基于新工科的移动机器人控制实验设计和教学实践
2021-07-27王军义贾子熙王冬冬
王 帅, 王军义, 贾子熙, 白 帆, 王冬冬
(东北大学机器人科学与工程学院,沈阳110819)
0 引 言
机器人工程专业是在新工科背景下顺应国家建设需求和国际发展趋势而设立的专业,在自动化类专业基础上深化机器人科学与工程学科特色,具有交叉性、实践性强的特点。按照机器人工程专业现行培养计划,大四上学期开设的移动机器人控制实验,以《工程教育认证标准》为指导目标,秉承“以学生为中心”的教学理念,采用项目式(project-based learning,PBL)教学方式[1],从符合产业发展的多学科交叉项目出发,“自顶而下”设计实验内容,并对复杂工程问题分层次进行研究,设计了基于深度学习的移动机械手抓取实验。以培养学生自主学习的能力以及团队成员协作交流能力,包括撰写报告和陈述发言、清晰表达或回应指令等能力。
1 移动机械手抓取实验平台总体架构
硬件系统为搭载单线激光雷达的移动平台、AUBO i5机械臂、Intel RealsenseSR300深度摄像头和带麦克风的IntelI7处理器的PC。软件部分主要是在Ubuntu16.04下完成的,在机器人操作系统(robot operation system,ROS)平台上进行各个部分的通信,并利用MoveIt进行机械臂的控制,系统总体架构如图1所示。
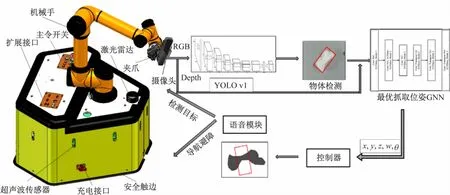
图1 机械臂抓取实验平台总体架构
通过语音系统下达任务指令,控制移动平台开始自主导航和避障到达目标点,进行目标检测和执行抓取任务。整个项目在ROS平台上搭建,利用百度语音识别系统与用户进行交互,借助ROS通信机制完成语音控制导航和控制目标检测与抓取的功能。在自主导航和避障方面,采用gmapping方法通过成本较低的激光雷达采集室内地图信息并保存为地图,利用amcl
