CSA-FFCM算法在玉米种子芽根长度自动化测定中的应用
2021-07-19马启良胡水星林冬茂贾良权祁亨年
马启良,胡水星,林冬茂,贾良权,祁亨年
(1.湖州师范学院 信息技术中心,浙江 湖州 313000;2.湖州师范学院 信息工程学院,浙江 湖州 313000;3.湖州师范学院 研究生院,浙江 湖州 313000)
0 引 言
种子发芽受各种因素影响,如温度、湿度、化学引发剂、菌类等.在不同条件和时间段内,种子芽根的生长速度明显不同.为获得在不同条件下和时间段内种子芽根的生长情况,既要进行大量的对比实验,又要在特定条件下对种子的发芽情况和芽根生长情况进行测量统计.而计算种子的发芽势、发芽率、发芽指数和活力指数等指标,又需要做大量且重复的测量和统计工作.目前的操作方法有通过人工用线对幼苗根芽长度进行测量,也有利用定制的标有刻度的专用实验设备进行测量,然后人工读取数据[1-2].这些方法虽能达到预期的实验效果,但操作工序烦琐,且对种子的芽根有一定损伤,不利于发芽实验的可持续观察,工作效率低下.
目前,有将种子置于培养试纸上培养的方法,但这种方法的种子放置密度较高,芽根长出后,每粒种子的芽根基本都交织在一起,很难从芽根系图像中提取芽根.从发展进程看,种子芽根系图像分割主要有手动分割、半自动分割和自动分割3种[2-4].手动分割准确度高,但费时费力;半自动分割很难对图像进行批量处理;自动分割虽能批量处理图像,但准确度低于手动分割.在处理种子芽根系图像时,为对芽根长度参数进行分析,首先需要对种子芽根系图像进行准确分割,才能提取出种子芽根系部分,图像分割效果的好坏直接影响种子芽根长度统计的准确性.因此,种子芽根系图像分割是难点也是重点.
本文主要从三方面给出解决方法:一是玉米种子芽根苗图像的分割,重点介绍模糊C-均值聚类算法(FCM)[5-10]、基于直方图的快速模糊C-均值聚类(FFCM)算法[11-13]和基于乌鸦搜索算法的快速模糊C-均值聚类算法(CSA-FFCM)[14-16],并根据聚类结果的隶属度值确定分割阈值,从而对图像进行分割处理;二是在二值图像中识别出每粒玉米种子芽根区域并进行个数统计;三是对每粒玉米种子芽根区域的二值图像进行细化操作,计算玉米种子芽根长度.
1 实验条件与方法
1.1 实验条件
本研究在64位Windows 7操作系统下,通过USB高清摄像头进行玉米种子芽根图像采集,利用Visual C+软件和OpenCV库实现相关算法研究.由于前期培养时玉米种子放置得较密集,导致玉米种子芽根交织在一起.为进一步研究,在放置玉米种子芽根苗时保持种子芽根间相对独立,见图1.

图1 实验室中玉米种子芽根苗图像Fig.1 Image of corn seed bud and root in the laboratory
1.2 玉米种子芽根长度分析方法
在同一环境下,发芽阶段的种子芽根长度能够反映种子生长的好坏状况.为能快速、准确地获取玉米种子的芽根生长情况,本研究将基于CSA优化的FFCM算法用于玉米种子芽根图像的分割和细化,并统计玉米种子芽根长度.算法流程如图2所示.
