基于启发式强化学习的AGV路径规划
2021-08-05唐恒亮唐滋芳董晨刚尹棋正海秋茹
唐恒亮,唐滋芳,董晨刚,尹棋正,海秋茹
(北京物资学院信息学院,北京 101149)
随着智能化与无人化科技的快速发展,自动引导小车(automated guided vehicle,AGV)在智能仓储中的应用愈加广泛.AGV路径规划是指在最短时间、最短路径和最小能耗的指标下,为AGV规划出一条从任务起点到任务终点的无障碍最优路径.目前,常用于AGV路径规划的算法有人工势场法、A*算法、遗传算法、蚁群算法、神经网络算法和强化学习算法等,这些算法都存在各自的优势,但在目前的复杂环境下也存在灵活性不高、收敛速度慢、易陷入局部最优解等问题.为优化这些问题,相关的学者一直在科研的道路上前赴后继.
用于AGV路径规划的传统算法主要有A*算法、Dijkstra算法、人工势场法和模拟退火法等.赵晓等[1]结合跳点搜索算法改进A*算法,让跳点替换Openlist和Closelist中的不必要节点,简化了计算,缩短了寻径时间;针对A*算法逐个检查相邻节点从而增加处理时间的问题,Guruji等[2]改进了A*算法,在碰撞阶段和碰撞过程之前计算目标函数,减少了处理时间.贺丽娜等[3]将Dijkstra算法和时间窗原理结合起来顺序规划每个AGV的路径,能够有效避免死锁与碰撞.人工势场法结构简单,但对周围环境感知较弱,易陷入局部最优解且目标不可达.因此,Lazarowska[4]提出了离散化人工势场算法,修改无冲突路径以获得更平滑和更短的路径;Zhang[5]针对传统人工势场法,将智能体的运动方向作为控制变量,解决了路径摇摆的问题.模拟退火算法存在收敛速度慢,全局搜索能力弱的问题.Issam等[6]结合模拟退火与禁忌搜索算法,加快了收敛速度且获得了更精确的规划路径;巩敦卫等[7]在模拟退火算法的基础上引入了脱障算子和一致寻优算子,提高了全局搜索能力.传统算法虽然能规划出完整路径,但全局搜索与学习能力确实不及智能算法.
用于AGV路径规划的智能算法主要有人工神经网络算法、遗传算法、蚁群算法和粒子群算法等.人工神经网络算法能够自学习、自组织、自适应,灵活性很强.Singh等[8]设计了4层神经网络且通过反向传播算法来训练网络使得机器人在避开静态障碍物方面取得明显成效;Oscar等[9]为完善规划路径多项指标,设计了多目标遗传算法(multiple objective genetic algorithms,MOGA);王功亮等[10]在适应度函数中添加转弯角度控制因子,将路径最短和转弯角度作为适应度函数的影响因子,并证明了改进结果的有效性.蚁群算法在路径规划中存在前期路径有效性差且易陷入局部极小值的问题.Stutzle等[11]提出了最大最小蚂蚁系统(max-min ant system,MMAS),限制了路径上信息素的最大和最小值,可在一定程度上避免陷入局部最优解;杨洋等[12]提出了基于弹性时间窗和改进蚁群算法的多AGV避碰路径优化策略,改进了传统蚁群算法的启发式信息和信息素更新策略,提出了AGV任务优先级排序并改进冲突解决策略.粒子群算法在路径规划中易陷入局部极小点,收敛速度慢.Tang等[13]提出一种随机扰动自适应粒子群算法,通过微小扰动帮助粒子跳出局部极小点;Li等[14]将路径规划问题转化为考虑路径长度、碰撞风险程度和平滑度的多目标优化问题,在算法中引入自适应机制来选择最合适的搜索策略.智能搜索算法易陷入局部最小值且避障困难、学习效率低,在实际应用中效果不及强化学习算法.
用于AGV路径规划的强化学习算法主要包括值函数法和直接策略搜索法[15].Q-learning算法是典型的、最受研究者青睐的基于值函数的强化学习算法,它使AGV具有自学习的能力[16],但在动态连续环境中,由于数据量较大导致Q值表存储空间不足,存在维数灾难问题,并且在没有先验知识的情况下,算法的学习效率较低.Zhang等[17]在训练网络中引入贪婪搜索因子,弥补了没有先验知识的不足,提高了Q-learning算法的学习效率.Fakoor等[18]将模糊逻辑引入到强化学习算法中求解路径规划问题.于乃功等[19]提出了一种Q值表设计方法,并设计了适用于连续环境的R值和动作,实现了Q-learning算法的动态避障.张福海等[20]通过将障碍物与方位信息离散成有限个状态,从而设计环境模型与状态空间数目,同时使用连续报酬函数使算法的训练效率提高.为解决强化学习在路径规划中存在路径平滑度差和收敛速度慢的问题,徐晓苏等[21]提出在Q值初始化中加入人工势场来加快收敛速度,同时在状态集中增加方向因素使路径更加平滑,但没有涉及AGV如何处理障碍的问题.对此卫玉梁等[22]用径向基函数网络(radial basis function,RBF)逼近Q-learning算法的动作值函数,实现了AGV在行驶环境中的路障规避.强化学习算法的全局搜索与学习能力比传统算法与智能算法强,但也存在收敛速度慢、引导不足导致学习效率低等问题.
针对上述传统算法、智能算法与强化学习算法在AGV路径规划中收敛速度慢、学习效率低等问题,本文基于强化学习中的多步Q-learning算法,即Q(λ)算法,引入了启发式奖励函数与动作选择策略,以提升传统强化学习算法学习效率和收敛速度.利用启发式强化学习算法结合障碍地图环境,使智能体在不需要任何先验知识的前提下,通过训练不断调整自身行为,从而实现高效的路径规划.
1 强化学习路径规划算法总体思路
首先,采用栅格法对地图环境进行建模,用二维坐标表示地图中各个点的位置,并在地图中设置障碍物.其次,分别利用传统Q(λ)算法和改进的Q(λ)算法在地图环境中进行训练学习,通过不断试错与行为调整后,得出各算法的训练模型.然后,根据模型,分别再用传统的与改进的Q(λ)算法在相同的地图环境中进行自主学习,得出最终的规划路径.重复实验20次,同时记录每个算法的探索次数、路径总长度、路径规划完成时间以及路径总转角,以这些数据指标来判断改进后的Q(λ)算法是否比传统的Q(λ)算法存在一定的优势.
改进的启发式Q(λ)算法在路径规划时,先设置初始参数,通过启发式奖励函数实现对智能体每一步动作的持续性即时奖励,让智能体能够在即时的持续奖励中快速学习好的动作,提升算法收敛效率.其次,根据启发式奖励函数设计得到连续的Q值表后,针对ε-greedy探索策略,引入调和函数实现启发式动作选择策略,使得智能体能够弱化无价值的行为,强化高收益的行为,智慧地选择并执行高回报的动作,从而减少不必要的探索行为,加快寻径速度.本文强化学习路径规划问题的总体思路见图1.

