计及排斥力损失的密集堆垛钢管识别方法∗
2021-07-16郁云,曹潇
郁 云,曹 潇
(1.南京信息职业技术学院数字商务学院,江苏 南京 210046;2.中国电力科学研究院有限公司新能源研究中心,北京 100192)
不锈钢管是一种中空长条圆形钢材,作为钢铁厂的成品产品在石化、医疗轻工业和建筑业得到广泛应用。建筑行业和钢管租赁行业目前主要采用人工计数法对钢管进行计数。堆垛的钢管规模通常在500 根~1 500 根不等,整个人工计数过程耗时长、效率低,劳动强度非常大。研究用于钢管生产厂家和钢管租赁厂家,通过拍摄图片进行钢管自动识别方法,可以减轻计数工人的劳动强度,提高计数效率。
对图像中圆形目标进行自动识别的传统图像识别方法得到广泛应用的主要是基于Hough 变换的圆检测算法[1-5]与结合轮廓提取和形态学重构的图像分割算法[6-8]。Suzuki 等[9]提出了基于梯度法的Hough 变换圆检测改进算法,对于目标与背景反差较大的场景有很高的准确率,但对于由于变形、堆垛不整齐、拍摄角度、阴影等因素导致的非整圆钢管图像,以及杂乱背景下的钢管图像,精度急剧下降,无法满足工程应用的需要。结合轮廓提取和形态学重构的几种方法相互类似,都是通过轮廓提取把图像分割为若干互不相交的子区域,再通过设定阈值来筛选符合条件的子区域,通过形态学对子区域的形状进行重构,最终实现对目标物体的识别[9]。该方法可以在一定程度上解决目标钢管非正圆的识别问题,同时杂乱背景下的钢管识别具有一定精度。但该方法在复杂光照条件下,无法区分钢管阴影与堆垛间隙;并且随着图片中待识别钢管的数量增多,单个钢管所包含有效像素点变少,导致复杂背景与待识别目标之间的轮廓特征差异性降低,对子区域的筛选阈值变得困难,最终导致识别精度的快速下降。
基于深度学习的目标检测方法近年来在实例分割、关键点提取以及目标识别等领域取得了应用突破,在精度、泛化能力和实用性等方面均显著超越传统机器视觉方法[10-14]。其中,谷歌提出的YOLOv3目标检测方法,利用多尺度特征进行对象检测[13]。通过设置13×13、26×26 以及52×52 三种不同分辨率的特征图,在图像中分别适配不同尺度的目标,在保持速度优势的前提下,提升了预测精度,尤其是加强了对小物体的识别能力,因此比较适合于本文所研究的密集堆垛钢管的检测。然而该算法与其他基于深度学习的目标检测算法一样,都是通过学习画出目标的一系列候选识别框,然后通过设置非极大抑制(NMS)阈值[15],祛除多余的候选框,最终定位目标。对于密集堆垛又有相互遮挡的小目标,NMS会变得非常敏感,较大或较小的NMS 值都容易造成漏检或误检,识别精度显著下降。另一方面,基于深度学习的目标检测方法极度依赖重度人工标注,相比与图像分类,目标检测任务不仅需要人工对训练集中图像进行分类,还需要在图像中标注所有待检测物体的位置、大小等信息。对于需要构造至少包含大于10 000 张已标注图片的训练集,而每个图片上包含大于1 000 个小目标的密集堆垛钢管检测任务,该方法又会带来极大的人工劳动强度,导致算法失去工程应用价值。
