科学数据重复使用的学科差异性研究*
2021-07-20王雪杨波
王 雪 杨 波
(1.南京工业大学图书馆 南京 210009;2.南京农业大学信息管理学院 南京 210095)
0 引 言
科学数据是指科研活动中产生的数据,包括实验数据、监测数据、调查数据等[1]。大数据时代,科学数据是科研活动的基础性资源,大部分的科研活动都是以数据的搜集和分析开始的。同时,科学数据也是一种重要的社会资源,以欧美为首的众多国家甚至将科学数据的管理与应用上升至国家战略层面。我国国务院办公厅印发实施的《科学数据管理办法》[2],为我国科学数据重用提供了重要的政策保障。
数据的价值在于使用。通过重用科学数据,可以节省科研人员的时间、精力和财力,也是对数据拥有者的权益保护,增强科研人员的数据共享信心[3]。了解科学数据重用过程中的障碍与难点、规范数据重用行为,是促进科研纵向发展的必由之路。
大数据时代的科学技术,为数据重用的实现奠定了基础。数据重用可以规避科研人员在数据收集过程中遇到的数据动态更新、数据格式不统一等客观性问题,同时也是个人数据收集能力的重要体现。不同学科领域,由于研究范式的差异,对于数据重用存在不同的认知。本研究以科研人员的角度出发,以多个学科为研究对象,采用定量的研究方法,多角度对比分析不同学科之间的数据重用行为差异,全方位揭示我国不同学科领域的数据重用行为特征,以期为我国科学数据重用规范的制定提供参考。
1 相关研究
数据重用最早开始于20世纪90年代,关于科学数据重用的内涵研究,仍处于初级阶段,国内外学者至今并没有明确的定义。一般而言,数据重用,也被称为数据复用、数据二次分析[4-6],指的是为了新的研究目的而将历史数据再分析的过程,或者是利用新的研究方法去解决原始的问题而组合成不同的数据集,或者是基于以往的数据而不仅限于原始数据以解决新的问题[7]。目前,关于科学数据重用的相关研究主要集中在数据可重用性、数据重用行为特征、数据重用意愿与影响因素等方面。
