基于核二次互信息的发酵过程质量预测模型
2021-07-21高学金齐咏生高慧慧
李 征,王 普,高学金+,齐咏生,高慧慧
(1.北京工业大学 信息学部,北京 100124;2.北京工业大学 数字社区教育部工程研究中心,北京 100124;3.北京工业大学 城市轨道交通北京实验室,北京 100124;4.北京工业大学 计算智能与智能系统北京市重点实验室,北京 100124;5.内蒙古工业大学 电力学院,内蒙古 呼和浩特 010051)
0 引 言
发酵过程广泛应用于生物制药领域。发酵过程中的质量变量难以在线预测,通常在批次结束后取适量发酵液带到实验室离线分析,具有时间延迟,不利于产品质量闭环控制。过程工业中常利用传感器读取的过程变量预测质量变量[1-3]。发酵过程动力学模型为强非线性,应用线性方法[4-6]难以保证预测精度。文献[7]应用核偏最小二乘法对关键变量进行预测,通过核映射将被测变量与可测变量间的非线性关系近似线性化。文献[8]使用最小二乘支持向量回归预测青霉素发酵中的质量变量,解决非线性问题。文献[9]提出约化双核偏最小二乘法,将核映射后的高维特征逆映射至质量空间,实现发酵过程中质量变量的预测。文献[10]建立核熵成分分析所提取的过程特征与质量数据之间的回归模型进行质量预测。然而,以上方法均基于相关性提取特征,不足以描述变量之间的非线性关系。文献[11-14]使用二次互信息衡量变量之间非线性关系提取特征,并解决了互信息计算量较大的难题。文献[15,16]在分类问题中通过最大化特征与类别标签之间的二次互信息,实现有监督特征提取。
为解决发酵过程质量预测中数据强非线性问题,提出一种基于核二次互信息的质量预测模型,依据信息论准则有监督地提取过程数据的特征,并建立回归模型对质量变量进行在线预测。
1 相关理论
1.1 发酵过程工艺
发酵过程工艺如图1所示。通过基因工程等方式改变微生物遗传特性,形成生产用的菌种。使用摇瓶对菌种进行扩大培养,将其接种至灭菌的发酵罐中进行生长培养。发酵罐中富含菌体生长所必需的营养原料。发酵过程包括菌种适应期、菌体快速生长期及蛋白表达期。微生物在合适的发酵条件下会合成代谢产物,某些代谢产物经过分离纯化后得到产品——目的蛋白。