基于卷积神经网络的列控车载设备故障分类研究
2021-07-30周璐婕党建武王瑜鑫张振海
周璐婕,党建武,2,王瑜鑫,张振海
(1.兰州交通大学 自动化与电气工程学院,甘肃 兰州 730070;2.甘肃省人工智能与图形图像处理工程研究中心,甘肃 兰州 730070;3.兰州交通大学 土木工程学院,甘肃 兰州 730070;4.中铁西北科学研究院有限公司,甘肃 兰州 730070)
车载设备是列车运行控制系统中重要的行车控制设备,是确保高速铁路安全运行的核心。车载设备运用至今,虽整体性能稳定,但使用过程中也发生了不少故障,严重干扰运输组织和秩序。车载设备故障诊断是防止列车故障、保证安全运行的重要部分,并且为维修人员提供及时的维修信息,压缩故障延时。
车载设备运行过程中,通过车载安全计算机记录了大量的应用事件日志(Application Event Log,AElog),可以反映车载某一时刻的状态信息,AElog数据由非结构化文本形式记录,包括各模块正常或异常工作时的标志性语句。技术员通过人工分析AElog数据来判别车载设备的运行情况,分析难度大,诊断效率低。为满足现代化铁路高速运行的需求,利用机器学习算法实现列控车载设备智能故障分类是当前急需解决的问题。
车载设备包含的模块众多,故障机理不同,各模块故障出现的概率不平衡。同时,正常工作的记录数据远大于故障数据,也存在正常与故障数据间不平衡的问题。因此须针对数据的不平衡性,研究有效的列控车载故障诊断模型。
目前,车载故障诊断主要基于数据驱动的智能分类技术[1-2]。通过人工进行故障文本特征选择,再输入分类模型进行分类,分类模型主要包括贝叶斯网络、逻辑回归、支持向量机等[3]。这些方法存在3个问题:①,依赖特征工程,例如文献[4]利用向量空间模型表征列控车载记录的文本数据,通过特征词选择与权值分配实现文本向量化转换,这种文本表示存在明显的表示稀疏问题,此类数据输入分类器,将面临维灾难,同时语义特征也无法被描述;②多数机器学习方法同等地对待数据集中的所有样本,以提升分类器总体分类精度为目标,适用于分布较均匀的数据集[5];③传统分类算法的优点是模型复杂度低,训练速度相对较快,可解释性较强。但由于模型层次较浅,不能实现文本特征的自动提取,分类效果受人工特征选择的影响。基于以上问题,并结合车载AElog数据的实际特点,本文提出针对性的模型对其改进。
深度学习[6]概念被提出后,迅速成为研究热点,该方法改变了先进行特征选择,再输入分类器训练的传统模式,实现了特征学习与提取。Mikolov团队[7-8]设计出包含CBOW和Skip-gram两种语言模型的词向量生成工具Word2vec,让Hinton[9]提出的文本分布式表示得以广泛应用。文本分布式表示可以通过训练语言模型,将词语映射成一个维度小、数值稠密的实数向量,能刻画词语的语义和语法关系,同时具备良好的计算性,避免了人工选择特征的困难,解决了向量稀疏的问题。借助词向量,深度学习在自然语言处理的典型任务中取得优异的性能[10-11]。