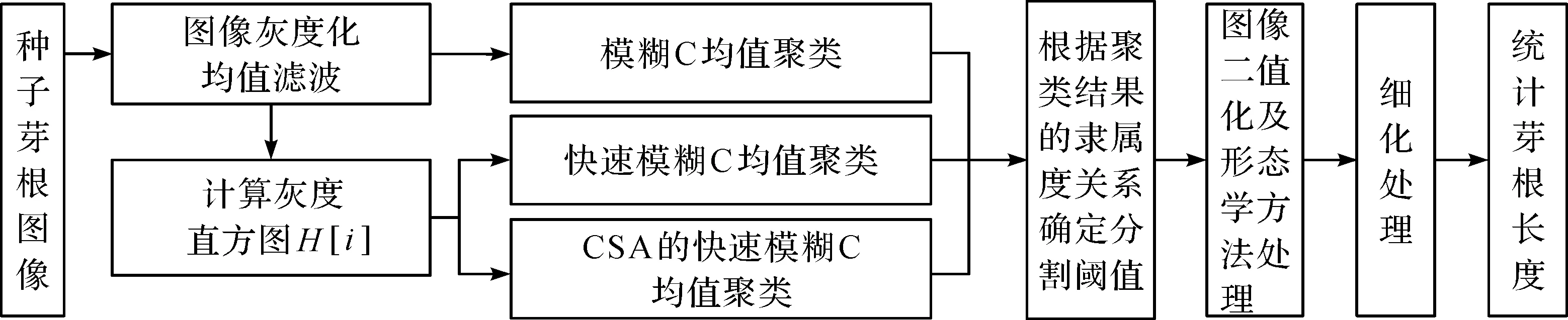
图2 算法流程Fig.2 Flow of algorithm
2 基于CSA优化的快速C均值聚类算法
近几年,自然启发式优化算法在聚类问题上得到大量应用,以克服传统聚类算法对聚类中心初始值选择过于敏感,且易陷入局部最优的问题[15].自2016年Askarzadeh提出CSA算法[16]以解决约束工程优化问题后,CSA算法得到了广泛应用.王丽婷等用该算法优化SVM参数[14];Ahmed等利用该算法优化FCM算法,用于农作物的识别[18];Pankaj等用该算法优化基于Kapur熵的多级阈值的选优[19];王颖等用该算法解决机器学习在特征选择中的不足[20],且验证了CSA优于其它优化算法(如粒子群优化(PSO)、差分进化(DE)、灰狼优化器(GWO)、蛾-火焰优化(MFO)和布谷鸟搜索(CS));宋涛等改进PSO算法优化核SVR的锂离子电池剩余寿命估计[26].
2.1 FCM聚类算法
FCM算法最早是由Dunn[5]根据RusPini定义的模糊划分概率提出的.Bezdek对Dunn的目标函数进行改进,得到了每个样本点对所有聚类中心的隶属度,从而决定对样本点的类属进行自动分类[6].目标函数定义为:
(1)
其中:U为隶属度矩阵;V为聚类中心集;D为数据集中数据总个数;N为设置的聚类中心数(2≤N≤D);m为加权指数,一般取值为2;uij为数据点xi到聚类中心cj的隶属度,数据点xi到所有聚类中心的隶属度总和为1.如式(2)所示:
(2)
其中,dij表示数据点xi到聚类中心cj的欧几里得距离.如式(3)所示:
(3)
FCM算法的实现步骤如下:
步骤1:初始化隶属度矩阵U,使其满足式(2).
步骤2:输入灰度图像,根据式(4)计算N个聚类中心点cj,j=1,2,…,N.
(4)
步骤3:根据目标函数式(1)计算目标函数值.如果目标函数值小于某个确定的阈值或相对上次目标函数值的改变量小于某个阈值,则算法结束.
步骤4:根据式(5)计算新的隶属度矩阵U.返回步骤2,继续迭代循环,直到算法结束.
(5)
2.2 基于直方图的FFCM算法
在标准的FCM算法中,要计算图像中每个像素到所有聚类中心的隶属度,并在算法收敛前更新一次聚类中心,需要对所有像素的隶属度进行再次计算,直至算法结束.但其忽略了图像本身所具有的数据冗余特性.当输入图像的分辨率增大时,算法的时间复杂度会迅速增高,从而导致算法效率低下.因此,使用图像的灰度直方图代替原始图像,利用图像中存在的大量冗余数据去除冗余数据,能避免大量相同灰度值隶属度的重复计算,有效改善FCM算法的计算效率,且不受输入图像大小的限制,大大降低FCM算法的复杂度[7].
该算法首先对输入图像进行均值滤波处理,统计滤波后图像的灰度直方图,获取最大灰度值Imax和最小灰度值Imin,再在Imin和Imax之间随机选择两个聚类中心,根据式(5)计算直方图每个灰度级的隶属度.在计算目标函数值和更新聚类中心时,对FCM算法的式(1)和式(4)进行修改,如式(6)和式(7):
(6)
(7)
其中:H[i]为图像的灰度直方图;i为直方图的灰度级(0~255).
该算法在运行速度上远超FCM算法.但在初始化参数时是根据一定经验标准选择的,如果初始聚类中心位置设置为接近局部最优值,算法将收敛到一个局部极值.为达到更好的分割效果,只能通过多次试验后进行相对的选择,否则将无法自动收敛到全局最优值.因此,考虑使用CSA来优化FFCM算法.CSA算法具有获得全局最优值的优势,且很难落入局部解[12].
2.3 CSA优化的FFCM算法
2.3.1CSA算法的基本原理
乌鸦搜索算法(CSA)是一种全局优化算法,是模拟一群乌鸦觅食的智能行为.乌鸦通过跟踪其它乌鸦,发现其隐藏食物的地方,一旦它们离开,将窃取它们的食物.但如果其它乌鸦发现自己被跟踪,它们将会根据自己窃取食物的经验来避免自己成为受害者,从而选择最安全的路线来保护自己的食物.CSA算法的详细步骤如下:
步骤一:在n维搜索空间中,初始化所有乌鸦的位置X及最佳存放食物的位置M,以及乌鸦的意识概率AP和飞行长度FL.
