基于加权萤火虫算法的关联规则特征挖掘
2021-07-30吴辰文刘文祎马国娟闫光辉
吴辰文, 刘文祎, 马国娟, 闫光辉
(兰州交通大学 电子与信息工程学院,甘肃 兰州 730070)
当今医院存有大量的医疗数据,在医院诊治患者过程中获得了大量的诊断、病历数据,通过对这些数据进行挖掘分析,可以得出很多有用的信息,这些信息可以提升医院的诊断水平以及服务质量。医院的医疗信息不是仅局限于短期的数据信息,而是长达数年或是十多年的数据积累,因此如此大并且时间跨度较长的数据中会有很多有用的信息以待发现。子宫癌的危害性较大,不论是发病率还是死亡率都十分高,因此通过药物治疗子宫癌变得十分重要。
针对关联规则这一问题的解决方法有很多种,其中由Agrawal等人提出的改进算法应用最为广泛,但算法挖掘效率低,而且频繁的扫描事务数据库极大地增加了系统的负担,不仅浪费时间并且浪费空间[1]。文献[2]提出采用遗传算法来改进Apriori算法,它引入兴趣度,对生成规则进行筛选,删除其中的虚假规则,使得结论更具说服力,但其没有对算法的运行效率进行提升。文献[3]提出了通过矩阵来压缩事务并相乘的改进算法,该算法通过用二维矩阵来表示数据库数据,再将数据二进制矩阵与辅助矩阵相乘得到频繁项目集。但这种方法需要很多矩阵相乘计算的内容,致使时间效率不高。文献[4]提出基于采样思想的关联规则挖掘算法,首先从数据库中随机抽取一部分数据为样本数据进行关联规则挖掘进而得到一些强关联规则,再用其他所有数据进行关联规则挖掘验证算法是否正确。该方法的优势在于可以快速挖掘出频繁项集,但因为是随机抽取数据,所以最终得出的结果与实际情况相差很大,效果不好。因此本文提出将加权萤火虫算法应用到Apriori关联规则挖掘算法中,通过萤火虫算法的良好性能,提高医疗大数据关联规则挖掘的效率。
1 关联规则算法概述
1.1 关联规则
两个或多个变量之间的取值存在某种规律性,就称为关联。现在已经有多种关联规则算法,其中较为经典和使用率较高的是Apriori算法、FP-growth算法等。关联规则算法的意义是:可以通过关联规则得出的结论来调整不同事物之间的搭配或联系,从而提升效率。
1.2 Apriori算法简介
关联规则挖掘可以发现数据中项目或属性之间的有用联系,而这些联系是预先未知的,Apriori算法是Agrawal和Strikant在1994年提出的第一个关联规则挖掘算法,能够较好地挖掘出数据中的规则[5-7]。关联规则挖掘规则的本质是在所有频繁项集中发现符合最小置信度的规则,所以一般来说,挖掘关联规则主要分为两部分:找出频繁项集和找出所有强关联规则[8]。
