基于深度学习的司机疲劳驾驶检测方法研究
2021-07-30李小平
李小平,白 超
(兰州交通大学 机电工程学院,甘肃 兰州 730070)
随着全世界铁路运输里程及汽车营运数量的快速增长,火车司机和汽车司机人数也快速增加,同时由于司机疲劳驾驶引起的交通事故也逐年增高,以美国为例,交通事故中有25%~35%与疲劳驾驶有关[1-2],每年大约有1 500多人丧生于疲劳驾驶引起的车祸[3]。因此对司机疲劳驾驶状态进行检测并做出相应的预警,对于保障交通运输安全至关重要。
目前的疲劳驾驶检测主要有基于司机的测量方法及基于车辆的测量方法,基于司机的测量方法又分为生理特征、视觉特征[4]和语音特征[5]等多种方法。基于车辆的检测方法受路况及驾驶员技能的影响,准确性较差[6];基于生理特征的疲劳检测由于使用了昂贵的传感器,并且传感器的侵入可能引起司机不适,不便于普及推广[7-8];基于语音特征的疲劳检测只适用于采用标准呼叫应答的驾驶场景且语音标记样本数据较为稀缺;基于视觉特征的疲劳检测具有非接触性及可直接根据司机面部特征(如眼睛睁闭、打哈欠等)反应其疲劳状态等优点,成为目前研究的主流方向[9]。传统的基于机器视觉的司机疲劳检测算法主要采用人工设计特征加分类器的方式,通过手动特征设计、制定检测标准来进行疲劳判断,检测速度较慢、准确性较低[10];随着以卷积神经网络CNN为代表的深度学习模型在计算机视觉领域的成功应用,如面部器官检测[11]、人体姿态估计[12]等,基于视觉特征深度学习的司机疲劳检测成为该领域的研究热点。
在基于视觉特征深度学习的疲劳驾驶检测研究领域,文献[13]提出了一种基于RNN的司机疲劳检测技术;文献[14]提出了一种类Haar特征和极限学习的疲劳检测方法;文献[15]基于嘴部特征疲劳检测,应用了功能校准深度卷积模型RF-DCM,解决了说话和打哈欠的区分问题;文献[16]提出了一种基于MSP模型的多任务分层CNN疲劳检测系统,实现了面部检测及眼睛和嘴巴状态检测;文献[17]通过直方图预训练梯度模型HOG和支持向量机SVM提取眼睛、鼻子和嘴巴的位置并评估眼睛长宽比、张口比和鼻子长度比率进行疲劳检测;文献[18]提出了一个深层级联LSTM的驾驶员疲劳检测方法;文献[19]提出了应用多面特征融合双流卷积网络的司机疲劳驾驶检测模型,实现了动态图像与静态图像的综合检测;文献[20]提出了基于多形态红外特征与深度学习的实时疲劳检测方法,解决了夜间驾驶疲劳的检测问题。
