基于众源数据的地理知识存储方法研究
2021-07-24杨波赵英俊
杨波,赵英俊
(核工业北京地质研究院遥感信息与图像分析技术国防科技重点实验室,北京 100029)
在众源数据中,数据的收集和管理是众源数据应用的基础。随着日常需求量的变化,以单一文件来收集与管理众源地理知识已经无法满足地理信息应用需求。目前众源数据主要利用数据库技术进行存储管理。但是,众源数据的地理知识的数据节点和其属性关系的复杂性,造成经典关系数据库无法满足对众源地理知识进行存储的场景需求。因此,本次研究以核电站场景为例,探究核电站众源地理知识的存储方法。为了更好地进行三元组地理数据的存储,笔者查阅了相关研究文献,发现,当前主流方法是利用图数据库的方法对地理知识数据进行存储[1-4]。本研究首先分析核电站图数据模型和图查询语言等模型设计原理,详细分析了如何利用各种主流知识图谱数据库构建地理知识图谱,包括基于关系数据库的存储方案、面向资源描述框架(Resource Description Framework,RDF)的三元组存储结构和知识图数据库。其次以图数据库Neo4j为例设计核电站图模型数据的底层存储原理,同时梳理图数据索引和查询处理等关键技术[5]。最后,以Neo4j为例,针对知识图谱数据库开源工具进行众源地理信息的实践,数据结果与技术流程可利用于地理信息领域。
1 众源数据知识模型
从数据模型角度来看,知识图谱本质上是一种图数据[6-9]。不同领域的知识图谱均需遵循相应的数据模型。往往一个数据模型的生命力要看其数学基础的强弱,关系模型长盛不衰的一个重要原因是其数学基础为关系代数。知识图谱的初始发展来自数学经典图论理论,在图论中,图是二元组G=( )V,E,其中,V是节点集合,E是边集合。图论认为客观现实可以用实体及其属性集合来抽取,而众源数据的知识模型也因此发展而来。
1.1 资源描述框架
RDF是万维网联盟(World Wide Web Consortium,W3C)官方认证的W3C指定的知识描述众源数据知识模型。在RDF三元组集合中,单一的众源事件信息都配有一个身份信息。事件信息的抽取方法是用三元组的形式进行抽取,三元组模型的抽取结构是(s,p,o)[10-11]。其中,s是主语,p是谓语,o是宾语。(s,p,o)表示知识s与知识o之间具有关联p,或表示知识s具有属性p且其结果为o。
图1所示是核电站员工的基于众源数据的知识图谱。其中,有运行二部的张某、李某与运行三部的赵某、王某4名研究人员。张某、李某来自运行二部,属同事关系。赵某、王某来自运行三部,也属同事关系,且李某与赵某属多元关系。他们4人共同参与了运营管理和实验2个项目,其中,实验项目[12]是属于运营管理项目。由于受本文内容的限制,只做简要的方法建设,现实中的人员与项目内容节点与属性的众源知识远比图中所示的复杂度高。
值得注意的是,RDF本身的节点和属性并无元数据信息。各类节点及属性的表示方式如图1中实线四边形,即图中的矩形。边上的属性存储方法表示起来稍显繁琐,在众源数据的表示过程中,通过抽象一类总节点本体[13]来对地理实体进行统称。如在图2中,通过设计超节点ex:参与实例类(ex:zhang,参与,ex:operation)来实现节点属性的表达,该节点通过RDF内置属性rdf:主语、rdf:谓语和rdf:宾语进行众源地理知识的内部建模,其中实例(ex:参与,权重,0.4)就实现了为原三元组增加边属性的效果。

