基于知识表示学习的知识可信度评估
2021-07-27张晓明孙维雅王会勇
张晓明,孙维雅,王会勇
(河北科技大学信息科学与工程学院,石家庄050000)
0 概述
随着知识图谱的快速发展,一些如DBpedia[1]、Freebase[2]和WordNet[3]等大规模开放知识图谱和领域知识图谱,已成功应用于智能问答、语义搜索与推荐、大数据分析与决策等任务以及金融和医疗等领域。然而,由于现实世界知识的迅速更新和增长,大量的知识未存在于构建好的知识图谱内,需要及时对知识图谱进行更新以满足应用需求。在更新过程中,不可避免地会引入一些噪声和冲突,影响了知识图谱的质量,因此,对知识的可信度进行评估是知识图谱构建过程中的重要步骤。传统的知识可信度评估主要依靠人工标注和监督的方式[4],造成了人工以及时间成本的浪费。因此,构建一个高效的知识可信度评估模型具有重要意义。可信度评估模型通过对知识的可信度进行计算,处理引入的噪声,降低知识图谱内的噪声和冲突,提高知识图谱内的知识质量,从而推动知识图谱自动化构建工作的进展。
知识可信度评估旨在使用已知的背景信息对三元组的可信度进行计算。具体地,对于三元组的可信度,使用一个[0,1]区间的数值进行衡量,数值越接近0,三元组成立的可能性越小,数值越接近1,三元组成立的可能性越大[5]。目前,对于知识可信度评估的研究主要采用基于表示学习的方法,具有良好性能表现的模型包括基于交叉神经网络结构的可信度计算模型KGTtm[5]、带置信度的知识表示学习模型CKRL[6]和一系列基于CKRL 进行改进的模型[7-8]以及基于规则的表示学习可信度计算模型[9-11],这些模型利用知识图谱的内部信息对三元组知识的可信度进行计算,保持信息的全局一致性,但是没有充分利用实体类型信息、文本描述信息和图像信息等外部信息。
本文建立一种基于表示学习的知识可信度评估模型PTCA,在保证背景信息全局一致性的前提下,结合知识图谱外部信息和内部结构信息,利用实体关联强度、实体类型以及多步关系路径信息对三元组知识的可信度进行计算。设计一种通过实体类型信息判断关系可靠性的方法,将待验证的三元组中两实体的实体类型信息以及关系类型信息进行匹配,依据匹配程度得出关系的可靠性,在存在噪声的FB15k-N1、FB15k-N2、FB15k-N3 和FB15kNM 数据集以及FB15k、FB40k 数据集上对PTCA 进行评估,以验证其可信度计算能力。
1 相关工作
知识可信度评估主要包括基于本体、基于概率图模型和基于知识表示学习的方法。
1.1 基于本体的可信度评估
基于本体的知识可信度评估主要使用本体中已经存在的概念对知识进行评估,这种方法的可解释性强,但是由于无法及时更新,概念的可扩展性较差。基于本体的评估方法从不同角度对可信度进行评估,包括依据本体概念以及本体映射信息进行可信度评估的方法[12]、依据内容以及节点信息进行可信度评估的方法[13-14]。
1.2 基于概率图模型的可信度评估
基于概率图模型的可信度评估方法将实体和关系建模成图模型,利用先验知识确立关联约束关系,进而对知识的可信度进行评估。此类方法的可解释性强,而且可以简化运算。基于概率图模型的可信度评估方法包括基于概率图模型且结合路径排名的算法[15]、神经网络使用先验知识进行评估的方法[4]以及基于马尔科夫逻辑网络[16]的可信度评估方法。
1.3 基于知识表示学习的可信度评估
自从BORDES 等人提出基于平移假设的TransE模型[17]之后,出现了一系列基于TransE 模型的知识表示学习模型[18-20],从而使基于知识表示学习对知识可信度进行评估的研究成为热点[21]。基于知识表示学习的可信度评估原理是将知识图谱内的实体和关系嵌入到相同的低维向量空间中,通过向量之间的运算对知识的可信度进行计算。将知识的可信度计算问题转化为向量间的计算问题,降低计算复杂度,简化复杂问题,但是同时降低了问题的可解释性。基于知识表示学习进行可信度计算的方法可以分为两类:利用背景信息基于知识表示学习进行计算的方法,利用规则基于知识表示学习进行计算的方法。
