基于多解析器的域名隐私保护机制
2021-07-23吴一铭王伟延志伟汪洋
吴一铭,王伟,延志伟,汪洋
1.中国科学院计算机网络信息中心,北京 100190
2.中国科学院大学,北京 100049
3.中国互联网络信息中心,北京 100190
引 言
作为互联网重要的基础架构,域名系统(DNS)承担了地址映射的重任,DNS解析这一过程完成域名到IP地址的转换[1],是几乎一切互联网行为的必要前置步骤,随着物联网的发展,DNS还将被用来进行物联网标识解析[2]。但在1983年DNS诞生之初,其协议设计[3]并未考虑数据完整性保护和隐私保护,在链路上明文传输的DNS报文内容可以被中间人轻易地窃听和篡改。
随着DNS的安全性和隐私性问题越发迫切,互联网工程任务组(IETF)已经推动了多项DNS隐私保护协议的标准化工作,例如DTLS上的DNS,TLS上的DNS(DoT)[4]和HTTPS上的DNS(DoH)[5]。这些方案采用的基本技术原理是一致的,就是通过加密协议传输原本的DNS报文。虽然这些加密方案都妥善地解决了DNS在传输链路上面临的安全和隐私威胁,但它们的实现和部署方式将为传统DNS的解析模型带来重大变化[6]。
本文研究的主要内容为DNS多解析器机制中的解析器选择策略。多解析器机制是一种实现于客户端的轻量级DNS隐私保护方案,通过DNS请求分散进行集中化避免和DNS服务端用户隐私保护。解析器选择策略是多解析器机制的核心问题。本文首先对DNS的隐私问题和集中化趋势等背景知识进行介绍,并对DNS隐私保护方案和相关研究工作进行梳理。之后对多解析器机制中的解析器选择策略进行了深入研究,通过解析记录表和基于ping延迟的权重计算对轮询方法进行改进,并设计实验将本文的方法与之前的传统轮询方法和哈希方法进行横向对比。实验结果表明,本文设计的轮询方法可以有效地将DNS请求均匀分散在多个解析器之间,加权轮询法则取得了显著的性能优化,相比简单的轮询方法和哈希方法有着明显的改进。
1 背景
1.1 传统DNS的隐私威胁
DNS的主要功能是将人类可读的域名转换为对应的IP地址。DNS服务主要由三个部分组成:域名空间和资源记录、权威服务器、递归服务器。用户与递归服务器直接沟通,由递归服务器完成后续的解析工作并返回解析结果。
本文以查询www.example.com为例,介绍传统DNS在查询A记录时的解析过程,如图1所示。
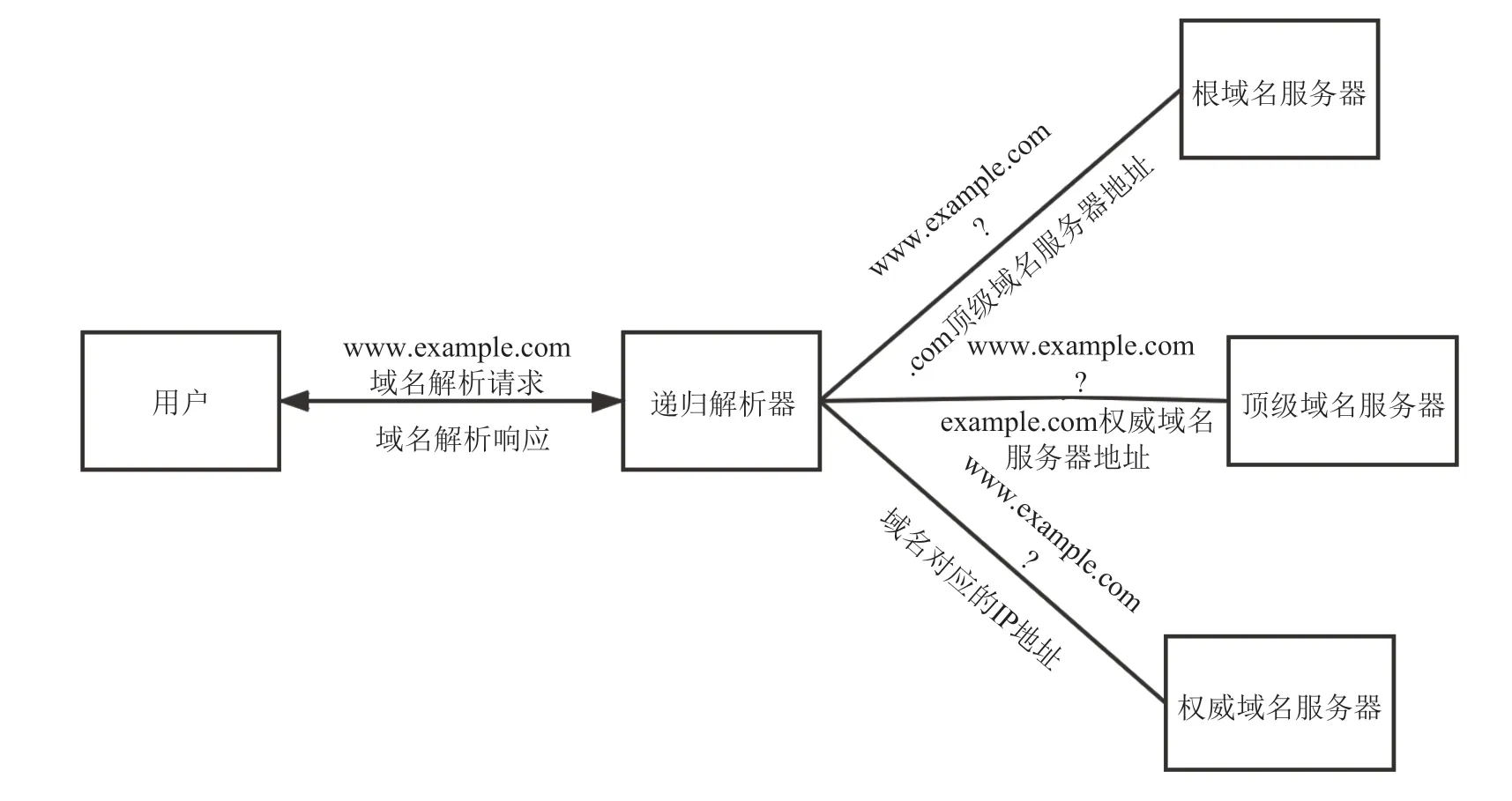
图1 DNS解析过程Fig.1 DNS resolution process