例如,青霉菌在合适发酵条件下可代谢产生广谱抗生素青霉素;大肠杆菌是现代生物制药领域中常用的基因工程菌之一,大肠杆菌在工业生产中常被基因改良并进行发酵生产,以制备抗肿瘤药物重组人白介素-2(Interleukin-2, IL-2)。发酵过程包含微生物代谢生长,过程机理复杂,难以建立精确的数学模型。发酵产品质量极易受到温度、溶氧等环境条件及灭菌、接种等人为操作的影响,波动较大。对菌体数量、菌体浓度、目的蛋白等质量变量进行在线预测,判断生产状态,具有十分重要的意义。
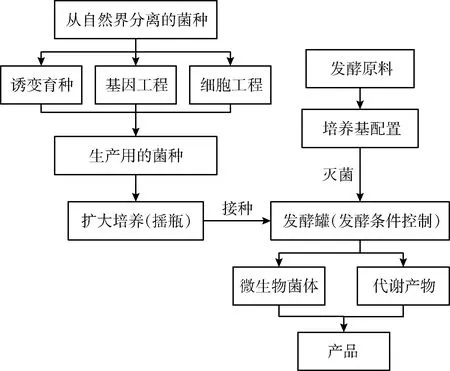
图1 发酵过程工艺
1.2 Renyi二次熵及其估计
信息论创始人香农定义了著名的香农熵,实现对随机变量所包含平均信息量的量化。熵值越大,代表随机变量的不确定性越大,所包含的信息量就越大。Renyi对熵进行推广,Renyi的a阶熵定义如下
(1)
其中,X是随机变量,f(x)是其概率密度函数。在a=2时,得到Renyi二次熵,表达式如下
(2)
当a→1时,Renyi熵近似为香农熵。Renyi二次熵在计算量上较香农熵具有明显优势。由Renyi二次熵定义式可知,Renyi二次熵中的log运算符在积分号外面,因此计算起来相对简便。因此,基于Renyi二次熵定义的二次互信息在计算上较经典的基于香农熵意义的互信息具有明显优势。
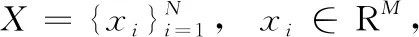
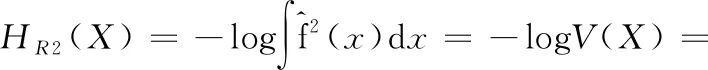
(3)
(4)
f(x)是产生数据集X的概率密度函数。 p(u,Σ) 是对f(x)进行Parzen窗估计时选取的高斯核函数。为便于计算,令Σ=σ2I为其协方差矩阵,以此确定窗宽大小。式(3) 中利用高斯核函数的重要性质[15],将繁杂的积分运算转换成两两样本之间核函数的计算,大大降低了计算复杂度和计算量。
1.3 二次互信息及其估计
互信息(mutual information,MI)与二次互信息(quadratic mutual information,QMI)都能够衡量随机变量之间的非线性关系,但QMI的计算复杂度小于MI且具有更强的噪声鲁棒性,更适合处理复杂的工业过程数据。对于两个随机变量X与Y,假设它们的边缘概率密度函数分别为fX(x) 与fY(y), 联合概率密度函数为fXY(x,y), 则基于欧氏距离的X与Y之间的QMI定义为
