一种可拓语义分析的农产品生产销售知识检索方法
2021-07-23杨春蕾
杨春蕾
(河北地质大学,河北 石家庄 050022)
0 引言
知识检索是一种基于语义和知识关联的高级信息检索方式。相较于信息检索,知识检索实现了信息查询语义化、智能化,提高了检索的效率和准确率。知识检索过程中最重要的一步便是语义相似度计算,它用来表示概念之间的相关性,语义相似度越高,则越符合检索要求。因此,提出一种计算结果准确且高效的计算方法尤为重要。
近年来,一些学者研究了多种语义相似度计算方法并将其运用到了多个领域。文献[1]提出了一种基于农业本体的语义相似度计算方法,但是该算法受到地理实体、文献资料、经验等各个因素的影响,效率较低。文献[2]提出了一种计算义原相似度的算法,提高了检索结果的准确性,但第一独立义原对结果影响很大。文献[3]提出了加权语义复杂网络文本相似度计算方法,利用了文本网络中特征词节点间的信息,对于复杂的文本网络仍有一定的局限性。文献[4-5]提出了基于WordNet的语义相似度计算方法,具有更高的皮尔森相关系数,但只适用于词汇语义相似度计算。文献[6]提出一种自适应相似度综合加权计算方法,解决了传统综合加权计算时人工赋权的不足。文献[7]利用结构化的维基百科节点中的最短路径关系,对2个词条之间的关系进行刻画,过程略显复杂。
本文运用可拓学基础,提出的语义相似度算法,充分考虑信息量、距离、属性等信息对语义相似度的影响,具有更高的准确性。将本文算法应用于农产品生产销售知识检索,为农产品的供需双方提供便利。
1 农业知识表示和可拓描述