挖掘关联规则的重点是生成所有频繁项集,主要方法从1-项集开始挖掘出通过最小支持度判断产生的1-项频繁集,继续对1-项频繁集进行组合产生2-项候选项集,再进行最小支持度判断生成2-项频繁项集,按照这种方法类推,直到得出最大频繁项集[9]。Apriori算法存在的性质是:一个频繁项集的任意子集也都是频繁项集,除空集之外。
假如数据库中包含有N项事务,其中A,B为数据库中不相交的两个项集,则支持度support(A)指的是项集A中出现的事务数占总事务数N的比值;当支持度大于某一给定阈值时,既称其为频繁项集;包含规则X-Y的支持度support(A→B)其含义为当A和B同时出现的事务数占事务总数N的比值;置信度confident(A→B)的含义为A→B的支持度support(A→B)与项集A的支持度support(A)的比值,当此比值大于给定阈值时此规则为强关联规则,强关联规则的含义是项集A出现的情况下项集B也出现的概率很高,提升度指的是当A出现时对B也出现的概率的提升,用来判断实际价值,即当使用规则两者同时出现与只有一项事物出现频率是否提升。
规则A→B的支持度与置信度提升度公式表示如下:
(1)
(2)
式中,σ(A)表示事务A出现的频数;σ(A→B)表示规则A→B出现的频数。
(3)
提升度大于1为规则有效;小于1则规则无效。
2 萤火虫算法概述
2.1 萤火虫算法仿生原理
萤火虫算法是模拟自然界中萤火虫发光行为的物理学意义,通过萤火虫自身发光的特性按照发光相对强度来搜索一定范围内的其他萤火虫,并且根据距离的远近向附近区域内位置较好的萤火虫靠拢,进而实现位置的更新[10]。
算法中萤火虫的移动由两个要素决定:自身亮度和吸引度。其中,萤火虫自身的亮度由其所在位置的目标值决定,位置越好的萤火虫越亮。吸引度与亮度相关,越亮的萤火虫吸引度越大,吸引度大的萤火虫会吸引吸引度较小的萤火虫向其移动,大多数萤火虫会聚集在搜索范围内最亮的萤火虫附近。亮度以及吸引度都与萤火虫间的距离成反比,两只萤火虫之间的相对亮度以及吸引度会随着距离的增加而减弱[11]。
2.2 萤火虫算法的数学定义
定义1:亮度。
I=I0×exp(-γrij)
(4)
式中,I0为初始荧光亮度,即在光源处的荧光亮度。
定义2:吸引力。
(5)
