一种面向工业边缘计算应用的缓存替换算法
2021-07-23陈鸿龙DanielBovensiepen
张 雷 李 琳 陈鸿龙 Daniel Bovensiepen
1(南京邮电大学物联网学院 南京 210009)
2(中国石油大学(华东)控制科学与工程学院 山东青岛 266580)
3(西门子中国研究院 北京 100102)
随着物联网技术的快速发展,越来越多的具有计算能力的智能传感器和执行器被应用在工业自动化系统中,产生了海量的物联网数据[1].这些数据可以用于改进控制工艺,优化生产流程,进而提高生产效率.例如传统工厂中控制策略通常通过离线下载到可编程逻辑控制器(programmable logic controller, PLC),在封闭的控制网络中运行,很难做到灵活更新.现在新型的PLC支持配备AI模块,使得利用机器学习等算法实现生产任务的柔性自组织成为可能[2-3].
机器学习算法的样本数据来自于传感器、控制器和执行器等现场设备在历史生产过程中产生的控制和状态参数.工厂底层现场的设备数量众多,加上单个设备产生的数据帧很短,但是由于生成周期小,因此每天产生的数据规模巨大.这些海量数据存储在云服务器,如果采用基于云的数据服务,数据传输的延迟将会非常大[4].而工业应用通常对数据传输的时延往往有严格要求,因此,将边缘计算应用于工业物联网有很大的优势[5].边缘计算在靠近用户的边缘部署服务器设备,利用其自身的存储和计算资源,对用户请求提供低延迟的数据传输服务,为实时性任务处理提供保障.
但是,边缘节点的存储容量通常非常有限,在边缘节点缓存所有内容是不可能的.因此,通过合理的缓存策略确定缓存内容集,最大化缓存利用率,减少向云服务器请求内容次数,对于边缘网络的服务性能保障至关重要.
尽管已经有很多边缘缓存的研究工作,据我们所知,目前还没有针对工业边缘计算应用的缓存策略.本文的主要贡献有2个方面:
1) 在分析典型工业应用场景的基础上,建立工业边缘网络模型.基于散粒噪声模型(shot noise model, SNM)对工业用户请求进行建模,进而建立用户请求的流行度变化模型;
2) 提出一种新的缓存替换算法,综合考虑时效性、内容大小优先性和流行度预测确定内容价值.通过与5种经典缓存算法的对比实验验证了所提出算法的有效性.
1 相关工作
一个边缘缓存策略是否成功主要取决于它对缓存内容价值估计的准确性.内容流行度是做出缓存决策的有效措施.经典的最近最久未使用(least recently used, LRU)算法[6]将用户访问时间作为流行度指标,离当前时刻最近的访问内容流行度最高,容易受到一些偶然访问内容的干扰.最近最少访问频次(least frequently used, LFU)算法[7]将不同内容的访问频次作为流行度指标,访问次数最多的内容流行度最高,容易导致缓存污染问题.Size算法[8]将内容大小作为流行度指标,最小内容流行度最高,可能会引起频繁请求流行度高的大内容,造成带宽的浪费.针对单个特征指标存在的问题,很多研究提出基于访问时间、访问频率、内容大小等多个特征的混合缓存策略,以提高流行度评估的准确性,代表性工作如贪婪双尺寸(greedy dual size, GDS)算法[9].
这些传统的缓存算法易于实现、算法复杂度低,已经取得广泛应用.然而随着因特网数据的爆发式增长,边缘计算、内容中心网络和5G网络等新型网络的出现对缓存策略提出了更高的要求,因此近年来的研究工作主要面向新型网络场景提出相应的缓存优化算法.
