网络安全知识图谱关键技术
2021-07-23李序连一峰张海霞黄克振
李序,连一峰,张海霞,黄克振
1.中国科学院大学,北京 100049
2.中国科学院软件研究所,可信计算与信息保障实验室,北京 100190
引 言
近年来,网络安全事件频发,网络攻击手段日益呈现复杂多变的特征,新型攻击工具层出不穷,单纯依靠入侵防御系统等被动防御手段已经无法有效地维护网络空间安全,特别是近年来频发的针对关键信息基础设施的攻击活动,对国家网络空间安全保障工作带来了巨大挑战[1]。同时,大数据、人工智能等技术的发展,也为网络安全防护提供了新的解决方案。互联网中存在大量的网络安全相关数据,例如防火墙、入侵检测系统等监测到的网络安全告警数据、网络安全研究机构或厂商建立的漏洞信息库(如CNNVD),以及互联网安全论坛和厂商发布的安全通告等。安全分析人员通过挖掘此类数据中的信息,可以为网络安全态势感知提供支撑,实现安全预警预测,支持网络安全决策。然而,网络安全数据存在海量化、分散化、碎片化以及关系隐蔽化的特点,如何及时、精准地对海量数据进行分析处理,提取关键要素和关联关系,挖掘潜在的有价值信息,是网络安全领域面临的重要问题。
1988年,Berners-Lee率先提出了语义网(Semantic Web)的概念[2],核心思想是在网页数据中添加能够被计算机所理解的语义信息,从而提升机器的理解能力。作为语义网的数据支撑,知识图谱(Knowledge Graph)的概念由谷歌公司于2012年提出,旨在实现更智能的搜索引擎,并于2013年开始在学术界和业界普及。知识图谱可以通过统一的框架将多源异构的数据组织起来,利用图结构表达数据之间的语义关系,为数据的分析和挖掘提供了支持。随着深度学习等人工智能技术的发展,知识图谱技术在金融风控、证券投资、医疗和地理信息等领域得到了广泛的应用。在网络安全领域,通过对海量安全数据进行知识抽取、融合和推理,能够实现多源异构数据的关联挖掘,从而在目标画像、APT检测、攻击溯源等方面发挥作用。
目前,网络安全知识图谱的研究尚处于起步阶段,对于构建和应用网络安全领域图谱的整体技术框架的研究很少,本文重点对网络安全领域知识图谱的各类关键技术进行研究,提出了网络安全知识图谱的技术架构。
本文第1节介绍相关技术的国内外研究现状,第2节提出网络安全知识图谱技术架构,从本体模型、实体抽取、关系抽取、图谱构建与推理方法等方面详细阐述知识图谱关键技术,最后第3节对全文进行总结。
1 国内外研究现状
知识图谱的核心是本体结构[3]。本体是对一个特定领域中的概念及其之间关系的一种描述。知识图谱描述的是真实世界中存在的实体或概念,强调实体和属性值。一个本体可以用五元组来表达:O =(C,R,F,A,I),C是本体概念的集合,描述领域内的实际概念;R是关系集合,描述概念之间的关系;F是上下文关系的集合;A是公理集合,代表本体内存在的事实,可以对本体内的概念或关系进行约束;I表示实例的集合。