(1)客户端向递归解析器发送查询请求;
(2)递归解析器检查缓存中是否有对应记录,如存在则直接返回结果,如不存在则向根域名服务器发送查询请求;
(3)根域名服务器向递归解析器返回.com顶级域名服务器的地址;
(4)递归解析器向.com顶级域名服务器发送查询请求;
(5).com顶级域名服务器向递归解析器返回example.com权威域名服务器的地址;
(6)递归解析器向example.com权威域名服务器发起请求;
(7)example.com权威域名服务器向递归解析器返回www.example.com对应的IPv4地址;
(8)递归解析器向客户端返回结果。
如前所述,这些传统的DNS解析并没有进行加密,所有的查询和响应都以明文的形式暴露在链路上,因此导致了许多安全和隐私问题[7]。以上述流程为例,在用户和递归解析器的通信过程中,用户的IP和请求的域名www.example.com会同时暴露在链路上,同一网络下的攻击者可以轻易地获取用户的隐私数据,甚至对请求和响应内容进行篡改。除链路上的隐私泄露以外,在解析器方面也存在着隐私风险,域名解析请求中包含的用户隐私信息对解析器是可见的,解析器可以在向用户提供DNS服务的同时对用户隐私进行收集和滥用。
1.2 DNS加密与集中化趋势
针对链路上的隐私泄露问题,已经出现了很多基于加密的DNS传输方法并已推出了相关标准,例如DoT和DoH,可以有效避免DNS携带的用户隐私在链路上明文暴露。
对DNS消息进行加密以避免传输链路上的信息暴露能使得所有有隐私意识的互联网用户受益,但是对DNS报文进行加密不能阻止解析器看到用户的网站域名访问记录,用户的隐私依然面临着来自解析器方的威胁。另一方面,DNS加密传输得到广泛部署的一种可能后果是导致DNS流量集中涌向少部分加密解析服务提供商。
传统DNS中递归解析器通常由用户各自的网络服务提供者进行分配,在用户切换网络接入点时(例如在公司、住处,以及移动网络之间切换),用户使用的递归解析器也可能改变,而DNS加密的出现和实现方式改变了这一情况。2020年2月Mozilla与Cloudflare合作为美国的所有Firefox用户默认启用了DoH[8],这一举措引发了业界的争议和担忧。在目前的与浏览器结合的实现方式中,开启DoH的浏览器用户在切换网络接入点时递归解析器依然保持不变,用户的全部域名解析历史都会被DoH解析器收集。虽然用户可以自主选择该解析器的提供者,但无论如何选择,用户最终总是要将自己的全部网页浏览历史记录对其选择的解析器呈现。如果该解析器恶意地将收集到的DNS查询记录用于非法目的,就会对用户的隐私造成严重威胁,而一般用户很难判断某个解析器是否值得信任。恶意的解析器不仅会威胁个人隐私安全,而且当其获取足够大的用户流量后,可以对一片区域、一个国家甚至全球范围的用户进行分析和侵害。除了隐私威胁问题以外,集中化的解析模型下解析服务单点失效[9]也将造成大范围的严重影响。