根据缓存内容集合与用户请求内容集合的关系,这些缓存策略可分为2类:1)假设网络节点缓存所有用户请求的内容,此类缓存研究将主要关注点放在请求内容如何在不同节点上进行缓存部署.一般做法是基于成本、延迟等网络性能指标将缓存部署问题转化线性优化问题[10-11],接着通过进化算法或启发式算法找到优化的全局缓存部署方案.这类策略需要收集全局网络信息,求解开销昂贵.因此文献[12-13]利用节点间合作关系,提出分布式缓存策略,得到节点的最佳缓存内容集.2)缓存研究假设缓存容量有限,网络节点只缓存部分内容.经典的基于流行度的缓存算法MPC(most-popular content)[14]认为缓存热点内容相比缓存不是热点的内容所带来的缓存效益更高,因此通过流行度表记录每个内容的流行度值,只有足够流行的内容才可能请求缓存.文献[15]综合比较了MPC及其改进算法的性能,并面向命名数据网络提出改进算法.Sun等人[16]针对D2D网络提出一种基于移动感知的MPC改进算法.Deng等人[17]针对车联网中车辆的需求和偏好,以及收发节点的相对位置,提出分布式概率缓存策略.
目前大多数缓存策略研究都采用了静态的内容流行度模型,通常假设服从Zipf分布.但是静态模型忽略了真实场景下用户对不同内容的请求偏好随时间变化的动态性.当内容请求发生变化,缓存算法会出现性能退化.因此,最近的研究已经转向分析和预测流行度的动态变化,并设计动态缓存策略.这些缓存策略主要从内容本身特征或用户请求特征刻画流行度模型.
一部分研究者通过分析视频、社交内容的更多相关特征,用于流行度预测.有数据表明,视频流量数据已经成为互联网的主要流量[18].Zhang等人[19]将视频文件序列化为具有名称前缀和顺序索引的块,通过分析用户的请求行为发现视频块之间的关联特征从而预测未来视频块的流行度.朱琛刚等人[20]分析了电视节目与上线日期、播出时间和节目类型等特征的关联性,从中提取影响节目流行度的关键特征构建节目流行度随时间变化的模型,使用随机森林算法构建电视节目流行度预测模型,并提出了一种节目缓存调度算法.社交流量数据是另外一类活跃因特网流量,可利用社交媒体的传播特性进行内容流行度分析.朱海龙等人[21]基于传播加速度和用户活跃性提出微博消息的在线流行度预测方法.Li等人[22]提出面向社交网络的popCaching缓存策略,算法没有预测每个内容单独的流行度,而是假设上下文特征相似时内容流行度相似,采用4段历史访问量作为当前上下文特征.
另一部分研究者挖掘新型网络场景下的用户偏好和请求特性用于动态流行度预测.如无线网络区别于有线网络一个重要特征是用户的移动性,不同用户移动时体现为不同的时空特征.因此很多研究者面向移动边缘计算应用,结合实际场景下用户的时空移动特性,为边缘节点提出流行度预测算法和缓存策略.如Yang等人[23]和Yan等人[24]利用边缘节点的位置特征代表该位置的用户偏好,并提出在线预测算法,提高内容命中率.Gao等人[25]通过基站感知用户的移动模式,以此来计算本地内容的流行度,并将不同移动速度用户请求的文件分别缓存在不同的基站.Li等人[26]针对移动网络用户的移动历史数据,建立Markov模型预测用户在移动和请求方面的行为,根据计算的内容流行度进行预缓存.Bharath等人[27]针对时变且未知的内容流行度,分别以Bernoulli模型和Poisson模型作为内容请求模型,面向异构无线网络的小基站节点,提出根据预估的内容流行度和最优值的误差决定缓存更新,仿真结果表明比定期的缓存更新性能更优.
可以发现,对于基于流行度动态变化的缓存策略研究方法主要面向在线音视频、社交网络等互联网内容,在某个具体网络情境下引入更多的分析特征提高流行度预测准确性,进而提高缓存命中率.而工业应用与在线音视频、社交网络等互联网应用有着截然不同的流量和用户请求特征.音视频数据流具有数据帧长、流量大、占用带宽高的特点,而工业生产过程生成的数据量巨大,数据帧短且时效性高.互联网中的内容有可能被任意一个用户请求,而工业边缘缓存节点往往服务于特定的工业控制设备,设备的内容请求与生产任务相关,没有复杂的社会关系交互的干扰,不会发生内容在大部分设备上广泛传播.因此,已有的缓存算法很难直接应用于工业应用场景下的边缘缓存.