(自适应蒙特卡洛定位)方法实现自我定位,通过实时接收的里程计数据,调整移动机器人的运动,以减少误差,并利用Bresenham算法计算栅格地图中非障碍物格点的集合,将机器人安全地移动到目标位置,实现室内的低成本、高准确度的导航与避障功能。在目标检测方面,直接读取相机的彩色图像,利用预训练完成的YOLO模型进行物体识别与检测,并将识别到的候选目标与语音指令中的目标对比,选定最终的目标区域,将其对应的深度图像输入到抓取生成卷积网络GGCNN中。该网络可以将深度图像作为输入,直接预测出每个像素点的抓取质量(成功率)、宽度和位姿,获得物体的最优的抓取位姿。直接在ROS平台下利用MoveIt控制机械臂,到达目标位姿,完成抓取动作。实验结果表明本文构建的移动机器人系统能够实现在语音控制下的导航避障、物体检测与自主抓取,结合语音识别、SLAM、目标检测、位姿生成、ROS和机械臂与移动平台控制等多种技术,提高了学生解决复杂工程问题的能力。
2 课程设计内容
2.1 实验目的与要求
(1)了解SLAM原理,并学会在ROS下应用SLAM;
(2)了解ROS下语音控制移动机器人导航方法;
(3)理解YOLO的算法原理,并学会利用预训练的YOLO模型,进行物体识别与检测;
(4)学会训练并使用最优抓取位姿生成神经网络(GG-CNN)模型,实现抓取位姿生成;
(5)掌握眼在手上的机器人视觉标定与相机内参标定;
(6)学会在ROS平台下利用MoveIt控制机械臂完成目标抓取。
2.2 实验内容
2.2.1 语音识别
在ROS下,利用百度语音识别系统实现人机交互,将语音信号转化为指令,控制机器人导航到达目的地以及目标检测指定物体功能[2]。表1为语音控制的伪代码。

表1 语音控制伪代码
2.2.2 自主导航和实时避障
对实验场景进行地图构建。Gmapping是基于滤波SLAM框架的常用开源SLAM算法,可以实时构建室内地图,在构建小场景地图所需的计算量较小且精度较高。相比Hector SLAM对激光雷达频率要求低、鲁棒性高。基于Gmapping算法建立的地图如图2所示。
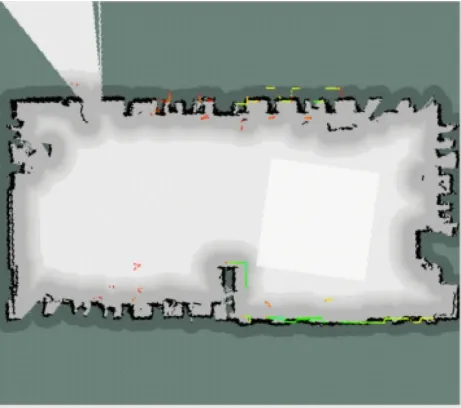
图2 Gmapping地图