式中,β0为最大吸引力,即光源处的吸引力,通常情况下β0取值为1;m值大多数情况下取2;参数γ是空间中介质对光的吸收率,常取γ∈[0.1,10];rij为萤火虫i到j的笛卡尔距离:
(6)
式中,d为变量的维数。吸引力函数可以为任何一种单调递减函数[12]。
定义 3:位置更新公式。
假设萤火虫i比萤火虫j亮度大,则i向j移动的位置更新公式为
xi=xi+β×(xj-xj)+α×(rand-1/2)
(7)
式中,xi,xj为萤火虫i,j所处的位置;α为随机步长因子,即萤火虫每次移动的步长,取值范围为[0,1];rand为[0,1]上服从均匀分布的随机因子,α×(rand-1/2)的作用是增加萤火虫移动的扰动项,防止算法陷入局部最优解[13]。萤火虫通过多次移动后,所有个体都将移动到搜索范围内亮度最大的萤火虫位置上,最终实现寻优。
2.3 算法的伪代码
Start初始化。
设定参数γ,βο,α,G(最大迭代次数),n;初始化萤火虫位置x(i),(i=1,2,…,n);初始化萤火虫亮度I(i),(i=1,2,…,n)。
迭代过如下:
Whileg≤G
Fori=1:n-1
Forj=i+1:n
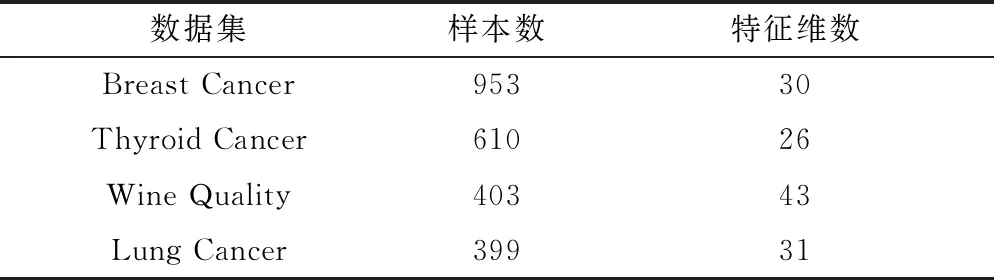
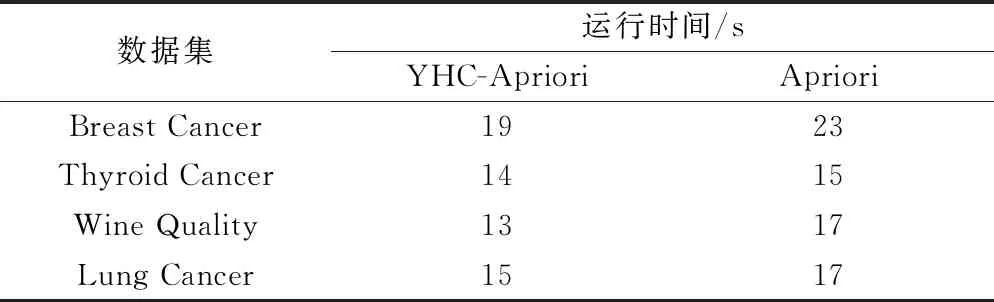
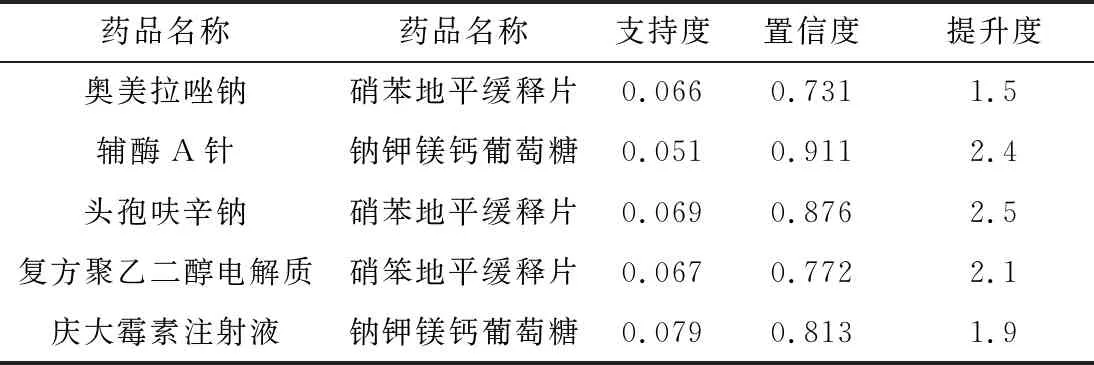
IfI(j) End If; End Forj; End Fori; g=g+1; End While End Start 因为Apriori算法要反复求每个数据项的支持度,所以算法效率低,而萤火虫算法可以根据数据项的支持度大小来快速求出数据项之间的关联度。 根据已有数据库信息,扫描每一个事务,计算每一事物的支持度,再设定参数x为最小支持度,先将所有小于最小支持度的事务删除,这样不仅降低了由于数据过多导致的系统资源占用过多的弊端,而且筛选掉了支持度较小的数据,使得出的结论更有说服力。萤火虫的亮度I设置为数据的支持度,萤火虫根据数据支持度的大小判断哪个数据集的吸引力β更大,并开始选择向着吸引力更大的数据集移动,萤火虫的运动轨迹被记录下来,当至少有两只萤火虫近似位于同一位置时,说明二者之间存在较强关联规则,将该信息记录到关联规则表中,以此类推直到所有萤火虫遍历完成停止移动,则可得出所有关联规则信息。 一个优化算法的效率在于对寻找一个新的最优解的探索和开发。