基于多跳推理的篇章情感分析模型∗
2021-07-16朱敏,班浩,赵力
朱 敏,班 浩,赵 力
(1.常州信息职业技术学院电子工程学院,江苏 常州 213164;2.东南大学信息科学与工程学院,江苏 南京 210096)
互联网的快速发展使得社交媒体成为用户表达意见的重要渠道,因此有效挖掘用户评论的情感信息具有十分重要的应用价值[1]。情感分析任务根据粒度不同分为篇章情感分析、句子情感分析和方面级情感分析,篇章情感分析的目的是评估文档整体的情感倾向或情感等级。传统的情感分析方法通常是利用N 元文法模型(N-grams)将文档表示成稀疏特征向量,然后再基于支持向量机(SVM)等分类方法完成情感倾向或等级的预测。近年来随着深度学习理论的发展,神经网络在学习文档稠密特征表示的应用逐渐成熟,其中使用最为广泛的是卷积神经网络和循环神经网络[2]。前者能够学习到文本中的关键词等局部不变性特征,但不能有效利用单词的顺序信息,而且无法解决文本数据的长程依赖问题,因此仅适用于短文本和句子情感分析任务[3]。后者由于处理序列数据的特性,因此适用于长文本和篇章情感分析任务[4]。
根据语言学的组合性原理[5],篇章语义信息的产生表现为由词到句、再由句到篇的层级结构,相同的单词和句子在不同语境下有可能表达不同甚至相反的语义。因此对于篇章情感分析,将文档简单地看作是单词序列处理是不合适的。为了能够更好地理解文档整体的语义信息,所构建的情感分析模型也应该需要适应这种层级结构。
本文提出一种融合多跳机制的篇章情感分析模型[6],既考虑了层级结构,又充分挖掘上下文语句之间的潜在语义影响,在IMDB 和Yelp 公开评论数据集上取得了优于当前最新模型的结果。
1 篇章情感分析
篇章情感分析任务的目的是确定输入文档的整体情感倾向或情感等级,也可以认为是特殊的文档分类任务,因此文本特征需要能够反映出篇章整体语义信息以及情感倾向。常用的文本特征提取流程包括词袋特征、词频逆文档频率特征以及卡方等特征选择方法,再根据数据特性和应用场景选择合适的分类方法,训练出良好性能的分类器模型。Alm[7]使用监督学习方法探讨了基于文本的情感预测。Cheng[8]研究了词语级和句子级的情感分析,首先利用机器学习方法学习具有情感属性的词语,然后在这个基础上通过朴素贝叶斯方法识别句子情感极性。Lakkaraju[9]对特征和情感主题建立一个联合的概率模型,该模型以监督的方式对评论中的特征和意见建模从而得到一个生成模型。
近年来,深度学习在自然语言处理的应用逐渐深入[10]。Socher[11]提出了递归神经网络识别文本所具有的情感类别。Kim[12]提出了基于卷积神经网络的文本情感分析模型,实验证实简单的卷积神经网络模型能够在情感分析任务中取得不错的分类性能。循环神经网络被设计来处理序列数据,因此基于循环神经网络的模型广泛用于自然语言处理任务,包括篇章情感分析、阅读理解等。Lai[13]提出循环卷积网络,首先使用双向循环网络得到每个单词的上下文相关向量表示,再结合单词本身向量表示通过最大池化得到句子表示,进而通过全连接层得到文本的情感倾向。Tang[14]首先提出从单词组合得到句子的特征表示,再从句子组合得到文档整体的特征表示,最终得到篇章情感倾向性的GatedRNN模型。需要指出的是,这种方法虽然考虑到了篇章层级结构,但不能高效捕捉到同一文档中不同句子之间的语义关联信息,也限制了模型效果的提升。基于循环网络的注意力机制在自然语言处理中最早应用于机器翻译[15],实质在解码输出时为每个时间步的隐藏向量表示计算权重,因为在翻译目标语言时,源语言不同单词的对当前时刻目标单词的贡献是不同的。对注意力权重的可视化表明这种假设的合理性与正确性。