对重用数据质量进行评估,是保证数据重用具有价值的重要前提。国内外学者分别从重用数据的获取途径[8]、重用数据的质量评价指标[9-10]等方面进行理论与实证的研究。另外,Yoon从失败的数据重用经验的角度出发,研究发现可重用数据的易用性是数据能否重用成功的重要条件,往往数据重用失败是因为缺少一个开放的数据共享系统[11]。关于科研人员的数据重用行为特征,相关研究主要集中在基因与遗传学[12]、生态学[13]、管理学[14]、经济学[15]、生物医学[16]等多个学科领域,但是由于学科之间的差异性,关于数据重用行为特征也有所不同。科学数据的重用受到众多因素的影响,除了数据的质量[17],数据贡献者或数据重用者的意愿也会影响数据的重用效果。国内外学者发现,影响科研人员数据重用意愿有多重因素中,主要是数据重用者的学科背景[18]、数据素养[19-20]、数据感知力[21-22]等。
科学数据的重用是一个复杂的过程。国外学者相关研究成果较为丰富,从理论到实践都进行了全面探索,国内相关研究更侧重于探索数据重用的实践,应用范围广泛涉及到自然领域和社会领域。我国科研人员多数聚焦于数据重用的意愿与影响因素,对于数据重用行为的本质特征研究较少,而且多是基于特定的某个学科领域,不能准确、全面地了解各学科领域之间的数据重用差异。本研究通过对不同学科科研人员的数据重用行为进行量化分析,有助于了解科研人员的数据重用需求与习惯,发现不同学科的数据重用表现特点,以便于针对性的制定规范化的数据重用标准,提高我国科研数据的重用率,推动数据的开放与共享,实现数据价值的增值。
2 研究方法