在建立完世界地图后,利用移动机器人的概率定位算法AMCL[3],通过PF粒子滤波来跟踪定位已知地图中的机器人位置。激光传感器会向固定的方向发射激光束,发射出的激光遇到障碍物会被反射,这样就能得到激光从发射到收到的时间差,乘以速度除以2就得到了传感器到该方向上最近障碍物的距离,再计算障碍物在栅格地图中的坐标,以及机器人在栅格地图中的坐标,使用Bresenham算法来计算非障碍物格点的集合。利用激光传感器构建栅格地图来完成避障导航功能[4],自主导航效果图如图3所示。

图3 自主导航效果图
2.2.3 物体识别与检测
考虑到目标检测的实时性,直接采用YOLO v1[5]进行目标检测。YOLO v1是一种基于深度神经网络的对象识别和定位算法,其最大的特点是运行速度快,可用于实时系统。YOLO v1将物体检测作为回归问题求解。基于一个单独的end-to-end网络,完成从原始图像的输入到物体位置和类别的输出。仅经过一次模型推理,便能得到图像中所有物体的位置和其所属类别及相应的置信概率。
为方便学生尽快将目标检测应用于项目中,在学习完YOLO v1的基本理论以后,直接应用预训练的YOLO v1模型进行常用物体的识别与检测,避免长时间的模型训练。
在目标检测过程中,加载预训练的YOLO v1模型,读取相机的彩色图像,并以448×448×3的大小输入到YOLO v1模型中,经过网络模型的推理,得到输出的是一个7×7×30的向量,包含了图片中物体的分类结果以及其位置信息的编码。输出的30维的特征向量中前20维为模型预测的20个对象的概率,接着2维分别预测2个bounding box的置信度,最后的8维分别表示2个bounding box的位置,其中每个bounding box的位置需要4个数值进行表示。通过模型的输出特征得到检测的候选物体,并将其与语音指令中的物体对比,得到最终的目标物体,并将该区域对应的深度图像发布到位姿生成算法的话题上,完成目标检测。YOLO v1网络示意图如图4,算法流程图如图5所示。
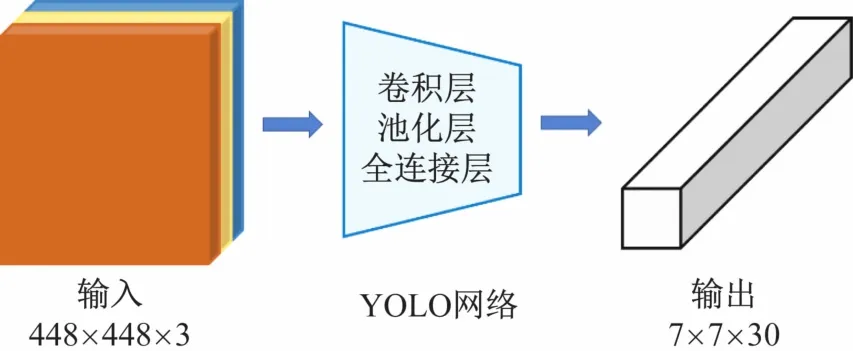
图4 YOLO网络示意图
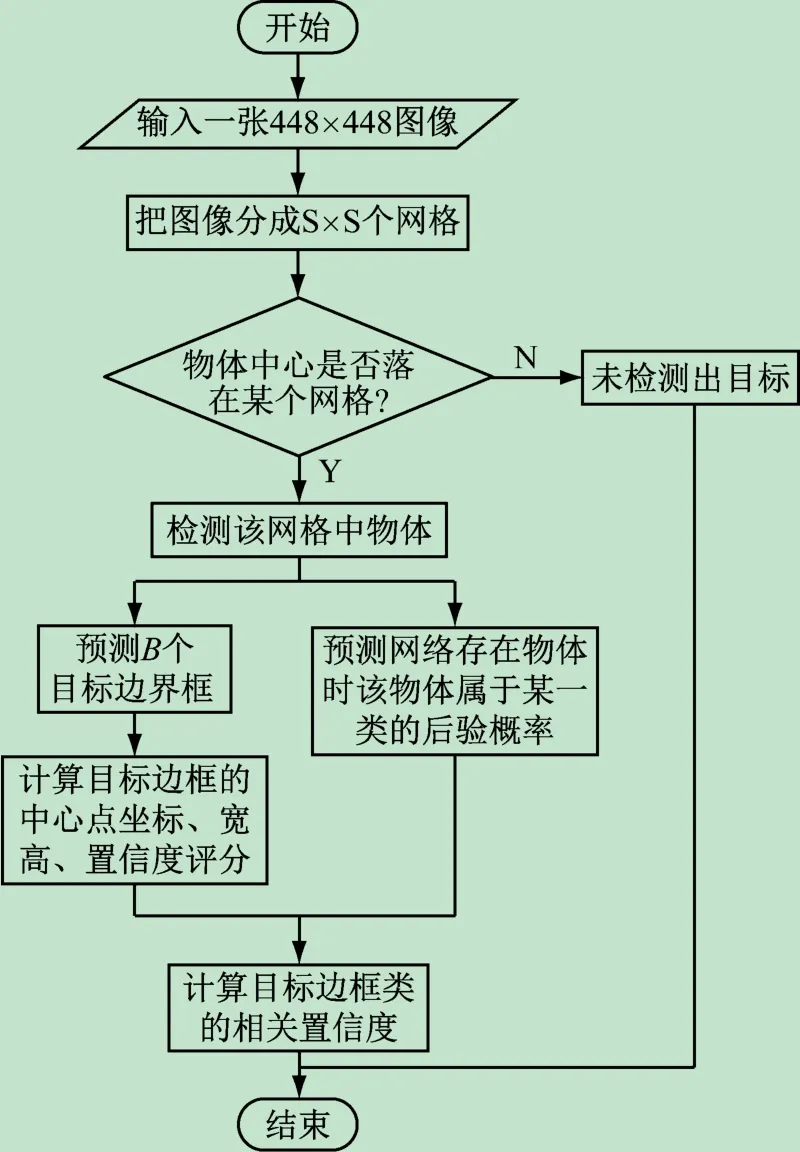
图5 YOLO算法检测流程
2.2.4 抓取位姿生成
