社交网络信息传播预测与特定信息抑制
2021-07-23曹玖新高庆清夏蓉清刘伟佳朱雪林
曹玖新 高庆清 夏蓉清 刘伟佳 朱雪林 刘 波
1(东南大学网络空间安全学院 南京 211189)
2(东南大学计算机科学与工程学院 南京 211189)
近年来,社交网络以其多样化的分享功能,打破了固有的信息传播形式.随着社交网络平台的普及度越来越高,时间与空间不再成为信息传播的阻碍,为人们提供了极大的便利.然而,社交网络中存在着海量的信息,隐藏其中的谣言、不实信息、有恶意导向性的舆论等往往也会被广为传播.
目前,微博上的用户可以对微博中存在垃圾营销、不实信息、诈骗信息等情况进行投诉,平台验证后会对该微博以及该微博的作者进行一定的处理,来达到抑制该信息传播的目的.微信上,用户阅读过或分享过的文章如果被鉴定为谣言,那么用户将会收到来自“微信辟谣助手”小程序的提醒.然而,会对个人或企业造成不良影响的负向引导性信息往往不会受到社交网络平台的关注.例如,某品牌手机某一系列的个别产品曾经出现过绿屏的现象,这个问题不是普遍发生的,却引发大量用户在社交平台上发布相关负向言论,给该品牌造成了较大的负面影响.社交网络平台并不会针对这种情况提供解决方案,因而会给个人或企业带来很大的困扰.
1 研究现状
由于社交网络的快速发展,国内外已经对社交网络中的信息传播预测与抑制进行了广泛研究,主要包括了信息转发预测、信息传播模型以及信息传播抑制3个方面.有关信息传播预测与抑制的相关工作介绍为:
在社交网络中,转发行为是信息传播的主要形式,不少学者对社交网络中的转发行为进行了研究.目前转发预测相关研究按照任务类别可以分为3种:预测转发对象[1],即预测用户最有可能转发的Top-N条博文;预测转发时间[2],即预测用户转发给定博文的时间;预测转发行为[3-5],即预测用户是否转发给定博文或转发给定博文的概率.本文聚焦于预测用户转发行为,从而为之后的特定信息抑制提供基础.在预测用户转发行为方面,文献[3]提出了一个基于影响局部性函数的逻辑回归模型,综合考虑了粉丝数、相互关注数、注册时间等特征;文献[4]提出了一个基于注意力的深度神经网络来整合上下文和社交信息,该模型主要考虑的因素有微博作者特征、微博文本特征、待预测用户特征和用户兴趣特征;文献[5]提出了一种基于上下文感知、联合矩阵-张量分解的转发预测模型,综合考虑了用户、博文和影响力3个维度信息.
目前已有大量的文献对社交网络中的信息传播模型进行研究,基于网络中传播的信息数量可以分为单一信息传播模型和多信息竞争传播模型两大类.现有的单一信息传播模型主要可以分为3个方向:基于个体状态的传播模型、基于网络结构的传播模型以及基于信息特性的传播模型.其中,基于个体状态的传播模型主要有传染病模型,如SI模型[6]、SIR模型[7]等以及它们的改进模型:Maki-Thompson模型[8]等;基于网络结构的传播模型主要有线性阈值模型和独立级联模型[9]以及基于这2个模型的各类改进模型;基于信息特性的传播模型主要是根据特定信息源和信息传播平台建立的模型.同时,也有一些学者研究了多信息竞争传播模型.Tzoumas等人[10]从非合作博弈论的角度研究了2条信息的竞争传播过程,并通过扩展线性阈值模型对2条信息的竞争传播过程进行建模;Liu等人[11]扩展了SIR模型,提出了敏感-迟疑-感染-移除(sensitive-hesitate-infection-remove, SHIR)模型来研究2条信息的竞争传播过程;曹玖新等人[12]针对多条相似信息的竞争传播问题,提出了基于竞争的线性阈值扩展模型,模型中考虑到了不同信息的主题分布的不一致性.已有研究针对不同的竞争传播应用场景对传统的传播模型进行了扩展,然而现有研究大多没有同时考虑到不同信息在网络中传播的起始时间的不同以及用户对于权威账户和普通账户发布的信息的信任程度的差异.
现有的信息传播抑制相关研究可分为2个主要方向:1)通过去除网络中的部分边或节点来阻断特定信息的传播;2)通过选取网络部分节点传播与特定信息内容相反的信息来抑制特定信息的不良影响.文献[13]提出了一种基于贪心策略的方法来移除网络中的部分连边,从而抑制信息传播;文献[14]提出了一种贪心算法来选取网络中部分未激活节点进行阻断以最小化最终被特定信息激活的节点数量;Yan等人[15]基于独立级联模型,提出了一个谣言传播模型,并采用改进了的贪心算法来提高选取需阻断节点的效率;Nguyen等人[16]通过找到一组具有高度影响力的节点作为正确信息影响节点,来限制不良信息在整个网络中的传播,并给出了几种选取正确信息影响节点的贪心算法和启发式算法;Tong等人[17]提出了一个随机算法来选取正确信息影响节点集合以节约运行时间.
然而,现有研究大多没有使用真实社交网络上的信息传播数据.尽管有些研究是基于真实的社交网络拓扑结构,但是具体的信息传播与抑制过程完全使用仿真的方式,缺乏真实性.
本研究的主要贡献包括4个方面:
1) 基于真实的新浪微博数据进行实验,更客观地证明了本文模型的合理性以及算法的有效性;
2) 提出了不依赖于传播模型的独立信息转发预测机制,并通过实验筛选出了对于转发预测最有效的特征组合;
3) 考虑到真实应用场景下,用户的初始状态以及状态转化方式与传统的竞争影响力传播模型的不同,提出了异步信息不平等竞争传播模型;
4) 为个人、企业澄清与自身相关的不良信息提供了解决的方案.
