基于粘连符号分割和多特征融合的手写公式识别
2021-08-05付鹏斌李建君杨惠荣
付鹏斌,李建君,杨惠荣
(北京工业大学信息学部,北京 100124)
字符粘连是影响数学公式正确识别的一个重要原因.自首次提出数学公式识别的概念以来,国内外研究者针对识别过程中遇到的粘连问题提出不同的解决方案:Strathy等[1]提出基于结构特征的分割算法,该算法利用字符结构上的特征点对粘连区域进行切分,但存在手写体字符特征识别不准确的问题.Vellasques等[2]、Tamhankar等[3]基于垂直投影,通过连接图像垂直投影的波峰和波谷得到一条切割粘连部分的路径,以此来实现切分粘连符号的目的.Congedo等[4]提出滴水算法,通过模拟水的滴落过程来切分粘连符号.Pal等[5]的储水区算法利用区域的大小和位置找到字符的粘连位置,但字符的阈值大小难以把控.以上几类常见的方法都只能针对水平结构的简单粘连符号进行裁切,无法解决具有复杂二维空间结构的粘连符号,而这类粘连符号一般包含着数学特殊符号,切分难度更大.随着深度学习的发展,Wang等[6]、Liu等[7]、Shan等[8]、Zhang等[9]提出基于编码-解码器框架的多模态注意网络来进行算式的识别,该方法通过端对端的方式规避了传统识别方法中的切分步骤,通过直接训练端对端的网络模型得到识别结果.但该方法需要大量标注数据用来训练模型,而手写数学公式空间结构复杂且种类繁多,难以标注,方法所需客观条件较难满足,达不到应用场景需求.
针对以上方法的不足,本文提出一种基于字符两侧轮廓轨迹特征的裁切方法来获取粘连符号的切分点和切分方向,同时结合字符的几何特性对切分后的字符片段进行多特征融合的特殊符号判别,最终使特殊符号与普通字符分离,达到切分粘连符号的目的.经实验验证,本方法能有效裁切具有复杂二维空间结构的粘连符号,同时无须大量数据训练模型,具有应用性广的特点.
1 公式图片预处理
脱机手写数学公式的识别应用场景多是实际的教学领域,公式图像的获取途径主要是拍摄设备拍摄或光学设备扫描.受光照等外界因素影响,需首先对公式图像进行预处理.具体步骤如图1所示.
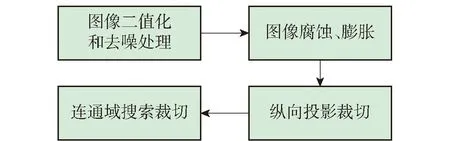
图1 图像预处理Fig.1 Image pretreatment
首先采用高斯阈值分割算法和高斯去噪算法[10]对原图像进行二值化和去噪处理;然后对图像进行腐蚀、膨胀操作[11],使字符之间的边界更加凸出;再进行纵向投影,将公式纵向地分为若干字符块,如图2中①;最后针对字符块进一步分割,如图2中②,采用八连通域搜索算法,得到多个单连通字符,在该步骤中包含对“i”“j”等由多连通区域构成的字符和“5”“θ”等容易写成孤立两笔的字符的合并处理,得到最终待处理的字符对象.

图2 字符粗切分Fig.2 Character rough-segmentation
经过纵向投影和连通域搜索裁切,能实现公式的基本分割,但手写公式中还存在字符粘连情况,如图3(a)所示,原图分离出的一个根式,其中根号与底数存在粘连点,不能有效分离;而在图3(b)(c)(d)中,也分别存在与分号、积分、求和这类特殊符号粘连的情况.这些特殊符号和数字字母之间存在半包围、上下重叠关系,右上角、右下角空间位置等复杂关系组合,用常规的裁切方法难以分隔.

图3 粘连符号示例Fig.3 Examples of adhesive characters
2 粘连符号的切分
2.1 粘连符号的检测
在对粘连符号进行裁切前首先需要进行粘连符号的检测.由于粘连符号的大小一般比同一公式中其余普通字符大,同时内部笔画数相对较多[12].利用这2个特点,提取出宽度、高度、黑白交替变化最大值3个特征来检测粘连符号块.
定义1自上而下(自左而右)逐行(列)扫描图像,统计每一行(列)像素点由黑到白的变化次数,最后取所有行(列)中最大值,该值即为黑白交替变化最大值.
如图4所示,该粘连符号的横向黑白交替变化最大值为虚线l3与图像的交点个数5,纵向黑白交替变化最大值为虚线l1与图像的交点个数2.
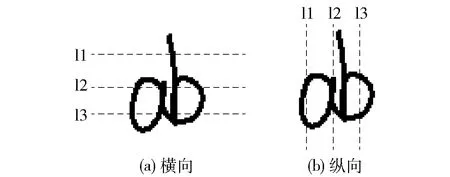
图4 横/纵向黑白交替变化Fig.4 Horizontal/vertical alternation of pixels
收集得到1 291条手写数学公式图片,其中存在粘连符号共199个.对收集得到的粘连符号的宽度、高度、横/纵向黑白交替变化最大值进行统计,并与原公式全体字符的平均高度、宽度进行对比.统计结果如表1所示.
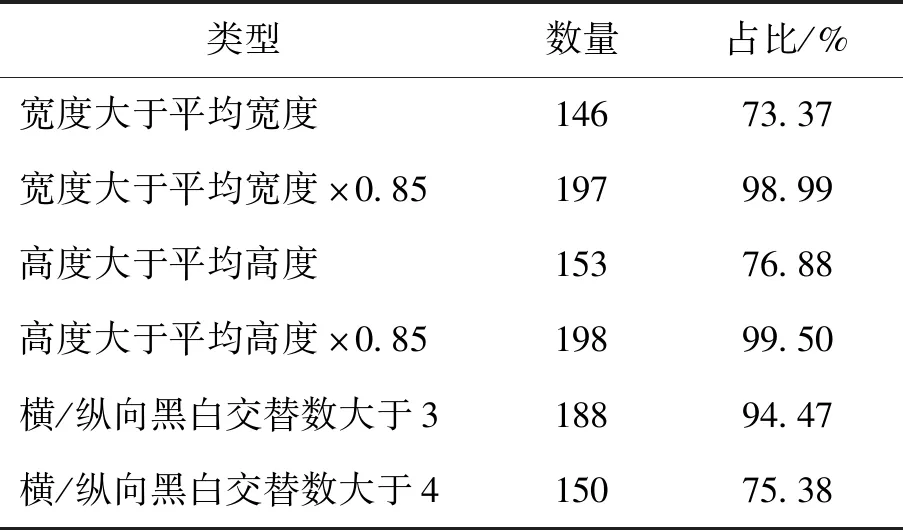
表1 粘连符号统计特征及数量Table 1 Statistical characteristics and quantity of adhesive characters
经过统计,98.99%以上粘连符号的平均高度或宽度都大于公式整体字符平均水平的0.85,94.47%以上粘连符号的横/纵向黑白交替变化最大值都大于3.由此,得到候选粘连符号的筛选流程,具体步骤如下:
首先,以原始图像的左上角坐标为坐标原点、坐标轴为X轴水平向右、Y轴竖直向下建立直角坐标系.遍历公式图片中所有单连通字符C1,C2,…,Cn,对每个字符Ci(1≤i≤n)循环其所有点Pi1,Pi2,…,Pim,每个点Pij包含该点坐标信息(xij,yij),据此得到每个单连通字符的高度Hi和宽度Wi分别为
Hi=max(yi1,…,yim)-min(yi1,…,yim)+1
(1)
Wi=max(xi1,…,xim)-min(xi1,…,xim)+1
(2)
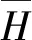
然后,统计得到所有单连通字符的横/纵向黑白交替变化最大值.横向使用一条水平直线从图像最上侧平移到图像最下侧,统计与字符的最大交叉点个数K1;纵向使用一条竖直直线从图像最左侧平移到图像最右侧,统计与字符的最大交叉点个数K2.
