一种基于元学习框架的时间序列预测方法
2021-08-04李睿峰吴忠德戴金玲王树友
李睿峰,吴忠德,戴金玲,王树友
(海军航空大学, 山东 烟台 264001)
1 引言
时间序列预测(time series prediction,TSP)是机器学习领域一个重要而活跃的研究课题,在许多实际数据挖掘应用中具有不可缺少的重要性[1]。时间序列数据广泛存在于水文(河流水位)、天气(降雨量)、金融(股票走势)和军事装备健康管理(早期故障预示)等各个领域。例如,飞机发动机系统的状态预测,对排除早期故障、降低维护成本、提高系统稳定性和安全性具有重要意义。
常用于解决TSP问题的机器学习方法主要有人工神经网络[2-3]、支持向量机[4-5]以及相关向量机[6-7]等,这些方法在各自应用领域取得了较为理想的预测结果。Huang等[8]提出的超限学习机(extreme learning machine,ELM)因其快速的计算速度、突出的全局近似能力,已被广泛应用于处理包括TSP在内的复杂非线性问题[9-10]。Huang等[11]利用核方法对ELM进行扩展,提出了核超限学习机(kernel extreme learning machine,KELM),文献[12-15]将改进的KELM扩展到了在线学习领域。
总体来看,上述用于解决TSP问题的方法都只采用了单一预测器模式,但是根据NFL定理,并不存在一种算法对所有的任务都适用。Yao[1]分析指出,将集成学习方法应用于解决TSP问题具有比单个模型更优良的性能。这类方法在TSP问题中的应用包括神经网络线性集成框架[16]、ELM改进层集成架构[17]等。同时,为了降低集成学习的空间复杂度,集成选择技术[18-20]更受研究者青睐。该技术的核心在于定义基预测器的性能评价准则,以挑选出最能“胜任”当前预测任务的一组预测器进行组合决策。但是集成选择技术在处理TSP问题时存在一些固有缺陷:① 当前已被提出的评价准则具有很大的局限性,为特定TSP问题确定恰当的评价准则难度较大;② 虽然动态集成选择灵活性较强,但是为每个样本动态选择基预测器的方式,无形中增加了算法时间复杂度。
元学习领域的叠加归纳策略主要思想是将基本学习器分布在多个层次上,采用多层学习器来完成学习任务。这一方法在分类领域应用广泛,典型结构为“基分类器-元分类器”形式的分层集成模型。元分类器并不试图挑选出最优的基分类器,而是对基分类器的结果进行“再学习”,以纠正错误分类、巩固正确分类,使元分类器的准确度优于所有基分类器。但是这类方法在TSP领域的应用尚未明确,且如果将之用于TSP任务存在2个问题有待解决:① 算法的时效性,能否实时跟踪时间序列;② 基预测器中存在对于当前任务的预测“能力”较弱者,对全部基预测器的结果进行再学习无疑会降低最终决策的可靠性。
综上,本文改进了分层集成模型,以适应时间序列预测任务的时效性要求;在此基础上增加了优化选择过程,以控制模型规模,并消除预测能力差的基预测器的不利影响。在此基础上提出了一种基于元学习框架的时间序列预测方法(time series prediction method based on META-learning,META-TSP)。首先,以KELM为基预测器,采用相空间重构之后的训练数据对基预测器进行训练;然后,将基预测器对验证数据的预测结果作为元数据对元学习器进行训练,并通过BPSO算法,以均方根误差为适应度函数对基预测器进行筛选;最后,将相空间重构之后的测试数据输入到训练好的模型中,预测其输出。实例分析表明,本文方法在保证时效性前提下能够有效提高预测的准确性和稳定性,适用于解决时间序列预测问题。
2 算法基础
2.1 核超限学习机