网络安全知识图谱在语义网技术作为知识表示的基础上,最重要的是本体结构[4]。Undercoffer等人[5]提出了一个针对网络攻击的本体结构并应用到了分布式入侵检测系统中,作者分析了4 000多种网络攻击,从目标和攻击两个维度进行建模;Herzog等人[6]定义网络安全本体模型的核心概念包括资产、威胁、漏洞和对策,并描述了资产与漏洞、威胁与目标资产之间的关联关系;Iannacone等人[7]面向网络安全整体领域构建了一种本体,包含了15种实体及115个属性;SYED等人[8]扩展了Undercoffer提出的面向入侵检测系统的本体,提出了一个更为通用的网络安全知识本体——UCO,可以将网络安全本体映射为STIX格式,对应CVE等网络安全知识库以及DBPedia等通用知识库。除此之外,国内很多学者也对网络安全领域的本体构建进行了研究,贾焰等人[9]基于现有的漏洞数据库和攻击规则库,构建了包含漏洞、资产、软件、操作系统和攻击在内的网络安全实体;王通等人[10]根据威胁情报目标需求,参考威胁情报模型STIX和攻击模式模型CAPEC构建了网络威胁情报本体模型。
实体抽取又称为命名实体识别,目前的命名实体识别技术主要包括基于规则的方法、基于统计学习的方法和基于深度学习的方法。基于规则的方法一般由领域专家手工构建规则模板,选择词语的统计信息、指示词等作为特征,以模式匹配为主要手段,例如Balduccini等人[11]提出将本体与正则表达式相结合来抽取网络日志中的实体,该方法采用遗传算法生成正则表达式对日志段落中的信息进行标记,然后通过本体将标记信息匹配为实体;Liao等人[12]采用语法树和正则表达式相结合的方法来识别网络安全博客文本中的失陷指标(Indicators Of Compromise)。基于规则的方法对于实体识别的准确率较高,但是需要耗费大量人力来构建规则,并且规则的移植性较差。基于统计学习的方法是将命名实体作为序列标注或多分类任务来处理,主要采用最大熵、条件随机场、隐马尔可夫等模型。随着机器学习技术的发展,出现了很多命名实体识别工具,例如Stanford NLP、Stanform NER等,但这些工具都是基于通用知识语料库进行训练的,直接应用到网络安全领域的信息抽取中并不能取得较好的结果。贾焰等人[9]使用现有漏洞数据库中的“influence platform”字段进行汇总,构建了实体字典,选择Standform NER中的字典特征进行训练,取得了较好的效果;Joshi等人[13]在条件随机场(CRF)模型的基础上采用网络安全语料进行训练。基于统计学习的方法可以自动抽取实体,但需要大量的人工标注数据。随着深度学习技术的发展,神经网络方法被广泛应用到了命名实体识别任务中,并成为目前的主流方法,其中Huang等人[14]首次将BiLSTM-CRF模型应用到了命名实体识别中,利用双向长短时记忆网络(LSTM)进行特征提取和CRF进行实体标注;Houssem等人[15]利用LSTM进行网络安全实体识别,也取得了较好的效果。