2 相关工作
2.1 DNS隐私威胁研究
RFC 3833[10]将DNS面临的安全威胁分为3个部分,包括:DNS传输链路上的安全通信威胁,拒绝服务攻击(DoS/DDoS),以及利用DNS服务器软件的漏洞对DNS服务器进行攻击。ROSSEBO J等人对DNS隐私被利用的方式进行了分析,发现一些组织和公司通过收集用户DNS数据来建立用户画像,设计商业行为[11]。KONINGS B等人通过在校园网进行实验,发现用户真实姓名、用户设备名称等敏感信息也会伴随DNS隐私一同泄露[12]。BANSE C等人对基于流量的行为跟踪技术做出了研究,使用贝叶斯模型和DNS数据对用户进行跟踪,实验结果表明,通过DNS数据可以准确的分析用户行为[13]。
2.2 链路上DNS隐私保护研究
为了解决链路上的DNS隐私问题IETF推动了多项DNS加密协议的研究与标准化工作,其中主要的成果就是DoT和DoH。这些加密传输方案为DNS提供传输过程中的数据完整性保护和隐私保护。
DoT基于TLS来对DNS请求交互报文进行加密,可以保证DNS查询结果不会被窃听和篡改。但是由于 DoT 会占用一个单独的853端口,网关可以通过限制这个端口流量来限制 DoT 的查询。这一弱点使得推广过程中ISP方面的阻力变得不可忽视。
DoH是目前广受欢迎且具有代表性的域名解析安全增强方案[14],其使用加密的HTTPS协议进行DNS解析请求,如图2所示,保护了用户的域名解析请求和接收到的响应,最终达到保护DNS数据完整性和隐私性的目的。虽然HTTPS带来了额外的链接成本和传输开销,但通过链接复用等手段可以有效地提高DoH的性能表现,其相比传统DNS的额外延迟是可以接受的。
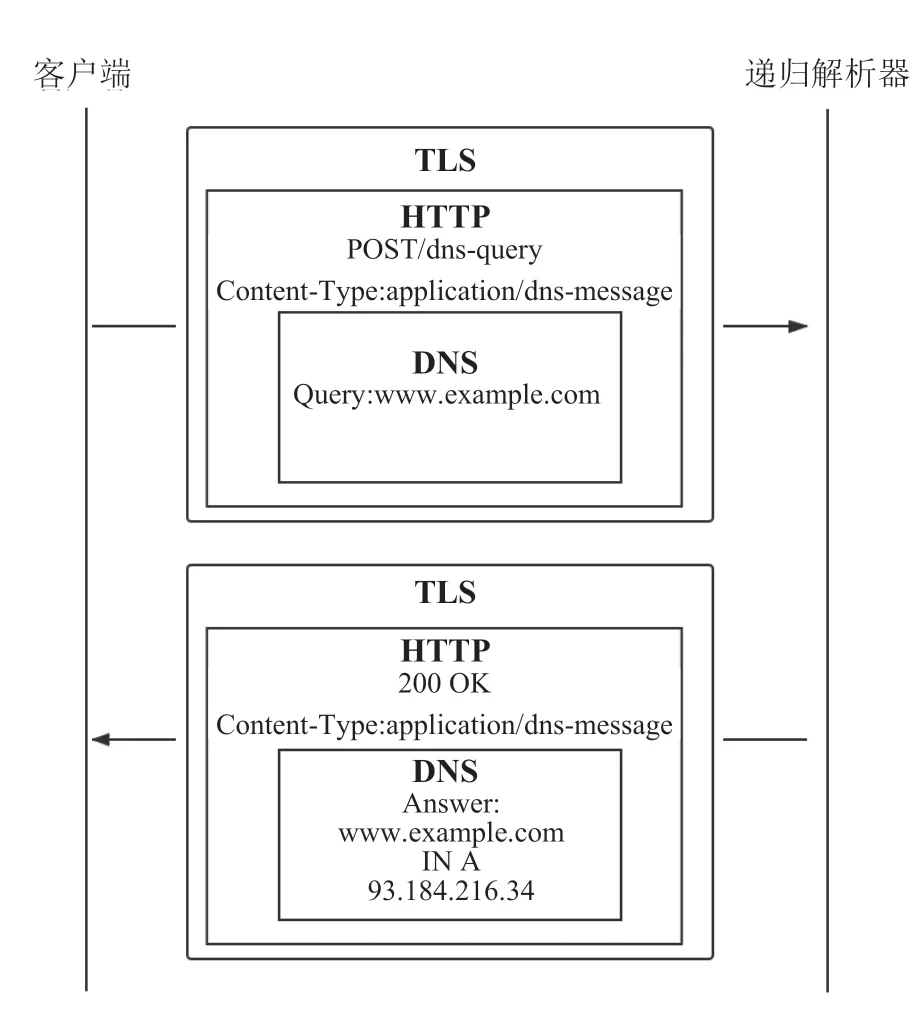
图2 DoH通过安全的HTTPS传输DNS报文Fig.2 DoH transmits DNS messages over secure HTTPS
DNS加密传输方案作为目前解决DNS隐私问题最为可行的办法,成为了近期DNS隐私保护方向的研究热点,国内外已经针对DoT和DoH开展了很多研究工作。BÖTTGER等人对DoH的性能表现和额外开销进行了测量,并评估了DoH对网页加载时间的影响[15]。LU等人对DoT和DoH的部署情况和传输性能进行了广泛测量,并对DNS加密传输的互操作性进行了研究[16]。SHULMAN等人讨论了DNS加密传输方案在部署时可能面临的困难,对DNS加密传输的隐私保护效益、互操作性和额外开销进行了分析[17]。