QMIE(X,Y)=∬fXY2(x,y)dxdy+∬fX2(x)fY2(y)dxdy-2∬fXY(x,y)fX(x)fY(y)dxdy
(5)
可以看出,QMIE(X,Y)≥0恒成立。当且仅当X与Y相互独立时,QMIE(X,Y)=0。
接下来对QMI进行估计。由式(5),将QMIE(X,Y) 改写成以下形式
QMIE(X,Y)=VJS+VMS-2VCS
(6)
其中
VJS=∬fXY2(x,y)dxdy
VMS=∬fX2(x)fY2(y)dxdy
VCS=∬fXY(x,y)fX(x)fY(y)dxdy
(7)
选用式(4)中的高斯核函数,使用Parzen窗估计对VJS、VMS与VCS分别进行计算
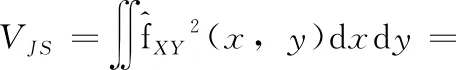
(8)
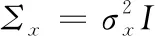
2 核二次互信息回归模型(KQMIR)
2.1 基于核二次互信息(Kernel QMI)的特征提取方法
图2为基于再生核希尔伯特空间(reproducing kernel hilbert space,RKHS)对输入X进行特征提取的示意图。首先,将过程数据X(输入)进行非线性变换,通过核映射获取高维特征Φ。之后基于RKHS空间,对高维数据进行线性变换W提取过程数据的低维特征T。低维特征T即为所要求取的过程特征。基于过程特征T与质量数据(输出)Y之间的QMI及过程特征T的Renyi二次熵定义目标函数J,使用梯度下降法求取线性变换W的最优值,进而求取过程特征T。最后建立过程特征T与质量数据Y之间的回归模型进行质量预测。
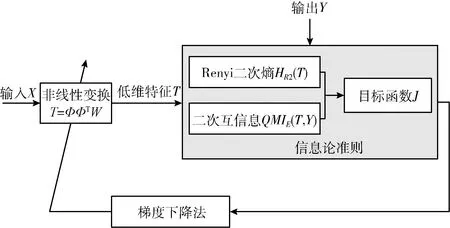
图2 基于核二次互信息的过程数据特征提取
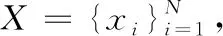
(9)
则不同的核参数σ将输入X映射到不同的无穷维的特征空间中,即Q→∞。
接下来,对核矩阵K实施线性变换,将其映射到低维特征空间。首先寻找出一个变换权重向量w,使得变换后的低维特征t与输出Y之间的二次互信息最大,同时尽可能保留原始输入X的自信息。令t=Kw, 其中,w为N×1 权重向量。t=(t1,…,tN)T为线性变换后的投影值,也是N×1维向量。若共计提取r维新特征,则权重向量w变为N×r维权重矩阵W,W中的每一列为一个维N×1权重向量。t变为N×r维矩阵T,T的第r列为K在W的第r列wr作用下的得分向量,T为K在低维空间中的新特征,即T=ΦΦTW。 特征提取的目标函数定义如下