2.1数据来源为了全面了解我国科学数据重用情况,本研究以收录在CNKI 10个学科门类的期刊文献为数据采集对象。CNKI将所有学科分为10个门类,每个门类下细分出多个学科,每个学科包含多个期刊。本研究的样本获取方式如下:首先,选择CNKI每个学科门类下的综合学科专题。然后,依据复合影响因子将核心期刊进行排序,选择排名前3的期刊。最后,获取这些期刊2017-2019年3年间每年第1期的所有研究型论文,共1 544篇。其中,《计算机研究与发展》期刊2019年第1期为庆祝创刊六十周年的特别活动,均为综述性论文,因而选择第二期。因整体文献量过大,最后从每种期刊的第一期中各随机选择10篇作为研究样本。其中,《世界经济》《中国农村观察》《中华内科杂志》等期刊的每期发表研究型论文数少于10篇,因而最终获得有效论文891篇。
2.2数据采集目前,基于内容的数据使用标引并没有可靠的自动识别方法,因而本研究采用人工标注的方式采集数据。人工标注数据重用的基本情况,详细编码内容主要包括是否使用数据、数据获取方式、数据是否重用、数据提及方式、独立的数据使用说明模块、数据来源类型等方面,每个编码项具体描述如表1。标注过程中,对于数据集的相关信息通过搜索引擎、数据平台等各种信息渠道获取,确保标注数据的准确性。
编码说明:
①是否使用数据:文中是否使用数据进行分析研究,如果有,编码“是”,如果没有,编码“否”。
②数据获取方式:如果文中的数据是作者自己收集,则编码“自己采集”;如果数据是从公共科学数据仓储平台获取,则编码“公共数据集合”;如果未指出数据获取方式,则编码“不明来源”。如果是同一篇文章采用多种形式获取数据,则标注每一种类别。
③数据是否重用:数据重用是指根据已有数据进行新的分析与研究,即科研人员使用的数据不是自己采集或者实验所得。根据上述定义,判定文献是否数据重用,如果重用已有数据,编码“是”,否则为“否”。
④数据提及方式:重用数据在文献中的提及方式,如名称、参考文献、URL、DOI、注释、其他等。