2 基于机器学习的信息传播预测模型
在社交网络这一特定场景下,信息传播的过程是由不同用户的转发行为所构成的.因此,本节将宏观的信息传播预测问题转化为微观的用户转发预测问题.可将问题具体定义为:给定用户u与微博w,预测用户u转发微博w的概率puw.
基于该问题定义,本文提出了不依赖于传播模型的独立信息转发预测(independent information forwarding prediction, IIFP)机制:首先进行多维度特征提取,然后将特征输入到合适的分类器中训练分类模型以进行信息转发预测.
在特征提取阶段,需要综合考虑可能对转发行为有影响的因素.本研究从4个维度进行特征选取:特定信息微博维度、用户维度(包括待预测用户和特定信息微博作者用户)、待预测用户与特预测微博作者的相似程度、待预测用户历史微博与特定信息微博的相似程度.在这4个维度中选取的具体特征如表1所示,本文将在实验部分对不同特征的贡献进行对比.
特征提取之后,便可训练分类器.本研究采用Lightgbm分类器[18]对用户转发特定信息微博的概率pv进行预测,该分类器是梯度提升决策树(gradient boosting decision tree, GBDT)的一种优化,具有能够直接处理类别特征、运算速度快、分类效果好等优点,并且支持并行和大规模的数据处理.Lightgbm是一种集成模型,理论上会比普通的单一模型效果好,实验部分也会对Lightgbm与其他分类器的综合性能进行对比.
3 异步信息不平等竞争传播模型
本节提出了异步信息不平等竞争传播模型(asynchronous information unequal competition propagation model, AIUCP)作为特定信息与免疫信息的竞争传播机制.
3.1 概念定义
本节首先明确相关概念定义:
定义1.社交网络
本文中社交网络用有向图G(V,E)表示,其中V为节点集合,即社交网络中的用户集合,E为有向边集合,即社交网络中的用户间关注关系集合.具体来说,对用户u,v∈V,若存在euv∈E,则表示用户u被用户v关注,此时用户u为用户v的内邻居节点,用户v为用户u的外邻居节点.
定义2.传播子图
在独立级联模型下,影响力的传播是一个随机的过程,信息经过一次完整传播后,网络G中被该信息影响的节点构成的子图称为网络G的一个传播子图g.
定义3.特定信息
特定信息为可能对某些群体造成不利影响的言论,其中包含谣言、不实信息、有恶意导向性的舆论等,在社交网络中被转发传播会对社会或者某类用户产生不利影响.
定义4.免疫信息
免疫信息是与特定信息内容语义相反的信息,一般由被认证为权威机构的微博用户发布,将其投入社交网络中可以抑制特定信息的传播.
定义5.抑制效果
设被特定信息激活的节点的状态是状态A,被免疫信息激活的节点的状态是状态B,初始特定信息传播节点集合是IA,选取的免疫信息节点集合是IB.σ(IA,IB)表示已知初始状态A节点集合为IA的情况下,种子节点集合IB所能影响的节点个数,即特定信息传播抑制效果.
3.2 传播场景特殊性
在本文的研究场景下,特定信息与免疫信息在社交网络中共同传播,与传统的竞争影响力传播有一定的相似.然而,该场景下节点的行为状态与转化方式有所不同,具体表现在:
1) 免疫信息在特定信息传播了一定时间后才会被投放.因此,初始状态下只有部分节点处于已被特定信息激活的状态,其他节点均处于未激活状态;
2) 免疫信息通常由权威账户发布,其发布内容具有天然的优先可信度.因此,当某一节点同时接收到特定信息和免疫信息,该节点更倾向于被免疫信息激活.同时,被特定信息激活的节点仍有可能被免疫信息激活,但是被免疫信息激活的节点状态不会再发生改变.
3.3 用户状态与用户间影响概率
在异步信息不平等竞争传播模型下,用户分为4种状态:1)状态A.相信特定信息并转发,即被特定信息激活;2)状态B.相信免疫信息并转发,即被免疫信息激活;3)状态N.尚未看到特定信息或免疫信息;4)状态O.对特定信息和免疫信息都不感兴趣无应对行为.其中,状态O的用户可作为无关节点直接去除.初始状态下,有一部分节点已处于被特定信息激活的状态为状态A,其余节点均为状态N.
本文在第2节中,通过独立信息转发预测机制预测用户u转发微博w的概率puw.本节中,微博w是特定的,因此将用户u转发特定微博的概率简写为pu.本文第2节提出的机制在预测过程中并不考虑用户看到信息的途径,因此进一步考虑用户间相似度,以获取用户v转发特定上游用户u原创或转发的信息的概率,即用户间的影响权重p(u,v).具体计算公式为
p(u,v)=pv×simu,v,
(1)
其中,pv为用户v转发特定信息微博的概率,simu,v为用户u与用户v的相似度,该相似度将采用Jaccard[19]相似度计算公式从关注列表的相似程度、粉丝列表的相似程度、标签的相似程度、省份是否相同、城市是否相同以及关注关系6个角度来计算.
3.4 信息传播过程
异步信息不平等竞争传播模型的信息传播过程描述具体分为4个步骤:
1) 在t=0步时,已有部分节点处于被特定信息激活的状态A,此时,在未激活的节点集中选取种子集合,为它们赋予状态B;
2) 在第t步时,在时间步t-1状态为激活状态的节点u尝试以传播概率p(u,v)激活它的外邻居节点v.如果一个节点被多个状态的多个节点影响时,分为3种情况进行讨论:
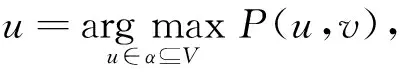
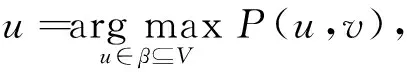
③ 当节点v的状态为状态B时,节点v的状态不会发生改变;
3) 若节点v在第t步被激活,那么它将在第(t+1)步尝试激活它的邻居节点;
4) 当没有节点可以再被激活时,传播结束.
