一种融合注意力机制的自适应实体识别方法
2021-07-23陈启丽黄冠和王元卓杜则尧
陈启丽,黄冠和,,王元卓,张 琨,杜则尧
(1. 北京信息科技大学 自动化学院,北京 100192;2. 中国科学院 计算技术研究所,北京 100190;3. 北京微梦创科网络技术有限公司,北京 100080)
0 引言
MUC-6[1]提出的命名实体识别(NER)是信息抽取任务之一,也是完成自然语言处理下游任务(如机器翻译、文本生成以及问答系统等)的重要保证。目前,NER在中英文上均取得大量成果[2-4],但是现有的监督学习方法依赖于大规模语料,针对低资源领域,如何快速移植已经在通用领域取得突破的NER方法仍然是研究热点。
近年来在通用领域应用的NER算法可以分为以下三类: ①基于规则匹配的算法; ②基于统计机器学习的算法; ③基于神经网络深度学习的算法。基于规则匹配的算法始终无法解决人工构建规则复杂性问题和低泛化能力问题。在基于统计机器学习的方法中,CRF在序列标注中是广泛应用的模型,能有效提取标签预测的约束特征[5-6],使得不合理输出标签序列出现的概率降低。端到端深度学习神经网络模型也被应用于大规模文本的非线性隐性特征的自动提取,被大量应用在改进统计机器学习NER任务的效果上,例如,向CRF模型中引入深度学习网络(DNN)和词性特征以优化系统特征提取能力[7],融入多种语义特征的双向长短时神经网络(BiLSTM)模型[8],在BiLSTM的基础上引入注意力机制(attention mechanism)[9]等,神经网络的强特征提取能力使NER研究取得了突破性进展。
近期的研究热点之一是如何融合词向量来改进NER算法的效果。用向量表示文本中的字、词,甚至句子、段落等,一直都是许多下游任务,如机器翻译、问答系统的关键基础任务。近年来的研究表明,加入基于表示学习的预训练词向量语言模型比完整训练神经网络效果更好[10]。Devlin等人提出的BERT模型[11]使用深度双向Transformer Encoder神经网络[12]联合所有层构建双向预训练语言模型,根据不同的应用领域对神经网络输出层进行微调,在CoNLL、SQuAD任务上得到很好的效果。ERNIE[13]在中文领域使用了BERT-WWM(whole word mask)模型,其与原模型最大的区别在于采用了实体级遮蔽训练策略,并结合外部知识来训练BERT模型,在中文领域进行的NER实验性能优于原始BERT。尽管在通用领域这些模型已经达到了SOTA(state of the art),但是通过大量非结构化语料下训练的预训练模型能否在特定领域提升NER任务效果仍然需要相关研究验证。