⑤数据使用声明模块位置:文献中关于重用数据的使用声明的模块,共分为研究设计、数据与方法、实验与实证、其他四种类型。
⑥数据来源类型:数据的类型可能是商业、政府及组织、一般性门户网站、高校及科研机构、期刊论文、其他。如果同一篇文章的数据类型是多样的,则标注每一种类型;如果同一篇文献多次使用同类型的数据,则只标注一次。其他类型如档案文件、媒体报道、企业内刊、纸质出版物等。
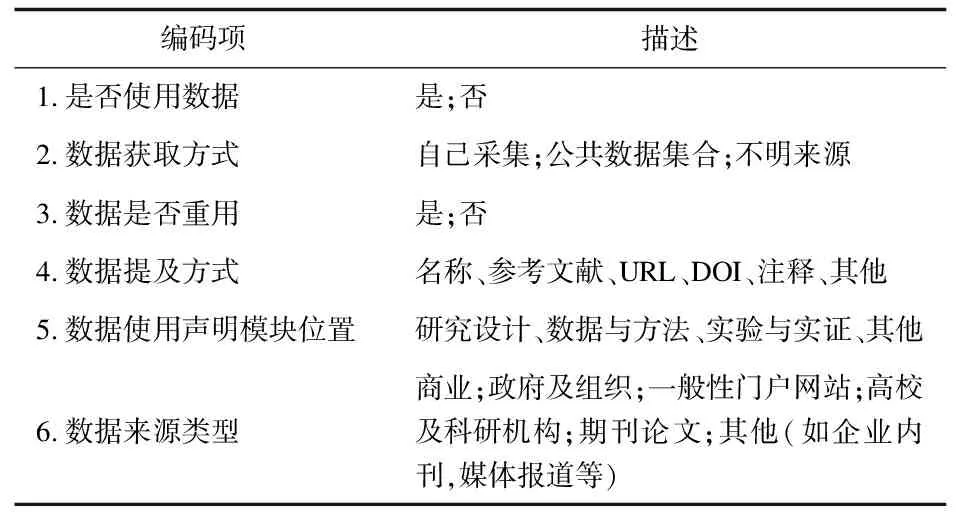
表1 编码表
3 结果分析
3.1描述性统计通过对编码后的文献进行统计分析发现,使用数据的文献共525篇,占总文献量的59%,这也反映出了科学数据已经成为当今科研活动的重要组成其中,仅自己采集获取数据的文献量341篇,占比高达65%。本研究中的数据重用文献共177篇,占总文献量的20%,每年的数据重用文献数分别为47篇(占比16%)、69篇(占比23%)、61篇(占比21%),说明我国科研人员整体的数据重用行为普及率较低。
统计数据显示,科研人员关于重用数据的提及方式比较多样。图2所示,在重用数据的177篇文献中,科研人员主要是提供数据获取平台的“名称”,共有文献171篇(占比97%)。引用是科研人员最为普遍的文献参考形式,但通过引用形式声明数据重用的文献仅有31篇(占比18%),这也说明我国科研人员尚未形成普遍的数据标引习惯。以注释或者URL形式提及数据获取平台的文献分别仅有14篇和8篇,而DOI作为数据唯一识别符号,仅有1篇文献提及。我国科研人员在数据重用过程中缺乏数据引用意识,且引用形式不规范。