图1 A厂众源知识Fig.1 Crowdsourcing data of A factory
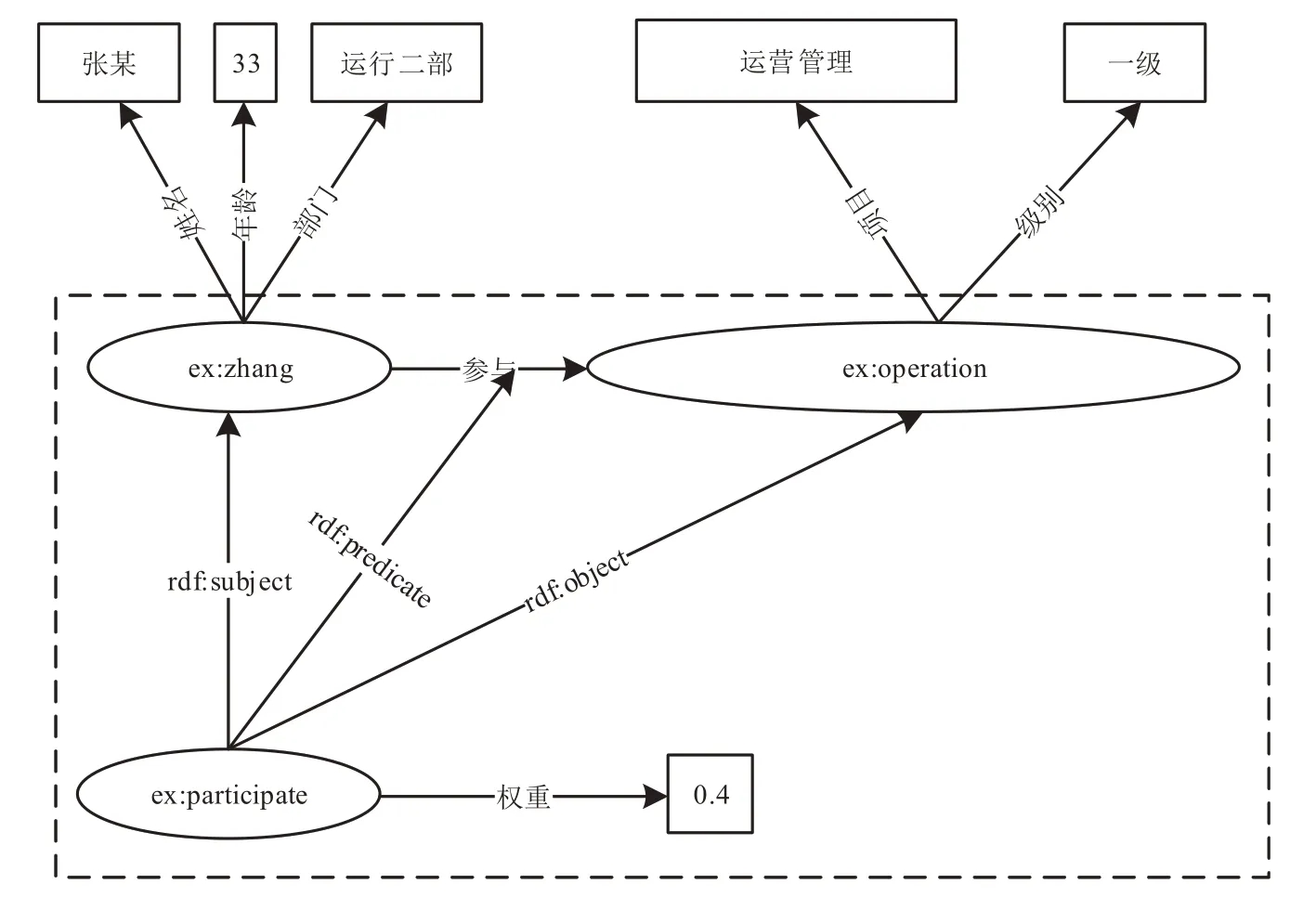
图2 众源知识中边属性的表示Fig.2 Representation of edge attributes in RDF graph
1.2 属性知识建模
属性知识可以说是目前被图数据库业界采纳最广的一种图数据模型。属性知识由节点集和边集组成,且满足如下性质:
(1)每个节点具有唯一的id;
(2)每个节点具有若干条出边;
(3)每个节点具有若干条入边;
(4)每个节点具有一组属性,每个属性是一个键值对;
(5)每条边具有唯一的id;
(6)每条边具有一个头节点;
(7)每条边具有一个尾节点;
(8)每条边具有一个标签,表示联系;
(9)每条边具有一组属性,每个属性是一个键值对。
图3的每个节点和每条边均有id,遵照属性知识的要素,节点1的出边集合为{边11,边18},入边集合为{边10,边15},属性集合为{姓名=赵某,年龄=48,部门=运行三部};边11的头节点是节点5,尾节点是节点1,标签是“参与”,属性集合为{权重=0.4}。