4 社交网络特定信息抑制
4.1 问题定义
已知社交网络G(V,E),节点u影响节点v的概率为p(u,v),特定信息影响的初始节点集合为IA.要求找到大小为k的免疫信息种子节点集合IB,使得免疫信息种子节点集合IB所能影响的节点个数最多.
4.2 特定信息抑制影响最大化目标函数
基于4.1节中的问题定义,给出特定信息抑制影响最大化目标函数为
(2)
其中,σ(IA,IB)表示已知初始状态A节点集合为IA的情况下,种子节点集合IB所能影响的节点个数,Pr(g)表示传播子图g出现的概率,σg(IA,IB)表示在传播子图g中给定集合IA的情况下,种子节点集合IB所能影响的节点个数.
定义传播子图g的出现概率[20]Pr(g)为
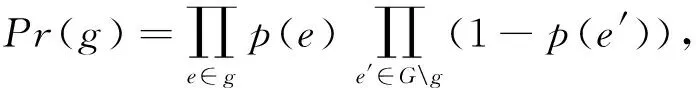
(3)
其中,e和e′均表示社交网络G中的一条有向边,p(e)和p(e′)分别表示边e和e′属于子图g的概率.
4.3 目标函数的数学性质证明
本节对目标函数的单调性和子模性进行证明.
1) 单调性证明
首先,根据单调性的定义5来证明抑制影响最大化的目标函数具有单调性.
定义5.如果对于所有子集S⊆T⊆V,有f(S)≤f(T),则集合函数f:2V→R是单调的.
引理1.如果对于所有子集I1⊆I2⊆VB有σ(IA,I1)≤σ(IA,I2),则抑制影响最大化目标函数σ(IA,IB)是单调的.其中,VB=VIA为免疫信息种子节点的可选集合.
证明:
根据式(3)
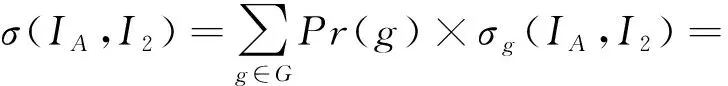
其中,δg(IA,u)表示在网络中某个传播子图g已有特定信息节点集合IA传播的情况下,免疫信息种子节点u能够影响激活的节点集合.
由此可推出
σ(IA,I1)≤σ(IA,I2),
即抑制影响最大化目标函数具有单调性.
证毕.
2) 子模性证明
定义6.如果对于所有子集S⊆T⊆V和所有节点v∈VT,有f(S∪{v})-f(S)≥f(T∪{v})-f(T),则集合函数f:2V→R是子模的.
引理2.如果对于所有子集I1⊆I2⊆VB和所有节点v∈VBI2,有:
σ(IA,I1∪{v})-σ(IA,I1)≥
σ(IA,I2∪{v})-σ(IA,I2),
则抑制影响最大化目标函数σ(IA,IB)是子模的.其中,VB=VIA为免疫信息种子节点的可选集合.
证明:
根据式(2),
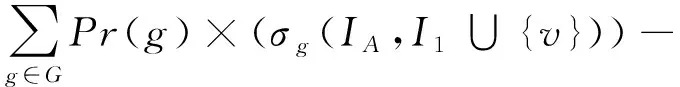
由容斥原理,上式等价于
|δg(IA,I1∩{v})|-|δg(IA,I1)|)=
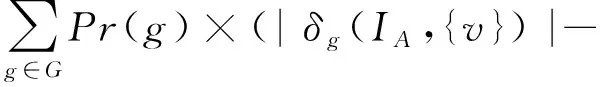
同理可推出:
σ(IA,I2∪{v})-σ(IA,I2)=
σ(IA,{v})-σ(IA,I2∩{v}).
由I1⊆I2可推出:
I1∩{v}⊆I2∩{v}.
由引理2,目标函数的单调性可得:
σ(IA,I1∩{v})≤σ(IA,I2∩{v}),
故:
σ(IA,{v})-σ(IA,I1∩{v})≥
σ(IA,{v})-σ(IA,I2∩{v}).
即
σ(IA,I1∪{v})-σ(IA,I1)≥
σ(IA,I2∪{v})-σ(IA,I2).
证毕.
由此可得,抑制影响最大化目标函数具有子模性.
4.4 抑制影响最大化贪心算法
根据Nemhauser等人[21]于1978年提出的理论,若目标函数满足单调性和子模性,则采用贪心法每一轮选取边际影响力最大的节点,共选取k个种子节点集合IB,可以得出该影响传播问题最优解的1-1e近似解.
基础贪心算法的计算量大、时间复杂度高.因此,本文基于具有成本效益的惰性前向选择(cost-effective lazy forward selection, CELF)算法的基本思想,改进了传统的贪心算法,提出了在本文模型下的异步信息抑制传播贪心算法(asynchronous infor-mation suppression propagation greedy algorithm, AISPG)来选取免疫信息种子节点集合.算法首先计算每个没有被特定信息影响的节点的边际影响力,将边际影响力最大的节点加入免疫信息种子集合IB,接着进行k-1轮循环,每轮基于CELF思想选取边际影响力最大的节点加入免疫信息种子集合.具体算法步骤如算法1所示:
算法1.异步信息抑制传播贪心算法.
输入:社交网络G(V,E)、信息从用户u传播到用户v的概率p(u,v)、特定信息影响的初始节点集合IA、种子节点数目k;
输出:免疫信息种子集合IB.