卷积神经网络(Convolutional Neural Network,CNN)能够从词向量表示的文本中获得局部敏感信息,提取高层次文本特征,缓解了特征工程的工作量,有效用于文本分类问题[12]。文献[13]利用CNN对短文本进行建模,并在7组公开数据集上进行对比试验,证明CNN在文本分类任务中的有效性,同时也表明了词向量对提升系统性能的重要意义。文献[14]提出将基于字符级的CNN模型用于文本分类,该模型适用于多种语言,性能优于词袋模型等传统模型以及循环网络模型。总的来看,借助词向量和基于深度学习的文本分类方法在多数分类任务中取得了比以往研究更好的效果。但多数用于文本分类的CNN没有考虑到样本不均衡的问题,造成多数样本类的分类精度高,而少数样本类分类精度低,直接影响分类效果。
不平衡分类问题的研究主要包括基于数据和基于算法的两种方法[15]。数据层面利用欠采样对多数类样本进行约简或是利用过采样对少数类样本自动生成,通过改变数据集中样本的分布来降低数据间的不平衡程度。算法层面通过改进模型的损失函数或调整模型结构使之更倾向于少数类样本。
借鉴前人的研究经验,本文进一步探索文本结构化处理与非均衡数据分类在车载设备记录数据中的应用,解决列控车载故障诊断问题。以车载安全计算机记录的AElog数据为依据,分析故障模式;结合AElog数据特点,利用语言模型训练词向量来表示文本语义特征,实现文本的向量转化;采用CNN进行文本深层次特征提取,用于故障分类;针对样本不均衡问题,通过合成少数类过采样方法(Synthetic Minority Over-sampling Technique,SMOTE)随机生成少数类文本向量数据,并在卷积神经网络的训练阶段采用焦点损失函数对样本加权,进一步减小不均衡样本对分类效果造成的影响。为验证模型的有效性,选取某铁路局提供的车载AElog数据进行试验分析,通过精确率、召回率、G-mean和F1-Measure等指标对构建的基于卷积神经网络的模型进行评价,验证该模型在列控车载故障诊断中的可行性与优越性。
1 列控车载设备记录数据
我国CTCS-3级列控车载设备硬件采用分布式结构设计,双系冷备,核心控制模块采用“单硬件双软件”的设计结构。CTCS3-300T型列控车载设备主要由CTCS-3控制单元ATPCU、CTCS-2控制单元C2CU、测速测距单元SDU、网关TSG、安全数字输入输出单元VDX、安全无线传输单元STU-V、司法记录单元JRU、应答器信息接收模块BTM+CAU、轨道电路信息接收单元TCR、人机界面DMI等组成[16]。
ATPCU是CTCS-3核心计算控制单元,在每个ATPCU单元内部均有一块非易失存储区,在列车运行过程中,可实时记录车载各个模块正常或异常工作时的标志性语句,即AElog数据。通过查看这些文本型数据,可以分析出相关模块的工作状态,也能根据故障语句分析故障原因。记录内容通常包括记录时间、报告此记录的文件、文件中的行数、任务名称、上电时间、语句编码、模块正常工作或故障时的标志性语句等。图1为某次列车运行结束后AElog记录的实例,其中记录了BTM工作异常导致的BTM端口无效的故障,文本中“Balise Port invalid”“StatusPort invalid in BTM”等语句是关注的重点。从图1中可以看出,这些语句按时间顺序逐条记录,由大量长短不一的英文短文本组成,故障或正常语句多样,包含了重要的故障信息,如故障发生的具体模块、具体现象等,是判断车载故障的主要依据。

