结合域间与域内变化的跨域行人重识别算法
2021-07-14胡月琳蔡晓东刘玉柱
胡月琳,蔡晓东,刘玉柱
桂林电子科技大学 信息与通信学院,广西 桂林541004
行人重识别(ReID),旨在给定查询对象的情况下,在大型数据库中检索指定行人的图像。由于大规模数据集的出现,以及特征提取和度量学习方法的不断改进,近年来,在单域情况下,ReID 任务已经得到了巨大进展。然而,当在不可见的目标域中直接利用模型时,性能会有巨大的下降,这在新数据集上测试模型时尤为明显[1-3]。这就是在机器学习领域普遍存在的域适应问题。
在跨域行人重识别中,训练集为源域,而测试集为目标域,两个域之间通常存在显著的域差。例如,公开数据集Market1501[4]采集在夏天国内校园,行人多着短袖,色彩相对鲜明,而DukeMTMC-reID[5-6]采集于冬季国外校园,行人多着厚重冬装,色彩相对暗沉。这种显著的着装风格差异塑造了两个数据集之间的域差,并降低模型在这两个数据集之间跨域使用的准确率。
为增强跨域行人重识别模型的泛化能力,近年来提出的算法分别从域间和域内两个方面来增强域自适应性。针对域间变化,Deng和Wei等人[1-2]提出域间风格迁移的方法,通过把源域训练样本风格迁移到目标域的测试集,在原始图像层面减小域差,但这类方法大多需要依赖生成对抗网络(GAN)来实现风格迁移。
针对域内变化,Zhong 等人[7]提出目标域内风格迁移的方法,该方法不直接在源域和目标域之间进行风格迁移,而是在目标域内部进行细粒度的风格迁移,利用StarGAN[8]让目标域不同相机图像之间互相迁移风格,但这种方法忽略了目标域中潜在的正样本对,可能导致ReID 模型对目标域中的其他特征敏感,例如姿势和背景变化。Huang 等人[9]在目标域进行辅助的监督学习,利用在目标域额外的人工解析帮助模型区分语义部件,从而增进泛化能力,然而该方法需要通过额外训练姿势估计模型来找关键点,增大了实验的复杂性和训练时间。Zhong和Yu等人[10-11]在目标域引入一些无监督学习任务,提高模型在目标域的泛化能力。其中,Zhong 等人[10]利用源域模型给目标域图像生成各自的软标签,虽然这个标签不够准确,但却可以被巧妙地用来监督深度嵌入学习。Yu等人[11]引入样本不变性,相机风格不变性和邻域不变性约束,通过示例性存储器来存储目标域的特征并适应3个不变性属性,有效提高了模型的泛化能力。这两种方法仅考虑目标域内的无监督学习任务,并未考虑域间的不变性信息。
为尽可能地挖掘源域与目标域内的可用信息,本文同时结合域间和域内变化来增强行人重识别的域自适应性。首先,采用PR 策略将行人特征图进行分区处理。具体地说,将特征图均匀分区为P个水平区域,用于汇集局部特征,而统一划分不可避免地会在每个区域产生异常值,这些异常值与其他区域更相似,因此,对P个水平区域进行“软化”处理,将这些异常值重新分配给它们最接近的区域,从而提高了区域内部一致性。然后,提出域间姿势不变性,将目标域的行人学习源域行人的姿势特征生成新的行人图像加入训练,缩小源域和目标域的姿势差距。接着,提出域内姿势不变性,将目标域内不同行人的姿势特征相互学习,缩小域内姿势差距。最后,引入域内样本不变性,相机风格不变性和邻域不变性并采用样本存储器存储目标域的特征并适应不变性。将本文方法分别在Market1501和DukeMTMCreID 进行实验,验证了PR 策略和5 个不变性对行人重识别中的跨域问题是有益的。
1 增强域自适应的方法设计
1.1 系统框架
本文提供完全记的源域{XS,D(XS)}和未标记的目标域XT。其中,XS和XT分别表示源域和目标域的图像域,D(XS)表示源域的身份域。源域中任一行人图像xS,j与其身份d(yS,j)相对应。
本文的系统框架如图1 所示。首先,在训练期间,标记的源域和未标记的目标域数据被前馈到ReID网络以获得最新表示。接着,结合域间和域内变化设计两条线路来优化ReID网络。第一条线路是具有区域对齐与“软化”处理的分类模块,用于计算源域数据的交叉熵损失。第二条线路是不变性学习模块,用于计算域间姿势不变性,域内姿势不变性,样本不变性,相机风格不变性和邻域不变性五个不变性损失。
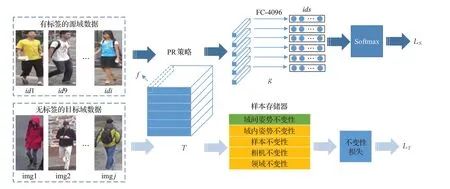
图1 系统框架图
1.2 区域对齐与“软化”处理的ReID模型
最近的研究表明,将行人身体部位进行对齐处理对跨域行人重识别是有益的,因此,本文根据PR策略提出一种具有区域对齐与“软化”处理的ReID模型(PR)。首先参考最先进的部件模型PCB[12],将行人特征图均匀分区为P个水平区域,用于汇集局部特征。接着,由于统一划分不可避免地会在每个区域产生异常值,而这些异常值与其他区域更相似,因此,将这些异常值重新分配给它们最接近的区域,即对原始水平区域进行“软化”处理进而提高区域内部的一致性。
本文采用在ImageNet[13]上预训练的ResNet-50[14]为基础网络,并将其参照PCB[12]进行重塑。具体来说,原始全局平均池(GAP)层之前的结构与基础网络保持完全相同,只是删除GAP 层及其后续内容。当输入图像从基础网络向前经过堆叠的卷积层时,形成了3D 张量P。接着,用传统的平均池化层代替了原始的全局池化层,以在空间上将T下采样为P个列向量g。最后,与PCB不同,在本文中,放弃使用卷积层减小g的尺寸,直接将列向量g输入到分类器中。其中,每个分类器都通过添加4 096 维完全卷积(FC)层和Softmax 函数实现。在训练过程中,每个分类器都会预测输入图像的身份,并受到交叉熵损失的监督,每个区域的交叉熵损失Lid计算方法如公式(1)所示,不同区域的损失累积和LP计算方式如公式(2)所示:

其中,nS表示训练批次中的源域图像数。p(d(xS,i)|xS,i)表示源域图像xS,i属于身份d(xS,i)的预测概率,其由分类模块获得。
均匀地将特征图分割为P个水平区域,然后在每个区域中应用池化以获得局部特征。但是,统一划分不可避免地会在每个区域产生异常值。例如,不同图像的相同区域不对应于相同的身体部位,这些异常值与其他身体部位更相似,因此,将这些异常值进行重新分配给最接近的区域。若区域内所属身体部位一致,T的同一区域中的列向量f应该彼此相似,并且与其他区域中的列向量不相似。
为此,需要对T中的所有列向量f进行动态分类。基于已经学习的T,按照公式(3)使用线性层和Softmax激活作为“软化”处理的方式。

其中P(Pi|f)表示f属于零件Pi的预测概率,W表示“软化”方法的可训练权重矩阵。
将f分配给Pi并以P(Pi|f)作为置信度,相应地,从所有列向量f中以P(Pi|f)作为采样权重对每个区域Pi进行采样。

其中F是张量T中列向量的完整集合,{}表示形成集合的采样操作。
经过“软化”处理进行重新分区后,源域所有区域的平均损失如公式(5)所示。

其中,Lid表示不同区域的交叉熵损失,计算方法如公式(1)所示。
1.3 域间与域内的不变性学习
把在源域训练的ReID模型直接在目标域的进行测试通常取得不理想的效果。通过了解域间与域内变化有助于提高跨域ReID中的模型自适应性。本文从域间姿势不变性、域内姿势不变性、样本不变性、相机风格不变性和邻域不变性5个方面来挖掘跨域ReID中不变性信息。
样本不变性(E)。扩大不同身份的样本之间的距离对提高ReID 识别能力是有益的。因此,样本不变性的作用是使每个样本相互远离,目标是最小化目标域训练集上的负似然对数。