给定数据流S={(x1,y1),(x2,y2),…},其中xi∈Rd表示输入向量,d∈N+是xi的维数,yi是与xi对应的输出值,则ELM模型定义为[8]:
(1)
式(1)中:β=[β1,…,βL]T是模型输出权重向量;h(xi)=[h1(xi),…,hL(xi)]表示隐层神经元对输入样本xi的映射向量;ξi表示对应于第i个样本的训练误差;c是正则化参数,并且c∈R+。基于KKT优化条件求解式(1)的优化问题,可得输出权重为:
β=HT(c-1I+HHT)-1y
(2)
式(2)中:yt=[y1,…,yt]T是输入样本对应的目标值向量;H=[h(x1)T,…,h(xt)T]T是输入样本的映射矩阵。应用Mercer条件定义核矩阵Ω=HHT,Ω(i,j)=h(xi)·h(xj)T=k(xi,xj),可得ELM的核化形式为:
(3)
式(3)中:kt是当前时刻的核估计向量,并且有kt=[k(·,x1),…,k(·,xt)];θt=[θ1,…,θt]T是t时刻的核权重向量,且θt=(c-1I+Ωt)-1yt。
应用KELM解决TSP问题具有以下优势:① 算法层次结构简洁高效,需要的时间和空间开支少,更能满足TSP问题的时效要求;② 无需像ELM一样设置映射函数和隐层神经元数量,降低了模型的随机性,仅通过核函数设置即可完成算法优化,而核函数的设置范围,相比ELM算法的映射函数和隐层神经元选择范围要小得多。
2.2 二进制粒子群优化算法
粒子群优化(PSO)算法以其简单的寻优模式和较低的计算代价,是目前最常用的进化算法之一,BPSO作为PSO算法的离散二进制版本,已被证明在多目标选择领域具有优良的性能[22]。由于本研究涉及到了基预测器的选择过程,因此采用BPSO算法,以最小化均方根误差为目标,挑选出预测能力最强的一组基预测器。
步骤1:初始化。按照种群大小,在搜索空间中随机初始化粒子位置和速度。计算适应度函数值,初始化粒子的个体最优位置和全局最优位置。设置最大进化代数及其他终止条件。
步骤2:更新粒子速度。粒子速度公式为:
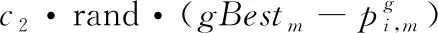
(4)
式(4)中:pBesti={pBesti,1,…,pBesti,M}表示第i个粒子访问的最优位置;gBest={gBest1,…,gBestM}表示考虑到整个粒子群的全局最优位置;ω对应于惯性权值,通常设置为1;c1和c2是加速度系数,rand是在0和1之间随机产生的数字;g是进化代数。
步骤3:更新粒子位置。BPSO算法采用传递函数将粒子速度映射到[0,1]区间,作为粒子位置变化的概率。传递函数通常采用sigmoid函数s(x)=1/(1+e-x),粒子位置更新公式为:
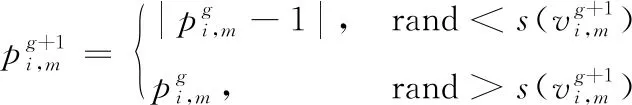
(5)
步骤4:更新适应度函数。利用当前粒子位置信息计算适应度函数值。
步骤5:更新单个粒子最优位置和粒子群全局最优位置。如果满足终止条件,则输出最优解;否则,返回步骤2。
3 META-TSP方法
3.1 方法机构
META-TSP方法通过改进分层集成模型来构建元学习机构,并采用BPSO算法对基预测器进行优化选择,具体可细分为3个阶段:基预测器训练阶段、元学习器训练阶段和测试阶段,如图1所示。该方法将训练数据分为2个子集:训练集DTr和验证集Dval。

图1 META-TSP机构框图
3.1.1基预测器训练阶段
基预测器训练阶段用来训练产生M个基预测器,从训练集DTr中随机抽取样本子集,通过为KELM设置不同的核函数和核参数,每一个样本子集用来训练生成一个基预测器。
由试验数据可知,对于同1个试验温度测点,5次测量的温度值会有波动,当温度波动大于0.2 ℃时,传热系数K值的测量值会出现明显的波动[9].具体数据如表6、表7所示.
