采煤机运行状态数据分布式实时预测模型
2021-07-30张俭让刘睿卿李学文王智鹏史振东
张俭让, 刘睿卿, 李学文, 王智鹏, 史振东
(1.西安科技大学 安全科学与工程学院, 陕西 西安 710054;2.教育部西部矿井开采及灾害防治重点实验室, 陕西 西安 710054)
0 引言
随着煤矿智能化的发展,数据量的增长异常迅猛。采煤机是综采“三机”之一,其工作环境复杂,自身安装有多个传感器,采样频率高,数据量大[1-2]。采煤机运行状态数据属于动态的时间序列数据,可用于采煤机运行状态的实时分析判断及预测。对采煤机运行状态数据进行实时采集与分析处理,可一定程度上保障采煤机及人员安全,对采煤机智能化运行具有重要意义[3]。
目前机械设备的状态预测方法仍然大量使用传统机器学习方法,如自回归模型[4]、隐马尔科夫模型[5]、BP神经网络预测模型[6]等。这些模型在预测少量数据时取得了不错的效果,但面对大量数据应用时往往效果不理想。
Storm是一种开源的分布式实时大数据处理框架,具有适用场景广泛、可伸缩性高、无数据丢失的特点,适用于大量时间序列流数据的实时处理[7-8]。因此,本文在Storm框架基础上进行采煤机运行状态预测。循环神经网络在处理与时间序列相关的数据方面取得了良好效果,但在反向传播过程中,随着层数增多,会出现梯度消失或者爆炸现象,对模型的拟合程度有较大影响。门控循环单元(Gate Recurrent Unit,GRU)是循环神经网络的一种变体,其解决了长距离时序数据预测中容易出现的梯度爆炸和消失问题,应用于金融时间序列预测[9]、电力负荷预测[10]等领域时取得了良好效果。因此,本文采用GRU预测采煤机的时序数据,结合Storm框架和GRU实现采煤机运行状态预测。
1 Storm数据流模型
Storm的核心组件主要包括主控节点(Nimbus)和从节点(Supervisor)。Nimbus节点主要负责资源分配和任务调度,Supervisor节点负责接收Nimbus分配的任务,管理和启动所有的工作(Worker)。1个Supervisor对应4个Worker,1个Worker对应1个拓扑(Topology),Topology由Stream、Spout和Bolt组成。Stream即数据流;Spout充当采集器的角色,实现与数据源的连接;Bolt为业务逻辑运算节点,订阅多个Spout,实现业务处理、连接运算等操作。Storm数据流模型基本结构如图1所示。
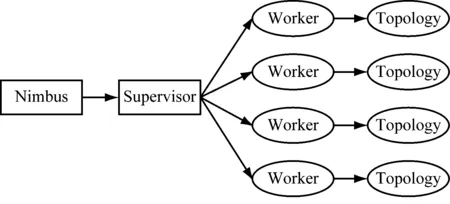
图1 Storm数据流模型基本结构
2 GRU结构及原理
GRU结构如图2所示。其中xt为t时刻的输入值,ct为记忆细胞,ht为t时刻隐藏单元的历史信息,at为重写的记忆细胞的候选值,ot为t时刻的输出值,rt为重置门,ut为更新门。GRU通过记忆细胞ct将历史数据信息保存下来,用于数据预测。当t时刻实际数据xt到达时,结合隐藏单元历史信息ht-1,通过更新门和重置门控制上一个单元有多少信息可以保留,当前单元有多少信息可以添加到记忆细胞ct并传递给下一个单元,通过激活函数输出当前时刻的预测值ot。常用的激活函数为tanh,K类别分类问题可以选用softmax作为激活函数。为了简化描述,设置输出的激活函数为softmax函数,隐藏层的激活函数为tanh函数。