利用背景信息基于知识表示学习进行计算的方法通过背景信息中的内容对知识的可信度进行评估,因此,其表现效果容易受到背景信息内容的影响。JIA 等[5]在平移假设的基础上结合两实体之间的关联强度以及对可达路径的推理,提出一个基于交叉神经网络结构来衡量三元组可信度的模型KGTtm,该模型综合利用知识图谱内三元组的信息以及全局推理信息,从实体、关系和全局三个层面对三元组的可信度进行评估。XIE 等[6]提出一种带置信度的知识表示学习框架(CKRL),基于平移假设,使用三元组的实体、关系以及实体之间的路径信息,提出三元组置信度的概念,并把置信度引入知识表示学习,从而发现知识图谱中潜在的噪声和冲突。SHAN 等人[7]以CKRL 为基础,通过对知识图谱中已有的三元组知识替换实体后形成的负样本进行评估,形成对带噪声的知识图谱中的负样本知识进行评估的方法NSM。ZHAO 等[8]在CKRL 框架的基础上结合实体类型信息以及实体文本描述信息,提出对知识可信度进行评估的方法SCEF。上述一系列模型主要通过可信度对知识表示学习的效果进行强化,未获得三元组可信度计算的直接结果。
利用规则基于知识表示学习进行计算的方法通过制定的规则对知识的可信度进行评估,但是由于规则的作用域、时间、数量以及规则之间的相互作用的限制,使用该方法对三元组的可信度进行评估时存在一定的局限性。MINERVINI 等人[9]通过指定规则的可信度级别,简单考虑关系的等价性和逆向性,对规则的可信度进行评估。规则增强的知识表示学习方法[10]首先对知识图谱内的知识进行规则的挖掘以及推理,然后对规则的支持度以及置信度进行计算,得到规则的可信度。SHU 等[11]提出软规则的概念,即一种带可信度的规则,并且依据已有知识以及软规则对知识进行评估和筛选,从而获得更加可信的知识。利用规则进行计算的方法首先需要对规则进行挖掘以及推理,然后利用已知的规则进行可信度计算。因此,必须具有完备的规则才能获取更高的准确性。
本文利用背景信息基于知识表示学习进行可信度计算,考虑到背景信息的丰富性对计算效果的影响以及保持信息全局一致的必要性,选取实体类型信息[22]以及知识图谱内部信息作为背景信息,以进行三元组知识可信度计算。
2 问题描述
随着知识图谱的应用和发展,高质量知识的需求量不断增加,而现有的知识图谱内存在的噪声和冲突导致知识的质量不高,为了提高知识图谱内知识的质量,需要对知识的可信度进行评估,筛选出高质量的知识。图1所示为本文主要任务描述,依据已知的背景信息对知识图谱内三元组知识的可信度进行计算,进而得到带可信度的知识,其中,已知背景信息包括内部信息(关系路径、实体关联强度)和外部信息(实体类型)。
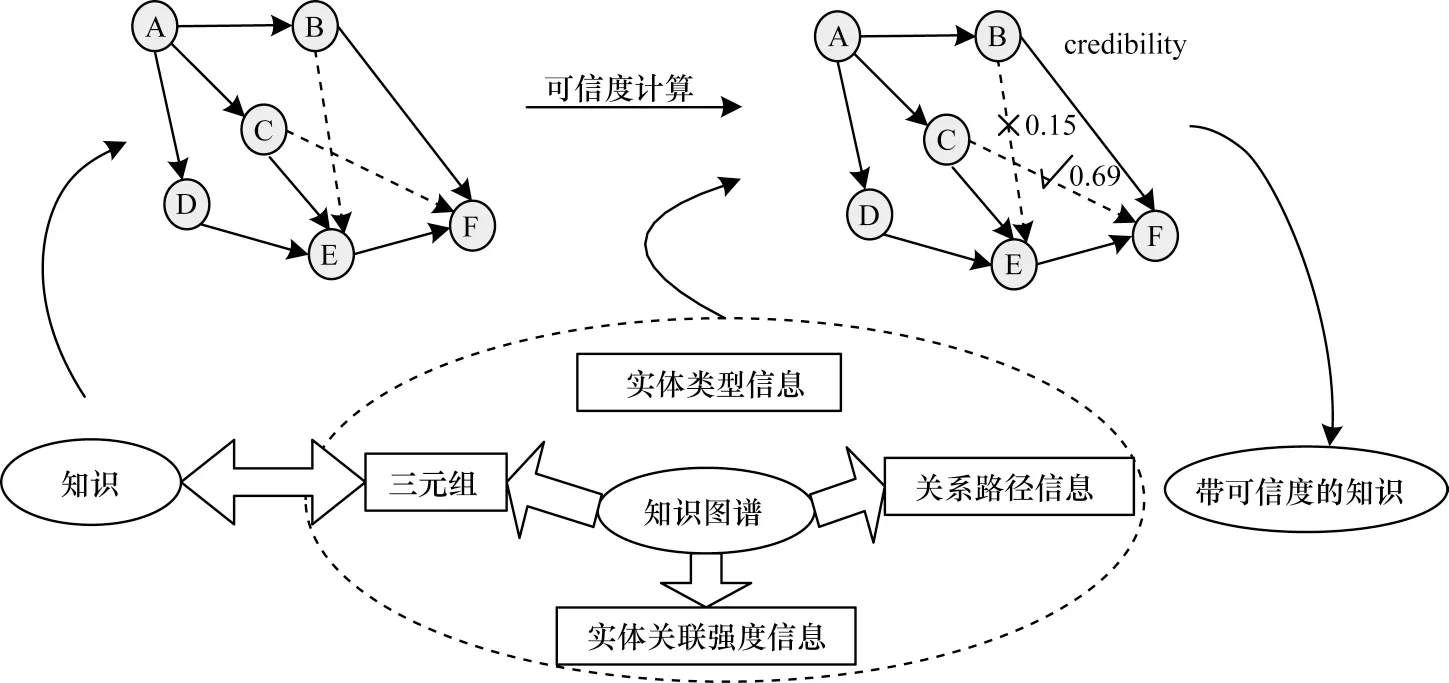
图1 主要任务描述Fig.1 Main tasks description
3 基于PTCA 模型的知识可信度计算
3.1 PTCA 模型及方法概述
对本文使用的符号进行定义,将三元组表示为(h,r,t)∈T,其包括头实体h、尾实体t以及连接头实体和尾实体的关系r,且h、t∈E,r∈R,其中,E和R分别代表实体集和关系集。ei(i=1,2,…,n)表示实体i,rj(j=1,2,…,n)表示实体对之间的关系j。EET表示实体类型,RRT表示关系类型。EET(ei)表示实体ei的实体类型,RRT(rj)表示关系rj的关系类型。
本文对基于多步关系路径的知识表示学习模型(PTransE)[23]进行改进,设计PTCA 模型。PTCA 模型主要包括3 个方面:1)通过实体间的关联强度对实体间出现关联的可能性进行计算;2)结合实体类型信息衡量两实体之间存在的关系;3)构造两实体之间的关系路径,利用多步关系路径信息进行计算。为确保信息结合的有效性,要保证信息以及结合方式的有效性。实体关联强度信息基于实体携带的资源以及实体之间的资源数量,类型信息数据采用经过验证的TKRL[22]提取的类型实例以及关系类型信息,多步关系路径信息通过计算路径p与直接关系r的相似度进行衡量,同时使用不改变结果数据趋势的转换函数来确保结果有效。3 种信息的计算结果通过能量函数进行结合,通过计算损失函数的方式迭代进行表示学习,从而确保信息结合方式有效。PTCA 模型结构如图2所示,其中,C1表示通过实体间关联强度计算的结果,C2表示通过实体类型信息计算的结果,C3表示通过多步路径信息进行推理计算的结果。