3.1.2元学习器训练阶段
首先,使用上一阶段训练产生的M个基预测器对验证集Dval中的样本进行预测,预测结果作为元特征,每一个基预测器都对应着一个特征维度,元特征为M维;以验证集Dval中样本的实际输出为元目标,元特征与元目标共同构成元数据。然后,调用BPSO算法,以均方根误差为适应度函数,对元特征进行优化选择(实际上是对基预测器进行筛选)。最后,利用特征约简后的元数据训练一个元学习器。该阶段的伪代码如下:


3.1.3测试阶段
对于测试样本xtest,首先使用M个基预测器对其进行预测,得到元特征;然后根据上一阶段的特征选择结果对元特征进行约简;最后将约简后的元特征输入到上一阶段训练好的元学习器λ中,得到最终预测输出。该阶段的伪代码如下:

3.2 复杂性分析
下面对META-TSP方法3个阶段的复杂性进行简要分析。
在基预测器训练过程中,假设训练子集的大小为S1,该阶段训练产生M个基预测器,时间复杂度为O(S1·M)。元学习器训练阶段,假设验证集的大小为S2,使用M个基预测器对验证集进行预测,时间复杂度为O(S2·M);BPSO优化过程中,元学习器训练并预测gmax+1次,由于该过程对元数据进行约简,故时间复杂度不超过O(S2·(gmax+1))。测试阶段,假设测试集的大小为S3,P′的尺寸为M′,使用P′对测试集进行预测,时间复杂度为O(S3·M′);元学习器预测过程的时间复杂度仅为O(S3)。
一般来说,训练数据的规模(即S1+S2)不会太大,通过控制基预测器池的大小M和最大进化代数gmax,即可提升算法的时间效率。因此,该方法可以满足时间序列实时预测需求。
4 实验分析
4.1 实验设置
4.1.1算法设置