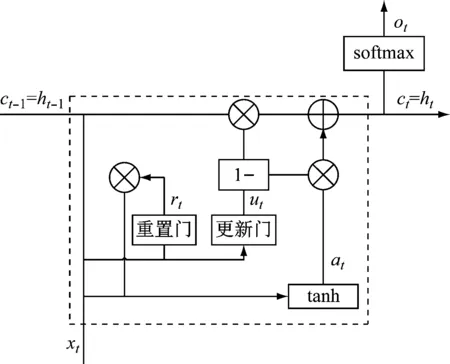
图2 GRU结构
更新门ut用于确定上一隐藏层中的记忆信息,重置门rt用于确定上一隐藏层中的遗忘信息,记忆细胞候选值at用于确定当前的记忆内容,记忆细胞ct用于确定当前要保留的信息,其计算公式分别为
ut=σ(wu[ct-1,xt]+bu)
(1)
rt=σ(wr[ct-1,xt]+br)
(2)
at=tanh(wh[rtct-1,xt]+bc)
(3)
ct=utat+(1-ut)ct-1
(4)
式中:σ为sigmoid函数;wu,wr,wh分别为更新门ut、重置门rt和记忆细胞候选值at的更新权值;bu,br,bc分别为更新门ut、重置门rt和记忆细胞候选值at的偏差值。
3 基于Storm的采煤机运行状态数据分布式实时预测模型
3.1 预测模型原理
基于Storm的采煤机运行状态数据分布式实时预测模型如图3所示。采煤机运行状态数据是以固定时间间隔源源不断地产生,本文结合在煤矿收集的采煤机运行状态数据,在Hadoop分布式存储数据库中通过crontab编写定时读取数据的脚本,用来模拟采煤机的实时数据流。将流数据传送到不同的消息队列Spout中,Spout将数据以元组流的形式发送给相应Bolt,通过多个Bolt实现对数据的预处理、预测、误差计算及存储,最终实现对采煤机运行状态数据的实时预测[11]。
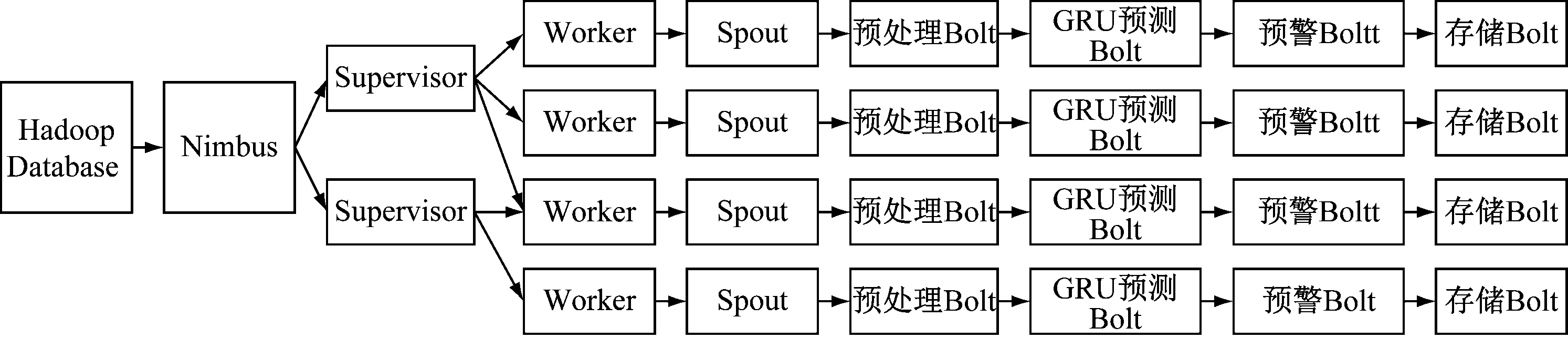
图3 基于Storm的采煤机运行状态数据分布式实时预测模型
3.2 Hadoop分布式存储数据库
为方便管理海量的采煤机运行状态数据,基于Hadoop[12]设计数据存储结构,包括1张索引表和多张数据表[13]。索引表包括监测点位置、预测模型、预警阈值上界TUBn(n为监测点数)和下界TLBn,见表1。数据表通过行增长的方式模拟时间序列,每一列代表某个监测点所采集的时间序列数据,见表2,其中m为时间点数,Datanm为监测数据。在实际生产中,各个测点的实时运行数据会以固定时间间隔存入Hadoop中,经主控节点Nimbus的调配传入 Spout中进行处理。

表1 索引表
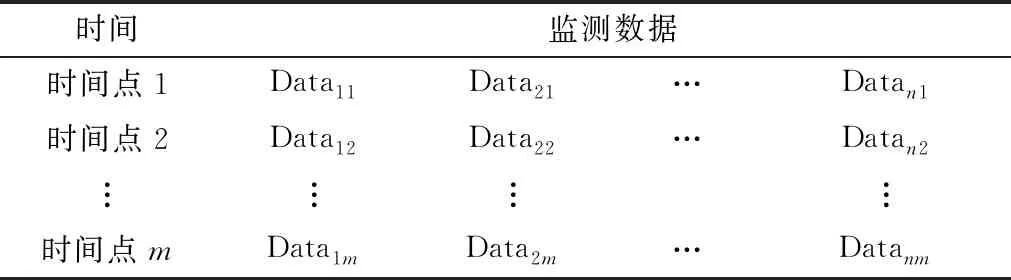
表2 数据表
3.3 Spout设计
Spout通过调用nextTuple()方法从Hadoop中提取相应监测点的信息,将信息封装后传递给Bolt,具体步骤如下:
(1) 连接Hadoop,从相应监测点的数据表中读取n个数据。
(2) 判断数据序列长度是否达到预测的历史数据样本容量N,达到则进行步骤(4),否则进行步骤(3)。
(3) 从数据库读取新数据,将新数据添加到序列末尾,跳回步骤(2)。
(4) 将数据封装成元组形式发送到预处理Bolt。
3.4 Bolt设计