通过上述算法存在的问题,结合工程应用的实际需求,本文提出了一种通过实现半自动标注来降低人工标注劳动强度,然后通过优化YOLOv3 目标检测模型的损失函数,来提高密集堆垛钢管识别精度的优化方法。该方法首先利用变分自编码模型(VAE)[12]结合少量人工筛选训练样本实现了对训练样本集的半自动标注,然后将已标注训练集输入计及排斥力损失的目标检测模型进行训练,最终用训练后的模型输出钢管检测结果。算法流程图见图1。该方法通过引入排斥力损失函数(Repulsion Loss)优化了YOLOv3 模型的目标位置回归损失函数,降低了NMS 的敏感性,提高了模型对相互遮挡的密集钢管截面的检测精度。现场拍摄的密集钢管堆垛图像的实际检测验证了算法的有效性和精度。
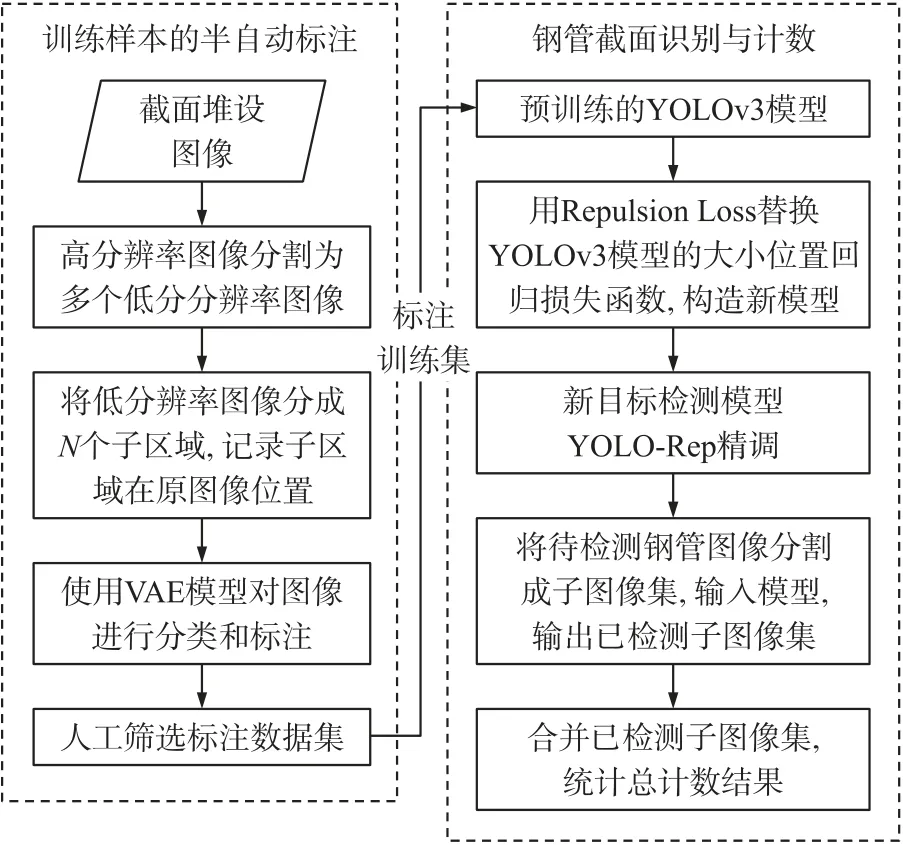
图1 算法流程图
1 训练样本的半自动标注
现有的深度学习模型需要大量的人工标注样本作为训练集来保证模型的精度。而相对于图像分类任务,目标检测任务需要强标注信息作为模型的输入,劳动强度极大。因此,实现无需人工参与,或仅需要少量人工修正的半自动标注方法成为深度学习模型推广应用的前提。
变分自编码器(VAE)[12]是一种引入先验分布的自编码模型(AE)[16],可以作为图像特征提取器使用。通过将包含较少钢管截面的低分辨率图像输入变分自编码器进行特征提取,利用模型输出的特征,设定阈值,对图像子区域进行无监督聚类,区分目标子区域(钢管、钢材、木材的截面)和非目标子区域(背景、空隙、阴影,非完整截面等)。据此,本文的思路是将高分辨率的钢管堆垛图像分割成低分辨率的图像,然后利用变分自编码器模型的无监督聚类功能,对每个图像的目标子区域与非目标子区域进行划分,最后结合子区域的中心点位置数据实现对目标子区域的自动标注。其具体步骤如下:
步骤1 利用滑动窗将高分辨率的堆垛横截面图像集G中的每张图片gi分割成N个R×R像素的低分辨率图像组成的图像集GLi(i=1,…,N),其中R由目标检测算法的推荐输入图像尺寸决定;
步骤2 利用滑动窗将GLi中的每个图像分成M个R0×R0像素的子区域集GSj(j=1,…,M),其中R0是人工预估的目标子区域的基准半径,并记录每个子区域在原图像中的位置POSj;
步骤3 将GSj作为训练集输入变分自编码器模型(VAE),对GLi中目标子区域GPj与非目标子区域GNj进行无监督聚类,我们采用式(1)作为VAE 用来聚类的损失函数(Loss);