基预测池由11个KELM构成,用到的核函数包括线性核、多项式核、高斯核,正则化参数C设置为10,线性核不需要设置其他参数,多项式核的参数设置为{[1,2],[1,3],[-1,2],[-1,3]},高斯核的参数设置为样本间最大欧式距离和最小欧式距离间随机选取的6个离散值(调用dd_tools工具箱的scale_range 函数实现)。
所有算法均在MATLAB 2018a上运行,实验电脑配置为:Windows 10操作系统,Inter Core i7-7700HQ CPU,2.80 GHz主频和8G RAM。
4.1.2参数设置
简便起见,实验同样采用了KLEM作为META-TSP方法的元级学习器,核函数采用RBF核,并通过网格搜索法确定最优参数。FOKELM、NOS-KELM和FARF-OSKBIELM方法的参数均与文献[15]一致:高斯核,核参数σ=10,时间窗m=50;FOKELM和NOS-KELM的正则化参数C=2×104,其余参数见文献[15]。DES-PALR算法首先需要定义测试样本的局部区域,与文献[20]相同,该区域使用k-means聚类算法得到,聚类数设置为4;DVP-OpOp算法需要设置验证集的大小,实验中取训练集尺寸的10%;DES-CP算法沿用文献[20]的设置,采用遗传算法生成基预测器子集,子集总数n取10。
4.1.3评价指标
在TSP问题的研究中,通常从计算复杂性、预测精度、预测稳定性等3个方面来评价算法的性能。计算复杂性指标包括训练时间和测试时间,预测精度指标通过均方根误差(root mean square Error,RMSE)来衡量,预测稳定性指标可以从最大绝对预测误差(maximal absolute prediction error,MAPE)和平均相对误差率(mean relative error rate,MRPE)角度来度量。计算公式为:
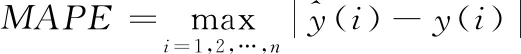
4.2 非平稳Mackey-Glass 混沌时间序列预测
本节首先验证算法对Mackey-Glass混沌时间序列预测的有效性。该序列可以通过以下非线性时滞微分方程得到。
取a=0.2,b=0.1,τ=17,x(0)=1.2,当t<0时,x(t)=0,步长Δ=0.1,通过4阶Runge-Kutta方法解方程,在此基础上,加上正弦曲线0.3sin(2πt/3 000),以得到新的时间序列。设置采样间隔Ts=10Δ,规定时间嵌入维数等于10,由此获得了与文献[14-15]完全相同数据集,包含1 191组样本数据,前991组用于训练,后200组用于测试。
6种对比算法和本文方法的预测曲线如图2所示,预测结果如表1所示,各项指标的最优值均加粗表示。
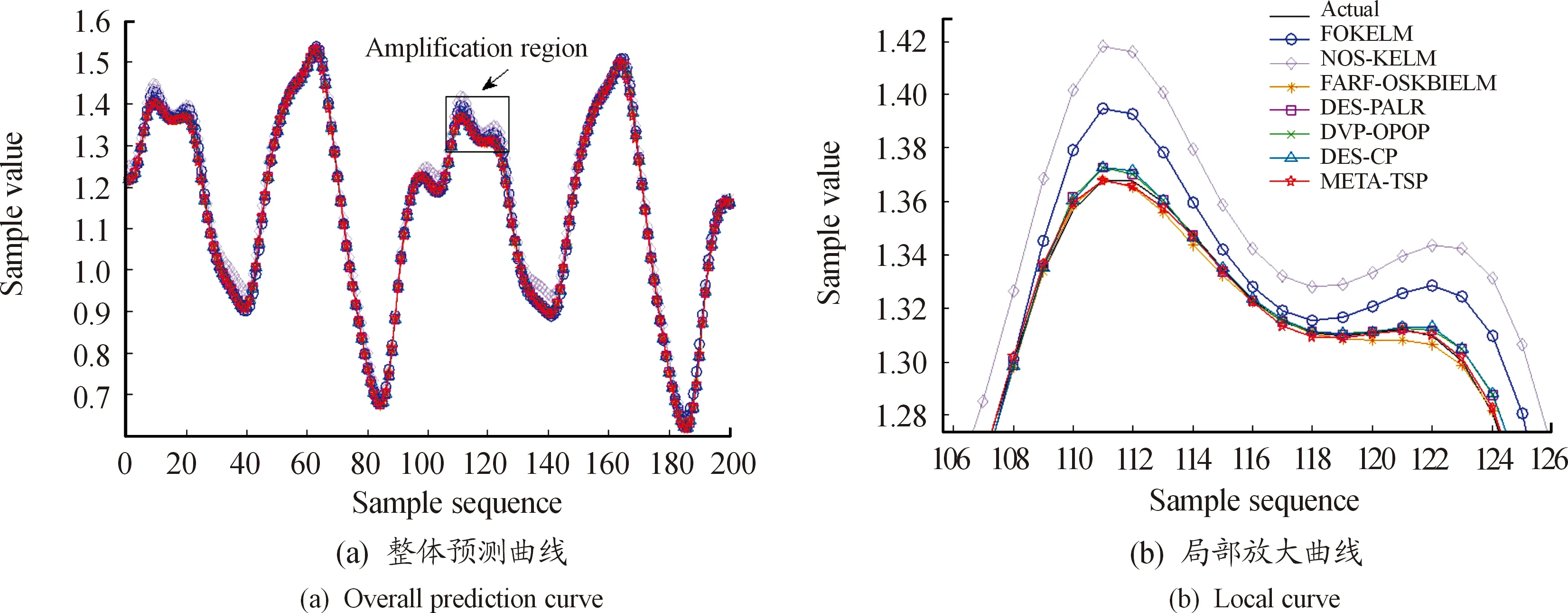
图2 Mackey-Glass 混沌时间序列预测曲线
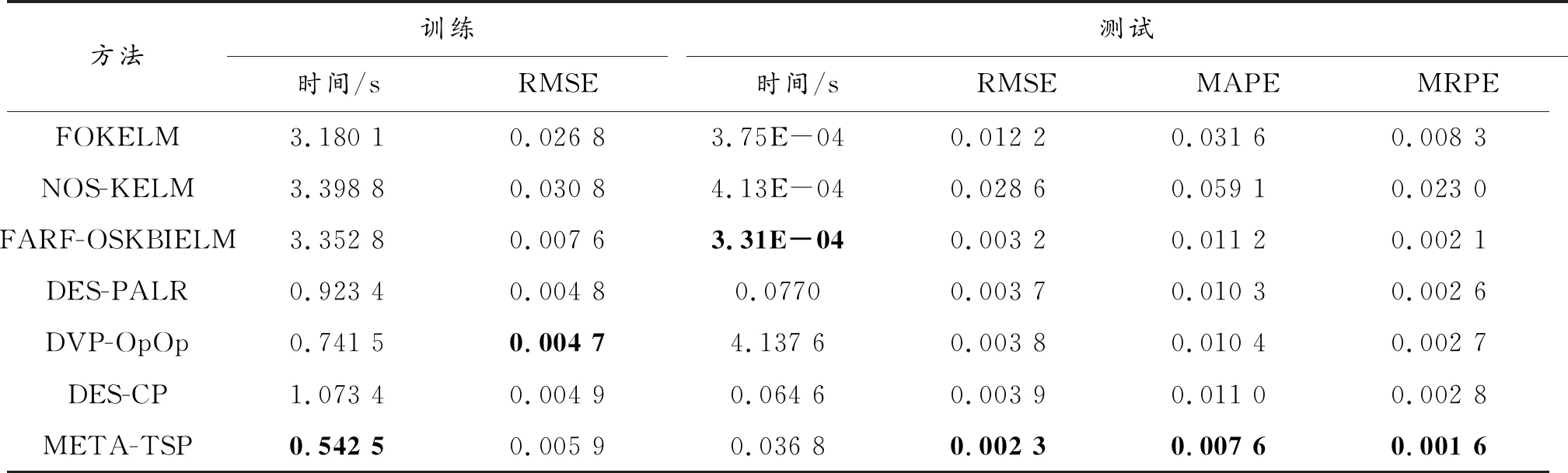
表1 Mackey-Glass预测结果
由表1和图2可以得出以下结论:
1) 在预测精度和预测稳定性方面,META-TSP方法均是最优的。相比于其他6种算法,META-TSP方法在RMSE指标上分别提高了80.98%、91.87%、27.72%、37.01%、38.91%和39.88%,在MAPE指标上分别提高了76.06%、87.19%、32.59%、26.32%、27.43%和30.97%,在MRPE指标上分别提高了80.46%、92.94%、22.68%、37.79%、40.78%和41.61%。这说明META-TSP方法对时间序列的未来走势预测最准确,并且预测效果最稳定。
