基于软迁移和渐进式学习的人体行为识别方法
2021-07-21袁申强
张 鹏,王 莉,梅 雪,袁申强
(南京工业大学 电气工程与控制科学学院,江苏 南京 211816)
0 引 言
近年来,许多科研人员将深度学习应用于动作识别领域的研究中,涌现出一大批高效的网络结构,如C3D[1]、I3D[2]、P3D[3]、R(2+1)D[4]、ECO[5]、TSN[6]等。虽然这些网络模型在结构上互不相同,但是对视频数据均具备较高的建模能力,能有效区分自然场景下不同的人体行为。理论上,不同网络模型所获的特征描述向量都对类别信息敏感(以分类任务为例),并在网络的输出层变得线性可分,即便来自不同的建模过程,得到的特征向量应该是相似的。不同网络结构获取的知识能否被学习和共享是一个值得讨论的问题。Chen等[7]增加原始网络的宽度和深度,利用原始参数的分解或单位矩阵初始化权重参数,实现了跨结构的迁移学习。Ali等[8]利用了2D网络去监督3D网络的输入和输出,让3D网络拟合2D网络的输出特征分布,间接实现了跨结构学习。受此启发,本文进一步放宽模型结构的限制条件,在结构差异更大的两个网络之间,采用有效度量策略[9,10],实现了更一般意义上的迁移学习,称之为软迁移。
本文基于DenseNet[11]基本模块设计了MDN(modified DenseNet)的新型网络结构,并使用软迁移技术学习继承I3D和R(2+1)D网络的视频特征建模能力,其中不同网络模型在结构上互不相同。记MDN-I3D为一个半监督式的“学习者-监督者”组合。受到GoogleNet[12]多阶段监督的启发,本文提出了三阶段的渐进式监督策略对学习者执行有效的监督。最后,在UCF101和HMDB51数据集上进行实验,成功地将监督者的建模能力迁移到了学习者身上,验证了软迁移学习方法的可行性。
1 方 法
为实现不同结构模型之间的知识迁移,本文提出了软迁移学习方法。本文改进了密集连接网络将其轻量化并适应视频数据,并使用多阶段监督学习的方法来加快网络收敛,以此实现跨结构的迁移学习。
1.1 改进的密集链接网络
图1为MDN网络结构示意,图中 (7,7,7), (2,2,2) 表示3D卷积核的尺度和步长。
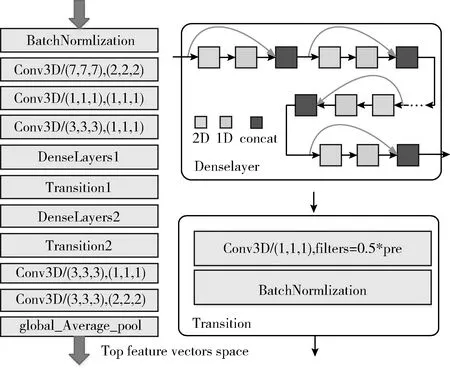
图1 MDN网络结构
为体现MDN结构上与监督网络(I3D和R(2+1)D) 的不同,采用了密集连接的设计方案。但对比原始的3D DenseNet 121[13]做了一些改进:密集连接层数缩减,DenseLayer具有的3D卷积核被拆分为(2+1)D,从而使模型轻量化;为了适应变长时间序列图像,采用全卷积和全局池化生成固定维度的视频描述向量,网络模型共计17层。在输入为25×112×112×3的情况下,计算量为48.54 Gflops,高于I3D(28.9 G),但低于R(2+1)D (76.8 G)。网络具体的细节参数见表1。

