取代苯酚类化合物生物毒性的模拟预测
2021-08-03廖立敏
廖立敏
内江师范学院化学化工学院,内江 641100
苯酚类化合物是重要的精细化学品或中间体,在农药、医药、炸药和染料等方面有广泛应用。苯酚类化合物大多具有毒性,个别还具有较强的致癌作用。随着现代工农业的发展,越来越多的苯酚类化合物随着废水排放到环境中,给动植物造成严重的危害。因此,全面评估苯酚类化合物的毒性,对于规范其生产、管理、使用和排放具有重要的意义。定量构效关系(QSAR)利用计算机模拟预测有机污染物性质参数,简便、省时、节约实验资源且降低费用,在全面获取有机污染物各种参数方面显示出了明显的优势[1-4]。QSAR研究中,化合物结构参数化是关键步骤之一,目前应用广泛的主要有二维结构表征法[5-6]和三维结构表征法[7-8]。二维结构表征法的优势是计算简单、快速,但无法分辨顺反异构、光学异构等现象;三维结构表征法的优势是基于化合物三维立体结构计算,对各种异构体能很好地区分,但计算量大、复杂难懂。本文基于化合物分子二维结构构建一种简易的结构描述符对化合物结构参数化表达,通过多元线性回归(MLR)和偏最小二乘回归(PLS)进行建模,分析影响化合物毒性的结构因素,为苯酚类化合物结构-性质研究提供参考。
1 材料与方法(Materials and methods)
1.1 实验材料
以25个取代苯酚类化合物为研究样本,化合物毒性以其诱发浮萍萎黄的活性值的负对数(pC)表示,其实验值取自文献[9],结果如表1所示。pC值越大表示化合物对浮萍的毒性越强,反之越弱。

表1 化合物及其毒性活性值的负对数(pC)Table 1 Compounds and their negative logarithm of toxic activity (pC)
1.2 实验方法
化合物结构参数化是建立化合物结构与毒性关系模型的关键一环,认为化合物中的非氢原子及非氢原子之间的关系对化合物的生物毒性有影响,而氢原子仅仅影响与其直接相连的非氢原子的取值。非氢原子的取值除与其直接相连的氢原子有关外,还与非氢原子自身的电子结构相关,首先在参考文献[10-11]的基础上,利用式(1)对化合物中的非氢原子进行赋值。
Zi=[(ni-hi)/(mi-ni-1)]1/2
(1)
式中:i为原子在分子中的编码,ni为非氢原子i的价电子数,mi为原子核外电子总数,hi为与其直接连接的氢原子数。
不同类型的非氢原子对化合物的毒性值影响不尽相同,而相同类型的非氢原子对化合物的毒性值影响具有加和性,因而需要将化合物中的非氢原子进行分类。参阅文献[12-14]方法将化合物中的非氢原子分为4类,与k(≤4)个非氢原子直接相连的非氢原子为第k类非氢原子,如与2个非氢原子直接相连的仲碳原子为第2类非氢原子,以此类推。不同类型的非氢原子自身对化合物生物毒性的影响按式(2)进行累加。
(2)
式中:k表示非氢原子i的原子类型,Zi按式(1)计算。根据非氢原子的分类,对于一个有机化合物分子中最多含有4类非氢原子,因此最终可得到4个非氢原子自身对化合物生物毒性的影响项,用x1、x2、x3和x4表示。
不同类型的非氢原子的关系对化合物的生物毒性的影响可能不同,相同类型的非氢原子之间的关系对化合物毒性的影响具有加和性。非氢原子之间的关系并非某种具体的相互作用,这种关系随着非氢原子之间的距离的增加而减弱,随着非氢原子的某种性质的增加而加强,式(3)可以满足这一要求。

