基于集成学习算法的带钢表面缺陷分类算法研究
2021-07-16宗德祥何永辉
宗德祥,蒋 渝,何永辉
(宝山钢铁股份有限公司1.中央研究院,上海 201999; 2.冷轧厂,上海 201900)
集成学习,顾名思义,不是单指某种特定的学习算法,而是由多种学习算法构建而成的用于解决实际问题的一种理论方法,目标是获得较高的预测准确率。目前常见的集成学习算法主要有两种[1]:基于Bagging的算法和基于Boosting的算法。其中基于Bagging的代表算法有随机森林,而基于Boosting的代表算法则有Adaboost、GBDT、xgboost等。
带钢表面质量在线检测系统,从20世纪50年代诞生以来,就开启了缺陷检测识别的征途。伴随着机器学习算法的进步,这些算法逐步被引入到带钢表面质量在线检测系统中,使得系统的性能逐步得以提升。然而在实践中,往往发现常规的算法并不能够满足智慧制造时代的需求。目前常见的基于决策树的算法,分类准确率通常稳定在75%~80%之间,显然仅能够满足用户最基本的需求。为了解决这一问题,本文提出了传统算法与深度学习算法相结合的算法,来实现分类准确性的提升。
1 本文算法模型
通过对采集到的带钢图像进行跟踪分析发现,通常情况下,带钢表面真实缺陷发生数同实际采集到的图像数相比,占比在10%~30%之间,如图1所示,随机抽取3个月内生产的10卷冷轧钢卷统计出的数据,即意味着存在大量的不含缺陷的图像数据被采集。这些多余的数据将会对后续的缺陷分类产生负面影响。因此,若能有效过滤此类图像数据,将能有效提升系统的性能。
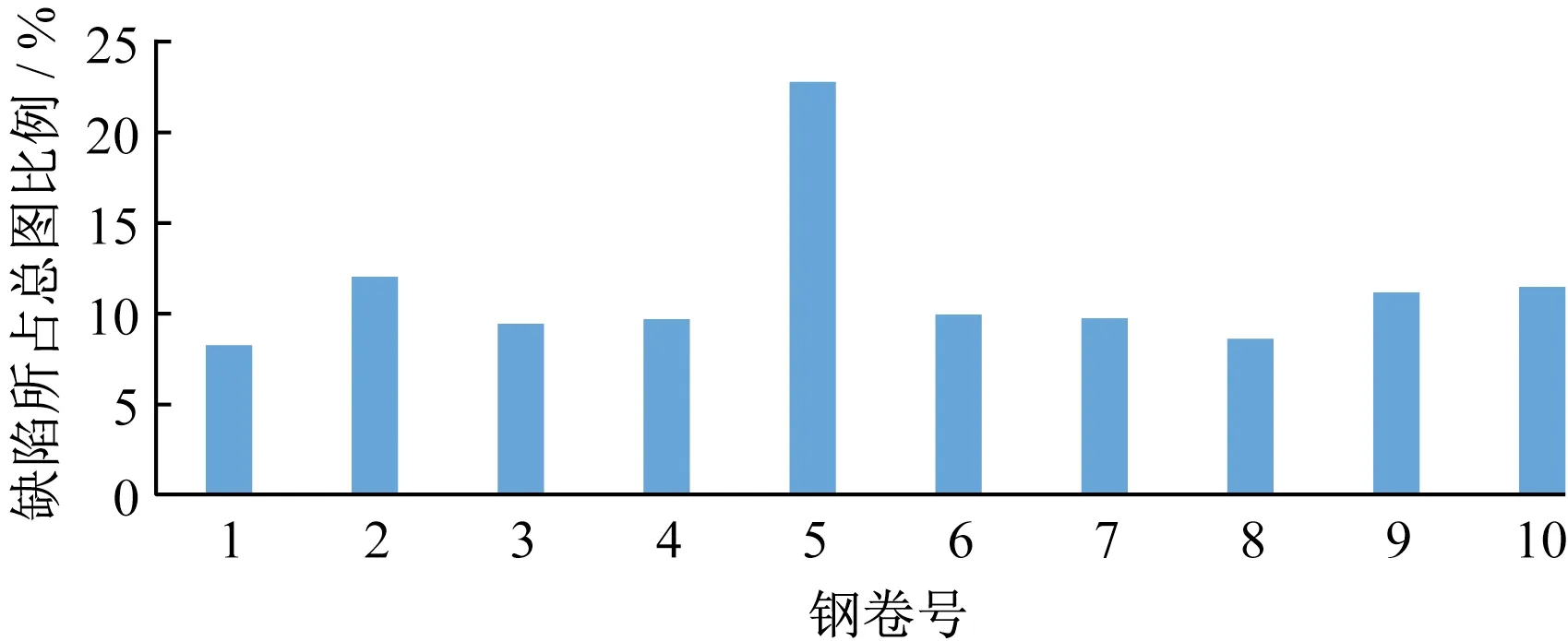
图1 缺陷所占总图比例统计图
因此,本文提出一种基于集成学习算法进行缺陷过滤并结合多尺度卷积、特征金字塔与视觉注意力机制和传统特征的深度学习网络算法模型,如图2所示。该模型算法分为两个主要阶段:第一阶段为虚线框中的部分,称之为缺陷身份过滤阶段,在该阶段,完成海量的数据筛选工作,从而降低系统的负荷,该阶段也可称之为数据预处理阶段;第二阶段为基于深度学习的目标分类识别阶段,为了提升目标识别准确性,将第一阶段人工设计的特征也作为参数输入到深度神经网络之中,进一步提升系统的精度。