图1 强化学习路径规划总体思路Fig.1 General idea of the reinforcement learning path planning
2 传统Q(λ)算法
强化学习算法中,智能体经过不断的更新迭代,与周围环境信息进行交互和作用,并依据环境信息进行自主的适应和调整,实现最大化奖励.获得累积最大化奖励所对应的动作选择策略构成智能体的最佳动作策略集.在实际的强化学习进程中,因为环境给予的信息毕竟有限,所以智能体必须在利用已有经验和知识的基础上,通过自身和环境的持续交互以及试错来进行学习,传统的强化学习框架如图2所示.

图2 强化学习基本框图Fig.2 Basic diagram of reinforcement learning
2.1 算法简介
由Watkins[23]提出的Q-learning算法实施步骤较为简便,具有较强的扩展性和适应性,同时不会受模型的干扰和影响,一直备受诸多学者的青睐.但在传统的Q-learning算法中,由于其数据的传输过程会有所滞后,算法每一次更新迭代都要进行整个过程的备份,相对来说比较繁复,收敛速度慢.针对此问题,在参考时间差分[24](TD(λ))思想的基础上,Q(λ)算法是在Q学习基础上提出的多步Q学习算法.
Q(λ)算法的思想主要来源于TD(λ)算法,核心与TD(λ)算法相类似,在原先的Q(λ)算法中首次应用了资格迹机制[25],使系统会自动对智能体访问的状态进行标识.Q(λ)算法在状态s执行动作a的价值函数迭代公式为
Q(s,a)=Q(s,a)+αδe(s,a)
(1)
式中:α为学习率;δ为Q值增量,即

(2)
式中:γ为折扣因子,一般取值为0.9;r为在不同情况下状态s采取动作a对应的奖励,即

(3)
式中m、n为正数.