最后,遍历图片中所有单连通字符C1,C2,…,Cn,依次对每一个字符Ci(1≤i≤n)进行判断,若满足
(3)
则该字符为候选粘连符号.
2.2 轮廓双侧检测切分算法
对于粘连符号,粘连部位情况[13]见表2.
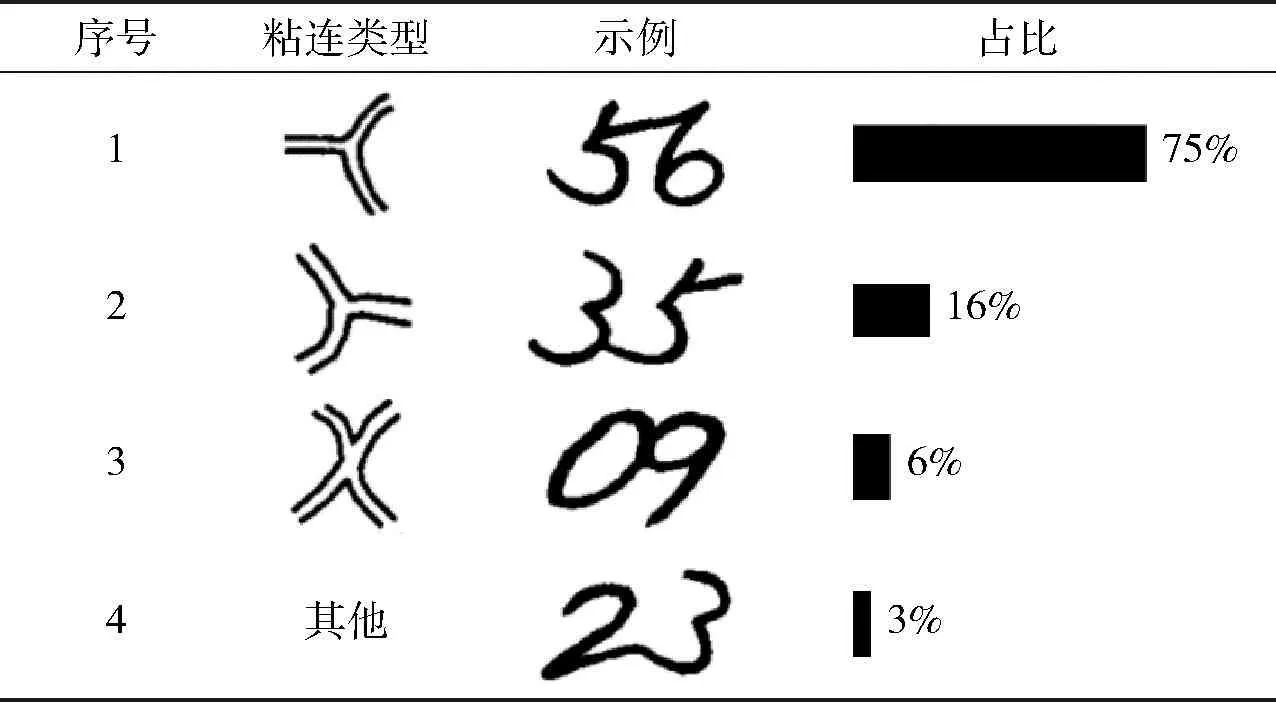
表2 粘连部位类型Table 2 Touching patterns
可见,对于绝大多数的粘连情况,在粘连点处两侧轮廓的变化趋势都会发生突变.
定义2从图像一端点出发,分别沿着该线的两侧行进,行进路线为2条由所有图像连续边界点构成的曲线.这2条曲线分别定义为图像内轮廓曲线、图像外轮廓曲线.如图5中表示的2条有向曲线.

图5 图像内/外轮廓曲线Fig.5 Inner/outer contour curve of image
如图6所示,顺着某一端点A的两侧轮廓出发,当未遇到粘连点S时,两侧轮廓的趋势是一致的,见图6中1与1′;而当遇到粘连点时,两侧轮廓的趋势发生变化,见图6中2与2′.
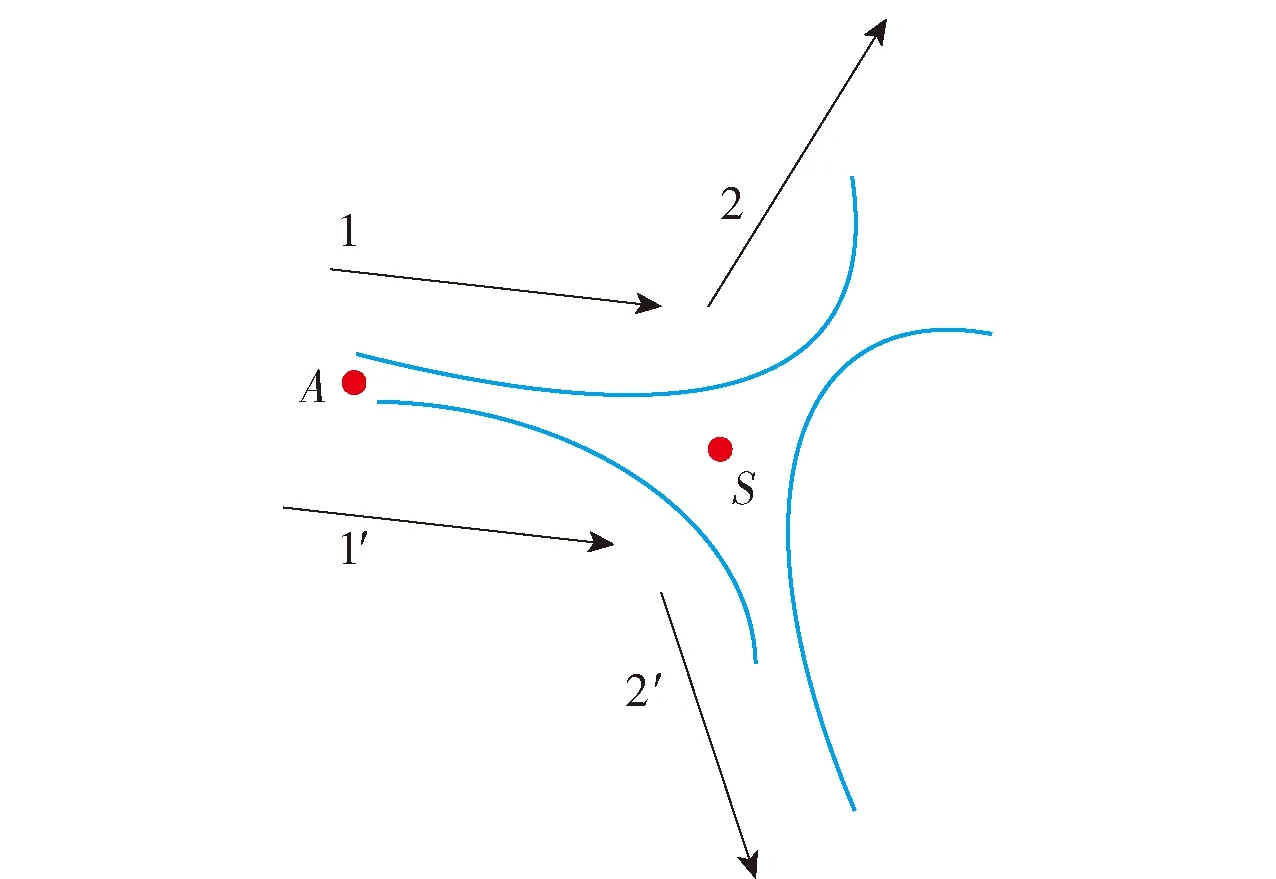
图6 粘连部位内外轮廓趋势变化Fig.6 Trend of adhesive regions’ inner/outer contour
根据这个特点,本文提出轮廓双侧检测切分算法,通过字符轮廓两侧的行进趋势变化来寻找粘连符号的粘连点,进而实现切分粘连符号的目的.主要分为以下几步:首先得到字符图像的端点,接着顺着端点得到所有轮廓点的邻接顺序,再沿着正反2条轮廓序列寻找粘连点,最后沿着粘连点进行裁切和组合以得到正确的裁切结果.具体步骤如下.