1983年,我国学者蔡文、杨春燕等人提出了一个新的学科—可拓学(extenics)。可拓论、可拓创新方法和可拓工程构成了可拓学[8]。可拓学的主要思想是利用创新的方法和理论解决各个领域中的矛盾问题。通过形式化描述矛盾问题将其转换为不矛盾问题,研究解决该问题的方法形成理论体系,形式化描述解决过程,转换成计算机可读的语言,智能化解决问题。不管面对什么样的问题,都需要遵循可拓逻辑,充分考虑事物本身的概念和特征,定量的表示逻辑值,形成可拓模型,通过可拓变换,推导矛盾问题,使计算机能够处理该问题。
实现农产品的生产销售平台首先需要解决的是农业知识表示这个关键问题[9]。通过使用统一的规则将知识进行描述,形成计算机可以识别的语言,方便进行语义相似度的计算[10]。本文的研究通过可拓学中的创新方法来对农业知识进行相似度的计算,从而完成知识检索。
本文所设计的流程图如图1所示。
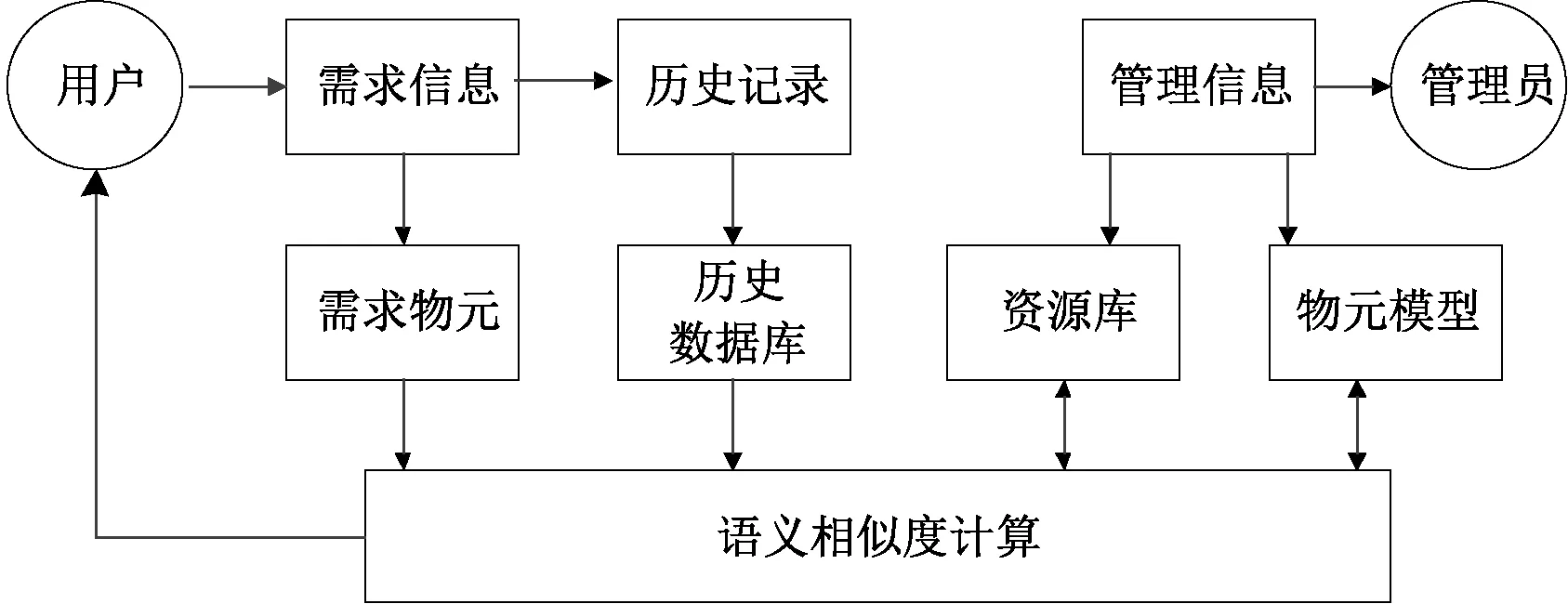
图1 农产品产销平台的知识检索流程图Fig.1 Knowledge retrieval flowchart of agricultural product production and marketing platform
2 基于可拓学的知识表示
本文引入可拓论,对农业知识进行表示,为语义相似度计算提供结构化的描述。可拓学中事元、物元和关系元组成基元,是形式化描述事物及其相互关系的基本逻辑单元。我们以有序三元组R=(c,m,v)表示基元,其中c为对象,m为特征,v为量值,通过基元建立解决问题的可拓模型。
定义系统中有概念c,此概念具有n个特征分别为m1,m2,…,mn,各自对应的量值为v1,v2…,vn。所构成的阵列即为物元R,物元模型为:

本文将农业知识用物元模型表示,知识由信息构成,信息的基元表示称为信息元。可拓学以可拓模型为基础,研究可拓信息-知识-策略的形式化体系[9]。在本系统中,c为相关概念,有多个取值,对于在农产品生产销售中所需要的特征称为m,每个特征对应的值或描述称为v。
例如,对于农产品玉米,其物元表示为:

该物元表示的对象是玉米,选取了价格、产地、品种和别名等四个特征,其中特征价格的量值是2.3/kg,产地是石家庄,品种是郑丹958,别名有包谷、棒子、苞米等。该物元模型形象且准确的表示了玉米这个农业知识的相关信息,在农产品销售系统中,可以根据供需双方的物元计算语义相似度。
3 语义相似度算法
本文语义相似度计算方法从信息、语义距离和属性等方面来计算。在对农业知识进行可拓描述时,了解到各个概念的信息及相关属性值,形成物元模型,将其以树形结构存储。这样将各个概念进行了分类,得到了知识的层次结构。我们可以直观形象地观察出各个节点信息和节点之间的路径长度。
3.1 基于信息的语义相似度
基于信息的语义相似度计算是通过概念之间共有信息量来判断的[12],两个概念共有的信息的信息量需要追溯到二者的父节点[13],对共有信息在父节点中出现的次数进行量化。共有信息越多时,相似度越高[14]。概念C的信息量定义为:
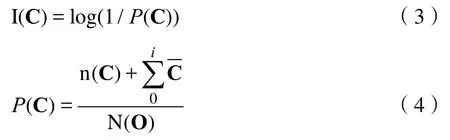
其中,P(C)表示概念C出现的概率;n(C)表示概念C在物元中出现的次数;N(O)是物元中概念的总数;表示概念C的子概念集合。
计算概念C1,C2的相似度,计算方法可表示为:
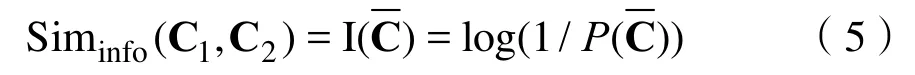
通过该方式对两个概念的相似度粗略计算后,需对其语义距离进行计算以提高准确率。
3.2 基于语义距离的语义相似度
将农业知识的物元以树形结构进行存储,计算两个概念的语义距离,需从树状图中分析两个节点之间的距离。由于两个节点之间的路径不同,距离也就不同,本文以二者之间的最短路径为准[15]。同时,将语义距离的单位距离统一为1。两个概念节点C1,C2的语义距离表示为:
