一种改进的高分辨率遥感图像语义分割模型∗
2021-07-16沈旭东雷英栋朱立妙吴湘莲
沈旭东,楼 平∗,雷英栋,朱立妙,吴湘莲
(1.嘉兴职业技术学院,浙江 嘉兴 314036;2.同济大学浙江学院,浙江 嘉兴 314051)
遥感图像语义分割是指对图像中对每个区域的像素标签进行语义上的分类,它对地表空间信息的提取、城市土地资源管理、环境监测和自然资源保护等方面都起到十分重要的作用。随着遥感技术的发展,获取高分辨率遥感图像在国内已经得到广泛的应用[1],这给城市土地信息的提取提供了很好的资源基础,传统的方法使用手动的方式对遥感图像信息进行标注,会花费大量的时间和人力,因此构建一种自动的高分辨率遥感图像语义分割方法具有重要的作用。和传统的计算机视觉图像不同,遥感图像一般可获得的数量比较少,而且一个图像中会包含很多的物体,比如:道路、建筑物、植被、高树木、汽车等。另外,建筑物有不同的大小,汽车相比其他物体很小,植被和高树木只是在高度上有区别,这些问题都给基于标签的图像语义分割增加了很大的困难。
近年来,随着深度学习技术的发展,为了解决图像语义分割的难点,很多学者在图像语义分割上做了很多研究,2015 年全卷积神经网络[2](Fully Convolutional Networks,FCN)的提出为图像语义分割提供了全新的基础模型,采用“编码解码”的结构,实现了端到端的分割方法,比起其他模型有了很大的改进。本文针对高分辨率遥感图像的特点,在该结构的基础上设计了一种改进的端到端网络模型,在编码阶段使用遥感图像中具有三维特征的红外雷达(IRRG)和具有一维特征的数字表面模型(nDSM)作为输入[3],如图1 所示,采用resnet[4]预训练网络作为特征提取网络,设计了一种注意力补偿模块(Attention Complementary Block,ACB)网络结构,将IRRG 和nDSM 双输入特征做融合,加强了特征提取的效果。为了有效获取全局信息,我们在特征提取的最后一个阶段,构建了一个带有空洞卷积的空间金字塔结构[5](Atrous Spatial Pyramid Pooling,ASPP)网络模块,采用具有不同空洞率的空洞卷积网络,增大了卷积感受野,进一步提高了网络模型对于全局信息的获取。在解码阶段,我们设计了一种通道注意力增强模块(Channel Attention Enhance Block,CAEB)、空间注意力增强模块(Spatial Attention Enhance Block,SAEB)两种空间网络结构,采用CAEB 和SAEB 串接的方式对深层特征和浅层特征进行特征融合,再使用上采样结构减小通道数量,增加图像的尺寸,最后使用1×1 卷积得到需要的输出图像。
本文主要做的工作有以下几个方面:
(1)传统的图像语义分割算法大都是使用三维图像作为输入,进行图像的预测,很多遥感图像语义分割的研究论文中,有提到对遥感图像和nDSM 图像同时输入,但是融合的方法很少有详细描述,本文结合IRRG 和nDSM 的图像特征,设计了一种ACB注意力模型结构,对两个图像的特征进行提取,并在不同的特征层上进行融合,提高了特征提取的效果。
(2)由于遥感图像上物体结构复杂多样,本文借鉴DeeplabV3+[5]网络模型中的ASPP 网络结构,对网络参数进行改进,重新调整空洞卷积的空洞率,取得不错的效果。
(3)设计了CAEB、SAEB 两种空间网络结构,使用CAEB 和SAEB 串接的方式对深层特征和浅层特征进行融合,再进行上采样,增强了不同层图像特征全局信息的融合。
1 网络设计方法
1.1 基础特征提取网络
在设计语义分割网络时,基础网络设计是很重要的一部分,由于条件的限制,高分辨率遥感图像在进行训练时,很难获得海量遥感图像数据集,一般情况下只有几张或者几十张,在这样少量的数据集上提取特征,采用具有预训练的图像分类模型是不错的选择,本文选用resnet50 作为图像特征提取模型,因为它是在网络中增加残差网络的方法,解决了网络深度到一定程度,误差升高,效果变差,梯度消失现象越明显,使得网络反向传播求最小损失难以实现,网络模型框图如图2 所示。实现上,由于图像输入的数据有两部分,分别是IRRG 图像和nDSM 图像,以256×256 大小的图像为例,IRRG 图像的大小为(3,256,256),nDSM 图像的大小为(1,256,256),无法直接输入到resnet50 网络模型中,本文中将网络模型分为两个分支,一个分支处理IRRG 图像信息,一个分支处理nDSM 图像信息,由于默认的resnet50 模型为三通道输入,需要将nDSM 图像分支模型输入通道改为1。其次由于我们需要在深层网络之后使用ASPP 多尺度模块进行全局信息的提取,而resnet50 最后特征的输出只有(2056,8,8),尺寸太小,因此在第四层网络设计中,我们修改了卷积步长使得最后一层特征的输出大小为(2056,16,16),经过修改后resnet50 总的框架如表1 所示。
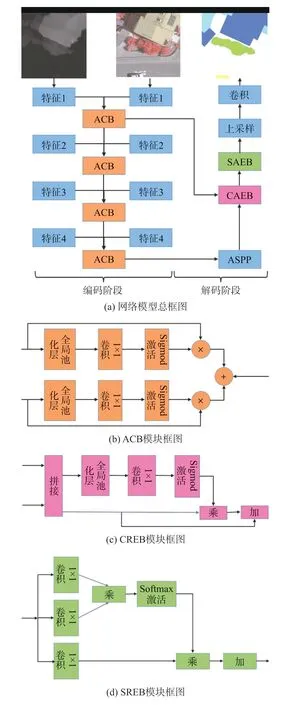
图2 网络模型框图