2.3 服务端DNS隐私保护研究
在防止DNS解析服务提供者对用户隐私进行收集的研究中主要有两种思路:通过代理的方式防止DNS服务端得到用户的IP,通过改变用户的请求方式来避免服务端收集用户的真实完整行为历史。
其中基于代理的方式有ODNS和ODoH, P SCHMITT等人提出了ODNS(Oblivious DNS)[18],使用ODNS名称空间的权威服务器作为用户的递归解析器,通过额外的模糊层避免这些解析器获得用户的IP地址。SINGANAMALLA等人提出了ODoH(Oblivious DNS over HTTPS)[19],通过代理的方式增强了DoH,DoH服务器仅能获取代理服务器的IP而无法获得用户的IP,同时加密的DoH可以确保代理服务器仅能获取用户的IP而无法观察到用户请求的内容。因此这一机制有效保护用户隐私的前提是代理服务提供者和DoH服务提供者不能相同。
通过改变用户请求方式来实现用户隐私保护的方案均实现于DNS客户端内,可以保证与现有DNS体系的兼容,属于轻量级隐私保护方案。ZHAO等人对传统DNS 解析的整个流程进行了分析,对每个步骤存在的DNS隐私泄露风险进行了总结,并提出了范围查询(Range Query)[20],使用冗余的查询来隐藏用户真正的查询意图。NP HOANG等人提出了K-resolver[21],通过基于哈希法的请求分散策略避免单个解析器对用户请求历史的完整收集。AUSTIN HOUNSEL等人分析了与DNS加密和集中化相关的争议和隐私问题,并对请求分散策略中递归解析器的选择方法进行了对比研究[22]。
3 多解析器机制中的选择方法研究
使用多解析器机制对用户的DNS请求进行分散的过程中,解析器的选择方法是机制的核心问题。不同的选择方法直接决定了请求分散的效果和用户感知到的域名解析体验。
常用的解析器选择方法有哈希法、轮询法和随机法。其中哈希法将域名映射到候选解析器上,可以保证域名和解析器的固定对应关系。轮询法在每次用户发起域名解析请求时在候选解析器列表中进行轮询。随机法即每次选择解析器时进行随机选择。如文献[22]中所述,在目前的选择方法中,仅有哈希法可以实现域名与解析器的固定化,即多次对同一个域名发起请求,每次选择的解析器都为同一个。而缺少固定化的选择方法在足够多的解析次数后,每个候选解析器最终都能观察到用户的全部域名访问记录。