2 系统模型
本节面向典型的工厂应用需求建立网络模型和缓存问题模型.
2.1 网络模型
一个典型工业应用场景中的边缘网络体系结构如图1所示.最上层为云服务器中心.中间层为边缘节点层,每个边缘节点都有有限大小的缓存资源.底层为现场智能设备,如智能传感器、PLC、工控机、工程师站等.

Fig. 1 A typical industrial edge network structure图1 一个典型的工业边缘网络结构
假设底层传感器、控制器和执行器等现场设备产生的历史生产控制和状态参数等内容集合记为Ω.现场设备进行学习任务时将请求其中部分内容集合M,大小为|M|,每块内容m的大小为Sm.为了减小数据传输延迟,N个边缘节点将提供缓存服务,每个边缘节点n缓存容量为L(单位为MB).
2.2 问题模型
假设工业用户总共发出了K次内容请求,Cmk表示第k次请求的内容是否为第m个内容,是则Cmk=1,否则Cmk=0.Ank表示请求内容是否被缓存到边缘节点n,是则Ank=1,否则Ank=0.缓存命中率表示为
(1)
边缘网络中的数据传输延迟由2部分组成,如用户请求内容被缓存,延迟为内容从边缘节点传输到用户的时间,即延迟为缓存读取时间d.如用户请求的内容没有在缓存中时,边缘缓存设备需要向工厂私有云请求缓存该内容,数据的传输会受到回传链路容量的限制,令B表示工厂云服务器向边缘缓存节点的传输链路带宽,γ表示该链路的传输因子,即网络不稳定或拥塞时引起的延迟.则平均传输延迟D可以表示为

(2)
本文的优化目标是最大化边缘节点的缓存命中率,最小化用户请求内容的传输延迟,优先保障控制数据.优化问题可以表述为
maxH,
(3)
minD.
(4)
3 用户请求流行度预测
本节首先结合工业应用中用户请求特点,建立用户请求模型,然后梳理了工业用户请求内容的特征属性,并给出用户请求流行度变化的预测方法.
3.1 用户请求模型
目前用户请求模型使用比较广泛的是独立参考模型(independent reference model, IRM)[28].IRM模型作为一种静态模型,假设内容请求的流行度不随时间改变,用户请求遵循Zipf分布.该模型简化了缓存问题复杂度,但是无法反映内容流行度的时间局部性特征.而工业应用中,设备请求的内容随着生产任务的变化而变化,请求内容的生命周期与生产节拍密切相关,因此IRM模型不适用于工业场景.本文采用Traverso等人[29]提出的SNM作为用户请求模型.与IRM模型相比,SNM模型描述了内容请求的过程,可以更好地表现不同内容热度随时间变化的动态趋势.
SNM模型下,内容请求产生过程被假定为Poisson过程,对每个内容的请求过程是独立的齐次Poisson过程.整个请求过程表示为许多独立过程的叠加,每个内容的请求过程对应一个独立过程.具体地,对于内容m,将时间u处的请求到达率表示为
Ym(u)=Vmλm(u-τm),
(5)
其中,m代表内容m进入系统的时间点,λm(u)代表对内容m的请求到达率随时间u变化的规律,即“流行度轮廓”.文献[30]提到常用的3种流行度轮廓为指数轮廓、均匀轮廓和随机轮廓.为简化应用,本文采用均匀流行度轮廓,即内容m遵循在生命周期T内,平均到达率为λ的齐次Poisson过程.在整个评估时间E期间所请求的内容的平均数量为λE.Vm表示内容m在活跃时间内被请求的总次数.通过以上特征来描述内容m随时间变化的请求过程.


