融合用户兴趣漂移的Top-N推荐算法
2021-08-04刘浩翰马晓璐贺怀清
刘浩翰,马晓璐,贺怀清
(中国民航大学计算机科学与技术学院,天津 300300)
当今时代,互联网技术的蓬勃发展促使大量庞杂无序信息的快速更迭,使得用户兴趣变幻不定,难以捉摸。因此,如何利用用户兴趣漂移的规律准确建模,向用户进行满足时间漂移特性的推荐,正成为目前个性化推荐研究中的热点和难点。
基于矩阵分解的推荐算法是推荐领域成熟、高效的算法,对用户和项目信息中的隐含结构进行建模能够挖掘更深层次的用户和项目关系。Koren 等[1]认为隐式反馈信息有助于用户的偏好建模,从而提出了基于奇异值分解的SVD(sigular value decomposition)++方法,但该方法是基于用户兴趣和项目属性是静态的假设,与现实不符。Koren[2]又提出了使用时间信息的Time SVD++(temporal dynamics at SVD++)方法,把4 类随时间变化的用户和项目因素建模成时间函数,得到了很好的推荐效果,但该模型的计算成本很高,也不能够预测用户未来的行为。Steffen 等[3]提出的BPRMF(Bayesian personalized ranking matrix factorization)算法是基于贝叶斯后验优化的个性化排序算法,针对两个项目的相对偏好排序进行建模,最终为每个用户计算其负例项目的偏好排序。尽管矩阵分解非常有吸引力,但没有明确考虑数据的时间变化,因此,更多研究者关注于使用循环神经网络(RNN,recurrent neural network)来建模推荐系统中的时间动态,且获得了高质量的推荐效果。Wu 等[4]提出了基于RNN 进行时序性建模,考虑到时间序列数据和现实中的因果关系,严格按照评分发生的时间顺序划分数据集,根据历史评分数据预测将来的用户偏好。Hidasi 等[5]提出的GRU4Rec(four gated recurrent unit for recommendation)是将RNN 运用于基于会话的推荐,单纯地使用门控循环单元对用户的项目序列进行训练,而没有考虑到项目本身的动态性。
为了兼顾用户的长期兴趣和短期兴趣漂移,提出一种新的推荐算法,以长短期记忆网络(LSTM,long short term memory)为核心,使用矩阵分解对用户的长期兴趣进行建模,通过LSTM 基于当前趋势预测用户未来的短期兴趣,将注意力机制纳入LSTM 隐藏状态的表示中来捕获用户长短期兴趣的关系,从用户历史行为数据中获取用户长期兴趣对短期兴趣的不同影响,并在两个公开数据集上通过与其他流行算法比较分析验证该算法的有效性和准确性。
1 推荐算法模型构建
用户的兴趣可分为即时变化的短期兴趣和相对稳定的长期兴趣。基于LSTM 对用户短期兴趣漂移建模,用矩阵分解的固定向量来表示用户的长期兴趣,并加入注意力机制来获取用户长期兴趣的隐向量因子对短期兴趣的影响。最终为用户生成一个Top-N 推荐列表(Top-N recommendation)。方法的整体结构如图1 所示,共分为模型输入、矩阵分解、构建加入注意力层的LSTM、模型输出并生成Top-N 推荐列表4 步,具体描述如下。

图1 用户兴趣漂移推荐模型Fig.1 Recommendation model of user′s interest drift
1.1 用户的短期兴趣
用户近期的交互数据反映了用户当前时期的兴趣变化,因LSTM 特殊的结构,可以根据时序数据的历史信息获取其动态变化的特征来预测未来状态,因此使用LSTM 对用户近期的历史行为数据进行建模。
1.1.1 用户短期兴趣表示
定义用户集合U={u1,u2,…,um}和项目集合V={v1,v2,…,vn},且|U|=m,|V|=n由此可以生成1 个稀疏的用户-项目评分矩阵R∈Rm×n,评分矩阵R中的每项rij,t表示在时间步长t用户ui给项目vj的打分,将评分rij,t视为用户ui和项目vj在时间步长t的相关性。Pui t∈Rn表示给定用户ui∈U在时间步长t的评分向量,xuivj,t =r表示用户ui在时间步长t给项目vj的评分为r,则用户ui的评分序列可以表示为。假定用户ui在时间步长t的短期兴趣可以从近期时间内获得,则用户ui在时间步长t内的短期兴趣变化(从0 到t)可以表示如下

