基于Hbase的车联网海量数据存储
2021-07-19邬少飞
李 星 邬少飞
(武汉工程大学计算机科学与工程学院,湖北 武汉 430000)
1 引言
在当前的交通运输领域中,车联网(IoV) 属于物联网(IoT)内最典型的应用,但因汽车的使用存在周期性,使得数据的产生也存在周期性,汽车数据的海量产生会固定出现在早高峰和晚高峰期间。每天汽车产生的海量大数据存储达到了日增数据15TB,而如此巨量的数据在每日的产生并不是均匀分布而是周期性的产生,在短时时间里面会产生大量的数据。为了应对数据波动性产生对集群存储性能的影响,部分研究者从算法上希望能够解决Hbase 数据不平衡的问题,比如通过对预先对数据进行采集分析后再进行数据的分配[1,2],还有对Hbase的原有算法进行优化,这些方法很好地解决了数据的不均衡问题,实现了Hbase的最大化利用,但是面对TB级别的数据其对cpu和集群性能的损耗是巨大的。部分研究者对数据进行了预处理[3-5],通过对数据的特征进行提取,预估不同分区的负载情况,然后提前对region 进行拆分或是保证热点数据分布在不同的分区,保证Hbase的负载平衡,同样面对TB 级别的数据,其cpu 的消耗成为了新的瓶颈。近些年来,面对大数据量的存储,高并发的场景,普遍会采用Kafka 作为中间件,因为Kafka 作为消息中间件所采取的消息消费模式是发布-订阅的消息模式,面对不同的消费者,Kafka的分布式消息读取可以很好地支持到它们,相对于以往的消息队列,Kafka 单点的生产者和消费者拥有显著的优越性,能够做到百万级的读写速率,其吞吐量更高,性能更加优越,同时它能将数据写入磁盘的同时将数据复制到集群里面,这些处理不仅保证了数据的持久化更使数据的容错性得到了保障[6]。
基于以上背景,为解决海量数据存储在Hbase中的存储问题,本文研究出一种基于Hbase的海量数据存储方案。考虑到车联网数据的特殊性本文采用了相应的行键设计和预分区[7-11]。
2 数据预处理与表设计
2.1 数据预处理
研究采用的数据来自实际传输进来的报文,原始数据包包含每辆车采集的该车编号信息、采集时间、各个部分的埋点信息等480个信号。经过对原始数据的分析,确认了不同数据拥有不同的价值,以及不同数据的归类不同,而大量的信息让处理的成本更高,为了提高这些信息的利用价值和保证核心数据的不缺失,需要对数据先进行简单的处理后再存储进入Hbase数据库里面,处理的具体步骤如下:
(1)剔除缺失数据,缺失数据指的是当上传的时候有些车辆的信息没有被录入到系统里面,当查询该车辆或是该种车架信息的时候,该车辆的信息不存在,这些信息将无法录入数据库中。
(2)区分不同状态信息,汽车数据中有部分是属于报警数据,在这些数据在中间件处理的时候就需要被识别出来,然后及时通过报警系统将数据上传,关于这部分数据的存储需要先通告报警系统后再录入系统。
(3)剔除失效数据,当数据传输过程中存在数据的累计,如所处环境的网络信号差,导致后期上传的数据的接收时间相同,对于这种数据仅取发送时间距离当下最近的数据,对于其他数据不进行存储,以防数据之间的冲突。
2.2 行键表达式及行键生成算法
对于数据库的优化,不可忽略的部分就是进行预分区以及对行键进行优化,针对不同的数据结构需要采取的分区方式和行键的设计都是不同的。面对车联网的海量数据,行键的设计和预分区都是十分重要。在对行键进行设计时,会对核心字段进行简化并在最开始就约定实现的规则,在后期就依循着规则来生成行键。选取的行键要求能对存储和查询存在一定的优化效果,而在当前的大数据量存储的系统中,核心是进行存储的优化。面对行量数据存储的场景,本文选择了将核心字段处理后拼接到行键里面,同时对行键进行散列化,使行键能够尽可能地散落在不同的Region 里面,避免热点现象的出现。