Bolt接收Spout传递的元组,通过多个Bolt调用execute()方法,分别实现数据的预处理、预测、误差计算和存储,具体步骤[14]如下:
(1) 预处理Bolt接收从Spout传递来的元组,解析对应监测点的N个数据;导入python包处理异常值,并将数据标准化,以元组形式发送到GRU预测Bolt。
(2) 预测Bolt接收预处理Bolt传递的标准化后的数据,导入训练好的GRU模型,预测下一时刻的数据,并等待该时刻实际数据,将预测数据和实际数据一起发送到预警Bolt。
(3) 预警Bolt根据设定的阈值判断是否要预警,将预测结果和预警信息发送到存储Bolt。
(4) 存储Bolt接收数据并存储。
4 实验分析
4.1 实验环境及过程
以某矿综采工作面MG400930-WD电牵引采煤机的数据为例,取采煤机中的截割部电动机电流、截割部电动机温度、牵引部电动机电流、牵引部电动机转速、调高泵工作压力、调高泵工作转速、冷却水压、变频器电流8种监测数据(依次用a—h表示)各1 000条作为实验数据。
首先进行GRU模型训练。对原始数据中的缺失值、异常值及噪声进行预处理,将预处理后的数据作为输入数据。将输入数据以7∶3的比例分为训练集和测试集。隐藏层针对训练集进行训练,通过优化函数Adam、损失函数MSE调节模型的超参数,以损失值最小作为调优准则对模型进行优化。
通过训练找到GRU的最优参数,在Hadoop上模拟实时数据流,设置基本时间窗口为1 min。在主控节点Nimbus调控下,将8种测试集数据并行输入8个Worker中,在各自的拓扑中完成对数据的预测和预警。
4.2 实验结果
GRU超参数寻优结果见表3,其中C1—C7分别为寻优训练次数、学习率、神经元数量、权重衰减、时间步数、每次训练样本数、隐藏层数。从表3可看出,8种监测数据在GRU模型中收敛的训练次数不同,但均小于500次,收敛速度较快。

表3 GRU超参数寻优结果
将训练好的GRU导入Bolt中,用测试集模拟实时数据流,各测试集中300个点的真实值和预测结果对比如图4所示。

a) 截割部电动机电流
4.3 结果分析
4.3.1 GRU预测结果评价
采用平均绝对误差(MAE)、均方根误差(RMSE)及拟合优度(R2)作为GRU拟合程度的评价指标,其计算公式分别为
(5)

如果我们回到一般城邦的具体的人员构成上,就会发现,在寡头制和平民制中,穷人阶层和富人阶层可以得到很好的混合,即形成一个人数较多的中产阶层,他们既不太穷,又不太富,而是拥有中等家资。这是贫富混合得适中、恰到好处的一个阶层。如果他们执政,则可以兼得平民制和寡头制的好处,能服务于所有公民;同时,这种财富状况对于他们的政治美德培养是一个极好的基础,因为他们“最容易听从理性”[2](P144),可以避免人的两种极端的性格品质。这样的城邦就是尽可能地由平等或同等的人所组成,这样他们之间就能坦荡地交往,并且产生出公民友谊,所以,这样的城邦就将是现实中最优良的城邦,能得到最出色的治理。
(6)
(7)
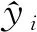