图1 AElog数据(部分)记录
本文以CTCS3-300T型车载设备中的列车接口相关故障和BTM相关故障为例,以AElog记录的文本数据为基础,挖掘具体故障信息,实现故障的自动分类。将这两种故障类型进行编号,见表1。加入正常状态共13种模式。
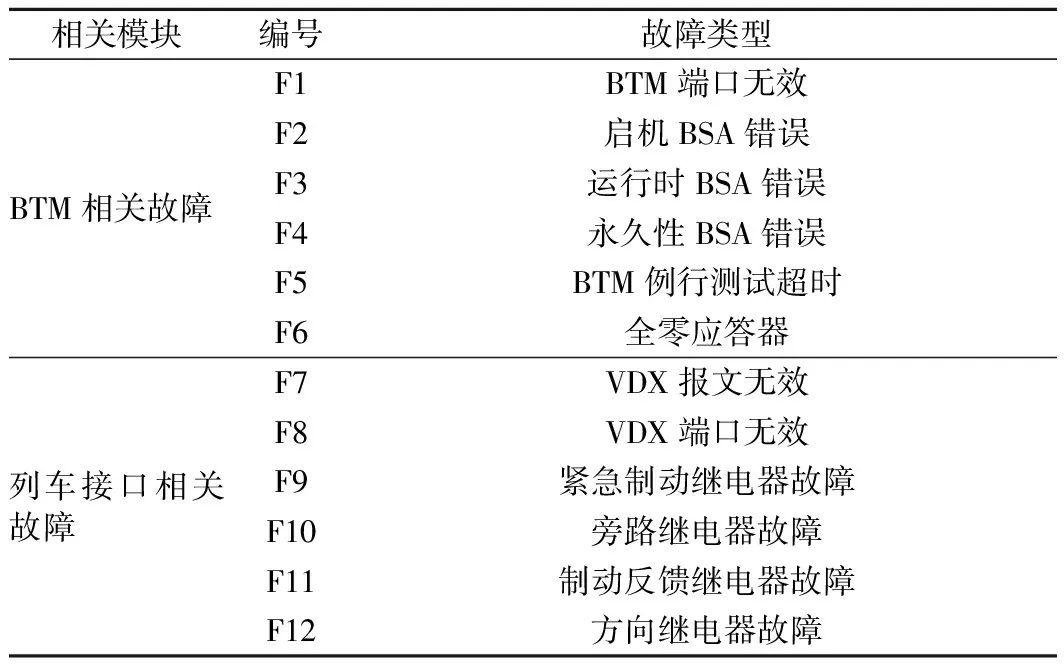
表1 故障类型
2 基于卷积神经网络的列控车载设备故障分类模型
基于CNN的车载设备故障分类模型见图2,主要包括3部分:文本预处理、利用CNN实现特征学习与分类、对CNN进行训练。在预处理阶段,通过训练CBOW模型将AElog文本转化为计算机可识别的向量形式。针对转换后的文本向量矩阵,利用SMOTE方法对少数类数据自动生成,降低数据间的不平衡程度。再经CNN的卷积与池化操作,实现文本特征的自动提取,在输出层利用Softmax实现分类。训练时通过改进CNN模型的损失函数,使模型更加关注难分样本,进一步提升分类器对不平衡数据的分类能力。

图2 列控车载设备故障分类模型结构
2.1 文本预处理
文本需要通过预处理转化为计算机可识别的数字形式。数字化的过程需最大程度保留文本的语义特征,减少语义信息的损失。针对车载记录数据的特点,AElog数据的预处理包含标志性语句分段、分词、向量表示和少数类样本自动生成等,主要步骤如下:
Step1AElog文件处理:由于列车每趟运行后,记录数据多达数百条,为提高诊断精度,将对数据统一模式,提取标志性语句,以AElog中的提示指令为节点对数据进行分段,则每段包含1~7条标志性语句。
Step2分词:以词为单位对其进行分词处理,相较于中文文本,英文文本以空格为依据进行分词,结合AElog数据的特点,下划线也作为分词依据。为节省存储空间、提高搜索效率,需过滤停用词和符号。部分车载词典和分词结果见表2和表3。

表2 部分车载词典

表3 部分故障说明
Step3生成词向量词典:文本分布式表示的优势在于可以短时间内充分利用文本的上下文信息训练语言模型,将词语转化为向量空间中同一维度的稠密向量,解决向量稀疏问题;且向量空间的相似度可以表示文本语义的相似度,修正词与词之间完全正交的不恰当结果。参考Word2vec中基于Hierarchical Softmax算法的CBOW模型,以分词后的车载记录数据作为训练语料库C。算法主要思想是通过当前任意词的上下文Context(w)来预测当前词w,优化目标函数为

(1)