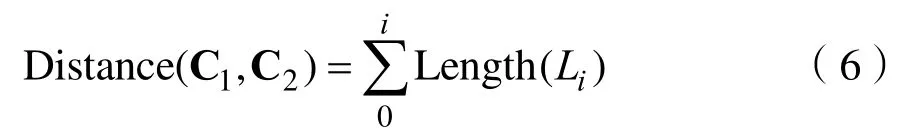
Distance(C1,C2)表示概念 C1,C2节点之间的语义距离,Length(Li)表示在连接 C1,C2两个概念的最短路径中,第i条边Li的长度。这样一来,概念之间的语义距离为:

上述将语义距离的单位距离定为 1,概念之间的语义距离可以定义为:
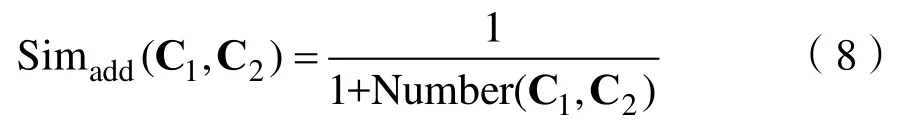
节点深度即概念节点在形成的结构树中的深度,若语义距离一定时,两个节点的深度越大,概念划分的准则越细致,则概念之间的相似度越大[16]。另Depth(C)表示概念C的节点深度,对于概念C1,C2,深度影响因子可以定义为:
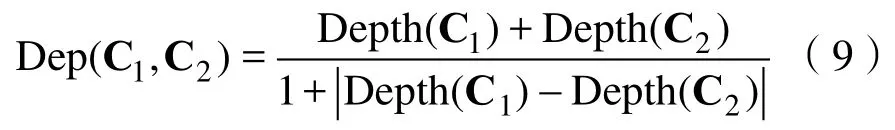
且 Dep(C1,C2)>1。
节点密度是针对于两个概念节点的最近公共父节点而言,当此节点所产生的直接子节点越多,它的节点密度越大,子节点之间的关联程度越大,语义相似度也就越大[17]。同样定义Density(C)为节点C的子节点数量,是节点C1,C2的最近公共父节点,节点密度影响因子定义为:
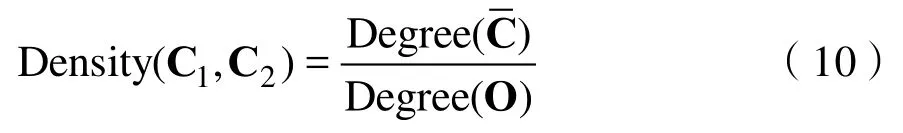
其中,Degree(O)为在由物元形成的整颗树中,最大的度。
综上所述,这些条件对语义相似度的结果都有影响,为保证计算的准确度,本文引入加权概念,根据对结果影响程度,对各个影响因素分配不同的权值。经过分析,得到的加权之后的语义相似度计算公式为:
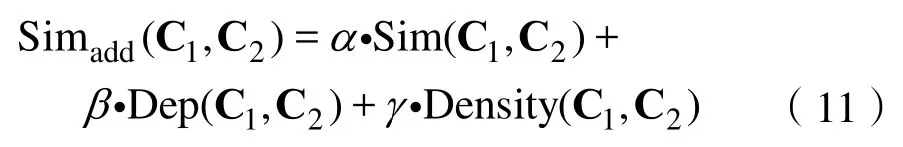
其中,α+β+γ=1
3.3 基于属性的语义相似度
每个属性都是对概念的一种描述,如果两个概念之间属性值相同或是相似,也能够在一定程度上反应两个概念之间的相似程度。通过参考文献[6]得出:
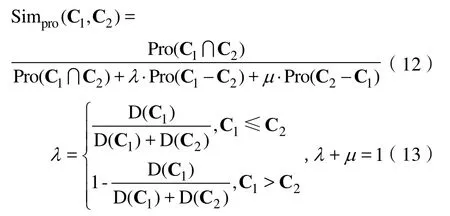
在式(12)(13)中,Pro(C1∩C2)表示概念C1,C2属性的交集,即二者的公共属性;Pro(C1–C2)表示概念的差集,即概念C1有而C2没有的属性,同理Pro(C1–C2)表示概念C2有而C1没有的属性;D(C1)和D(C2)表示在形成的物元结构的树中,概念所在的深度。
3.4 加权语义相似度
经过对语义相似度影响因素的研究,我们得到信息、语义距离、属性等三个影响因子,但若计算综合语义相似度需要结合3.1-3.3中介绍的三种情况[18-20]。通过请教专业领域的专家得知,三种影响因子对计算结果的影响程度不尽相同,因此,得到最后的加权语义相似度计算公式:
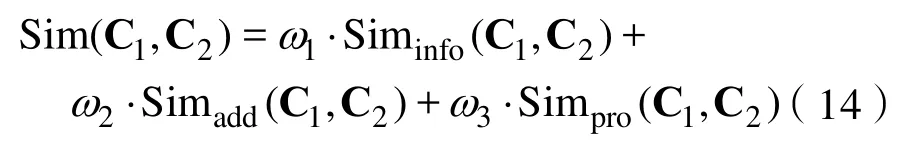
4 案例研究
随着互联网的发展,工作生活中的各项服务越发智能化,各应用系统迫切需要高准确性的语义相似度算法,农产品相关系统也不例外。
本文抽取部分实验数据进行语义相似度计算,这些实验数据形成的结构树如图2所示。
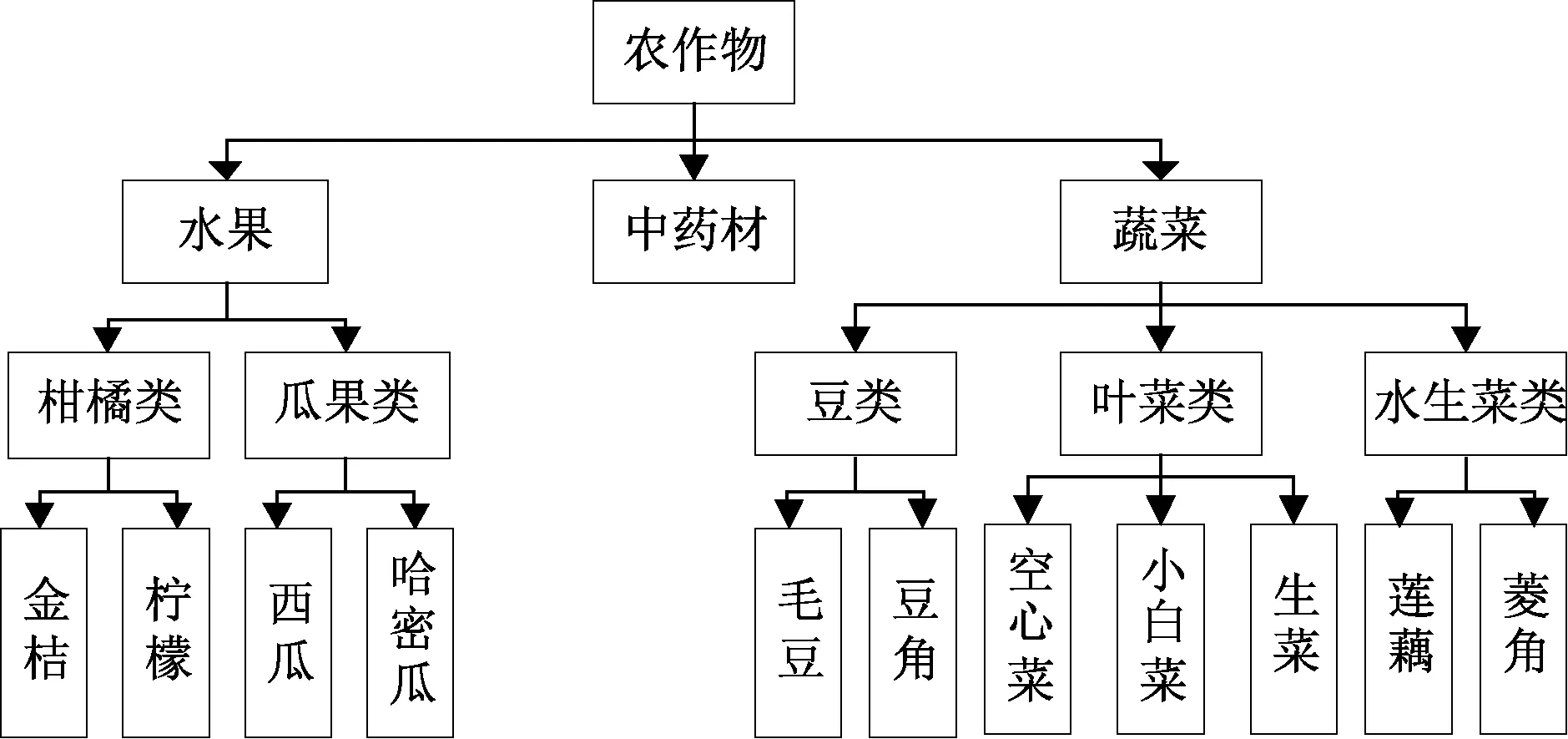
图2 结构树Fig.2 S tructure tree
4.1 实例计算
经过查阅相关资料与市场调查,选定对生产销售影响较大的属性,现选取物元中部分属性进行举例,价格定为市场调查当日的数值。本文选取的几种概念的部分属性如表1所示。

表1 农作物物元的部分属性Tab.1 Some attributes of crop matter elements
下面以计算“生菜”“小白菜”为例,计算二者的语义相似度,过程如下。