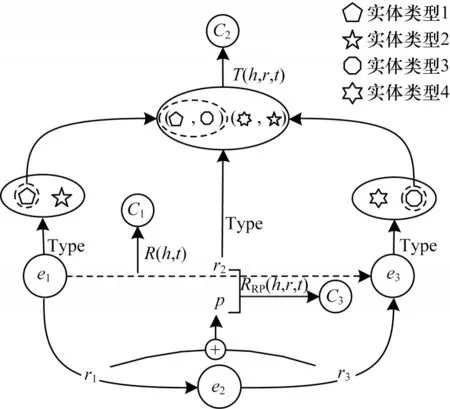
图2 PTCA 模型结构Fig.2 PTCA model structure
三元组可信度的能量函数E(T)通过式(1)进行计算,分数越低说明表示学习效果越好。得到能量函数的计算结果E(T),然后通过式(2)进行转换将其作为三元组的可信度得分,分数越高说明三元组的可信度越高。
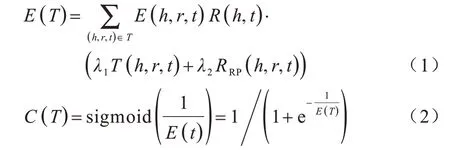
PTCA 模型主要包括3 个步骤:
步骤1根据知识图谱内的信息获取实体关联强度C1,同时得到实体之间的关系路径信息以及每条路径出现的概率。
步骤2通过实体类型与关系类型(由拥有此关系的两实体的实体类型得出)的匹配计算得出C2。
步骤3结合每条路径出现的概率,使用多步关系路径信息判断关系成立的可能性C3。依据能量函数计算的结果,使用式(2)进行转换得到三元组知识的可信度。
赋予可信度计算的初始值为0,当缺少实体关联强度信息、实体类型信息或者路径信息中的一种信息时,缺少信息对应的计算结果为0,最终计算结果有效。在图3 中,以三元组(Toshikazu Shiozawa,nationality,Japan)为例对可信度计算的流程进行描述。

图3 可信度计算的流程Fig.3 The procedure of credibility calculation
3.2 实体间的关联强度
两实体间的关联强度指两个实体存在关联的可能性,本文使用[0,1]之间的数值进行衡量,数值越接近1 说明两实体之间存在关联的可能性越大,即两实体间的关联强度越大,得出实体关联强度的相关定理1。CKRL 模型[6]通过PCRA 算法[23]对实体间的关联强度进行衡量,使用连接两实体的路径数量表示实体间的关联强度。文献[5]提出基于图模型进行运算的ResourceRank 算法,以刻画两个实体之间的关联强度。
定理1两实体之间的关联强度越大,它们之间出现关系的可能性越大。
PTCA 将两实体之间的关联强度作为衡量三元组可信度的一个指标。如图4所示,已知实体对(e1,e2)之间存在关系{r2+r3}、{r1}、{r4+r5+r6},实体对(e1,e3)之间存在关系{r3}。依据定理1,实体对(e1,e2)之间存在关系的可能性大于实体对(e1,e3)之间存在关系的可能性。两实体之间关联强度的计算主要包括3 个步骤:1)获取知识图谱内的实体;2)迭代得出两实体之间的关系路径;3)计算两实体之间的关联强度R(h,t)。
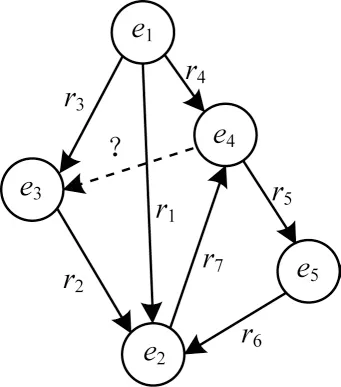
图4 实体关联强度示意图Fig.4 Schematic diagram of entity correlation strength
两实体之间的关联强度通过式(3)进行计算,R(h,t)表示实体h和实体t之间的关联强度,R(h,t)的值处于[0,1]之间,越接近于1 说明两实体之间的关联强度越大。文献[5]中考虑到由于知识图谱中可能存在噪声和冲突,对信息的正确性产生影响,因此为了提高模型的容错率,假设每个节点的资源流都有相同概率θ可以直接跳转到的随机节点,并且随机流向t的这部分资源是1/N,其中,N是实体数。本文为了提高PTCA 的容错率,引入随机跳转概率θ。两实体之间的关联强度通过两实体之间的资源(关系路径的数量)占两实体总资源量的比例进行衡量。实体的资源量可以衡量某实体携带的信息量,将每个实体看作1 个节点,通过式(4)进行计算,R(n)表示n节点的资源量。假设m为n的前驱节点,S为m节点的集合(即n节点的所有前驱节点的集合),Nmn表示连接m、n两节点的关系路径数量,OODm表示经由m节点流出的资源,即m的出度。n节点的资源量通过集合S内所有前驱节点m分别按规则进行运算,然后求和,计算规则如下:m节点与n节点之间的资源占m节点流出资源的比例与m节点携带资源量的乘积,这种计算规则的定义参考了CKRL[6]模型中使用的PCRA[22]算法。