信息抽取中的另外一项任务是关系抽取,不同的关系将独立的实体连接在一起形成知识图谱。目前关系抽取主要分为三种方法:基于规则的模式匹配方法、基于监督学习的方法和基于半监督或无监督的方法。早期的关系抽取主要采用基于规则的模式匹配方法,由领域专家定义各类关系的规则,然后使用规则和文本进行模式匹配,但是领域专家无法对所有关系的规则进行穷举。基于监督学习的方法把关系抽取作为多分类问题来处理,每一种关系都是一个类别,通过标签数据对分类器进行训练。这种方法依赖于标注数据的规模和特征的选择,获得大量标注数据的代价通常是非常高昂的。为了解决这个问题,出现了基于半监督或无监督的关系抽取方法,主要包括基于Bootstrapping的方法和远程监督的方法,其中Bootstrapping方法利用少量实例作为初始种子(seed tuples)集合,通过学习得到新的模式(pattern),进而基于新的模式发现更多的实例,不断迭代从非结构化数据中寻找和发现新的潜在关系三元组;Mintz等人[16]提出了远程监督方法,通过将知识库与非结构化文本对齐来自动构建大量训练数据,然后构建特征用于训练分类器;Riede对传统的远程监督学习方法进行改进,提出了增强的远程监督假设,即“如果两个实体之间存在某种关系,那么至少有一个提到两个实体的句子可以表达这种关系”,使用无向图模型预测实体之间的关系以及哪个句子表达了这个关系,与原始的远程监督方法相比,错误率降低了31%;Zeng等人[17]使用卷积神经网络来自动提取特征,解决了采用词性标注、依存句法树等技术构建特征时错误率偏高的问题;Miwa等人[18]提出了使用双向LSTM和树形LSTM同时对实体和句子进行建模的方法。在网络安全领域的关系抽取中,Pingle等人[19]在网络安全语料库上训练Word2Vec模型对实体进行词嵌入,采用前馈神经网络FFNN预测实体间的关系。
在网络安全知识图谱的构建和推理方面,绿盟科技[20]基于知识图谱进行APT组织的追踪分析,通过采集威胁情报、各机构发布的APT报告及安全通告等数据,定义APT攻击本体,建立APT攻击知识图谱,实现对APT攻击行为的追踪溯源。瑞星公司构建了威胁情报及网络安全知识图谱[21],包含100亿+实体以及400亿+关系,其中,实体包含文件、漏洞、IP、黑客组织等网络安全攻击事件中涉及到的所有元素,与普通的威胁情报平台相比,在恶意软件领域可以发挥特长,将一些恶意软件模糊搜索、自动归类的技术应用到了知识图谱的检索中。在学术界,也有很多研究人员对知识图谱在网络安全领域中的应用开展了研究工作,Yulu等人[22]基于网络安全知识图谱对网络攻击进行溯源分析;Wei等人[23]通过知识图谱来过滤不相关的警报日志;Narayanan集成不同来源的威胁情报构建网络威胁情报图谱[24],实现了简单的网络安全事件预测;陶源等人利用知识图谱建立日志审计分析模型,以支持网络安全等级保护工作[25]。