图3 属性知识示例Fig.3 Example of property graph
2 众源知识存储方法
为了对众源数据进行有效存储和管理,调研发现,众源数据管理方法有三种类型,关系型、三元组型及原生图数据库型,通过文献调研和核电站数据实验发现,第三种方法最适合本次研究内容。其中,关系数据库拥有40多年的发展历史,从理论到实践有着一整套的成熟体系[14]。数据库体系从层次数据库到关系数据库转变,这也带来了一系列商业数据库的诞生与发展[15]。以此类推,知识型数据管理方法的诞生也催生了一类知识型商业数据管理与存储产品。因此,本此研究核心部分将要利用知识型数据的管理及存储方法对众源数据进行有效的收集和管理。为此,构建了众源数据的知识管理方法、横向存储方法、属性存储方法、纵向存储方法、多重查询方法以及混合管理方法,为基于众源数据的地理知识存储提供多元存储方案。
图4所示是以收集并处理核电站的众源数据集的RDF数据作为知识图谱进行实验和举例。该知识图谱构建了N公司及其董事长陈某和M公司及其董事长刘某的节点属性和弧关联。该实验数据对于其他格式的知识图谱,这种存储方案同样适用。

图4 核电站众源数据RDF知识图谱Fig.4 Crowdsourcing data RDF knowledge graph for nuclear power plant
2.1 知识管理
知识管理方法的核心组成如下:知识管理方法(主语,谓语,宾语)
如表1所示,以M和N公司员工为例,对众源数据中的知识信息进行抽取挖掘得到下表。每一个实体代表一个类似的主语节点,谓语表示属性信息,宾语是尾节点知识。

表1 三元组存储案例Table 1 Triple storage case
知识管理方法的优点是结构简单,众源数据的技术入门比较低[16]。但缺点是规则混乱,无标准可参考。图5所示的SPARSQL查询时查找某年份出生且是某出生地的某公司的董事长,并且可以将该SPARSQL查询转换为关系型数据库查询。

图5 SPARQL查询与SQL查询对比Fig.5 Comparison between SPARQL query and SQL query
2.2 横向存储
横向存储法的特点是存储结构框架模式,该方法与知识管理方法不同,这里的方法是将众源数据按照行优先的策略进行存储。具体内容如表2所示,其共有5行、5列,限于篇幅省略了若干列。不难看出,横向存储法用列创建众源数据的属性信息,而行用于创建事件的头节点内容。

表2 横向存储案例Table 2 Horizontal storage case
横向存储方法,其众源数据的核心查询语法规则是:
SELECT主语
FROM a
WHERE出生=‘年份’AND籍贯=‘出生地’董事长LIKE‘_%’
横向存储方法的语法,本文用符号a代替为查询表,而且,单表查询即可完成该任务,不用进行连接操作。在基于众源数据的地理信息数据集中,该数据的存储方法对于行优先存储来说,会出现大量的存储空间闲置的情况。如果将该方法应用到实际场景中,这种方法会增加数据库管理的复杂度和运营数据的成本。
2.3 属性存储
属性存储方法是把横向存储方法进行更加详细的划分描述,即把一个横向存储方法分为人、专业化公司和母子公司三个分栏。对于图5中SPARQL查询,在属性存储方法上等价的SQL查询如下所示:
SELECT主语
FROM人
WHERE出生=‘年份’AND籍贯=‘出生地’董事长LIKE‘_%’
该查询与横向存储方法上查询的唯一区别是将栏名由a变成了员工。
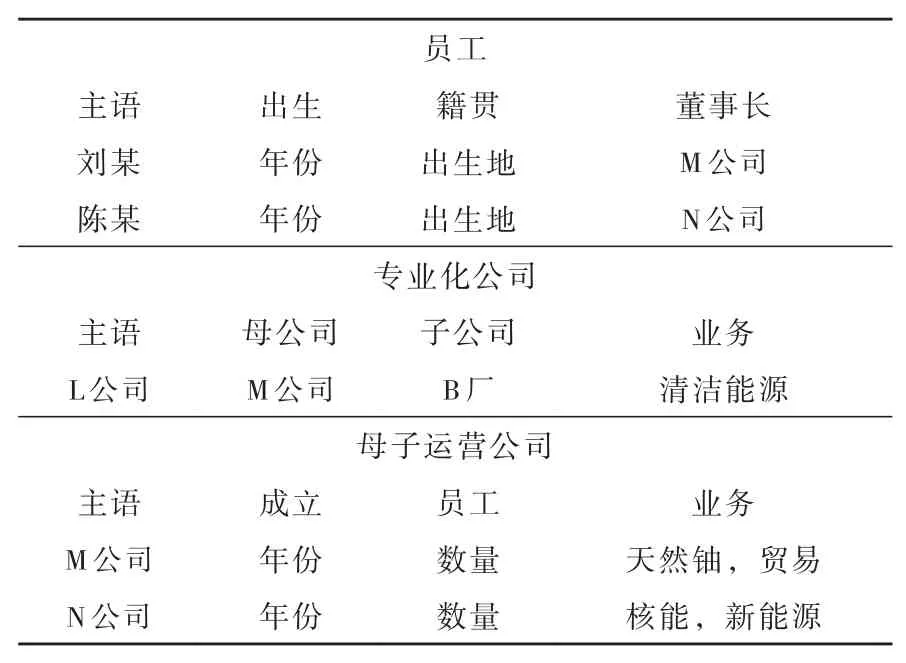
表3 属性存储方法Table 3 Store of attribute
属性存储方法是在对知识管理方法和横向存储法上的优化升级,反过来看,知识管理方法和横向存储法又是属性存储法的特例。按照属性存储方法,虽然它弥补了上面两个方法的缺点,但是,其本身也出现了数据冗余的缺点。而且,属性存储方法仍然会进行多个表之间的连接操作,从而影响查询效率。
2.4 纵向划分
纵向划分起源于美国高等学府,该方法以三元组的谓语作为划分维度,将RDF知识图谱划分为若干张只包含(主语,宾语)两列的表,该表的突出特征是以众源数据的属性信息为分表。也就是说,图6中分表分别是出生、董事长、业务、子公司等众源属性信息。