表1 基于resnet50 的基础特征提取网络框架
1.2 ACB 注意力模块
由前面分析,我们知道图像的输入信息有两部分组成,分别是IRRG 图像和nDSM 图像,为了能从这两部分图像中有选择地获取有用的信息,我们设计了一个注意力模块[6],使得网络能够更加关注图像中有用信息的区域。设计方法如下:假设输入图像特征A=[A1,…,Ac]∈ℝC×H×W,其中Ai表示每个像素点在全部通道上的点集合,C表示通道数量,H,W表示特征图像的高度和宽度,对F使用全局平均池化操作,得到输出Z,Z∈ℝC×1×1,公式如下:

其次,使用通道数不变的1×1 卷积操作,目的是为了对像素相关的类通道做强化,对像素不相关的类通道做抑制处理[7],从而给每个通道以合适的权值,然后使用Sigmod 激活函数激活卷积结果,通过训练可以得到针对每一个通道的最佳权值V∈ℝC×1×1,范围为0~1 之间,最后使用F×V得到输出结果,表达式可以写为公式:

式中:U为一个分支的输出结果,W1代表1×1 卷积,fs为Sigmod 激活函数,×为矩阵对应元素相乘。
将IRRG 图像和nDSM 图像依次独立采用上述模型进行特征的提取,并在每一层对提取的特征图进行融合,以特征层1 为例,得到的可视化结果(总共512 通道取0~8 通道),如图3 所示。
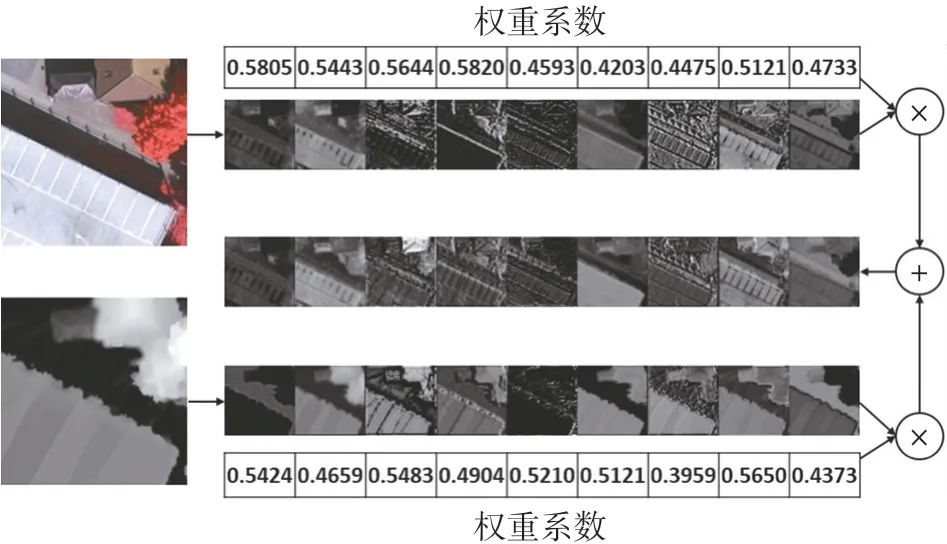
图3 IRRG 图像和nDSM 图像融合特征图
1.3 CAEB 和SREB 注意力模块
为了有效地完成遥感图像中不同物体之间的区分,特别是一些从图中看很相近的物体,比如:“矮植被”和“树木”通常是很难区分的,并且对于不同大小的汽车有时也很难区分,为了提高像素级识别特征表示的辨别能力,我们在深层特征和浅层特征融合的过程中采用了空间位置注意力和通道注意力两个网络的串接融合。
对于空间位置注意力模块,我们使用注意力机制,通过计算像素所在位置每个通道上的加权累计,得到每个像素可更新的权值比例,其大小由相应的两个位置之间的特征相似程度来决定,从而使得空间任意两个像素之间的依赖关系得以表示,通过空间位置注意力网络后,两个位置之间的关系程度和空间位置上的距离无关。网络具体实现如图4 所示,实现方法如下:

图4 空间位置注意力模块
(1)假设输入图像特征A∈ℝC×H×W;
(2)通过两个1× 1 卷积后,得到两个新的特征A和B,{A,B}∈ℝC×H×W;
(3)将A和B两个特征变型操作为ℝC×(HW),其中HW为H×W;
(4)然后用A的转置乘上B,再对结果使用softmax 求取每个像素的注意力权值,得到S∈ℝ(HW)×(HW),其中Sji表示第i个位置和第j个位置像素的注意力权值,即两个位置的相关程度。
(5)再通过1× 1 卷积后,得到新的特征C,{C}∈ℝC×H×W,并变型为ℝC×(HW),然后对S和变型后的C′对应元素相乘,最后再与输入特征相加得到输出E∈ℝC×H×W,表达式如下,
SREB 注意力模块基本原理同ACB 注意力模块,网络具体实现如图5 所示。

图5 通道注意力模块
2 实验方案设计
2.1 数据集描述
选取的数据集为Vaihingen 数据集[8],该数据集采集自航摄飞机拍摄的标准航空遥感影像,由33 幅高分辨率航空影像组成,涵盖1.38 km2城市的面积,图像平均尺寸大小为2 494× 2 064,每张图像具有3 个波段,分别为红外、红色和绿色波段,nDSM图像表征的是地面上物体的高度数据,作为补充数据输入,在这33 张图中,其中有16 张图片是有人工标注的,我们选12 张图片作为训练集,4 张图片作为验证集,数据集的信息如表2 所示。

表2 Vaihingen 数据集实验方案
2.2 数据增强方法
一般情况下,高分辨率遥感图像单张图像的尺寸都比较大,无法直接输入到深度学习网络中去,而且大部分高分辨率遥感图像只提供非常有限的数据量,比如,Vaihingen 数据集只提供16 张大小为2 494×2 064 带标签的完整图像,虽然很多深度学习语义分割模型能输入任意尺寸的图像,但是由于GPU 内存的限制和图像数量的原因,一次输入这么大的图像显然是不合适的,我们需要对图像进行随机裁剪,训练时我们在原始图像的基础上,随机把图像裁剪为256×256 大小,并对图像进行0°、90°、180°、270°、水平和垂直6 个方向的随机旋转,在实现的过程中图像的裁剪和训练没有分开,这样可以保证每次随机到的图像都可以不一样,如果先裁剪好再训练,每次训练的数据集就不会变,会影响最后的训练准确度。验证时,我们采用重叠覆盖的方法,把图像裁剪为256×256 大小,如图6 所示,设置x方向步长和y方向步长,对预测图像进行裁剪,这样可以提高整张图片最终预测的准确度。

图6 验证时图像裁剪方法
2.3 损失函数及训练细节
(1)损失函数设计
在语义分割领域,通用的损失函数一般选择交叉熵损失函数CEloss,定义如下:

式中:N表示批处理的大小表示每个标签样本的概率,表示相应标签类别的编码。针对数据集中大目标类别(比如道路和建筑物等)的像素点数量占据绝对优势,不同类别的像素点数据分布不均衡,因此高分辨率遥感图像存在样本类不平衡的问题,式(2)损失函数计算的是所有像素的总和,不能很好地处理类不平衡问题[9],我们采用对不同类别的损失进行加权,计算每个类别的权重,频率越高的权重越小,带权重的交叉熵损失函数定义如下:

(2)训练细节
在进行设计时,我们的程序使用Pytorch 框架进行设计,实验所用图像工作站配置为:8 核CPU,内存32G,TeslaV100 GPU,显存16G,操作系统Ubuntu 16.04,优化器采用随机梯度法,参数设置:lr =0.01,momentum =0.9,weight_decay =1e-4,迭代次数50000,批处理大小16,为了评估网络的性能,我们使用全局准确率(OA),均交并比(mIOU)来进行比较,对于两个数据集我们都使用不带边界腐蚀的标注图进行性能指标测试,评价函数如下:

TP表示“正样例被分类成正样例”像素,FP表示“负样例被分类成正样例”像素,FN表示“正样例被分类成负样例”像素,N表示总的像素值。
2.4 实验结果分析
我们采用FCN- 8S、Unet[10]、Segnet[11]、DeeplabV3+四种不同的语义分割网络进行对比分析,从表3 数据可以看出,我们设计网络在均交并比(mIOU)和准确率(OA)上都有了一定程度的提高,和基础网络FCN-8S 相比,我们的网络在mIOU 上提高了5.1%,在OA 上提高了3%,证明我们的网络添加了基于注意力机制的多尺度融合模型是有效的,对于类不平衡的优化设计,我们采用了带权重的交叉熵损失函数,我们的模型在小物体的识别上也有了一定的提高,比如,汽车类别的IOU 达到了73.06%,在相似物体的识别上也比其他的模型表现要好,比如建筑物比较大而且颜色不一致时,比较难识别,经常会出现中间缺失像素的现象,我们的模型建筑物类别IOU 的比例达到了90.78%,而且从预测图中看识别比较完整。
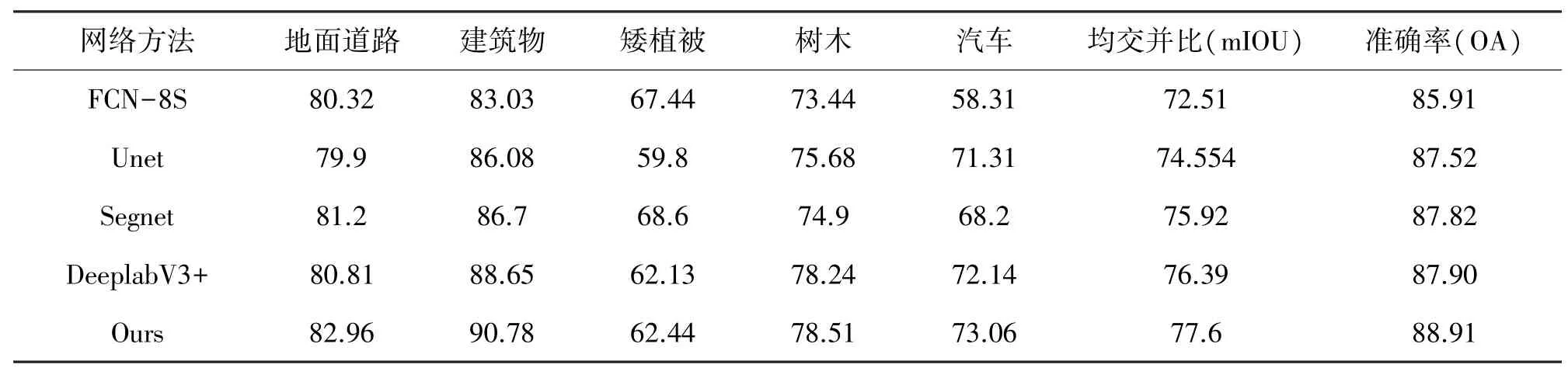
表3 Vaihingen 数据集对比测试数据
由图7 可知,很多的物体是比较相近的,比如一个建筑物在被识别的时候就分散开了,中间夹着很多其他的像素,或者树木和矮植被两种物体,比较难被区分开,这是因为各种其他的模型不能很好地使用全局的上下文信息,导致某个像素在识别的时候只考虑了周围有限的一些像素信息,从而使得信息的识别不是很完整,我们在模型中添加的注意力机制模型和多尺度模型在很大程度上可以改进这些问题。

图7 Vaihingen 裁剪图测试对比
我们对所有的256×256 图像进行了重叠覆盖拼接的预测,拼接后测试对比结果如图8 所示,经测试该方法比单独拼接在最终的准确率上要高1~1.5%左右,在最终结果中可以去除大部分预测错误的小点,从整体的预测效果上看,我们模型的预测结果在物体的完整性和预测的准确性上都要比其他的模型表现好。

图8 Vaihingen 30 号图拼接后整图测试对比
3 结束语
通过对遥感图像的分析,我们设计了一种新的针对高分辨率遥感图像端到端的网络模型,对IRRG图像和nDSM 图像进行融合输入,并在模型的设计中引入了空间注意力模块和多尺度模块,从最终的预测性能看,该模型比其他几种流行的语义分割网络模型预测效果要好,但是在相近物体的识别上还是存在一些问题,比如矮植被的识别没有凸显出很大的优势,需要在以后的设计中进一步改进。