由于深度学习算法依赖于人工标注的大规模语料,导致这些模型在特定领域并不具备良好的可移植性。为了解决这个问题,迁移学习被引入以解决其在特定领域的应用问题。
一般来说,跨域数据的分布是不同的。直接的解决方法是在各个领域训练特定的系统。但是,这一方法需要针对每个目标域的训练数据进行标记,耗时且无法利用领域之间的共享信息。另一种策略是,从可使用已标记数据的域集中训练单个模型,然后将其应用于其他目标域,这种在不同分布上训练和测试模型的问题被称为领域适应。
目前主流的NER迁移学习策略主要包括: ①多任务学习(MULT): 使用源域数据集和目标域数据集同时训练神经网络,共享一部分参数; ②参数初始化(INIT): 使用源域数据集单独训练神经网络来完成初始化,然后用目标域数据集修正模型的语义空间[14]。此外,迁移学习中神经网络可被用于调整模型的参数区域,这种神经网络一般被分为词嵌入层、隐含层和输出层。Mou等人[15]的研究表明,随机初始化的输出层在目标域的表现优于迁移源域输出层,而词嵌入层和隐含层的泛化能力较好,迁移到目标域后能够有效地映射到目标域的语义向量空间上。Yang等人[16]认为迁移学习的效果主要取决于: ①目标域任务的标签数量; ②源域和目标域的语义相关性; ③目标域和源域可以共享的参数量。因此,本文假设迁移学习的效率同样也受到目标域和源域相关性的影响。
本文尝试根据以上方法的特点来改进现有迁移学习方法。为了更好地利用源域模型,受Lin等人[17]的启发,本文提出一种基于BERT的自适应神经网络。面对目标域与源域通常存在着许多未登录词和不同语法的挑战时,尝试引入自适应神经网络输出适应层来应用迁移学习策略,模型的网络结构如图1所示。该网络是一个融合了注意力机制的自适应神经网络模型,整体模型框架由文本嵌入层、BERT嵌入层、预训练源域BiLSTM层、基于注意力机制的输出自适应层、CRF标签层组成。
本文选择“古汉语”领域来作为迁移的目标领域,主要原因有:
(1) 古汉语作为现代汉语的孪生体,与现代汉语的语义空间差别较大,古汉语中存在大量同字不同义的现象,这种现象与其他领域相比更为频繁。这一特点可以更好地验证迁移学习模型的实用性。
(2) 古汉语作为中文的珍贵参考资料,由于语料的稀缺,在少量语料上进行的NER实验,可以探索基础任务下迁移学习的表现,对其他低资源信息抽取任务有参考价值[18]。