① 初始化IB为空集,大顶堆HB为空堆;
② foru∈VIA
③ 计算Δ(u)=σG(u|IA,∅);
/*边际影响力*/
④ 将Δ(u)插入HB;
⑤ end for
⑥ 更新IB←IB∪{HB.peek};
⑦ while |SB| ⑧ foru∈V(IA∪IB) ⑨u.status=false; ⑩ end for 针对节点规模较大的社交网络,可以采用启发式算法来选取免疫信息种子节点集合以进一步降低计算量.因此,基于本文提出的传播模型,提出了异步信息抑制传播启发式算法-简版(asynchronous information suppression propagation heuristic algorithm _easy, AISPH_E).AISPH_E算法综合考虑了节点本身的特性以及其与邻居节点的影响关系,给出了计算单个节点u的影响力公式为 (4) 其中,pu表示节点u的转发概率,p(u,v)表示节点u与节点v间影响权重,|Nout(u)|表示u的出度节点数量,|N(u)|表示u的邻居节点数量.AISPH_E算法每次选取影响力σ(u)最大的节点加入免疫信息种子集合,直到选出k个节点,具体流程如算法2所示: 算法2.异步信息抑制传播启发式算法-简版. 输入:社交网络G(V,E)、信息从用户u传播到用户v的概率p(u,v)、特定信息影响的初始节点集合IA、种子节点数目k; 输出:免疫信息种子集合IB. ① 初始化IB为空集,大顶堆HB为空堆; ② foru∈VIA ③ 计算u的影响力σ(u); ④ 将σ(u)插入HB ⑤ end for ⑥sort(HB) ⑦ while |IB≤k| ⑧ ifHB.peek!=NULL ⑨ 更新IB←IB∪{HB.peek}; ⑩HB.pop; 为了避免选取的种子节点的邻居节点重合度过高,本文进一步提出异步信息抑制传播启发式算法(asynchronous information suppression propagation heuristic algorithm, AISPH),对AISPH_E算法中的节点影响力计算方式进行改进,改进后的节点影响力计算为 (5) 其中,pu表示该节点的影响权重,p(u,v)表示节点u,v间影响权重,N(u)表示u的邻居节点集合,Nout(u)表示u的出度节点集合,S表示已选择的种子节点集合. 本节将在实验室高性能服务器计算集群上对独立信息转发预测与社交网络特定信息传播抑制进行分布式并行实验.单个计算节点的具体参数为:Inter Xeon Gold 6132. 本文主要抓取2018~2019年内微博的真实数据以展开实验,具体步骤为: 首先,从微博社区管理中心选取经过平台验证确定为不实信息的微博,作为我们需要抑制的特定信息;接着,根据不实信息微博爬取参与过转发的用户,按时间顺序还原不实信息微博的传播过程,保留转发链完整的不实信息微博;然后,将参与过转发的用户作为种子节点,通过爬虫爬取每个用户的各项个人信息、近期发布的微博以及其好友关系;最后,通过每个节点的被关注关系向外拓展,获取带有好友关系的社交关系网. 经过初步筛选,共获取2 500条原创特定信息微博,涉及861 419名用户,其中连边有3 442 626条.对微博的转发量情况进行统计,如图1所示: Fig. 1 Microblog forwarding histogram图1 微博转发量直方图 从图1中可以看出,微博的转发量主要集中20~100之间.因此,进一步选择转发量在20~100之间的1 180条微博,根据参与这些微博转发过程的用户的相关信息构建数据集. 由于微博文本的规范性较差,获取的数据集需要进行文本规范化处理,即通过正则表达式过滤微博文本中的标点符号和表情符号. 本节将对转发预测中不同特征的贡献以及不同分类器的表现进行对比,并在选定特征集与分类器后,与其他文献中的算法进行对比. 5.2.1 评价指标 转发预测问题实际上是一个二分类问题,而评价分类器性能的常用指标有:准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1值(F1-score). 