基于深度学习的自适应睡枕设计①
2021-08-02余益臻郭力宁
余益臻,任 佳,刘 瑜,郭力宁
1(浙江理工大学 机械与自动控制学院,杭州 310018)
2(深圳市深智杰科技有限公司,深圳 518102)
睡眠约占人生命总时长的三分之一,随着生活节奏的加快,越来越多的人饱受睡眠问题的困扰,睡眠质量不好是危害健康的一大隐患[1].越来越多的流行病学证据支持睡眠时间短与肥胖和糖尿病风险之间的联系.与行为或睡眠障碍有关的慢性睡眠丧失,可能是体重增加、胰岛素抵抗和2 型糖尿病的一个新的危险因素[2].有关研究表明,人侧躺时睡枕的高度应大于平躺时的高度[3],以减轻侧躺时肩部承受的压力.因此,需要设计一种能根据睡姿来调整高度的枕头来改善睡眠质量.于是,如何有效地识别人体平躺和侧躺这两种睡姿就成了解决该问题的关键.
目前,对于人体睡姿识别的研究还比较少,已知的睡姿识别方法有基于睡姿图像技术,即摄像头采集人体睡眠时的图像,通过数字图像处理和机器学习算法对该图像进行分类[4],识别出此时人体的睡姿.也有通过置于床垫中的阵列式压力传感器,采集人体压力分布,来识别当前睡姿[5].然而,以上两种方案存在着一些不足和需要改进的地方.首先,通过摄像头采集睡姿图像的方法,涉及了用户隐私,以及当人体被物体遮盖时(如脸被头发遮挡,身体被被子遮盖),识别错误的问题.其次,采集人体压力分布的方法,置于床垫中的阵列式压力传感器面积大,传感器损耗大,且精度要求高,整个系统成本较高.
针对上述问题,本文提出了一种基于深度学习的自适应睡枕设计方案.通过枕头内部的压力传感器和气压传感器,分别采集头部对枕头的压力和枕头气囊内的气压,生成时间序列数据帧,并利用深度学习方法,自动学习深度特征,解决睡姿识别问题.
自适应睡枕的设计主要分为两个部分:硬件平台设计和睡姿识别算法的设计.
1 硬件平台设计
系统硬件平台的总体设计如图1所示,主控芯片选用意法半导体(ST) 公司的STM32F407ZGT6,该MCU 采用ARM Cortex-M4 架构,主频高达168 MHz,带有FPU,具有强大的浮点运算能力.MCU 主要负责处理传感器采集到的数据,根据识别的结果去控制执行器,并每隔一段时间数据写入外部Flash,还通过蓝牙与手机APP 通信.传感器有压力传感器和气压传感器,分别使用HX711 模块的压力传感器,XGZP6847 气压计模块,用于采集头部对枕头的压力和置于枕头内部气囊的气压.执行器为气泵和气阀,分别选择5 V 微型充气泵和5 V 微型电磁气阀,用于控制气囊的充放气,达到调整枕头至对应高度的目的.主控芯片通过低功耗HC-42 蓝牙5.0BLE 模块与手机进行通信,手机APP 可实现对枕头高度的设定、固件程序的升级,以及提取储存在Flash中的数据并生成txt 文件.

图1 硬件平台示意图
2 睡姿识别算法设计
2.1 数据预处理
通常,自然界中的大部分信号都存在噪声,而直接采集所得的压力和气压原始数据包含了各种噪声,会对后续的工作产生影响,因此,需要对压力和气压原始数据进行预处理.首先,将数据进行均值滤波,去除尖锐噪声.再将数据进行标准化,将数据限定在一定的范围内,消除奇异样本数据的影响,并且有效提升模型的收敛速度.

然后将每8 s的数据生成一帧时序数据,每两帧数据间的时间重叠为4 s.因数据采样频率为10 Hz,每次采样得到1个压力值和1个气压值,所以每一帧时序数据包含了80个压力数据和80个气压数据,如图2所示.