根据图 2物元树状图,计算“生菜”和“小白菜的”语义相似度。为了确定各个权值和参数,进行了大量的数据研究和实际考察,采用专家经验和试错法,得到结果 α=0.5,β=0.2,γ=0.3,ω1=0.2,ω2=0.1,ω3=0.7。
在图2中,“生菜”和“小白菜”的父节点是“叶菜类”,根据式(3)可以计算得到“叶菜类”的概率为1/5,这样根据式(4)计算出“叶菜类”的信息量为 0.699,最后由式(5)得到“生菜”和“小白菜”的信息相似度为0.699。
在图2中,“生菜”和“小白菜”的高度均为4,结合式(9)算得到,节点深度是 8。在图 2所示的树中,最大度为3,“生菜”和“小白菜”父节点的度也是3,利用式(10)节点密度是1。最终利用公式11二者语义距离为2.067。
根据上文计算“生菜”和“小白菜”的深度,可得到 λ=μ=1/2,参照表1中的属性,“生菜”和“小白菜”的共有属性为5,利用式(12)(13)性相似度为0.625。
最终,利用式(14)算出“生菜”和“小白菜”的语义相似度为0.785。
4.2 分析
根据项目需求分析和实际情况,得到对概念影响较大的属性并确定相应描述和数值,建立物元模型,对所有农业信息进行物元表示,然后根据调研结果将这些农作物的物元采用树的结构存储,建立农作物物元的树形结构,最后计算语义相似度。本文现只选取图2中的部分概念进行语义相似度计算。
为了更好地验证本文算法的准确性,采用文献[1]中的算法和目前常用的计算方法与本文算法进行对比,表 2为三种算法语义相似度计算结果。
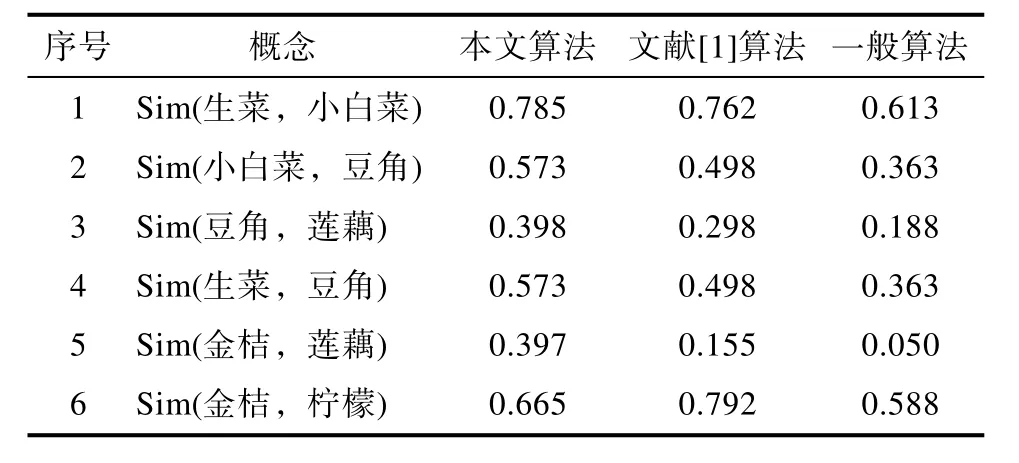
表2 三种算法语义相似度计算结果Tab.2 Se mantic similarity calculation results of three algorithms
图3是三种算法的语义相似度计算结果的对比图,其中横坐标代表用于计算语义相似度的概念对,纵坐标代表数值,蓝色、橘色和灰色折线分别代表本文算法、文献[1]算法和一般算法的计算结果。