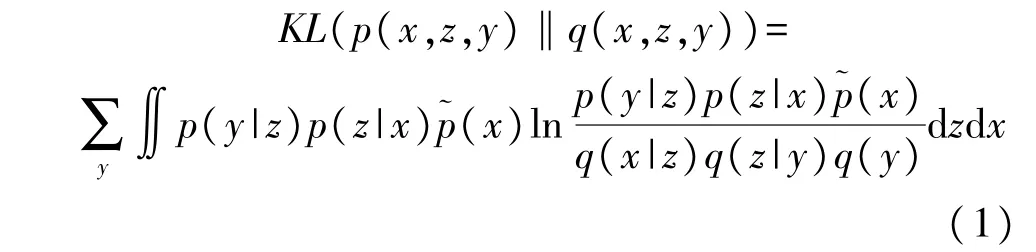
式中:x是待分类的样本数据变量,(z,y)是通过VAE 模型学习提取的特征隐变量,z代表分类编码,y是一个离散值,代表类别标签。~p(x) 是通过一批采样数据统计获得的样本经验分布,p(z|x)假设为满足均值为μ(x)、方差为σ2(x)的正态分布,q(x|z)为方差为常数的正态分布,q(z|y)是均值为μ(y)方差为1 的正态分布,q(y)假设为均匀分布时是一个常数。p(y|z)即为对隐变量z的分类器,可以通过训练一个softmax 网络[17]来拟合,拟合后的结果即可实现对输入图像的分类和标注。结合POSj实现对GLi中每个图像的自动标注,形成已标注数据集M(GPj,POSj)。
步骤4 人工对对数据集M中误差较大的标注数据样本进行筛除。
至此,我们实现了仅需要少量人工筛选的密集钢管堆垛图像的半自动标注。
2 钢管截面识别与计数
目标检测是很多计算机视觉应用的基础,比如实例分割、人体关键点提取、人脸识别等,它结合了目标分类和定位两个任务。钢管截面识别也是一种典型的目标检测任务。YOLOv3 模型因为不需要优化中间输出结果,采用的底层深度神经网络骨架可替换,对小物体的识别精度较高,非常适合本文所述场景的工程应用。
YOLOv3 模型的目标检测策略是:
步骤1 向模型输入经过重度标注的训练集进行目标分类和大小、位置的训练。训练中用来计算预测目标与真实目标之间的大小、位置的误差(即目标位置回归损失函数)被称为IOU。IOU 被定义为预测目标区域框(Box) 与真实目标区域框(Ground Truth,GT)之间的面积交并比。定义公式如式(2)
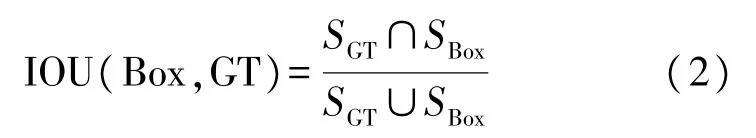
步骤2 向模型输入待检测的测试数据集,利用k-means 聚类算法对所有预测识别框进行聚类分析,找出最优的k个框,作为检测模型的备选结果框。k-means 算法适用的距离函数如式(3)

步骤3 利用已训练模型,计算所有备选结果框的预测置信度,选出置信度最大的框作为中心框,计算其他备选框到中心框之间的IOU,再通过非极大抑制法(NMS),设定IOU 阈值,祛除IOU 小于阈值的备选框,最终输出测试集中的预测目标框。为保证识别精度,IOU 阈值一般设置为0.6 以上。
然而,密集堆垛的钢筋截面图像中往往包含上千根钢管,对于多数拍摄角度,均存在密集遮挡问题,即待检测目标(钢管)之间相互遮挡,即同类遮挡。对于上述的同类遮挡(见图2),由于密集遮挡的两个目标的类别是相同的,所以两个目标之间的特征是相似的,检测器很可能无法定位。本应该属于目标A 的候选框很可能会向目标B 发生偏移,导致定位不准确,而目标B 本身有自己的候选框,在接下来的非极大值抑制中,目标A 的候选框很可能被目标B 的候选框所抑制,进而造成了目标A 的漏检。因此,对于密集遮挡问题,NMS 的阈值是很敏感的,阈值过高,造成误检,阈值低,造成漏检。