图2 基于集成学习算法的带钢检测分类模型
1.1 数据预处理
本文数据预处理的目标是为后续目标分类提供合理的数据输入。由于全连接层的存在,一般来说,分类网络需要有固定大小的输入,但是由于缺陷的形态各异、大小不一,如图3所示,无法将原始缺陷块直接输入到网络中,因此需要对数据进行预处理,取出固定大小的缺陷块输入到网络中。

图3 几种典型的缺陷样本
经过一系列试验对比分析,最终选择一种缺陷块和固定大小背景图融合的方式,由于原始图像较大,选择256×256大小的表面干净的钢板背景图,将裁取出的缺陷块和背景融合,具体步骤如下:
(1)边界提取。
本文采用混合阈值界定法,即采用灰度梯度阈值和灰度阈值联合搜索方法,具体流程如图4所示。

图4 边界提取的算法流程
在得到待检测图像后首先对其进行了一次Sobel 算子的X方向卷积操作,将之与图像作平面卷积,即可分别得出横向及纵向的亮度差分近似值。从模板可以看出,X方向模板对于X方向上的灰度突变敏感,因而可以很好地检测出竖直边缘,将卷积结果二值化后可以得出比较明显的钢材区域,效果如图5所示。

图5 边界提取效果图
(2)裁取缺陷块。
根据缺陷顶点坐标和长、宽的数据直接将缺陷块进行处理,裁取过程中需要注意一下特殊情况,如果缺陷的长度大于256,则只取中间长度为256的缺陷;如果缺陷的高度大于256,则进行一些缩放和裁剪的操作,保证不会越界。在处理小缺陷块的时候,对缺陷外围适当地向外扩张,以保持检测不完整的情况下能尽量得到更完整的缺陷。得到的缺陷块如图6所示。
图6 图像块
(3)缺陷块与背景融合。
取一张干净的背景图,如图7。将裁取到的缺陷块以背景钢板图的中心为中心进行融合,采取泊松融合的方式。泊松融合是一种非常强大的图像融合算法,可以把一个前景区域无缝地融合到目标背景图中。它通过计算两个图像交接部分的梯度,然后对两个图像进行适当的调整,使得两个看起来不太融洽的图像看起来是一致的,边界融合效果十分好。泊松融合的效果如图8。