实体关联强度具体实例如图5所示。以三元组(Toshikazu Shiozawa,nationality,Japan)为例,已知两实体之间存在8 条路径,头实体Toshikazu Shiozawa 的出度为5,尾实体Japan 的入度为8,通过迭代得出头实体的资源量R(h)以及尾实体的资源量R(t),进而计算得出两实体间的关联强度R(h,t)。
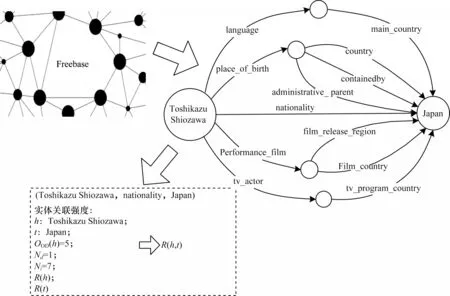
图5 实体关联强度实例Fig.5 Entity correlation strength example
3.3 结合类型信息的关系判断
类型信息包括实体类型信息以及关系类型信息,其中,关系类型表示拥有某关系的两实体的实体类型。例如,已知所有存在关系r的实体对,同时得到这些实体对中每个实体的实体类型,实体对中两个实体的实体类型以成对的形式组成实体类型对,r的所有实体类型对组成r的关系类型,同时使用定理2作为计算依据。PTCA 通过对三元组(h,r,t)中头实体h的实体类型信息EET(h)、尾实体t的实体类型信息EET(t)、r的关系类型信息RRT(r)进行匹配,判断实体对(h,t)之间存在关系r的可能性。匹配方法如图6所示,对于三元组(e1,r1,e2),已知头实体e1的实体类型EET(e1)包括EET1、EET2、EET3、EET4,尾实体e2的实体类型EET(e2)包括EET1、EET2、EET4,r1对应的关系类型RRT(r1)包括RRT1(EET4,EET`)、RRT2(EET4,EET3)、RRT3(EET5,EET2)、RRT4(EET2,EET2),通过实体类型与关系类型的匹配可以得出成功进行匹配的有RRT1和RRT4,依据定理2可以判断实体对(e1,e2)之间存在关系r1的可能性。

图6 实体类型匹配示意图Fig.6 Schematic diagram of entity type matching
定理2实体类型与关系类型成功匹配的数量越多,实体之间存在关系的可能性越大。
通过式(5)计算实体类型的匹配程度,将全部类型中匹配到的数量的比例作为衡量三元组可信度的标准,其中,N表示实体的类型与实体对类型相匹配的数量,NNTh表示头实体中实体类型数量,NNTt表示尾实体中实体类型数量,NNTr表示关系类型的数量。T(h,r,t)处于[0,1]区间,值越大说明三元组的可信度越大。
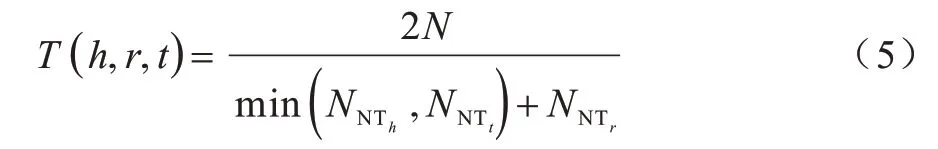
实体类型匹配具体实例如图7所示。对于三元组(Toshikazu Shiozawa,nationality,Japan),已知实体Toshikazu Shiozawa存在5种实体类型,如people/person、film/actor 等,实体Japan 存在8 种实体类型,如location/location、location/country 等,拥有关系nationality 的实体对可能存在3种实体类型,如(people/person,location/country)、(tv/tv_actor,tv/tv_location)等。由图7 可知,实体类型成功匹配的数量为3,该三元组通过匹配计算得出的可信度为0.75。

图7 实体类型匹配实例Fig.7 Entity type matching example
3.4 基于多步路径信息的关系判断
路径信息中蕴含丰富的关系信息,为三元组可信度计算提供了有力支撑。CKRL[6]通过计算两实体间关系r和路径p之间的语义相似度对三元组的可信度进行衡量,KGTtm[5]使用可达路径推理的算法计算三元组可信度。
