云际环境下基于用户行为的软件安全研究
2021-07-22马杰
马杰

摘 要:随着云计算和大数据的高速发展,网络资源越来越丰富,计算机网络开始逐渐渗透到人们生活的各个领域。但是,随之而来的网络和软件安全问题日益严重,严重影响了云计算的发展。本文提出了一种基于用户行为的软件安全模型,通过分析网络流量和本地用户行为数据,实现对异常行为的检测。
关键词:云计算;软件安全;用户行为;异常检测
中图分类号:TP393.09文献标识码:A文章编号:1003-5168(2021)08-0007-03
Research on Software Security Based on User Behavior in Cloud Computing
MA Jie
(Henan College of Finance and Monetary,Zhengzhou Henan 451464)
Abstract: With the rapid development of cloud computing and big data, network resources are becoming more and more abundant, and computer networks have gradually penetrated into all areas of peoples life. However, the ensuing network and software security problems have become more and more serious, which has seriously affected the development of cloud computing. This paper proposes a software security model based on user behavior, which can detect abnormal behaviors by analyzing network traffic and local user behavior data.
Keywords: cloud computing;software security;user behavior;abnormal detection
随着科技的不断发展,云计算已从概念导入进入广泛普及、应用繁荣的新阶段,成为提升信息化发展水平、打造数字经济新动能的重要支撑。党中央、国务院高度重视以云计算为代表的新一代信息产业发展,发布了《国务院关于促进云计算创新发展培育信息产业新业态的意见》(国发〔2015〕5号)等政策文件。但随着云计算和大数据等新技术的广泛应用以及新型攻击方式的出现,传统软件安全面临着巨大挑战,严重影响了云计算等新技术的持续发展。在云计算平台中,资源的所有权和管理权被分离,催生很多新的安全威胁,尤其是当攻击由云内部用户发起的时候[1]。
