基于稀疏性深度学习的航拍图像超分辨重构
2021-07-27王彩云李阳雨李晓飞王佳宁魏文怡
王彩云, 李阳雨, 李晓飞, 王佳宁, 魏文怡
(1.南京航空航天大学航天学院, 江苏 南京 210016; 2.北京电子工程总体研究所, 北京 100854)
0 引 言
随着无人机技术研究的飞速发展,航拍图像成像效果要求也日益严格。图像超分辨(super-resolution, SR)重构技术旨在从低分辨(low-resolution, LR)图像中恢复高分辨(high-resolution, HR)图像,HR图像具备边缘锐化、无块状模糊等特点,便于后续的图像处理、分析与理解等工作。
目前图像SR重构方法可分为基于重构和基于学习这两类方法。基于重构的方法[1-3]被广泛研究,其核心在于利用已知的图像退化模型,约束SR产生的HR图像与输入LR图像间的映射关系[4-5];基于学习的方法是近年来的热点,高、低分辨率图像间的映射关系通过学习获取,这种方法能获取更多高频细节,因此图像重构效果更好。该方法根据利用的图像特征不同分为基于机器学习和基于深度学习两类。2002年,Freeman[6]等人首次将机器学习应用于图像重构任务,但重构图像质量较低。Dang[7]等人提出了一种基于局部HR补丁流形切线空间估计的图像SR方法,同样具有计算复杂度较高的问题。基于稀疏表示的机器学习重构方法受压缩感知理论启发,杨学峰[8]等人对训练图像在小波域的不同频带建立不同的字典,利用全局限制求取HR图像的初始解,最后在小波域对初始解进行多字典稀疏求解,能够重建出质量更高的图像,并且计算复杂度有所下降,但是基于稀疏表示的重构需要求解超完备字典的稀疏表示[9-10]。Timofte[11]与Yang[12]同样研究基于稀疏字典的图像SR重构方法,均存在当字典规模或待重构图像的尺寸较大时,计算复杂度仍较高的问题。Dong[13]等人首次将深度学习应用于图像SR,通过不同的神经网络学习方法获取LR图像特征与HR图像特征映射关系并进行图像重建,获得更高质量的图像。吴磊[14]等人在神经网络中引入多尺度思想,优化图像SR效果。
深度学习在数学上拥有更加简单的表达,具有很强的泛化学习能力,在分类任务、自然语言处理、目标检测、运动建模等领域[15-16]的应用已取得成效,因此本文利用深度学习方法进行SR重构。另外,在硬件条件一般的情况下,基于深度学习方法的训练阶段耗时较大,而本文方法通过构建一种稀疏卷积神经网络SR(SR based on sparse convolutional neural network, SRSCNN)重构方法,显著缩短训练时间,能够在更短时间内实现图像重构,满足实时性要求。
1 图像SR重构理论
1.1 SR重构原理
常见的图像退化过程X→Y可表示为
Y=HX+n
(1)
式中:H为退化因子,表征退化模型的形变、模糊和降采样等过程;n为噪声。
退化模型如图1所示。