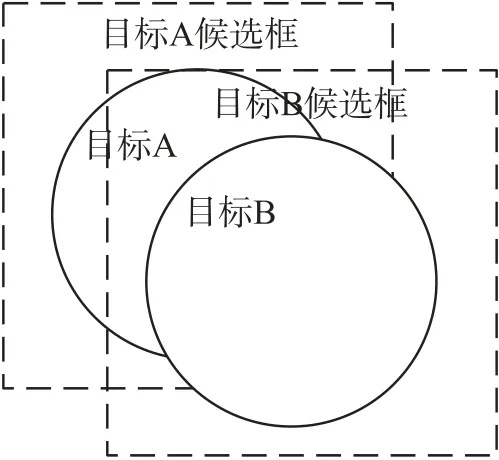
图2 同类遮挡示意图
针对上述问题,本文算法在YOLOv3 模型训练阶段引入了排斥力损失来优化YOLOv3 的目标位置回归损失函数。该损失函数在强化目标之间的吸引因素的同时,也计及周围目标框之间的排斥因素,有效解决了上述的漏检和误检问题,提高了目标检测的精度。
定义1排斥力损失
一种优化的目标位置回归损失函数。其包括一个吸引项和两个排斥项,吸引项使预测框(如图3-目标A 预测框)和所对应的真实目标框(如图3-目标A 真实框)的距离缩小,而排斥项使得其与周围非对应目标框(如图3-目标B 真实框)的距离加大。

图3 排斥力损失定义示意图
计算公式如式(4)
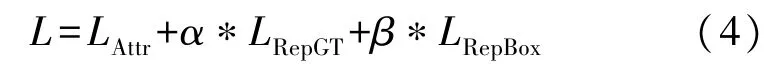
通过两个相关系数α和β来平衡三项损失值。其中,LAttr见式(5)为吸引项,优化目标是使预测框尽量靠近目标对象。

式中:ρ+为所有正样本的集合,P为其中一个候选回归,BP为回归P的预测框。
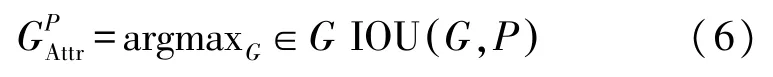

排斥项LRepGT见式(8)。目标是让预测框离除了分配给它的真实框之外的极大值框尽可能远。
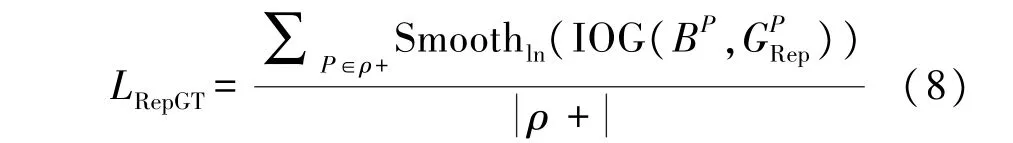
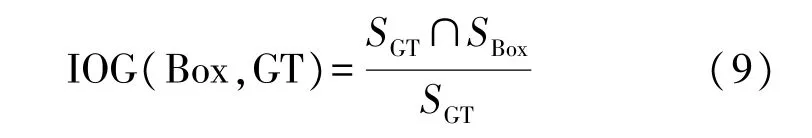
而排斥项LRepBox见式(10)。目标是让分配了不同真实框目标的候选框尽可能远。
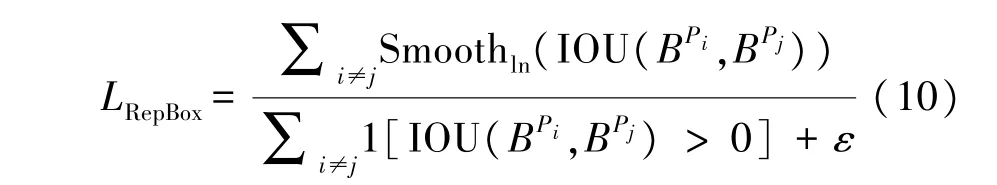
根据真实目标框将ρ+分为不同子集,LRepBox的优化目标是使得来自与不同子集的候选框之间覆盖(IOU 值)尽可能小。其中,分母为示性函数,表示:必须是有交集的预测框才计入损失值,如果两个预测框完全不相邻,则不计入。
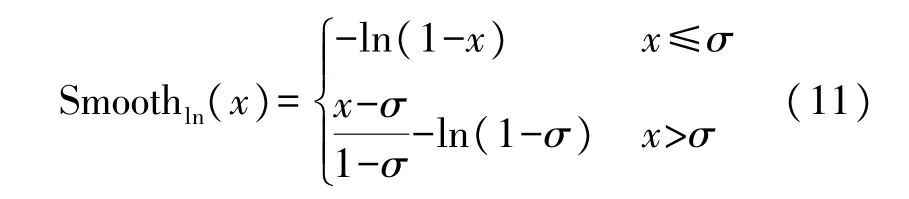
式中:σ为敏感性参数,在实验中,RepGT 和RepBox损失分别在σ=1 和σ=0 取得更好的效果。
综上,计及排斥力损失的密集堆垛钢管识别与计数方法的具体步骤如下:
步骤1 导入含有预训练网络权重的YOLOv3模型,并对模型进行超参数设置:一般情况下设置IOU 阈值>0.6。
步骤2 用排斥力损失计算代替YOLOv3 模型中用于计算目标位置回归损失函数,构造新的目标检测模型YOLO-Rep。