传统的基于流量特征库的高级持续性威胁(Advanced Persistent Threat,APT)攻击检测与防御方法对于已知威胁(如已知漏洞或病毒木马程序的攻击)比较有效,但对于攻击特征未知、技术复杂以及持续时间长的APT攻击则无法进行有效检测与定位[2]。传统用户异常行为检测方法无法满足海量数据检测需求,对不断更新的异常行为和恶意软件无法快速做出响应,没有考虑用户行为管理等问题,导致异常检测的精度和稳定性都不足[3]。文献[4-5]提出了一种基于深度学习的网络异常行为检测方法,能够利用历史网络数据,建模并训练网络异常行为检测模型,进而實现快速的异常行为检测,但检测精度不高。
本文提出了一种云际环境下基于用户行为的检测模型,该模型通过实时分析网络流量并对本地用户行为进行数据挖掘,共同构建云际软件安全体系。
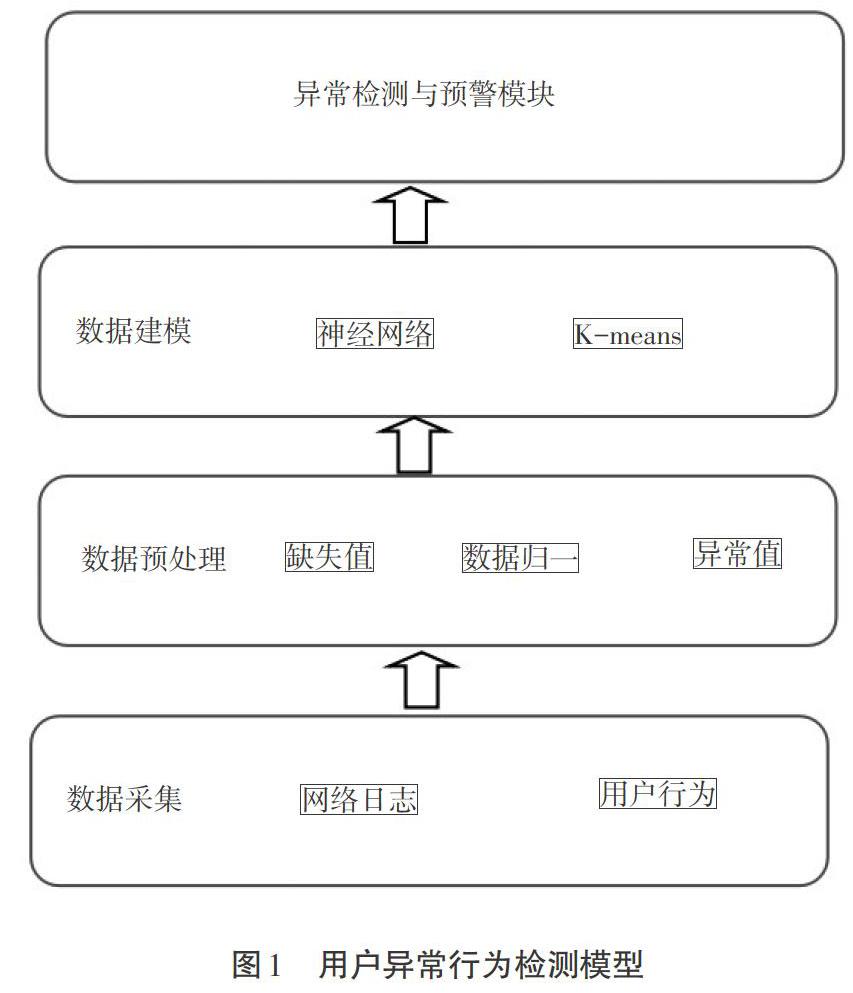
如图1所示,该检测模型主要包括数据采集模块、数据预处理模块、数据建模模块以及异常检测与预警模块。
1 数据采集
数据采集部分主要分为网络流量采集和本地用户行为数据采集。
网络流量分析是行之有效的手段,因为再高级的攻击都会留下网络痕迹,网络攻击者的行为和人们正常的网络访问行为不一样。首先通过Hadoop日志系统获取历史网络流量数据,包括源IP地址、目的IP地址、源端口、目的端口、协议、用户、时间、数据地址以及数据量等信息。
本地用户行为数据主要通过采集用户操作输入习惯,包括鼠标单击事件、鼠标双击事件、鼠标移动轨迹、鼠标滚动事件、键盘敲击事件、键盘特殊符号使用频率以及应用程序名称等。
2 数据预处理
数据的质量直接决定了模型预测和泛化能力的好坏。为了提高数据质量,人们要进行数据预处理,包括缺失值处理、异常值处理、噪声处理、数据归一化以及维度变换等。
在获取信息和数据的过程中,各类原因会导致数据丢失和空缺。异常值是数据分布的常态,处于特定分布区域或范围之外的数据通常被定义为异常或噪声。这些缺失值和噪声可以使用完整数据集中对应属性的平均值进行填充,也可以使用中位数填充。若变量的缺失率较高,覆盖率和重要性较低,则可以直接将变量删除。
噪声是变量的随机误差和方差,是观测点和真实点之间的误差。人们可以对数据进行分箱操作,等频或等宽分箱,然后用每个箱的平均数、中位数或者边界值代替箱中所有的数,起到平滑数据的作用。
为了进行归一化,人们可以对数据进行最大-最小规范化,将数据映射到[0,1]区间。
维度变换是将现有数据降到更小的维度,尽量保证数据信息的完整性,可以使用主成分分析(Principal Component Analysis,PCA)和因子分析(Factor Analysis,FA)进行降维处理。
3 数据建模
本文将采用深度神经网络(Deep Neural Networks,DNN)和K-means来构建异常检测模型,然后将预处理后的数据导入模型进行训练。
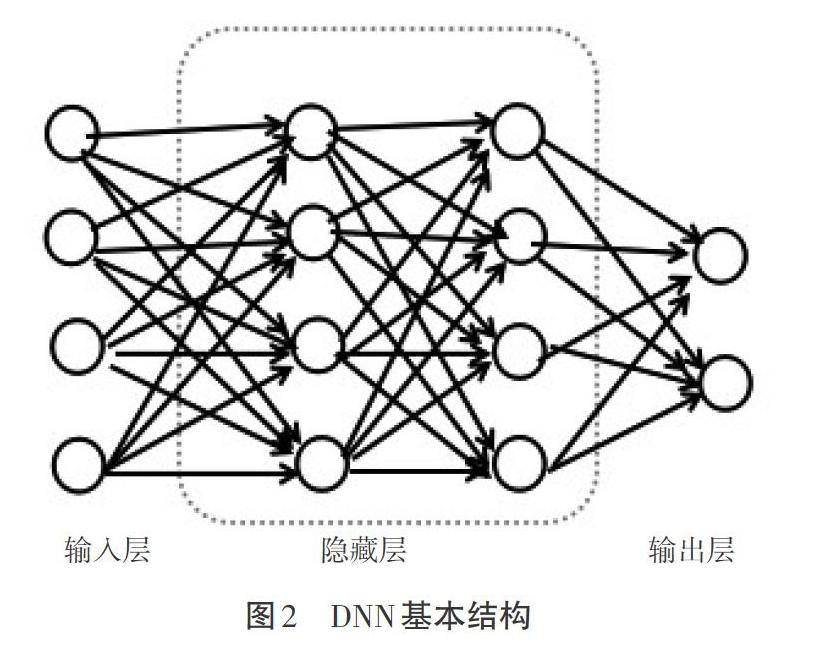
3.1 深度神经网络
DNN可以分为3层,分别是输入层、隐藏层以及输出层,基本结构如图2所示,其中隐藏层可以有多个。
算法过程如下:
将样本数据随机分为测试数据和训练数据,训练数据作为输入层,然后进行计算,计算公式为:
[y=w0x0+w1x1+…+wpxp+b] (1)
式中,[y]是输入特征[x0]到[xp]的加权求和,权重系数为[w0]到[wp]。