J=-HR2(T)·QMIE(T,Y)
(10)
可以看出,通过求取目标函数的最小值,可以使得变换后的过程特征T与输出Y之间的QMI最大,保证原始输入数据能够最大程度的包含输出数据所承载的信息量。同时,新提取的T的Renyi二次熵能够最大程度保留X的自信息。
2.2 模型学习过程
(11)
其中
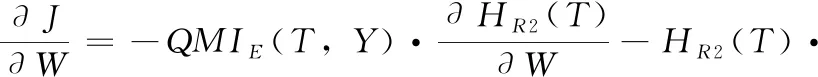
(12)
(13)
由T=KW, 则
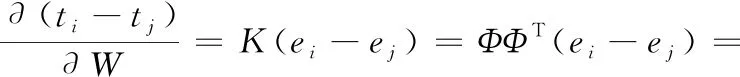
(14)
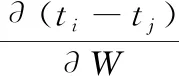
(15)

(16)

(17)
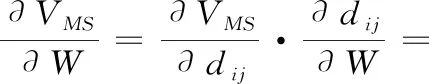
(18)
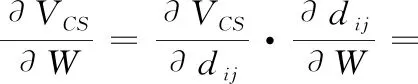
(19)

(20)
式(9)中核参数σ的取值可使用输入样本X的样本协方差矩阵对角线元素σx确定。使用Silverman’s经验准则计算σt,即
(21)
其中,r为特征空间的维数。σy可以直接由输出样本的方差确定。
2.3 回归预测模型
经过以上计算,由梯度下降法求得W*,此时T*=ΦΦTW*。 建立T与Y之间的最小二乘回归模型为
(22)
将T*=ΦΦTW*代入式(22),则X与Y之间的最终回归模型为
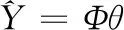
(23)
θ为回归系数
θ=ΦTW*(W*TK2W*)-1W*TKY
(24)
将以上模型称为二次互信息回归(kernel quadratic mutual information regression,KQMIR)模型。
3 基于KQMIR模型的质量预测
3.1 数据预处理