本文引入了BERT-BiLSTM-CRF的模型框架,通过预训练模型改进预训练词向量的语义丰富度,并通过BiLSTM提取上下文特征,通过CRF来优化序列标注,最后基于迁移学习的方法,改进自适应的神经网络层实现古汉语领域的NER。通过在古文数据集上的对比实验表明,本文提出的方法在识别精度上优于直接移植通用模型。
本文组织结构如下: 第1节介绍BERT模型的实现原理;第2节介绍自适应神经网络的具体组成;第3节给出实验结果并进行分析;第4节是总结和展望。
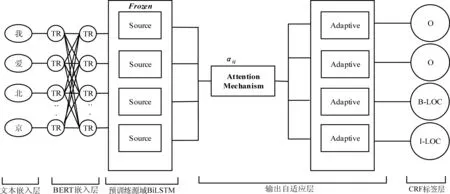
图1 Adaptive-BERT-BiLSTM-CRF模型结构
1 BERT
在整个预训练过程中,BERT通过采用Transformer Encoder模型实现了所有层之间的联合语境约束优化,实现了从左到右的双向训练,同时也能进行上下层之间的交叉信息传递,而不只是关注当前的输入词的文本信息。
Transformer Encoder由多头自注意机制层和前馈神经网络层组成,如图2所示,多头注意机制层主要由多个注意力机制单元组成,单个注意力机制单元采用SDPA(scaled dot-product attention)原理。对每个输入进行完全双向的注意力值计算,输入的嵌入词向量I与代表每个单词位置的位置编码矩阵相加后,通过与矩阵权值WQ、WK、WV相乘计算生成Q(Query)矩阵、K(Key)矩阵、V(Value)矩阵,其中Q矩阵[Q1,Q2,Q3,…],由当前词生成,K矩阵[K1,K2,K3,…]和V矩阵[V1,V2,V3,…],由上下文单词生成。如式(1)所示,在单个注意力机制单元中,输入当前词的Q矩阵与[K1,K2,K3,…]相乘后再除以K矩阵的维度dk,经过Softmax归一化得到权重矩阵并与[V1,V2,V3,…]相乘得到自注意力单元Zi。由式(2)所示,拼接所有自注意力单元Zi,经过W进行线性映射得到多头注意力矩阵Z,使用Z矩阵来反映当前词与上下文单词的关系。最后将Z与原来的输入嵌入词向量I相加并正则化,通过前馈神经网络后再一次与前馈层输入矩阵相加并正则化,得到Transformer编码向量。
2 自适应神经网络层
2.1 源域预训练LSTM层