图2 一帧数据示意图

其中,X为一帧时序数据,xi为i时刻的数据,xi∈R2,pih为i时刻的压力值,pig为i时刻的气压值.
最后将一帧时序数据作为神经网络的输入,该数据为一维双通道时序数据,须选择合适网络模型对其进行特征提取和预测分类.
2.2 卷积神经网络
卷积神经网络(CNN)是一种处理具有类似网格结构的数据的神经网络,与传统人工神经网络结构不同,CNN 包含了卷积层和池化层.卷积层之间采用稀疏连接和权值共享的连接方式,可大幅降低参数数量[6],加快了学习速率.池化层降低了输出至下一层的数据维度,简化了网络的复杂度,同时也在一定程度上减少了过拟合的可能.
与二维、三维卷积神经网络相比,对于固定长度片段的数据,且该数据的一些特征在片段中的位置不具有高度相关性时,一维卷积神经网络(1DCNN)可以有效地将这些特征提取出来.本文中每个通道的数据为一维数据,1DCNN的卷积核朝一个方向移动,如图3箭头所示.一维卷积运算公式如下:

图3 1DCNN 卷积操作

其中,s(n)为卷积后的序列,f为待卷积的离散信号,g为卷积核,N是信号f的长度.为了去除冗余信息,简化网络复杂度,防止数据过拟合,需在一维卷积层后添加池化层.
2.3 循环神经网络
循环神经网络(RNN)是专门用于处理序列的神经网络,长短期记忆网络(LSTM)是一种特殊的RNN,是为了解决RNN 梯度消失和梯度爆炸而提出的.在传统的RNN中,训练算法使用的是BPTT,当时间比较长时,需要回传的残差会指数下降,导致网络权重更新缓慢,无法体现出RNN的长期记忆的效果,需要一个存储记忆的单元,因此,LSTM 模型被提出.
LSTM 单元结构如图4所示,t−1表示上一时刻,t表示当前时刻.LSTM的核心在于,每个LSTM 单元的长期记忆中的信息状态(cell state).LSTM 通过设置3个门来控制长期记忆中的信息,这3个门分别是:遗忘门(forget gate)、输入门(input gate)和输出门(output gate)[7].门由一个Sigmoid 层和一个点乘操作组成,可以让信息选择性保留.

图4 LSTM 单元结构
遗忘门可以决定清除或保留长期记忆中的信息.

在Sigmoid 层输入上一时刻的隐含状态ht−1和当前时刻的输入xt,由循环权重Wf、输入权重Uf和偏置bf,可以计算得到一个0 与1 之间的数ft,来决定上一时刻需要保留的信息量.
输入门决定了当前时刻被存进长期记忆中的信息.

在tanh 层输入上一时刻的隐含状态ht−1和当前时刻的输入xt,tanh 激活函数可以将输出值限制在−1和+1 之间,输出一个新的向量,表示当前时刻待存储的信息.同样地,ht−1和xt经过一个Sigmoid 层,计算得到it来决定中需被存储的信息量.Ct表示经过遗忘门和输入门添加了一部分新信息后,当前时刻长期记忆中的信息.
LSTM 单元的输出,即当前时刻的隐含状态ht,取决于Ct和输出门.

将Ct输入至一个tanh 层,得到一个待输出量.同样地,将在Sigmoid 层输入ht−1和xt,计算得到ot来决定输出,最后得到该LSTM 单元的输出ht.
门控循环单元网络(GRU)是一种特殊的RNN,是LSTM的一个变种,如图5所示,与LSTM 主要不同之处在于,GRU 单个门控单元同时控制遗忘因子和更新状态单元的决定.GRU 将LSTM的遗忘门、输入门和输出门进行了改动,变为更新门(update gate)和重置门(reset gate).在很多情况下,GRU 实际表现效果与LSTM 接近,而GRU 模型比LSTM 模型更简单,能够有效减少模型消耗的资源[8].

图5 GRU 结构
重置门和更新门的计算公式如下:

更新门用于控制上一时刻的状态信息被保留至当前状态中的程度,更新门的值越大表示上一时刻的状态信息保留越多.重置门用于控制忽略前一时刻的状态信息的程度,重置门的值越大表示忽略越少.