图7 背景钢板

图8 泊松融合图
(4)图像缩放。
经过泊松融合后的图像大小为256×256,而我们的网络标准输入为299×299,因此需要对图像进行缩放,得到标准的网络输入大小。采用这种方式可以得到极其干净的缺陷图,比起直接贴图的方式效果更好,除去真实缺陷以外全部都是干净的背景,降低了背景中其他部分对分类造成的影响,同时在进行图像增广的时候,可以通过缺陷块的随机位置放置进行大量的增广。
(5)特征提取。
缺陷图像蕴含丰富的信息,但像素数据太大、太稀疏,直接使用图像上每一个像素来分类要求的计算量是巨大的,同时,通常情况下,单一的像素点没有对应的确定且可解释的意义。因此,图像的内容需要通过一些特征来进行描述。图像的特征包括颜色特征、纹理特征、形状特征、梯度特征等,颜色特征和纹理特征描述了图像区域的表面性质,比如灰度均值、纹理均匀性。形状特征有两类表示方法,一类是轮廓特征,主要针对物体的外边界;另一类是区域特征,主要是描述整个形状区域。梯度特征是基于梯度图生成的,能有效地描述缺陷边缘变化的情况。形状特征包括周长、面积、宽高比等,纹理特征包括纹理对比度、纹理均匀性、纹理熵、纹理二阶矩等,灰度特征包含灰度均值、灰度方差、能量、熵、最大最小灰度值等,梯度特征包含边缘梯度均值、W方向梯度均值、H方向提取均值、边缘梯度方差等。
(6)xgboost目标预分类。
xgboost类似于GBDT,是一种梯度提升算法的版本。它的思想很简单,由多个弱分类器,经过Boost框架,以负梯度为优化目标进行集成学习。它区别于GBDT的显著特征是对代价函数进行了二阶泰勒展开,同时使用了一阶和二阶导数,并且将树的结构作为正则项加到了代价函数中,可以控制模型的复杂度。在本文中,使用二分类的xgboost分类器,将上节中提取到的多维传统特征作为输入,为了防止严重缺陷被误丢弃,模型输出结果小于0.3判定为伪缺陷,输出结果大于0.3则为真实缺陷。
1.2 目标分类识别
结合钢板缺陷分类中存在的缺陷大小不一、长宽比差异大等特点,Inception模块中的多尺度卷积可以起到很好的特征提取作用,因此,本文采用GoogleNet-Inception v3作为基础网络[2-3]。但是Inception v3网络并不能完全解决钢板表面缺陷分类中存在的复杂问题,为了进一步增强通道域的特征表达,在Inception v3中引入了基于通道的注意力模块SENet,其结构如图9所示。SENet的核心思想在于通过网络根基loss去学习通道方向的特征权重,增强有效的feature map,抑制无用的feature map,以此达到更好的效果。SENet并不是一个完整的网络结构,而是一个子结构,可以方便地嵌入到任何网络中。虽然插入SE Block会增加一些参数和计算量,但是相对于效果的提升是完全可以接受的。
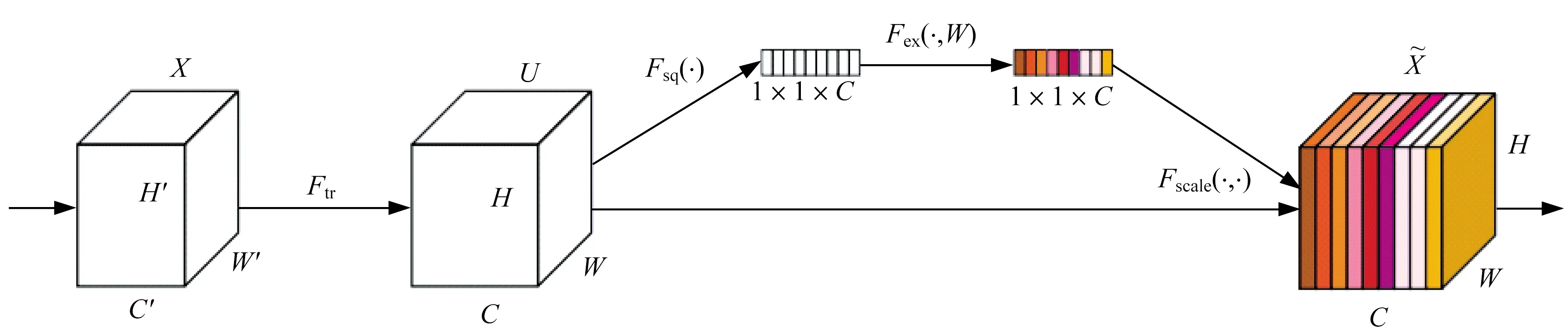
图9 SENet模块结构
为了提高算法的鲁棒性,降低网络的过拟合,还在网络中融合了传统特征。通过图像中计算得到的缺陷形状、灰度、纹理、梯度等传统信息,组合成一个传统特征的嵌入向量,对该向量进行一定的处理后与深度学习模块学习的特征进行融合,融合后的特征再接入到最后的分类层,传统特征的引入能进一步提升网络的分类准确率。
2 模型训练及评估
2.1 数据集
本数据集共包含24类缺陷样本,其中21类真实缺陷,3类伪缺陷,总数量8 876张样本。数据集样本分布如图10所示。将收集的原始数据以每类8∶2的比例划分成训练集和测试,由于数据数量较少,难以满足深层的网络对大量数据的需求,所以对原始数据进行部分数据增广操作,在不改变缺陷特征的情况下,使用镜像、翻转、裁剪、平滑去噪、模糊、压缩和拉伸、灰度变化等方式进行增广。通过以上多种方式的数据增广,可以对数据进行数十倍的增广,有效地降低模型的过拟合,增强模型的学习表达能力。