综上所述,目前基于视觉特征深度学习的司机疲劳检测算法主要有基于RNN的方法[13]、基于CNN的方法[14-17]以及RNN与CNN的融合方法[18-20],一般采用滑动窗口加分类器方式,由于输入图像较大而导致系统耗时多[21],检测效率不高,而且当司机头部姿态变化(如侧脸、有遮挡等)时成像质量较差,准确率不高。针对上述问题,本文在前人研究的基础上,提出一种基于MTCNN-PFLD-LSTM深度学习模型的司机疲劳检测算法,首先采用多任务卷积神经网络(Multi-task Cascaded Convolutional Networks,MTCNN)对视频图像帧的目标区域内人像进行由粗到细的定位[22],提高定位效率,降低后续输入图像的尺寸;然后对人脸图像采用精度高、速度快的PFLD(Praclical Facial Landmark Detector)模型[23]进行68个关键点定位;最后根据P80原则计算出每帧图像的眼部、嘴部、头部3个疲劳参数,融合PFLD检测出每帧图像中人脸关键点的3个空间姿态角(偏航角,俯仰角,滚转角)共6个参数,输入长短期记忆网络(Long Short-Term Memory,LSTM)进行疲劳检测。该算法由于采用由粗到细的方法建模,加上PFLD模型结构小,并通过合理设计6个疲劳检测参数及加权累积损失函数,使得司机疲劳检测的准确率和效率得到了有效提升。
1 脸部疲劳状态表征
1.1 脸部轮廓定位
常见的人脸轮廓定位方法有5点、68点、98点定位,见图1。图1(a)中,5点定位仅包含左眼、右眼、鼻子、左嘴角、右嘴角5个位置,只能进行人脸轮廓定位,无法判断是否处于疲劳状态;图1(b)中,98点定位包含的人脸信息过多,会导致系统运算量大、识别效率低、实时性较差;图1(c)中,68点定位可以比较准确地描述人的脸部轮廓以及眼睛、嘴巴等局部特征,又减少了运算时间,提高了人脸识别的实时性[24]。在68点定位中,左眼有6个关键点(37~42),右眼有6个关键点(43~48),嘴巴有20个关键点(49~68),其余为脸部轮廓关键点。
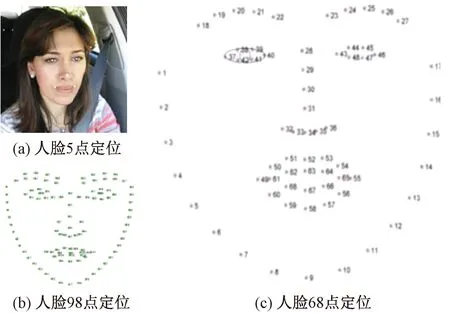
图1 人脸面部轮廓定位(图中人像来源于YawDD数据集[25])
1.2 眼部疲劳状态表征
眼部特征是一个重要的疲劳表征参数,可以直观反映司机是否处于疲劳状态。本文采用PERCLOS原则[26]判断眼部的睁闭状态,当眼睑遮住瞳孔的面积超过80%时就记为眼睛闭合。为基于PERCLOS原则的眼睛睁闭曲线见图2。

图2 基于PERCOLS原则的眼睛睁闭曲线
图2中,纵轴为眼睛的睁开程度Eopen,横轴为时间t,0~t1为眼睛从完全睁开到20%闭合所用的时间,t1~t2是眼睛从20%闭合到80%闭合所用的时间,t2~t3是眼睛完全闭合所用的时间,t3~t4是眼睛从20%睁开到80%睁开所用的时间。设这一时段内眼睛闭合时间所占的百分比为fp,则