LSTM神经网络模型针对序列标注任务进行特征提取,目前已得到了广泛应用,可以用来训练拥有丰富语料集的传统新闻领域的模型,本文参考文献[19]实现源域模型的快速训练,如图3所示。LSTM单元的结构图中,it、ft、ot分别表示LSTM单元中的输入门(input gate)、遗忘门(forget gate)、输出门(output gate)在t时刻的状态,ht-1表示在t-1时刻的隐藏状态(hidden state),ct表示在t时刻的细胞记忆状态(cell state)。σ表示Sigmoid,tanh表示双曲正切激励函数,如式(3)~式(8)所示。
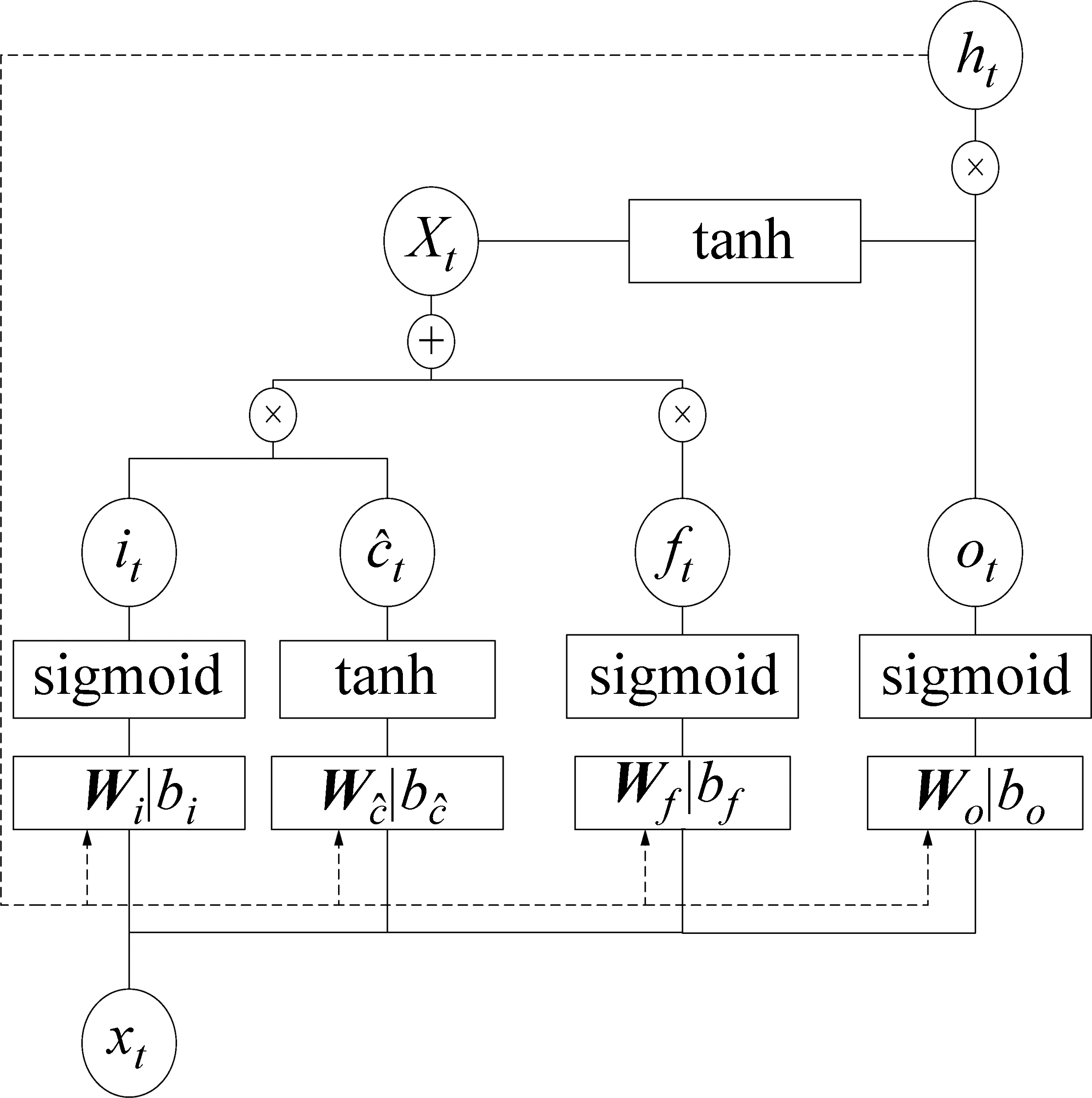
图3 LSTM单元
在t时刻,BERT预训练层的词向量作为LSTM层的输入,与LSTM的t-1时刻的隐藏状态结合得到了t时刻的隐藏状态,最后拼接前向LSTM隐藏状态和反向LSTM隐藏状态即可得到BiLSTM的输出隐藏状态。
2.2 融合注意力机制的BiLSTM输出适应层
引入注意力机制来提取上下文中的特征向量,文本中的关键文字将获得更加高效的特征提取,使得特征向量将融合更多的上下文语义。对输入的句子L=[x1,x2,x3,…], 在t时刻输入BERT嵌入词向量的当前词xt,首先计算注意力权值αtj,其中αtj的值越大说明当前词xt受到xj的影响越大,如式(9)所示。
(9)
本文使用下面四种对齐算法计算score(xt,xj),并以此衡量当前词与上下文单词的关联程度,分别是: (a)曼哈顿距离;(b)欧氏距离;(c)余弦距离;(d)感知机机制。其中,曼哈顿距离、欧氏距离的结果越大说明关联程度越高,而余弦距离、感知机的结果越大则说明关联程度越小,最后的结果为score(xt,xj)=a+b-c-d,如式(10)所示。
(10)
然后再将预训练源域BiLSTM冻结层的各个时刻输出隐藏状态hj与注意力权值αtj进行加权求和,得到全局变量gt,并与当前时刻的输出隐藏状态ht拼接后经过矩阵Wg进行线性映射,经过tanh激活函数得到注意力层的输出Mt,并通过随机初始化的BiLSTM进行更深一步的特征提取,如式(11)、式(12)所示。
2.3 CRF标签层
从融合注意力机制的BiLSTM输出适应层提取的上下文特征中,CRF层可以进一步考虑序列标签之间的依赖关系。发射矩阵Pxt,yt是对BiLSTM输出适应层给出的xt输出概率,而转移矩阵Tyt-1,yt则表示从t-1时刻到t时刻,输出yt-1转移到输出yt的概率,对所有预设标签进行归一化计算,得到当前输出标签的概率,在给定输入xt下得到输出yt的得分s(xt,yt)。再进行归一化得到当前输出标签的概率,如式(13)、式(14)所示。