2) META-TSP方法的预测时间高于3种基于KELM改进型的方法,低于3种DES算法。但是META-TSP方法的预测时间仍然是毫秒级的,能够满足实时预测的需求。值得注意的是,DVP-OpOp算法的预测时间过长,这是由于该算法在预测阶段会计算全部测试数据与训练数据预测结果的距离,这一过程增加了算法的时间消耗,即使其他各项指标都比较优良,该算法并不适用于TSP问题。
3) 训练精度方面,DVP-OpOp算法的均方根误差是最低的,但是DES-PALR、DES-CP和META-TSP方法与之非常接近,而且如前文所述,DVP-OpOp算法的测试时间过长,不适合处理TSP问题。此外,由于META-TSP方法的测试精度是最高的,说明该方法抑制过拟合效果更为明显。
4) META-TSP方法的训练时间是最短的,说明该方法采用的学习机制比较高效,能够根据训练数据更快地拟合时间序列。虽然使用了多个KELM生成基预测器池,但是仍比针对单个KELM进行优化的方法训练时间短很多。
5) FARF-OSKBIELM方法采用了自适应的正则化因子,预测效果比FOKELM和NOS-KELM方法好,但不及META-TSP方法,说明将元学习器引入预测过程更能充分挖掘时间序列所蕴含的信息。
关于Mackey-Glass混沌时间序列的绝对预测误差(absolute prediction error,APE),FOKELM、NOS-KELM、FARF-OSKBIELM、DES-PALR、DVP-OpOp和DES-CP分别与META-TSP方法的预测曲线如图3所示。总体来看,META-TSP方法比其他几种方法的预测误差都小,对时间序列未来趋势的预测能力最优。