本文提出一种改进的解析器轮询选择方法。改进的轮询方法通过增加一个解析记录表来实现域名和解析器的固定对应,记录表保存用户的所有域名解析历史。当一个新的解析请求到来时,检查其中包含的域名是否被某个解析器处理过。如存在处理记录,则为了保持该域名与其相关解析器的固定关系,继续使用之前的解析器处理本次请求。如不存在相应的记录,则由轮询算法选择处理该域名请求的解析器,完成解析后增加新的记录。
相比哈希法,轮询法可以实现更高的请求分散效果。此外,轮询法可以通过选择合适的指标,引入权重系数后优化为加权轮询法,提高多解析器机制的整体域名解析速度。
3.1 基于改进轮询的多解析器机制设计
本文实现的机制没有改变DNS层次结构的任何其他组件或DoH协议本身,仅研究在客户端实现多解析器查询方案来达成分散用户隐私的设计目标。在大多数现有的DoH实现中,DoH客户端被集成在了浏览器内。而本文为了实现更通用的设计且便于代码实现,对多解析器机制进行独立实现,与浏览器解藕。通过修改操作系统的DNS递归解析器地址配置,所有DNS解析请求会被发送至一个本地的DNS-DoH翻译器,由翻译器向递归解析器发起DoH请求并向请求者返回DNS结果。DNS和DoH报文的转换过程发生在本地,所以不会出现明文暴露在链路上的问题。
本文的多解析器方法在进行解析器选择时主要考虑的因素是候选解析器的选择方式以及域名和递归解析器的固定化,固定化通过对域名-解析器查询记录表的检查和更新实现,最终设计如图3所示。
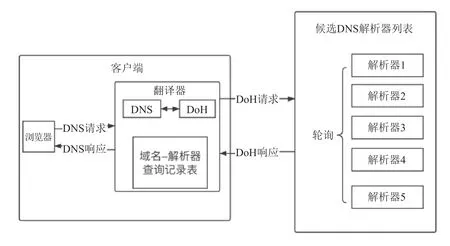
图3 多解析器机制设计Fig.3 Multi-resolver mechanism design
在候选解析器选择方式上,采用朴素的轮询方式可以使用户的域名查询隐私在各解析器之间均匀分布。采用基于ping值的加权轮询方式可以使用户获得更好的域名解析服务体验。权重计算公式如下:

以一个实际场景为例对整个流程进行详细介绍。现有用户使用浏览器多次访问了两个域名a.com和b.com,考虑用户访问顺序、访问时间间隔和用户侧缓存过期等因素,设最终浏览器发起的域名解析请求顺序如下[a.com, b.com, a.com],则本文实现的多解析器机制工作情况如下:
(1)浏览器发起DNS解析系统调用,操作系统根据配置的DNS解析器地址(翻译器)将a.com发送至翻译器请求解析;
(2)翻译器查找域名-解析器查询记录表,不存在a.com的查询记录,根据轮询方式选择解析器1作为本次解析的服务器;