(1)
眼睛可以看作是两个嵌套的椭圆,见图1(c)。假设眼睛睁开的宽度为w,上下眼睑的垂直距离为h,则眼睛的面积近似为S=πwh。以左眼为例,根据眼部采集到的关键点,人眼部的w、h的计算式为
(2)
式中:x37、x40为人左眼两端的关键点横坐标;y41、y39为人左眼眼睑上下右侧的关键点纵坐标。右眼同理,则眼部睁开百分比计算为
(3)
式中:wmax、hmax分别为眼睛完全睁开时的宽度、高度。将计算得到的Eopen按照PERCOLS原理计算出t1、t2、t3、t4,代入式(1)即可计算出fp,fp输入LSTM网络进行训练即可判断司机是否处于疲劳状态。
1.3 嘴部疲劳状态表征
嘴部的状态通常有3种:闭合、说话、打哈欠,人在疲劳时会较为频繁地打哈欠,因此嘴部的特征也是疲劳判定的一个重要参数。
嘴部的宽度wmouth、高度hmouth计算式为
(4)
式中:x49、x55为嘴部左右的两个关键点的横坐标;y51、y53、y57、y59分别为嘴部上下的4个关键点的纵坐标,通过计算其坐标的平均值获得嘴部高度。
司机在疲劳打哈欠时嘴巴的张开程度最大,嘴部会出现高度增加,宽度减少,为了衡量这两种指标表征的疲劳状态,引入嘴部纵横比Kmouth,其计算式为
(5)
将Kmouth输入LSTM网络进行训练即可判断司机是否处于疲劳驾驶状态。
1.4 头部疲劳状态表征
人在疲劳时头部容易出现频繁点头或者长时间低头的情况,因此可以将点头(低头)情况作为疲劳表征参数。人在低头时,摄像头拍摄的照片中两眼中点到达嘴巴的距离会比抬头时出现明显的缩短,故采用该距离的变化作为点头(低头)姿态的变化。
在图1(c)中,设
(6)
则两眼的直线函数为
(7)
式中:xleft、xright、yleft、yright分别为人左右眼中点的横纵坐标;x、y为两眼的直线函数横纵坐标。将式(7)化为标准型Ax+By+C=0时,可得到A,B,C的值为
(8)
再利用人脸两眼中点52号点计算到该直线的距离,即
(9)
d为图像上两眼中点到达嘴巴的距离。再以视频第一帧的pitch1计算俯仰角为0时的dmax,即
(10)
当d≤0.8dmax时可认定为司机处于低头状态。若低头超过3 s则直接判定为处于疲劳状态,若小于3 s则记入时间,计算头部低头时间所占时间的百分比,即
(11)
式中:tdown为低头时间;t为总时间;hdown为低头百分比,该数值越大则疲劳程度越深,hdown同样可以作为LSTM的输入进行疲劳状态判断。
2 基于MTCNN-PFLD-LSTM的疲劳驾驶检测模型