图1 图像退化模型
图像SR是图像退化的逆过程,求解过程是不适定问题。基于深度学习的SR重构能够学习高、低分辨图像之间的端到端映射关系,其算法框架如图2所示。

图2 基于深度学习的SR重构算法框架
1.2 图像质量评价方法
图像质量评价在图像处理系统中,对算法分析比较和系统性能提供度量指标[17]。图像质量评价存在主观评价与客观评价两个分支。主观评价是观察者对图像的主观定性评价。客观评价一般为借助特定数学模型计算的图像质量量化值,同时也常用图像质量量化值与主观观测值的一致性来评估图像质量。常用的客观评价标准有峰值信噪比(peak signal to noise ratio, PSNR)、信息熵(information entropy, IE)和结构相似度(structure similarity, SSIM)[18]。
假设原始图像I与测试图像K像素为m×n,则
(2)
(3)
式中:MSE表示图像均方误差;MAX表示图像的灰度值极大值,在8 bit的灰度图中,MAX为255。
PSNR表征图像失真度,单位为dB,PSNR值越大表示测试图像与参考图像之间的失真度越小,图像质量越高。这种方法从图像的全局统计角度衡量图像质量,未考虑人眼的局部视觉因素特征,故PSNR的评价结果与人眼主观不一致。相对于PSNR,SSIM是一种符合人眼视觉系统特征的图像质量客观评价指标,根据图像像素间的相关性构造测试图像与参考图像之间结构相似性,并由图像的均值、标准差和协方差定义亮度、对比度和结构相似度。3个相似度综合就是SSIM指标:
SSIM(i,j)=[l(i,j)]α[c(i,j)]β[s(i,j)]γ
(4)
式中:l(i,j)为亮度相似度;c(i,j)为对比度相似度;s(i,j)为结构相似度;参数α、β、γ一般取值为1。
由于航拍图像的SR重构是自动目标识别的预处理部分,显著性区域的质量比全图质量更为重要,因此本文将梯度模相似性偏差(gradient magnitude similarity deviation, GMSD)[19]与显著图检测融合,提出一种新的图像质量评价方法,即基于显著性区域的GMSD(saliency-map-based GMSD, SGMSD)。流程如图3所示。

图3 SGMSD流程框图
具体步骤为:首先检测输入图像的显著性区域,得到显著图Vs(i);接着计算图像的梯度模相似图GSM(i);然后引入显著图,得到基于显著图检测的梯度相似图SGSM(i);最后计算其相似性偏差即为SGMSD图像质量评价指标。流程可以简单描述如下。
步骤 1采用FT算法计算图像显著性图Vs(i)。
步骤 2计算图像的梯度模相似图GSM(i)。
步骤 2.1Sobel梯度算子
设水平和竖直方向的Sobel算子Gx、Gy为
(5)
步骤 2.2梯度模相似图计算
由式(6)和式(7)计算输入图像I与参考图像R的梯度模mI与mR分别为
(6)
(7)
式中:I(i)与R(i)表示以i为中心位置的图像区域。
接着由式(8)计算梯度模相似图GSM(i)为
(8)
式中:c为极小正常数,以防分母为0。
步骤 3计算基于显著图的梯度模相似图SGSM(i):
SGSM(i)=GSM(i)Vs(i)
(9)
步骤 4最后计算SGSM(i)的相似度偏差SGMSD,即为所求评价指标:
(10)
(11)
式中:SGMSD的值越大,表明梯度相似度越高。
2 SRSCNN重构
2.1 概述
Dong[20]等人提出的加速图像SR卷积神经网络(convolutional neural network, CNN)(fast SR CNN, FSRCNN)是一种紧凑的沙漏形CNN结构,相比于最早的SRCNN[7],其SR重构效果更好,并且可以在通用CPU上实现实时性能。同时,神经网络模型的稀疏技术能优化神经网络性能,提高模型的泛化能力。代表性的稀疏方法有参数剪枝、低秩分解、参数量化和知识蒸馏4种[21]。相关研究发现,人体的脑部结构网络的连接密度会随着年龄增长反而逐渐减小,但是脑部学习能力却不断增强。推理可得,若删除神经网络中较小的连接,减少神经网络的连接密度,将能够加速网络的推理和训练过程,有效降低计算成本。因此,本文采用参数剪枝的模型稀疏方法,优化FSRCNN网络。
本文基于FSRCNN的网络结构,提出SRSCNN,包含7个卷积层和1个反卷积层,每个卷积层的激活函数均选择PReLU函数,损失函数采用欧氏距离。SRSCNN网络结构如图4所示。
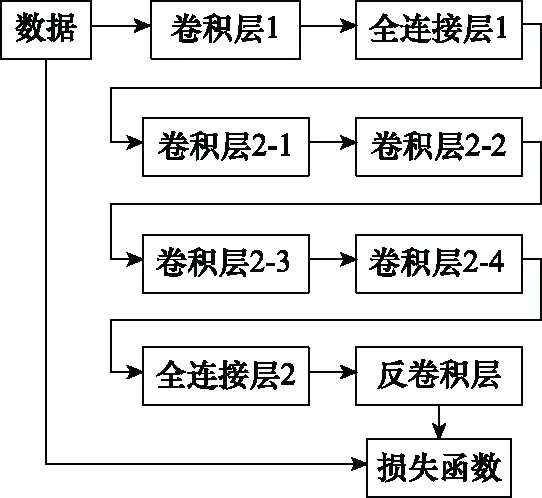
图4 SRSCNN网络结构
为减少网络参数,本文提出的SRSCNN网络结构中各卷积层的和反卷积层的参数设置如表1所示。