图6 纵向划分存储方案Fig.6 Vertical partition storage solution
对于图6中的SPARQL查询,在纵向划分存储方案中等价的SQL查询如下:
SELECT出生.主语
FROM出生,业务,董事长
WHERE出生.宾语=‘年份’AND业务.宾语=‘天然铀’AND出生.主语=业务.主语AND出生.主语=董事长.主语
该查询涉及3项谓语属性,出生、业务和董事长的连接操作。由于谓语表中的行都是按照主语列进行排序的,可以快速执行这种以“主语-主语”作为连接条件的查询操作,而这种连接操作又是常用的。
2.5 多重查询
多重查询法是对RDF存储的一种延伸,该方法利用主、谓、宾语之间的概率分布关系进行自由组合,其典型的三元组排列组合方式如表4所示。因为该方法将所有RDF进行排列组合,这极大地提升了数据库查询检索的效率,但也增加了存储空间的消耗。

表4 三元组模式查询能够使用的索引Table 4 Usable indexes for triple query
图7所示的链式SPARQL查询“查找生于某年份目前是公司的董事长的人”,可以通过spo和pso表的连接快速执行三元组模式“?person董事长?company”与“?company行业?ind”的连接操作,避免了单表的自连接。
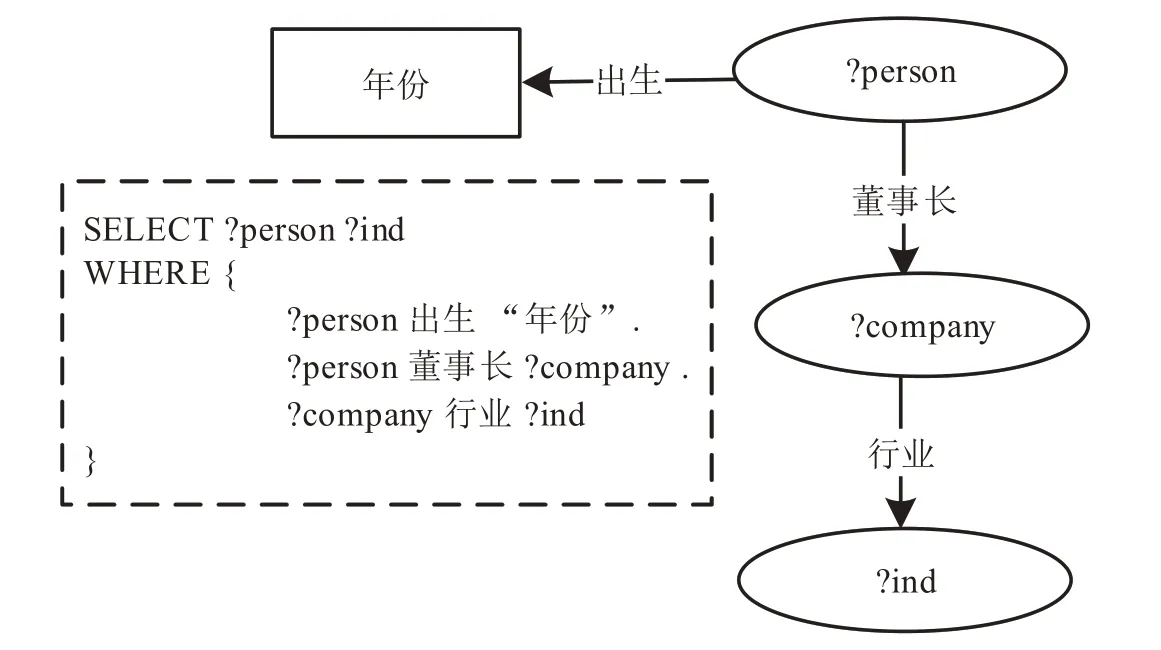
图7 一个链式SPARQL查询Fig.7 A chained SPARQL query
2.6 混合管理
例如,在表5中的dph栏中,主语刘某的谓语行业(pred1列)是多值谓语,则在其宾语列(val1)存储id值lid:1。例如,主语刘某和陈某的谓语董事长都被分配到pred3列,该列也存储了主语M公司的谓语专业化公司和直属单位。