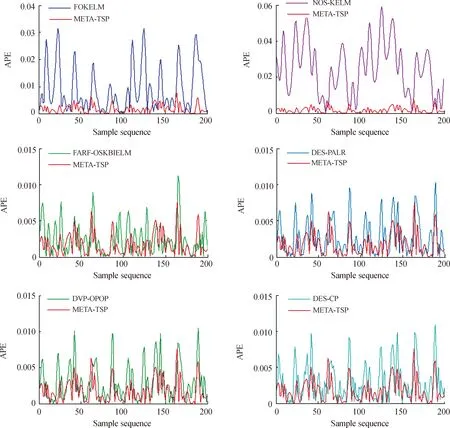
图3 预测误差曲线
4.3 某型飞机飞行参数预测
本节将META-TSP方法应用到具体案例中,验证该方法对飞机飞行状态预测的有效性。以某飞行训练部队某型教练机的发动机为例,选取低压转子转速(转每秒,r/s,记为LSpeed)、高压转子转速(转每秒,r/s,记为HSpeed)、涡轮后温度(开尔文,K,记为Temperature)和油门杆角位移(毫米,mm,记为Displacement)为监测项目。收集了该机型飞参系统某一架次的原始数据,数据采样每隔1 s进行一次,每个项目取250个样本,变化曲线如图4所示。其中,由于涡轮后温度的单位是K,在数量级上是其他项目的4倍,故在图4中将之转换成摄氏温度展示。
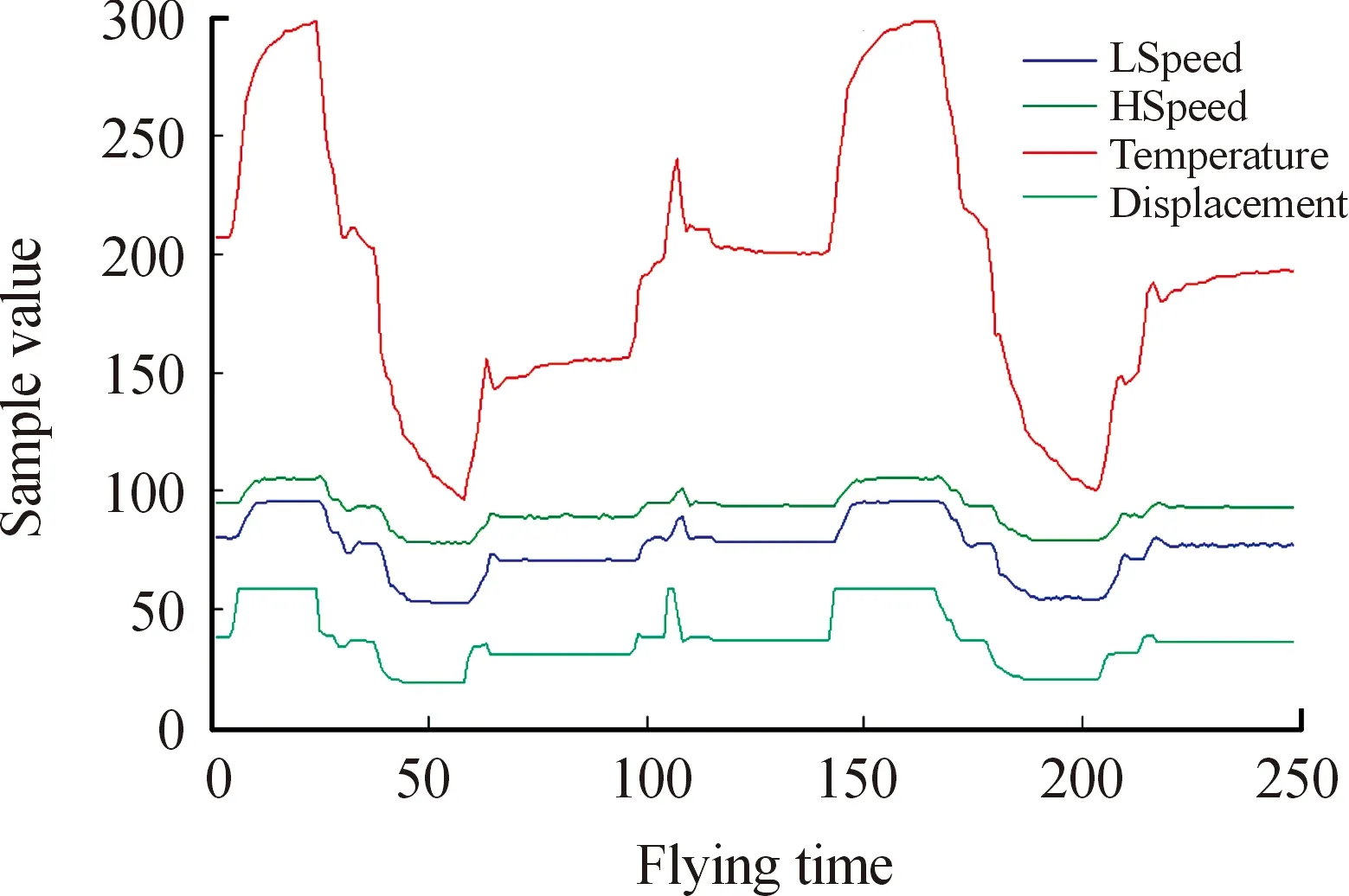
图4 某型飞机飞行状态参数变化曲线
设置嵌入维度为m1=m2=m3=m4=6,可得到244组数据样本。实验将前194组样本作为训练数据,后50组为测试数据。KELM改进型方法和DES算法中,选择Mackey-Glass混沌时间序列预测实验中整体性能最好的2种方法——FARF-OSKBIELM和DES-PALR,与本文方法META-TSP进行比较。表2列出了3种方法分别对4个监测项目的预测结果。其中各监测项目上的最优指标加粗表示。
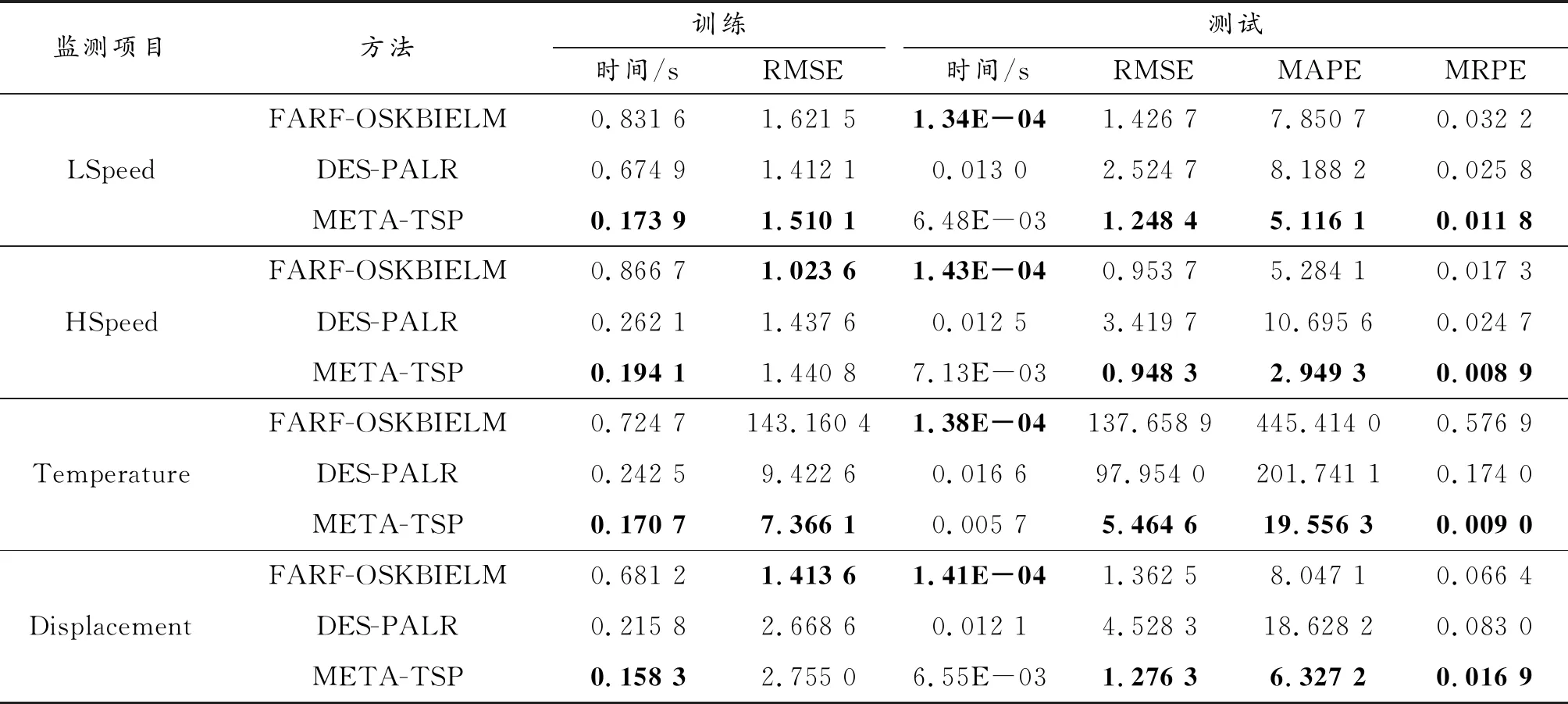
表2 飞行状态参数预测结果
