基于特征融合的随机森林模型茶鲜叶分类
2021-07-24陈忠辉方洪波闫建伟张文勇谢本亮
万 广,陈忠辉,方洪波,闫建伟,张文勇,谢本亮
(1 贵州大学 大数据与信息工程学院,贵州 贵阳 550025; 2 贵州大学 机械工程学院,贵州 贵阳 550025; 3 贵州大学 计算机科学与技术学院,贵州 贵阳 550025)
作为茶叶的原产地之一,中国有着历史悠久的茶文化底蕴[1],茶鲜叶质量的优劣基本决定着茶叶品质的高低。随着劳动力的短缺以及劳动成本的提升,茶产业机械化、工业化进程的不断推进,茶鲜叶的机械化采摘技术和装备日趋成熟。但机采茶鲜叶混杂度高,包含有各种等级的茶叶,因此在制茶工艺中,分选成为了一道费工、费时且关键的工序。早期根据茶鲜叶的物理特性,研制出了滚筛、圆筛、风选等分选方法[2],虽然可以去除茶鲜叶中的杂物(如残叶、叶梗等),但难以对茶鲜叶进行精确的等级划分。
近年来,随着机器视觉和机器学习技术的发展,茶叶的分类技术进入智能化时代。陈全胜等[3]利用颜色特征建立支持向量机(Support vector machines, SVM)分类模型,通过色泽来分辨茶叶品质的优次,模型的平均识别率达到95%左右;吴正敏等[4]以大红袍为例,通过提取夏秋季节茶叶各种形态特征参数,判断特征权重进行特征选择,并且设置不同的权重比来完成叶和梗的分离,最终识别准确率为93.8%;高震宇等[5]通过建立卷积神经网络,通过局部连接和权值共享等方法提高了网络的训练性能,最终识别的准确率不低于90%。余洪[6]通过 RGB(Red, green, blue)和 HIS(Hue, instensity,saturation)颜色模型提取颜色特征,通过统计矩和灰度共生矩提取纹理特征,共提取到12个颜色特征和22个纹理特征,建立基于主成分分析、遗传算法和BP神经网络的茶叶品质分级模型,识别准确率达到92.5%。
本研究应用随机森林分类模型,以3种不同品质的茶鲜叶图像作为依据,分别提取茶鲜叶样本图像的颜色特征和边缘特征,并且将2种特征同时输入到分类模型中,以期实现对3种不同品质茶鲜叶的精确识别和分类。
1 材料与方法
1.1 图像采集
试验研究对象是绿茶中的都匀毛尖,于春季在贵州省黔西南州采摘,共采集到茶鲜叶样本叶片906个,其中包括单芽299个、一芽一叶302个、一芽二叶305个。拍摄环境为实验室,拍照设备为手机荣耀 20 (后置四摄 4800 万+1600 万+200 万+200万像素);为了突出茶鲜叶的颜色特征和边缘特征,拍照背景选择A4白纸以提高对比度;并用普通白炽灯照射,减弱周围其他光源的影响;拍摄方式为垂直俯拍,并用支架固定手机拍摄位置,手机与样本之间的距离为30 cm左右。采集的部分样本图像如图1所示。

图 1 不同等级茶鲜叶样本图像Fig. 1 Representative images of different grades of fresh tea leaves
1.2 图像预处理
图像采集过程中避免不了外界因素的干扰,为了便于后续特征提取的方便,需要对获得的图像数据集进行预处理。其中包括区域裁剪、尺寸归一化和噪声去除[7]。具体操作流程如图2所示。