(3)翻译器根据RFC8484将原始的DNS请求转为DoH请求,向解析器1发送;
(4)解析器1完成后续的域名解析工作并向翻译器返回DoH的解析结果;
(5)翻译器将DoH转换为原始DNS报文并返回;
(6)翻译器记录本次查询的域名a.com和处理本次查询的解析器1;
(7)当b.com的解析请求到来时,机制工作过程与(1)-(6)相同,翻译器最终记录b.com和通过轮询得到的处理该域名的解析器2;
(8)第二次处理a.com时,翻译器查找记录表找到a.com和上次处理该域名的解析器1,因此不进行轮询选择,直接向解析器1再次发送DoH解析请求。
以上所述的多解析器机制通过引入域名解析记录表,可以在多个候选解析器之间分散用户的域名解析请求并保证域名和解析器的固定化。基于记录表的轮询选择方法相比哈希方法更加灵活,能通过定义权重进行性能优化。虽然记录表带来了额外的存储空间消耗和维护成本,但对于一般的互联网用户所请求解析的域名总量而言,该成本可以忽略不计。
4 实验
本节中将讨论如何设置和进行实验,以分析多解析器机制在不同选择方法下的隐私保护效果及整体解析性能。
4.1 实验准备
本文选取了Tranco提供的域名列表的前100个来模拟用户的域名访问列表[23]。在解析器列表的制定上,根据解析器所处的地理位置在Curl提供的公共DoH服务器项目[24]中进行选择。具体的解析器选择和编号结果见表1。

表1 候选DNS解析器Table 1 Candidate DNS resolver
4.2 选择算法实现
哈希方法中,域名字符串被哈希函数映射到0-5的整数,对应序号的候选解析器将被选中负责完成该域名的解析。
改进的轮询方法中,通过维护一个全局变量在每次解析请求后自增一并候选解析器个数取模,与解析器编号进行对应,完成解析器的轮询。
基于ping值的加权轮询算法中,首先对候选解析器进行ping延迟测量,根据解析器的ping时间进行排序并计算权重,生成加权轮询队列以进行解析器的选择。
4.3 实验过程和结果分析
本文在运行Ubuntu 18.04.3 LTS的机器上进行实验,实验机的网络环境为中国科学院教育网。
(1)记录表轮询的固定化验证
首先对引入记录表而获得的域名-解析器固定化进行验证。实验中对多选择器机制进行多次解析测试,每完成一轮测试后将域名列表进行打乱重排再进行下一次测试。在完成有记录表机制的轮询的多次解析测试后,通过修改代码实现中的记录表部分,屏蔽向记录表中添加域名请求记录的功能,实现无记录表机制的传统轮询选择方法,再次进行多次解析测试,将域名请求的分布结果进行对比,如图4所示。