由表2可以看出:① FARF-OSKBIELM的测试时间总是最短的,因为该方法只采用了单个预测器进行预测。但是META-TSP的测试时间只比FARF-OSKBIELM高出一个数量级,且这种毫秒级的时间开销几乎可以忽略不计,完全能够满足实时预测需求。此外,META-TSP的训练时间总是最短的,使得该方法能够更快地训练出预测器模型。② META-TSP在4个监测项目上的测试精度都是最高的,具有最好的整体预测性能。其中,对于Temperature项目而言,FARF-OSKBIELM的均方根误差很大,DES-PALR存在过拟合现象。③ META-TSP在4个监测项目上的MAPE和MRPE值都是最低的,说明该方法的预测结果更稳定。以预测发动机未来50个单位时间内的低压转子转速为例,3种方法的预测曲线图5所示。
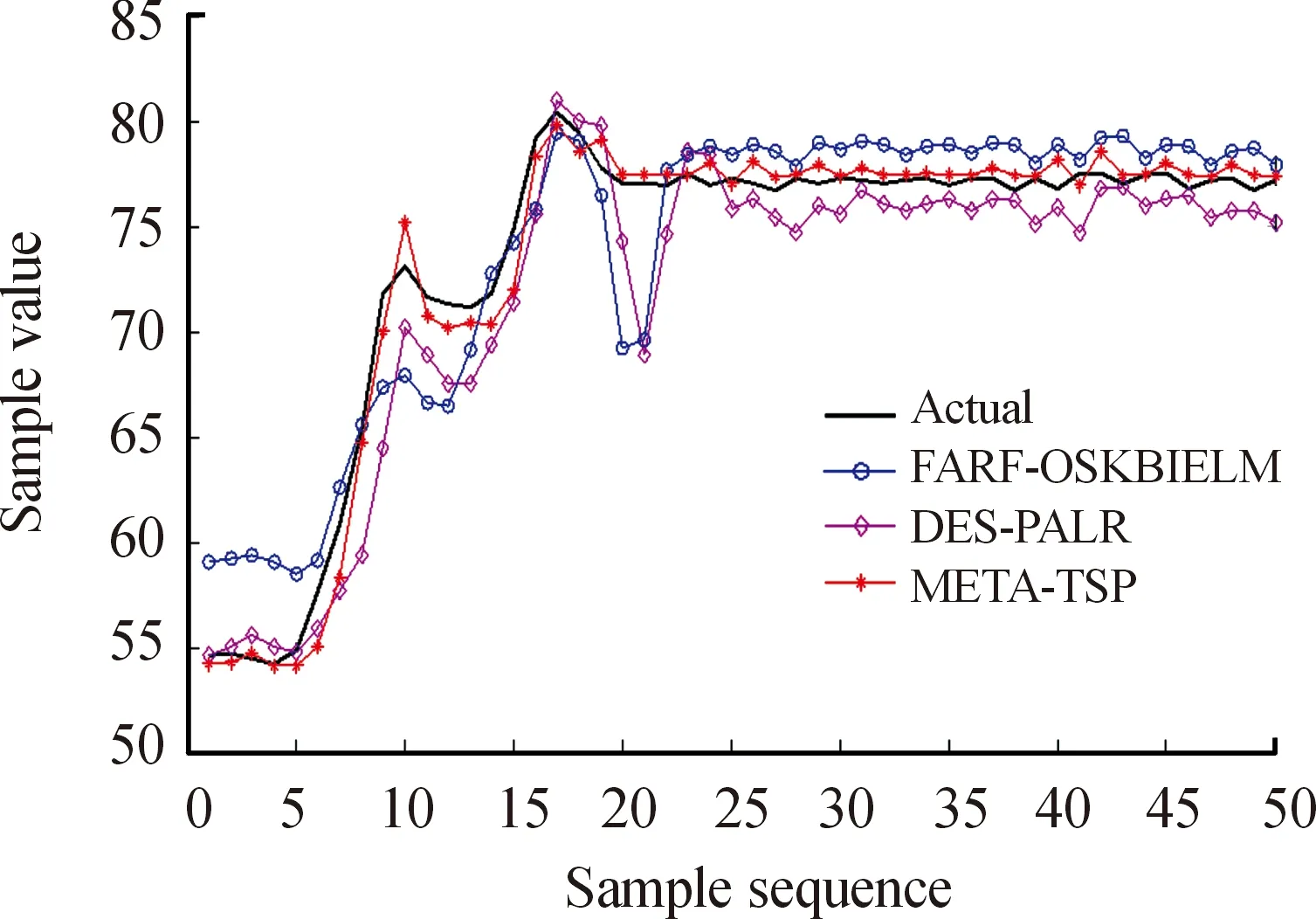
图5 低压转子转速预测曲线
由图5可知,显然,与其他2种方法相比,META-TSP对真实状态的跟踪能力最好。
5 结论
1) META-TSP方法完全能够满足实时预测需求,具有比FARF-OSKBIELM和DES-PALR方法更快的训练速度和极短的测试时间,在4个监测项目上的平均训练时间分别缩短了77.48%和33.91%。
2) 在预测精度方面,该方法的整体性能优于FARF-OSKBIELM和DES-PALR等2种对比方法,能够兼顾4个监测项目,平均预测均方根误差比其余2种方法分别提升了28.86%和72.26%。此外,该方法能有效抑制过拟合,且预测结果更稳定。
3)META-TSP方法采用BPSO机制对基预测器进行优化集成,控制了模型规模,且避免了预测能力差的基预测器对预测结果产生的不利影响;运用元学习器,对基预测器的结果进行再学习,相比于只采用单个预测器的方法,能对训练数据所含信息进行更充分的挖掘。