与LSTM中的一些功能类似,重置门控制的上一时刻的信息量ht−1需 要被保留.更新门控制ht−1中需要
丢弃的信息和h~t中多少信息会被保留,最后得到该GRU单元的输出ht.
2.4 本文采用的网络模型
本文采用的1DCNN-GRU 网络模型,由一维卷积神经网络(1DCNN)与门控循环单元网络(GRU)组成.先由1DCNN 网络对经过预处理的时序数据进行一维卷积操作,提取数据在空间结构上的特征,再将提取出来的特征传入GRU 网络.经过1DCNN 后,提取得到的特征仍具有时序特性,所以GRU 网络可以有效地对这些特征进行处理,并对处理结果进行有效地预测和分类.通常,分类模型的最后一层由一个Softmax 函数激活的全连接层构成,Softmax 函数定义如下:

Softmax 函数将n个范围在(−∞,+∞)的数,映射为n个(0,1)之间的概率.同时,使用Softmax 函数可以防止数值出现上溢和下溢.经过该全连接层后,输出模型预测的分类.
3 实验
3.1 数据采集
本文将整个睡眠状态细分为6 种,分别为:1)平躺保持不动;2)平躺虽有变化但仍为平躺;3)平躺变侧躺;4)侧躺保持不动;5)侧躺虽有变化但仍为侧躺;6)侧躺变平躺.其中,平躺时枕头高度应处在低位,侧躺时应升至高位.
本文参与实验的人员共有10 人,包括8 名大学生和2 名教师.图6–图11为2 号实验员的其中一组数据,该组数据记录了该实验员的6 种睡眠状态,每种睡眠状态包含了连续16 s的头部对枕头的压力值和枕头气囊内的气压值.该数据为一维双通道时序数据,片段长度固定且该数据的一些特征在片段中的位置不具有高度相关性.

图6 状态1 数据曲线图

图7 状态2 数据曲线图

图8 状态3 数据曲线图

图9 状态4 数据曲线图

图10 状态5 数据曲线图
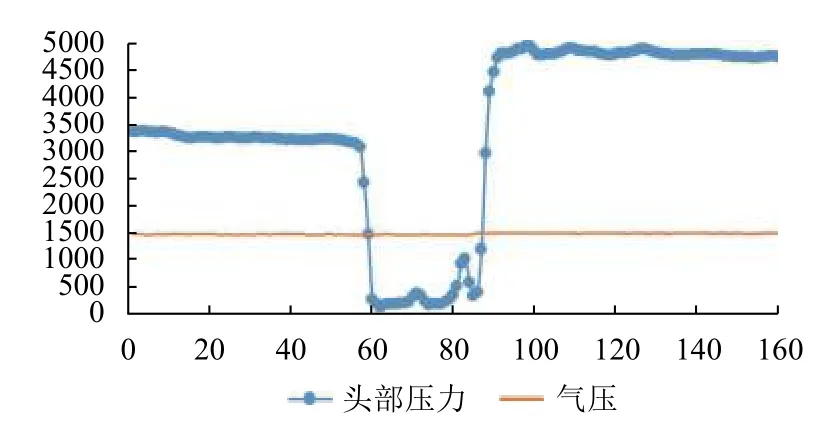
图11 状态6 数据曲线图
3.2 模型参数设置
本文网络模型搭建和训练在PC 机上进行,处理器为IntelCorei5-7300H,内存为8 GB,显卡为NVIDIA GTX1050 (2 GB),使用TensorFlow和Keras 深度学习框架.
网络模型的深度会很大程度地影响特征的学习.对于层数较少的浅层网络,该网络学习得到的特征表征能力有限,随着层数的增加,网络可以学习到表征能力更强的深度特征,可以更好地拟合复杂的特征输入.然而,网络参数量会随着网络的加深而增加,消耗更多的计算和存储资源,而且网络的加深可能会导致模型过拟合,因此需要对模型结构进行综合考虑.
神经网络主要分为输入层、隐藏层和输出层.网络的第一层为输入层,在该层传入预处理完的一帧时序数据.网络的输出层由1个Softmax 全连接层构成,该层的维数等于需分类类别的个数,本文一共需要识别6 种状态,所以输出层的维数是6.
网络的隐藏层共有6 层,如图12所示,由一维卷积层、池化层和GRU 层组成.其中,隐藏层的前3 层为一维卷积层,用于提取输入数据特征,文献[9,10]中将层数设置为3 时,已经有很好的效果.模型的超参数由多次实验确定.在前两层中,每一层定义64个卷积核用于提取特征,将卷积核大小设置为10,在第3 层中定义32个卷积核,将卷积核大小设置为5.第4 层是窗口大小为5的最大池化层,第5 层为GRU 层,将门控单元个数设置为64.优化器选择Adam 优化器[11],损失函数使用交叉熵损失函数.模型迭代50 次时,误差损失函数达到收敛状态,所以将训练次数设置为50.训练集和测试集比例为8:2.