Fig. 2 Examples of requests generated by two different contents图2 不同的2个内容生成的请求示例
3.2 用户请求的流行度变化预测
工业应用中设备请求的动态性与当前进行的生产任务更新调整具有高度的相关性.工厂一天内可能有多个不同生产优化任务发生.以生产的自组织调度为例,生产线可能包含多个不同种类的设备,控制器请求的内容尽管来源于同生产线的不同设备,但是都具有相同的位置属性.又例如控制器基于机器学习算法优化设备故障预测策略,需要请求设备对象自带的相关传感器历史数据、历史诊断数据以及类似设备的历史数据.这些请求的内容都来自同类型的对象设备.通过这2个实际应用案例对比,可以发现:不同任务发生时,控制器运行学习算法需要请求的内容完全不同.但是每个设备请求的内容有一定的共性特征,这些特征反映了当前进行的不同生产任务.
为了总结其特点,我们定义来自工业现场的内容的多维特征属性:时间属性、位置属性、来源设备属性、对象设备属性等.时间属性为数据采集的发生时间;位置属性为数据采集的发生地点;来源设备属性为数据源;对象设备属性为数据的监测对象.对于任意的内容m,都有W个特征属性,用集合{fm1,fm2,…,fmW}表示.
由于内容只在有限生命周期内活跃,流行度分析只统计最近的时间窗口的请求内容的特征属性变化.假设T为周期时间窗口大小,F(t)为第t个时间窗口内所有请求内容的特征集合.利用Jaccard相似度系数定义第t个和第t-1个时间窗口内请求内容集合的相似性函数为

(6)
在第t个时间窗口内,当相似度系数Sim(t)值大于阈值θ时,认为前后2个时间窗内进行的生产优化任务没有发生变化.当相似度系数值小于阈值θ时,认为当前活跃的生产优化任务已经发生变化.
在实验过程中发现,生产优化任务变化时,往往会有一个主导内容属性特征随之发生变化.因此本文没有统计所有特征属性,而是利用最近周期窗口内的出现次数最多的热点特征属性来表征当下实时进行的任务.这种单一特征属性指征的优势在于简化了计算,降低缓存算法复杂度.定义Mo(F(t))为热点特征属性,F(t)集合中Mo(F(t))的元素序数为w*,即fw*(t)=Mo(F(t)) ,则相似度函数的计算可简化为
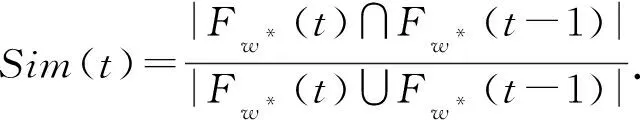
(7)
4 PPPS缓存算法
基于3.2小节对用户请求的流行度变化预测方法,提出基于属性特征流行度预测的缓存算法(combing periodic popularity prediction and size caching strategy, PPPS).PPPS算法一方面考虑流行度和内容尺寸的影响,为每个内容设置缓存内容价值;一方面,将热度较高的特征属性内容提前存储到边缘缓存的空闲空间,提升边缘缓存的命中率,提高缓存利用效率.
PPPS算法为每个内容定义了缓存价值Q,通过缓存价值函数作为缓存替换的依据.缓存价值函数首先考虑时间局部性的影响,设置缓存更新时间.其次根据最近的历史请求内容,预测各缓存内容流行度概率.再则,在工业应用下,控制和状态信息内容的尺寸小、频率高,音视频内容大但出现频率小,将尺寸纳入价值函数的意义在于优先保障缓存那些具有更重要的文件.对于任意内容m,得到其价值函数Qm:

(8)
该函数值的大小与缓存内容被替换的概率呈负相关.其中,pm(t)表示单个内容m在第t个时间窗内的流行度概率.第t个时间窗口内用户请求内容的热点属性特征集合为{fxw*,f(x+1)w*,…,f(x+T)w*},内容m的流行度概率可表征为其特征属性在第t个时间窗口的发生概率为
(9)
算法实现流程为:每次当新的用户请求内容到达,判断缓存中是否已经存在当前请求的内容.若命中,则更新该内容的价值;若未命中,则判断缓存剩余空间是否足以存储该内容,是则直接存入缓存队列,否则替换掉缓存价值最小的内容,直到空间大小足够容纳新内容.然后判断累计用户请求次数是否到达T,是则更新t值,t=t+1.同时计算t和t-1周期时间窗口请求内容的相似度系数Sim(t),当其小于阈值θ时,则删除缓存队列里非热点特征属性内容,并随机选择热点特征属性的内容放入缓存,但缓存内容价值Q=0.PPPS算法实现的伪代码如算法1所示:
算法1.PPPS算法.