基于MTCNN-PFLD-LSTM的疲劳驾驶检测模型见图3。
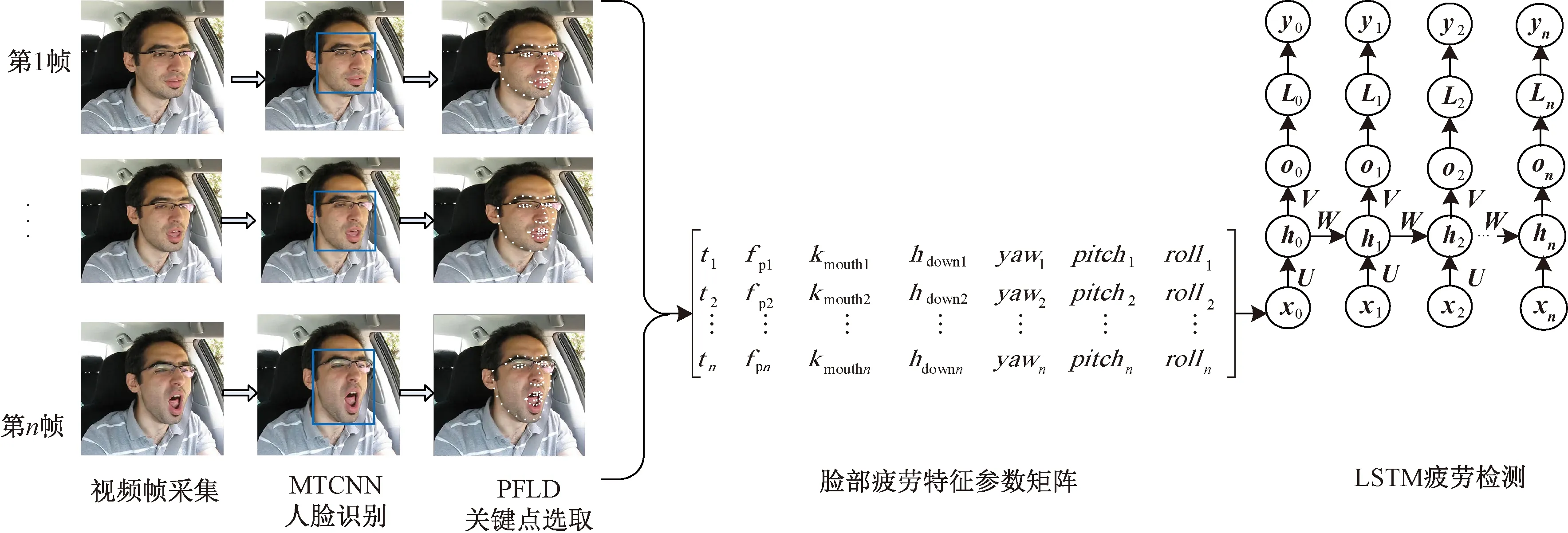
图3 基于MTCNN-PFLD-LSTM的疲劳驾驶检测模型(图中人像来源于YawDD数据集[25])
首先通过车载摄像设备实时获取司机的视频关键帧图像,通过MTCNN确定司机人脸的区域,然后将检测出的人脸区域采用PFLD模型进行人脸关键点检测,最后计算生成脸部疲劳特征参数矩阵,并按照视频时间序列将参数矩阵输入LSTM模型进行疲劳检测,通过softmax分类输出疲劳与非疲劳状态。
2.1 人脸区域检测
MTCNN是基于级联思想的深度学习模型,由P-Net(Proposal Network)、R-Net(Refine Network)、O-Net(Output Network)三层网络构成,能兼顾性能和准确率,可实现由粗到细的人脸检测。MTCNN的图像金字塔可以进行初始图像的尺度变换,P-Net模型用于生成大量的候选目标区域框,R-Net模型对目标区域框进行精选和边框回归,进而排除大部分的负例,O-Net网络对剩余的目标区域框进行判别和区域边框回归,从而实现人脸区域的5关键点检测定位,MTCNN模型结构见图4。
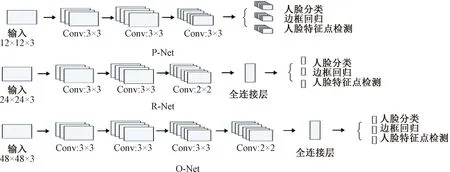
图4 MTCNN模型结构
(1)构建图像金字塔
对图片进行Resize操作,将原始图像缩放成不同的尺度,生成图像金字塔,便于实现多尺度人脸检测。
(2)P-Net网络
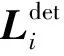
(12)

(3)R-Net网络
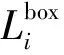
(13)
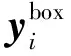
(4)O-Net网络
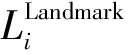
(14)

最终,MTCNN的损失函数L1为3个损失函数的加权累加,即
(15)
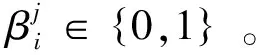
2.2PFLD人脸关键点检测
PFLD人脸关键点检测模型具有精度高、速度快、模型小的特点,特别适合算力不强的嵌入式移动设备,见图5。
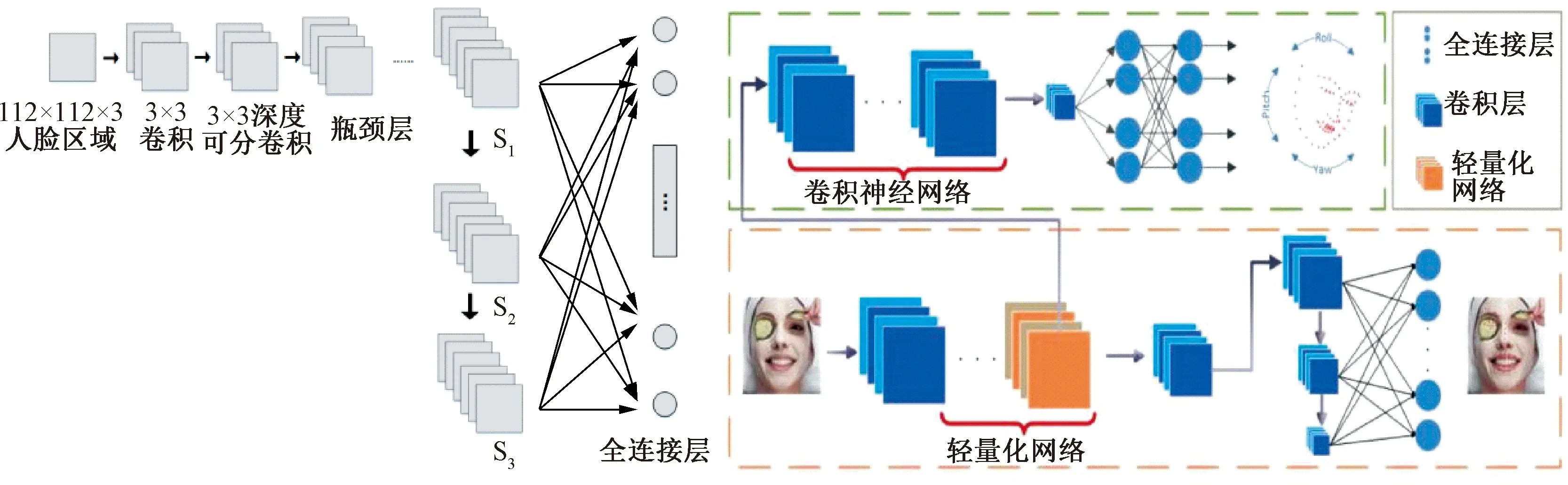
图5 PFLD模型
PFLD不仅可以通过主网络输出人脸的68个关键点,还可以通过辅助网络输出人脸的3个姿态角(偏航角yaw,俯仰角pitch,滚转角roll)。通过68个关键点及姿态角,可以根据式(1)、式(5)、式(11)计算出疲劳参数fp,Kmouth及hdown。