(4)
式中:e(s,a)为资格迹;λ为学习步长.
最终输出使价值函数最大化的最优策略为
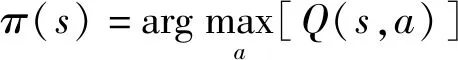
(5)
2.2 算法优缺点
Q(λ)算法结合了Q-learning和TD(λ)回报思想,利用将来无限多步的信息更新当前Q函数,并给出了基于资格迹的实现算法.Q(λ)算法主要依据状态对应的回报值选取相应动作,该查询二维表的方式存在以下不足:
1)Q(λ)算法要对状态及动作的Q值和相应的资格迹矩阵进行更新,当状态及动作空间规模很大时,计算量也很大,使得算法学习效率不高.
2)智能体在最初开始学习的过程中,对环境的认知是一片空白,不清楚什么动作是最佳策略.这时,如果奖励反馈是离散的,那么势必会使智能体在很长一段时间里处于任意状态,会浪费大量时间.
3 Q(λ)算法改进
针对Q(λ)算法存在学习效率不高、收敛速度慢、动作选择不稳定的问题,本文结合启发式强化学习算法,做了如下2个改进:
1)设计启发式奖励函数,引入启发因子D和E,根据不同状态与目标状态距离远近设计不同奖励值,为每一步动作计算生成不同奖励,得到持续奖励反馈,降低智能体的无效探索.
2)在传统动作选择策略的基础上增设调和函数G(st)以强化引导智能体的动作选择方式,使智能体更趋向于选择优质行为,进而提高其学习效率.
3.1 启发式奖励函数设计
一般的求解路径规划问题的传统强化学习方法,通常都会运用离散性奖励函数进行计算和模拟,具体的学习方式为:使智能体不断根据状态选择行为去执行,监测并掌握智能体相应获得的奖励信息,再通过奖励的反馈机制来对原有的行为进行改进和调整.由于智能体在最初开始学习的过程中,对环境的认知是一片空白,不清楚什么动作是最佳策略,这时,如果奖励函数是离散的,势必会使智能体在很长一段时间里处于任意的盲目状态,造成大量时间浪费.因此,应借助合理的途径和渠道把启发式思想与智能体的学习相结合,提升强化学习的效率和质量.针对这一问题,本文设计启发式奖励函数为智能体提供持续性的奖惩信息,使智能体能够更加高效地学习知识和经验.
在进行AGV路径规划时,从起点到终点移动智能体会经历许多不同的状态,这些状态的评价应该是不尽相同的.例如,通过一些先验领域的知识可以知道,当AGV所处的状态越接近终点状态,其获得的奖励值越大;反之,其获得的奖励值越小.因此,本文参考文献[26-27]的奖励参数设置并结合本文实验设计模式,将几种不同状态下的奖励情况定义为