在训练过程中,Viterbi[20]算法用于最大似然估计,使模型对输入文本预测出标定标签的概率最大化,得到Loss的表达式,如式(15)所示。
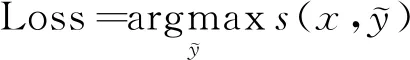
(15)
2.4 训练过程
在迁移学习训练过程中,在预训练语言模型源域BERT时,不可避免地会遇见一些未登录词,这些未登录词使得模型不得不重新生成新的词表并进行训练。为了尽可能利用预训练词向量模型中的丰富语义特征,本文只对出现的高频未登录词单独进行训练,并将其与源语言模型进行整合。初始化后,冻结BERT语言模型参数以避免过度拟合。
将源域数据集DS训练完成的LSTM模型参数θS作为目标域模型LSTM参数θT,由于源域与目标域的特征语义空间存在差异,激进的训练策略会使整个模型丢失来自目标域优化所需的源域语言特征信息。而如果过于谨慎地更新训练源域神经网络,将又会导致整个模型迭代效率下降,且易产生过拟合,本文的迁移学习设置了超参数ξ,作为LSTM层和融合注意力机制的自适应神经网络层的学习率之比,具体定义如式(16)、式(17)所示。
lrS=σ·lrT
(16)
(17)
其中,CountS、CountT分别作为源域、目标域数据集token的数量,ξ作为超参数,且本文将新加入的自适应神经网络层插入最后一层,因为这一层一般包含最少的知识[21],以此让源域模型占主导地位来进行迁移学习。
3 实验
3.1 实验样本与评价标准
本文是针对低资源语料集的表示学习和迁移学习应用,因此需要使用丰富资源的领域作预训练,如表1所示,源域是通用的新闻领域,该领域的公开数据集是人民日报1998年标注集,已被广泛应用于大量NER任务,是公信度较高的测试数据集。目标域为从古代文献上选取的一部分具有代表性的语料,进行了人工标注,并将数据集按照7∶2∶1分割为训练集、验证集和测试集。
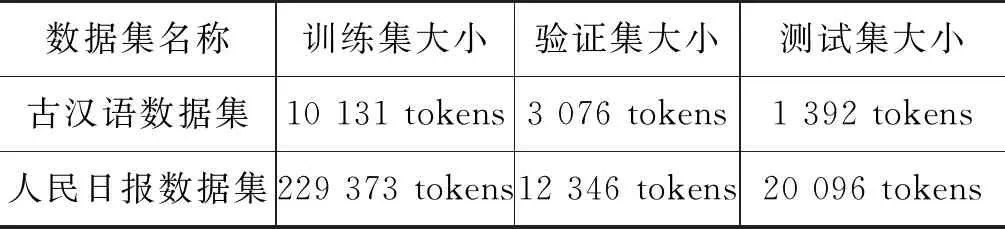
表1 NER训练集大小
本文使用的语料均采用了“BIO”标注方法,“B”表示标注实体的首字,“I”表示标注实体的非首字,“O”表示非标注实体。针对古汉语的NER算法,采用准确率(precision)、召回率(recall),F1值(F1-score)作为评判标准。具体定义如式(18)~式(20)所示。
3.2 不同预训练模型方法性能比较