发酵过程是间歇过程,在一个批次的生产结束后才能获取产品。因此,发酵过程的可测量过程数据是三维信息,包括时间、变量与批次。实际生产中,会记录当前批次的产品质量变量信息,比如菌体浓度等。通常将三维矩阵按照建模的需要按不同方式展开成二维矩阵[9]。本文选用批次展开方式,得到二维矩阵X(I×KJx), 如图3所示。其中,I为批次数,Jx为过程变量个数,K为总采样时刻。同时,每个批次结束后,会产生相应的产品质量变量,因此,质量数据阵可表示为Y(I×L),L为质量变量的个数。
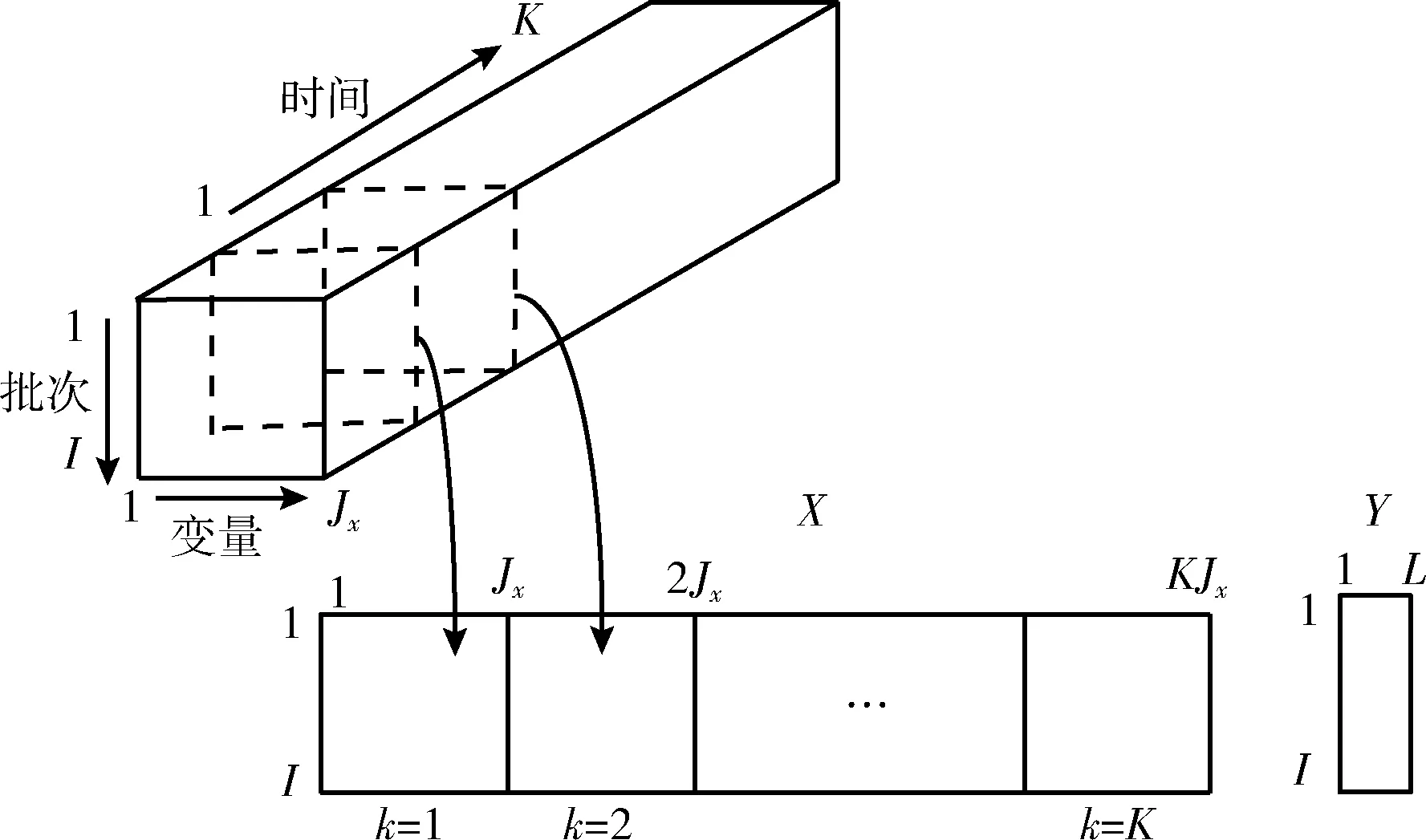
图3 间歇过程三维数据的批次展开方式
3.2 离线建模
离线建模步骤如下:
步骤2 对X与Y沿批次方向进行中心化与方差归一化,求取核参数σ及σx,σt,σy;
步骤3 使用核函数求取核矩阵Ko,并对其进行中心化及方差归一化。中心化处理如下
(25)
其中,IN是N维单位矩阵,1N是元素全为1的N×1维向量。方差归一化处理后得到最终K如下
(26)
步骤4 初始化权重矩阵W(N×r)。 使用梯度下降法求取目标函数J的最小值,计算出最优投影W*。梯度下降法的迭代过程如下:
(1)使用式(3)至式(8)计算J;
(3)使用式(11)更新权重矩阵,保证W的列向量之间相互正交;
(4)使用T=ΦΦTW计算特征T;
(5)重复以上过程,直到达到终止条件。
3.3 在线质量预测
在线质量预测步骤如下:
步骤1 对当前第k时刻样本xk(Jx×1) 进行数据填充。下一时刻至第K个采样时刻的样本值均使用xk填充,得到新样本xnew(KJx×1)=xnew(M×1)。 依据X的均值和标准差对xnew进行中心化与方差归一化处理;
步骤2 计算xnew的核向量Knew
Knew=φT(xnew)·ΦT=
[φT(xnew·φ(x1)…φT(xnew)·φ(xi)…φT(xnew)·φ(xN))]
(27)
对其中心化如下
(28)
方差归一化后得到最终Knew,计算如下
(29)
步骤3 依据式(23)~式(24)使用KQMIR模型进行质量预测,当前时刻对质量的预测值为
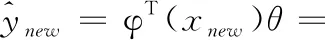
(30)
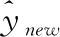
步骤5 使用以上步骤1至步骤4顺序计算未来每个采样时刻的质量预测值,直到当前批次结束。
最后,基于核二次互信息回归模型的质量预测的总体流程如图4所示。