其中,d表示真实的图像xT的身份。
邻域不变性(N)。样本不变性强制每个样本相互远离,但是具有相同身份的样本也会相距甚远,这对ReID 系统是不利的。因此,引入邻域不变性来鼓励每个样本及其邻居彼此接近能弥补样本不变性带来的不足。首先在样本存储器中找到与目标样本xT,i最为相似的k个样本,并定义它们的索引为M(xT,i,k)。因此,将xT,i属于类j的概率的权重分配如公式(7)所示:
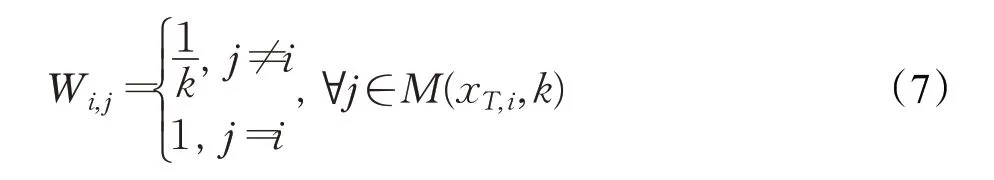
因此,邻域不变性的目标表达式如公式(8)所示:
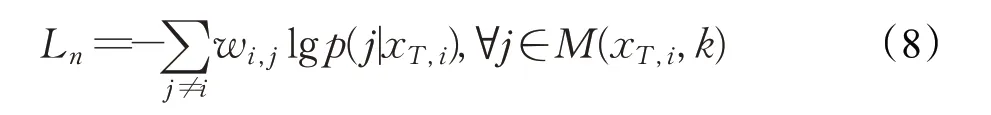
域间姿势不变性(R)。姿势的变化是影响跨域ReID 的重要因素。不同数据集有不同的行人分布特征,减小源域与目标域的特征分布差异有助于增强跨域ReID 的性能。本文提出域间姿势不变性,并采用DG-Net[15]为目标域生成源域的姿势。DG-Net不需要任何额外的辅助数据,仅利用现有的源域数据集内姿势便可为无标签的目标域生成相似的姿势,并在Market1501与DukeMTMC-reID 等大型数据集上表现良好。通过DG-Net 可以为目标域生成多个图像,这些图像保留衣服和鞋子,改变了其姿势,但每个真实的图像xT应与它改变姿势后的图像xTr属于相同的身份。因此,域间姿势不变性的损失函数计算如公式(9)所示:

其中,d表示真实的图像xT与改变域间姿势后的图像xTr的身份。
域内姿势不变性(A)。目标域训练集数据的多样性有助于提高ReID模型的泛化能力。为有效地扩大目标域训练集样本数量,本文提出域内姿势不变性,并采用DG-Net[15]将现有目标域内行人的姿势特征相互交换。交换姿势特征后行人的图像xTa应与其真实的图像xT拥有相同的身份。因此,域内姿势不变性的损失函数计算如公式(10)所示:

其中,d′表示真实图像xT与改变域内姿势后的图像xTa的身份。
相机风格不变性(C)。相机风格的不同也会影响ReID 的识别效果。对于目标域训练集,分别将每个摄像机视为一种样式域,采用StarGAN[8]为目标域训练摄像机样式(CamStyle)传输模型[16]。利用所学习的Cam-Style 传递模型,从任一相机收集的每个真实目标图像用其他相机的图像样式进行增强。每个真实的图像和它的风格转移对应的人拥有相同的身份。因此,相机风格不变性的目标损失函数如公式(11)所示:

其中,d″表示真实的图像xT与相机风格转移后的图像xTc的身份。
不变性损失累积和。通过结合域间域内变化的五种不变性特性,目标域训练集的不变性学习的整体损失如公式(10)所示。当i=j时,通过将分类为自己的类来利用样本不变性,相机风格不变性,域间和域内姿势不变性优化网络。当i≠j时,通过引导T,i接近它的中的临近值来利用邻域不变性优化网络。

1.4 样本存储器
为计算并转发ReID 网络的最新特征表示,本文采用样本存储器[11]来适应5 个不变性,其具有密钥存储器(K)和值存储器(V),其中,K负责存储FC-4096的L2标准化特征,V 负责存储标签。在每次训练迭代期间,对于目标训练样本xT,i,通过ReID网络转发它并获得FC-4096 的L2 标准化特征f(xT,i)。在反向传播期间,不断更新训练样本xT,i的密钥存储器中的特征。
1.5 网络总损失
为提高ReID 模型的跨域自适应性,网络的损失函数如公式(13)所示:

其中,α∈[0,1],它控制着源域和目标域所占比重。
2 实验数据与结果分析
本文研究实验平台的设置:Intel Xeon CPU E5-2640 v4 @ 2.40 GHz 处理器,11 GB 内存,GTX1080Ti显卡以及Ubuntu 14.04 操作系统,并使用pytorch 深度学习框架和Python编程语言实现。
2.1 数据集
为了方便对比实验结果,本文选择Market150 和DukeMTMC-reID两个广泛使用的数据集。本次实验依次将Market1501 和DukeMTMC-reID 数据集做为源域和目标域。训练和测试时输入图像均裁剪为128×256。
2.2 实施细节
(1)模型。实验使用ResNet-50[14]作为主干,将Conv5的步幅从2 改为1。在ResNet-50 的“pool5”层之后,附加一个4 096 维的完全连接层,接着添加批处理规范化和ReLU。在“pool5”层上应用Dropout,并将其值设为0.5。分区数P设置为6。
(2)训练。通过水平翻转和归一化来增强训练图像。将批处理大小设置为64,区域对齐训练时学习率初始化为0.1,40个epoch后衰减为0.01。当采用“软化”处理进行增强时,将学习率设置为0.01,再次训练10 个epochs进行重新分区。
(3)不变性。设定邻域不变性的正样本数k=6,损失权重α=0.2。
2.3 实验结果及分析
2.3.1 PR模型和5种不变性的有效性
本文依次将Market1501 和DukeMTMC-reID 作为源域,验证PR模型和5种不变性学习的有效性,对比结果如表1所示。其中,IDE表示基于ResNet-50的标准基线模型。在相同的实验平台设置下,将Market1501作为源域进行训练时,IDE、PCB[12]和PR对齐分别在25、40和55 个epoch 达到收敛,如图2 中(a)、(b)和(c)所示。完成模型训练总耗时分别约为35、55和70分钟,PCB训练时间的增加主要是由于取消了Conv5 层中最后一次空间向下采样操作,从而将张量T扩大了4倍,PR训练时间的增加主要是添加了4 096维的全连接层。