在重用数据过程中对数据进行详细的说明是必要的。由于不同的科研人员对于数据使用声明方式不同,因而数据重用声明在文中的位置也有所差异。本研究将数据使用声明模块的标题进行了规范化,主要有研究设计、数据与方法、实验与实证、其他四种类型。其中,数据与方法(占比56%)主要包括数据说明、数据来源、研究方法等模块,在这个部分声明数据使用的文献量最大;其次是实验与实证(占比22%)模块;其他(占比19%)类型主要包括背景概况,或者是全文没有提供数据使用声明,或者是分布在一些描述或统计模块,可见部分科研人员的数据使用声明意识需要提升。
在重用数据来源类型方面,同一篇文献的数据可能来自不同类型的数据平台。其中,来自政府及研究组织(占比50%)类型的数据最多主要是这些数据具有高度的规范性与连续性,能够反映出研究对象在不同的时间段或地区的变化情况,是科学研究的重要数据来源。其次是商业数据(占比33%),商业数据库由于数据量大、结构规范、指标详细等特点,成为科学研究数据的重要来源之一。
3.2学科特点分析虽然科学界对于科学数据的重要性已经达成普遍共识,但不同学科的科研人员对数据重用的认知是不同的,数据重用的行为特征也有所差异。
3.2.1 数据重用情况分析 本研究涉及的10个门类中,7个门类使用数据的文献量超过一半,医药卫生技术和社会科学Ⅱ两个门类的数据使用率甚至高达100%。图1所示,仅有经济与管理(占比62%)一个门类的重用数据文献量超过一半,该领域的研究主要依赖国家或地方机构的官方数据、金融机构公布数据、经济学数据库(CSMAR数据库、Wind数据库等)等平台;基础科学综合(占比43 %)和信息科技(32%)的数据重用情况也相当普遍;农业科技等其它七个门类的数据重用率较低。其中,医药卫生科技、社会科学Ⅱ这两个门类的数据使用率高、数据重用率低,可能是由于科研人员数据重用的感知力受到学科差异的影响,并且缺乏规范的数据重用规则、缺少便捷的数据获取渠道等多种因素造成我国该领域的数据重用实践发展较为缓慢。
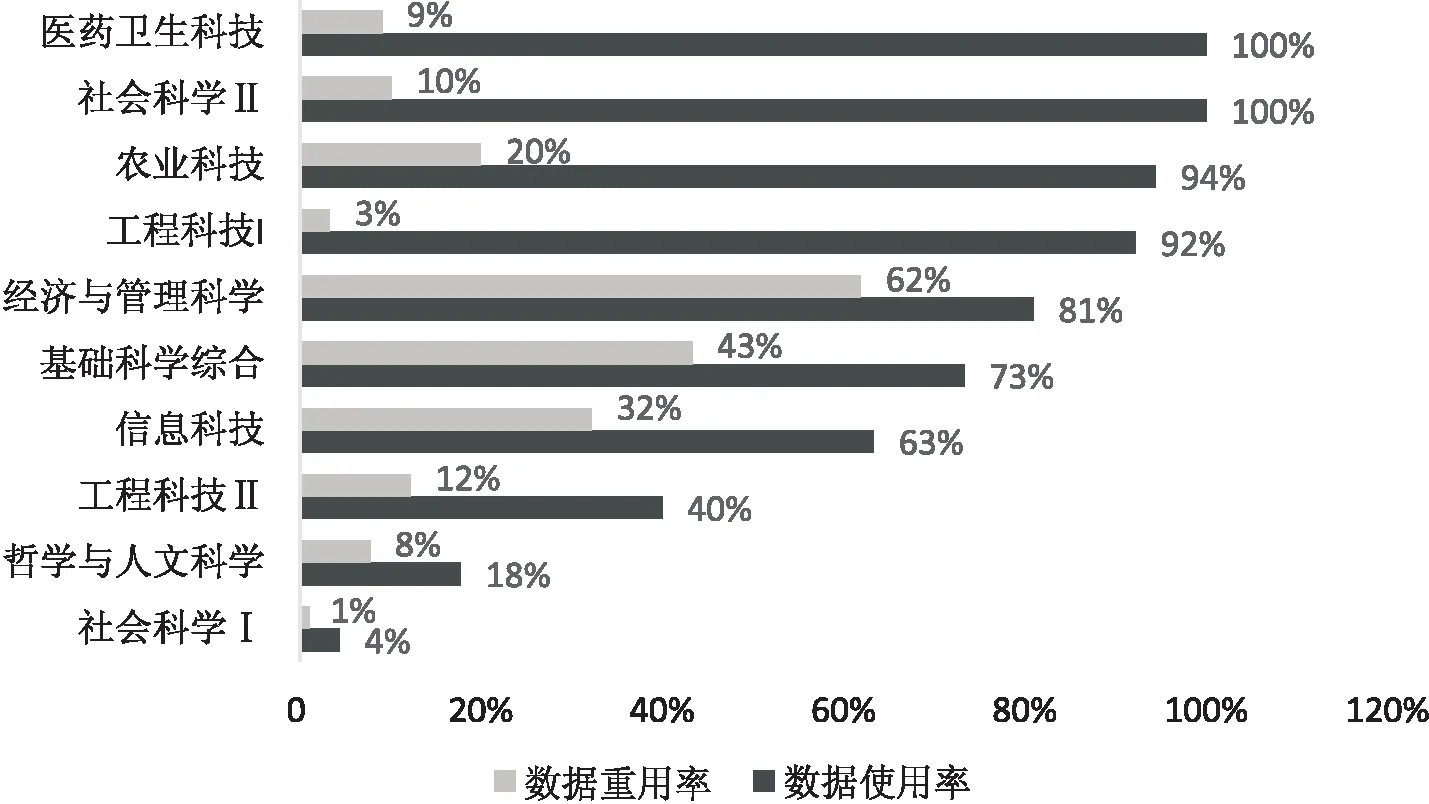