图 2 图像预处理流程图Fig. 2 Flow chart of image preprocessing
1.2.1 区域裁剪和尺寸归一化 由于拍摄条件的限制,茶鲜叶在图像中的显示位置会有差异,RGB图像也不能保持一致。因此需要对茶鲜叶的图像进行区域裁剪。区域裁剪的目的是将研究以外的区域去除,保留图像中心区域的茶鲜叶图像作为感兴趣区域 (Region of interest,ROI);对区域裁剪处理后的图像进行尺寸归一化,使各个指标处于同一个数量级,处理后的图像分辨率为 2 56×256像素,如图2b所示。
1.2.2 噪声去除 图像中存在的噪声会对茶鲜叶叶片的特征提取产生不利的影响,因此需要消除图像中的噪声干扰。采用中值滤波算法对图像进行预处理,在去除噪声的同时保留完整的叶片信息,并且能够很好地保护图像的边缘信息,使图像中茶鲜叶的边缘更加平滑,便于后续边缘特征的提取。得到的滤波后图像如图2c所示。
1.3 图像特征提取
1.3.1 颜色特征提取 颜色作为一种全局特征[8-10],是图像中最简单直接的一种特征,直方图作为一种简单有效的基于统计特性的特征描述,能描述图像中颜色的全局分布。本文将RGB颜色空间和HSV(Hue,saturation,value)颜色空间[11]配合使用来区分不同等级的茶鲜叶颜色特征。HSV是根据颜色的直观特性创建的一种颜色空间,更接近实际人类的视觉特征,手机拍摄获得的图像为RGB格式,需要转化为HSV格式,RGB坐标系向HSV空间转化的公式为:

式中:(R,G,B)min表示三者中的最小值;H代表色调,用角度度量,取值范围为 [0°,360°],从红色开始按逆时针方向计算,红色为0°,绿色为120°,蓝色为240°;S代表饱和度,表示颜色接近光谱色的程度;V代表明度,表示颜色明亮的程度,通常取值为0%(黑)~100%(白);R、G、B分别表示红、绿、蓝通道。
对经过中值滤波处理后的图像进行颜色特征的提取,3种不同等级的茶鲜叶的RGB空间的直方图和HSV空间的H、S、V通道的直方图像素分布情况如图3~图6所示。
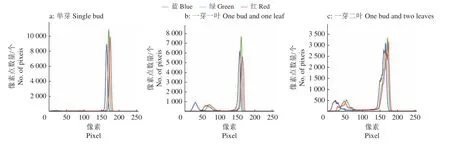
图 3 3种等级茶鲜叶的颜色空间直方图Fig. 3 Color space histogram of three grades of fresh tea leaves

图 4 单芽茶鲜叶的H、S、V通道直方图Fig. 4 H, S, V channel histogram of fresh tea leaf with single bud

图 5 一芽一叶茶鲜叶的H、S、V通道直方图Fig. 5 H, S, V channel histogram of fresh tea leaf with one bud and one leaf

图 6 一芽二叶茶鲜叶的H、S、V通道直方图Fig. 6 H, S, V channel histogram of fresh tea leaf with one bud and two leaves
对多个茶鲜叶的直方图的像素进行统计得出,在RGB空间中单芽图像的像素主要分布区间为[134,184],一芽一叶图像的像素主要分布区间为[43,96]和[147,186],一芽二叶图像的像素主要分布区间为[41,197]。在HSV空间中3种等级的茶鲜叶图像H通道像素主要分布区间为[0,70],S通道像素主要分布区间为[0,200],V通道像素主要分布区间为[40,200]。为了加强不同等级茶鲜叶像素之间的差异,分别对H、S、V三通道像素进行非等间隔的量化,其中色调H空间分为8份,饱和度S和亮度V空间各划分为3份,以提高分类器的构建效率和识别的准确率。
1.3.2 边缘特征提取 图像的边缘特征主要针对物体的外边界[12-14]。Canny算法是一种多级边缘检测算法,在实际操作中,Canny算法使用一个低阈值和一个高阈值来确定哪些点属于轮廓,低阈值主要包括所有属于明显图像轮廓的边缘像素;高阈值是定义所有重要轮廓的边缘,最后组合低阈值和高阈值两幅边缘图生成最优的轮廓图。图像的边缘可以指向不同的方向,因此经典Canny算法用4个梯度算子来计算水平、垂直和对角线方向的梯度[15]。本文采用梯度算子中的Sobel算子计算水平和垂直方向的差分Gx和Gy,由这2个条件便可计算梯度模和方向,如式(4)、式(5)所示。