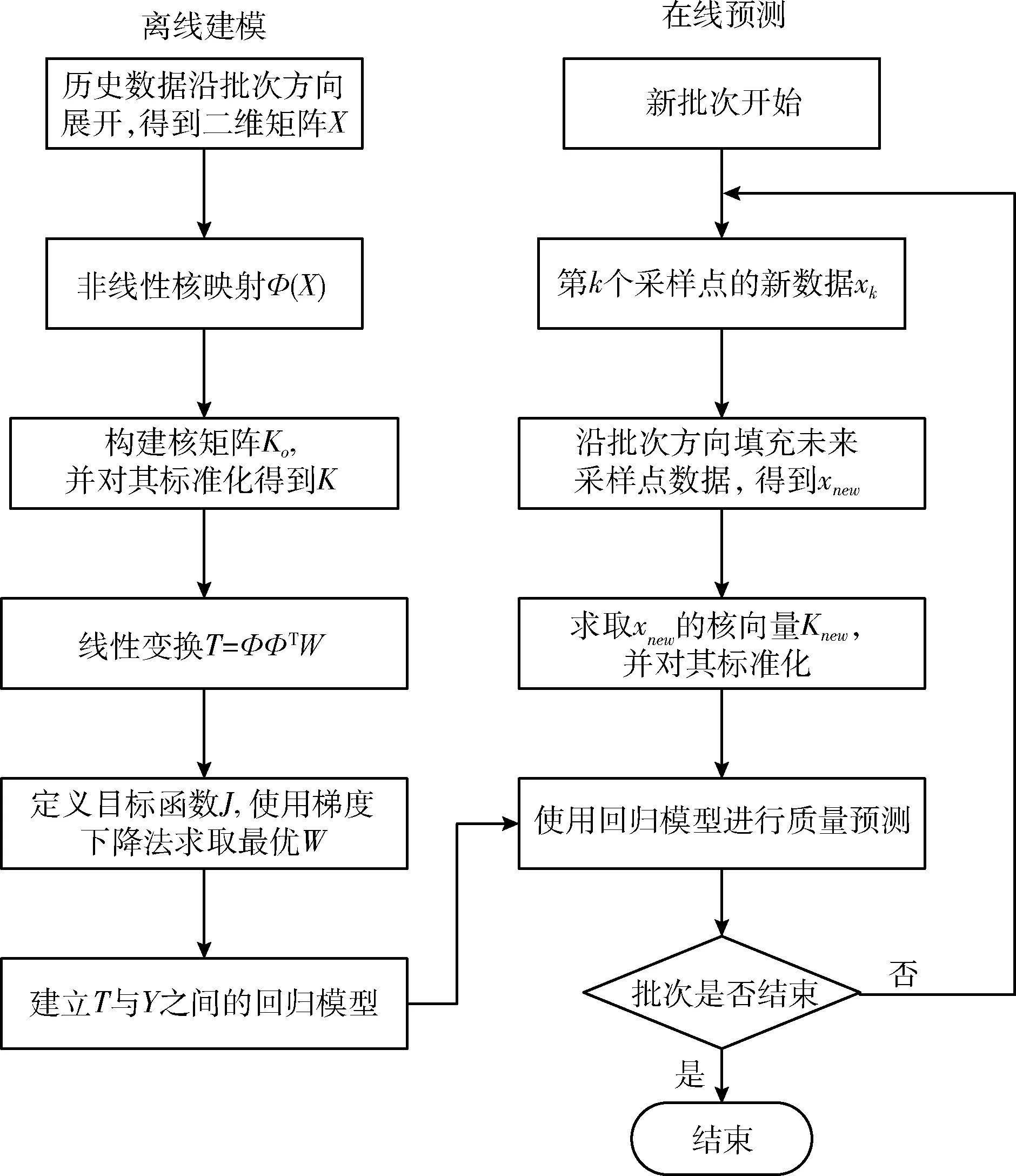
图4 基于KQMIR的在线质量预测
本文采用批次RMSE(简称RMSE)与采样时刻RMSE(简称RMSE(k))评价模型预测效果。批次RMSE定义如下
(31)

(32)
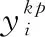
4 实验及结果分析
4.1 青霉素发酵仿真实验
Pensim是国际上较为广泛应用的青霉素发酵过程仿真平台。使用Pensim平台产生48批次的正常生产数据,任选40批次用于建模,8批次进行测试。发酵周期为400 h,采样间隔为1 h。共计选择10个过程变量(通风速率、搅拌功率、冷水流加速率、反应器体积、产热、溶氧浓度、温度、补料温度、pH、排气CO2浓度)与一个质量变量(青霉素浓度, 单位g/L)。
特征维数r不同取值下,KQMIR对8批次测试数据的批次RMSE的均值见表1。当r=4时,KQMIR预测误差最小。图5为不同r取值下KQMIR的采样时刻RMSE(k),200 h-400 h区间内,当r取2或4时,RMSE(k)取值较小,当r=1时,RMSE(k)取值较大,与表1结果一致。综上,在r=4时预测效果最优。

表1 Pensim中KQMIR模型的批次RMSE均值
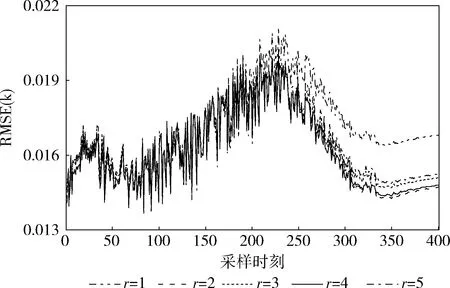
图5 KQMIR对所有测试批次的RMSE(k)
为验证方法的有效性,将本文提出的KQMIR模型与核偏最小二乘法(kernel partial least squares,KPLS)及支持向量回归法(support vector regression,SVR)进行对比实验。图6为某个测试批次下3种方法对批次最终青霉素浓度的预测结果。在前200 h,KQMIR与KPLS的预测效果明显优于SVR,且KQMIR预测效果略优于KPLS。在批次结束时,KQMIR方法预测结果最接近测量值。表2列出3种方法对所有8个测试批次的RMSE的均值及标准差。由RMSE的均值可以看出KQMIR对青霉素浓度的平均预测误差小于KPLS及SVR。从RMSE的标准差可以看出,SVR对不同测试批次的预测效果最稳定,KQMIR的预测稳定性略优于KPLS。图7为3种方法对所有测试批次的RMSE(k)。在生产开始及210 h前的绝大多数采样时刻,SVR的RMSE(k)值波动幅度较大,且远大于KQMIR及KPLS。210 h后,SVR的RMSE(k)最小,KQMIR的RMSE(k)值小于KPLS。