Du[16]调研了基于循环网络的注意力机制在文本分类任务的应用,在NLPCC2014 和Reuters 文本分类数据集上取得了优于基线模型的效果,证明了注意力机制应用于文本分类和情感分析的可行性。受Tang[14]考虑篇章层级结构的启发,Yang[17]提出层级注意力机制模型HAN,在单词层级的注意力机制得到句子表示,在句子层级的注意力机制得到篇章表示。在IMDB、Amazon 和Yelp 数据集上的结果表明所提出模型的优越性,并且通过注意力权重的可视化分析,对篇章整体情感倾向有贡献的单词,相应的权重会较大,因此具有一定的可解释性,得到了广泛应用。
2 多跳推理网络
多跳网络也叫记忆网络,最初提出用来解决阅读理解任务[6]。具体内容是给定一段文本描述,然后提出相关的问题,阅读理解模型要根据问题从文本描述中找出相应的回答。显然模型需要具备从文本描述和问题推理出相应回答的能力。多跳网络设计为模拟这个推理过程,包括记忆单元和推理单元。其中,记忆单元是存储文本描述和问题的隐藏特征,推理单元是根据问题从记忆单元中查询答案。记忆单元和推理单元具体的实现均由神经网络完成,不过其中最关键的是,文本描述和问题的隐藏特征是被存储在记忆单元中,因此可以多次访问进而实现多次推理。面对复杂问题,有可能需要从文本中多次推理才能对答案实现精准定位,因此多跳网络可以模拟阅读理解任务中的多次推理过程,这也是其名字的由来。
在篇章情感分析任务的层级注意力机制模型[17]中,研究者观察到注意力权重会集中在对情感倾向有贡献的情感词汇和程度词汇中。但对篇章整体而言,经常会存在某些句子表达的情感倾向和整体倾向不一致的情况,因此注意力权重集中在某些句子会造成对整体情感倾向的错误判断。为解决这个问题,需要平衡好篇章中不同情感倾向句子之间的关系。因此考虑将篇章情感分析转化为阅读理解问题,使用多跳网络可以对篇章中所有句子进行多次推理,从而充分均衡不同情感倾向句子对篇章整体情感倾向的影响。
图1 所示为用于篇章情感分析的多跳网络模型,以两次推理作为示例。首先使用GRU 在单词层级上得到句子的向量表示。这里没有使用注意力机制,一方面是因为避免模型过分关注某些情感倾向性很强的单词,从而考虑篇章整体;另一方面是减小模型运算复杂度。GRU 单元包括遗忘门zt和重置门rt:

图1 多跳网络结构
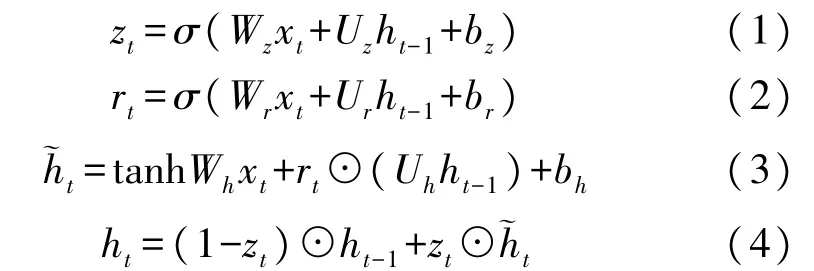
式中:xt表示GRU 第t时间步的输入,ht-1表示GRU第t-1 时间步的隐层输出;Wz和Uz分别表示GRU遗忘门zt中xt和ht-1的权重矩阵,bz表示偏置;Wr和Ur分别表示GRU 重置门rt中xt和ht-1的权重矩阵,br表示偏置;Wr和Ur分别表示GRU 当前时刻输入信息中xt和ht-1的权重矩阵,bh表示偏置,~ht表示当前时刻的输入信息,ht表示当前时刻的输出。
在得到句子的向量表示hi后,使用注意力机制来平衡不同句子之间的关系以及对篇章整体情感倾向的贡献:
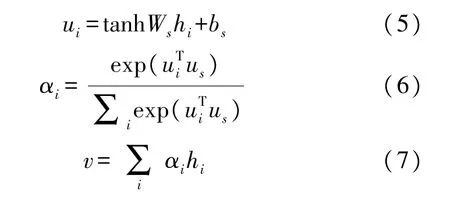
式中:us表示用于计算注意力权重的查询向量,αi表示对应每个时间步隐藏向量即每个句子的注意力权重,v表示篇章的特征向量。
如果不考虑多跳结构,则再经过全连接层可以预测输出整体的情感倾向。但对于篇幅较长的文档,常常包含情感倾向不同于整体情感倾向的句子,而且不同上下文之间还存在情感倾向的相互影响,因此就要考虑多跳结构。具体来说就是在已经得到篇章向量vt-1的基础上,再使用另一GRU 网络并且状态初始化为上一轮次的篇章向量,重新为每个句子计算注意力权重,得到当前轮次的篇章向量vt。