在抓取位姿生成模型训练中,采用Cornell Grasping Dataset[6]的数据。Cornell Grasping Dataset包含885个真实物体的RGB-D图像,每个图像打上若干标签,其中5 110个被打上“positive抓取”标签,2 909个被打上“negative抓取”标签。这是一个相对较小的抓取数据集,使用随机裁剪,缩放和旋转来增加Cornell Grasping Dataset的数量[7],创建一组8 840个深度图像和相关抓取图像的集合G T,并有效地结合了51 100个抓取示例。
Cornell Grasping Dataset使用像素坐标将待抓取位姿表示为矩形框,校准末端执行器的位置和旋转角度。为从抓取矩形框表示转变为基于图像的表示,选择每个抓取矩形的中心1/3处作为图像掩码,其对应于抓取器中心的位置,选用被标记为positive的抓取训练GG-CNN网络并假设其他任何的区域都不是有效的抓取。
抓取质量(准确率):将每个有效抓取视为二进制标签,并将抓取质量Q T的相应区域设置为1,其他所有像素均为0。
角度:计算每个抓取矩形在[-π/2,π/2]范围内的角度,并设置相应的抓取角度ΦT区域。由于二指抓取在±π/2弧度附近是对称的,本文使用两个分量sin(2ΦT)和cos(2ΦT),它们提供在ΦT∈[-π/2,π/2]内唯一且在±π/2处对称的值。
宽度:和角度类似,计算每个抓取矩形的宽度(以最大值为单位),表示抓取器的宽度并设置夹爪宽度W T的相应部分。在训练期间,将W T的值按1/150的比例缩小,使其在[0,1]范围内。
通过以上的定义和操作,从Cornell Grasping Dataset中,生成用于训练GG-CNN模型的数据集。
生成最优抓取位姿利用GG-CNN[8]计算函数Mθ(I)=(Qθ,Φθ,Wθ),直接从输入的深度图像I来近似生成抓取信息图像Gθ,以300×300的深度图像作为输入,经过3层卷积操作和3层反卷积操作,最终获得抓取的信息图。GG-CNN结构示意图如6所示。
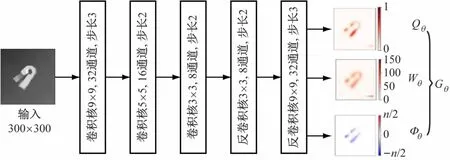
图6 GG-CNN结构示意图
将图像中的抓取位姿变换到机器人坐标系下。

式中:tRC为从相机坐标系转换到机械臂坐标系的坐标变换;tCI为基于相机内部参数和机器人与相机之间的已知校准,从2D图像坐标转换到3D相机坐标系;g~