图1 各门类的数据使用与重用情况分布
3.2.2 重用数据提及方式分析 各门类的重用数据提及方式中,数据来源平台的“名称”是重用数据最主要的提及方式,其中的经济与管理科学、社会科学Ⅰ、社会科学Ⅱ、信息科技、医药卫生科技、哲学与人文科学六个门类的“名称”提及率均为100%;引用是目前公认的较为规范的参考形式,但是,只有社会科学Ⅰ和信息科技两个门类的引用率高于50%;注释是社会科学论文写作中的常见方式,社会科学Ⅱ对科学数据的重用也体现了这种特点;URL在国际论文中较为普遍,而我国科研人员使用较少,且使用频率较低;DOI作为国际范围推广的数据参考形式,仅有基础科学综合一个门类使用(3%)。整体来看,我国各学科领域的科研人员在数据参考形式方面存在差异,且形式多样,没有统一的规范。一方面反映出我国科研人员的数据共享意识不强,另一方面也说明制定数据参考标准、提升科研人员数据共享意识的紧迫性。
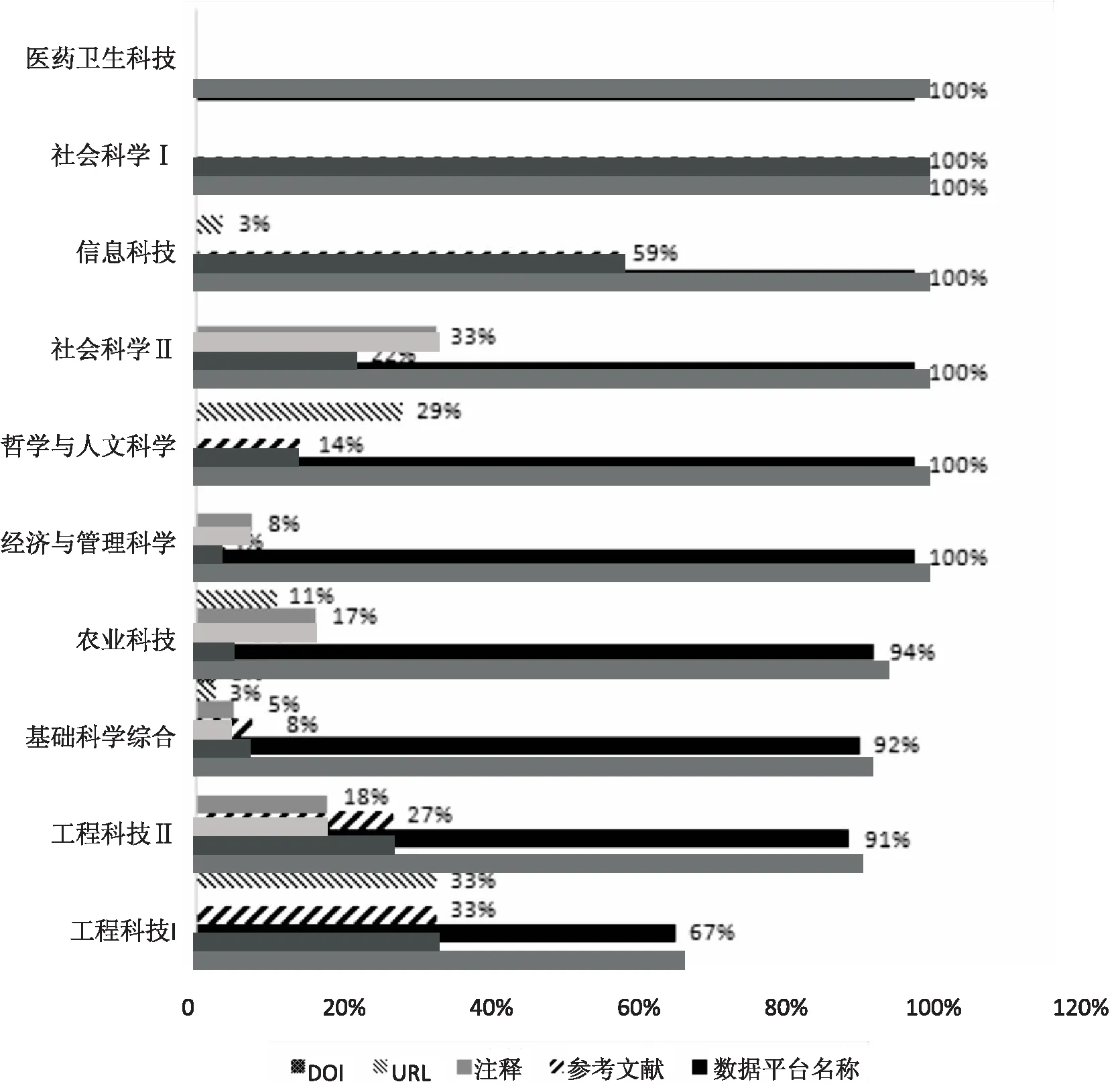
图2 各门类重用数据的提及方式分布
3.2.3 重用数据使用说明模块位置分析 在数据重用的文献中,不同学科的数据使用声明模块的位置分布也有所差异。如图3和图4所示,工程科技Ⅰ和哲学与人文科学在数据重用过程中,所有文献都提供数据使用声明模块(占比100%),模块位置主要分布在数据与方法类型中,两个门类的模块类型占比分别是67%和86%。信息科技、经济与管理科学、基础
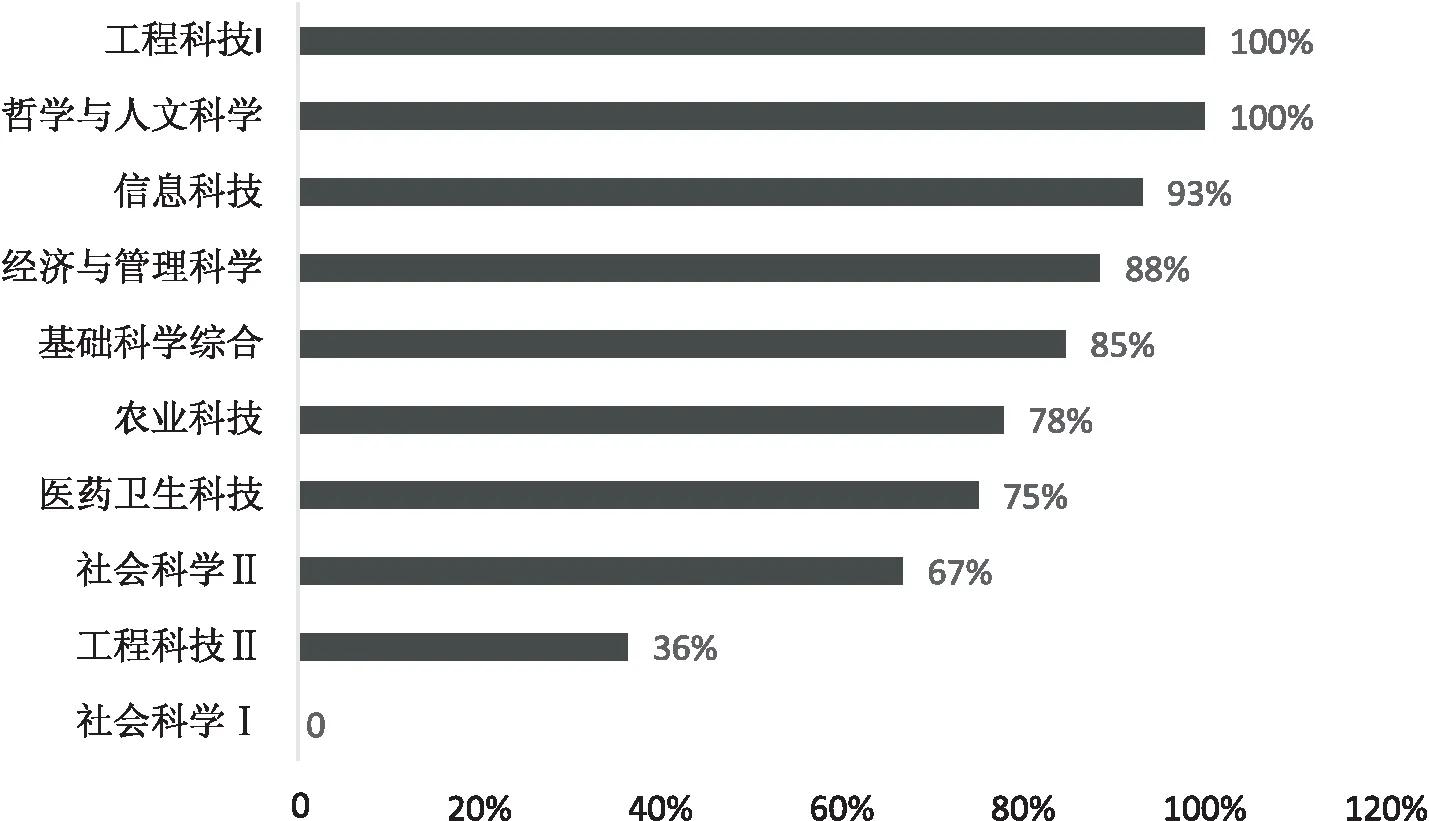
图3 各门类提供重用数据使用声明模块位置的文献占比分布
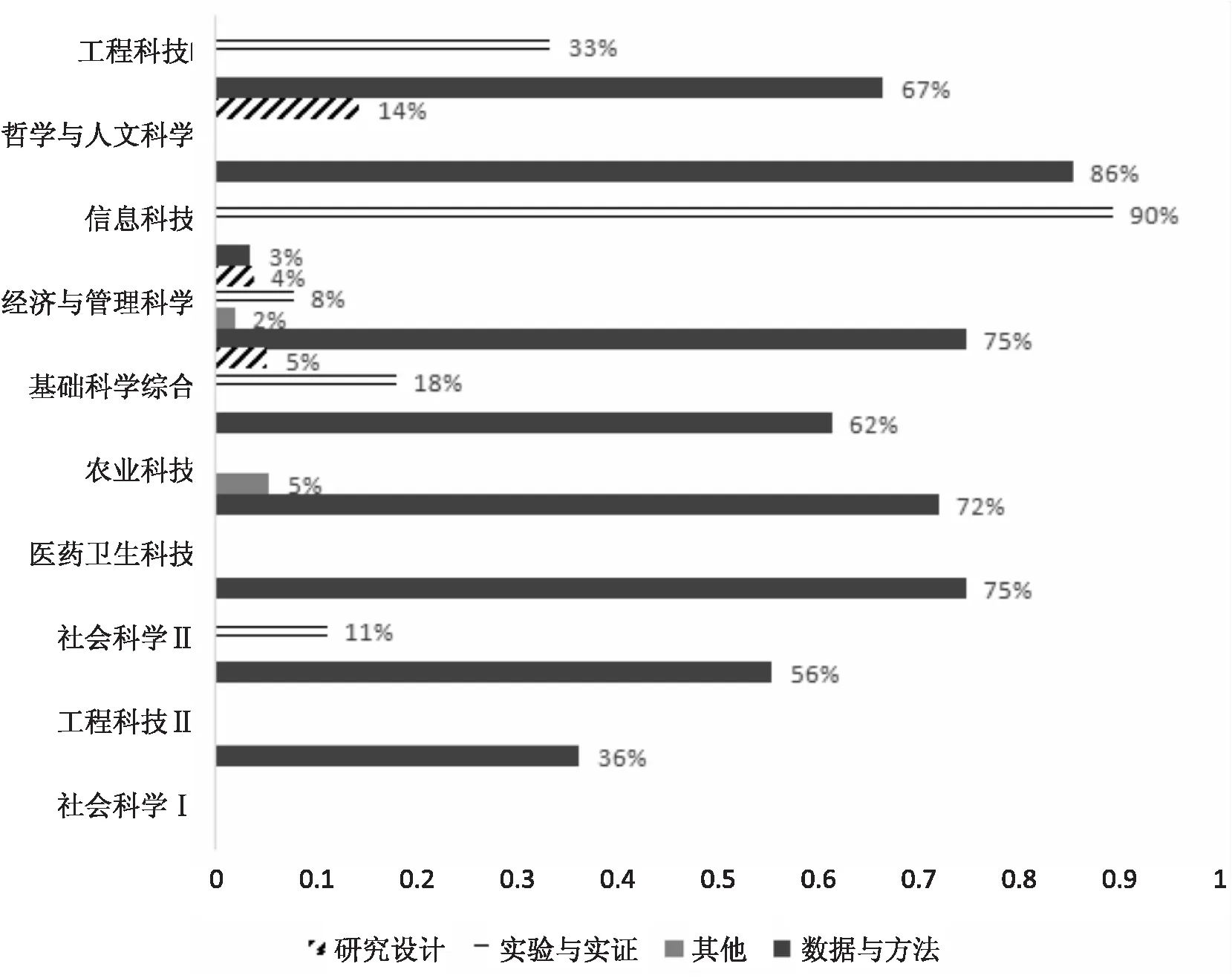
图4 各门类重用数据的使用声明模块位置分布