以下模型都是采用了Tensorflow实现的,实验参数的设置如下:
(1)BERT: 预训练模型使用了开源模型(1)https://github.com/google-research/bert,LSTM 隐藏层神经元的数目为 200, 优化方法为“Adam”,训练批次集为 128个单位,学习率为{3e-4, 5e-4,7e-4},Dropout率为 0.5,训练时间为100 epochs;
(2)BERT_WWM: 预训练模型使用了开源模型(2)https://github.com/ymcui/Chinese-BERT-wwm,LSTM 隐藏层神经元的数目均为200, 优化方法为“Adam”,训练批次集为 128个单位,学习率为{4e-4, 5e-4,6e-4},Dropout率为 0.5,训练时间为100 epochs。
针对古文领域数据集,本文进行了Fine-tuned迁移方法训练源域模型对比实验,对比的模型分别为基于机器学习的CRF、基于深度学习的BiLSTM-CRF,基于预训练词向量的Word2Vec-BiLSTM-CRF,BERT-BiLSTM-CRF,BERT_WWM-BiLSTM-CRF,实验结果如表2所示。
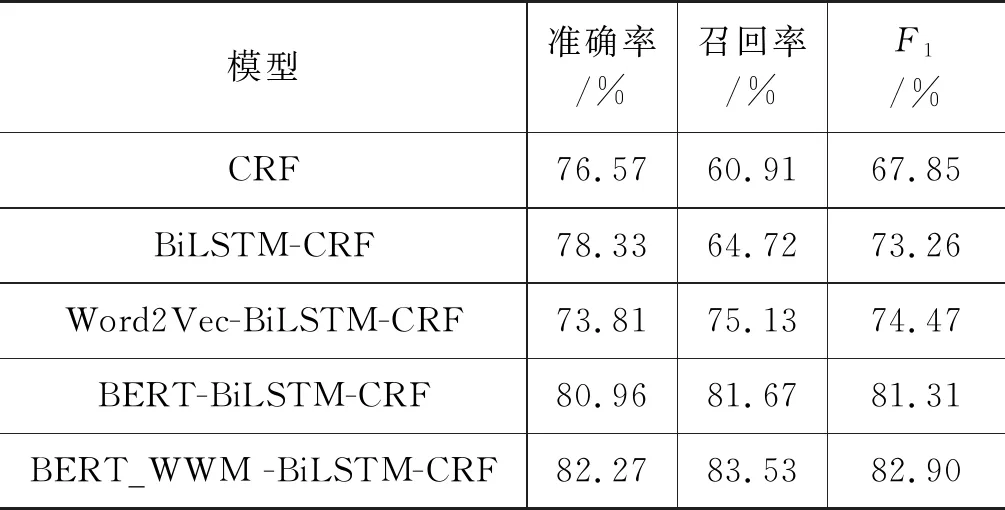
表2 预训练语言模型对比试验
从表2可以看出: 从整体上看,深度学习方法比机器学习方法效果更好,基于预训练词向量的方法要优于一般的深度学习方法。CRF在数年之前被证明是中文NER领域统计机器学习的最优模型[21],而加入BiLSTM神经网络优化CRF后,准确率提高了1.76%,召回率提高了3.81%,F1值提高了5.41%,这说明加入BiLSTM神经网络后具有更强的特征提取能力。加入预训练词向量Word2Vec后的BiLSTM-CRF模型在召回率上提升了10.41%,在F1值上提升了1.21%,说明融入了预训练的文本信息向量后,特征向量语言模型更加丰富了,而加入BERT字向量和BERT_WWM词向量后的BiLSTM-CRF相比主流的BiLSTM-CRF在准确率、召回率、F1值上性能均有显著提升,且BERT_WWM模型是对比实验中效果最好的,F1值达到了82.90%。从实验结果可以看出,相比基于静态构建的Word2Vec词向量,基于Transformer的BERT模型在不同的上下文中生成的不同特征词向量能更好地体现文本的语义,也使得它能更好地处理OOV(out of vocabulary)问题,缓和了模型的过拟合,使古文领域特征提取的效率增加了。