步骤1首先得到图像的外轮廓点和方向标记.对单连通字符图像的所有像素点进行遍历,判断其是否是轮廓点,轮廓点即为左右上下4个方向中任意一个方向所对应位置为空白的像素点.为了方便后续对轮廓点进行排序,这里对所有轮廓点定义其空白标记:对轮廓点4个方向按照上左下右的顺序进行遍历,若哪个方向最先出现空白位置,则该轮廓点的空白标记为该方向对应的标记,标记按照上左下右的顺序依次为1、2、3、4.
图7中外侧8个黑色像素块为1个单连通字符图像的外轮廓点,其中a、h、g三点的空白标记为1,b、c两点为2,d、e两点为3,f点则为4.

图7 方向标记Fig.7 Direction sign
步骤2得到单连通字符的轮廓点及其对应的空白标记后,接着利用空白标记来形成正确的轮廓顺序.空白标记的作用是,依据当前像素点的外围空白情况动态地调整搜索路径,以实现没有死循环、无重复路径、耗时最短地得到正确的轮廓点顺序.
首先随机选择一个轮廓点作为起点,并将其放入轮廓点顺序序列,随后进行路径的搜索,得到与该点相连的下一个轮廓点.搜索规则为:若当前轮廓点的空白标记为1,则搜索顺序为右上→右→右下→下→左下→左→左上,见图8(a);若当前轮廓点的空白标志位为2,则搜索顺序为左上→上→右上→右→右下→下→左下,见图8(b);若当前轮廓点的空白标志位为3,则搜索顺序为左下→左→左上→上→右上→右→右下,见图8(c);若当前轮廓点的空白标志位为4,则搜索顺序为右下→下→左下→左→左上→上→右上,见图8(d).按照以上搜索规则来获取第1个出现的轮廓点,将其放入轮廓点顺序序列,然后对该轮廓点执行相同的步骤,直到出现的新轮廓点为起点则搜索结束.经过以上步骤,得到轮廓点顺序序列〈P1,P2,…,Pn〉,n为轮廓点个数.
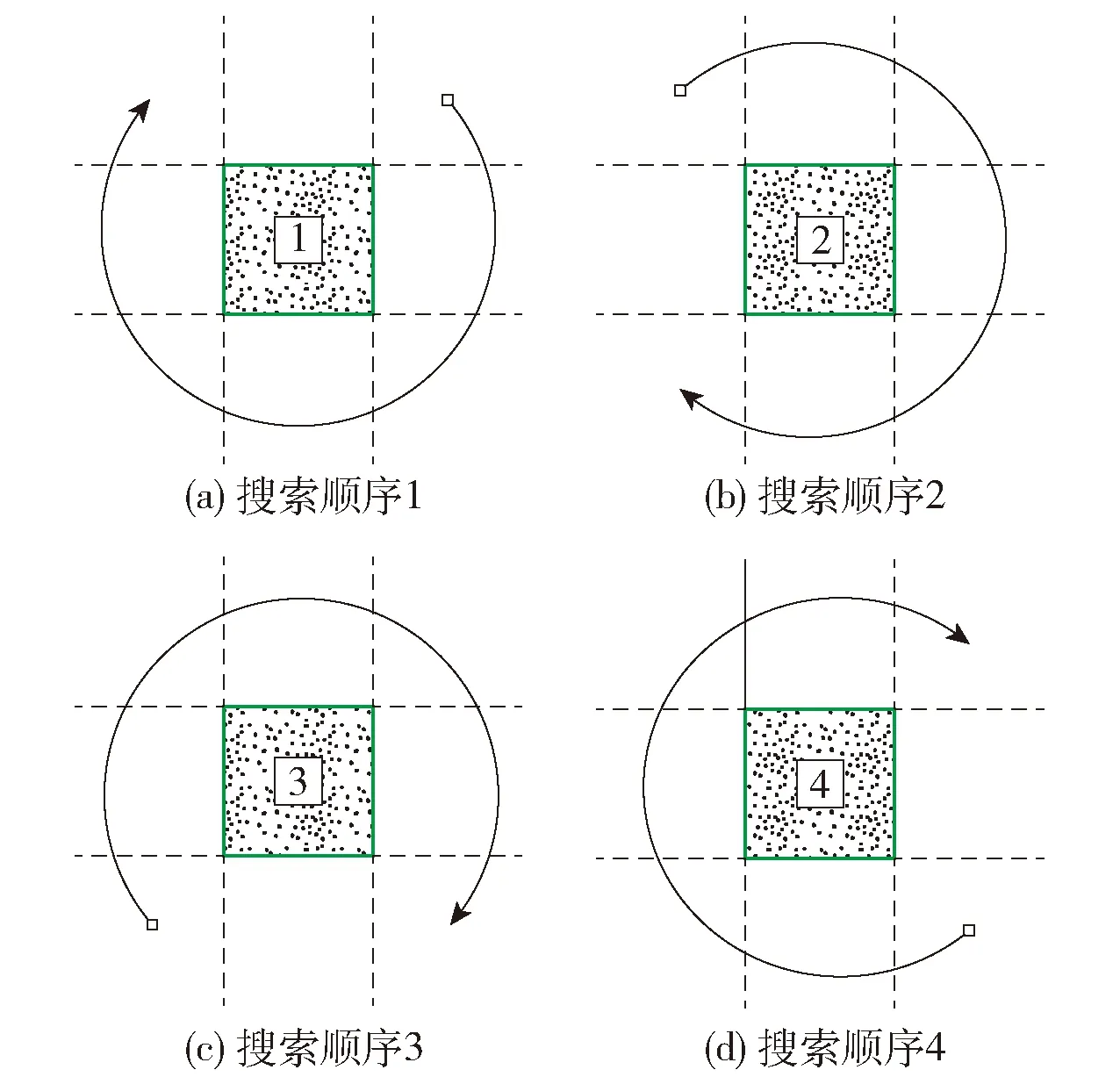
图8 轮廓点搜索顺序Fig.8 Searching order of outline points
步骤3接下来获取字符的所有端点,将它们作为本算法的出发点.端点的判定依据为:遍历图像的所有轮廓点,对每个点寻找其8个方向领域,若其领域内空白像素块的个数大于等于5,则可确定该轮廓点为端点,如图9中的字符共有7个端点,位置如箭头所示.得到字符所有端点后,对距离较近的端点进行合并,最终形成端点集合{D1,D2,…,Dk},k为端点个数.随机选择一个端点D1(假定在原轮廓点集合中为Pr)作为出发点,原轮廓点顺序序列〈P1,P2,…,Pn〉转化为〈Pr,Pr+1,…,Pn,P1,…,Pr-1〉.