根据分类器的输出结果和真实标签,可以将预测结果分为4种:1)真正例(true positive,TP),表示正样本被分为正样本的数量;2)假正例(false positive,FP),表示负样本被分为正样本的数量; 3)真负例(true negative,TN),表示负样本被分为负样本的数量;4)假负例(false negative,FN),表示正样本被分为负样本的数量.因此,准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1值(F1-score)可以定义为: (6) (7) (8) (9) 对于输出概率的分类器需要定义阈值来确定正负样本,在计算这4个指标时,阈值选择的不同会带来不同的结果.因此,本研究将进一步使用曲线下面积(area under curve,AUC)来评价输出概率的不同分类器的性能.AUC指的是受试者工作特征(receiver operating characteristic, ROC)曲线下的面积.ROC曲线的横坐标为假正率(false positive rate,FPR),纵坐标为真正率(true positive rate,TPR),该曲线代表了一个分类器在不同阈值下的分类效果.其中,FPR与TPR的计算公式为: 5.2.2 数据准备 进行转发预测实验前,需要在5.1节中获取的微博数据集的基础上构造转发预测数据集.具体来说,在5.1节获取的微博数据集中,将每条微博与转发过该微博用户标注为正样本,每条微博与未转发过该微博用户标注为负样本. 转发微博的用户远少于不转发微博的用户,因此,为了保证正负样本平衡,本研究随机采样10 000条正样本和10 000条负样本构成转发预测数据集. 实验时,随机将转发预测数据集按8∶2的比例分成2部分:训练数据和测试集.模型在训练数据上训练时,使用5折交叉验证. 5.2.3 实验方法与结果分析 实验主要分为3部分:各类特征对于转发预测的效果对比、不同的分类器在相同特征集上的效果对比以及选定特征集与分类器后,与其他文献中的算法进行对比. 1) 各类特征对于转发预测的效果对比 实验对比的特征维度包含4个: ① 信息微博维度.分别用TF-IDF,word2vec,BERT生成微博文本的向量化特征,与该维度其他特征组成特征集合,分别表示为:I-TF-IDF,I-word2vec,I-BERT; ② 用户维度(包括待预测用户和信息微博作者用户).将待预测用户和微博作者的维度特征集合表示为Ⅱ; ③ 待预测用户与信息微博作者的相似程度维度.将待预测用户和微博作者的相似度特征集合表示为Ⅲ; ④ 待预测用户历史微博与信息微博的相似程度维度.将分别用TF-IDF,word2vec,BERT这3种方法生成的用户历史微博与当前微博的相似度特征集合表示为IV-TF-IDF,IV-word2vec,IV-BERT. 为了对比各组特征的效果以及TF-IDF,word2vec,BERT提取文本向量特征的效果,每次实验仅仅使用其中一类特征,分类器采用Lightgbm,具体的实验结果如表2所示: Table 2 Comparison of Prediction Results on Variousfeatures表2 各类特征预测效果对比 由表2可知,在本文提出的4个维度的特征中,维度③待预测用户与信息微博作者的相似程度维度特征在当前数据集上的效果最好,准确率、精确率、召回率和F1值均是最高的;维度①信息微博维度下特征效果次之,平均F1值约为0.767;接着是维度②用户维度(包括待预测用户和信息微博作者用户)特征和维度④待预测用户历史微博与信息微博的相似程度维度特征.维度①信息微博维度下,采用TF-IDF,word2vec以及BERT提取句子向量用作文本特征时,表现相差不大;维度④待预测用户历史微博与信息微博的相似程度维度下,采用TF-IDF,word2vec以及BERT生成的用户历史微博与当前微博的相似度特征时,TF-IDF表现最好.因此,本文后续的实验统一采用TF-IDF,则维度①和维度④可以简化表示为Ⅰ和Ⅳ. 将各维度特征组合后进行实验,结果如表3所示.采用第Ⅰ,Ⅲ维度特征组合时,Precision最高;采用第Ⅰ,Ⅱ,Ⅲ维度特征组合时,Accuracy最高;采用第Ⅱ,Ⅲ,Ⅳ维度特征组合时,Recall最高;采用第Ⅰ,Ⅱ,Ⅲ,Ⅳ维度特征组合时,F1值最高.总体来看,使用第Ⅰ,Ⅲ维度特征组合的效果与同时使用四维度特征的效果相差不大.