PTCA 依据多步关系路径信息计算三元组可信度。在单步关系路径信息的基础上进一步推理得出间接关系路径,构成多步关系路径信息,然后得出定理3。基于多步路径信息计算三元组可信度的PTransE[23]方法如图8所示,依据定理3,通过三元组(h,r1,e1)、(e1,r2,t)可以得出包含多步关系路径的三元组(h,r1+r2,t),使用p表示多步关系路径r1+r2,因此,包含多步关系路径的三元组可以表示为(h,p,t)。对于三元组(e1,r,e2)之间的关系r,可以通过多步关系路径p1:r1+r2以及p2:r3+r4+r5推理得出。同时,通过实体间的关联强度来确保关系路径有效。
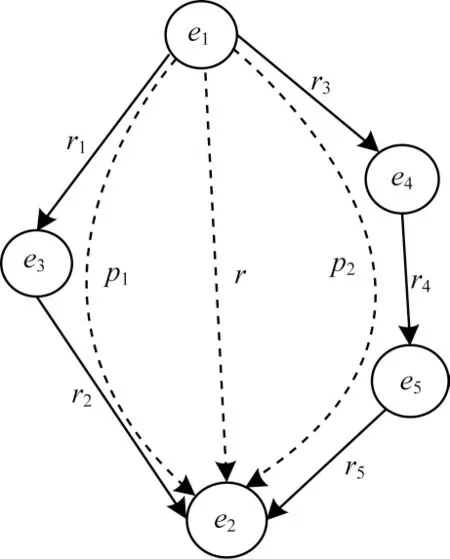
图8 多步路径信息示意图Fig.8 Schematic diagram of multi-step path information
定理3存在间接关系的2 个实体之间至少具有一条多步关系路径。
与PTransE[22]计算多步关系路径与直接关系相似度的方式相同,PTCA 使用式(6)计算路径p与直接关系r的相似程度,分数越低说明路径p与直接关系r越接近。

本文期望相似度的结果能够与前两种计算三元组可信度方法的结果趋势一致,即高分数代表高可信度的知识,且数值位于[0,1]区间,因此,通过式(7)对计算结果进行转换。其中,P(h,t)={p1,p2,…,pn}表示两实体之间存在的所有路径,n为路径的数量。每条路径通过式(6)进行计算,然后使用式(7)将计算的结果转换为[0,1]区间的数值,最后进行平均计算,得出基于多步关系路径信息的三元组可信度结果。

多步路径信息具体实例如图9所示。对于三元组(Toshikazu Shiozawa,nationality,Japan),两实体之间包含8 条关系路径、7 条多步关系路径以及1 条直接关系路径,将多步关系路径抽象为pi进行表示,计算路径与直接关系的相似程度EER(h,pi,t),然后将RRP(h,r,t)转换为[0,1]区间的数值进行路径与关系的相似程度衡量。

图9 多步路径信息实例Fig.9 Multi-step path information example
3.5 算法描述
PTCA 算法描述如算法1所示,使用三元组S={(h,r,t)}作为数据输入。首先,使用PTCA 的能量函数对实体和关系进行表示(嵌入);然后,通过R(h,t)、T(h,r,t)以及RRP(h,r,t)进行可信度计算,更新能量函数的结果;最后,更新损失函数,进行下一轮迭代学习。
算法1PTCA 算法
输入S,S′//S={(h,r,t)}为三元组集合,S′为负例三元组,设置正负例间隔γ、学习率、维度n
输出S_C//经过表示学习的三元组S及其可信度C的集合


4 实验结果与分析
本文通过三元组分类任务、噪声检测任务以及知识图谱补全任务,验证PTCA 模型的知识可信度计算性能。三元组分类任务使用可信度计算的结果对三元组进行二分类,分类为正确三元组以及错误三元组,通过正确分类的三元组的比例检验可信度计算结果的准确率。噪声检测任务依据三元组分类的结果,计算准确率以及召回率,依据PR(准确率/召回率)曲线衡量模型识别错误三元组的能力,进而衡量模型的可信度计算能力。知识图谱补全任务(实体链接预测)用来检验模型的知识表示学习效果。
4.1 数据集
本文实验使用从Freebase 提取的典型基准数据集FB15k、FB40k 作为正例样本集,使用文献[13]中基于FB15k 数据集[17]形成的带噪声数据集作为负例样本集,负例样本集包括包含10%噪声的FB15k-N1、包含20% 噪声的FB15k-N2 以及包含40% 噪声的FB15k-N3 数据集。此外,为了对实验结果进行有效评估,抽取正例样本集以及负例样本集中的三元组进行标注,形成包含20%噪声的FB15kNM 数据集,从FB15kNM 数据集中随机抽取同等数量的数据形成包含5% 噪声的FB15kNM-1、包含10% 噪声的FB15kNM-2 以及包含20%噪声的FB15kNM-3。其中:三元组分类任务以及噪声检测任务依据可信度计算结果进行评估,因此,选择使用0、1 标记的数据集进行实验;知识图谱补全任务依据能量函数的计算结果进行评估,因此,选用原始数据集进行实验。FB15k 与FB40k 之间最主要的差别在于实体数量,且数据集中不含噪声,因此,通过三元组分类任务以及知识图谱补全任务实验结果对模型在实体数量不同数据集上的性能表现进行对比,从而验证模型的适用性。数据集统计信息如表1所示。