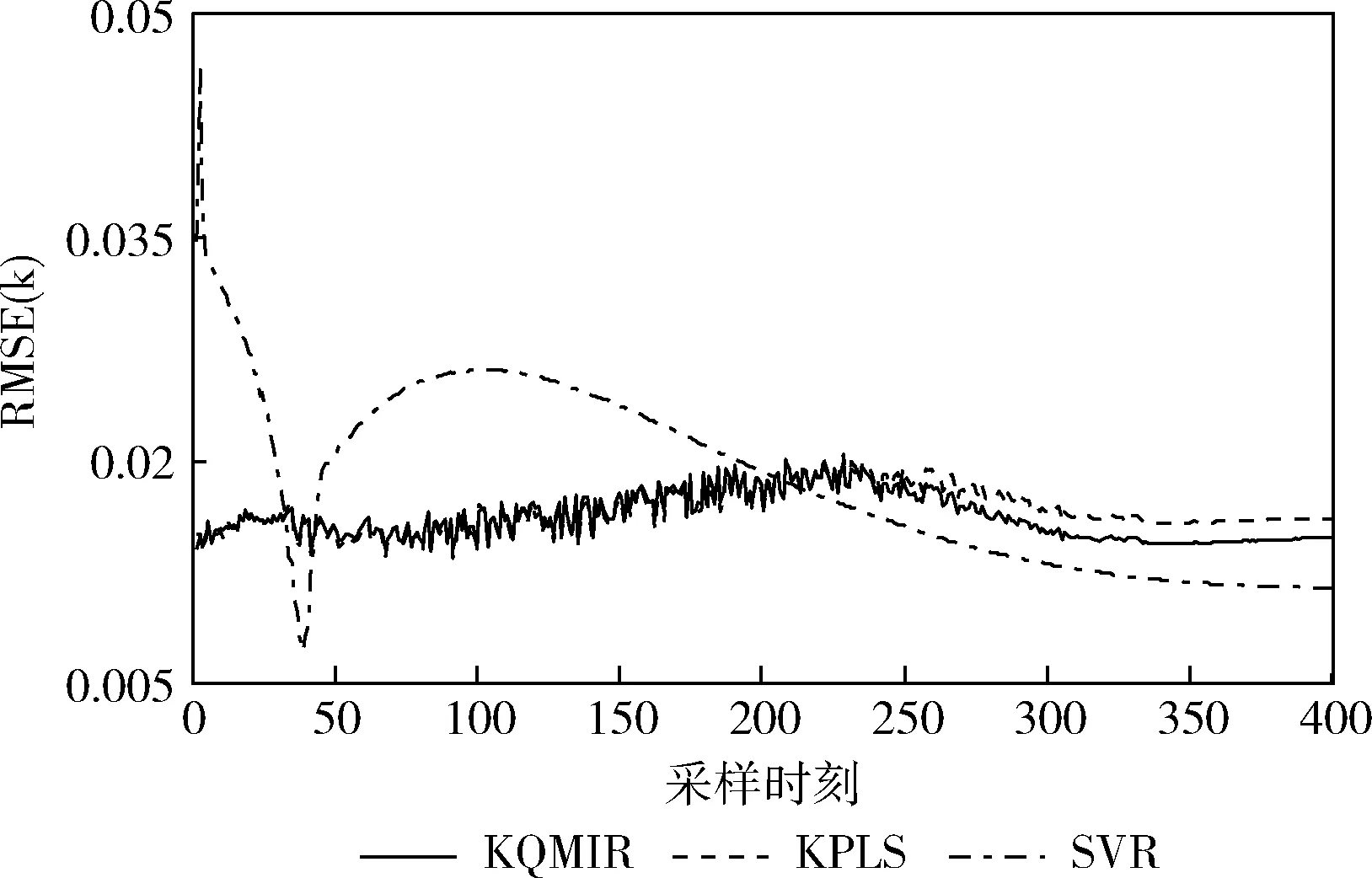
图7 3种方法对所有测试批次的RMSE(k)
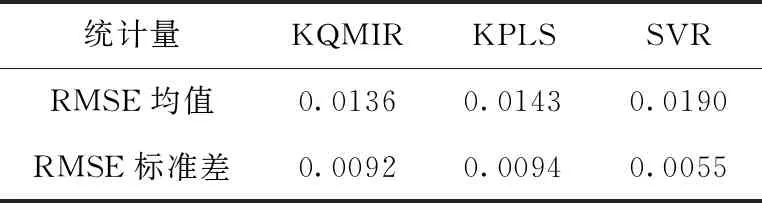
表2 3种方法的批次RMSE均值及标准差(Pensim)
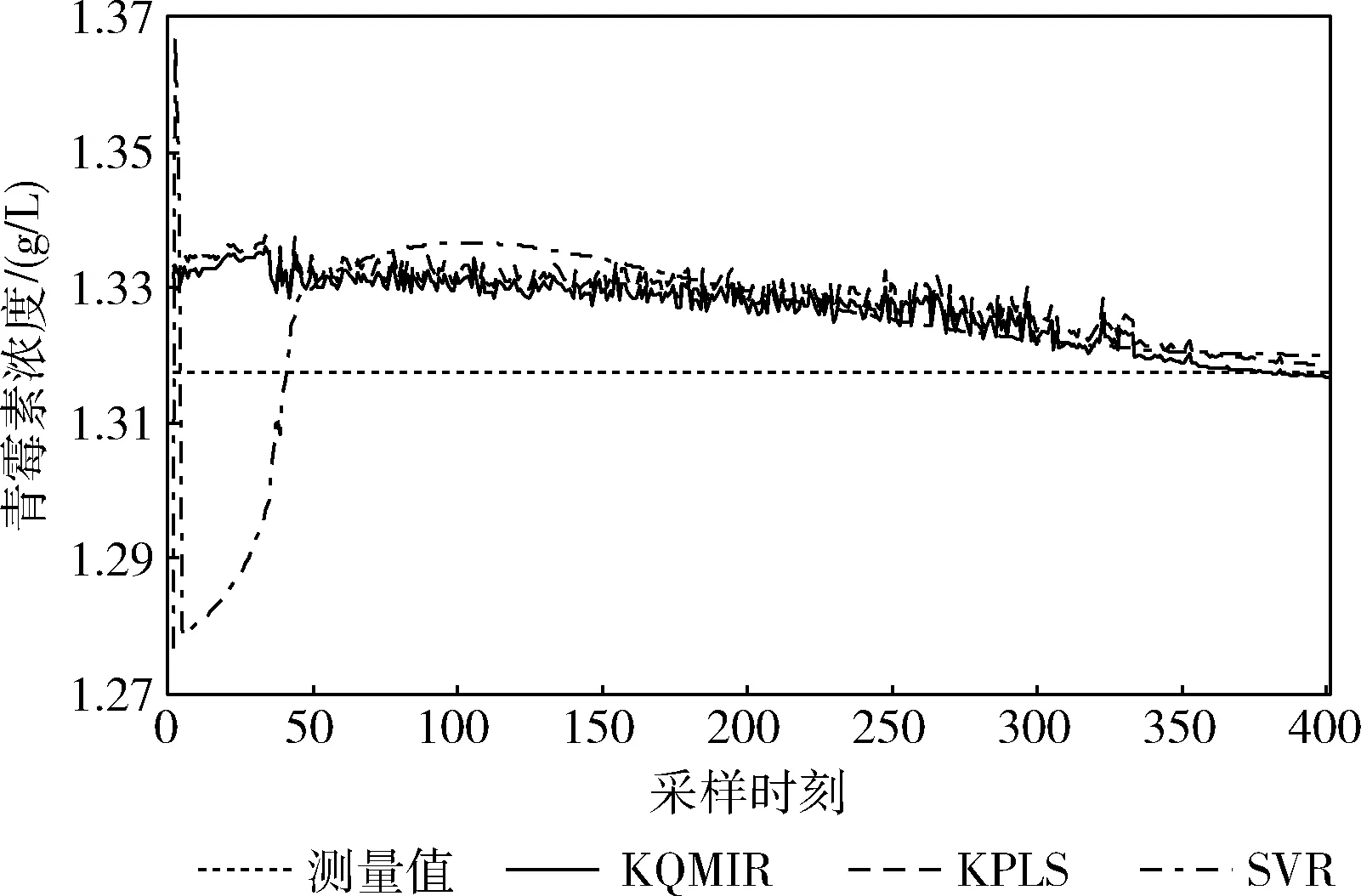
图6 3种方法对某个测试批次的青霉素浓度预测结果
综上,KQMIR对青霉素浓度的平均预测误差最小,预测效果最好。与在高维特征中采用相关性作为准则提取特征的KPLS方法相比,KQMIR在高维特征空间中采用二次互信息作为准则自适应提取特征。由于二次互信息是更高阶的统计量,因此能够更好地提取原始数据所包含的信息。
4.2 大肠杆菌发酵生产数据实验
实际生产数据验证更突显本方法的意义和效果,本文以北京亦庄某制药公司使用大肠杆菌制备抗肿瘤药用蛋白白介素-2(IL-2)的生产数据为验证对象。实际生产中,产物IL-2的质量往往难以在线预测,需要实验室分析。本文将对IL-2质量进行在线预测。
实验中,共计选择8个可测量的生产过程变量(pH值、罐压、溶氧、搅拌速率、温度、通风速率、补氮、补碳)与一个质量变量(IL-2质量,单位kg)。发酵时长约为19 h-20 h,采样间隔为0.5 h,共计39个采样时刻。共收集到28批次正常生产数据,随机选取其中的20批次进行离线回归建模,剩余8批次用于测试。实验开发语言为Matlab,开发平台为Matlab R2014a。
特征维数r取不同值时,KQMIR对8批次测试数据的预测RMSE的均值见表3,可以看出当r=2时,KQMIR取得最佳预测效果,具有最小的RMSE。此外,不同r取值下KQMIR的RMSE(k)值如图8所示,可以看出,RMSE(k)值大致在1-1.5区间内波动,在采样时刻22之后直至批次结束这段区间内,r=2时都具有最小的RMSE(k)。

表3 KQMIR模型的批次RMSE均值
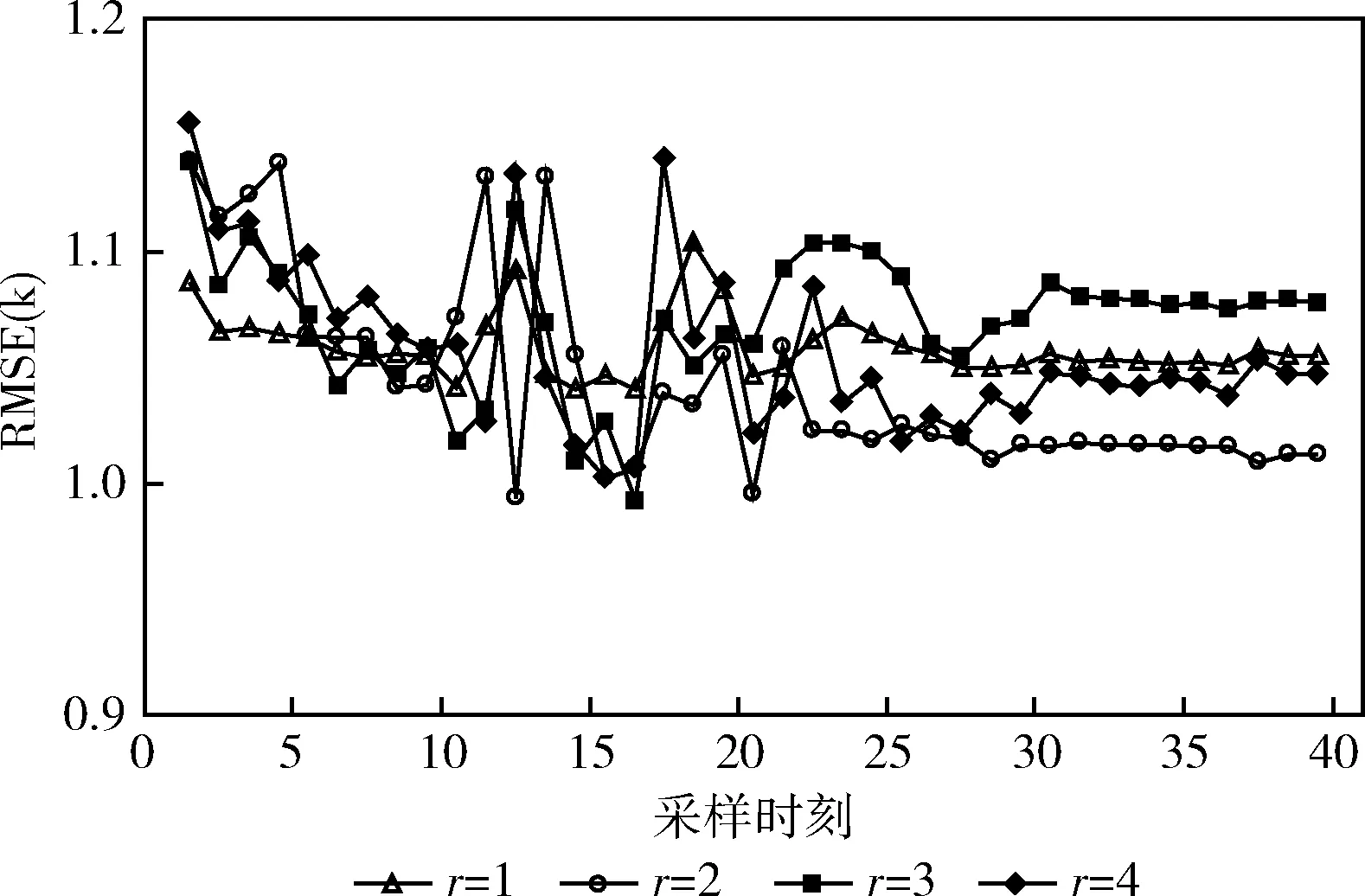