PFLD损失函数L2表示为
(16)
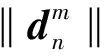
2.3 脸部疲劳状态参数矩阵
人的脸部疲劳状态可以根据眼睛(睁、闭)、嘴巴(闭合、说话、打哈欠)及头部偏航角yaw、俯仰角pitch、滚转角roll来综合表达。
在PFLD获得人脸的68个关键点后,对于连续时间节点序列(t1,t2,…,tn)上采集的视频图像帧(第1帧,第2帧,…,第n帧),每一帧图像可根据眼部、嘴部和头部关键点及yaw、pitch、roll角度计算出状态参数,生成脸部疲劳状态参数矩阵Xt为
(17)
2.4 基于LSTM网络的疲劳检测
LSTM模型是一种时间递归神经网络,旨在解决RNN的长期依赖与梯度消失问题,LSTM网络能够记住长期依赖关系,将前一时刻的网络输出选择性地记忆下来,为后续的网络学习提供丰富的事件关联性。LSTM网络见图6。
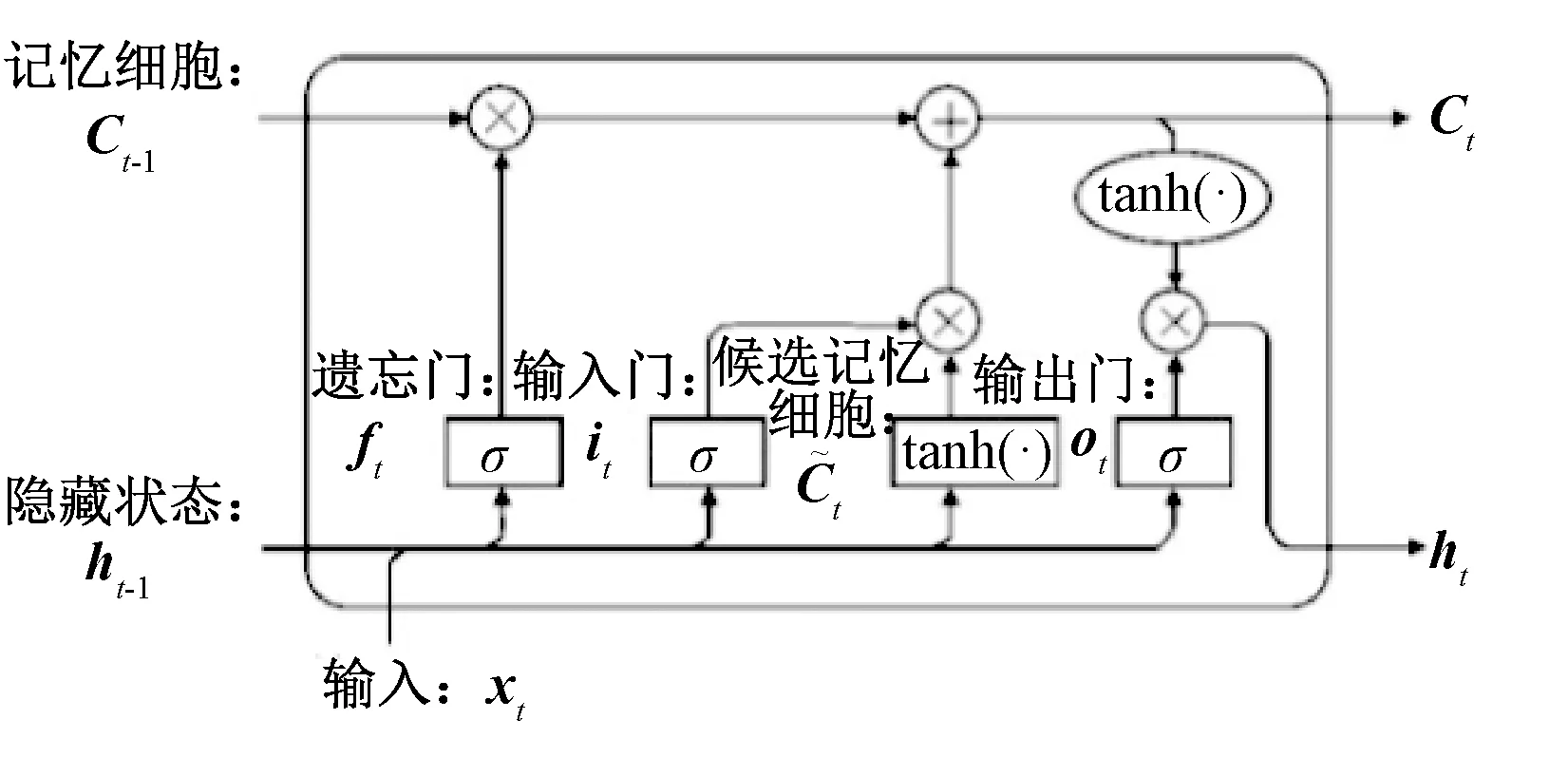
图6 LSTM网络
LSTM在t时刻的表达形式如下:
输入门为
it=σ(Wi×[ht-1,xt]+bi)
(18)
遗忘门为
ft=σ(Wf×[ht-1,xt]+bf])
(19)
记忆元胞单元为
(20)
(21)
输出门为
ot=σ(Wo×[ht-1,xt]+bo)
(22)
ht=ottanh(Ct)
(23)

在司机疲劳检测中,监控视频可以按帧分解成图片序列,按照时间顺序将每一帧图片的脸部疲劳状态参数矩阵Xt输入LSTM,即可实现运动状态下的司机疲劳状态判断。
LSTM输出为是否疲劳的分类状态,故采用softmax损失函数,由于softmax损失函数在分类时主要将不同类之间的差异最大化,但对于同类之内的样本差异不一定最小化,因此会使得模糊样本的特征提取效果不佳,从而影响分类的准确率,为此,本文引入中心损失函数Lcenter为
(24)
式中:xi为第i个视频疲劳特征矩阵;f(xi)为LSTM预测值;ci为该视频样本所属聚类的中心,聚类中心在初始阶段为随机确定;m为处理批次的大小,本文选用m=128,在之后每批次中更新聚类中心。则
L3=Lsoftmax+λLcenter
(25)
式中:L3为LSTM损失函数;Lsoftmax为softmax 交叉熵损失函数;Lcenter为中心损失函数;λ为中心损失权重。
采用加权累积方法计算MTCNN-PFLD-LSTM模型的损失函数L,则有
(26)
式中:J为训练样本数;k∈{1,2,3};ωk为MTCNN、PFLD、LSTM 3个处理过程中的损失函数权重值。