步骤二:利用式(6)的目标函数评估每只乌鸦所在位置的好坏.
步骤三:更新所有乌鸦的位置信息.例如乌鸦i寻找新的位置,随机选择另一只乌鸦j进行跟踪,如果没有被乌鸦j发现,乌鸦i将根据式(8)得到新的位置.其中,rd为一个在0~1之间均匀分布的随机数;Mj为乌鸦j的最佳存放食物位置;Xi为乌鸦i的位置.
(8)
如果乌鸦i被乌鸦j发现,乌鸦j将随机选择一个位置来愚弄乌鸦i.此时乌鸦i将根据式(9)得到新的位置.
(9)
因此,在每次迭代中,将根据式(10)更新位置信息.其中,rd、rj为在0~1之间均匀分布的随机数;Xi,iter为在迭代iter时乌鸦i的位置;Mj,iter为在迭代iter时乌鸦j的最佳存放食物位置.
(10)
步骤四:在得到所有乌鸦的新位置后,通过目标函数评估新位置的可行性.如果目标函数值小于上一次的值,则更新乌鸦的最佳存放食物位置M,如式(11)所示.其中,f(·)为式(6)的目标函数.
(11)
步骤五:如果终止条件满足或迭代结束,最优解将是目标函数值最小的乌鸦所存放食物的位置M.否则,返回步骤三.
2.3.2 CSA优化FFCM算法
FFCM算法的结果易受聚类中心初始位置的影响.本文引入CSA全局优化算法,解决FFCM算法参数初始化问题.该过程主要包括3个阶段:一是初始化CSA相关参数,包括乌鸦的种群大小、意识率、飞行步长、问题维度和最大迭代次数,其中问题维度表示所需的聚类中心数,以聚类中心的位置作为乌鸦的位置;二是CSA算法对乌鸦位置信息的迭代选优;三是在得到最优的乌鸦位置后计算每个灰度级的隶属度,再根据隶属度的大小确定每个灰度级归属的聚类中心.对灰度值大的一类取所有灰度级最小值,对灰度值小的一类取所有灰度级最大值,再将最大值和最小值的平均值作为图像分割的阈值,以达到自适应阈值的目的,为自动化测定奠定基础.
3 结果与分析
3.1 玉米种子芽根图像分割
利用上述算法分别对两幅图像进行聚类分析.初始聚类中心都以随机方式进行初始化.3种算法的聚类结果见表1.CSA-FFCM算法的相关参数初始化如下:乌鸦种群数量为20只,问题维度为2,最大迭代次数为300,飞行步长为1,意识率为0.15,乌鸦的初始位置是在图像直方图最大值与最小值之间随机生成的2维向量.CSA-FFCM算法的详细流程见图3.

表1 FCM、FFCM和CSA-FFCM算法的聚类结果

图3 CSA-FFCM算法详细流程Fig.3 Detailed process of CSA-FFCM algorithm
由表1可见,FCM算法的处理时间最长,且受图像分辨率的影响,分辨率越大处理时间越长;FFCM算法利用直方图优化FCM,处理时间短,且不受图像分辨率的影响;本文提到的CSA-FFCM算法在FFCM算法的基础上进行优化,解决了FCM、FFCM算法易受聚类中心初始位置影响的问题,且用时较FCM短.3种算法收敛的聚类中心基本一致.3种算法对玉米种子芽根图像的分割结果见图4.

图4 CSA-FFCM、FFCM和FCM算法的图像分割结果Fig.4 Image segmentation results of CSA-FFCM, FFCM and FCM algorithms
3.2 玉米种子芽根二值图像处理
从图4的分割结果可以看出,玉米种子芽根整体的连通性、边缘的平滑性等达不到对图像分析和识别的效果.本文对CSA-FFCM分割结果做进一步处理,使其更具有连通性和平滑性,即用数学形态学方法[17,21-22]对二值图像先后进行膨胀运算和腐蚀运算,并对图像进行平滑处理(图5(a)),同时去除二值图像中的小连通区域(图5(b)).
从处理后的二值图像中分割出每株玉米种子芽根区域,再分别进行细化处理.细化的目的是抽取芽根图像的骨架,让其像素宽度为1,以方便后续的统计分析.本文采用Hildich细化算法[23-25],细化处理结果见图5(c).