表1 数据集统计信息Table 1 Statistics of datasets
4.2 实验参数设置
实验设置不同超参数的值以对三元组分类的结果进行评测。已知λ1+λ2=2,通过设置不同参数得出此方法下表现最好的模型,最终选取具有代表性的平均计算模型PTCA1(参数设置为λ1=1、λ2=1)以及表现最好的模型PTCA2(参数设置为λ1=1.5、λ2=0.5)与对比模型CKRL[6]以及基准模型PTransE[22]进行比较。λ1、λ2的调参过程如下:以0.1为步长,保持λ1+λ2=2,调整参数,通过在FB15kNM 数据集上三元组分类任务的结果选取参数进行实验。参数λ1对三元组分类结果的影响如图10所示,实验结果显示,随着λ1的增加,三元组分类的准确率平稳上升,在λ1=1.5 时达到峰值,随后随着λ1的增加,三元组分类的准确率快速下降,可以得出此方法实验结果最好时参数的设置为λ1=1.5、λ2=0.5。
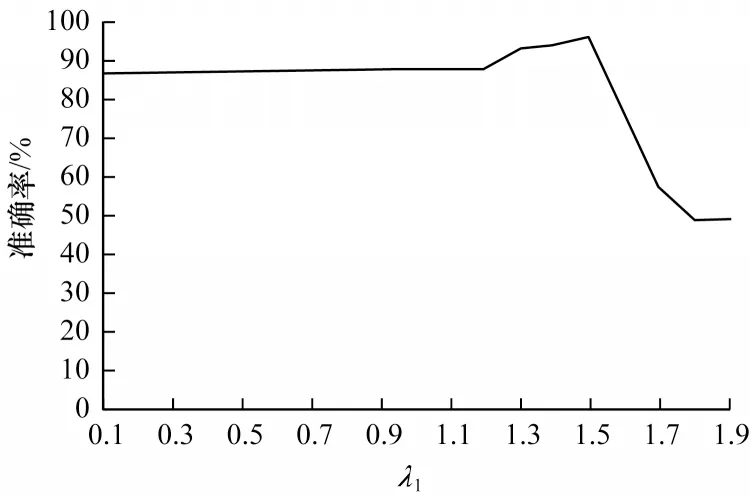
图10 参数λ1 对三元组分类任务结果的影响Fig.10 Influence of parameter λ1 on the results of triplet classification task
使用最小批量随机梯度下降方法(Mini-batch SGD)对参数进行优化和更新。正负例间隔γ设为1,学习率η在{0.000 1,0.001,0.01}中选择,本次实验学习率η为0.001,实体和关系的维度n为100。
4.3 三元组分类任务
三元组分类的目的是预测三元组是否正确,其可以看作是一个二分类问题。本次实验中PTCA 模型依据可信度得分进行三元组分类,其他对比模型通过式(2)对能量函数的计算结果进行转换,同样得到[0,1]之间的数值并作为其可信度得分,依据此得分进行三元组分类。将三元组正确分类的比例作为三元组分类结果的准确率并进行比较,准确率高则表示三元组分类效果好,三元组可信度计算结果更加准确。
4.3.1 评价标准
可信度计算的结果为[0,1]之间的数值,得分越高表示三元组越可信,因此,依据计算结果将可信度得分低于0.5 的三元组划分为错误三元组,将可信度得分不低于0.5 的三元组划分为正确三元组。
4.3.2 实验结果及讨论
在FB15k、FB40k 两个数据集上对PTCA、CKRL(LT+PP+AP)[6]以及基准模型PTransE 进行实验,比较模型在不同实体规模数据集上的性能表现,实验结果如表2所示。从表2 可以看出,与其他模型相比,PTCA 在不同实体数量数据集上的表现最优,并且在实体数量增加时模型仍然具有很高的准确率。因此,PTCA 模型具有一定的适用性。

表2 三元组分类的准确率比较结果1Table 2 The accuracy comparison results 1 of triplet classification %
分别在FB15kNM-N1、FB15kNM-N2、FB15kNM-N3三个数据集上对PTCA、CKRL(LT+PP+AP)[6]以及基准模型PTransE 进行比较,实验结果如表3所示。
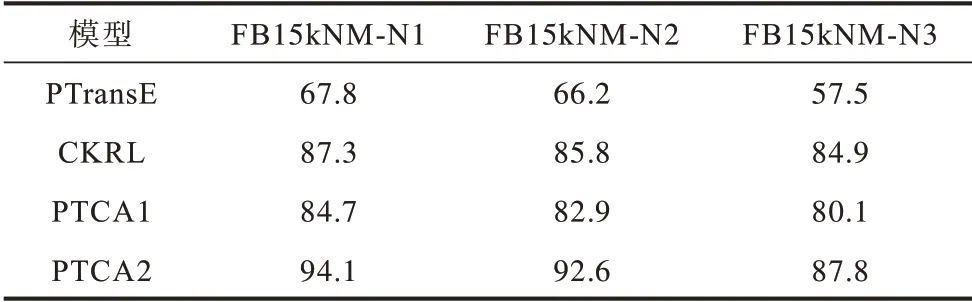
表3 三元组分类的准确率比较结果2Table 3 The accuracy comparison results 2 of triplet classification %
从表3 可以看出:
1)在同一数据集中,PTCA(PTCA2)三元组分类的效果优于CKRL[6]与基准模型PTransE[23],因此,PTCA具有更好的三元组分类能力。与对比模型以及基准模型相比,PTCA 最主要的区别以及优势在于实体类型信息的使用,结合调参实验结果可以看出,加入实体类型信息可以提高三元组分类的能力,但是仅使用类型信息而不结合路径信息将无法达到可信度计算的最优效果,进一步证明在通过实体关联强度信息进行限制的情况下,综合考虑实体类型信息以及多步关系路径信息对三元组进行可信度计算的有效性。
2)随着噪声的增加,PTCA 的三元组分类效果降低,说明加入噪声不利于三元组分类任务,PTCA(PTCA2)的准确率始终高于其他模型,说明实体关联强度信息、实体类型信息以及多步路径信息的结合使得模型对噪声的处理能力提高。
4.4 知识图谱噪声检测任务
噪声检测任务的目的是根据知识图谱内部的三元组来检测知识图谱内可能存在的噪声和冲突。为了验证PTCA 检测噪声的能力,采用该任务进行评测。本次实验依据三元组分类的结果,计算各模型对三元组进行分类的准确率以及召回率,使用抽样的方法得出PR 曲线,通过PR 曲线对三元组分类效果进行衡量。
4.4.1 评价标准
噪声检测任务的评价标准是三元组的可信度得分,得分越低的三元组成为噪声的可能性越大。因此,噪声检测任务可以通过模型对噪声数据正确分类的结果进行衡量。此任务可以直接衡量三元组可信度计算的效果,在同一召回率的情况下,准确率越高,模型的表现效果越好,识别噪声的能力越强,三元组可信度的计算结果越准确。
4.4.2 实验结果及讨论
在同一数据集FB15kNM 上通过噪声检测任务实验对PTCA、CKRL[6]以及PTransE[22]进行性能比较,其中,CKRL 模型包括LT(Local Triple Confidence)、PP(Prior Path Confidence)、AP(Adaptive Path Confidence)3 种模式,评测结果如图11所示。
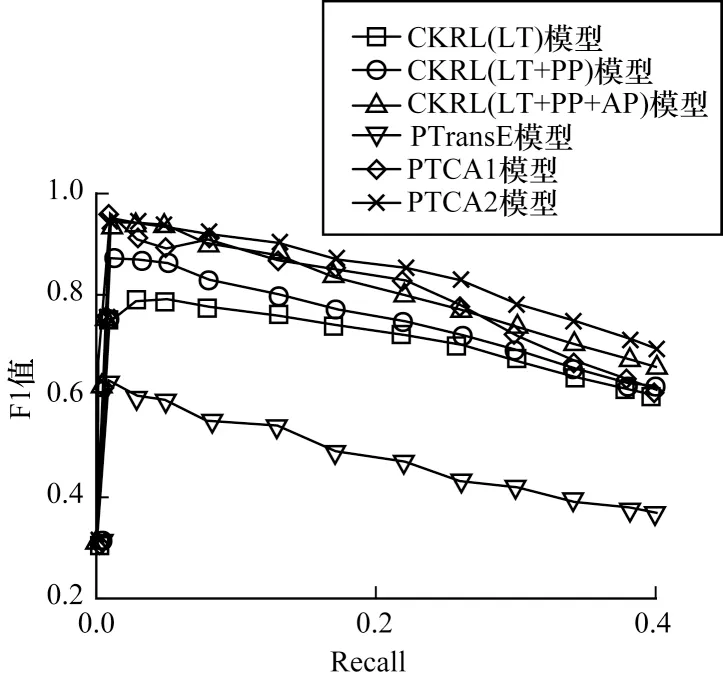
图11 噪声检测任务实验结果Fig.11 Experimental results of noise detection task
从图11 可以看出:
1)与其他模型相比,PTCA(PTCA2)的性能最好,优于经过证明具有良好噪声与冲突检测能力的CKRL模型,因此,PTCA 具有更好的噪声检测能力。但是,CKRL 模型中表现最好的CKRL(LT+PP+AP)效果优于PTCA1,可以认为,CKRL 中路径信息的使用方法优于PTCA 中多步路径信息的使用方法。实验结果证明,PTransE能量函数的局限性导致其噪声检测能力很弱。因此,CKRL 中使用的路径信息优于多步路径信息也可能是受到PTransE 能量函数的影响。
2)引入可信度计算的模型(PTCA、CKRL)噪声检测能力明显优于没有引入可信度计算的模型(PTransE)。因此,可信度计算可以提高模型的容错率。
图12所示为不同噪声比例的数据对PTCA、CKRL[6]以及PTransE[23]的影响,可以看出,随着噪声比例的增加,模型监测噪声的能力增强,与其他模型相比,PTCA检测噪声的能力更稳定,并且在噪声含量很低的数据集中仍然具有很高的准确率,其实际应用价值更高。

图12 噪声对模型的影响Fig.12 Effect of noise on models
4.5 知识图谱补全任务
知识图谱补全是一项经典的评测任务,其目标是对知识表示的质量进行评估。最常见的补全是基于表示学习的链接预测。本文实验通过实体链接预测进行知识图谱补全任务,实体链接预测通过三元组中已知的实体预测缺失的关系。由于PTCA 对三元组的表示学习过程使用了可信度计算的结果,因此通过实体链接预测可以对模型的表示学习能力进行评估,从而证明可信度计算的有效性。
4.5.1 评价标准