表1 MDN网络的详细结构参数
1.2 多阶段监督学习
MDN网络随机初始化会造成输出与监督网络之间的偏差过大,不利于收敛,尤其是在和监督网络结构上差异十分明显的情况下,极有可能不收敛。因此仅仅在最后的输出层进行监督是不够的,需要采用渐进的阶梯式监督策略,在网络底层开始增强网络监督,以保证MDN网络顺利找到优化方向。在网络最终的输出层位置,限制MDN生成与监督网络分布相近的特征空间,构成第二阶段的监督,显式地拟合特征分布,实现监督者对学习者的知识“传授”。
前面两个监督步骤并未用到标签信息,严格意义上属于无监督学习。最后,进行有监督训练来利用数据的标签信息,让学习者不仅与监督者输出相近的特征,且该特征对于分类有效。由此构成三阶段监督策略,加快网络的收敛。
1.2.1 余弦相似度损失
卷积神经网络中越接近网络底层,数据特征越一般化,与具体任务无关。此时可使用比较严格的损失度量函数,使学习者与监督者至少在浅层特征上保持一致,将网络的输出值钳制在一定范围内波动。余弦相似度可作为第一阶段的损失度量函数。图2表示的是在I3D和MDN中间层中设置的监察点,I3D网络的“Mixed_3c”层输出特征为grids∈Rd×h×w×480, MDN网络的“Transition1”层输出特征为gridt∈Rd×h×w×480, 视频特征由N=d×h×w个规则排列局部时空胞元g(g∈R1×480) 构成,N对胞元 (gsj,gtj) 的余弦相似误差反映了两个网络特征的失配程度。式(1)描述了相似度损失函数的计算过程,其中 <,> 表示内积操作,在计算之前,预先对grids和gridt做通道维的归一化,余弦相似度计算可简化成内积运算

图2 中间层特征监督
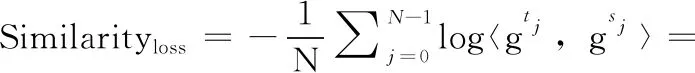
(1)
1.2.2 最大均值差异损失
最大均值差异损失(maximum mean discrepancy,MMD)在数据跨域适应的研究中十分有效,常用作度量特征分布的距离,主要思想是将原域和目标域的特征通过希尔伯特空间单位球内的函数映射到无穷维度,计算无穷维特征的均值误差[14]。在监督网络I3D与学习网络MDN顶层输出端,选择欧式距离(类似文献[8])这样的强约束,并不利于网络的迁移,结构上的巨大差异使得网络输出层特征受到输入数据和网络结构双重影响,波动过大,约束条件过于严格会导致网络不收敛。MMD方法仅仅度量了特征之间分布的相似性,通过多高斯核将约束变得更加灵活,比较适用于这种弱监督场景。Long等[15]在缺少数据标签的情形下,用MMD约束不同源数据呈现相似的特征分布。这些情景与本文目的类似,不需要目标特征与参考特征完全一致,获取相似的特征分布便可认为知识已经发生了转移,进一步的分类任务由最后的全连接完成

(2)
式(2)定义了最大均值差异损失,其中φ(·) 即为隐式的映射函数。在实际应用中通常通过样本的无偏估计来做具体计算,Nx和Ny表示两个特征集的样本量, k(xi,yj) 表示核运算,将特征维度映射和内积计算一次性完成