图12 网络模型结构
3.3 实验结果
本文采用了准确率(Accuracy)、精度(Precision)、召回率(Recall)和F1 值(F1-score)对该网络模型进行评价.准确率是预测正确的样本占所有样本的比例.精度表示预测为正样本中,真正是正样本的比例.召回率表示正样本中,有多少是预测正确的正样本.F1 值是精度和召回率的加权平均值.

其中,TP表示将正样本预测为正样本,FN表示将正样本预测为负样本,FP表示将负样本预测为正样本,TN表示将负样本预测为负样本.
对模型进行训练和验证后,得到混淆矩阵、召回率、精度和F1 值,如表1所示.

表1 1DCNN-GRU 模型分类结果
作为对比,使用如下的网络模型,进行相同实验,得到不同网络模型的参数量和准确率,如表2所示.

表2 模型对比结果
3.4 结果分析
结果表明,相比于其他3 种网络模型,1DCNN-GRU和1DCNN-LSTM 模型的准确率较高,1DCNN-GRU模型参数量更少,更有利于在单片机上的应用.
从理论上看,传入网络的数据为一维双通道时序数据,1DCNN 可以学习数据在整体结构上的特征,提取数据的局部特征,组合抽象成高层特征.并且卷积层之间采用稀疏连接和权值共享的连接方式,能大幅降低参数数量,加快了学习速率.池化层降低了输出至下一层的数据维度,进一步简化了网络的复杂度.由于经过1DCNN 后,提取得到的特征仍具有时序特性,所以LSTM和GRU 网络可以有效地处理这些特征.而且,GRU在LSTM的基础上优化了门结构,保持了与LSTM 相近的表现效果的同时,减少了模型的参数量,缩短了模型训练的时间.
4 移植
STM32CubeMX是一个图形化工具,可以对STM32微处理器进行配置,并生成相应可执行的初始化C 语言代码.STM32CubeAI是STM32CubeMX的一个工具包,可以将预先训练好的人工神经网络转换成可以在单片机上运行的优化代码.
将训练好的模型文件.h5 文件导入STM32CubeAI,并对该模型进行分析和验证,得出模型所需的资源和部分验证结果的混淆矩阵,如图13和表3所示,最后生成单片机代码工程文件,并在单片机上运行.

图13 10 组验证数据混淆矩阵

表3 网络模型所占资源
5 总结
本文针对睡姿识别任务,使用了1DCNN-GRU 网络模型,在PC 机上进行训练和验证.接着,对比了BP、1DCNN和1DCNN-LSTM 网络模型,选择将1DCNNGRU 网络模型移植至单片机,并在单片机上运行,能较好地识别睡姿.由于该实验缺乏相关的公开数据集,数据集只包含了少量实验人员的数据,且数据量少,加之考虑到模型的移植,网络模型不能太复杂,限制了网络的深度,影响了该网络模型的准确率,下一步的研究重点是继续改进和优化模型,进一步提高其准确率.