(3)
式中:Z按式(1)计算;dij为非氢原子i、j之间的相对距离(即键长之和与碳碳单键键长的比值,如果i、j之间有多条路径,则以最短的为准);n和l为原子所属类型,α=0.5。4类非氢原子之间可以有10种不同的组合,即m11、m12、…、m44,简写为x5、x6、…、x14,m13表示第1类非氢原子与第3类非氢原子之间的关系,以此类推。这样一来,对于一个化合物经参数化表达后最多可得14个变量(结构描述符),暂将其称为化合物非氢原子及其关系(non-hydrogen atoms and their relationship, NATR)。
运用多元线性回归(MLR)及偏最小二乘回归(PLS)进行建模,“留一法”对模型进行交互检验。
2 结果与讨论(Results and discussion)
将化合物进行结构参数化表征后得到14个变量,但由于研究样本中不具有第4类非氢原子,因而与第4类非氢原子相关的x4、x8、x11、x13、x14这5个变量全为“0”,其余9个非全“0”变量用于建模分析。
变量数达到9个,而样本数仅有25个,在建模之前有必要对变量进行筛选。剔除与化合物生物毒性相关性不大的变量,寻找最佳变量组合进行建模。运用逐步回归对变量进行筛选,依据变量的显著性大小依次将变量引入模型。逐步回归中建模相关系数(r)及标准偏差(SD)的变化情况如图1和图2所示。
由图1可知,建模的r随着变量的引入逐渐变大,起初增大的趋势非常明显,当变量数达到3个时,建模的r接近最大值,此后r略有增大,但增大趋势不明显。同样,由图2可知,SD随着变量的引入逐渐变小,起初变小的趋势非常明显,当变量数达到3个时,SD接近最小值,此后SD略减小,但减小趋势不明显。综上,应该选择3个变量进行建模,此时符合样本数(N)/变量数(n)≥5的经验规则,三变量模型如式(4)计算。

图1 相关系数(r)在逐步回归中的变化情况Fig. 1 Changes of correlation coefficient (r) in stepwise regression

图2 标准偏差(SD)在逐步回归中的变化情况Fig. 2 Changes of standard deviation (SD) in stepwise regression
pC=6.385-3.853×x1+2.401×x3-0.293×x7
(4)
建模:N=25,r=0.984,SD=0.216,F=219.822;交互检验:N=25,rCV=0.979,SDCV=0.248,FCV=165.810。
建模的r高达0.984,说明模型具有良好的拟合能力;“留一法”交互检验相关系数(rCV)高达0.979,并且比建模的r略小,说明模型具有良好的预测能力与稳定性。判断模型质量好坏的另一个指标是SD,优良的模型通常要求SD与数值范围之比处于10%范围内。本文所建模型的SD为0.216,而化合物毒性值最大值-最小值=6.20-1.80=4.40,0.216/4.40=4.91%,远<10%,说明模型对化合物的生物毒性值预测误差在可接受的范围内。
为进一步分析影响化合物生物毒性的结构因素,采用偏最小二乘回归(PLS)建模和分析。将化合物结构描述符作为自变量X,化合物诱发浮萍萎黄的活性参数pC作为因变量Y建立PLS模型(M2)。PLS模型(M2)的主成分数(A)为6,r为0.988,SD为0.174,rCV为0.980。从r、rCV及SD值来看,模型(M2)也具有良好的拟合效果、预测能力和稳定性,并且建模效果还优于模型(M1),可以用于预测取代苯酚类化合物的毒性值和分析影响化合物毒性的结构因素。
25个样本在PLS前2个主成分得分空间散点分布如图3所示,由图3可知,所有的样本得分点都落在95%置信度的椭圆置信圈内,说明本文构建的化合物结构描述符能恰当表达该类化合物的结构特征,并且在PLS模型中得到反映。