表5 混合管理方案Table 5 Hybrid management solution
SELECT a.主语
FROM dph AS a
WHERE a.pred1=‘籍贯’AND a.val1=‘出生地’AND a.pred2=‘出生’AND a.val2=‘年份’AND a.pred3=‘董事长’
从中可以看出,对于知识图谱的星型查询,混合管理存储方案只需查询dph栏即可完成,无须进行连接操作。
现在开始存储以L公司作为主语的三元组,见表6所示。将(L公司,母公司,M公司)进行数据添加时,根据h1的值将谓语母公司存入列pred1。将(L公司,子公司,C厂)进行数据添加时,根据h1的值将谓语子公司存储到pred2。在对(L公司,业务,清洁能源)进行数据添加时,将谓语业务被h1映射到列pred1,但该列已被占用,因而接着被h2映射到列pred3。将(L公司,子公司,B厂)插入到知识库时,谓语子公司被h1映射到列predk。在把(M公司,直属单位,X设计院)添加到知识库中时,此时数据库原有位置被占用,会自动添加到额外空间内容。
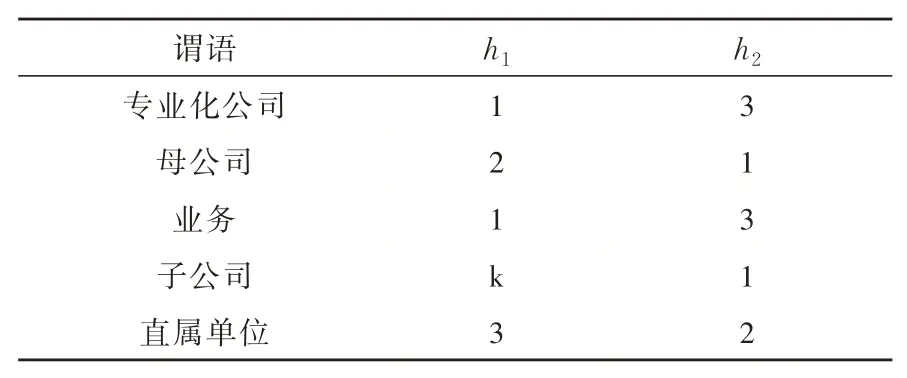
表6 谓语到列映射的散列函数Table 6 Hash function of predicate-to-column mapping
为此,构建图着色算法的冲突图。图中节点为知识图谱中的所有谓语。每对共现谓语节点之间由一条边相连。图着色问题的要求是为冲突图中的节点着上颜色使得每个节点的颜色不同于其在邻接节点的颜色,并使所有颜色数最少。对应到谓语映射问题,即为冲突图中的谓语节点分配列,使得每个谓语映射到的列不同于其任一共现谓语映射到的列,并使用所用的列数目最少。图8给出了图4中知识图谱的冲突图。可见,对于13个谓语,仅使用了5种颜色,即只需使用5列。需要指出的是,图着色是经典的NP难题,对于规模较大的冲突图可用贪心算法求得近似解。