输出:缓存命中率H.
① 初始化j=0,t=0;
② fork=1,2,…,Kdo
③ 用户请求内容m;
④ if内容m已被缓存
⑤j++;
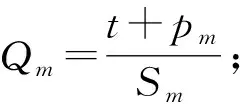
⑦ else
⑧ while(缓存空闲大小 ⑨ 删除最小价值Qmin的内容; ⑩ end while PPPS算法时间复杂度的计算可分为缓存更新和内容流行度计算2部分,缓存更新流程与LRU算法类似,算法复杂度为O(1);流行度的计算主要取决于热点特征属性w*的更新,可以归结为F(t)集合的众数求解问题,因此算法复杂度为O(TlogT).结合这2部分,PPPS算法时间复杂度为O(TlogT). 本节首先介绍了实验参数设置,然后通过3组实验场景分析和比较算法性能. 算法的运行环境为Matlab R2016b,操作系统为Windows10,计算机处理器为Intel i7-8565U 8核,主频为1.80 GHz,内存为8 GB. 工业边缘网络采用图1的网络结构.最上层的云存储了所有内容.在网络边缘部署了边缘节点,每个节点都有有限大小的缓存空间.每个缓存设备的容量在20~180 MB.从云服务器到边缘节点的链路传输带宽为100 MBps.缓存传输链路的延迟因子设为15 ms. 因为没有工业环境下的真实数据,我们通过仿真产生内容和用户请求序列.云服务器存储了M种内容.产生的内容大小是服从Zipf分布的随机数.基于SNM模型随机产生内容请求数据.随机生成各内容的生命周期和各内容活跃的起始时间,并根据起始时间来划分内容的位置属性. PPPS算法参数:阈值θ=0.1,时间窗口周期T=100.值得注意的是,时间窗口周期T设置与生产任务的更新频率有关.T值太小会导致缓存价值频繁更新,影响算法性能.缓存性能的影响因素很多,如用户请求序列、内容大小分布、内容种类、缓存容量等.通过3个实验分别分析主要因素对算法性能的影响. 实验1.对比了分别在IRM模型和SNM模型产生的数据流量下,各算法随缓存容量的性能变化.该实验旨在探究缓存算法分别在不同用户请求模型产生的数据流量下的性能表现.实验参数设置为:内容大小设置服从Zipf分布,参数α=0.7,范围为1~5 MB,内容种类M=200,总共请求次数为19 562次,缓存空间为20~180 MB. 实验2.研究内容大小相同时缓存算法的性能,并对比实验1探究内容尺寸对缓存算法的影响.实验1的内容尺寸是考虑工业网络混合了控制数据、视频数据、图像数据等多种类型内容.实验2的内容尺寸设置实际上也有现实的应用背景.在很多传统的工厂内,工业网络中的数据类型单一,现场设备产生很短的控制数据帧,经过网关缓存上传给云服务器,表现为单一的内容尺寸.实验参数设置为:所有内容大小设为1 MB,内容种类M=200,总共请求次数为19 562次,缓存空间为20~180 MB. 实验3.固定缓存容量,主要研究内容种类对缓存算法性能的影响.实验参数设置为:固定缓存为300 MB,内容种类M为100~500,各内容种类分别对应的请求次数为8 810,19 562,29 076,38 875,49 356,内容大小随机生成,服从Zipf分布,参数α=0.7,范围为1~5 MB. 为了更好地分析和比较所提出的PPPS算法,本文实现了5种经典的缓存策略FIFO,LRU,LFU,GDS,MPC算法作为对比算法.其中MPC算法本身并未考虑缓存容量有限的情况,因此许多研究工作在MPC算法实现时与LRU相结合,实现缓存内容的替换[31].本文采用同样的策略,MPC算法的流行度阈值设为3.