CBOW模型通过输入当前词上下文的词向量,经投影层对所有词向量进行累加,在输出层利用Huffman树实现目标优化。Huffman树以语料库中出现的词作为叶子节点,对语料库中任意词w,Huffman树都存在一条从根节点到词w对应的节点路径,将路径中的每个分支看成一次二分类,每次分类就产生一个概率,将这些概率连乘起来就是所需的P(w|Context(w))。之后用随机梯度上升法将此函数最大化,直至训练结果达到可以接受的误差范围。训练所得词语的语义相似度与词向量的余弦距离成正比。
Step4文本向量化:每类车载正常或故障状态均由1~7个短句构成的文本共同实现判别,按照短句中单词的顺序从词典中取出对应的词向量,使文本转化为向量矩阵。为解决各组文本数据长度不统一的问题,对样本中每组文本进行词数统计,选择最高词数作为文本向量维度,其他长度不足的文本用0补齐。

(2)
式中:rand(0,1)为0到1之间的随机数。SMOTE算法相对于随机复制过采样法,可以有效防止过拟合,提高分类器性能。在利用SMOTE算法获得新数据集的基础上,建立基于CNN的特征提取与故障分类模型。
2.2 基于卷积神经网络的故障分类
文献[13]利用卷积神经网络对文本进行建模,完成句子级的分类任务。本文在此网络结构上进行拓展研究,结合车载记录数据特点,构建具有多尺度卷积核和批归一化处理层的卷积神经网络分类模型。
2.2.1 网络概况
网络结构如图2卷积神经网络部分所示。
第一部分为输入层,用于输入文本向量矩阵M∈RS×n,其中行数S为文本段中最高词数,列数n为词向量维度。
第二部分为卷积及池化层,卷积层通过卷积窗口与输入层的局部区域连接。设卷积窗口的权值矩阵为W∈Rh×n,h为卷积窗口的宽度,n为矩阵的列数,且与M的列数相同,卷积窗与输入层由上到下滑动做卷积运算,对输入进行分层特征提取,所得卷积结果为
Ci=g(w·Mi:i+h-1+bi)
(3)
式中:i=1,2,…,s-h+1;Mi:i+h-1为由第i个词到第i+h-1个词组成的连续文本段;bi为偏置项;g(·)为不饱和非线性函数ReLU,此函数能解决梯度爆炸/梯度消失等问题,同时能够加快收敛速度[18]。将所获得的Ci依次排列就构成卷积层的向量C∈RS-h+1。
由于车载记录的故障文本长短变化大,为更全面地提取特征,本文选用3种宽度的卷积窗口以获取不同词数级别的语义特征。
在卷积之后,通过池化操作聚合信息,减少神经元数目,降低特征维数,实现特征的进一步提取。本文采用最大池化法来获取全局特征向量。池化结果为
Oj=max{C}
(4)
式中:j=1,2,…,t,t为卷积窗口总数。将Oj依次排列就构成池化层向量O∈Rt。
第三部分是分类层。经过卷积与池化操作,已经提取出所需的特征向量,下一步是实现分类。将池化层的输出经压平(Flatten)层压为1维向量,经全连接层整合局部信息,之后送入分类器。为提升网络性能,本层的激励函数也采用ReLU函数。在输出层利用Softmax逻辑回归实现分类。
2.2.2 批归一化处理
远程控制模块既可以使用具有固定IP地址的Web服务器作为中转站,也可以使用GPRS网络上网卡动态接收数据,从而使得控制中心可移动。在控制终端,将接收到的数据存入数据库,然后利用基于MatLAB的最小二乘支持向量机建立土壤水分检测盐分补偿模型。