2 网络安全知识图谱技术架构
当前,知识图谱相关技术发展迅猛,网络安全作为新兴的应用领域,相关的知识图谱本体模型、实体抽取、关系抽取,以及图谱构建及推理技术逐渐引起研究人员的重视。网络安全知识图谱技术架构主要分为三个层次,其中:
(1)本体构建层负责定义网络安全领域的概念及其关系,例如网络攻击者、攻击工具、木马病毒、攻击活动、安全事件、漏洞隐患、防护措施等;
(2)信息抽取层负责从多源异构的网络安全数据中抽取相关实体及其关系,将信息抽取过程中得到的实体进行对齐和链接,并通过对抽取到的实体及关系进行评估校验后构建知识图谱;
采用文献[27]Molish法对20%vol和72%vol红枣白兰地的致浊物进行定性分析,实验结果,20%vol未出现紫红色环,72%vol出现紫红色环。表明20%vol红枣白兰地致浊物中不含有糖类,72%vol红枣白兰地致浊物中可能含有糖类,与红外光谱图结果相吻合。
(3)知识推理层负责在初步构建的知识图谱基础上,通过知识推理分析挖掘新的实体或隐含关系,对图谱进行补全,提供网络安全决策支持。
2.1 本体模型
网络安全本体模型的构建应根据具体的目标需求来完成,例如针对APT攻击,本体模型应重点围绕APT攻击相关的组织、技术、工具、历史攻击活动、掌握资源等要素定义实体、属性及其关系;针对勒索病毒,则本体模型应重点定义病毒、代码特征、利用漏洞、目标对象、软硬件版本、传播范围、阻断方式等要素。
图1给出了针对通用网络安全目标需求的本体模型示例。图中每个节点代表本体模型的一类实体,节点间的连接代表实体间关系。例如,归属于某组织的攻击者利用攻击工具或恶意程序,发起对某个IP主机的攻击事件,该攻击工具或恶意程序利用了某款软件存在的安全漏洞。
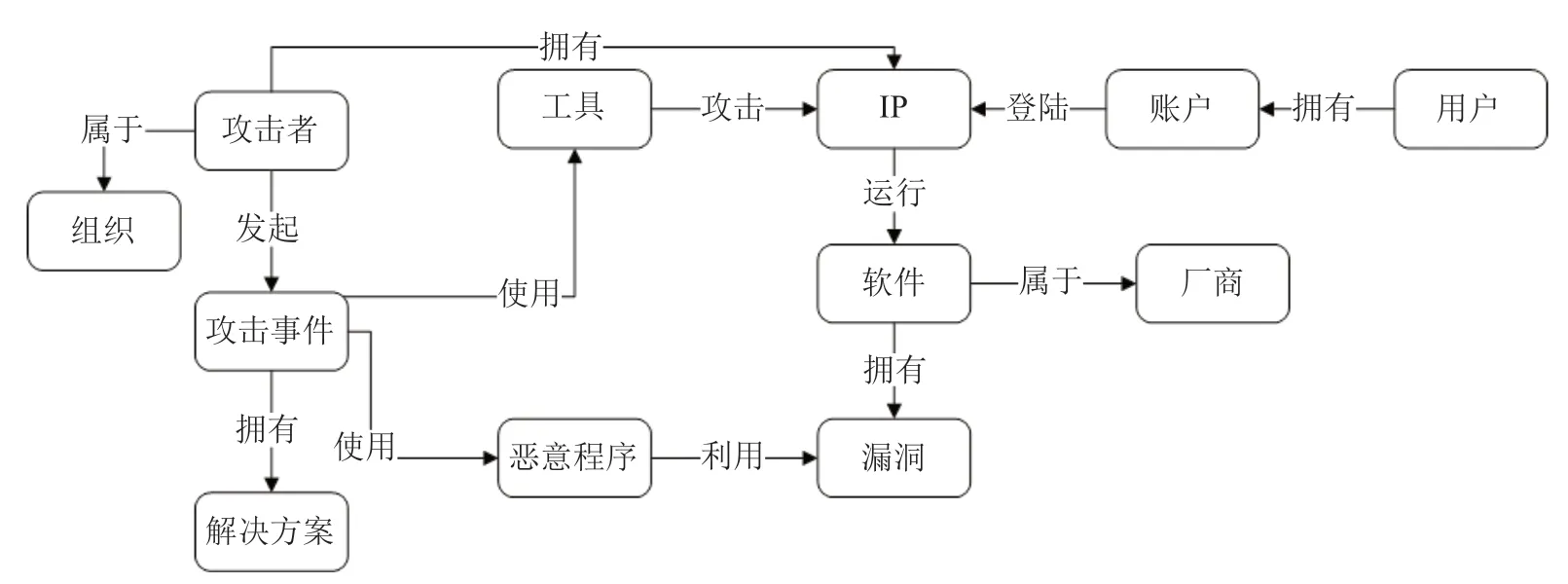
图1 网络安全本体模型示例Fig.1 An example of network security ontology model
2.2 实体抽取
网络安全实体抽取任务主要面向的是网络安全相关的非结构化文本,例如网络安全网站、论坛和各类社交媒体上发布的内容。本文介绍基于经典的双向长短时记忆网络-条件随机场(BiLSTM-CRF)模型的实体抽取方法。其中双向长短时记忆网络(BiLSTM)负责学习句子的上下文关系,条件随机场(CRF)则负责处理实体类型之间的依赖关系,模型结构如图2所示。

图2 BiLSTM-CRF模型Fig.2 BiLSTM-CRF model
模型的第一层是词嵌入层,通过Word2Vec工具,将单词序列(w1,w2,w3,...,wT)中的每个单词映射成低维向量xi∈Rd,d为词向量的维度。