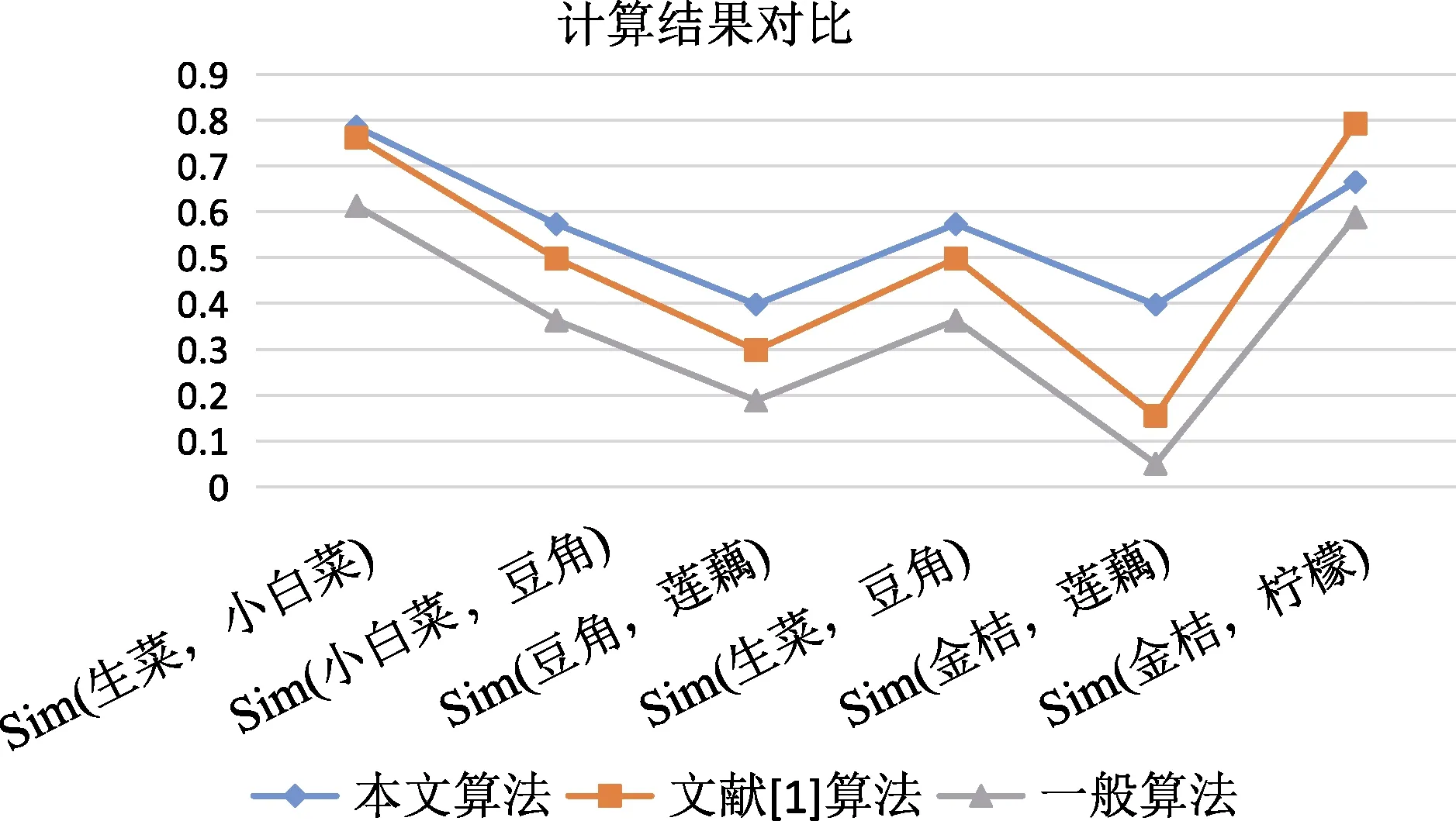
图3 三种算法计算结果对比图Fig.3 Comparison of calculation results of three algorithms
根据图 3我们可以看出上述三种算法的走势基本相同,其中在三种算法中相似度最高的均是金桔和柠檬,最低的是金桔和莲藕。
为方便比较三种算法的准确度,本文采用灵敏度比较,如式(15)所示:
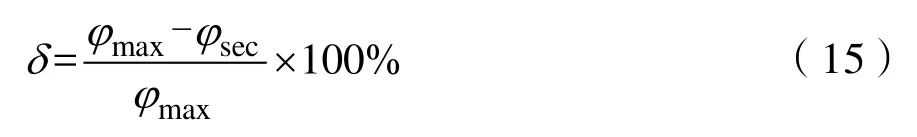
其中,φmax为优选中最大值,φsec为优选中的次大值。
三种算法的灵敏度如表3所示。

表3 三种算法灵敏度比较Tab.3 Comparison of the sensitivity of the three algorithms
可见本文算法有较高的灵敏性,可以应用到实际案例中。
5 系统实现
本文所描述的农产品生产销售知识检索系统采用Java语言,数据库使用MySql完成。
通过采用上文所述流程,完成需求分析,信息采集,将数据以物元形式提供给计算机,完成语义相似度计算后,知识检索的结果采用语义相似度由高到低的顺序排列,提供给用户。
6 结论
本文改进了一种新的语义相似度算法并成功应用与农产品的生产销售平台,该算法从信息量、语义距离、属性等三个方面进行分析,最后进行加权计算。充分考虑各个影响因素的同时,联系实际情况,研究各个因素对实验结果的影响程度,得到参数值,物元模型的应用直观形象地展现各个信息的概念、关系和属性,提高语义相似度的计算效率,节约存储空间。同时,为农产品的供需双方建立一个便捷可靠地平台。但是本文仍存在一些问题,计算结果容易受到主观因素的影响,这是需要继续研究的问题。