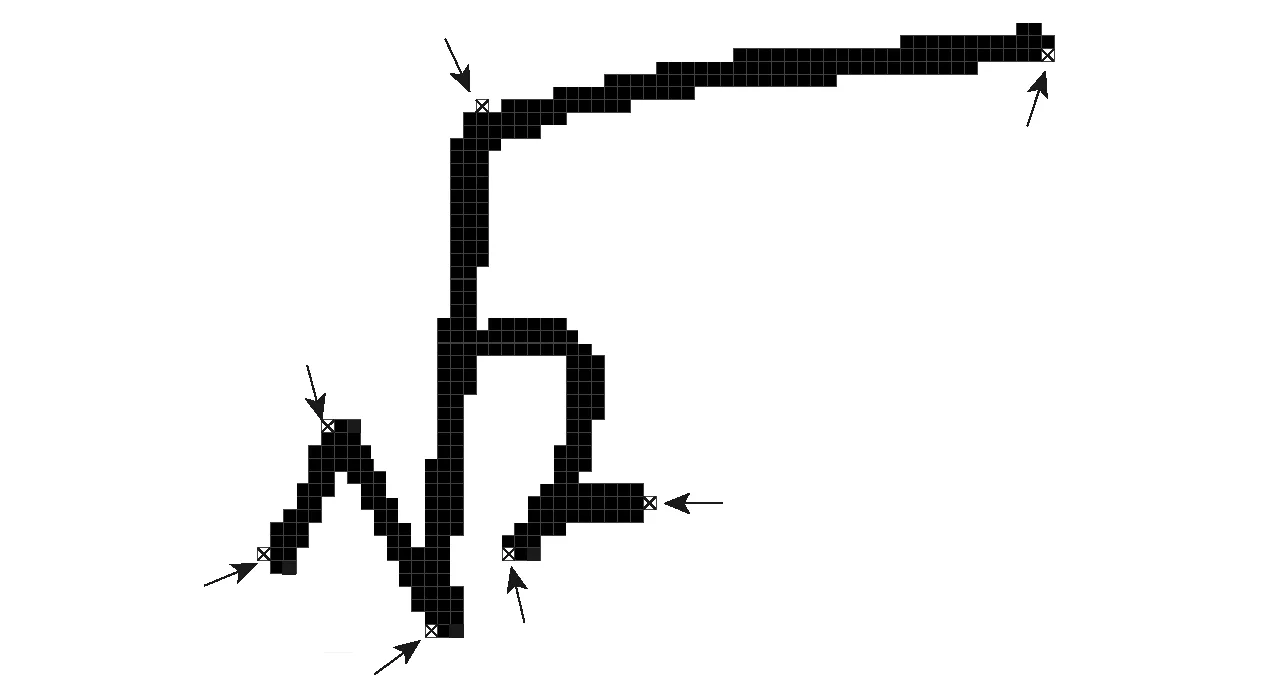
图9 端点Fig.9 Endpoint
步骤4经过步骤1~3,得到1条以P1作为起始点的图像轮廓点顺序序列〈P1,P2,…,Pn〉.再沿着起始端点向相反方向搜索,可得到1条与原序列相反的图像轮廓点顺序序列〈P1,Pn,Pn-1,…,P2〉.这2条序列分别对应图5(a)(b).
步骤5得到图像的正反轮廓点顺序序列后,计算图像的外轮廓方向链码.外轮廓方向链码的作用是表示图像轮廓点顺序序列的变化趋势,其计算方式为:依次遍历图像轮廓点顺序序列中的轮廓点,若下一个点在当前点的上方,链码为1;若在下方,链码为-1;若在右方,链码为2;若在左方,链码为-2.
步骤6通过步骤5中计算规则得到轮廓点链码序列〈R1,R2,…,Rn〉后,接下来开始寻找2个链码序列的突变点,并根据突变点将2个链码序列划分成若干子序列〈R1,R2,…,Ri〉,〈Ri+1,Ri+2,…,Rj〉,…,〈Rt,Rt+1,…,Rn-1〉,其中前后子序列的链码不一致,而每个子序列中的链码都相等.记录所有子序列的长度及链码,最终得到一个方向的轮廓趋势序列〈〈l1,s1〉,〈l2,s2〉,…,〈lm,sm〉〉(li为子序列的长度,si为对应的链码,si∈{1,-1,2,-2},i≤m).最后从前往后同时遍历2段轮廓趋势序列,若二者对应轮廓趋势子序列中的链码相等,且二者子序列长度的差值小于一定的阈值,则继续往后遍历;否则,2段子序列中发生突变的位置对应原图的点为候选粘连点,如图10(a)中切分点所示,结束遍历.若遍历结束,没有子序列满足上述条件,则该字符不是粘连符号.

图10 切分点与切分结果Fig.10 Cut point and cut results
若存在候选粘连点,根据正反轮廓趋势序列在该点处的链码,可得到2条切线.通过2条切线将原字符从粘连点处一分为三,切分结果见图10(b).
2.3 过切分合并
此时得出的是过切分结果,还需从切分出的3块子图中找出正确的组合,才能得到正确的字符图像.需对3块子图进行两两合并,见图11,对合并后的字符图像和单独子图,进行特殊符号的检测和识别.若存在特殊符号,则完成粘连符号的裁切任务;否则,从原图像另外一个端点出发,重复步骤4~6.若从所有端点出发都未能得到正确的切分结果,说明该字符图像中不存在特殊符号,后续按照普通字符的粘连情况处理.

图11 过切分子图组合Fig.11 Combinations of over-segmented subgraphs
3 公式符号的检测与识别
公式中存在2类符号:一类是大小、形状相对固定的普通数学符号;另一类是大小不固定、形状不规则的特殊符号,如根号、求和号、积分号等.无法用常规的算法对2类符号统一进行识别检测,因此将其从公式中正确剥离、提取识别至关重要.
3.1 多特征融合的特殊符号检测识别
本文结合宽度、高度、角点个数、投影轮廓、旋转对称等几何特性,对经2.2切分算法得到的过切分字符片段,经合并组合后进行特殊符号的识别检测.经统计[14],常见特殊符号包括以下4类:根号、分号、积分号、求和号.
3.1.1 根号的识别
根号由一条折线构成,其图像中存在3个突变点,如图12中箭头所示,被突变点分割的线段保持固定的斜率,而前后线段的斜率发生较大的变化.根据这种斜率趋势的变化,采用上轮廓投影斜率作为根号的判别特征.