因而在实际应用时,为提升整体效率,选择使用第Ⅰ,Ⅲ维度特征组合. Table 3 Comparison of Performance of Multi Class Feature Combinations表3 多类特征组合效果对比 Lightgbm模型在训练结束后,会输出每个特征的重要性,反映特征在模型学习过程中的贡献程度.重要性越高,则该特征对于转发预测越有效.图2展示了使用Ⅰ,Ⅲ类特征组合时,特征重要性的排名. Fig. 2 Feature importance ranking when using type Ⅰ and Ⅲ features图2 使用Ⅰ,Ⅲ类特征时特征重要性排名 从图2中可以看到,用户与作者的城市是否相同、用户与作者关注列表的相似度、微博的平均TF-IDF是最为有效的3个特征. 2) 不同的分类器在相同特征集上的效果对比 在使用Ⅰ,Ⅲ维度特征组合的前提下,对单一模型:感知机(Perceptron)、逻辑回归(Logistic Reg-ression, LR)、支持向量机(support vector machine, SVM);集成模型:AdaBoost、随机森林(Random Forest, RF)和Lightgbm共6种分类器进行了对比.实验结果如表4所示: Table 4 Performance Comparison of Each Classification Model表4 各分类器的效果对比 从表4可以看出,除Perceptron外的5种分类器的分类效果基本相近,这说明使用Ⅰ,Ⅲ维度特征组合,可以很好地区分正负样本.从表4可以进一步看出,Lightgbm在Accuracy,Precision和F1值上的表现是最佳的,尽管在Recall上的表现不是最好的,但是由于F1值是对Precision和Recall的整体评价,而Lightgbm取得了最高的F1值,所以综合来看Lightgbm是性能最佳的分类器. 输出是概率的4种分类器对应的ROC曲线如图3所示,对应的AUC值如表5所示. Fig. 3 ROC value comparison of each classifier图3 各分类器的ROC曲线对比 Table 5 AUC Value Comparison of Each Classifier表5 各分类器的AUC值对比 可以看出Lightgbm的AUC最高,其次是Random Forest和AdaBoost,最后是LR.Lightgbm的表现与预期相符合,是综合性能最佳的分类器. 3) 与现有转发预测模型的对比 为了进一步说明本文所提出模型的有效性,将该模型与现有研究中的转发预测模型进行对比.根据本文实验,将基于Ⅰ,Ⅲ类特征组合的Lightgbm分类器与相关领域现有研究进行对比. 对比模型如下: Zhang等人[3]提出的模型:一个基于影响局部性函数的逻辑回归模型.模型中使用的特征有粉丝数、相互关注数、注册时间、性别、是否认证、用户偏好于主题间的KL散度、用户活跃邻居数、距离微博发布时间的间隔、结构影响力以及成对影响力. SUA-ACNN[4].一个结合了卷积神经网络与注意力机制的模型.该研究微博转发预测问题中,主要考虑的因素有微博作者特征、微博文本特征、待预测用户特征和用户兴趣特征,并对它们进行进一步的细化.其中,在用户兴趣特征提取步骤中加入了注意力机制. RCMTF[5].一个基于上下文感知、联合矩阵-张量分解的转发预测模型.该模型基于网络结构、消息内容和历史交互,设计了用户相似度、消息相似度和成对影响的3个上下文因子矩阵. 与现有转发预测模型的对比结果如表6所示.其中,本文的IIFP模型在4个评价指标上均取得了了最好的表现.Zhang等人[3]提出的模型与本文的思路相似,同样是基于特征工程的机器学习方法,但实验结果不及本文的模型,说明本文选取了更有效的特征.SUA-ACNN[4]模型作为一个深度学习模型并没有在本研究数据集上表现出更好的效果,可能由于深度学习往往需要海量数据,而本文数据集的微博转发样本较少,导致深度学习无法自动提取有效特征.基于矩阵分解的RCMTF[5]模型在本研究数据集上同样未能超越本文模型的性能,分析发现微博中存在一定数量的中文词汇缺少预训练的中文词向量,导致矩阵分解中基于词向量计算的相似度矩阵不够准确,同时本研究数据用户数量较大,造成矩阵十分稀疏,导致矩阵分解模型的性能未能达到原论文中的效果. Table 6 Comparisonbetween IIFP and Existing Models表6 IIFP与现有模型的对比 本节将分别进行特定信息单独传播实验与特定信息与免疫信息共同传播实验,并将本文提出算法与多种已有算法在运行时间和抑制影响力2个方面进行对比. 