图8 KQMIR对所有测试批次的RMSE(k)
图9为某个测试批次下3种方法对IL-2质量的预测结果对比。可以看出,KQMIR的预测效果最好、最接近测量值。在采样时刻25至批次结束期间,KQMIR的预测结果好于KPLS,明显优于SVR。
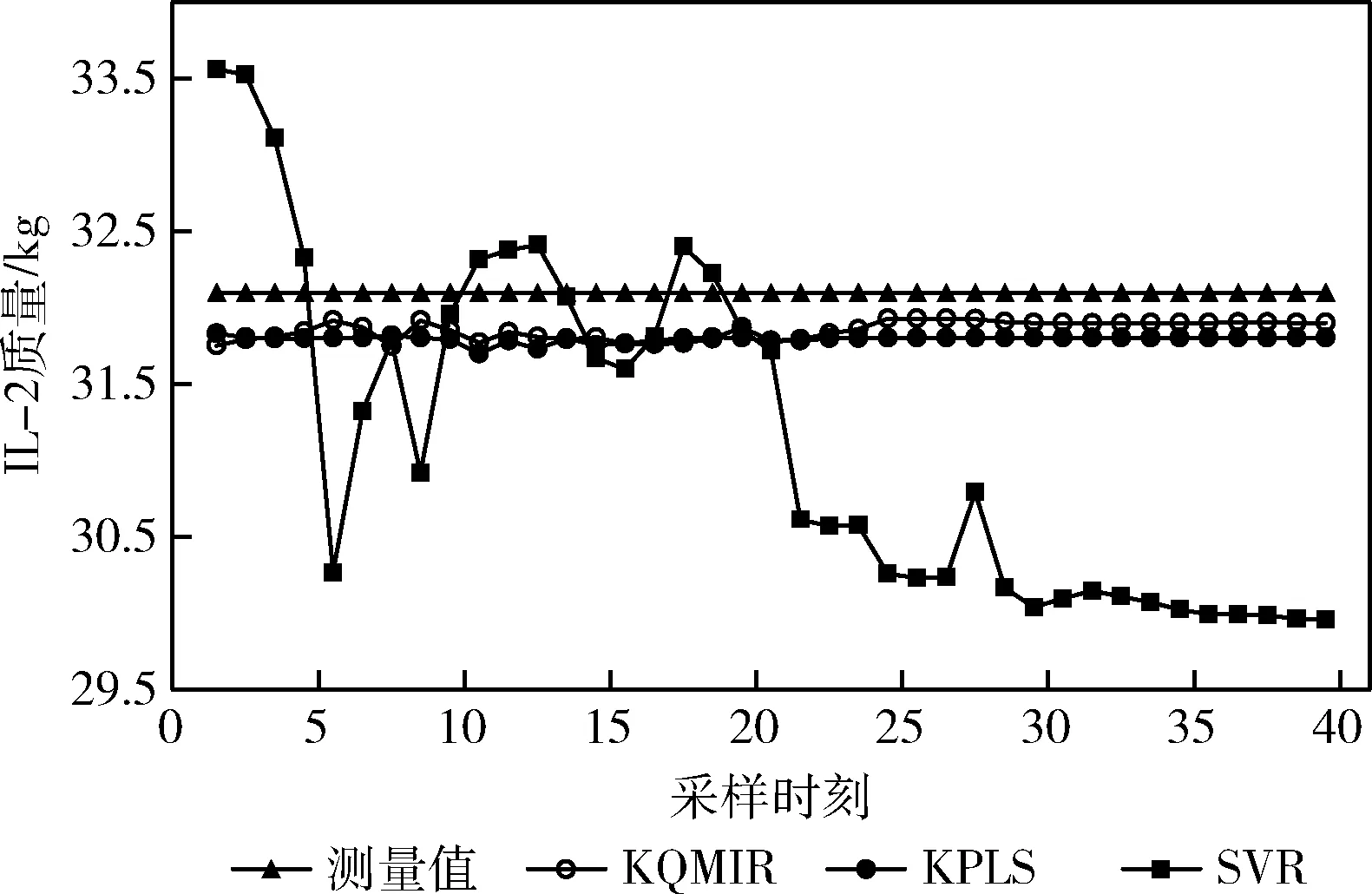
图9 3种方法对某个测试批次IL-2质量的预测结果
3种方法对所有测试批次的RMSE的均值及标准差见表4,由RMSE均值可以看出KQMIR对IL-2质量的预测精度优于KPLS,且明显优于SVR。另一方面,从RMSE的标准差可以看出,SVR对所有测试批次的预测效果最稳定,KQMIR的预测稳定性要略优于KPLS。此外,3种方法对所有测试批次的RMSE(k)值如图10所示,可以看出,SVR的RMSE(k)值明显大于KQMIR及KPLS。采样时刻15以后的所有采样时刻上,KQMIR的RMSE(k)值均小于KPLS。综上,本文提出的KQMIR具有最优的预测效果。
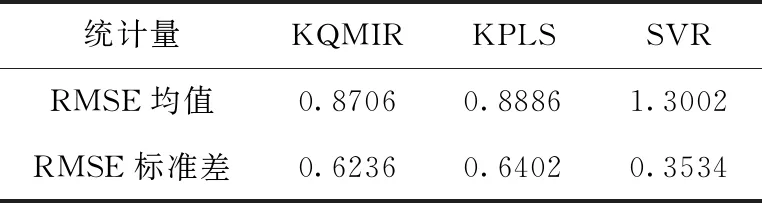
表4 3种方法的批次RMSE均值及标准差
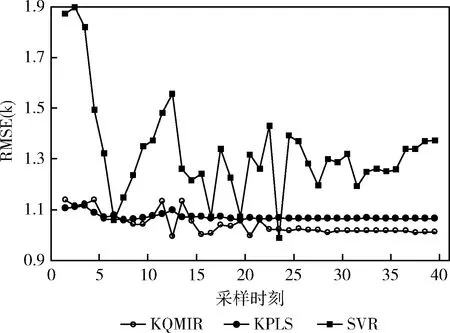
图10 3种方法对所有测试批次的RMSE(k)
5 结束语
为解决发酵过程数据的强非线性、质量变量难以在线预测的问题,提出一种基于二次互信息回归模型的质量预测方法。该方法具有以下优点:①将原始输入空间通过核映射到高维空间,加强对非线性数据的处理能力;②所提取的过程特征能够最好地描述过程数据和质量数据之间互相包含的信息,尽可能使得过程变量和质量变量之间的二次互信息最大化;③提取的特征可以最大化地保留过程数据的自信息量,尽可能使得过程变量自身的Renyi二次熵最大。该方法与经典的非线性回归方法KPLS及SVR进行对比实验。青霉素发酵仿真实验中对青霉素浓度的预测及大肠杆菌发酵过程中对IL-2质量进行预测的实验,验证了KQMIR的有效性,并且KQMIR具有优于KPLS及SVR的预测效果。KQMIR的质量预测方法可以推广到其它间歇过程中。目前,二次互信息准则还主要应用在图像分类、图像识别等领域,在过程建模中很少应用。本文将其引入过程领域,旨在探索QMI的相关理论在过程数据处理中的应用。