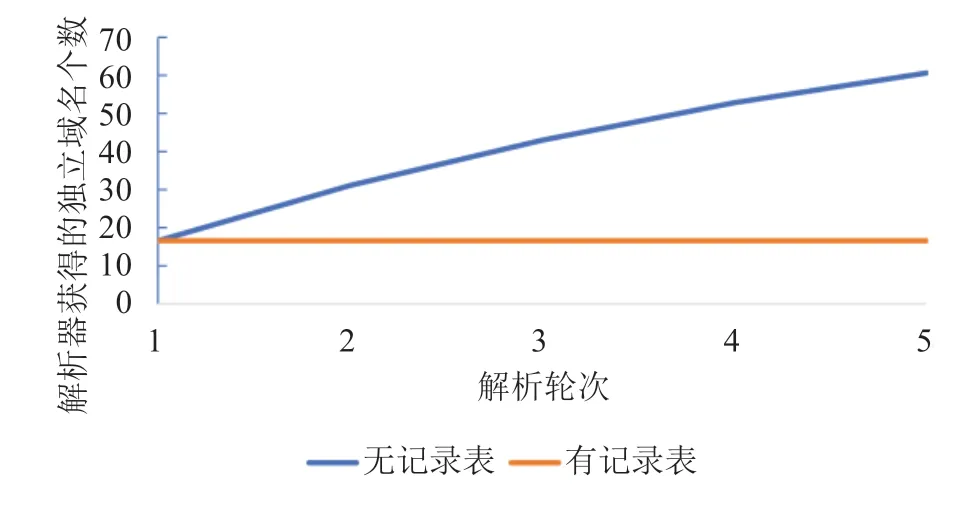
图4 解析器获得的独立域名个数与解析轮次关系Fig.4 Relationship between the number of independent domain names obtained by the resolver and the number of resolution rounds
由实验结果可见,无记录表的传统轮询方法由于缺少域名和解析器的绑定,随着解析次数的增加,候选的解析器能观察到更多的用户域名请求历史,无法实现请求分散的设计初衷。而本文提出的引入记录表的轮询实现可以实现域名和解析器的固定化,经过多轮解析测试后每个解析器依然只能观察到整个用户请求历史的一小部分。
(2)横向对比实验
为了获得加权轮询算法计算权重所需的ping延迟排序,开始对比实验前先对用户到所有候选解析器的ping值进行测量,为了避免解析器拒绝返回ICMP报文,测量使用了基于TCP的ping方式。测量结果、排序和权重计算结果如表2所示。

表2 候选解析器的ping测量和权重计算Table 2 Ping measurement and weight calculation for candidate resolvers
在对比实验中,本文对哈希,通过查询记录表保持固定化的朴素轮询,通过查询记录表保持固定化的加权轮询分别进行实验测试。每个独立的域名会被随机解析1到5次,以模拟现实场景中用户对相同网页的重复访问。
根据实验结果可见,各类解析器选择策略表现出了不同的请求分散程度,引入了记录表的轮询方法分布最为均匀。为了量化实验结果,通过标准差对各选择策略的分散程度进行衡量,标准差计算结果如表3所示。

表3 解析器上分布的域名数量的标准差Table 3 Standard deviation of the number of domains distributed on the resolvers
由不同选择策略的解析器选择结果标准差可见,改进的轮询法可以实现最好的请求分散效果,将用户在DNS服务端的隐私进行最大程度的分散,而加权轮询算法在分散效果上表现较差。在下一步实验中将对三种策略的性能表现进行进一步研究。
为了将传统集中式方法和多解析器方法的性能表现进行对比,在测试三种选择方法的同时对列表中每个解析器都单独进行一轮域名解析测试并记录解析延迟。
对比实验结果显示,加权轮询的平均解析延迟明显低于哈希法和轮询法,这是因为大部分的解析请求被发送到了响应较快的解析器上。此外,可以观察到轮询法的整体解析延迟略低于哈希法,通过结合图5的域名分布情况进行分析可知,这是由于哈希法将较多的域名映射到了响应最慢的解析器1上,而轮询法的延迟表现与各解析器的整体平均表现相当。