5.3.1 评价指标 通常情况下,影响力最大化研究相关的评价方式有2种:影响范围以及运行时间.通过蒙特卡洛模拟的方式可以仿真信息传播的影响范围,多次求解取平均可以得出接近真实的影响范围,而算法能否高效地选择符合要求的种子节点集合则体现在算法的运行时间上.于是,本研究将影响范围和运行时间作为评价算法效果的指标. 传统的蒙特卡洛模拟传播模型中,节点只能被激活一次,一旦激活状态不再发生改变.本研究提出的传播影响模型中,一个节点被激活为状态A后,仍可能被状态B的节点激活.因此在本文模型下的蒙特卡洛模拟算法如算法3所示: 算法3.计算种子集合影响范围的蒙特卡洛模拟算法. 输入:社交网络G(V,E)、每条边上的概率p(u,v)、特定信息影响集合IA、种子集合IB; 输出:影响范围resultA. ① 已被激活的用户状态集合activeA←IA,activeB←IB; ② foru∈activeA,v∈activeB ③ foru′∈Inf(u)activeA∪activeB ④ ifu.active(u′)= =success ⑤ 更新activeA←activeA∪{u′} ⑥ end if ① ② 2条特定不实信息来自微博社区管理中心(https://service.account.weibo.com) ⑦ end for ⑧ forv′∈Inf(v)activeB ⑨ ifv.active(v′)= =success ⑩ 更新activeB←activeB∪{v′} 将算法3的蒙特卡洛模拟重复实验10 000次,得到的影响范围取平均值,即可获得种子节点集合的影响范围,从而评价算法的有效性. 5.3.2 数据准备 在5.1节中获取的1 180条特定信息微博的基础上,随机抽取30%作为实验对象进行特定信息单独传播实验与特定信息与免疫信息共同传播实验.为展示特定信息单独传播时的影响范围变化,选取2条特定不实信息展示其传播过程: 特定不实信息(1):关于三峡工程发电收入的归属①. 特定不实信息(2):关于某轮奸犯仕途升至县长的网络谣言②. 5.3.3 对比算法 为了验证本文提出的算法的有效性,现将本文提出算法与多种已有算法进行对比并根据评价指标来分析结果,参与对比的算法有本文提出的AISPG和AISPH,AISPH_E以及Random算法、Proximity算法、Degree算法、Greedy算法. 参与对比的7个算法介绍: 1) AISPG算法.本文提出的异步信息抑制传播贪心算法; 2) AISPH_E算法.本文提出的异步信息抑制传播贪心算法-简版,不考虑选取的种子节点存在重复邻居节点的情况; 3) AISPH算法.本文提出的异步信息抑制传播贪心算法; 4) Random算法.随机选取种子节点集合; 5) Proximity算法.一种竞争影响最大化的算法,该算法每次都在需要被抑制的特定信息状态的节点的邻居节点中选取免疫信息种子节点; 6) DegreeHeuristic算法.度启发式算法是一种经典的启发式算法,按照每个节点连边的数量对节点进行降序排列,选择种子节点集合. 7) Greedy算法.计算每一个节点的边际影响力,每一次选取当前状态下边际影响力最大的节点加入种子节点集合. 5.3.4 实验结果 1) 特定信息单独传播实验 本文为了研究免疫信息的抑制效果,首先考虑网络中未注入免疫信息的情况,观察网络中已有特定信息的传播规律和传播范围.经过10 000次蒙特卡洛模拟后,得到这些特定信息的平均影响范围为573 724.55.由此可知,在不进行抑制的情况下,特定信息可以自动得到广泛传播. 为了更好地展示特定信息的影响范围变化,使用数据准备部分选取的2条特定信息展示其传播过程.选取的2条特定信息均已在网络中有一定范围的传播,实验中将该状态作为实验的初始状态.表7中反映了选取的特定信息的初始传播状态. Table 7 Number of Nodes Covered by Specific Information表7 特定信息已覆盖节点数 图4(a)、(b)分别体现了蒙特卡洛模拟下特定信息(1)、特定信息(2)在网络中的影响范围随步数变化的规律. 