(3)
如式(3)所示,利用K个高斯核,其中Ny×Nx等于批量随机梯度下降优化的batch_size,σk∈[10-6,10-5,…,105,106],xi∈R1×1024, MDNout=(x0,x1,…,xN-1),yi∈R1×1024, I3Dout=(y0,y1,…,yN-1)
argminΘF(Θ)=J(Θ)+γ1Similarityloss+γ2MKMmdloss
where J(Θ)=Entropyloss(Θ,clip,label)
(4)
式(4)形式化地定义了软迁移学习方法的整体损失函数, Entropyloss(·) 表示交叉熵分类损失,γ1和γ2作为两个超参数用以调节不同阶段监督作用的强弱。
2 实 验
本文1.2节以改进的MDN与监督网络I3D之间的迁移学习为例,描述了本文所提出的跨结构迁移方法的计算细节。为验证算法的有效性,本章增加了以R(2+1)D为监督网络的对比实验,设计了3个实验组: 学习者-监督者=[①MDN-I3D,②MDN-R(2+1)D,③I3D-R(2+1)D]。 R(2+1)D采用了文献[7]的 R(2+1)D-18网络结构,其中间层’conv_4x’的输出特征为grids∈Rd×h×w×256, R(2+1)Dout=(y0,y1,…,yN-1) 为输出层的特征yi∈R1×512, 实验②、实验③中根据监督网络输出特征维度对学习网络做结构上的调整用以互相匹配。
2.1 实验配置
软件环境为Ubuntu16.04LTS版操作系统,GPU版tensorflow深度学习框架的Python3 API,硬件环境为CPU i7-7800X 3.50 GHz 16 GB,两个GPU GTX1080Ti11GB独立加速显卡。为了加速训练,实验中采用了数据并行的多GPU联合训练架构,初始学习率设为0.1,采用指数衰减调整学习率,衰减系数设为0.95;数据集为UCF101和HMDB51,分别包含13 320和6766个视频片段,常被用作动作算法评估的基准。由于3D网络对于GPU内存要求过高,为了提高训练效率,预先使用I3D和R(2+1)D对两个数据集进行特征提取,将数据集的中间层特征和输出层特征保存至本地,在训练MDN时直接读取监督信息。这种离线的方法大大降低了多阶段监督训练的时间和空间复杂度,不必动态地运行一个监督网络。计算机底层对隐藏层的反向误差和导数的数值运算过程基本与原分类网络一致,增加的计算量主要来自式(1)、式(3)对损失值的计算,在输入数据大小一定的情况下,增加的时间和空间复杂度均为O(1),为常数复杂度。
2.2 实验结果及分析
表2展示了不同的网络结构在UCF101和HMDB51数据集上的表现。前两行数据是在参数迁移的情况下记录的,完全使用了原始的网络结构与预训练参数,仅在新数据集上微调得到的结果。后三行是利用本文提出的软迁移方法间接学习得到的结果,其中I3D和MDN作为待学习网络,使用Xavier随机初始化方法。可以看出参数迁移在精度上是领先的,虽然软迁移方法在精度上没有达到与硬迁移相同的水平,但是相比不使用监督网络从头开始训练的情况,确有较大的提升。表3记录了多阶段监督对网络最终收敛精度的影响,*标记表示不添加监督网络的约束,即γ1=γ2=0的情况下,在UCF101上从头训练得到的结果。如表3前两行所示,MDN*和I3D*没有利用迁移学习的情况下,在UCF101数据集上的验证精度为62.1%和82.5%,而在受到监督作用时分别达到了85.4%和94.7%,这个结果初步验证了软迁移方法的可行性。

表2 UCF101和HMDB51上的实验结果

表3 监督不同阶段的结果对比
由表3可以看出,γ1,γ2对网络性能的影响十分明显。在仅有中间层监督或仅有输出层监督的情况时,MDN精度的提升十分局限,而当γ1和γ2同时作用,MDN精度提高了20%左右。其中顶层的监督对MDN网络的作用最为显著,在MDN-I3D的训练中,50 k次迭代后分类损失函数就停止了下降,而此时mmd损失停留在0.15左右,当增大γ2到0.75时,网络开始了继续优化并促使最终的验证精度达到了80.3%。
实验中,MDN在R(2+1)D网络的监督下相比I3D监督,出现了更快的收敛速度与更高的验证精度。在UCF101训练集上,MDN-I3D与MDN-R(2+1)D训练精度首次达到80%用到的迭代次数分别为48 k和41 k,而从最终的验证精度上看,后者比前者高了3.1%,这种差异现象是监督网络与学习网络的结构相似性程度的不同造成的。MDN采用了残差跳跃连接结构,对3D卷积核也进行了拆分,这种方式与R(2+1)D在结构上的相近,而与I3D网络采用的inception结构差异较大,因此在迁移过程中MDN需要搜索更大的参数空间来学习I3D的结构信息。通过参数组合弥补结构差异是本文软迁移方法的核心思想,也是最难的部分。极端情形下,完全相同的结构是最容易实现知识软迁移的,算法会退化成为纯参数学习。
此外,学习者自身的可塑性对本文方法有较大影响,学习能力越强迁移效果越好。如图3(a)~图3(c)所示,I3D在结构上与R(2+1)D差异很大的情况下实现了快速收敛,仅仅在10 k次迭代之后,网络就开始趋于稳定。图3(d) ~图3(f)为MDN的训练过程,由于MDN对DenseNet在层数上进行了大幅缩减,减少网络层数弱化了残差网络的优势,使得其学习能力下降。相比DenseNet121(UCF101 87.6),MDN的精度下降了25.5%。本文的主要目的是验证跨结构迁移的可行性,仅仅考虑了学习者结构上与监督者的差异性,没有更进一步的精细化调整,整体上较为粗糙,而I3D网络结构是经过精心设计与验证的。由此可以看出,虽然跨结构迁移方法形式上可以做到结构无关,但是要求学习者本身具备良好的建模能力。