3 试验验证
基于视觉特征的火车司机和汽车司机疲劳检测需要在司机驾驶台上方安装视频采集装置,本文算法的原理相同,但由于采集装置、采集环境以及所采数据集的不同,导致MTCNN-PFLD-LSTM深度学习模型的训练参数会有所不同。由于篇幅限制,本文仅对汽车疲劳驾驶进行试验,以对算法的有效性进行验证。
3.1 试验环境及实验数据集
试验平台采用Intel(R)Core(TM)i5-4210,主频1.70 GHz,8 GB内存,配置较低。在Windows10环境下使用Tensorflow深度学习框架,采用Adam优化器,未使用GPU加速。
试验数据集使用YawDD视频数据集[25]和自采人脸图像数据集。YawDD数据集是一个公开的视频数据集,共有351个汽车司机驾驶视频,每个视频都标注了正常、说话、唱歌和疲劳打哈欠4种状态,本文将正常、说话、唱歌的状态标注为非疲劳状态,将疲劳打哈欠标注为疲劳状态[27]。人脸定位的精确度对于疲劳检测的结果至关重要,由于YawDD数据集中司机人数相对较少,用这些视频关键帧图像训练MTCNN模型时,样本数量略显不足,因此,本文从网络上不同的人脸图像数据集中采集了4 792张不同的人脸照片构成自采数据集,通过大量自采样本数据提高MTCNN模型训练质量,训练好的MTCNN网络模型直接用来对YawDD视频数据集中的关键帧图像进行人脸定位检测,弥补YawDD数据集样本较少的缺陷。图7为自采人脸图像数据集和YawDD数据集部分示例。

图7 自采人脸图像数据集和YawDD数据集(部分)
3.2 试验过程
Step1自采数据集人脸区域及关键点标注
样本标记的精确度对于深度学习的准确性至关重要,Labelimg是一个可视化的图像标定工具,通过可视化操作可保证标注的准确性,因此本文选用Labelimg软件为自采人脸数据集的4 792张照片添加人脸框以及关键点位置。自采集数据集中1419.jpg的Labelimg标注示例见图8。

图8 自采图像1419.jpg人脸区域及68关键点标记Labelimg标记
Step2MTCNN模型训练
将Step1中标注好的自采数据集的50%作为训练集,10%作为验证集,40%作为测试集。将训练集数据引入MTCNN进行训练,训练好的模型用验证集数据进行模型过拟合验证,然后用测试数据集进行测试,测试识别结果见表1。

表1 人脸区域识别结果
由表1可知,通过自采数据集对MTCNN模型进行训练,人脸区域识别率达到99.18%,取得了较好的训练效果。
Step3YawDD数据集中人脸区域识别
将YawDD数据集的每个视频文件按照关键帧分解出100张图片,共35 100张照片,输入训练好的MTCNN模型进行人脸区域检测,识别结果见表2。