由图4可以看出,尽管2条特定信息在传播过程中的影响范围变化情况有所不同,但是最终均达到了很大的影响范围. 2) 特定信息与免疫信息共同传播实验 本文提出的AISPG和AISPH_E,AISPH以及Random算法、Proximity算法、Degree Heuristic算法、Greedy算法的运行时间的对比图如图5(a)所示,其中纵坐标表示对数形式的算法运行时间(ms),横坐标表示种子节点数(个).从图中可知,Greedy算法和AISPG算法的运行时间要远大于其他算法.为了能够更清晰地对比其他几种算法的运行时间,本文在图5(b)中展现了除2种贪心算法外,其他算法的运行时间对比,其中纵坐标表示线性的算法运行时间(ms),横坐标表示种子节点数(个). 由图5(a)可看出,Greedy算法运行时间会随着节点选取数量的增加而迅速增加并且远大于其他算法;由图5(b)可以看出,几种启发式算法的运行时间随着种子节点选取数量的增加基本呈线性增加. Fig. 4 The range of influence of a particular information in a network varies with the number of steps图4 特定信息在网络中的影响范围随步数变化 Fig. 5 Comparison of algorithm running time图5 算法运行时间对比 Fig. 6 Influence range comparison after suppression图6 抑制后的影响范围对比 本文提出的改进的贪心算法AISPG算法虽然运行时间也大于其他启发式算法,但是其运行时间随着种子节点选取数量的增加并没有明显增大,可见是对Greedy算法效率的有效改进. 特定信息与免疫信息在社交网络中共同传播的抑制影响力实验结果对比如图6所示.从图6可以看出,在本文提出的特定信息传播与抑制模型下,贪心算法选择的种子节点相比于启发式算法能达到更好的抑制效果.而本文提出的贪心算法AISPG能够在提高运行效率的前提下达到与传统的Greedy算法接近的抑制效果;本文提出的启发式算法AISPH和AISPH_E在算法效果方面虽然略逊于贪心算法,但时间复杂度低,更适用于在大型社交网络中选取免疫信息节点. 本文提出了不依赖于传播模型的独立信息转发预测机制以及适用于特定信息与免疫信息共同传播这一特殊场景的异步信息不平等竞争传播模型,并根据该传播模型提出了种子节点选取算法.实验验证,本文提出的转发预测模型以及种子节点选取算法具有合理性与有效性. 本文构建的独立信息转发预测机制考虑到了影响用户兴趣的固有特征.然而,用户的兴趣会随着时间不断变化.因此,在未来的研究中进行用户兴趣点建模时,可以考虑加入时序特征,从而更准确地挖掘用户兴趣的阶段性变化.除此以外,如何衡量用户在动态网络中的影响力也是值得进一步关注的问题. 作者贡献声明:曹玖新提出研究选题,给出研究思路,设计研究方案,终审论文;高庆清完善论文思路,设计实验,完成部分主实验,撰写论文;夏蓉清收集分析资料,完成部分主实验;刘伟佳归纳整理实验数据,校对论文;朱雪林完成对比实验部分;刘波给予论文思路上的指导.4.5 抑制影响最大化启发式算法

5 实验与分析
5.1 数据获取与预处理

5.2 独立信息转发预测实验
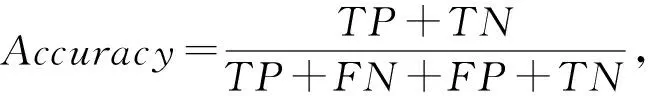
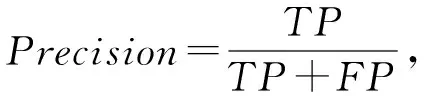
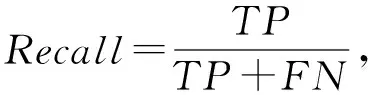
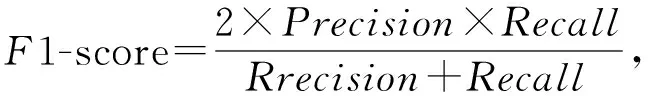
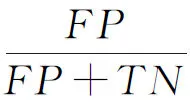
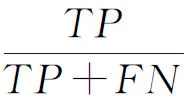


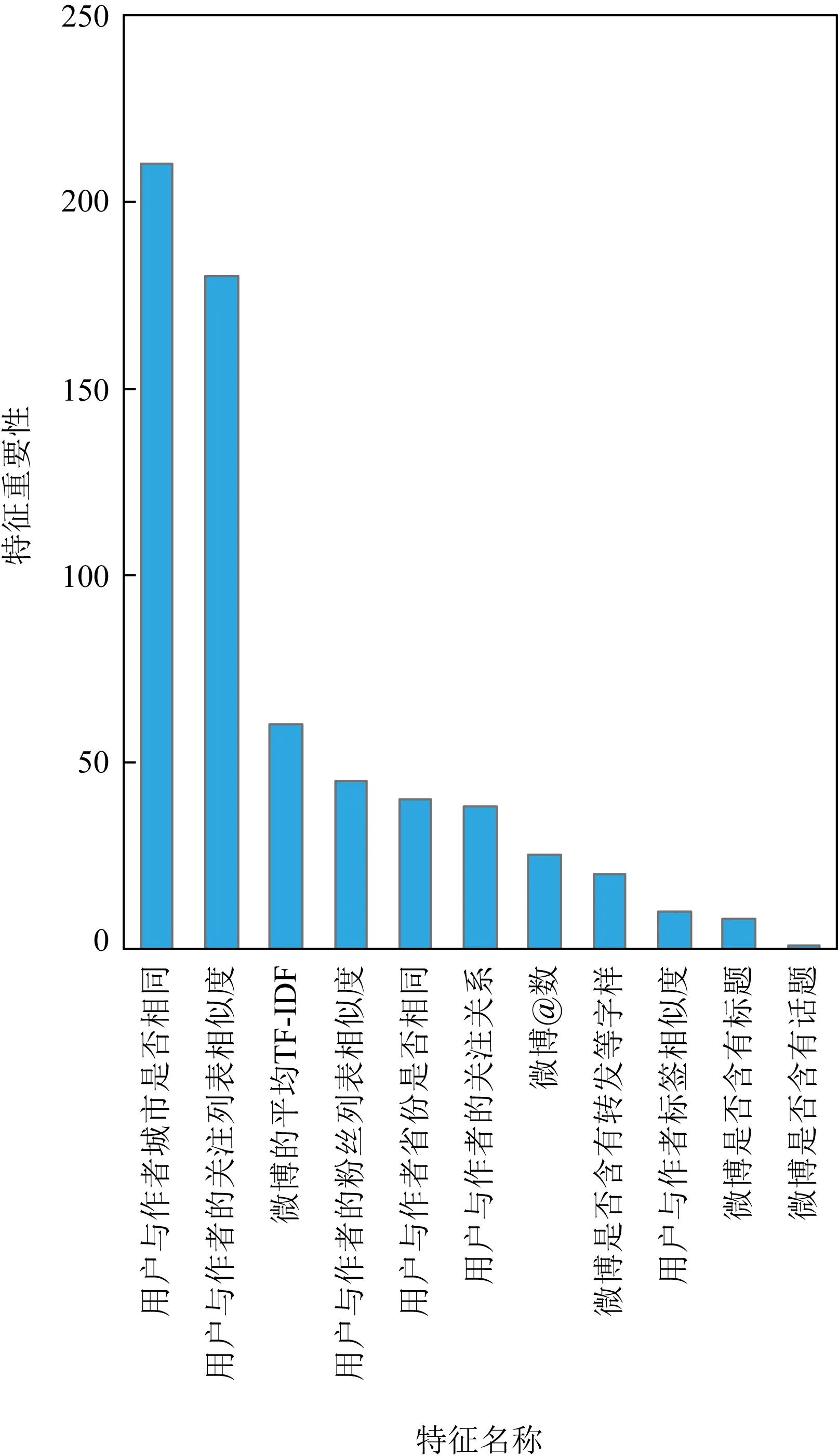
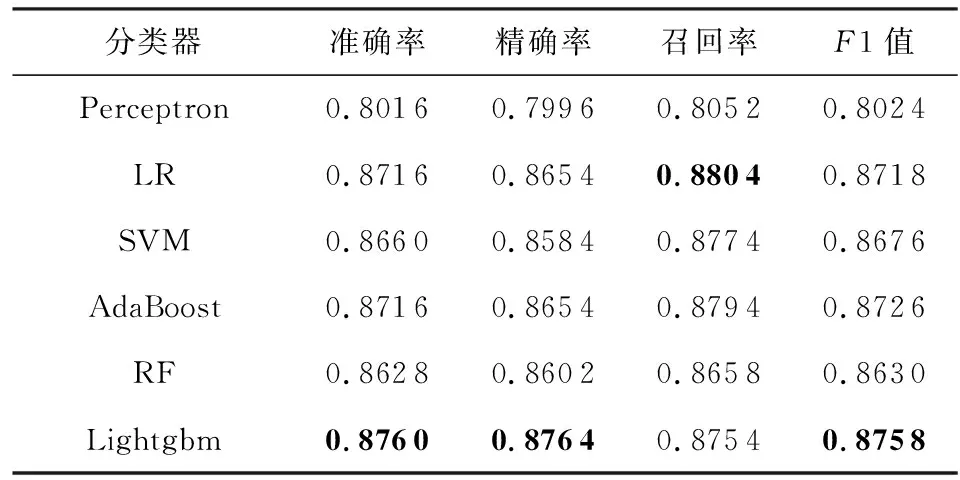
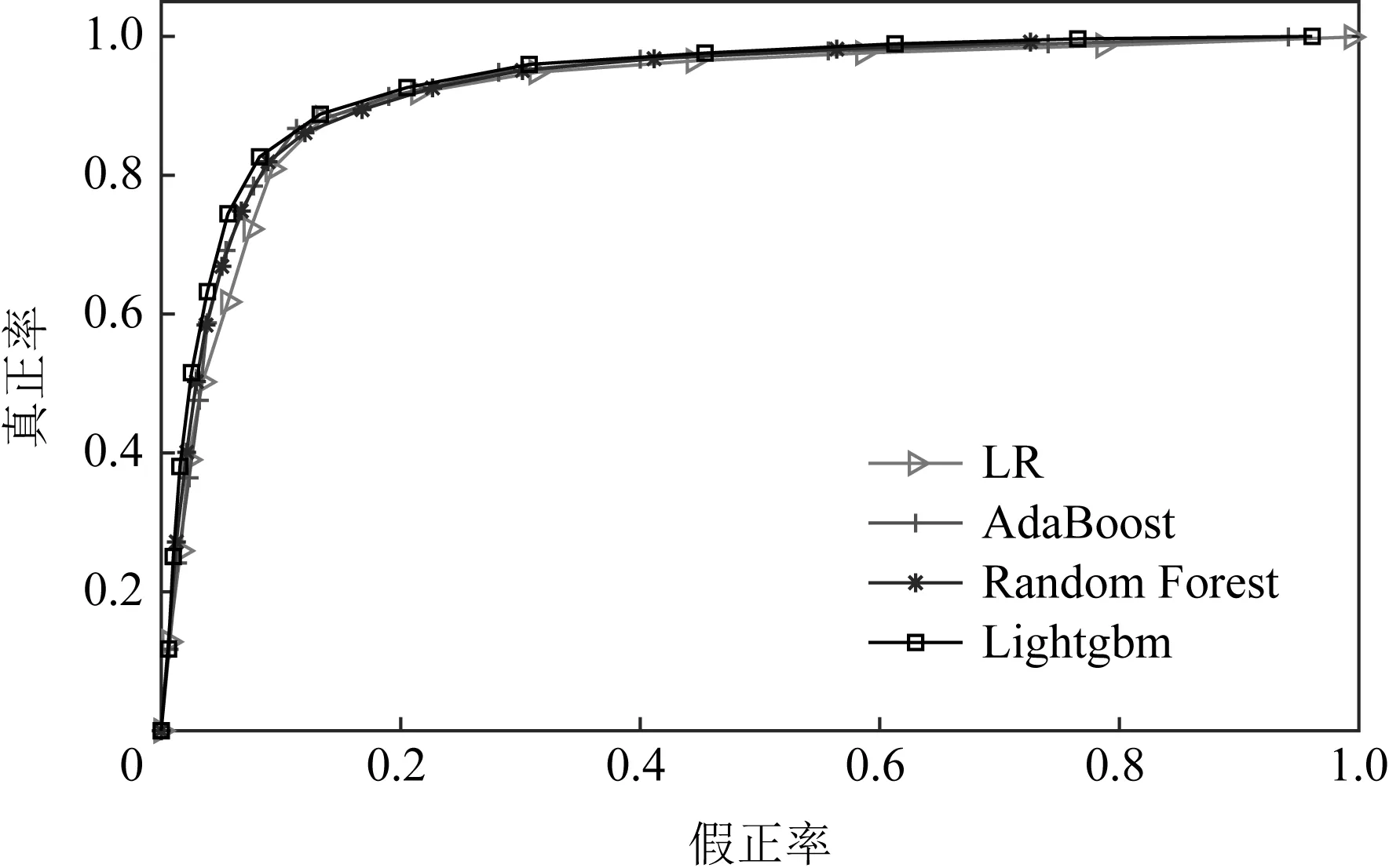


5.3 社交网络特定信息抑制实验




6 总结与展望