在神经网络训练过程中,各层之间参数变化会引起数据分布发生变化,出现梯度弥散、影响网络收敛速度等问题,为减少内部协变量迁移(Internal Covariate Shift)的影响[19],本模型中在两处加入批归一化BN(Batch Normalization)处理:①在卷积运算后加入归一化层,再进行激活和池化运算;②在分类层计算激活值前加入归一化层。相较于未归一化处理的网络输入是{x1,…,xm},该批次样本数量为r,处理后的输出数据为{y1,…,ym},算法过程如下,计算输入样本的均值μ与方差σ分别为
(5)
(6)
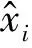
(7)
式中:ε为一个常量。
为了解决在归一化处理后带来的数据分布特征被破坏的问题,引入参数α和β对归一化后的数据进行性重构,恢复原始的特征分布。
(8)
批归一化处理包括对输入进行归一化以及对归一化后的数据重构,进行尺度不变的平移变换。
2.2.3 模型训练
训练多分类卷积神经网络模型时,常选用标准的交叉熵损失函数CE为
(9)

为控制不均衡类别对误差损失值的贡献程度,引入一个权重因子α,削弱大数量类别对误差损失值的影响。
(10)
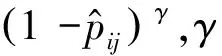
与式(10)结合,得到能调整非均衡和难易分类样本的多类别焦点损失函数FL为
(11)
本文采用反向传播算法通过上述定义的多类别焦点损失函数训练卷积神经网络,并对α和γ的取值进行实验,根据Adam优化算法进行梯度更新。
3 试验与分析
3.1 试验数据与评价指标
为研究本文提出的列控车载记录数据分类模型对故障的分类效果,根据某铁路局电务段提供的2017年8月至2018年12月的AElog文件,选取其中包含列车接口相关故障和BTM相关故障的文件,文件中包含正常运行时的数据和故障时出现的表1所示的12种故障数据。通过对AElog文件进行预处理,共得到2 450段包含正常或故障标志性语句的文本段,并对每段样本进行分类标注。通过Word2vec的CBOW模型进行无监督训练获得词向量词典,其中窗口宽度(Window)设置为5,词向量维度为300。构建图2所示的包含一个卷积层和一个池化层的卷积神经网络,为获取丰富的特征信息,在卷积层设置多种窗口卷积核对输入矩阵进行卷积操作,其中卷积核窗口宽度分别为3、4、5,每组窗口个数均为200,卷积核函数选取ReLU函数。池化层利用最大池化操作进行特征压缩。CNN的迷你批处理尺寸设置为60,迭代次数为60,Adam学习速率0.001。每组试验均采用十折交叉的方式进行。
在非均衡数据分类中,用准确率不足以充分评价分类器性能的优劣,因此基于混淆矩阵,选取精确率Precision、召回率Recall、F1-Measure和G-mean等[21-23]同时作为非均衡分类器的评价指标。对于一个M分类问题的混淆矩阵见表4。