模型的第二层是双向LSTM层,负责自动提取句子特征。将单词序列的各个词向量(x1,x2,x3,...,xT)作为双向LSTM在各个时间点的输入,再将正向LSTM输出的隐状态序列与反向LSTM在各个位置输出的隐状态进行拼接,得到完整的隐状态序列(h1,h2,h3,...,hT)∈RTxm,接入一个线性层,将隐状态向量从m维映射为13维向量(共有13种实体类别),从而得到自动提取的句子特征,记作L=(L1,L2,L3,...,LT)∈RTx13,Li∈R13的每一维Lij是把单词wi分类为第j类实体的得分:

进而得到归一化之后的概率如公式(2)所示,P(y|x)表示将单词序列x的实体类别预测为y的概率,Y表示单词序列x对应所有可能的实体类别序列构成的集合,|Y|=13T:

模型通过最大化似然函数进行训练,一个训练样本(x,yx)的似然函数计算如公式(3)所示,其中P(yx|x)表示单词序列x的实体类别序列为yx的概率:

最后由条件随机场(CRF)层使用动态规划Viterbi算法来得到预测值。
2.3 关系抽取
针对网络安全关系抽取任务,由于缺乏中文标注的网络安全实体关系数据集,因此传统的模式匹配和监督学习方法并不适用。考虑使用远程监督方法,在只需要少量标注数据集的基础上进行模型训练。本文介绍分段卷积神经网络(Piecewise Convolutional Neural Networks,PCNN)模型[26],将远程监督学习看作是一个多实例学习问题,使用卷积神经网络(CNN)模型自动学习文本特征,在最后的池化操作中使用分段池化的方法,利用该模型进行网络安全实体关系的识别。PCNN模型结构如图3所示。
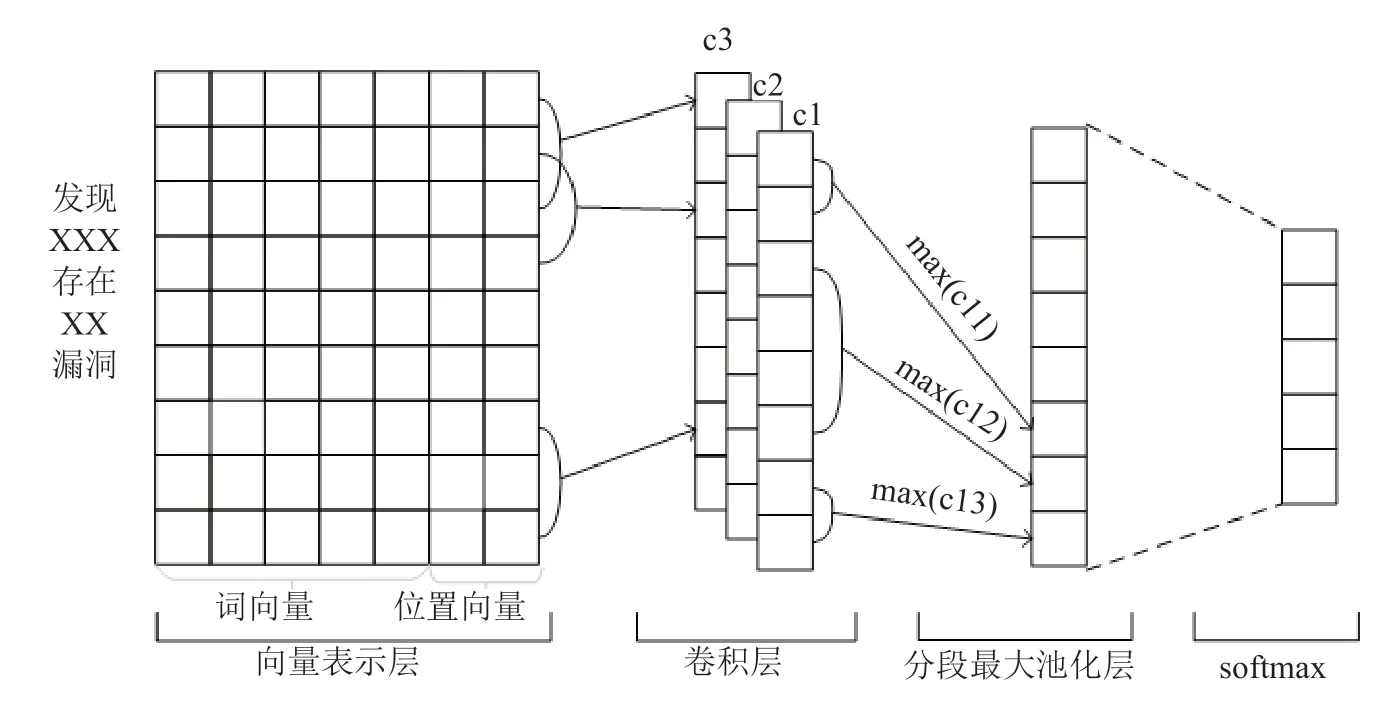
图3 PCNN模型Fig.3 PCNN model
PCNN模型的第一层是词嵌入层,将输入的单词转化为词向量。PCNN模型根据每个单词相对两个实体的位置信息进行拼接形成位置向量,然后在卷积层通过CNN模型来提取文本特征。常用的最大池化操作因为对句子长度特征池化,不适合关系抽取任务。PCNN模型将句子按照实体位置分为三段,分别对每段进行池化,最后通过softmax层计算句子属于每类关系的得分。
PCNN使用多实例学习方法来降低错误标注带来的影响。多实例学习每次使用一袋包含同一对实体的样本,袋的标签为实体对在知识图谱中的关系,袋中的数据相互独立。每次对M袋数据进行训练,首先从每一袋数据中选取最具代表性的样本,计算方式如下:
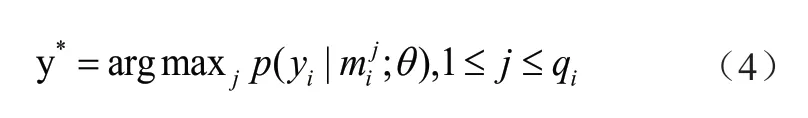
其中,qi表示第i袋样本的数量,yi为第i袋数据的标签,mji表示第i袋数据中的第j个样本;然后,将该样本的标签视为此袋数据的预测标签,计算交叉熵损失:

其中,M表示袋的数量,yi为第i袋数据的标签,为第i袋数据中选出的最具代表性的样本。
2.4 图谱构建与推理方法