(6)
同时,本文对地图环境信息进行特征提取,计算任意的当前状态所在位置的坐标与终点所在位置坐标的欧氏距离,计算公式为
(7)
距离D刻画了AGV当前状态与目标状态的差距大小,为奖励函数引入了启发因子.E代表了当前状态与地图边界及地图中障碍物的欧氏距离总和,反映了当前状态与惩罚状态的接近程度.D、E为奖励函数R的启发因子,启发式奖励函数R为
习近平总书记在中国共产党第十九次全国代表大会报告中指出:“要建立现代金融体系”;“健全金融监管体系,守住不发生系统性金融风险的底线”。 “校园贷”作为现代金融体系中不可忽视的一部分,在现实中却是一把双刃剑。进入校园后,一方面为在校大学生提供了便利的同时,另一方面也不断爆出各种负面新闻。根据媒体报道,因各种原因落入“校园贷”圈套的被骗学生已不在少数。及时发现高职院校“校园贷”中存在的问题,增强高职院校学生相关的法律观念和意识,抵制不良“校园贷”,防患于未然,对于高等职业人才的培养具有很强的现实性和迫切性。
(8)
为保证不对已有的奖励r产生较大的影响,不影响算法随机探索的特性,通过反复实验测试后,将c取值为0.6,d取值为0.4.
3.2 启发式动作选择策略
通常情况下,在同一环境的不断交互过程中,智能体可以通过持续的学习结果来修正Q值表的相应值,并查找、选择最佳策略以获取最大的回报函数.从另一个方面来说,智能体还须进行不同的尝试,探索开发新的路径和方法,对具体的搜索范围进行扩展,对陷入局部最优的情况进行有效的规避和应对.Q-learning算法大多采用ε-greedy探索策略来进行动作选择.ε-greedy是在贪心策略前提下进行完善和改进的探索策略,其主要意图是使智能体能够依据一定的概率来选择并执行相应的动作策略.当智能体进行具体的动作策略选择时,用概率ε选择随机动作策略,使智能体搜索到更多的状态空间;利用概率1-ε选取使得奖励函数取得最大值所对应的动作策略,从而实现周边环境信息和数据的最大化探索.具体的表达式为
(9)
式中p为(0,1)内的任意一个随机数,当这个随机数小于1-ε时,选择状态s对应奖励值最大的动作a,反之将随机选择下一个动作.
本文采用改进ε-greedy探索策略并结合启发式思想来共同决定智能体在学习过程中的动作选择策略,即在ε-greedy探索策略基础上新增了调和函数G(st).调和函数的主要作用为:在智能体进行动作选择的决策过程中,结合调和函数来分析动作策略,智能地调整每次决策对整体过程的影响,通过不断的尝试和实验,强化好的决策,弱化坏的决策,减少不必要的探索和行为,加快整个算法的收敛速度.改进后的搜索策略的探索分布式为
(10)
式中:Q(st,at)代表了某一状态st下的Q值;G(st)代表了该状态下的调和函数,其形式为
(11)
式中:xi为当前AGV所处位置状态的横坐标;xi-1为前一个状态下的AGV位置的横坐标;xend为AGV终点目标的横坐标;η为一个较小的正常数.本文实验设计中,AGV运行的起点和终点的横坐标是不相同的,故利用式(11)可以较好地度量AGV从初始状态到当前状态与终点状态的横坐标的距离接近程度.当G(st)的值为正数时,表明当前所执行的动作序列在横坐标方向上接近目标状态;当G(st)的值为负数时,表明当前的动作选择在横坐标方向上远离目标状态.
通过引入启发因子D、E和调和函数G(st),对传统Q(λ)算法在奖励函数设计与动作选择策略两方面分别进行改进,使得算法在整体学习效率上有了很大的提高,有效地减少了探索无效状态的次数,也减少了探索低收益动作的次数,从而加速了算法的收敛过程.启发式Q(λ)算法学习框架如图3所示.

图3 启发式Q(λ)算法学习框架Fig.3 Learning frame of heuristic Q(λ)algorithm
改进后的Q(λ)算法流程如算法1所示.
算法1改进Q(λ)算法流程
1)将Q初始化为0,同时给定α、γ、λ、ε、m、n的初始值.
2)随机选择初始状态s0.
3)根据启发式动作选择策略选择当前状态st对应的动作at,并由式(8)反馈得到这一动作的立即回报R(st).
4)结合式(1)~(3),计算价值函数Q(st,at),并从当前状态st过渡到下一个状态st+1.
5)不断重复执行3)和4),直到s状态为终止状态或达到最大迭代次数.
6)输出最优策略π(s).
4 仿真实验
为了验证启发式强化学习算法相比于传统强化学习算法在单AGV路径规划中具有一定的优越性,本文结合传统Q(λ)算法与改进的Q(λ)算法,基于MATLAB设计了AGV路径规划仿真实验,以验证本文提出的启发式改进策略的有效性.
目前,对地图环境建模的方法主要有可视图法[28]、几何法[29]和栅格法[30]等,其中栅格法应用简单,便于更新维护.实验采用的AGV运行地图环境为栅格化之后100 m×60 m的虚拟地图,AGV的尺寸为1 m2,每次所能执行的动作为上下左右每次移动一个单位长度,以栅格中心的坐标state(i,j)作为其位置信息(i、j分别为栅格中心的横、纵坐标),见图4.

图4 栅格坐标示意图Fig.4 Diagram of grid coordinates
参考文献[31-32]的相关实验参数设置,本文所采用的强化学习算法中的相关参数设置如表1所示.