标准萤火虫算法在移动步骤中同时实现了对寻找一个最优解的探索和开发[6]。自适应权重被添加到萤火虫算法的萤火虫移动步骤中以增强算法的效率。使用自适应权重的萤火虫运动由式(8)给出: Xnew(t+1)=W(t)Xold+β0exp(-γcm)(xj-xi)+αεi (8) 式中,Xnew(t+1)为i萤火虫经过t+1次运动后的位置;α为随机化参数,值在0和1之间;εi是随机数向量;W(t)是惯性权重,由式(9)给出。 (9) 式中,Wmax和Wmin是迭代t中的最大和最小权重;MaxG是最大迭代次数。 首先扫描一次基准数据库中的所有事物,从而建立每只萤火虫的支持度信息表。 输入:数据项集合。 输出:强关联规则列表Rule。 ① 初始设定所有带有支持度的萤火虫,即数据项,都没有移动过; ② 根据最小支持度,首先排除支持度小于最小支持度的数据; ③ 萤火虫开始移动,根据萤火虫亮度的大小来判定萤火虫之间的相对移动; ④ 记录萤火虫移动的路线,当有至少两只萤火虫近似位于同一位置时,生成相应的关联规则并将生成的规则放入列表Rule中,以此类推得出总体的关联规则列表; ⑤ 当所有萤火虫停止移动则迭代结束; ⑥ 输出最大频繁项集T; ⑦ 输出萤火虫关联规则算法挖掘的关联规则。 实验数据来源于某地妇幼保健院的子宫癌完整数据,首先对数据进行清洗,对数据结果没有影响的属性进行删减,例如:患者住院天数,患者编号,患者年龄等,另外对于数据中缺失部分进行填充。 本实验在Windows 7环境下实施,R语言版本为3.4.2,对比算法为Apriori,将数据集划分为两个不同大小等级,一个是1000数据,另一个是10000数据。实验结果如图1、图2所示。 图1 事务集为10000时两种方法时间效率比较 图2 事务集为1000时两种方法时间效率比较 取事务集个数为1000,10000,最小支持度取2%,最小置信度取45%,将改进算法YHC-Apriori算法与Apriori算法进行实验对比分析,从图1、图2可知,采用萤火虫优化算法的效率更高,当运行时间相同时,改进算法得到的频繁项集更多,当生成频繁项集数量相同时,改进算法用的时间更短,证明用萤火虫算法改进的Apriori算法运行效率更高,并且当数据量越多时改进算法的效率提升会更加显著。医生在通过改进的关联规则算法对大量的临床数据进行分析时更能得出有用的用药信息。 