步骤3 将已标注的训练数据集M 输入YOLORep 目标检测模型,进行模型精调,调整模型中网络节点的预训练权重。
步骤4 将待检测图像经过YOLOv3 模型目标检测策略步骤1 中的方法进行分割后将子图像集输入YOLO-Rep 模型进行目标检测,输出含预测目标框的已检测子图像集。
步骤5 合并已检测子图像集并统计总计数结果。
3 实验及结果分析
本文的实验验证选用在某钢管租赁公司脚手架用钢管的图像5 000 张作为图像实验训练集,选取1 000 张作为图像测试集,规格均为3 000×2 000 像素。选取2 种图像:图像A(共3 000 张,其中训练集2 500 张,测试集500 张,见图4),场景为堆垛形式的仓库储存状态;图像B(共3 000 张,其中训练集2 500 张,测试集500 张,见图5),场景为装车待运输状态,分别代表钢管总数在500 根以下和1 000根以上的场景。

图4 识别结果1
实验中,采用目标区域分类效果实验及图像整体计数精度实验等两组实验来全面评价本文算法(YOLO-Rep)与传统的基于轮廓提取方法(Contours-Find)以及YOLOv3 原始算法的实际效果。
3.1 目标区域分类效果实验
将待训练的图像按照YOLOv3 对输入图片尺寸的要求,分割成416∗416 像素的低分辨率图像集。按本文第1 节所述进行半自动标注后,作为YOLOV3 及本文算法的训练集输入进行模型训练,对于轮廓提取方法则不需要训练集。在YOLOv3 算法及本文算法中,均设置IOU =0.7。在排斥力损失计算中,设置相关系数α=0.5 和β=0.5。
为全面客观地评价算法效果,采用二分类算法通用的评价指标:精度(Precision,P)、召回率(Recall,R)以及F1 得分(F1-score)作为指标来评价上述3 种算法。
精度

式中:TP代表目标区域(钢管)被正确分类的样本数,FP代表非目标区域(杂物、背景)被错误分类为目标区域的样本数。精度指标体现了算法对目标区域识别的准确率。
召回率

式中:FN代表目标区域被错误分类为非目标区域的样本数。召回率指标体现了算法对目标区域样本的利用率。
F1 得分

F1 得分是精度和召回率的调和平均数,用来全面平衡地评价算法性能。
为检验钢管数量较多的复杂环境下各算法的目标检测性能,实验中将上述图像测试集中的图像B测试集(单个图像中含1 000 根以上的钢管截面)分割成416∗416 像素的低分辨率图像集作为实验输入。通过人工在算法输出的低分辨率图像上判断样本分类的正确性,对结果进行统计。得到的上述三种方法分类结果的评价对比如表1。
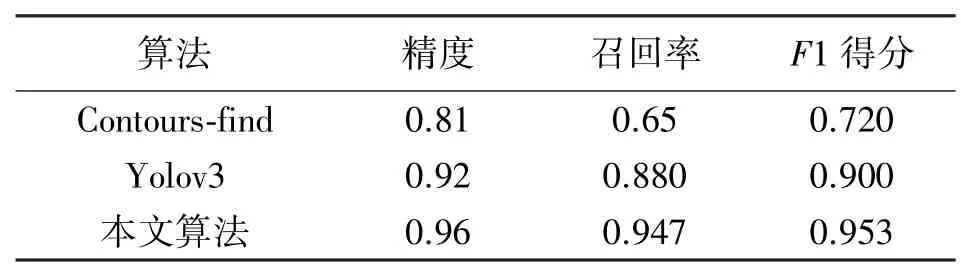