图8 冲突图Fig.8 Interference graph
3 众源知识存储关键技术
为了适应大规模知识图谱数据的存储管理与查询处理,知识图谱数据库内部针对图数据模型设计了专门的存储方案和查询后处理机制,以图数据库Neo4j为例创建其存储核电站知识场景方案。
这一部分将深入Neo4j图数据库底层,探究其原生的图存储方案。作为对比,将原有的众源数据知识库与关系数据库进行存储原理进行分析。图9左边给出了一个全局索引的示例,典型方法是利用B+树进行全局检索,如查找“张某”的同事,需要O( logn)带代价,其中,n为节点总数。如果觉得这样的查找代价还是可以接受的话,那么换一个问题,谁认识“赵某”的查找代价是多少?显然,对于这个查询,需要通过全局索引检查每个节点,看其认识的人或共事的人中是否有赵某,总代价为O(nlogn),这样的复杂度对于图数据的遍历操作是不可接受的。也有学者认为,可为“被认识”关系再建一个同样的全局索引,但那样索引的维护开销就会翻倍,而且仍然不能做到图遍历操作代价与图规模无关。

图9 邻接关系的全局索引示例Fig.9 Example of global index for adjacency
在图数据库中,把属性信息认为是区别于关系数据库的关键点,即数据库中最基本、最核心的概念,如关系数据库中的“关系”,才能实现真正的“无索引邻接”特性。在图6右边查找“张某”的同事时,可以通过张某的“同事”出边进行索引。搜索认识“赵某”的员工,可以通过赵某入边进行索引。当然,目前这种方法的时间复杂度为O(1)。
Neo4j与其它众源数据知识库不同,它是将属性数据集和节点数据集分开管理。该方法的提出,使得Neo4j的运行和管理效率都在同行业数据库中处于领先地位。首先,在Neo4j中是如何存储图节点和边。图10所示,在Neo4j中,存储单个节点和属性分别占用9和33个物理存储单位。其中,节点集数据存储在neostore.nodestore.db里,在每一个节点集中分别存储着不同的记录信息。包括,相连节点、本节点的身份信息、本节点的属性信息以及该节点属性信息的身份信息等内容。在众源数据属性信息集中,属性集存储在neostore.relationshipstore.db里,在单个属性数据中,会依次存储该属性物理位置是否使用、该属性的头节点和尾节点位置信息、还会包含属性连接节点相应的身份信息,最后还有头节点指向下一个节点的地址以及尾节点指向下一个节点的地址信息。
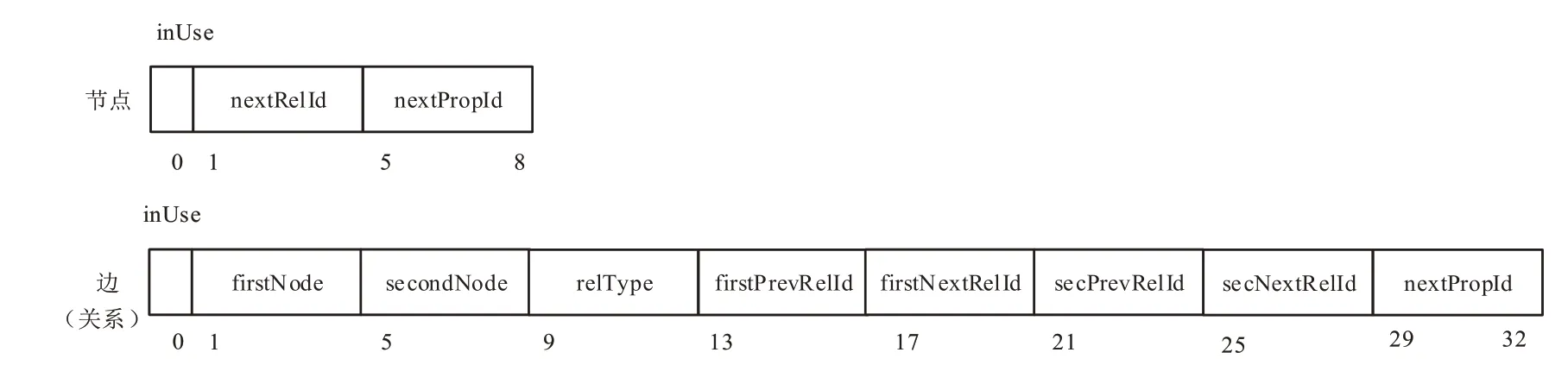
图10 Neo4j中节点和边记录的物理存储结构Fig.10 Physical storage structure of the node and edge records in Neo4j
图11所示是以核电站员工为例,用Neo4j的各种节点集和属性集进行举例,来说明各种众源数据的知识信息是如何相互之间进行信息沟通。以张某和赵某节点为例,二者在存储关系上分别属于数据存储的初始位置。通过二者都关联的同事信息,可以通过虚线链接来确定张某与赵某节点。对于图中的核心节点与项目节点都使用双向联系,而对于单一位置员工的属性信息,则使用单一方向联系。该方法不仅方便查询各个员工的关联关系,同时对于众源知识图谱添加与管理也非常便捷。