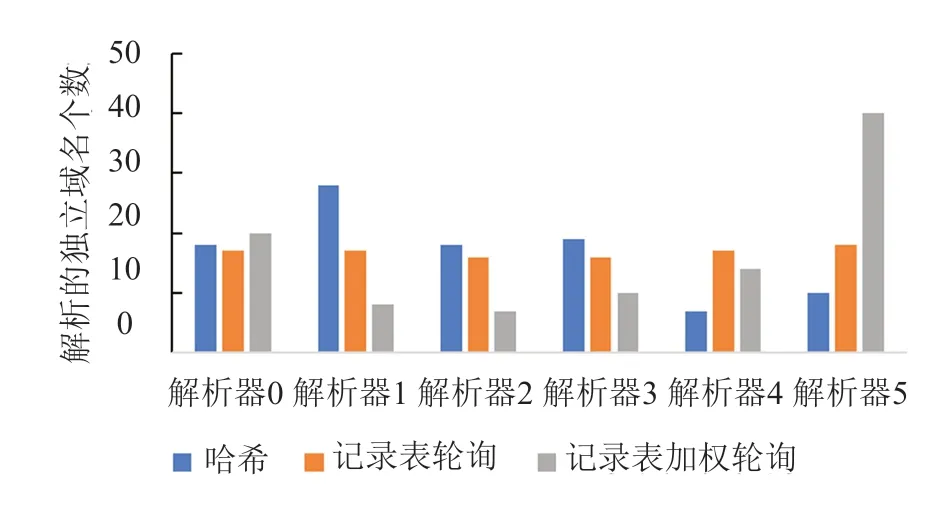
图5 不同选择策略的域名解析分布Fig.5 Distribution of domain name resolution with different selection strategies

图6 域名解析延迟对比Fig.6 Domain name resolution latency comparison
综合全部实验结果可得出三种选择策略的特点。其中,哈希方法将请求以接近正态分布的方式分散在候选解析器列表中。由于哈希结果的随机性,可能会导致较多的流量流向部分响应很慢的解析器,导致整体性能不佳,也可能反之,因此基于哈希法的多解析器机制最终性能表现有一定的不确定性。朴素轮询法可以以均匀分布的形式分散用户的请求,因此其最终性能表现将为候选解析器列表的整体平均性能。加权轮询法相比朴素轮询牺牲了一部分请求分散效果,以换取更好的性能表现,其分散程度和性能水平由权重计算的具体实现方法决定。本文提出的权重计算方法仅作为一种参考。
5 总结与展望
在当前DNS隐私保护逐渐受到重视的趋势下,DNS加密传输带来的集中化问题也需要更多的关注和研究。多解析器机制作为一种实现于域名解析客户端上的轻量级解决方案,可以有效缓解集中化问题,在递归解析服务端保护用户隐私。多解析器机制相比基于代理的ODNS和ODoH方法,没有改变DNS层次结构的其他组件,无需部署额外的基础设施,在应用和推广上有着很大的优势,值得深入研究。本文通过对多解析器机制中的请求分散策略进行研究分析,提出了一种引入域名解析记录表的轮询策略,并进一步提出使用基于ping延迟的加权轮询方法改进多解析器机制的整体性能。相比此前研究主要采用的哈希方法,本文提出的改进轮询方法在请求分散的效果上可以实现均匀分布的最佳分散效果,在性能优化方面,加权轮询方法提升了多解析器机制的整体解析速度,代价是降低了请求分散的能力。用户可以根据其对隐私保护效果和性能的偏好在两种方案中进行选择。
多解析器机制的请求分散策略中还有一个问题未得到解决,就是分散程度与用户隐私保护效果的具体关系。以本文的加权轮询方法为例,当某个候选解析器权重过高时,它将能收集到足够用来构建用户画像的隐私数据。在该方向的下一步的研究中,应当在信息熵等角度对分散程度和用户隐私保护效益的关系进行更深入的探讨。
利益冲突声明
所有作者声明不存在利益冲突关系。