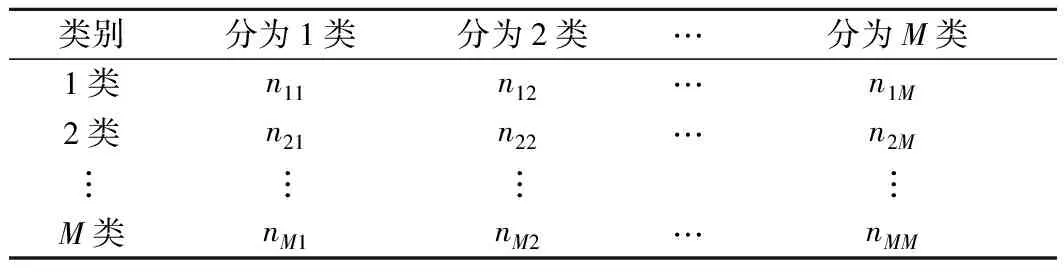
表4 混淆矩阵
矩阵中第i类被正确预测的样本个数为nii,nij为类别i被预测为类别j的样本个数,nji为类别j被预测为类别i的样本数。
根据表4,可定义性能指标为
(12)
(13)
(14)
(15)
试验处理平台为联想计算机,处理器为Intel(R) Core(TM) i5-7200,主频2.5 GHz,8 GB内存,120 GB固态硬盘,运行环境为Windows 10专业版64位。模型通过Keras框架实现,编程语言为Python 3.4。
3.2 试验参数设置与性能影响
3.2.1 卷积神经网络参数
为验证卷积神经网络参数对模型故障分类效果的影响,本文针对词向量维度、卷积核窗口宽度以及每组卷积窗口数目3个因素设置对比试验,见表5。由表5可见,在网络模型其他参数不变时,相较于100和200维的词向量表示,在300维词向量表示下,各项性能指标均有提升。因为通过训练词向量,克服了稀疏表示中存在的维灾难,将词语间的词性和语义关系表示为词向量间的空间距离,维度更高的词向量可包含更丰富、全面的文本特征和语义信息,对模型的分类有积极的影响。但训练时间也同时增长,因为词向量维度的提升将导致模型中并行数据维度急剧上升。在词向量维度一致时,相较于两种单尺寸卷积核窗口,用多尺寸卷积窗口提取文本特征时,性能指标均有所提升,说明采用多尺寸卷积窗口提取特征时可适应包含不同词数级别的文本长度变化,能够更全面地提取特征。当模型每组卷积窗口数目增加到一定程度后,分类F1-Measure和G-mean等指标出现了波动。通过模型参数对故障分类性能影响的比较,可知当词向量维度为300维,卷积三种窗口宽度为3、4、5,每组卷积窗口数目为200时,车载设备故障分类效果最佳。
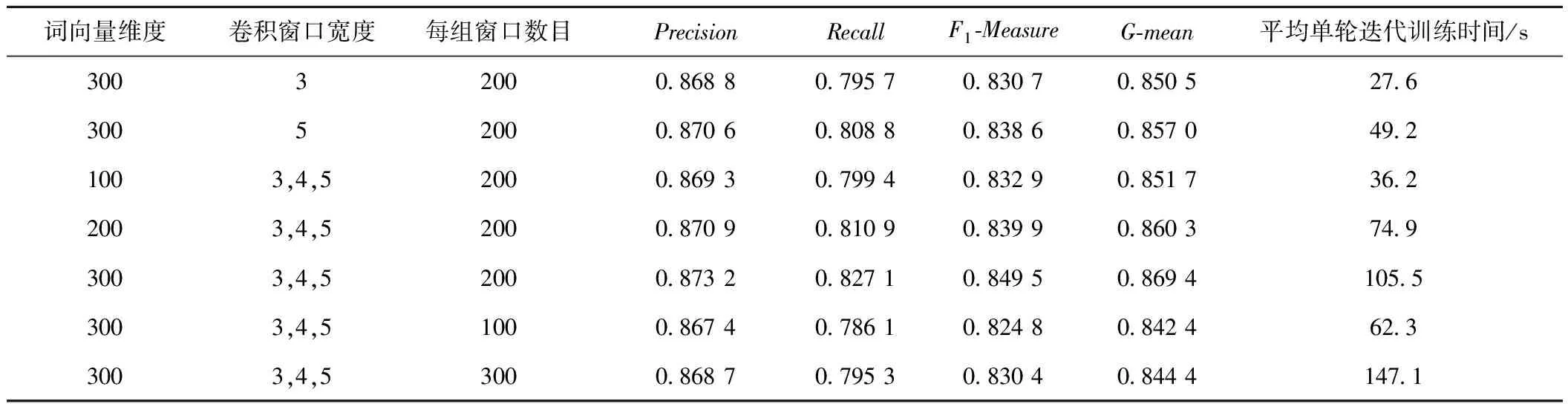
表5 卷积神经网络模型参数取值比较
3.2.2 焦点损失函数参数
焦点损失函数的核心是用一个合适的函数衡量不均衡类别间以及易分/难分样本间对总体误差损失的贡献,所以参数α和γ的取值尤为重要。本文对α和γ的取值对车载设备故障分类性能的影响进行测试,使用F1-Measure作为分类结果的评估指标,该指标综合考虑了分类精确率与召回率。测试结果见表6,当α=0.2,γ=0.5时,可以找到不均衡类别间以及易分/难分样本间的平衡点,此时F1-Measure值最高。

表6 焦点损失函数参数取值比较
因此,本文利用焦点损失函数训练模型,该方法能够降低不平衡、难分样本对模型训练的影响,使模型更加关注难分样本。
3.3 批归一化处理对分类性能的影响
为验证批归一化处理对本文提出的卷积神经网络在收敛速度及准确率上的影响,分别使用未加入BN层的CNN网络以及本文加入BN层的网络进行试验。两种网络在训练集上的损失值变化见图3,损失值越大,网络的预测值与真实值间的差距越大。从图3可以看出在训练阶段,加入BN层的网络比未加入BN层的网络损失值更小,且在训练初期,加入BN层的网络损失值下降速度更快,说明批归一化处理可以提升卷积神经网络的梯度下降过程的收敛速度。图4为两种网络在验证集上的准确率的变化趋势,加入BN层的网络性能稳定,提高了网络的泛化性,整个过程中分类准确率都高于未加入BN层的网络。