GRU预测结果评价指标对比见表4。

表4 评价指标对比
拟合优度R2的值越接近1,MAE和RMSE的值越接近0,效果越好。由表4可知,因为原始数据较大,数据类型d和f的MAE和RMSE的值相对较大,而其余类型的原始数据较小,误差也相对较小。8种数据的MAE和RMSE均接近0,初步判断GRU可作为预测模型。8种数据的R2均达到0.9以上,说明基于Storm的分布式时间序列实时预测模型适用于采煤机运行状态数据的预测。
4.3.2 预警的准确性
根据经验和误差要求,设定各类实验数据的阈值,见表5,其中Ie1,Ie2分别截割部电动机、牵引部电动机的额定电流,Ie1=87 A,Ie2=105 A。
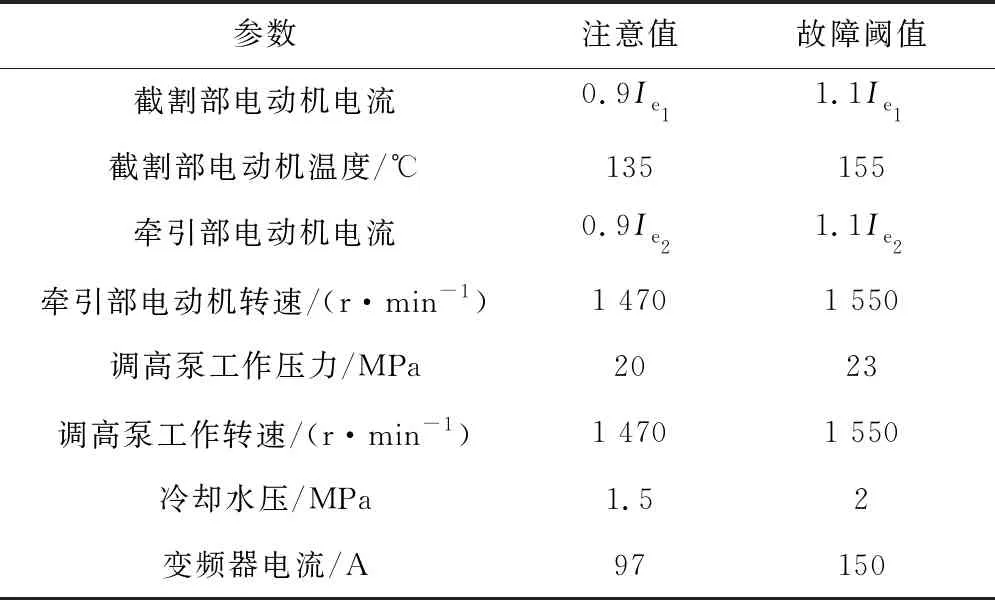
表5 数据阈值设定
根据阈值设定,将各类数据的状态分为正常、注意和故障3种。当采煤机运行时,若数据未达到注意值,则状态为正常,工作性能稳定,无需采取措施;若数据达到注意值而未达到故障阈值,则状态为注意;若数据达到故障阈值,则状态为故障。预测Bolt在得到预测数据而实际数据未到时,对数据状态进行预测并作出相应预警[15]。测试集的各数据预测状态与实际状态的对比结果如图5所示,其中纵坐标1,2,3分别表示正常、注意和故障3种状态。各类数据的预警准确率见表6。
(a) 截割部电动机电流
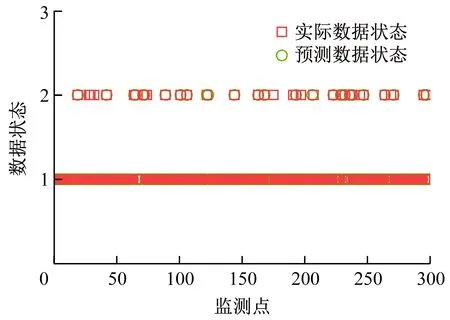
从表6可看出,除冷却水压外,其余数据的预警准确率均达到95%以上,满足实际应用要求。由于冷却水压数据值较小,注意值和故障阈值间隔很小,预测时误差偏大,但也达到85%以上,准确率较高,具有一定的实用价值。
表6 预警准确率
4.3.3 处理时间
实验模拟从传感器得到数据并传入Hadoop中,Storm从Hadoop中读取数据,主控节点Nimbus通过Zookeeper监控和分配任务,通过Supervisor节点将具体的处理逻辑交由Worker完成。分别测量将流数据传入Spout中所需要的时间,Spout将数据分发给Bolt所需要的时间,预处理Bolt、预测Bolt、预警Bolt和存储Bolt所需要的总时间,结果见表7。

表7 预测模型处理时间
从表7可看出,数据库、Worker中Spout和各Bolt针对流数据的处理速度较快,整个预警过程共10 s左右,远低于测点数据采集间隔(1 min), 因此,可满足应用要求。
5 结论
(1) 提出基于Storm的采煤机运行状态数据分布式实时预测模型,结合Hadoop 数据库,模拟实际生产中采煤机时间序列运行数据,采用深度学习中的GRU对数据进行处理,实现对采煤机运行状态数据的预测和预警。
(2) 实验结果表明:GRU收敛速度较快,且拟合优度达到0.9以上;各种数据状态预测的准确率均达到85%以上,整个预警过程仅需10 s左右,远低于测点数据采集间隔(1 min),模型的预警准确率和效率均能满足要求。
(3) Storm框架仍需进行包括负载均衡、集群调优等优化,以更好地满足应用要求,下一步将对此进行研究。