图10 样本集
2.2 模型训练
网络训练的流程图如图11所示,主要是由正向传播与反向传播交替进行。数据由输入层传入隐藏层,经过若干层隐藏层处理后传入输出层,由输出层将结果输出的过程被称为正向传播。一次正向传播结束后,需要对比正向传播的输出与正确结果的误差,用这个误差来描述这次网络的状态。反向传播是将误差传递给前一层的过程,基于梯度的误差会一层一层地反向传递到第一层隐藏层,每一层的每个单元会根据误差情况来更新自己的权值。

图11 模型训练流程
鉴于初期训练网络的样本较少以及训练效率两方面因素,我们采用了迁移学习的思想。初始化低层卷积层参数采用在ImageNet上预训练的去掉全连接层的CNN模型,因为低层卷积层提取的局部特征主要包括边缘特征、亮度特征等低层语义特征,具有较强的普适性,因而利用预训练好的模型作为模型的初始化参数,可以加快网络的收敛速度。网络的输入图像大小为299×299,网络的训练和评估使用GTX 1080Ti,训练时batch size设置为64,测试时为32,训练50个epochs,初始化学习率设为10-4,学习率随epoch以一定的规律递减。
2.3 评估标准
对于缺陷分类的评价方法采用常用的图像识别的评价标准。该方法需要已知输入图像缺陷的正确类别,将正确结果与分类器的结果进行对比。将一张缺陷图像输入到训练好的网络中,若类别判定正确,则Cor+1,统计整个测试集的所有测试图像的测试结果(All),记为该算法的识别准确率Acc,如公式(1)所示。
(1)
2.4 试验结果统计
对样本集以8∶2的比例随机划分训练集和测试集,对测试集进行测试,测试结果如图 12所示。
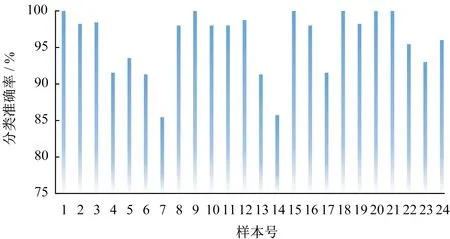
图12 样本分类准确率统计
对算法模型(图2)进行各模块增删试验,验证本文模型的有效性,如表 1所示,不同网络结构对目标分类准确率存在较大影响。由试验结果可以看到,在Inception v3的基础上加上SENet和传统特征能获得最好的效果。

表1 不同网络结构的分类准确率
3 结论
(1)本文所述的基于集成学习算法的带钢表面缺陷分类算法,将Googlenet的多尺度卷积作为骨干网络,用密集成分来近似最优的局部细数结构,引入SENet缺陷注意力模块,接入到多尺度卷积网络结构中,它通过压缩—激励—重标定的过程,在通道方向加强有用信息,弱化无用信息,从而达到提高缺陷通道特征注意力的作用。
(2)在深度学习网络中融入传统特征,如形状、灰度、纹理、梯度和投影等,来加强网络的分类能力和泛化能力。
(3)结合多尺度卷积、特征金字塔与视觉注意力机制和传统特征的深度学习网络,由于具有较高的鲁棒性和准确性,在工程实践中取得了较好的应用成效,满足用户对质量控制的需求。