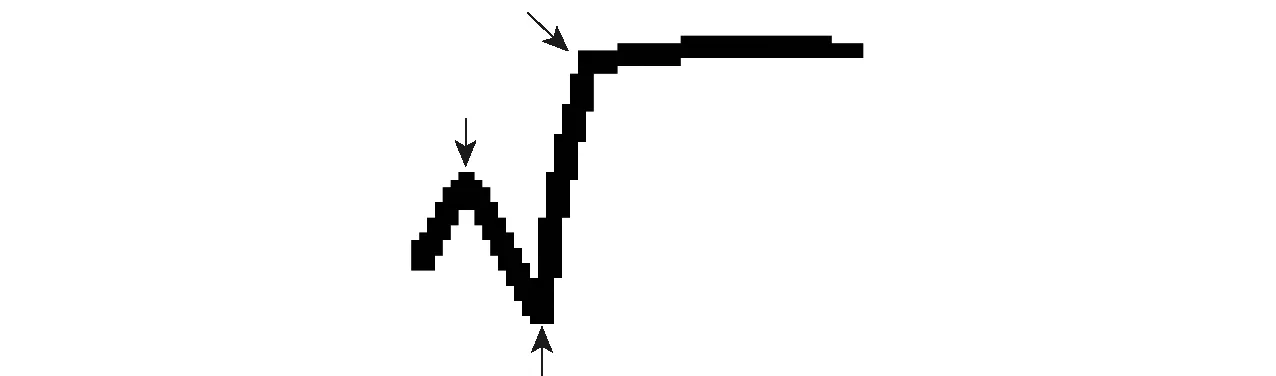
图12 根号及其突变点Fig.12 Diagram of radical and its breakpoint
定义3自上而下逐列扫描图像,由每列的第1个黑色像素点组成的轮廓曲线称之为上轮廓投影,见图13.上轮廓中后一点与前一点的高度的差值为上轮廓投影斜率,见图14.
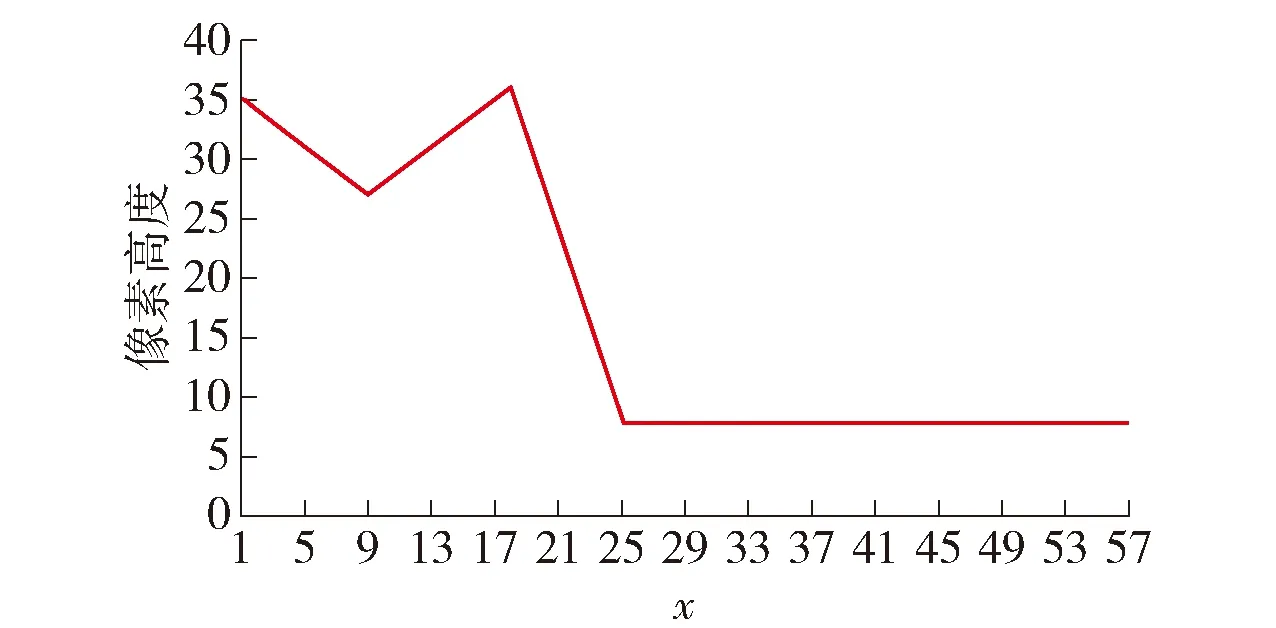
图13 上轮廓投影Fig.13 Upper contour projection

图14 上轮廓投影斜率Fig.14 Slope of upper contour projection
由此可得根号的识别算法步骤如下.
步骤1算法输入:字符图像image.
步骤2从左到右依次从图像顶端向下垂直作投影,记录其与每一列相交的第1个黑色像素点对应的高度值hi,并最终依次合并,形成上轮廓点序列L:〈h1,h2,…,hn〉.
步骤3遍历上轮廓点序列L,对序列中的值进行两两相减得到斜率ri=hi-hi-1,最终合并所有斜率得到上轮廓斜率序列S:〈r1,r2,…,rn-1〉.
步骤4对上轮廓斜率序列S进行预处理,在不影响局部变化趋势的前提下对干扰点进行抹平.
步骤5遍历上轮廓斜率序列S,记录斜率突变点i及其前后段的斜率大小.若满足以下2种情况之一,则点i为突变点:1)后段斜率ri与前段斜率ri-1之积小于0;2)前段斜率ri-1小于0同时后段斜率ri与前段斜率ri-1之差小于等于2.
步骤6统计突变点的个数R,并将突变点i的横纵坐标xi、yi及其前后段斜率ki-、ki+按照横坐标递增的顺序排列,得到突变点信息序列L:〈〈x1,y1,k1-,k1+〉,〈x2,y2,k2-,k2+〉,…,〈xR,yR,kR-,kR+〉〉.若突变点信息序列L同时满足以下几项,则可判定该字符图像为根号:1)突变点的个数R等于3;2)3个突变点的横坐标满足x1
步骤7输出识别结果result.
3.1.2 分号的识别
分号是一条较长的水平直线,此处使用上轮廓斜率序列S:〈r1,r2,…,rn〉、宽高比θ、纵向黑白交替变化数N来作为分式判别的特征.
若图像同时满足以下条件,则该字符被识别为分号:1)宽高比θ≥2;2)纵向黑白交替变化数恒为1;3)上轮廓斜率稳定,保持在0左右.