在现实中,不仅是用户的兴趣会随时间变化,项目的属性也会随时间变化,因此,对项目也采用相同的处理方式。Qvj t∈Rm表示给定项目vj∈V在时间步长t的评分向量,表示项目vj在时间步长t被用户ui评分为r,则项目序列可以表示为。项目在时间步长内的短期属性变化为


式中:Wa∈Rm×D和Wb∈Rn×D分别是用户和项目的参数投影矩阵;D是低维稠密向量的维数;τt表示对每个时间步长t的评分向量提取的特征向量。
1.1.2 长短期记忆网络
基于RNN 的推荐算法可以根据用户的历史状态预测未来的行为,使用RNN 的主要目的是捕获用户和项目的时变状态[6]。RNN 中的LSTM 可以充分利用历史信息提取到用户和项目的最新状态。LSTM 由1个存储单元ct、1 个输入门it、1 个遗忘门ft和1 个输出门ot组成,这些门根据前一时刻的隐藏状态ht-1和当前输入xt计算得出

式中:σ 是激活函数;W 是隐藏层之间的权重矩阵。
存储单元ct的更新一部分来自丢弃现有的信息,另一部分是新的候选向量的加入

LSTM 单元更新后,t 时刻的隐藏状态就变为

因此,t 时刻的LSTM 的隐藏状态更新为


式中,hui,t和hvj,t分别表示用户ui和项目vj在时间步长t 的隐藏状态。由此可获得用户的短期兴趣表示。
1.2 用户的长期兴趣
对于用户的长期兴趣和项目的静态属性使用矩阵分解算法。矩阵分解把用户和项目都映射到一个K维空间上,每个用户和项目都对应一个隐向量,用户隐向量代表用户的长期兴趣,而项目隐向量则表示其自身被关注的静态属性,用户和项目隐向量的内积就是用户的长期兴趣,即

式中:Vj∈RK为项目vj的隐向量;Ui∈RK为用户ui的隐向量;bui是用户ui的兴趣偏置;bvj是项目vj的属性偏置。
1.3 用户长短期兴趣关联
用户的长短期兴趣有一定相关性。用户的长期兴趣很大程度上决定了其短期兴趣,而用户的短期兴趣也有可能发展为稳定的长期兴趣。注意力机制可高效地在众多信息中获取任务目标最关键的信息,因此,加入注意力机制来获取用户长期兴趣的隐向量因子对短期兴趣的影响[7-9]。
在t 时刻,对于RNN 的当前隐藏状态,通过计算当前隐藏状态与目标状态的对齐可能性,得到每个隐藏状态的权重系数,然后对其进行加权求和,即可得到最终注意力分配概率的分配数值。
注意力机制的具体计算过程可分为两步,第1 步是计算目标状态中各元素的匹配权,即
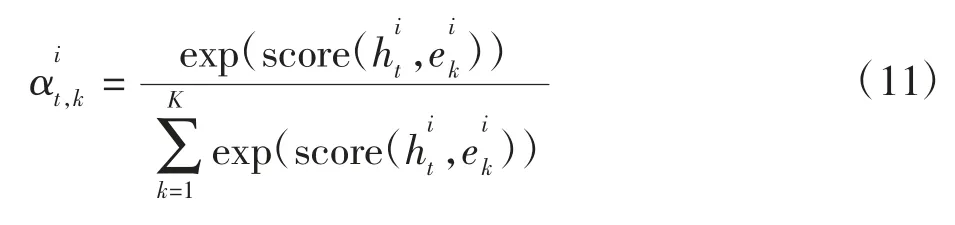