采用缓存命中率和平均延迟作为算法的性能评估指标. 1) IRM模型和SNM模型的用户请求影响分析用SNM模型和IRM模型分别产生用户请求序列,假设请求时间总长为S,按时间顺序分为4等份,图3对比了2种模型下内容请求过程中不同时间段的请求频率.IRM模型产生的内容序列遵循Zipf分布,内容流行度始终不变.而SNM模型产生的内容序列则更好地体现了内容流行度在生命周期内的动态变化.随不同内容热度的逐渐上升,热点内容都在某一时间段内出现请求高峰值,符合工业应用场景. Fig. 3 Frequency of requested contents under different content request models图3 不同内容请求模型下内容请求频率分布 实验1结果对应图4和图5.首先,图4描述了PPPS算法和5种对比算法在基于SNM模型的用户请求序列下,随缓存容量变化命中率和平均延迟的性能表现.从图4(a)可以看出,LFU算法的命中率表现最差,是由于过气的热点内容长期滞留缓存的“缓存污染”问题造成.FIFO算法和LRU算法的命中率次之,反映了2种算法对动态模型下的内容请求分布适应性也较差.MPC算法只缓存超过阈值的流行内容,因此缓存容量较小时MPC在LRU基础上性能有一定改进,但随着缓存容量变大MPC的命中率出现收敛趋势.GDS算法中权衡了内容尺寸和访问时间,因此更适应存在很多小尺寸的控制流量的工业应用.GDS算法在缓存容量较小时与MPC表现接近,但随缓存容量增大,GDS可以达到比MPC更好的命中率.本文提出的PPPS算法命中率始终保持最高.缓存容量为120 MB时,PPPS算法的命中率比MPC提高12.3%,比GDS提高15.7%,比LRU提高21.3%,比LFU提高24%,比FIFO提高29.6%. Fig. 4 Algorithm performance comparison under the SNM图4 SNM模型下算法性能对比 图4(b)描述了6种缓存算法随缓存容量的变化引起的平均延迟变化.可以看出,平均延迟的变化与命中率变化的趋势相反,随着缓存容量的增大,6种算法的延迟都逐渐减小,PPPS算法的平均延迟一直低于其他5种缓存算法,与命中率的表现具有一致性.缓存容量为120 MB时,PPPS算法的平均延迟比MPC降低12.3%,比GDS降低15.7%,比LRU降低21.3%,比LFU降低24%,比FIFO降低29.6%.因此可以说PPPS算法平衡了内容尺寸、时间和流行度等影响因素,在数据请求为动态分布时有最优的性能表现. 图5展示了内容请求序列遵循Zipf分布时,6种缓存算法随缓存容量变化的命中率和平均延迟的比较.可以看到LFU算法命中率较高,这是因为Zipf分布遵循二八定律,有少数的内容被多次请求,这对于按照请求频次作为流行度指标的LFU算法十分有利. PPPS算法随缓存容量的增大,其命中率始终高于其他5种算法.缓存容量为120 MB时,PPPS算法的命中率比MPC提高9.8%,比GDS提高5.6%,比LFU提高2.2%,比LRU提高11.5%,比FIFO提高15.6%. 在算法的平均延迟表现上.PPPS算法也具有较低的延迟.因此,PPPS算法在数据请求为Zipf分布时也有较稳定的性能. Fig. 5 Algorithm performance comparison under the IRM图5 IRM模型下算法性能对比 2) 内容大小相同时缓存算法的性能分析 实验2结果对应图6,旨在探究内容的尺寸对缓存算法的性能影响.