3.1.3 积分号的识别
积分号具有旋转对称的特点,即将图像的下半部分从几何中心处旋转180°,其与图像的上半部分大致重叠,见图15(a).同时积分号一定宽度范围内的点的斜率满足先增大后减小的规律,见图15(b)中虚线范围内的点a、b、c、d,满足ka
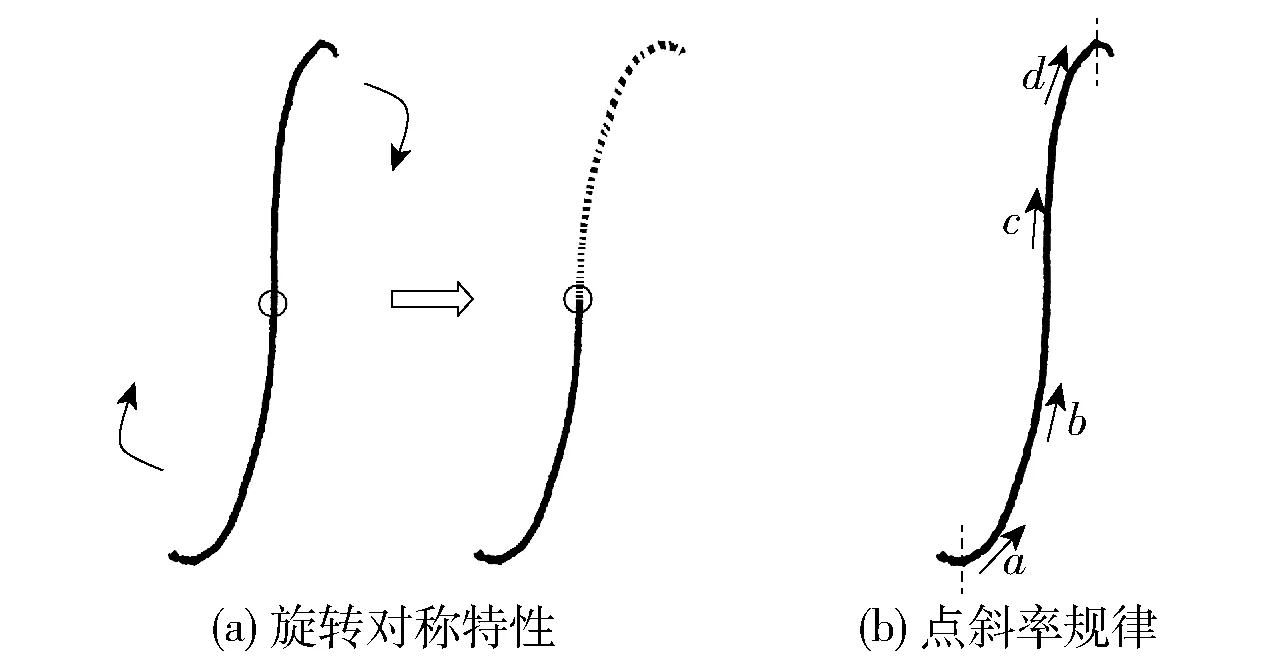
图15 积分号部分特征Fig.15 Some features of integral sign
3.1.4 求和号的识别
求和号中存在一个宽度界限,在该界限范围内纵向黑白交替变化数恒为4.同时,该范围内的图像可被划分成如图16(a)的3个区域,3个区域内的纵向空白像素长度的变化满足递增或递减的规律,如图16(a)中①③区间的纵向空白像素长度从左到右依次递增,而②区间的纵向空白像素长度从左到右始终递减.

图16 求和号部分特征Fig.16 Some features of summation sign
求和号的笔画都是笔直的线段,线段的交叉点较为明显,这类点被称作角点,如图16(b)中的a、b、c、d、e五点都是角点.求和号的角点个数N及其相互位置关系满足以下规律:1)N=5;2)xa>xc,xb>xc,xd
3.2 普通字符识别
经统计,数学公式中常用数学普通符号类型如表3所示.

表3 常用数学符号Table 3 Common mathematical symbols
针对普通字符,采用卷积神经网络模型[15]进行识别.网络模型包含2个卷积层、2个池化层和2个全连接层.网络模型见图17.
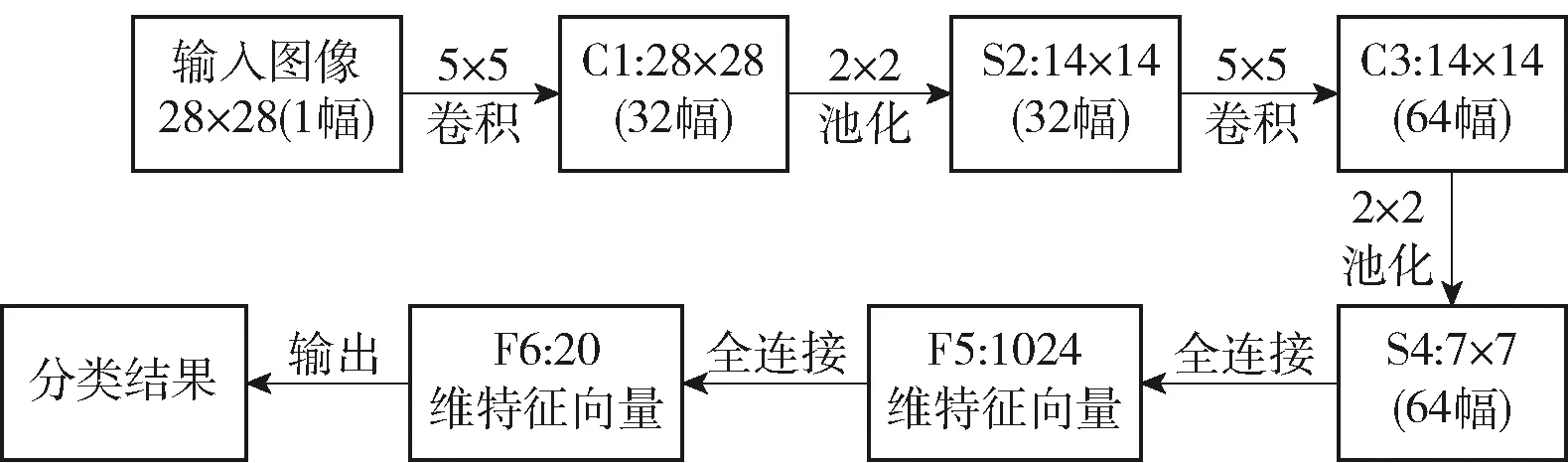
图17 卷积神经网络模型Fig.17 Model of convolutional neural network
经过模型训练,单字符的识别率达到了98.85%,达到了预期目标.错误的原因主要是几类易混字符的误判,如1和l、a和α.
4 结构解析与整体公式识别
经过前面的裁切与识别,得到单个数学公式中所有单字符的识别结果.本文利用数学特殊符号与其相邻字符位置关系进行公式的语义解析,以实现公式的整体识别.
特殊结构中一般包含如下特殊符号:根号、分号、积分号、求和号.它们与周围普通字符之间的位置关系见图18.

图18 特殊符号及其周边位置关系Fig.18 Position relations between special symbols and their surrounding characters
这4类复杂结构加上上下标结构构成了数学公式中需要结构解析的主要部分.针对这几类复杂结构,本文提出各自的解析算法.
以下算法是整体结构的解析算法,用于判断对某结构使用什么具体的解析算法.
输入:一个字符块的单字符识别列表[P1,P2,…,Pi,…,Pn].
输出:识别结果result.
步骤1循环遍历[P1,P2,…,Pi,…,Pn],若字符Ci的识别结果Pi为根号、分号、积分号、求和号,执行相应解析规则,得到解析结果r,并放入结果result中.执行步骤2.
步骤2遍历检查列表中未被解析的剩余字符.若列表中剩余字符无4类特殊符号,则解析完毕,执行步骤3;否则,执行步骤1.
步骤3返回识别结果result.
4.1 根式解析算法
根据根号与其底数构成半包围、与其指数构成左上右下的空间位置关系,提出根式解析算法解析步骤.
输入:Pi被识别为根号的单字符识别列表[P1,P2,…,Pi,…,Pn].
输出:识别结果result.
步骤1判断根号Pi前是否存在其他字符.若Pi前存在其他字符,则执行步骤2;否则,该根式的根指数为2,根指数字符串n默认为空,执行步骤3.
步骤2对Pi前的字符进行筛选,根据根指数分布在根号左上角的位置和根指数字符串的大小小于根号的大小这2个特点,得到根指数字符列表[P1,P2,…,Ps],其中s≤i-1.然后递归地解析根指数字符列表,得到根指数字符串n.执行步骤3.