表1 三种算法对图像B 测试集分类性能对比
从表1,我们可以得出结论,基于轮廓提取的算法F1 得分仅为0.72,不适合用作含1 000 根以上钢管堆垛的计数。而本文算法在精度、召回率以及F1得分上均显著优于YOLOv3 算法。
3.2 图像整体计数精度实验
将图像A 和图像B 测试集输入已由上述实验训练集训练好的YOLOv3 模型和本文算法模型,直接输出带钢管区域识别标记的结果图像(识别出的每根钢管在输出图像中用1 个点来标记),并自动统计识别出的钢管总数。在实验结果检验中,由人工观察带标记的结果图像,通过统计漏标和错标钢管数量,修正算法统计的钢管总数,最终确定钢管总数的真值。
利用本文算法对钢管图像A 和图像B 两种图像的识别结果如图4(a)与图5(a)所示。相应地,图4(b)与图5(b)分别为利用YOLOv3 模型对图像A 和图像B 进行钢管识别的结果。

图5 识别结果2
将图4(a)与图4(b)对比可以看到,对于钢管数量在500 根以下的图像,单个钢管所占像素点较多,钢管之间没有明显遮挡,YOLOv3 算法与本文算法计算结果相对接近。但图4(b)中出现了由于排列不齐导致钢管截面不在一个平面上,造成钢管图像被遗漏的情况。将图5(a)与图5(b)对比可以看到,对于钢管数量在1 000 根以上的图像,单个钢管所占像素点较少,钢管之间出现相互遮挡,在此种情况下,YOLOv3 模型的精度下降较快,堆垛边缘以及有遮挡的钢管均没有被成功识别;而本文算法模型在有相互遮挡、单个钢管有效像素点快速下降的情况下,保持了稳定的识别精度,体现了在工程实践中良好的实用性与易用性。表2 说明了采用上述两种算法分别对图像A 和图像B 进行识别的计数精度统计。

表2 两种算法对图像A 与图像B 测试集识别精度对比
4 结论
本文提出了首先利用变分自编码器对图像训练集进行半自动标注,然后提出了计及排斥力损失的密集堆垛目标检测算法,最终实现了端到端的密集堆垛钢管自动识别计数。通过与传统基于轮廓提取的图像分割算法以及现有的基于深度学习的目标检测方法相比较,结合现场实际检测结果对比验证,本文提出的算法具有以下优点:(1)具有很强的抗干扰性和鲁棒性,对图像拍摄者和拍摄光照条件的要求较低。(2)通过无监督学习方法,实现了图像的自动标注,极大降低了人工标注的工作量,提高了模型训练效率。(3)对于包含大量相互遮挡的密集堆垛目标的图像识别,表现出优秀的性能,适合广泛应用于各种密集堆垛目标自动计数的场景。
实验与分析结果证明,本文所提出的算法具有很强的抗干扰性和鲁棒性,对图像拍摄者的要求较低。特别是对于包含大量钢管目标的图像识别,在较低算法复杂度下,表现出优秀的性能。因此,对工程应用的复杂场景具有广泛的实用性和易用性。