图11 Neo4j中图的物理存储Fig.11 Physical storage diagram in Neo4j
例如,由节点3导航到节点1的过程为:
(1)由节点3知道其第1条边为7;
(2)在边文件中通过定长记录计算出边7的存储地址;
(3)由边7通过双向链表找到边8;
(4)由边8获得其中的终止节点id(secondNode),即节点1;
(5)在节点文件中通过定长记录计算出节点1的存储地址。
4 结果与分析
当前有多种知识图谱开源及商业数据库,本文以Neo4j为例,设计具体的核电站知识存储过程,Neo4j的1.0版本发布于2010年。Neo4j是典型的以知识形式进行数据存储与管理的数据库,它不仅规定了专属使用语言,而且还提供了数据库专业的核心案例以帮助初学者更好地入门。同时,Neo4j还具备OLTP数据库必须的ACID事务处理功能。
Neo4j的不足之处在于其社区版是单机系统,虽然Neo4j企业版支持高可用性(High Availability)集群,但其与分布式图存储系统的最大区别在于每个节点上存储图数据库的完整副本(类似于关系数据库镜像的副本集群),不是将图数据划分为子图进行分布式存储,并非真正意义上的分布式数据库系统。如果图数据超过一定规模,系统性能就会因为磁盘、内存等限制而大幅降低。
开发者注册信息后可以免费下载Neo4j桌面打包安装版,其中包括Neo4j企业版的全部功能,即Neo4j服务器、客服端及全部组件。安装之后打开软件为Neo4j Desktop数据库管理界面,然后选择浏览器,打开Neo4j浏览器。Neo4j浏览器是功能完成的Neo4j可视化交互式客户端工具,可以用于执行Cypher语言。使用Neo4j内置的电影图数据库执行Cypher查询,返回“汤姆·汉克斯”所出演的全部电影,如图12所示。此外,成功启动Neo4j服务器之后,会在7474和7473端口分别开启HTTP和HTTPS。例 如,使 用 浏 览 器 访 问http://localhost:7474/进 入Web界 面,执 行Cypher查询,其功能与Neo4j浏览器一致。
本文以具体知识存储过程为例。如图12所示,对核电站的工作人员信息进行代码案例测试,六名人员与四个地理位置信息的知识结果见图12(a),通过分析可以发现,张某与孙某都是来自同一个城市,并且二人是夫妻关系;在两类节点之间,王某是最受同事喜爱的人。从图12(b)中可以看出,每个员工节点有不少于一类属性关系,这表明各类知识节点的属性关系,不仅仅只是同事和家属关系,而且对比(a)与(b)可以看出,实体类的关系存储和表示,并非是单一的行或列存储。对众源数据的地理知识的存储,表现的具体实例上可以看出是节点与属性知识的融合。

图12 Neo4j数据库实例Fig.12 Neo4j database instance
5 结论
针对众源数据这一典型数据的存储问题,利用当前流行的知识图谱技术对众源数据进行存储,不仅利用关系数据库的方法,还利用了图数据库的方法进行存储。通过对各种方法的对比分析,发现传统的关系数据库在存储众源地理信息时,会造成存储位置上的数据稀疏,并且弱化了众源数据中地理知识的相关关系。与之对比,图数据的优点明显,不仅可以解决关系型数据库在存储众源地理知识时数据存储稀疏,造成大量空间浪费的问题,而且还可以刻画了众源数据的关系特征。最后通过具体案例分析进一步表明,利用知识图谱数据库存储众源地理信息可以达到复杂度为O(1)的需求。在后续研究中,应进一步优化对众源数据的高效率知识抽取和挖掘,以及对抽取知识的智能化推理等问题。