表2 YawDD数据集中人脸区域识别结果
表2的识别率达到99.24%,比表1的识别率增加了0.06%,这也反映了虽然MTCNN模型参数不变,但数据集不同,网络输出结果会有一定程度的变化。
Step4YawDD数据集中人脸关键点检测
将Step3中检测出的人脸区域引入PFLD网络检测68个关键点,可得到所有关键帧照片的人脸关键点坐标,视频24-FemaleNoGlasses-Normal.avi中第10帧图像的人脸关键点坐标及姿态角见图9。

图9 24-FemaleNoGlasses-Normal第10帧图像人脸关键点坐标及姿态角
图9(a)为视频24-FemaleNoGlasses-Normal.avi中第10帧图像的人脸关键点及姿态角,蓝色关键点为标记点,红色关键点为检测点。35 100张视频帧照片的关键点检测结果见表3。

表3 人脸关键点检测结果
Step5计算疲劳参数矩阵
将Step4中检测出的关键点坐标及姿态角按照式(1)、式(5)、式(11)可以计算出相应的疲劳特征参数。视频24-FemaleNoGlasses-Normal.avi的疲劳参数计算结果见表4(前10帧)。
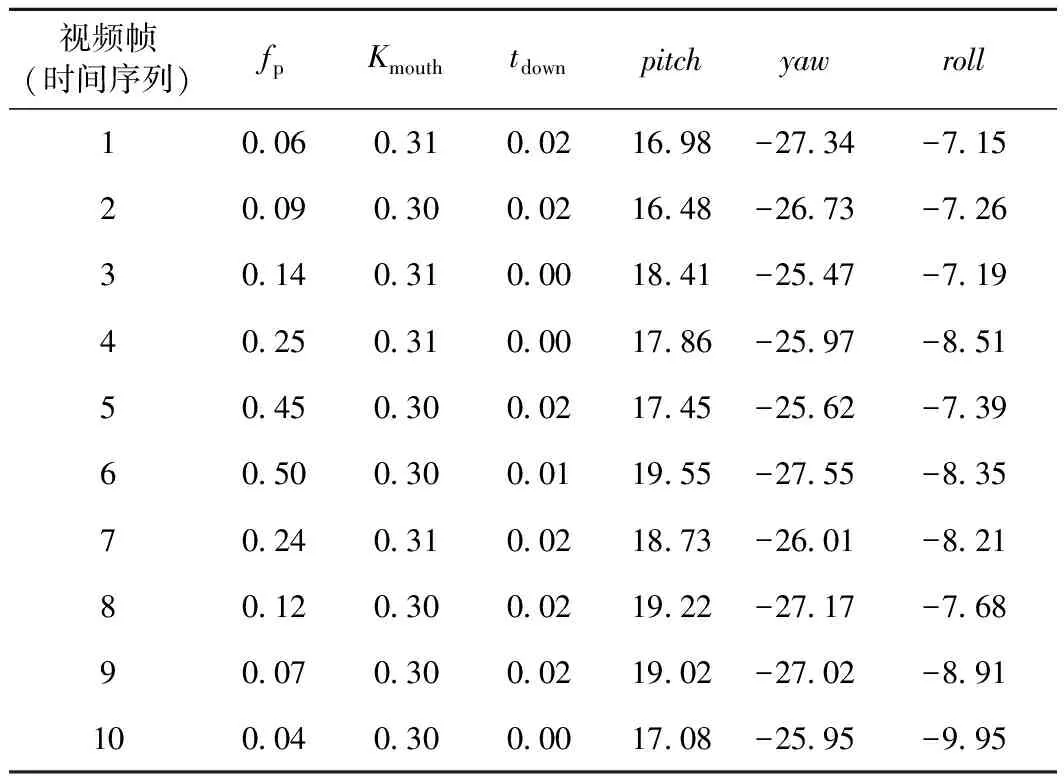
表4 视频24-FemaleNoGlasses-Normal疲劳参数计算结果(前10帧)
Step6LSTM疲劳检测
将Step5中计算出的疲劳参数输入LSTM网络,其中将223个视频(63.5%)作为训练集,128个视频(36.5%)作为测试集,学习率为0.001,最后通过softmax得到疲劳检测结果,见表5。

表5 疲劳检测结果
3.3 试验结果分析
司机疲劳状态检测属于分类问题,可以采用准确率以及检测帧率FPS来进行评估[28]。
根据表5可以计算出MTCNN-PFLD-LSTM疲劳检测准确率,结果见表6。
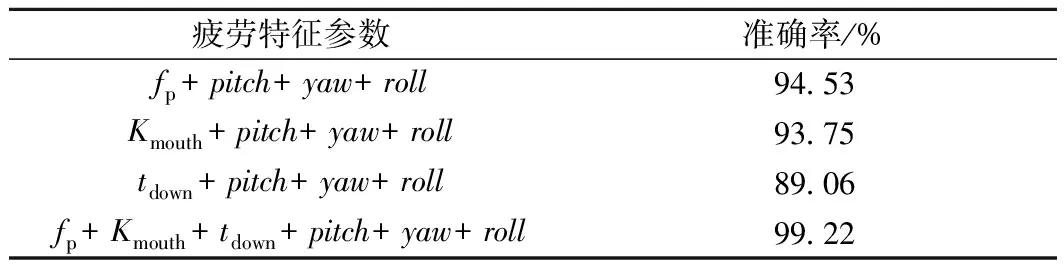
表6 MTCNN-PFLD-LSTM疲劳检测准确率
从表6可以看出,分别使用fp、Kmouth、hdown与3个空间姿态角yaw、pitch、roll共4个参数训练网络时,检测准确率分别为94.53%、93.75%、89.06%,而将fp、Kmouth、hdown与yaw、pitch、roll角度共6个参数输入网络训练时,检测准确率达到99.22%。
3.4 损失函数loss