步骤3对Pi后面的字符进行筛选,根据根底数在根号半包围结构中的特点,得到根底数字符列表[P1,P2,…,Pt],其中t≤n-i,对根底数字符列表递归解析,得到根底数字符串a.执行步骤4.
步骤4合并根号、根指数n和根底数a这三部分,result=[sqrt,a,n].执行步骤5.
步骤5返回识别结果result.
4.2 分式解析算法
由分子、分母分别位于分号正上方、正下方的空间位置关系,可提出以下解析步骤:
步骤1首先对单字符识别列表进行循环筛选,根据分子、分母与分号的位置关系分别得到分子字符列表[P1,P2,…,Ps]和分母字符列表[P1,P2,…,Pt],其中s+t≤n-1.
步骤2分别递归地解析2个列表,得到分子字符串a和分母字符串b.
步骤3合并得到解析结果[/,a,b].
4.3 积分解析算法
根据积分号与上、下底数构成左下右上和左上右下的空间位置关系,提出以下解析步骤:
步骤1遍历积分号Pi后所有字符,筛选得到区间下界字符列表[P1,P2,…,Ps]和区间上界字符列表[P1,P2,…,Pt],其中s+t≤n-1.
步骤2若积分号Pi没有积分区间,则区间上界字符串a和区间下界字符串b皆为空;否则递归解析区间下界字符列表和区间上界字符列表,得到解析后的结果a和b.
步骤3合并得到最终解析结果[int,a,b].
4.4 求和解析算法
由求和上标、下标分别位于求和号正上方、正下方的空间特点,可提出以下解析步骤.
步骤1遍历求和号后所有字符,筛选得到下标字符列表[P1,P2,…,Ps]和上标字符列表[P1,P2,…,Pt],其中s+t≤n-1,上下标的筛选标准是:下标字符位于求和号的正下角,上标则位于求和号的正上方,同时上下标字符的大小都小于求和号的大小.
步骤2筛选完毕后,若该求和号没有上下标,则上标字符串a和下标字符串b皆为空,否则递归解析上下标字符列表,得到解析后的结果a和b.
步骤3合并得到最终解析结果[sum,a,b].
4.5 整体公式识别
对于没有特殊结构的数学公式,可以按照从左到右的顺序对单字符的识别结果进行直接合并.如图19中的普通数学公式,经过前面一系列步骤得到单个字符的识别结果[’2’,’a’,’×’,’3’,’b’,’=’,’4’,’c’],接下来直接合并得到最终识别结果字符串“2a×3b=4c”.
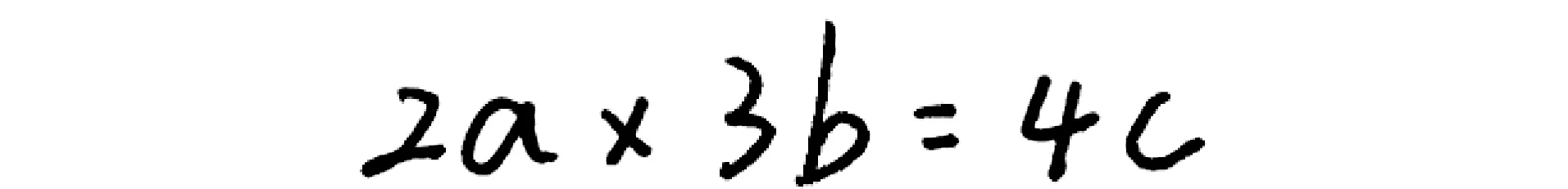
图19 普通公式Fig.19 Regular formula
而对于含有特殊结构的算式,先使用前几小节中的解析规则对结构进行解析,将复杂算式结构解析完毕后,再将整体进行合并.若公式较为复杂,包含多个嵌套特殊结构,则使用树形结构来递归地进行解析,见图20.首先根据垂直投影将公式切分成若干子图,再依次对子图进行解析:若当前子图中没有特殊结构,则直接合并单字符形成识别结果;否则根据各个特殊结构的特点,解析成特定的形式,若其中仍存在特殊结构,则继续递归地往下解析,直到所有的特殊结构都解析完毕,最后从下往上合并,形成公式的识别结果.

图20 复杂公式解析树Fig.20 Parse tree of complex formula
5 实验结果与分析
本文测试数据根据来源分为4类:第1类采自中学学生答卷中真实的手写数学公式图片,第2类为实验室课题组师生手写的公式,第3类为CROHME2019离线数学公式数据集[16]中包含有根号、分号、积分号和求和号的公式图片,第4类为NIST19手写字符串数据集中的部分普通文本粘连数据.下文中统一以简写学生数据、实验室数据、CROHME2019数据和NIST19数据来分别指代这4类手写数据.表4中给出了各类数据的数量,其中普通粘连字符的含义是指仅由数字、英文或普通数学符号构成的粘连字符,特殊粘连的字符是指粘连部分包含分号、根号、积分号或求和号这4类数学特殊符号的粘连字符.
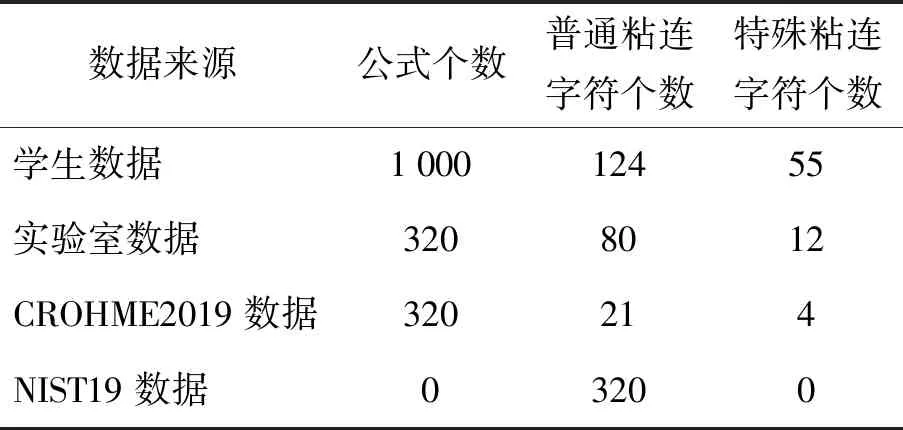
表4 测试数据Table 4 Test data
部分测试图片见图21,其中(a)为学生书写的数学公式图片,(b)为实验室课题组师生手写的数学公式,(c)为CROHME2019离线数学公式数据集中的公式图片,(d)为NIST19手写字符串数据集中的粘连字符串图片.

图21 部分测试数据Fig.21 Sometest data
本文设计了2组实验,一组验证本文轮廓双侧检测切分算法的裁切效果,另一组验证添加该算法后公式整体的识别效果.本文引入了切分正确率(CR)、公式识别率(RR)、公式第二识别率(SRR)[17]和运算时间4个评价指标来作为评判标准,部分数学定义为
(4)
(5)
(6)
式中:CN表示正确切分的粘连符号个数;WN表示粘连符号的总数;RN表示完全识别正确的公式个数;SRN表示最多只有一个字符被识别错误的公式个数;AN表示公式总数.由定义可知,CR越大,粘连字符被正确裁切的比例越高,裁切算法的裁切效果越好;RR、SRR越大,整体公式被正确识别的比例越高,公式整体识别的效果越好.