首先使用所有实体替换三元组中的某个实体(头实体或者尾实体)形成新的三元组,通过能量函数对这些三元组进行计算,并根据得分进行排序,得分越低排名越靠前。根据正确答案的排序评估该模型在链接预测中的能力,评价指标包括正确实体得分的平均结果排名(MeanRank)以及预测结果前十项中正确结果所占比例(Hits@10)。由于在负例生成过程中产生了一些“污染”三元组,因此本实验使用“Raw”和“Filter”两种设置,“Raw”表示未经处理的数据,“Filter”表示剔除“污染”三元组的数据。
4.5.2 实验结果及讨论
在FB15k、FB40k 两个数据集上对PTCA、CKRL(LT+PP+AP)[6]以及基准模型进行实体链接预测实验,比较模型在不同实体规模数据集上的表现,实验结果如表4所示,最优结果加粗表示。从表4 可以看出,模型在实体数量增加的情况下,MeanRank 评测指标的结果有所下降。但是,与其他模型相比,PTCA 的实体链接预测结果最好,表明其表示学习能力最强,具有一定的适用性。
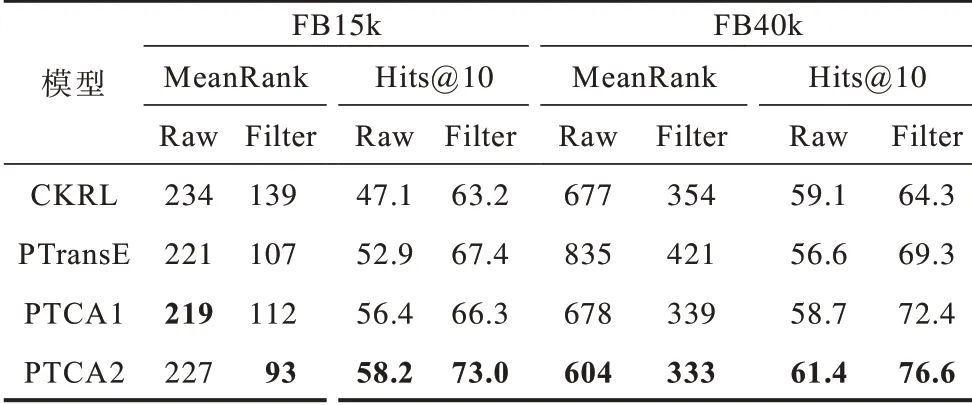
表4 实体链接预测结果1Table 4 Entity link prediction results 1
分别在FB15k-N1、FB15k-N2、FB15k-N3 等3 个数据集上对PTCA、CKRL(LT+PP+AP)[6]以及PTransE[23]进行比较,实验结果如表5所示,表中用MR 表示MeanRank,R 表示Raw,F 表示Filter。

表5 实体链接预测结果2Table 5 Entity link prediction results 2
从表5 可以看出:
1)PTCA(PTCA2)在所有数据集上的MeanRank评测指标,在剔除“污染”三元组的数据(Filter)上表现效果最优,在未经处理的数据(Raw)上表现效果比PTransE 差,结合不同参数设置下的结果发现,路径信息的权重越大,则结果越好,因此,路径信息相较类型信息更能提高模型的表示学习能力。PTCA的Hits@10 评测指标结果优于其他模型,因此,PTCA 具有较强的表示学习能力。与CKRL 相比,PTCA 的优势在于实体类型信息的使用,与PTransE相比,PTCA 的优势在于对三元组可信度的计算以及实体类型信息的使用。根据结果可以看出,可信度计算以及实体类型信息都可以增强模型的表示学习能力,而且实体类型信息更有助于提高模型的表示学习效果。因此,结合实体类型信息进行可信度计算的方法可以明显提高模型的实体链接预测能力。
2)随着噪声的增加,PTCA(PTCA2)的各项评测指标仍然保持稳定,而且与其他模型相比优势更加明显。因此,在有噪声干扰的情况下,经过可信度计算,PTCA 依然可以保持很好的表示学习效果,进一步证明可信度计算能够提高模型的噪声识别能力。
4.6 实验效果展示
本文提出一种计算三元组可信度的模型PTCA,使用实体间关联强度、实体类型信息、多步关系路径信息对三元组的可信度进行计算,并且通过图13 展示实验效果。可以看出,PTCA 首先对存在噪声的知识图谱内知识的可信度进行计算,得到带可信度的知识,图中使用实线表示高可信度的知识,使用虚线表示低可信度的知识,结合可信度计算的结果进行筛选,可以减少低可信度的知识,保留高可信度的知识,经过筛选的知识图谱中知识质量更高。

图13 实验效果展示Fig.13 Experimental effect display
5 结束语
本文建立一种使用实体间关联强度、实体类型信息、多步关系路径信息对三元组的可信度进行计算的PTCA 模型。分别在知识图谱噪声检测任务、知识图谱补全(实体链接预测)任务和三元组分类任务中对该模型进行评测,实验结果表明,相比CKRL和基准模型PTransE,PTCA 模型可以检测知识图谱内部存在的噪声和冲突,能够对三元组的可信度进行有效计算,而且在有大量噪声干扰的数据集中性能表现更优。然而,PTCA 模型仅引入不影响全局一致性的实体类型信息作为外部信息,未充分利用如图像信息、文本描述信息等大量丰富的外部信息。因此,下一步考虑将知识图谱内部结构信息、实体类型信息、图像信息、文本描述信息等引入知识可信度评估中,并在更复杂的大规模知识图谱内对模型的适用性以及鲁棒性进行测试。