3.3 不同迁移学习方法性能比较
自适应神经网络、INIT、MULT都采用了BERT+BiLSTM+CRF的模型训练,加入的自适应神经网络分为两部分: 随机化的自适应神经网络和进行训练的自适应神经网络,LSTM层数为{150,300,450},使用了“Adam”优化器,学习率被设置为{5e-4,6e-4,7e-4},ξ被设置为4。
为验证自适应层的加入是否可以提高模型优化效率,本文对不同的迁移学习方法和提出的自适应迁移学习方法进行对比研究,训练基于BERT-BiLSTM-CRF的不同迁移学习模型(3)在进行以上实验之前,为了确保基础神经结构接近其数据集上最先进的模型,本文引入BERT后的深度学习模型得到了基于人民日报数据集的优化程度最高的模型,在验证集上达到了94.68%的F1-Score。,并使用这个模型在古文数据集上进行NER测试。
(1)基于Baseline迁移学习的方法: 使用基于BERT预训练模型训练人民日报数据集后,不再进行任何训练,并在古文数据测试集上进行命名实体识别。
(2)基于INIT迁移学习的方法[22]: 使用基于BERT预训练模型训练人民日报数据集后,在古文数据集上再次训练,并在古文数据测试集上进行命名实体识别。
(3)基于MULT迁移学习的方法[23]: 使用基于BERT预训练模型同时训练人民日报数据集和古文数据集,并共享参数,得到的损失函数如式(21)所示。
J=λJT+(1-λ)JS
(21)
其中,J、JT、JS分别表示总损失函数、古文数据集模型损失函数、人民日报数据集模型损失函数。λ设定为0.5,在古文数据测试集上进行命名实体识别。
(4)基于Randomize-Adaptive Attention迁移学习的方法: 训练人民日报数据集后,插入基于自注意力机制的自适应层不再训练,在古文数据测试集上进行命名实体识别。
(5)基于Adaptive Attention迁移学习的方法: 使用基于BERT预训练模型训练人民日报数据集后,插入基于自注意力机制的自适应层,使用古文数据集再次训练,并在古文数据测试集上进行命名实体识别。
实验结果如表3所示。可以看出,在针对低资源的古文领域,基于INIT、MULT、Adaptive Attention迁移学习的方法训练的模型都超过了领域半监督方法,在其他的研究人员的方法中也得到了验证[24],其中本文提出的Adaptive Attention迁移学习模型效果最佳,在准确率、F1值上均超过了领域半监督方法模型8.37%、2.46%,但召回率下降了2.81%,这说明不同领域间的语义差异依旧是巨大的。基于迁移学习方法的特征提取能力得到了源域的优化,由于源域的数据集规模远远大于目标域,因此部分源域的模型参数被固定,从而减轻了梯度爆炸现象。