5.1 轮廓双侧检测切分算法的裁切效果实验
本组实验中,将本文提出的裁切方法与滴水分割算法[18]、垂直投影切分算法[19]及基于马尔可夫随机场的切分算法[20]分别进行了对比,实验结果见表5、6.表5中,数据1、2、3分别指代学生数据、实验室数据和CROHME2019数据中的全体粘连字符.CR表示切分正确率,定义如式(4)所示.表6中,测试数据为NIST19手写字符串数据集中的普通粘连字符.
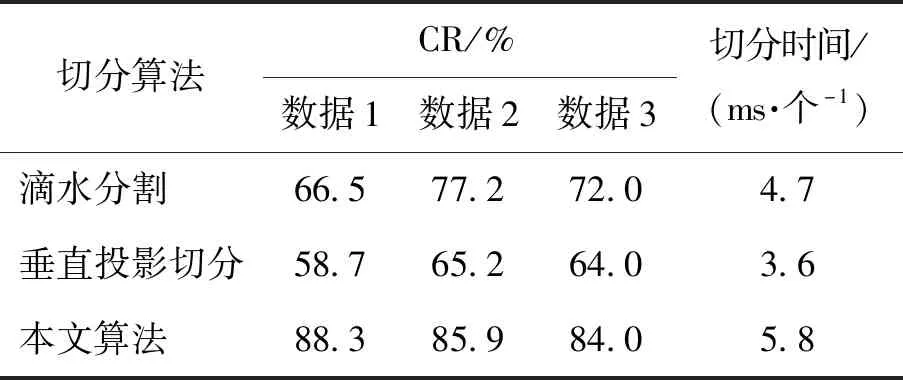
表5 数学粘连字符切分对比实验Table 5 Segmentation contrast experiment of mathematical touching characters
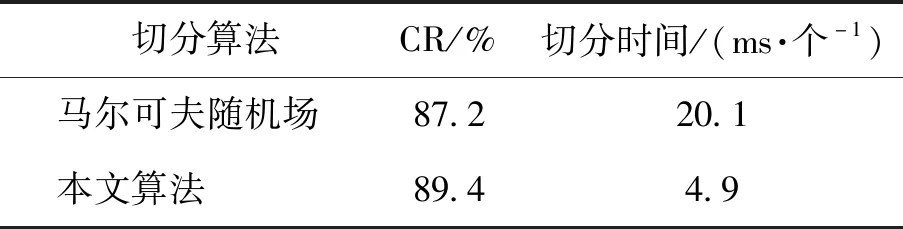
表6 NIST19粘连字符切分对比实验Table 6 Segmentation contrast experiment of NIST19 touching characters
从表5可以看出,滴水分割算法对公式的切分效果好于垂直投影算法.而本文算法由于考虑了公式中特殊字符的特征,效果明显优于前2种算法.对表5中的3类数据结果进行纵向对比,实验室师生数据的切分正确率最高,中学生数据次之,CROHME数据最低,印证了切分效果的优劣与数据本身的潦草、粘连程度相关性大.
对普通粘连字符的处理,本文轮廓双侧检测切分算法实际是滴水分割算法的延续,文献[20]中的基于马尔可夫随机场的切分算法,其适用范围也是不含特殊公式符号的普通字符串.因此,将本文算法与文献[20]中的普通粘连字符串裁切效果进行对比实验,由表6可知效果基本一致.
在切分速度方面,本文算法对于单个数学粘连符号和普通粘连符号的平均切分耗时见表5、6最后一列,分别为5.8、4.9 ms左右,远小于马尔可夫随机场切分算法耗时,比滴水分割算法稍慢,证明了本文算法的效率.
5.2 公式识别效果实验
第2组实验是对手写数学公式的整体识别率实验.分别在学生数据、实验室数据和CROHME2019数据上进行,从第一识别率(RR),第二识别率(SRR)及识别时间上,验证本文所提手写公式识别方法的有效性.部分公式的识别效果如图22所示,实验整体结果如表7、8所示.

图22 数学公式识别结果Fig.22 Recognition results of mathematical formula

表7 公式整体识别实验Table 7 Formula recognition experiment
由表7可知,在公式整体的识别率上,本文手写公式识别策略对中学生数据和实验室师生数据整体识别正确率较高.在允许1个字符被误识的条件下,识别率分别达到90.4%和94.1%.单个公式的识别平均时间82.5 ms,对于一张包含20个公式的图片的识别时间在1.6 s左右,处于可接受的范围.但对于CROHME2019公式数据集,本文手写公式识别策略不是很理想,整体公式的第一识别率和第二识别率分别为58.1%和63.1%.与参加CROHME2019脱机数学公式识别竞赛[17]相比,前面还有几支队伍成绩较好,本文整体公式识别率位于中下游,如表8所示.分析原因,本文方法重点考虑对特殊数学符号的正确切分和特殊符号识别率的提高,而忽视了模型对其他普通单个字符识别率的提升,因此,公式中任何一个字符的识别错误,都会导致整体公式的识别错误.数据集方面,本文一直采用在校中小学学生的手写数据进行实验,没有针对CROHME2019数据集进行研究,而CROHME2019中的单个字符书写方式与学生手写数据差别很大,也降低了整体公式的识别率.
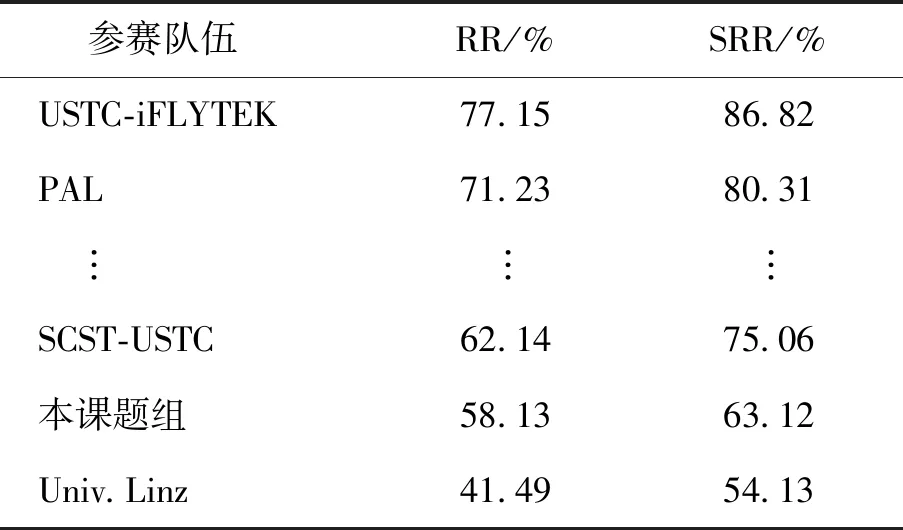
表8 CROHME2019竞赛结果对比Table 8 Comparison of CROHME2019 results
6 结论
1)实验表明,本文的轮廓双侧检测切分方法可以有效切分具有复杂二维空间结构的粘连符号,弥补了传统裁切方法的不足.根据特殊符号与普通符号形态上的差别,并采用多特征相融合的方式,可有效实现特殊符号的正确判别.根据特殊符号与周围字符的空间位置关系,可得到整体公式结构的解析结果,实现数学公式的自动识别.
2)针对整体公式在CROHME2019数据集上识别率不高的问题,本文通过改进模型,提高了对CROHME2019数据集中部分普通单字符的识别率,效果比较明显,公式整体识别率也得到提升,但受限于算力,没有做完整的实验.后期实验可在继续优化识别特殊公式符号的基础上,做单个字符的识别率的提升,从而提升公式的整体识别率.