具体地,针对研究的问题,首先将hui,t-1和hvj,t-1输入到激活函数中得到的结果sui,t-1和svj,t-1作为hui,t-1和hvj,t-1的隐含表示

式中:Wc、Wd为神经网络中的权重矩阵;bc、bd为偏置项。
αui,t和βvj,t分别是用户ui和项目vj在时间步长t的归一化权重矩阵,代表用户长期兴趣和项目静态属性中每个隐向量因子的权重,元素表示如下

式中:K 是用户和项目隐向量映射空间的维数;σ 是激活函数。
用cui,t和cvj,t分别表示时间步长t 的用户ui和项目vj的上下文向量,即用户长短期兴趣之间的联系。上下文向量cui,t和cvj,t更新LSTM 隐藏状态的输入计算来确保每个时间步长中LSTM 都能获得完整的上下文信息,计算如下

通过上一时间步长的隐层状态获取的上下文向量来更新当前隐层状态,计算如下
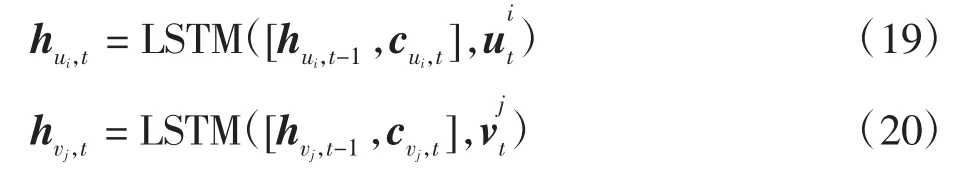
1.4 用户长短期兴趣模型
前两节中已经获取了用户的长期兴趣和短期兴趣,将最终的打分函数定义如下
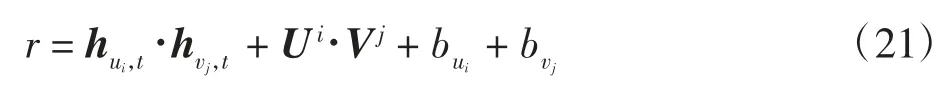
式中:hui,t和hvj,t为通过式(19)和式(20)得到的用户ui和项目vj在时间步长t由LSTM 学习到的隐藏状态,内积hui,t·hvj,t表示用户和项目的动态相关性;Ui和Vj是通过式(10)得到的用户ui和项目vj全局隐向量,内积Ui·Vj是用户ui和vj项目的静态相关性;bui是用户ui的兴趣偏置;bvj是项目vj的属性偏置。
将得到的打分函数rij,t经过Softmax 函数得到最终用户ui和项目vj相关性的概率函数P(ui,vj|t),用来表示项目vj在时间步长t出现在用户ui的项目列表中的概率,即

采用Pairwise 方法来生成排名[10-11]。对于每个用户ui,为其提供一个已标注的项目集合Vn={〈vj,vk〉|vj>vk},vj>vk表示vj比vk有更大的相关性,vj来自用户项目的正例集合,vk是针对每个正例vj的负例集合进行采样得到的负样本。损失函数使用交叉熵来平衡正负样本的分布差异,计算如下

式中:n是项目个数;yj表示用户ui与vj项目是否发生交互,对于项目vj∈V,如果项目确实存在于真实数据集中,则yj=1,否则yj=0。Θ 表示模型中所有需要学习的参数,Θ={U,V,Wa,Wb,Wc,Wd,bc,bd,bui,bvj}。参数选用L2 正则化项控制模型的复杂度,防止模型过拟合。
2 实验评估
2.1 数据集和参数设置
为了验证模型的有效性,在ML-100K 和Yelp 两个真实数据集上进行实验,如表1 所示。将整个数据集依据时间划分训练集和测试集,给定时间步长分别析取出用户和项目的交互序列来模拟需要预测未来评分的实际情况。