图3 样本在前2个主成分得分分布Fig. 3 Distribution of the top 2 principal component scores of the sample
变量重要性投影(VIP)可以反映各个变量与化合物的生物毒性相关性大小,通常认为VIP值>1的变量与所研究的性质相关性大,而其他变量与所研究的性质相关性可能较小。VIP如图4所示,由图4可知,x5、x3和x2的VIP值>1,说明这3个变量与化合物的毒性值相关性较大。进一步分析发现,VIP值最大的x5为第1类非氢原子之间的关系对化合物毒性值的影响,第1类非氢原子对应的是化合物取代基末端原子;x3为第3类非氢原子自身对化合物毒性值的影响,第3类非氢原子对应的大部分是苯环上被取代后的碳原子,x5和x3这2个变量都与化合物的取代基数量有关。综上,化合物取代基越多,该化合物的生物毒性值可能就越大,这与表1中的数据特征基本相符。化合物产生毒性通常需要透过生物脂质膜,而化合物的体积与疏水性与其透过脂质膜的能力密切相关,当化合物分子都比较小时,化合物的疏水性起主导作用。本文研究样本中的取代基都为疏水性基团,取代基越多,该化合物的疏水性就越强,越易透过脂质膜而产生毒性。
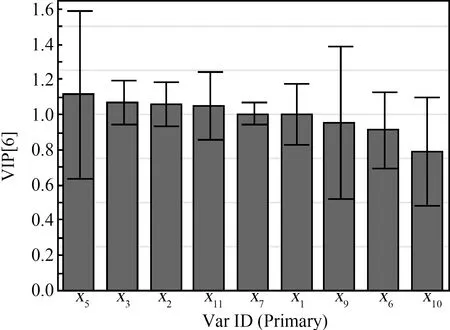
图4 变量重要性投影图Fig. 4 Projection of variable importance
2个模型对化合物的毒性值进行了预测,预测值分别为表1的Cal.1和Cal.2,Err.1和Err.2分别为其误差。模型预测值与实验值相关图如图5所示。
由图5可知,所有的样本点都落在正方形的45°对角线上及附近,说明模型预测值与实验值高度相关,两者之间相差性小。2个模型对化合物毒性值预测误差的绝对值分布如图6所示。由图6可知,绝大部分样本的预测误差的绝对值都小于模型的2倍标准偏差(2SD)。模型(M1)中,有2个样本的预测误差的绝对值超出了2SD的范围,而模型(M2)中所有样本的预测误差的绝对值均处于2SD范围内,说明模型(M2)对化合物毒性值的预测比模型(M1)更为准确,这与上述分析结果一致。

图5 模型预测值与实验值的相关图Fig. 5 Correlation diagram between model predicted values and experimental values
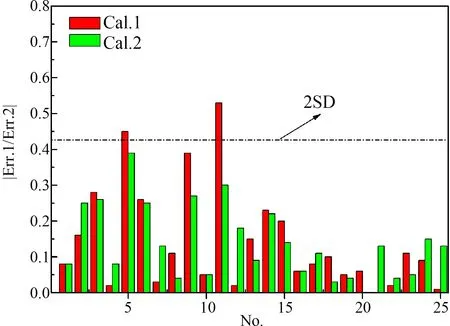
图6 模型对样本毒性的预测误差注:SD表示标准偏差。Fig. 6 Model prediction error of samples’ toxicityNote: SD stands for standard deviation.
文献[15]采用DFT-B3LYP计算描述符,运用多元线性回归(MLR)进行了建模研究,将文献结果与本文结果进行了对比(表2)。
由表2可知,本文所建模型的r及rCV明显大于文献结果,而SD明显小于文献结果,说明本文所建模型优于文献结果。另外,文献采用的分子结构表征方法DFT-B3LYP需经过分子结构优化,结算量大、复杂,而本文构建的结构描述符是基于分子二维结构计算得到,无需结构优化,计算量小,简单易懂。

表2 模型比较Table 2 Model comparison
以化合物中的非氢原子及非氢原子之间的关系构建结构描述符,对部分取代苯酚类化合物结构进行了参数化表征。通过MLR和PLS方法建立了化合物结构与毒性关系模型,模型具有良好的拟合能力与预测能力。分析了影响化合物毒性的结构参数,并将结果与文献进行了对比,化合物苯环上的取代基越多,该化合物可能就有较大的毒性值,本文取得的结果明显优于文献结果。本文所构建的化合物结构描述符简单、易懂、计算方便,对于环境中的有机污染物的结构与生物毒性关系研究具有一定的参考价值。但结构描述符还存在不能区分顺反异构、光学异构等现象,这些在后续研究中都应予以考虑。
◆