图2 模型训练曲线图

表1 PR和5种不变性学习的有效性 %
由表1 可以看出,在对标准IDE 进行统一分区与“软化”处理后,得到的PR 模型在加大训练时长的前提下有效地提高了跨域ReID 的识别准确度。在PR 模型的基础上添加样本不变性,相机风格不变性和邻域不变性后,Top-1 和mAP 的识别精度得到了极大提升。当继续添加域间和域内姿势不变性后,Top-1 和mAP的识别精度又略微上升。具体而言,在PR 模型的基础上结合域间与域内变化的5 个不变性特性后,分别在DukeMTMC-reID 和Market1501 上进行测试,Top-1 从44.1%提高到65.4%,从59.5%提高到77.5%;mAP 从24.7%提高到42.2%,从28.1%提高到45.1%。实验结果说明,PR 模型和5 种不变性特性对提高跨域ReID 的域自适应性是有益的。
2.3.2 与其他方法的比较
分别在Market1501 和DukeMTMC-reID 测试时,与目前仅考虑域间和域内变化的方法比较,结果如表2所示。
表2 比较了PTGAN[2]和SPGAN[1]两种提出域间风格迁移的方法,它们把源域训练样本风格迁移到目标域的测试集上。HHL[7]在目标域内进行细粒度风格迁移的方法,ECN[11]引入样本不变性、相机风格不变性和邻域不变性约束的方法。
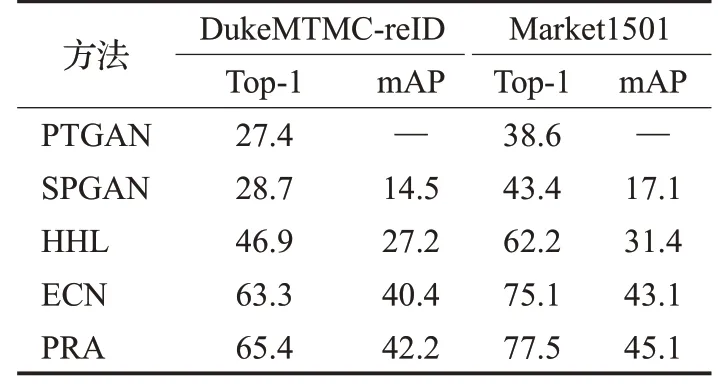
表2 与其他方法的比较 %
与目前领先的跨域ReID方法相比,本文提出的PR策略和结合域间与域内的5 种不变性约束的方法(PRA)明显优于它们。具体而言,当使用Market1501作为源域并在DukeMTMC-reID 上进行测试时,实现了Top-1 和mAP 分别为65.4%和42.2%的准确度。当使用DukeMTMC-reID 作为源域并在Market1501 上测试时,获得Top-1和mAP分别为77.5%和45.1%的准确度。在DukeMTMC-reID和Market1501上分别测试时,Top-1准确度比目前领先的ECN[8]高2.1个百分点和2.4个百分点。
3 结语
本文提出一种结合域间与域内变化来增强跨域行人重识别中的域自适应性方法。对源域行人图像统一分区和“软化”处理可有效提高跨域行人重识别的区域对齐的性能,进而提高模型的泛化能力。结合域间与域内变化添加5 个不变性约束,可极大地挖掘域间与域内的有用信息,提高跨域行人重识别中的域自适应性。实验表明,本文方法能有效地增强跨域行人重识别中的域自适应性。然而,对于姿势不变性、行人姿势改变前后只有衣服和鞋子是保持不变的,而体型和头部信息发生改变,因此,姿势特征的学习并不十分精准。进一步研究可以用更加精确的姿态转移算法,使原始行人的姿势特征可以更加准确地传递给目标行人。