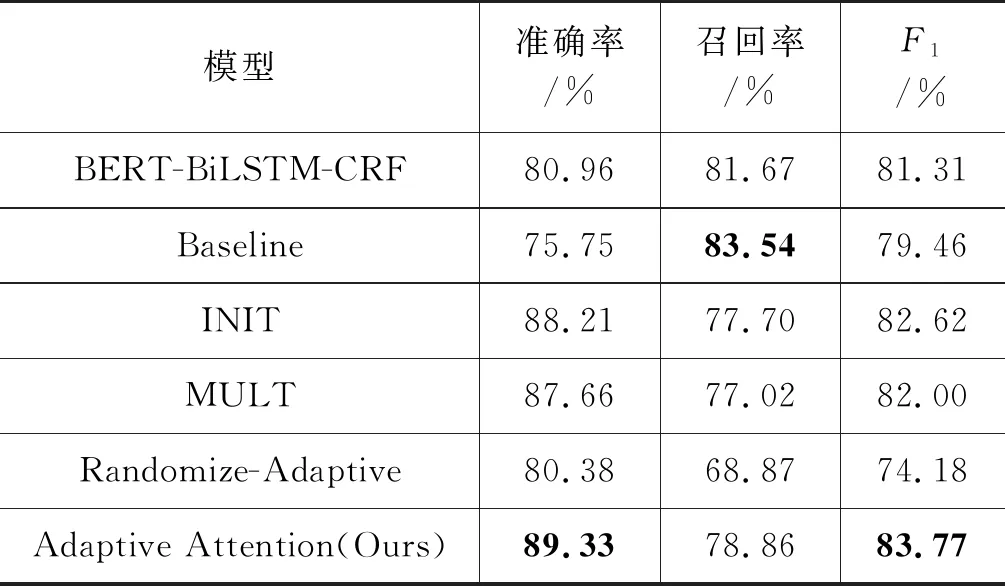
表3 迁移学习对比试验
如图4(a)所示,超参数ξ对模型会产生不同的影响,在ξ分别为4、6时模型得到了良好的效果,在古文域与通用域间进行迁移学习时,当ξ参数过小时,自适应模型性能较差。本文认为这是由于古文模型与通用模型在语义空间上的差异导致的,目标域模型需要更大的优化速度。
从迁移学习的角度出发,实验数据集的大小是影响模型精度的关键因素之一,如图4(b)所示,当数据集较小时,不同的迁移学习优化模型均丢失了许多关键信息,Adaptive-Attention方法对数据集大小的依赖相对较大,本文认为这是由于新插入的自适应层比INIT、MULT等模型网络参数多,导致训练程度也需要相应的增强,才能达到更好的效果。
本文也应用训练成功的人民日报数据集Baseline模型在古文数据集上进行直接验证,结果如表4所示,研究结果表明其效果低于半监督学习方法,这说明不同领域的模型语义特征空间是异质。另一方面,Baseline的高召回率证明了通用领域的模型成功捕获了与领域无关的文本属性,预训练语言模型对未知领域的知识特征有更好的泛化性。为了进一步验证模型尺寸增大对性能的影响,实验还设置Randomize-Adaptive的对照组来随机化插入自适应层,实验结果表明,模型性能有明显下降,证明在迁移学习中单纯增加模型的深度并不能使模型得到优化。
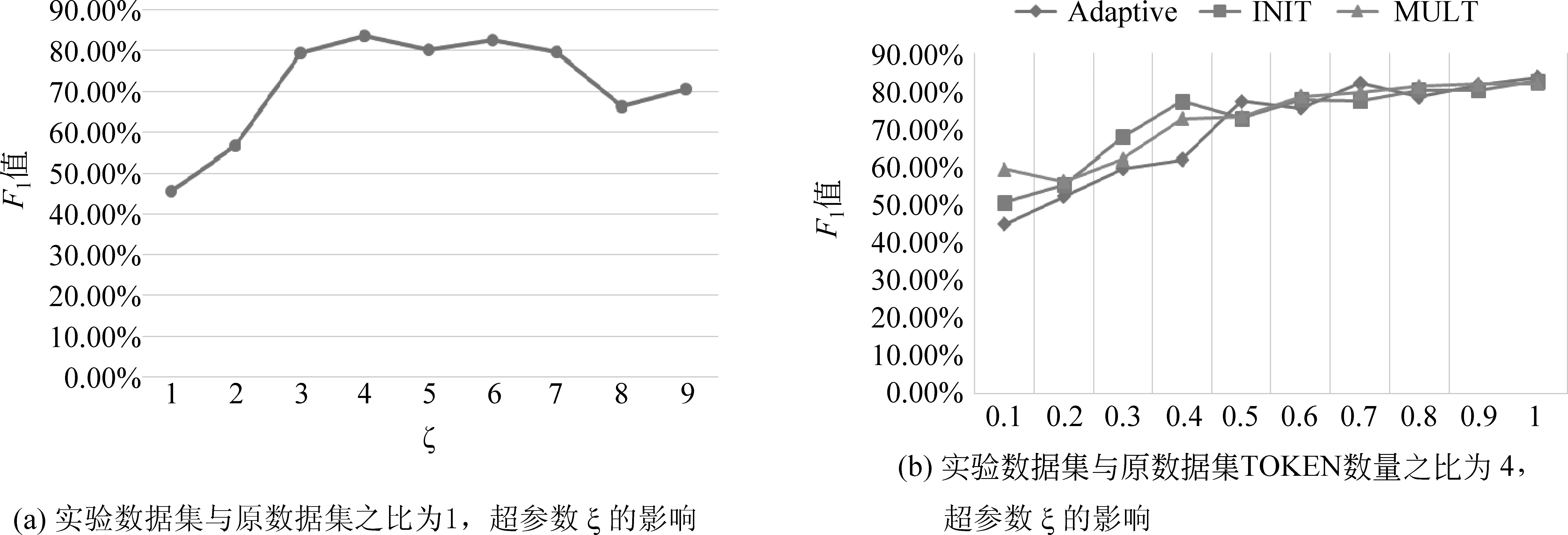
图4 超参数的影响

表4 古文数据集的NER实例
4 总结和展望
针对低资源的古文领域,本文首先使用BERT等近期主流的预训练语言模型在古文数据集上进行NER实验,并进一步提出了基于Adaptive Attention的迁移学习框架进行跨领域NER。实验结果证明,BERT_WWM在预训练模型对比试验中表现最好,F1值达到82.90%,融合注意力机制的自适应算法实验结果比其他迁移学习方法好,F1值达到了83.77%,进一步证明了利用迁移学习构建低资源领域模型的可行性。未来的工作将进一步探索自适应迁移学习在低资源领域的Zero-shot NER任务的应用。