表1 数据集统计特征Tab.1 Statistical characteristics of datasets
ML-100K 和Yelp 的矩阵分解向量维数K分别设置为15 和20,LSTM 的神经元个数为40,嵌入层向量维数D=10,采用7 d 的时间粒度,时间步长t=4,由此将1 mon 的用户交互序列作为1 次会话输入,正则化参数λ=0.2,采用随机梯度下降(SGD,stochastic gradient descent)算法优化参数,学习速率为0.001。
2.2 评估指标
为了评价模型的推荐效果,以准确率、平均倒数排名(MRR,mean reciprocal rank)、平均精度均值(MAP,mean average precision)和归一化折损累计增益(NDCG,normalized discounted cumulative gain)作为推荐结果的评估指标。准确率反映了用户喜欢的项目命中的概率,MRR、MAP、NDCG 都反映了推荐结果中用户喜欢的项目的占比和排名情况。
1)准确率

式中:Relu是测试集中用户u的项目集合;Recu是推荐给用户u的Top-N 推荐列表;K表示Top-N 推荐列表中取前K个项目。
2)平均倒数排名

式中Rank(u)是用户u的Top-N 推荐列表中第1 个命中的项目的排名。
3)平均精度均值
首先计算每个用户的平均精度

式中:I 为用户u 的Top-N 推荐列表中命中的项目集合;Rec(u,v)是项目v 在用户u 的Top-N 推荐列表中的排名;Rel(u,v)是测试集中项目v 在用户u 的项目集合中的排名。
然后对所有用户的AP 求均值,即

4)归一化折损累计增益

其中

式中,Reli表示项目是否命中,取值为0 或1;K 表示Top-N 推荐列表中取前K 个项目。
DCG 反映了Top-N 推荐列表中推荐结果中命中的项目排名情况,推荐结果中与真实数据集(测试集)相关性强的项目排名靠前的推荐效果越好,DCG 越大。IDCG 是理想化的DCG,即返回最好的推荐结果,即
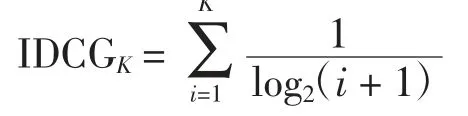
2.3 实验及结果分析
为评估提出的用户动态行为建模算法,实验分为算法对比实验和模型参数实验。前者选取了3 个推荐算法BPRMF、GRU4Rec、RRN 与所提算法的推荐结果进行比较,后者对所提算法在时间划分的不同方式对推荐结果的影响进行了测试。
2.3.1 算法推荐性能对比
实验中在两个数据稠密度不同的数据集上采用P5、P10、NDCG5、NDCG10、MAP、MRR 评估算法,实验重复10 次,采用平均值作为最后的实验结果,如表2 所示。