计算完加权求和后,再应用Sigmoid激活函数对结果进行非线性校正,将校正结果作为输入提交给隐藏层进行下一次计算,重复此过程直至输出层输出结果。
得到输出结果后,使用交叉熵损失函数度量预测值与真实值之间的差异程度,若误差不满足要求,则进行反向传播。若误差满足要求,则再使用测试集进行测试,直到准确率也达到要求,停止训练,否则从头重新计算。
在模型训练过程中,由于训练样本规模太大,为了加快训练速度,可以将数据分成N块分N次进行训练。完成训练后,DNN模型可以有效识别出网络流量中的异常行为,提高后续异常检测的适应性和准确性。
3.2 K-meams算法
云际环境下,因为不同户的操作习惯、工作内容、兴趣爱好以及访问内容不同,用户行为具有很大的差异性,异常行为很难预先界定,不适合使用监督学习算法。因此,本文采用聚类算法来解决本地用户行为的异常检测。
通常情况下,用户的正常操作行为和异常操作行为会有很大的差异,适合使用K-means算法进行聚类。K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法首先随机选取K个对象作为簇中心进行初始化,然后开始迭代计算,因此簇中心点的选择将直接影响算法的效率。
本文对K-means算法做了改进,过程如下:①输入样本数据,使用欧氏距离法计算各个样本之间的距离,然后选择距离最远的K个样本,作为初始的簇中心。②计算样本数据到达各簇中心的距离,并将样本归入距离最近的簇。③重新计算各簇的均值,得到新的簇中心。④根据新的簇中心再次将各样本数据归入距离最近的簇。重复步骤③和④,直至簇中心不再变化。经过模型训练之后,标出正常簇和各正常簇半径R,用于后续异常检测。
4 异常检测与预警模块
完成模型训练后,实时采集流量数据和用户行为数据进行异常检测,若发现异常行为,则发送预警信息给管理员和用户,提示他们做出相应处理。其中流量数据可直接导入DNN模型,而用户行为数据需要再次进行计算,具体计算过程如下:①计算数据和K-means模型中各正常簇中心点的距离,若小于半径R,则判定为正常行为,若大于半径R,则判定为异常行为。②若该行为是正常行为,则将数据加入集合m中。③若集合m中的数据超过阈值,则重新对K-means模型进行训练,直至簇中心不再变化,将新的模型继续用于后续异常检测。
5 结论
为了保证云际环境下的网络和软件安全,本文提出了一种基于用户行为的异常检测模型。通过构建DNN和K-means算法,对实时流量数据和本地用户行为数据进行检测,弥补了传统流量检测手段忽视用户操作行为的缺点,提高了异常行为检测的准确率。
参考文献:
[1]许洪军,张洪,贺维.一种基于鼠标行为的云用户异常检测方法[J].哈尔滨理工大学学报,2019(4):127-132.
[2]周涛.基于统计学习的网络异常行为检测技术[J].大数据,2015(4):38-47.
[3]陈胜,朱国胜,祁小云,等.基于深度神经网络的自定义用户异常行为检测[J].计算机科学,2019(2):442-445.
[4]李铮,傅阳.一种基于深度学习的网络异常行为检测方法[J].网络安全技术与应用,2020(8):66-68.
[5]邓红莉,杨韬.一种基于深度学习的异常檢测方法[J].信息通信,2015(3):3-4.