科学综合、农业科技、医药卫生科技、社会科学Ⅱ的重用数据文献中,大部分都提供数据使用声明模块(占比大于50%),其中,信息科技(96%)主要在实验与实证类型的模块中提及;经济与管理科学(85%)、基础科学综合(73%)、农业科技(93%)、医药卫生科技(100%)、社会科学Ⅱ(83%)主要在数据与方法类型的模块中提及。工程科技Ⅱ中提供数据使用声明模块的文献较少(占比36%),主要分布在数据与方法(100%)类型的模块。社会科学Ⅰ未有文献提供数据使用声明模块(占比0%)。综合来看,我国科研人员在数据重用过程中,对于如何描述重用数据的使用声明,还没有统一的标准。
3.2.4 重用数据来源类型分析 重用数据的可获得性,是影响数据重用的重要因素。图5显示,政府及组织是多数门类的数据获取途径。农业科技和社会科学Ⅱ,数据来自政府及组织文献占比高达89%;医药卫生科技和哲学与人文科学的数据主要来自于商业途径;信息技术的数据主要来自一般性门户网站;经济与管理科学、基础科学研究两个门类的数据主要来源于政府及组织、商业两种途径,这与张莹、戚景琳等学者关于经济学和管理学的结论一致。以上这些较为方便的几种数据获取途径为其他人员重用科学数据提供了便利,然而,医药卫生科技、基础科学综合领域有相
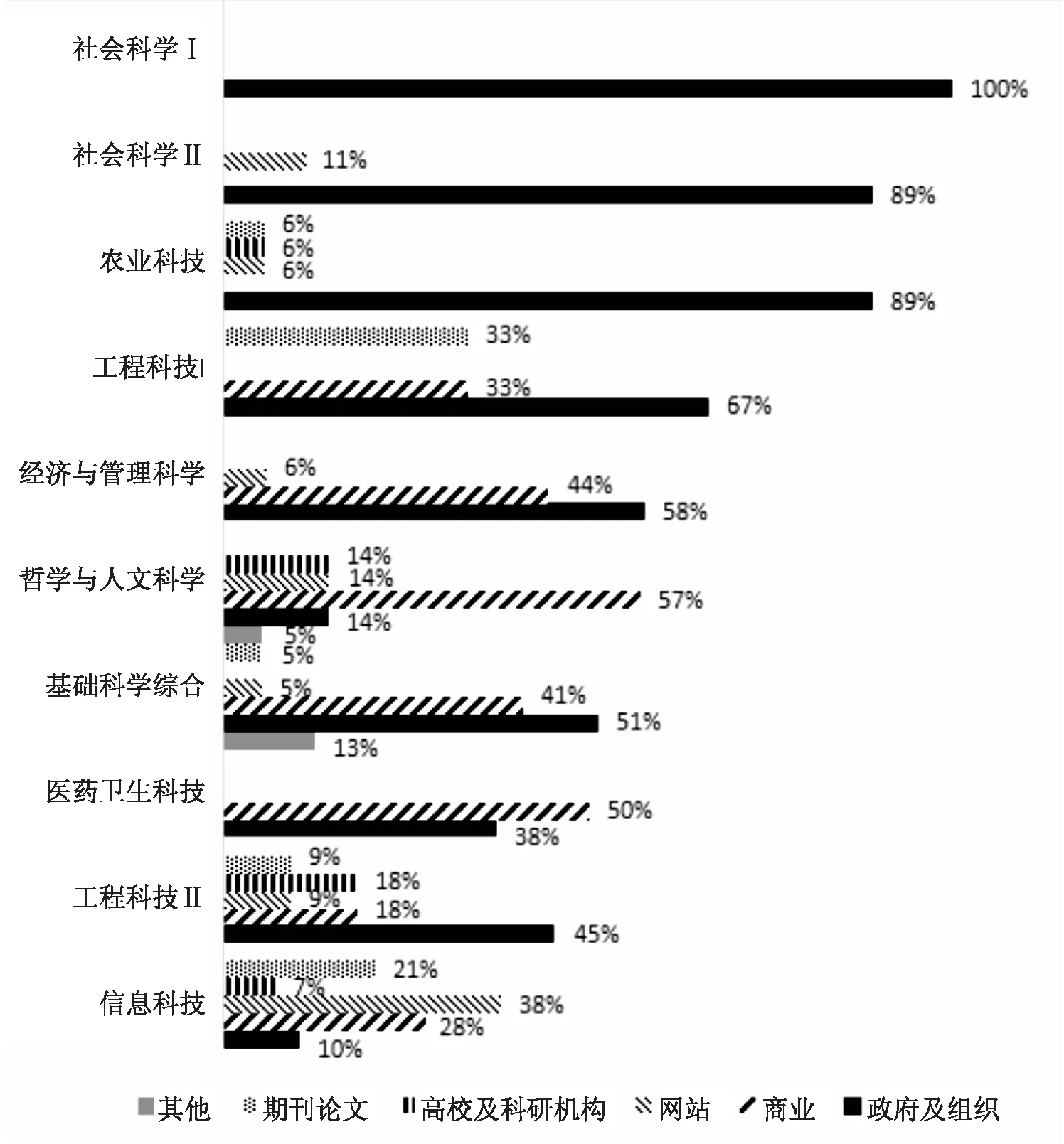
图5 各门类重用数据的来源类型分布
当一部分数据来自于除此之外的其他途径的。由于时间、环境等其他因素的干扰,这种类型的数据对其他人员的数据重用会有所影响。
4 结论及建议
数据重用是数据共享的目标之一,也是数据增值的过程。当前关于数据重用的研究主要是基于某个特定学科,针对不同学科的数据重用行为特征的对比研究较少。本研究采用内容分析法,以CNKI 10个门类的891篇研究型论文为研究样本,探究不同学科科研人员的数据重用行为特征。虽然Mengnan Zhao和Erjia Yan[23]等学者对12个学科的600篇外文文献的统计中并没有提供和本研究对等的统计数据,但从他们的研究中仍然可以发现,不同学科的科研人员在数据收集、引用和整理等方面的情况差异很大。而且,很高比例的科研人员更愿意自己收集数据,而不是重用先前的研究数据。