图 7 边缘特征图像Fig. 7 Edge feature image
1.4 随机森林算法
1.4.1 算法原理 随机森林 (Random forest,RF)[16-19]属于并行集成学习中Bagging(Bootstrap AGGregatING)算法的一种扩展变体,是在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入随机属性选择。它将多种弱分类器集成,形成新的分类器模型,决策树决定了输出分类,无需特征筛选也能得到较高的正确率,对特征具有较好的鲁棒性。与传统的分类器相比,随机森林需要很少的参数调整,并且在准确率方面有很大的优势。随机森林拥有其独特的特点,能够处理很高维度(特征较多)的数据,不需要降维,训练速度较快,容易做成并行化方法,由于随机性的引入,使得其很少出现过拟合的现象,随机森林算法流程如图8所示。

图 8 随机森林流程图Fig. 8 Flow chart of random forest
1.4.2 随机森林的训练过程 随机森林的模型训练是通过随机采样(Bootstrap)方法随机有放回地抽取k个样本,并进行Ntree次采样,生成Ntree个训练集,分别训练Ntree个决策树模型的过程。对于单个决策树模型,每次分裂时根据信息增益和信息熵选择最好的特征进行分裂。对没有抽中的样本作为袋外数据 (Out of bag,OOB)。
针对分类问题,随机森林的输出采用多数投票法。利用随机森林模型对测试集样本进行分类判别,过程就是让每棵决策树进行投票抉择,最终输出最多的那个类别作为分类结果,输出判别式如式(6)所示。

式中: a rgmax表示函数取得最大值时的参数值;H(x)表示随机森林的最终分类结果;hi(x)表示单一决策树模型分类结果;I()为示性函数(所谓示性函数是指一个函数使得当集合内有此数时值为1,当集合内无此数时值为0)[18];Y表示输出变量(或称目标变量)。
2 结果与分析
2.1 试验平台和参数
本试验在Pycharm环境下进行操作,所用电脑操作系统为Win10(64位),运行内存4 G,处理器为酷睿i5-6200u,主频2.30 GHz,进行图像处理为OpenCV2库。通过sklearn.ensemble调用Random-ForestClassifier分类模块。随机森林中决策树的数目(Ntree)对最终分类结果有着及其重要的影响,Random-ForestClassifier模块中通过n_estimators进行调节。
多次试验证明,当Ntree取值较小时,随机森林的分类误差会较大,当Ntree的值逐渐增大时,随机森林分类的精确度会有明显的提升,但最终会趋于稳定,甚至会有所下降。但当Ntree的数量越大时,占用的内存与训练和预测的时间也会相应增加,且边际效益是递减的,所以要在可承受范围内尽可能地选取合适的数量。
为了进一步选择合适的决策树数量,在固定其他参数不变、仅改变n_estimators参数的情况下,对茶鲜叶数据集进行多次分类试验,观察分类精确度随着决策树数目的变化。
图9显示了分类准确率随着Ntree变化而变化的曲线。考虑到内存和训练时间,本试验的Ntree选择为35。
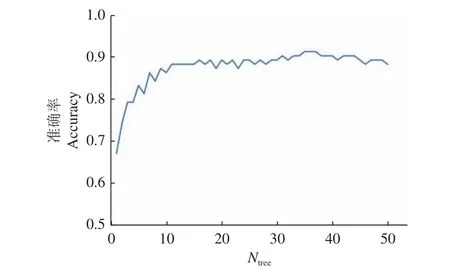
图 9 分类准确率随决策树数目(N tree)的变化Fig. 9 Classification accuracy varied with the number of decision trees (N tree)
2.2 试验结果
试验时针对上述构建好的随机森林分类器模型,将预处理之后得到的906张图像(单芽图像299张,一芽一叶图像302张,一芽二叶图像305张)按照4∶1的比例划分后进行试验,其中训练集724张,测试集182张。识别准确率(Accuracy)是分类器性能判断的重要指标之一,另外,精确率(Precision)、召回率(Recall)以及综合评价指标(F1-score)在最终分类阶段也作为常用的指标。4种评价指标公式如式(7)~式(10)所示。