表1 Q(λ)算法初始参数设置Table 1 Initial parameters of Q(λ)algorithm
4.1 实验结果
假设在栅格化的虚拟地图中,AGV分别以state(5,95)、state(5,45)及state(5,5)作为起始点,终点状态分别为state(95,5)、state(95,45)和state(95,95),并且在地图中设置3种障碍环境,命名为障碍1、障碍2和障碍3.首先,对传统Q(λ)算法与启发式Q(λ)算法在设有相同障碍的地图环境中分别进行学习训练,得到离散性Q值表与连续性Q值表,图5为在障碍1地图环境中训练得到的Q值表;然后,根据训练所得的模型,利用2个算法分别在障碍1、障碍2和障碍3的地图环境中进行20组全局路径规划实验,具有代表性的规划路径结果见图6~8,图中红色线表示障碍体.

图5 2种算法的Q值表对比Fig.5 Comparison of Q table between two algorithms

图6 障碍1环境下的2种算法路径规划结果对比Fig.6 Comparison of planned path between two algorithms in obstacle 1

图7 障碍2环境下的2种算法路径规划结果对比Fig.7 Comparison of planned path between two algorithms in obstacle 2

图8 障碍3环境下的2种算法路径规划结果对比Fig.8 Comparison of planned path between two algorithms in obstacle 3
传统Q(λ)算法与启发式Q(λ)算法分别在3种障碍环境中进行20组实验,得到4个主要性能指标数据均值,如表2所示.由表2可见,启发式Q(λ)算法比传统Q(λ)算法在探索次数、路径规划时间、路径长度、路径转角方面分别提升20.53%、16.31%、30.77%、50.00%.

表2 传统Q(λ)算法与启发式Q(λ)算法实验数据对比Table 2 Comparison of results between traditional Q(λ)algorithm and heuristic Q(λ)algorithm
此外,为进一步验证本文启发式强化学习算法的性能,结合本文实验环境,将本文算法与基于成功率搜索[33]的Q(λ)算法在障碍1环境下进行路径规划实验对比,此对比实验结果作为考量本文算法可行性的一个参考.具有代表性的基于成功率搜索的Q(λ)算法路径规划结果见图9.

图9 障碍1环境中基于成功率搜索的Q(λ)算法AGV路线Fig.9 AGV path of Q(λ)algorithm based on success rate search in obstacle 1
通过在障碍1环境下进行20次反复实验,得出基于成功率搜索的Q(λ)算法与启发式Q(λ)算法的主要性能指标均值,见表3.

表3 基于成功率搜索的Q(λ)算法与启发式Q(λ)算法实验数据对比Table 3 Comparison of results between Q(λ)algorithm based on success rate search and heuristic Q(λ)algorithm
4.2 实验结果分析
通过分析实验结果,可知:
1)通过设计启发性的持续奖励,使得AGV在每一个动作中都能获得不同程度的反馈.由图5(a)可知,离散性的奖励分布使AGV在很多时刻都是盲目且无序的状态,浪费了大量的寻径时间,而图5(b)中不同的持续奖励值可使AGV能更准确地判断哪些动作是有价值的且能判断每个动作的价值程度,便于提高AGV的学习效率.
2)结合图6~8和表2可知,通过设计启发式动作选择策略,使得Q(λ)算法规划出的AGV路径更加简短.相比于传统Q(λ)算法,启发式Q(λ)算法规划的路径长度减少了30.77%,路径转角减少了50%;结合图6(b)、图9与表3可知,与基于成功率搜索的Q(λ)算法相比,本文启发式动作选择策略在减少路径转角、简化规划路径方面具有一定的优势.可见,本文改进后的算法在很大程度上节约了AGV的能耗.
3)通过表2分析可知,在相同的障碍地图环境中,启发式Q(λ)算法的探索次数更少,提升了20.53%,减少的探索次数说明改进后的Q(λ)算法收敛速度更快,有效探索的比率更高.此外,相比于传统的Q(λ)算法,同等条件下,启发式Q(λ)算法能够节省16.31%的路径规划时间.假如将问题规模扩大,那么将会节约较大程度的时间成本.
5 结论
1)本文针对传统强化学习算法存在学习效率低、收敛速度慢的问题,在传统Q(λ)算法中引入启发式思想,设计启发式奖励函数,实现对智能体连续性动作的实时奖励反馈,从而优化奖励反馈机制,提升智能体学习能力与效率.
2)本文提出了基于ε-greedy探索策略和调和函数的启发式动作选择策略,使智能体能够在一定程度中和不佳策略,强化其有效探索,明显缩短智能体寻径时间.
3)本文引入并融合启发式思想以提升传统强化学习算法的学习效率与收敛时间,后续可进一步探讨多AGV动态障碍环境中启发式强化学习方法的可行性.