为了达到这样的存储效果,当前系统采用的行键设计方案是:
第一,对车辆的vin码的前四位进行了md5处理,将数据散列开;
第二,在后面添加车辆的vin码(20位);
第三,添加数据类型(15 位)再加上采集时间(18 位,前14 位为年月日时分秒,第15 位为N 表示设备上没有上传采集时间,由系统自动加上当前时间作为采集时间);
第四,加随机数(4位,解决同一时间上传一个数据包,里头包含两个告警数据导致数据覆盖的问题)。
最终的行键设计方案如表1所示。

表1 行键最终方案
2.3 表的设计和预分区
相对于其他的数据而言,车联网的大批量数据更多是直接存储进入Hbase中,其90%以上的操作都是写入操作,而且数据量极其巨大,面对这样的场景可以直接将所有的数据存储于一个列簇里面,将核心的数据如车辆定位、定位时的详细时间、汽车移动速度、汽车的油量、汽车的里程数等数据封装入一条Json字符串里,当需要处理时再提取字符串进行处理,这样就仅需要一个列,可以极大减轻存储的压力。
第三,好教育要有一支数量充足的高素质的校长、教师队伍。《国家教育中长期教育改革与发展规划纲要(2010 —2020年)》指出,有好的教师才有好的教育。高素质、专业化的校长队伍与师德高尚、业务精湛、充满活力的教师队伍,是构成好教育的最重要因素,也是办好教育的第一资源。校长要敢于担当,有教育情怀,有办学思路,懂管理,全心全意为学生着想、为教职工服务。好教师不仅要有较高的学历,更要有专业精神和正确的教育观、学生观、质量观。
当创建一个Hbase表的时候,如果不指定预分区Region,默认是只会创建一个Region。当海量数据写入Hbase 的时候,所有的数据都会写入默认的Region里面,直至Region的空间消耗完,然后进行拆分操作,将一个Region 划分为两个小的Region。这样处理将会造成两个问题:一是数据存储在单一的Region 中,更容易出现单节点故障,这会影响到入库的性能;二是该行为会导致磁盘的拆分,而拆分操作将使大量的集群I/O 资源被消耗掉。为了解决这些问题,本文结合Rowkey的设计确定预分区的方案。选择在全表创建10个分区,分区的划分使用HexStringSplit算法实现。
3 数据处理优化
数据实时处理是车联网海量数据存储的核心层。车联网数据的处理对于实时性的要求是极强的,在一定时间里面若数据没有处理完全,那么这一帧数据就会失效,因为只有满足实时性才能实现对车辆的实时监控,并做出及时的反馈。面对传统平台处理海量数据存在的高延迟、高并发问题,本文选择了开发新的PVO 中间件担任Kafka 到Hbase 中间的数据实时处理工作。
车载终端采集的数据是实时、不间断的,要求实时处理层稳定可靠、不宕机。而PVO层的处理能力是有限的,如果不进行获取消费数据的限制可能会导致数据出现延时,当前数据还未处理完全,后面的数据又进来了,当完全堆积在PVO 的内存后会导致程序压力过大,降低程序的运行速度,严重情况下甚至会导致宕机。为了处理这个问题,选择在中间件添加计数器进行数据消费的控制。