式中:TP(True positive)为真阳性,表示实际类别为正,算法输出类别也为正;FP(False positive)为假阳性,表示实际类别为负,样本输出类别为正;TN(False negative)为假负性,表示实际类别为负,算法输出类别也为负;FN(False negative)为假阴性,表示实际类别为正,算法输出类别为负。
为了验证本文方法的有效性,分别将2个单一特征和融合特征输入到随机森林分类模型中,根据式(7)~(10),得到准确率、精确率、召回率和综合评价指标等结果数值,分别列于表1~表3。

表 1 颜色特征分类结果Table 1 Color feature classification results %

表 2 边缘特征分类结果Table 2 Edge feature classification results%

表 3 融合特征分类结果Table 3 Fusion feature classification results %
由表1可知,颜色特征的识别准确率为92.31%,对单芽的分类结果最好,精确率、召回率和综合评价指标都为96.23%,主要原因在于单芽的直方图像素区间较小,比较集中;一芽一叶和一芽二叶的颜色特征综合评价指标为90%左右,因为大多数一芽一叶的直方图像素区间为2个,但2个区间的像素数量并不是绝对为0,所以一芽一叶和一芽二叶容易造成混淆。
由表2可知,边缘特征的识别准确率为90.11%,比颜色特征低2.2个百分点,主要原因也在于一芽一叶和一芽二叶之间的混淆,例如:测试集混淆矩阵中,一芽一叶55张,有7张识别为一芽二叶;一芽二叶59张,有8张识别为一芽一叶。
由表3可知,颜色和边缘特征融合识别的准确率为99.45%,比颜色特征和边缘特征的识别准确率分别高7.14,9.34个百分点,该方法取2个特征识别时的交集,避免了单一特征识别时的局限性,提高了识别准确率,证明了该方法的可行性。
2.3 不同分类模型结果对比
为了进一步说明本文方法的有效性,将本文方法同传统的机器学习方法K最近邻(K-nearest neighbor, KNN)[20]和SVM分类器[21-22]进行对照试验。其中K最近邻算法中K设置为3,SVM分类器中惩罚系数C设置为10,核函数系数gamma为0.0001,试验结果如表 4 所示。

表 4 不同模型的平均分类结果Table 4 Average classification results of different models %
由表4可以看出,针对茶鲜叶等级的分类问题,随机森林模型明显优于K最近邻和SVM分类器,在准确率上分别高出15.38和5.49个百分点,精确率、召回率和综合评价指标也有明显的优势。以上结果表明,在茶鲜叶的分类中,随机森林模型的分类性能最优,SVM次之,K最近邻效果最差。作为机器学习中最常用的一种算法,SVM需要对参数进行不断的优化,以提高分类的准确率和防止过拟合问题的出现,相较于随机森林模型需要耗费更多的时间和精力。作为最简单的算法之一,K最近邻算法原理简单,容易理解,但需要对样本的特征进行量化,才能获得较好的分类结果。
3 结论
本文以春季的都匀毛尖作为研究对象,利用随机森林分类模型,提出了一种颜色特征和边缘特征融合的方法,对3种不同等级的茶鲜叶进行识别和分类。根据准确率、精确率、召回率和综合评价指标进行判定。首先对茶鲜叶图像进行区域裁剪、尺寸归一化和噪声去除等预处理,提取RGB空间的彩色直方图并转移到HSV空间中,计算H、S、V三通道像素区间,获得茶鲜叶图像的颜色特征。利用Canny边缘检测算法提取图像的边缘特征,将2种特征融合作为茶鲜叶的识别特征。为了判断本文方法的有效性,将单一特征和融合特征后的分类结果进行对照,并且将随机森林模型同K最近邻和SVM分类器进行对照试验。试验结果表明,特征融合随机森林模型的分类准确率、精确率、召回率和综合评价指标分别达99.45%、99.40%、99.44%和99.42%,明显高于单一特征的分类结果,并且随机森林模型的分类性能最优。该方法也能快速应用到其他类型的茶鲜叶分选,为茶鲜叶分选的智能化进程提供了一定的依据。