此外,考虑到在单词层级得到句子向量表示过程中,并未使用注意力机制,其原因是避免模型过度学习到某些较强倾向性句子的情感特征而忽略篇章整体。但同时也为防止模型在单词层级不能学习到有效的句子表示,考虑使用位置编码,包含不同单词对句子情感倾向的贡献,位置编码权重对句子所包含单词的词向量加权后与GRU 得到的句子向量拼接起来,作为句子特征的增强:
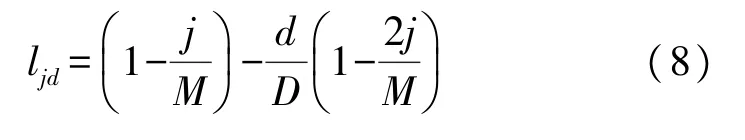
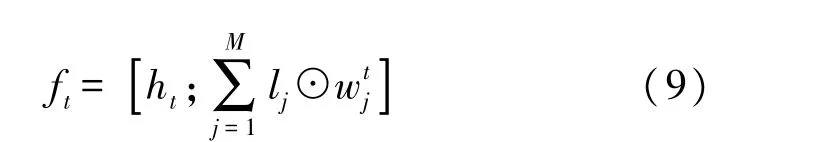
式中:d表示词向量某一维度,D为预设词向量维度,表示第t个句子的第j个单词的词向量,M表示句子长度。
3 实验结果与分析
本文选择的篇章情感分析数据集为公开的IMDB 影视评论数据集、Yelp-13、Yelp-14 饭店评论数据集,其中训练集、验证集和测试集划分与Tang[14]相同。各数据集统计信息见表1。
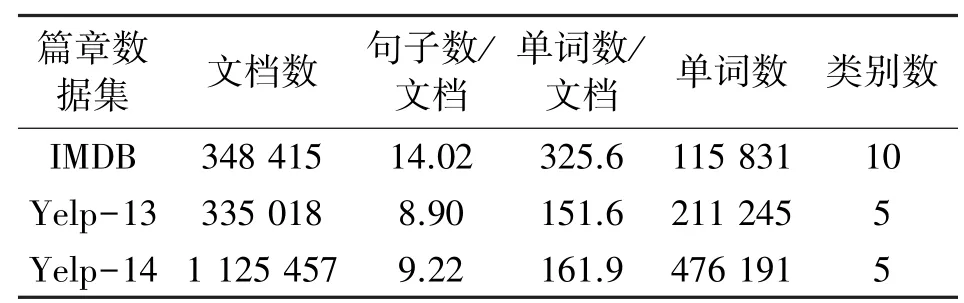
表1 数据集统计信息
数据预处理过程使用NLTK 工具进行切分句子和分词,构建词表时仅保留词频超过100 的单词。模型性能的评估使用指标为准确率,即正确分类数据占所有数据的百分比。模型在训练过程中超参数训练轮次设置为50 次,当且仅当本轮次训练模型在验证集上取得当前最好结果时保存模型参数,训练结束则加载验证集上表现最好的模型在测试集上进行预测。批次样本数据量选择为64,词向量维度选择为300,使用预训练好的Glove 词向量[18]。训练过程中的dropout 正则概率设置为0.5,L2 正则权值设置为0.2,并且仅对全连接层神经网络的权重施加L2 正则。训练模型所使用机器为Windows 系统,显卡型号为NVIDIA GTX1060,运行内存为8G。实验结果如表2 所示。

表2 实验结果
对所提出的多跳网络模型以及位置编码增强的模型进行对比实验,选择的基线模型包括:
(1)Average 表示将文档中所有单词的词向量取平均,作为篇章整体的向量表示,然后经过全连接网络预测输出情感类别或倾向;
(2)TextCNN 将整篇文档视为长序列,使用卷积神经网络对文档情感分类。宽度为[3,4,5]的卷积核各128 个,卷积结果经最大池化后再经过全连接网络进行预测输出;
(3)TextRNN 同样将整篇文档视为长序列,使用循环神经网络GRU 对文档情感分类;
(4)TextRNN+Att 在TextRNN 的基础上,使用注意力机制对文档情感分类;
(5)GatedRNN 考虑文档层级结构,使用GRU先在单词层级得到句子向量表示,再在句子层级得到文档向量表示进而完成分类;
(6)HAN 考虑文档层级结构,在单词层级和句子层级使用基于注意力机制的GRU 得到相应表示进而完成分类。
由实验结果可知,适于处理序列数据的循环网络性能要好于卷积网络;使用注意力机制可提高实验结果准确率;考虑文档层级结构的模型表现优于不考虑层级结构的模型;多跳推理结构可以改善层级结构模型的实验结果,但随着跳数越多表现不升反降,可能的原因时出现过拟合,而且训练时间也明显变长;位置编码对多跳推理结构的影响不是很明显。在三种篇章情感分类数据集的实验结果表明,所提出的多跳推理情感分析模型是合理且有效的。
4 结论
本文引入阅读理解中的多跳结构,用来解决篇章情感分析模型过分关注某些情感词汇和不能很好建模不同句子,尤其是情感倾向不同于文档整体倾向的句子之间的语义关联和影响的问题。在所选择的数据集上的实验结果证明了多跳结构的有效性。但本文所提出的模型仍存在一些缺点,引入多跳结构增加了模型复杂度,而且跳数越多训练时间明显变长。未来的研究为在保持多跳结构的同时,进一步降低模型复杂度,在不损失模型性能的前提下,加快训练时间。