表2 算法推荐性能对比Tab.2 Comparison of recommending performance of algorithms
由表2 可看出,所提算法在各个指标的综合性能上都要优于其他算法。BPRMF 虽然引入了最大后验估计假设提高了用户个性化推荐效果,但本质上还是矩阵分解算法,是以用户和项目状态都是静态属性为前提。GRU4Rec 虽然利用了时间信息对用户的点击行为进行建模,但仅考虑了用户的兴趣会发生漂移,而忽略了项目的状态也随时间动态变化。RRN 综合考虑了用户和项目的状态都随时间动态变化,对两者分别建模,但是建模方法较为粗糙,没有考虑到用户和项目状态的长短期关联性。而所提算法结合用户和项目的动态和静态属性,并通过注意力机制平衡长短期属性的相互制约,高效地对用户和项目状态进行了动态建模。
2.3.2 时间划分对推荐结果的影响
所提算法是基于用户最近时期的交互数据来获取用户的兴趣漂移,时间粒度和时间步长对算法性能有重要的影响。因此进行了两项测试,一是时间粒度相同,不同时间步长对算法性能的影响,如图2 所示(对于ML-100K 数据集,时间粒度相同,时间步长分别取1、4、6、10、12);二是相同时间窗口,不同时间步长和时间粒度对算法性能的影响,如表3 所示。
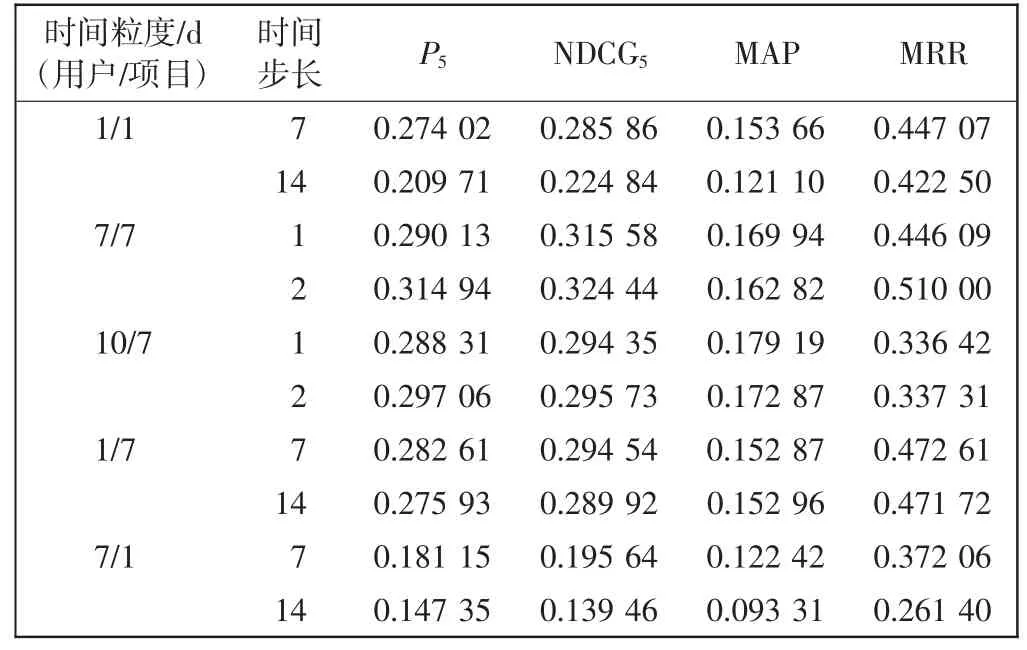
表3 时间粒度和时间步长对推荐结果的影响Tab.3 Recommendation results with different time granularitites and time steps

图2 时间步长对推荐结果的影响Fig.2 Recommendation results with different time steps
由图2 可知,时间步长取值对推荐结果有重要影响。实验结果表明随着LSTM 中输入的时间信息增多,推荐精度也在升高,但是训练时间也相应在增加,所以需要权衡时间开销和推荐精度。
由表3 可知,在每个时间步长内时间粒度的划分会使推荐结果大不相同。在相同时间内采用较小的时间粒度结果较差,这是由于时间划分过细,在每个时间步长内获取的序列信息较少,LSTM 没有充分的序列信息去学习,从而无法获得用户和项目动态变化的趋势。用户和项目采用不同的时间粒度,项目采用较大的时间粒度推荐结果比时间粒度小时要好,这是由于项目的属性相对较稳定,一定时期内变化较小,对时间粒度划分不敏感,时间范围扩大时才能体现出项目的动态变化,而用户的情况则相反,由于用户的兴趣变化较频繁,采用较大的时间粒度会使推荐精度下降。
3 结语
基于LSTM 的推荐算法通过对用户和项目状态的静态和动态建模,增强了算法对用户兴趣的理解能力,引入了注意力机制增强了模型对用户和项目静态和动态属性时间关联性的捕捉,在两个真实数据集上进行的实验,结果表明,所提算法能够有效改进推荐结果,满足用户个性化需求。