表1 SRSCNN网络参数设置
2.2 样本库建立
常见的通用图像数据集有Set 5、Set 91、General-100、CIFAR-10、ImageNet等。本文选用Set91和General-100作为训练集,选用Set 5作为测试集。为提高模型的泛化能力,采用数据增强的方式扩充样本:将样本库内图像均旋转90°、180°、270°。对样本库中的HR图像进行3倍下采样处理,并将得到的高、低分辨率图像进行分块,每个图像块的大小为7×7。
2.3 网络训练
SRSCNN的训练过程类比传统神经网络训练方法,包含前向传播、损失计算、后向传播、权重更新4个阶段。
初始化卷积核的权重W和偏置b,那么,前向传播过程可表示为
(12)
式中:f为非线性激活函数,用于解决线性不可分的问题,提高神经网络分类能力。
前向传播后,由输出计算损失函数L,并由梯度下降法更新权重和偏置:
(13)
SRSCNN稀疏化的具体步骤为:假设第t层有N个神经元,根据当前层权重W大小,对权重进行排序,丢弃权重较小的部分连接,保留权重较大的连接,依次对中间6个隐含层的权重进行选择性筛选,达到稀疏网络的目的,筛选策略如算法1所示。

算法1 SR重构网络权重筛选策略 设置S=sort(|W(t)|);k=N×s;λ=S(k);以λ为阈值选择权重Mask=(|W(t)|>λ);while当前为隐藏层W(t)=W(t-1)-η(t)Δf(W(t-1),x(t-1));W(t)=W(t)·Mask;t=t+1;end
其中,s为设定的稀疏度,本文设为0.7。
稀疏连接的神经网络能够减少参数个数,降低运算复杂度。
3 实验结果与分析
本文实验在inter core i7-8750H @2.20 GHz内存为8 GB的Win10环境下进行,使用Caffe深度学习框架。将原网络训练0.5×105次的模型取出进行稀疏化,稀疏化后的新网络继续训练。本文实验选择图像质量评价以及算法运行时间作为算法性能评判标准,对实验结果进行分析。
以尺寸为457×343的航拍图像为例,从主观视觉效果看,SRSCNN具有较好的重构效果,如图5所示。

图5 航拍图像SR重构效果
SRSCNN能够大大缩短训练时间,如图6所示。以航拍图像为例,SRSCNN迭代1×105次时,PSNR值为28.2;而原网络FSRCNN需要迭代约2.1×105次才能够得到相同的PSNR值。

图6 PSNR随迭代次数变化
选取两种网络训练3×105次的模型与Bicubic方法进行对比验证实验,将Set 14数据集中的lenna、baboon、comic、flowers和face 5张自然图像作为实验对象。表2~表4分别是3种重构算法下的重构图像的PSNR,SSIM,SGMSD评价指标对比结果。

表2 重构图像PSNR值

表3 重构图像SSIM值

表4 重构图像SGMSD值
可以看到,在相同情况下,SRSCNN算法输出图像的PSNR、SSIM、SGMSD评价指标值普遍更高,图像重构效果更好。
为对比算法的实时性能,分别将不同重构方法对相同的图像重复运行500次,计算平均重构时间。表5所示为各方法的平均重构时间。

表5 平均重构时间
由表5所示可看到,对于尺寸约300×300~500×500的图像,SRSCNN的重构速度约7~16 fps,达到实时性能。SRSCNN可以在不影响重构效果的情况下缩短训练时间。
4 结 论
深度学习理论以其强大的学习能力,在图像处理领域逐渐流行,其优越的数据处理能力有助于降低硬件设备要求。为加快网络模型学习能力,本文提出了一种稀疏化的神经网络SRSCNN,包含7个稀疏连接的卷积层和一个反卷积层,实验通过PSNR、SSIM、SGMSD这3种图像质量评价方法证明该网络结构能够避免过拟合,并且在不影响重构效果和计算速度的情况下缩短训练时间。SRSCNN的重构速度较快,能够达到实时性的要求,符合航拍图像的处理环境。