为从抓取信息图Gθ中得到的一组抓取信息。
2.2.5 手眼标定
本文采用眼在手上(eye in hand)的方式识别AR Marker码[10]来进行相机外参标定,如图7所示。
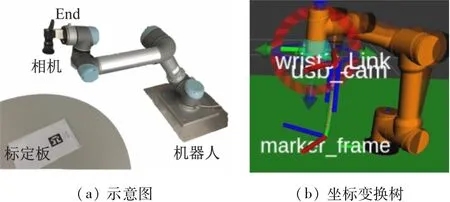
图7 Eye-in-hand手眼标定过程
对于机器人移动过程中任意两个位姿,机器人底座和标定板的关系始终不变,求出相机和机器人末端坐标系的位姿关系。

式中:Camera1、Camera2为两次运动相机的位姿;End1、End2为两次运动机械臂末端位姿,根据标定板(Object)和机器人底座间(Base)两次运动保持不变,上式经过转换后,可得:

即

在标定中,首先利用ROScamera_calibration包基于张正友法进行内参标定[9],然后再利用easy_handeye手眼标定功能包直接求解[10]进行外参标定,至此完成手眼标定用于后面的基于视觉的抓取工作。
2.2.6 实验结果
本文在1080ti GPU训练GG-CNN网络模型,经过100个epoch的训练后,将训练好的模型进行测试,预测效果如图8所示。
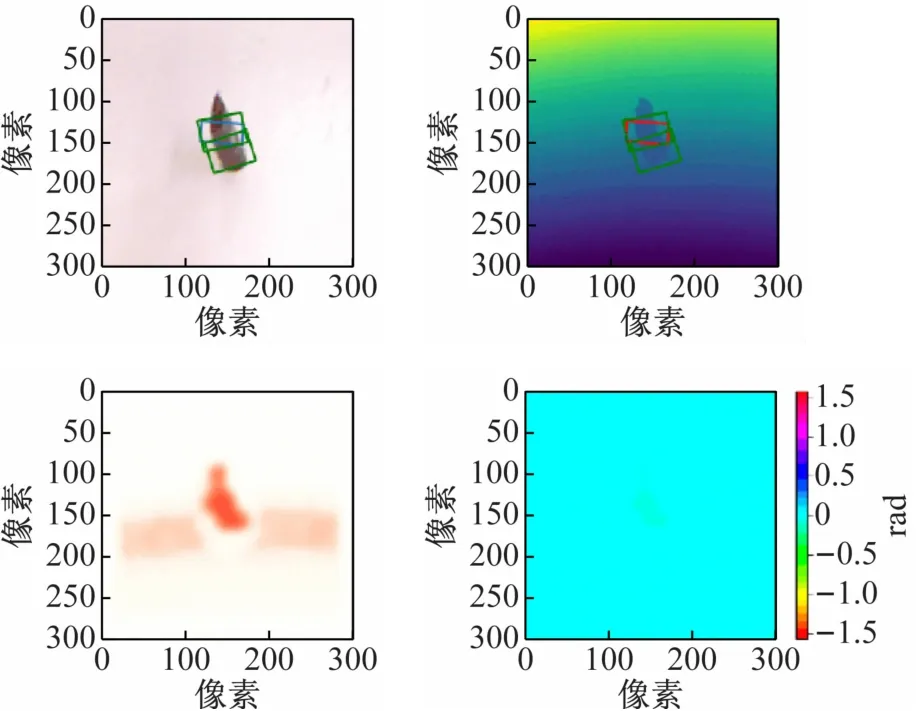
图8 GG-CNN输出及抓取框生成
将数据集中带标记抓取框(绿色)的RGB图像(左上)、生成抓取框(红色)的深度图像(右上)、网络输出的抓取宽度图像(左下)和抓取角度图像(右下)显示出来。从生成抓取框的灰度图像可以清晰地看出,GG-CNN所生成的抓取框与原数据集中标记的抓取框的位置、宽度和角度值相差不大,效果理想。
将项目整体进行实验测试,硬件系统为搭载激光雷达的移动平台、AUBO i5机械臂、Intel Realsense SR300深度摄像头和带麦克风的Intel I7处理器的PC。软件部分主要是在Ubuntu16.04下完成的,在ROS平台上进行各个部分的通信,并利用MoveIt控制机械臂完成抓取动作[11],实验效果如图9所示。

图9 实验系统验证效果