本文选择UCI上4种数据集来测试萤火虫Apriori算法的准确性以及稳定性,数据集分别为乳腺癌数据(Breast Cancer)、甲状腺癌数据( Thyroid Cancer)、葡萄酒质量数据(Wine Quality)、肺癌数据(Lung Cancer),4种数据集信息如表1所示。实验结果如表2所示。 表1 数据集信息 表2 算法时间效率对比表 由表2中信息可知,改进的萤火虫Apriori算法时间效率都要高于Apriori算法,证明萤火虫Apriori算法适用于各种不同类型的数据集,其稳定性更加出色。 通过对患者用药数据进行关联规则挖掘发现一些子宫癌患者常用药规律,其主要关联药品为奥美拉唑钠、辅酶A针、头孢呋辛钠、复方聚乙二醇电解质散、庆大霉素注射液、硝苯地平控释片、钠钾镁钙葡萄糖、维生素B6,其中生成的关联规则如表3所示。 表3 用药关联规则 通过分析表3可得出一些有用的用药关联规则,例如:有6.6%子宫瘤患者同时用到奥美拉唑钠,硝苯地平控释片两种药物,用奥美拉唑钠药物的患者有73.1%的概率用到硝苯地平控释片;有5.1%的患者同时用辅酶A针和钠钾镁钙葡萄糖两种药物,用辅酶A针药物的患者有91.1%的概率用到钠钾镁钙葡萄糖。当医生开药方时奥美拉唑钠与硝苯地平缓释片可一同写进药方,辅酶A针与钠钾镁钙葡萄糖可一同写进药方,以此类推关联度大的药品可以结合使用。 本文首先介绍了萤火虫算法和关联规则算法的特点和研究现状。目前很多学者针对关联规则提出了很多较好的算法,但也都存在着一些问题,本文提出一种基于加权萤火虫算法的关联规则挖掘算法,与之前经典的算法比较,在算法运行效率上有明显的提升。同时本文将患者用药情况进行挖掘得出一些关联性较高的规则,其可以为医院医师使用药物进行科学的统计分析,方便医生对药物进行合理的使用。 由于关联规则挖掘生成的规则数较多,在大量的规则中发现有用的信息还需要花费一些额外的时间和精力,因此在同样最小支持度参数情况下,能生成较少的但更有价值的规则就更能够提升算法的效率,这是接下来要研究的方向。3 基于加权萤火虫算法的关联规则挖掘
3.1 YHC-Apriori算法设计
3.2 加权萤火虫位置更新
3.3 具体算法
4 实验结果
4.1 数据预处理
4.2 实验平台及结果对比
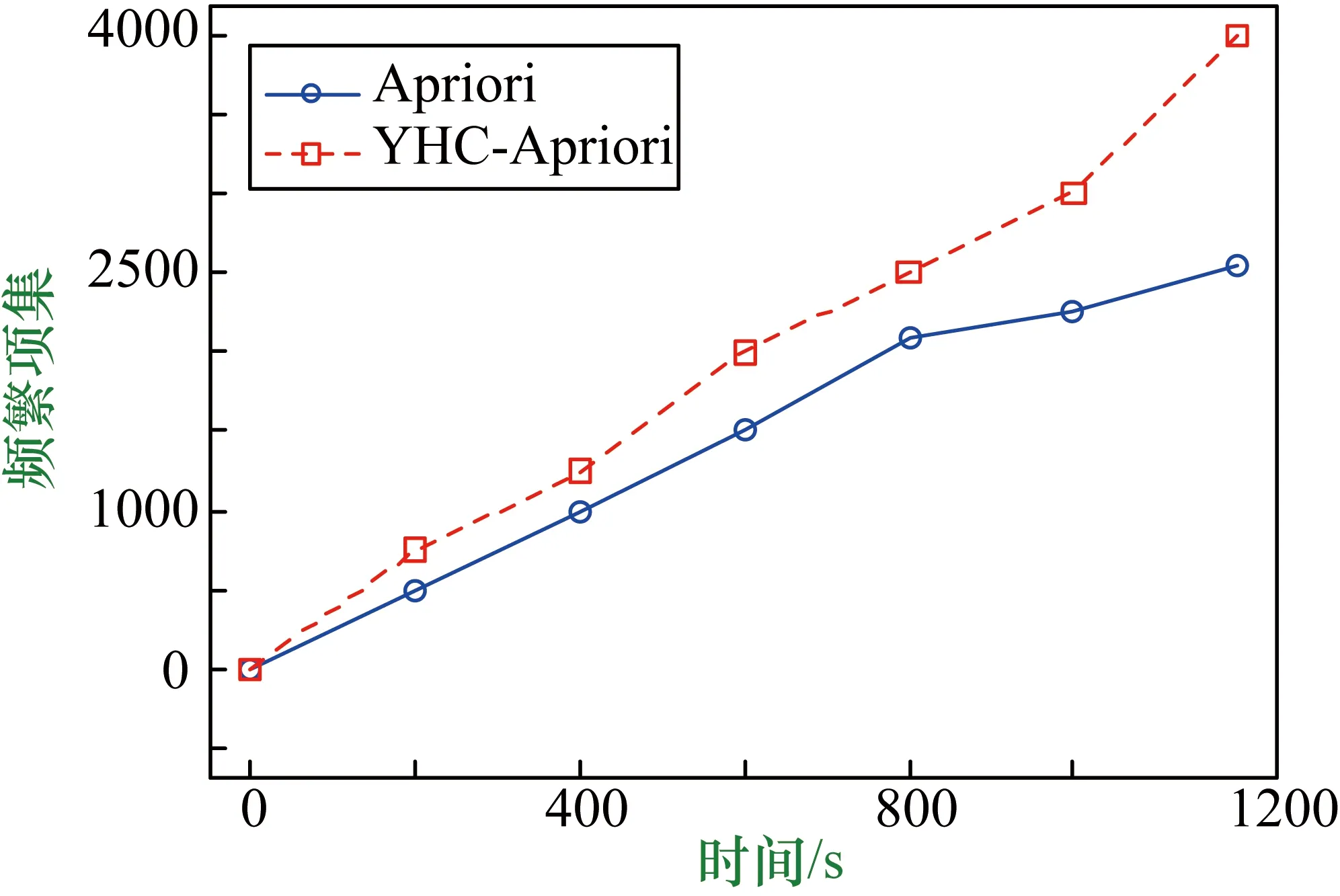
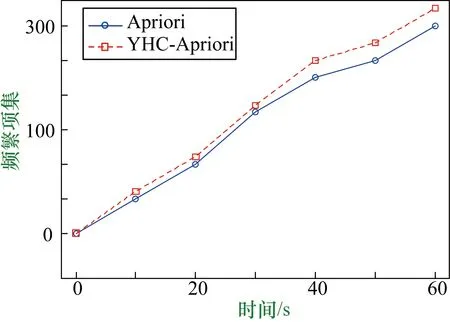
4.3 萤火虫Apriori算法稳定性测试
4.4 子宫癌患者用药分析
5 结束语