损失函数loss用来表现预测值和实际值之间的差异程度,权重ωk的不同取值对于实验结果影响较大。假定ω1变化、ω2=ω3,分析ω1的变化对loss的影响,选取ω1∶ω2∶ω3=0.1∶0.45∶0.45、ω1∶ω2∶ω3=0.3∶0.35∶0.35、ω1∶ω2∶ω3=0.5∶0.25∶0.25、ω1∶ω2∶ω3=0.7∶0.15∶0.15,损失函数图像见图10(a),可以看出,当ω1权重较低时模型收敛速度较慢,损失函数loss增大、准确率降低,故应增大ω1的权重,充分验证了人脸图像分割精度对于疲劳检测的重要性,但当ω1取值过高时(如ω1=0.7),模型收敛速度反而又会降低,经过反复试验,当ω1=0.5时模型收敛速度快、准确率高。当ω1=0.5时,分析ω2、ω3变化对loss函数的影响,分别取ω2=0.1、ω3=0.4,ω2=0.2、ω3=0.3,ω2=0.25、ω3=0.25,ω2=0.3、ω3=0.2,ω2=0.4、ω3=0.1,loss曲线见图10(b),可以看出,当ω2=ω3=0.25时模型收敛速度快、准确率高。经过反复试验,最终确定权重ωk的取值为ω1∶ω2∶ω3=0.5∶0.25∶0.25。
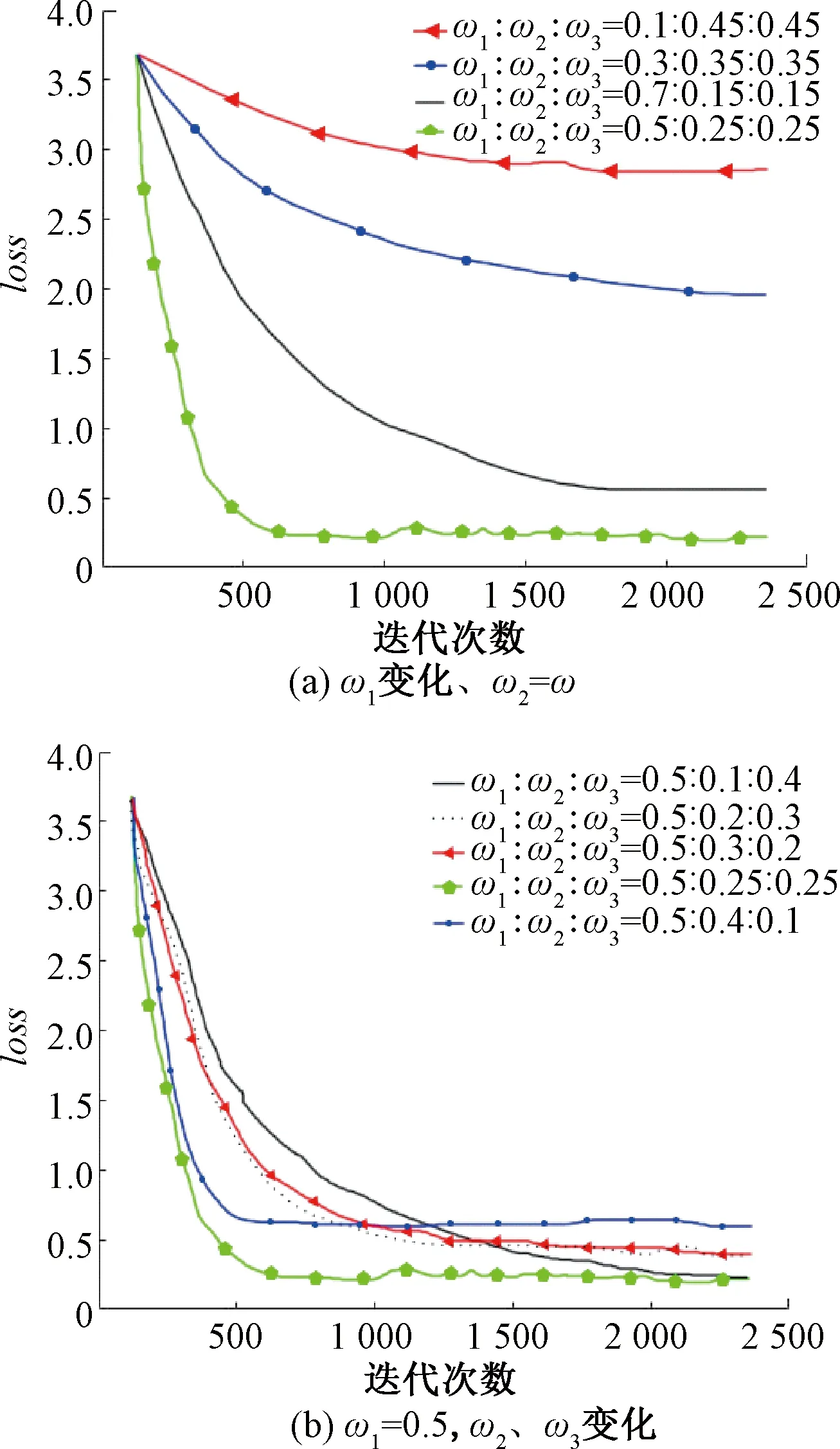
图10 权值ωk取不同值时的loss曲线
当ω1∶ω2∶ω3=0.5∶0.25∶0.25时,通过损失函数曲线可以看出该模型收敛速度较快,在训练了500张图像时的损失值和训练2 500张图像时的损失值相差不大,在训练到2 500张图像时损失函数波动很小,显示出模型具有较好的鲁棒性。
为验证本文算法的优越性,和其他最新的疲劳检测算法进行对比,结果见表7。
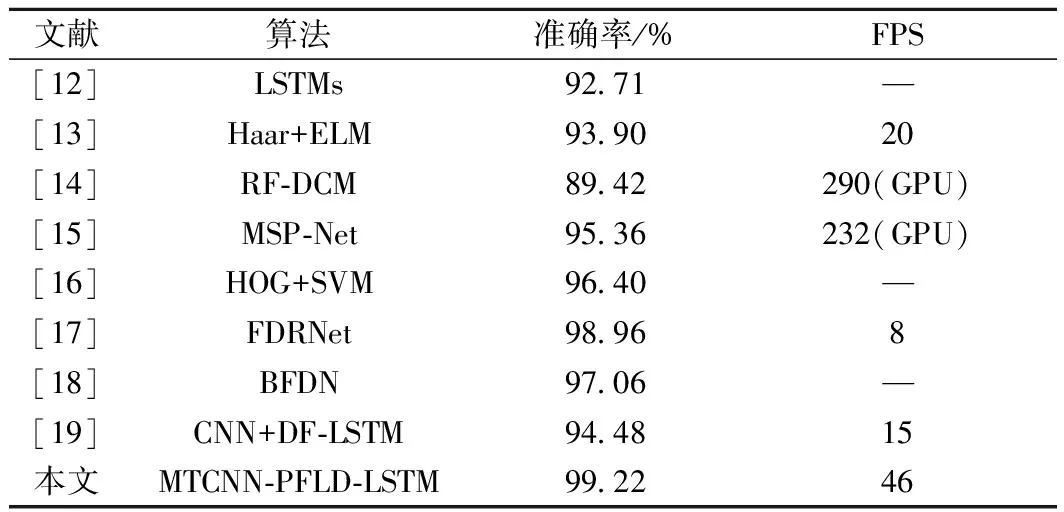
表7 对比实验结果
由表7可以看出,本文在低算力设备及无GPU加速情况下,采用MTCNN-PFLD-LSTM算法,准确率达到99.22%,检测帧率达到46;本文检测准确率比第2的模型(文献[17])增加了0.26%,检测帧率FPS比性能第2的模型(文献[13])增加了1.3倍。文献[14]和文献[15]由于采用了GPU加速,所以FPS较高,但是硬件配置要求较高;文献[17]的检测准确率较高,但是检测帧率为8,运算效率较低。对比试验结果表明,本文提出的算法在低算力设备上应用时耗时较少,检测准确率较高,综合检测效果较好。
4 结论
本文采用MTCNN-PFLD-LSTM模型进行司机疲劳驾驶检测,无须GPU加速,便于在移动设备等低算力设备上应用。通过优化MTCNN-PFLD-LSTM模型在不同阶段任务的损失函数权重,在YawDD数据集中的检测准确率达到99.22%,检测帧率达到46,检测的效率与准确性较好,能够满足基于视觉特征的司机疲劳驾驶检测要求。