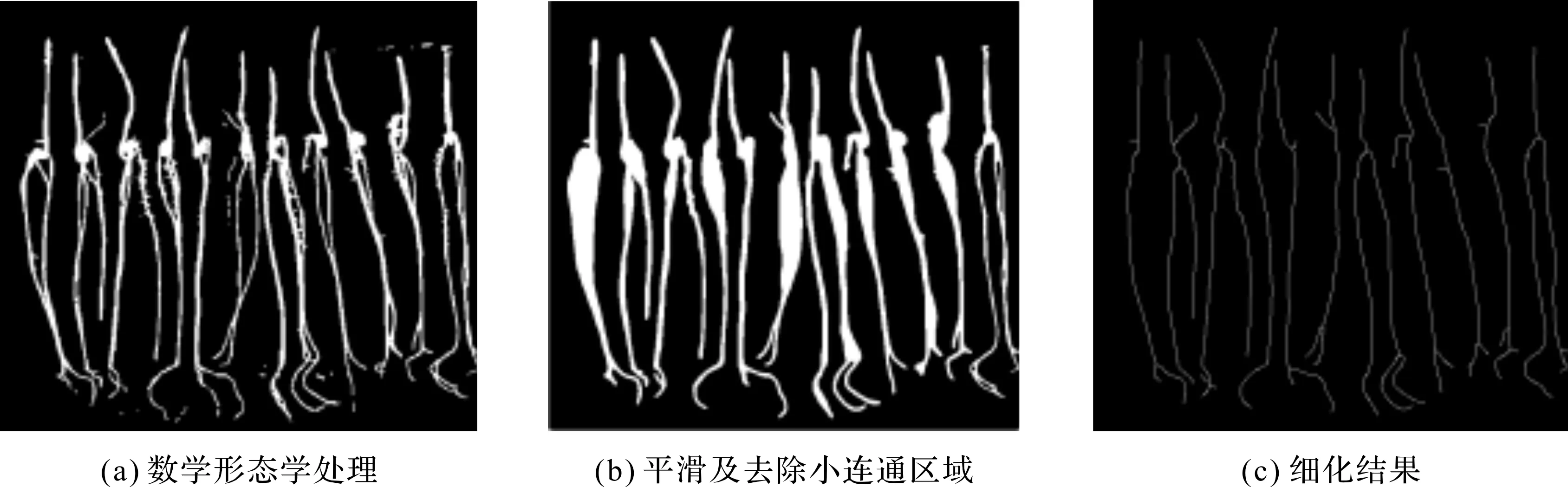
图5 种子芽根图像的算法处理结果Fig.5 Algorithm processing results of seed bud root image
原图的二值化图像在细小的根尖处出现断裂、不连续等情况,经过形态学方法处理后,图像得到明显增强,且不连续的情况得到有效改善;经平滑处理并去除断裂不连续的小连通区域后,目标更加显著,有利于目标的分割与统计.每个目标经过细化处理得到芽根骨架图.
3.3 玉米种子芽根长度统计
经细化处理后,每粒玉米种子根芽区域只保留像素宽度为1的骨架结构,且是连续的.此时图像上的像素点主要分为3种类型:端点、分支点和连接点.端点表示该像素点的8邻域只有一个像素与之相邻,在骨架图中表现为起点或末端点.分支点表示该像素点的8邻域有3个或3个以上的像素点与之相邻,且这3个像素点相互间不存在4邻域的情况,在骨架图像中表现为分叉点.连接点表示该像素点的8邻域有2个像素点与之相邻,在骨架图中表现为中间点.
由于玉米种子芽根图像的特殊性,在统计长度时从骨架图左端开始逐一对每个芽根骨架进行统计,找到顶部末端后开始往下搜索,统计骨架图顶部端点到所有分支末端点的长度,以最长的分支为芽根的总长度.本文通过PS测量工具对图片中11株种子芽根长度分别进行测量,并将其作为标准长度对采用本文方法自动检测的结果进行误差分析,结果见表2.

表2 两组图像中芽根手工测量长度与本文方法自动测量长度比较
从表2可以看出,采用自动测量的玉米种子芽根长与采用PS测量的玉米种子芽根长的误差均小于5%.
4 结 论
CSA-FFCM算法首先通过乌鸦的智慧搜索能力,找出最佳阈值并分割种子芽根目标;再在识别出每株种子芽根区域后,分别对其进行细化处理,得到玉米种子芽根的骨架图;最后自动测量测得玉米种子芽根骨架的长度.该方法由于利用了直方图,其处理速度对图像分辨率大小不敏感,因此要尽可能地通过提高拍摄图像的分辨率来增加测量精度.本研究选择玉米种子的幼苗进行算法研究.实验结果证明,该算法应用于玉米幼苗芽根长度的计算是可行的.本研究为后期自动化测量设备的设计和实时批量处理种子芽根图像提供了强有力的理论和技术参考.