移动机器人在实验者语音的指导下由“客厅”走进“厨房”,然后按照命令夹起“香蕉”。经过实验验证与测试,移动机器人能够在用户的语音控制下顺利地完成自主导航与避障、目标物体的识别检测与自主抓取,系统的鲁棒性和实时性较好。
3 实验实施及项目评估
实验采用5~6人一组,自由组队,组长分配任务和权重。实验内容及考核方式见表2。
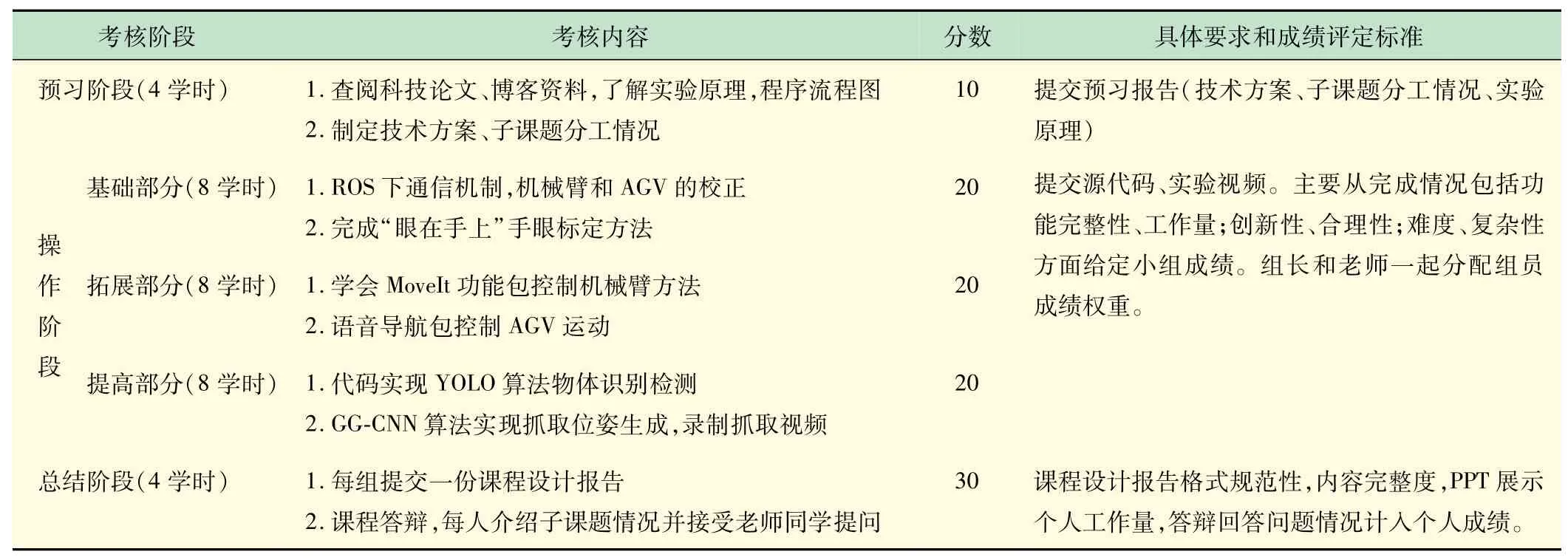
表2 实验内容及考核方式
(1)预习阶段。通过检索国内外科技论文,查阅资料,了解移动机器人的组成、导航算法、目标检测算法、抓取位姿生成算法,以及语音识别,手眼标定,MoveIt控制机械臂;引导学生把项目分解为若干子课题,讨论分工及子课题的进行顺序,撰写实验计划。
(2)操作阶段。根据学生的知识水平、学习能力和实践能力,结合课程设计项目的难度和特点,分“基础-拓展-提高”3阶段有序开展创新能力培养工作。基础阶段首先让学生了解ROS下通信机制,完成机械臂和AGV的校正,完成“眼在手上”手眼标定;拓展阶段学会MoveIt功能包控制机械臂,以及利用百度语音识别库控制AGV运动;提高阶段实现物体识别检测,生成最优抓取位姿,控制机械臂抓取。
(3)总结阶段。每组写一份课程设计报告,介绍分组情况,系统原理、硬件组成、软件组成、代码实现、系统调试等部分。每组进行演示答辩,老师给出每组成绩,组长和老师一起分配组员成绩权重。
4 结 语
针对移动机器人控制实验课程,搭建了基于深度学习的移动机械手实验平台,并设计了32学时的课程设计内容,取得良好的教学效果。实验项目具有以下特点:
(1)按照“自底向上”的教学设计方法,对标《工程教育认证标准》,制定人才培养方案,同时融合“自顶向下”的教学设计方法,分阶段完成复杂工程项目[12]。
(2)基于PBL项目式实践教学模式,把大学4年所学多门课程如机器人基础原理、机器人操作系统、图像处理、机器视觉等知识融会贯通,真正做到多学科交叉。
(3)阶梯式创新人才培养模式[13],把科研项目拆解成子课题,根据学生的知识水平、学习能力和实践能力,结合课程设计项目的难度和特点,分阶段有序开展创新能力培养工作。
(4)本系统可在多领域应用,如可以用作智能轮椅为老年人与残疾人的生活提供便利,或者作为搬运机器人,具有一定的社会意义和研究价值[14-16]。