本研究从重用数据的提及方式、数据使用声明模块位置、数据来源类型等方面,全面揭示不同学科领域下,我国科研人员的数据重用行为特征。研究发现,a.各学科的科研人员整体数据重用率低,亟需强化科研人员的数据重用意识;b.各学科的数据引用方式不一,且数据引用率低,通常只提供数据获取平台的名称;c.各学科的重用数据主要来自政府及组织、商业数据库等途径,还有部分数据来自档案文件、媒体报道等其他途径。d.各学科在数据重用时,大部分都提供数据使用声明。
从之前的研究结论可以得知,目前国内外的科研人员对于数据重用的态度,整体呈现出认可度高但是实践水平低的现状[24-25],本研究对所有学科的分析数据进一步印证了上述结论。另外,不同学科领域的数据重用强度是不同的,这也是由学科本质特点、科研环境决定的。其中,经济领域的数据重用程度最高,这与戚景琳、林奇秀等学者的研究结论一致。经济学作为重要的实证性社会科学,该领域的重用数据来源最主要是政府及组织,并有少部分数据来源于个人或研究团队的期刊论文、著作等。而Piwowar、Vision、Fear等学者发现,国外的科学研究大多使用个人或研究团体的数据,这可能与各国的科研环境以及科学意识有关。
通过对不同学科的数据重用行为特征的研究,可以全面了解我国数据重用现状,同时为后续的数据重用行为特征探索提供借鉴,本研究也存在一些不足,比如选择期刊较少,不能够全面覆盖所有细分学科、只关注文本内容,未能精确对文本以外的情感、动机等因素进行分析研究。在今后的深入研究中,需要扩大研究样本、结合多种分析方法,更加全面、准确地分析科研人员的数据重用行为特征。