图3 训练损失值随迭代次数变化曲线

图4 验证准确率随迭代次数变化曲线
3.4 不同分类模型比较
为进一步验证本文模型对车载设备故障的分类性能,将其与其他分类模型进行对比,设定以经过CBOW模型训练所得的文本向量作为各模型的输入。在对比试验中分别验证SMOTE和焦点损失函数对卷积神经网络分类效果的影响,并与具有代表性的传统机器学习算法支持向量机(Support Vector Machine,SVM)进行对比。由于随机欠采样[15]也是数据层面处理不均衡分类的有效方法,因此也对其设置对比试验,不同分类方法比较见表7。

表7 不同分类方法比较
基于表7的统计结果,可以进行以下对比分析:
(1) 通过SMOTE方法对少数类样本自动生成,降低数据间不平衡程度,或者利用焦点损失函数训练模型,使模型倾向于少数类、难分样本,这两种方法都可以提升卷积神经网络的分类效果。且在最优参数条件下,焦点损失函数对模型的性能提升更多,表明焦点损失函数可以有效降低不平衡、难分样本对模型训练的影响。两种方式结合使用可以进一步提升卷积神经网络对车载故障的分类性能。
(2) 与传统机器学习分类方法SVM对比,本文模型在精确率Precision、召回率Recall、F1-Measure和G-mean等指标上均高于SVM。将SMOTE方法与SVM结合,分类效果得到提升,表明降低数据间的不平衡程度,有利于分类器的学习,但其分类效果不及SMOTE-CNN模型,说明由于CNN特征学习的作用,在处理车载记录数据时,能更加有效地从输入的文本向量矩阵中提取出有用信息,从而提高了模型的识别能力。
(3) 将随机欠采样方法与卷积神经网络结合,效果较SMOTE有差距,说明对多数类样本进行约简,虽然可以降低数据间的不平衡程度,提升模型的分类效果,但会造成多数类的样本信息损失,性能提升不理想。
4 结论
本文以列控车载安全计算机记录的AElog数据为基础,分析列控车载各模块故障形式,并对其文本数据进行预处理,利用CBOW模型实现文本分布式表示,完成文本数据的结构转化。通过SMOTE方法实现车载记录中少数类数据的自动生成,降低数据间的不平衡程度。以卷积神经网络为基础,结合AElog数据中各模块正常或异常工作时的标志性语句长短不一的特点,利用多尺寸卷积网络模型更全面地提取文本特征,避免了传统分类方法中人工特征选择的过程;加入批归一化层提高网络的泛化性,加快网络收敛,提升分类准确率;利用焦点损失函数训练模型,进一步避免不平衡、难分样本对模型训练的影响。通过对某铁路局列控车载实际运行数据的试验,将本文模型与其他模型进行对比,验证本文模型在分类精确率Precision、召回率Recall、F1-Measure和G-mean等指标上的优势。也为实现高速铁路列控车载设备故障诊断提供理论依据和使用价值。