经过实体抽取和关系抽取之后,网络安全数据中的实体和关系可以链接到本体模型中定义的概念及关系,通过Neo4j等图数据库可以存储初步形成的知识图谱。为保证图谱的质量,还需对图谱中的知识进行评估校验,去除多数据源中的冗余知识,并研判解决存在冲突的信息,避免在知识推理过程中错误传播。
由于很多网络安全数据的组织形式比较简单,信息抽取之后创建的知识图谱中主要包含句子中显式表达的关系,还需要在现有知识的基础上通过知识推理,挖掘潜在的隐含知识,丰富网络安全知识图谱。网络安全知识图谱的知识推理可以结合具体的任务需求,综合使用基于规则的推理和基于知识表示学习的推理方法。某些网络安全数据可以根据专家经验知识定义规则,例如对于某些具有鲜明特征的APT组织的攻击手段或技术方法,可以由专家定义规则知识库,将图谱知识与规则库进行模式匹配。
另一方面,知识表示学习可以将图谱中离散的关系和实体映射成低维的连续向量,同时不损失知识图谱中的原有语义。目前常用的方法主要是基于深度学习的知识表示学习,针对本文构建的网络安全知识图谱,将<实体,关系,实体>三元组映射成低维的向量,使用循环神经网络模型进行多步知识推理。目前在知识图谱推理的基础研究中,结合领域知识图谱的本体知识来构建图谱表示模型的研究成果较少,研究针对网络安全领域知识图谱的表示模型,可以在一定程度上提高图谱推理的准确率,实现更为精准、更具可操作性的安全决策推理。
3 小结
本文提出了网络安全知识图谱的技术架构,从本体模型定义、实体抽取、关系抽取、图谱构建及推理等方面阐述了网络安全领域知识图谱的关键技术。当前,知识图谱在信息检索、推荐系统等领域得到了广泛应用,在网络安全领域中也开始发挥越来越重要的作用。将知识图谱引入网络安全领域中,可以将互联网中零散的网络安全数据组织在一起,挖掘网络安全数据之间潜在的语义关系,帮助全方位掌握威胁信息,对当前的网络安全态势做出判断,进而预警、预测未来可能发生的威胁。
本文提出的网络安全知识图谱的技术架构中知识抽取、推理等关键技术主要还是基于深度学习技术,然而使用深度学习技术构建知识图谱仍然存在不准确、不全面的问题,首先深度学习技术依赖于大量的标注的语料库,目前通用知识语料库主要还是关注人物、事物等,将深度学习知识图谱引入到领域图谱中时会出现准确率大大降低等问题,可移植性较低;其次,知识图谱涉及各个方面各个场景,并不像图片、语音可以在单一的维度来训练模型,从而达到足够的精度和召回率;在知识推理方面,目前主流的方法还是基于深度学习与知识表示学习,单纯依赖大量的标注数据,在网络安全领域的知识图谱中,有诸多的先验知识无法有效使用并融合到深度学习的推理模型当中,以提高知识推理的精度。
后续可以围绕如何提升网络安全领域信息抽取的准确性,如何融合已有的专家知识构建网络安全领域知识图谱表示模型和推理模型,进一步开展更多的研究和探索工作,以提高网络安全主动防御能力。
利益冲突声明
所有作者声明不存在利益冲突关系。