详细处理流程如图1。这里首先对PVO 的性能进行压力测试,待内存消耗完,测试出其最大的承受数据量为DEFAULT_MAX_BLOCKING_SIZE。PVO 会在对Kafka 数 据进行消费的同时用Scheduled 算法对消费数据进行监控,当大流量涌入并超过最大承受量的时候就会进入等待期同时进行警告,等待期满发现内存释放出来后会立刻继续进行消费。此外,当出现网络波动等问题时也会导致数据处理延迟,导致数据的堆积,针对这样的问题,在处理数据前还会调取Hbase的数据存入耗时,当前面的数据存储时间过长时,会先让进程等待,同时进行警报处理,方便后期对问题进行排查和维护,直到等待期满后再重复进行判断,判断通过后再进行数据处理。
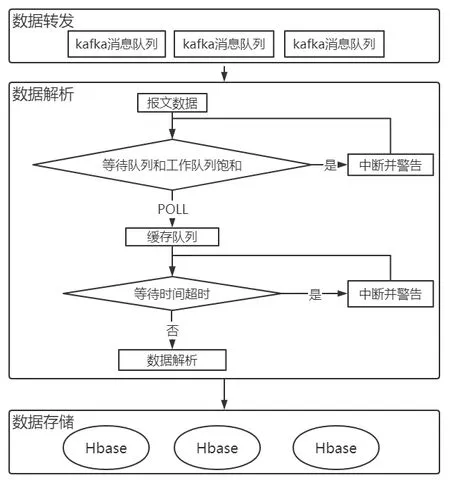
图1 数据处理流程图
4 实验与结果分析
为了验证上述Hbase表设计和数据处理优化的性能,通过实验对其进行评测。实验使用的操作系统均为centos 6.10,所搭建的Hbase 集群部署在Cloudera Manager 上面,版本为5.13.1。CDH 版本为5.13.1,hadoop 版本为2.6.0,HDFS版本为2.6.0,Hbase 版本为1.2.0。Hbase 集群的详细配置如表2所示。

表2 集群配置
4.1 行键设计方案的性能验证
为确认当前设计的Hbase行键方案是有效的且能够提升存储的性能,这里采取了相同的数据集进行输入测试,控制数据集是相同的,数量也相同,唯一变化的就是行键是否进行设计,详细的测试流程如下:
(2)每组对比实验采用随机模拟的报文数据;
(3)每组实验重复三次,取最终存储效率的平均值绘图。
按照以上的策略测试有行键设计的方案和没有行键的设计方案,以Cloudera Manager 中对Hbase 写数据的监控数据作为对比,通过对比两者的差异来比较两种设计方案的优劣。实验结果如图2所示,横轴为数据开始输入的时间,纵轴为一分钟内平均的数据请求数量。

图2 存储效率对比
由图2可知,在前两分钟里面数据的写入会快速达到最大峰值,然后就在该峰值处波动,直到数据存储完毕没有数据录入的最后两分钟数据写入才会大幅降低。同样是写入100w数据,两者的时间消耗不同,但是两种方案都呈现了性能达到峰值后的稳定性,这显示了Hbase对于海量数据存储的适用性,符合长期高性能稳定的运行要求。同时,图2中也可以看见无行键设计的方案每秒请求数在3w左右就达到了峰值,而有行键设计的方案直到6w 才到达数据存储的峰值。实验说明,在Hbase的表设计中,是否针对存储做合理的行键设计,对数据的存储性能影响较大。
4.2 中间件优化性能验证
在所搭建的平台上对上述的优化进行测试,实验数据来自于内部的报文模拟器。为验证优化后的中间件拥有更好的性能,采用如下方法进行测试:
(1)启动报文模拟器稳定向Kafka发送报文;
(2)开启PVO中间件拉取Kafka的报文并对报文进行处理;
(3)将数据存储到Hbase里面;
(4)通过Cloudera Manager的读请求监控观测数据处理的稳定性;
(5)关闭报文模拟器后切换PVO 中间件为优化后的PVO中间件;
(6)重复步骤一到步骤四。
PVO优化前后的监控结果如图3,可以很清晰地看到相比起优化前的数据存储,优化后的数据存储的稳定性更强。

图3 请求数目对比
5 结语
车联网在未来的交通出行扮演的角色越来越重要,对车联网数据的处理也有着更大的需求。本文针对采集自海量汽车的详细数据,提出了一种基于Hbase对数据存储性能进行优化的中间件控制方案。该方案对原生的PVO中间件添加计数器限流的功能,该方法在实验中展现出了更为优越的稳定性。该方案通过对Rowkey和表结构的设计使得存储性能得到极大的提升。在Hbase的集群上进行测试,相对于未进行设计的Rowkey方案,优化后的Rowkey方案展现了在存储效率上的优越性。