图3 不同网络在数据集UCF101的训练过程
2.3 可视化分析
为了进一步观测MDN对监督网络的学习,本文做了补充实验,查看学习者对监督者建模能力的继承情况。理论上,监督网络在大数据集上训练过,都具备很强的泛化能力,假设在监督网络的影响下,MDN对没训练过的数据集也产生了一定的泛化性,那么可以认为其学到了监督网络某些有效的连接特性。以MDN-I3D为例,检验MDN-I3D对Kinetic中视频数据的泛化性能(本文所用I3D预训练模型是在Kinetic-400上训练的)。由于Kinetic-400数据集过于庞大,仅从验证集的216类样本中选择2500个视频进行实验,其中2000个用于训练,500个用于验证。训练在2.2节的基础上进行,分别利用MDN-I3D和MDN*的学习参数对MDN网络初始化。
图4展示了训练迭代20 k步时,不同初始化方式对500个验证视频提取特征的分布情况,可以看到图4(b)中大部分数据点已经变得离散,意味着不同类别的数据经过MDN产生了不同的响应,而图4(a)中数据点依然紧紧的聚集在一起,表示MDN此时还无法对这些视频进行区分。这一结果表明I3D参数对Kinetic-400数据集的泛化性通过监督-学习机制一定程度上被MDN继承了,因此才会在对Kinetic中的数据训练过程中更快找到不同类别视频间的差异信息。而从头开始训练的MDN网络参数仅仅学到了UCF数据集的数据建模知识,数据量太小,难以对Kinetic数据集产生泛化性。因此在短时间内很难对来自Kinetic数据集的数据产生明显的分辨效果,出现了图4(a)、图4(b)之间的显著差异。

图4 MDN对500个Kinetic-400视频的特征提取
3 结束语
本文提出了一个神经网络迁移学习的新问题,尝试利用网络的学习能力去间接学习异构网络内部的连接特性,拟合监督网络的输出特征分布。区别于传统的基于参数的硬迁移方法,引出了基于间接学习的软迁移方法,设计了一种监督者-学习者机制,研究神经网络跨结构相互学习的可行性。通过将监督网络I3D和R(2+1)D的泛化能力迁移具有到不同结构的学习网络MDN中,验证了跨结构学习是可行的。对比不同阶段监督情况,验证了多阶段渐进式监督策略的必要性;讨论了模型结构对软迁移效果的影响,发现在监督网络与学习网络具有相似的结构时,网络更容易收敛。此外R(2+1)D与I3D两个基准网络间的成功迁移,表明学习者自身的表达能力对软迁移效果具有决定性影响,结构上具有的较大差异的网络在学习能力足够强的情况下也能通过软迁移学到监督者的能力,进一步验证了模型结构精细化设计的重要性。最后,本文提出的软迁移方法拓展了传统迁移学习的范围,突破了模型结构的制约,提高了已有动作识别模型的适用性。