在SNM模型生成的请求流量下,将所有内容的大小设置为相同,图6(a)为6种缓存替换算法在不同缓存容量下的命中率比较.MPC算法的表现最差,这是因为当内容大小都设置为1 MB的小文件时,MPC由于设定了静态的流行度阈值,导致即使缓存有充足的空间,相当部分的数据由于达不到流行度阈值不能进入缓存.LFU算法次之.LRU,GDS,FIFO三种算法的性能相近.PPPS算法的命中率仍然保持最高,且随着缓存容量变大性能改进更加明显.缓存容量为120 MB时,PPPS算法的命中率比GDS,LRU,FIFO这3种算法提高5.5%,比LFU提高16.8%,比MPC提高20.7%.图6(b)为6种缓存算法平均延迟的比较,PPPS算法具有最小的平均延迟.可见将内容尺寸的影响因素去除后,PPPS算法的表现仍然最佳,证实了基于属性特征流行度预测方法的有效性. Fig. 6 Algorithm performance comparison with unique content size setting图6 内容尺寸相同时算法性能对比 3) 内容种类对算法性能的影响分析 实验3结果对应图7,旨在探究缓存算法在不同内容种类下的性能表现.在SNM模型生成的请求流量下,令内容种类范围为100~500,图7展示了6种缓存替换算法的性能对比.可以看到,随内容种类的增多,所有缓存算法的命中率都逐渐下降,平均延迟都逐渐增大.LFU算法因为缓存污染的问题在各内容种类下性能都较低,LFU算法的平均延迟曲线出现小的波动,这是因为工业中小尺寸内容较多,当请求频率较低的大尺寸内容发生频繁替换时,容易导致延迟的增加.FIFO,LRU,GDS这3种算法性能曲线相近,在LFU的基础上有不同程度的性能提升.MPC算法在缓存容量足够大时,性能出现退化;随着内容流量增加,MPC算法表现逐渐优于LRU算法.PPPS算法则始终保持最高的命中率,以及更低的延迟.内容种类为350种时,PPPS算法的命中率比GDS提高15.3%,比MPC提高17.3%,比LRU提高20.1%,比FIFO提高22.3%,比LFU提高24.8%.并且,PPPS算法相对于其他算法的性能改进随着内容种类的增加而增加.在工业应用中可能面临内容种类的多样性,PPPS算法在不同的内容种类测试中,均保持了最优表现. Fig. 7 Algorithm performance comparison with different content types setting图7 内容种类变化时算法性能对比 从实验结果可以看出,内容大小、内容种类、用户请求模型都对缓存替换算法的性能产生影响,但是本文提出的PPPS算法与其他经典缓存算法相比,始终具有最高的缓存命中率和较低的平均延迟.PPPS算法通过周期性预测特征属性热度,将内容流行度预测纳入缓存价值的计算,并判断未来热点内容,在缓存空间空余时提前将热点内容存储到边缘缓存中,确实有效提升缓存利用率,提高缓存命中率,并有效减少传输延迟. 本文基于工业边缘计算应用场景,首先建立工业边缘网络模型和用户请求模型,然后基于最近时间窗口的内容请求序列的特征变化,建立单一维度的内容流行度概率模型,结合内容尺寸提出一种新的PPPS缓存替换算法.实验结果表明:PPPS算法与MPC,GDS,LRU,LFU,FIFO 这5种经典算法对比,在缓存命中率和平均延迟2种性能指标下,在不同内容大小分布、内容种类、用户请求模型下均取得最佳性能,为实际工业场景里缓存算法的选择提供了依据.未来工作将考虑通过多维度特征表征内容流行度,并使用机器学习算法预测流行度周期的变化.5 算法性能评估
5.1 实验参数设置
5.2 实验结果分析





6 总 结
