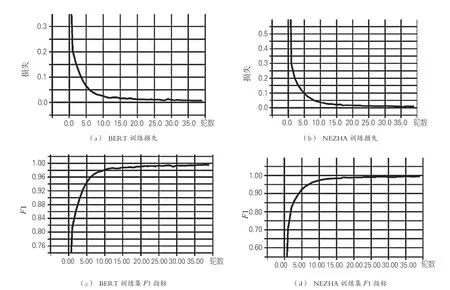
图4 训练损失及F1指标
训练之后的模型在验证集上进行测试,基于BERT和NEZHA的模型F1指标分别达到80.43和80.71。该文所采用的方法的BERT-base模型较BERT-CRF有1.61个百分点的提升,NEZHA-base模型略好于RoBERTa模型,具体指标见表2。从表2中可以看出,地址类实体得分最低,表中所示方法均不超过70%。景点类实体得分比地址实体略好,最好成绩为74.75。其他类别的F1指标均达到80以上。
4.6 错误分析
由表2可以看出,人工分辨CLUENER各组标签的综合能力为63.41,许多类别标注存在较大难度,列举个别案例,见表3。对于组织和政府、地址和景点,不同人的理解可能不同。查阅了魔兽争霸游戏的资料,行号372表述的主体是“魔兽争霸3版本1.25”,这对非专业人士和通用NER来讲难度都比较大。

表2 不同模型命名实体识别结果

表3 错误预测案例
对于预训练模型,因为训练集中单词的词频不同,所以高词频和低频词的空间分布特性导致了相似度过高或过低。假设2个单词在语义上是相同的,但是它们的词频差异导致了空间上的距离差异,这时词向量的距离对语义相关度的表征能力会降低,文献[12]Bert Flow中称之为各向异性的词嵌入空间。
5 结语
针对中文命名实体识别通常采用序列标注的间接标注方法,该文提出了一种棋盘空间的命名实体直接标注方法,在预训练模型的基础上构建了该标注方法的NER识别模型,该方法在中文CLUENER2020数据集上的效果略优于BERT-CRF等基线模型。棋盘空间的直接标注法更加适用于嵌套实体和多标签实体的情况,具有较广的适应性。对于其他NLP任务,如果在低维度不可区分,在更高维度下标注将是十分有意义的尝试。另外,该文随机选取了超参数并且除预训练模型外没有融入其他知识,将来计划结合知识图谱进一步提高中文命名实体识别的效果。
