深度学习驱动的水下图像预处理研究进展综述
2021-07-14彭小红梁子祥陈荣发
彭小红,梁子祥,张 军,陈荣发
广东海洋大学 数学与计算机学院,广东 湛江524088
地球71%的面积都是海洋,海洋与地球上每个人的生活都息息相关。我国除了国土面积辽阔,更是拥有丰富的海洋资源,其中有6 500 多个岛屿,主要分布在渤海,黄海,东海,南海附近。我国是世界上海岸线最长的国家之一,大陆海岸线长约18 000 千米,岛屿海岸线长达14 000 千米,海岸线的总长度排在世界第四。200 海里的水域面积约有250 万平方千米,位居世界第十,这都是世界性的优势[1]。随着国家实力的日益增强,国际社会对海洋资源开发的不断重视,在未来,各个国家之间对于海洋资源的竞争必然会越来越激烈。目前,深度学习已广泛应用于水产养殖[2-4]、海洋资源勘测[5-7]以及海洋灾害防治[8-9]等领域,同时水下图像是海洋信息的一个重要载体,海洋资源的信息可以通过图像进行展示,如何将深度学习技术应用到水下图像中,成为一个至关重要的问题。
水下图像的成像环境较陆地复杂,由于水中的浮游生物、悬浮颗粒以及光照条件差等因素的影响,水下图像会呈现出对比度低、颜色失真、细节模糊等问题[10],因此对水下检测任务提出了严峻的挑战,如何对水下图像进行预处理成为了许多国内外学者迫切需要解决的问题。近些年,国内外有许多的学者对水下图像预处理做过大量的研究,克服了水下图像预处理中的种种技术难题,为水下图像预处理技术的发展做出了显著的贡献。有一些学者已经对水下图像预处理的相关技术进行了总结和归纳。林明星等[11]介绍了水下成像模型,以及水下图像预处理的两种方法:水下图像复原和水下图像增强,总结了这两种方法的优缺点,并对水下图像处理技术的发展进行了展望。郭继昌等[12]指出了水下图像退化的原因,并总结了水下图像增强和复原的相关算法,并通过实验,对不同的算法之间进行比较。近年来,随着深度学习研究的不断发展,深度学习被越来越多的学者应用到水下图像预处理领域,推动了水产养殖智能化,海洋资源勘测智能化以及海洋灾害防治智能化的发展。本文将重点介绍基于深度学习的水下图像预处理方法。
本文第1 章主要介绍水下图像成像的过程并对水下图像预处理方法进行分类。第2 章将传统的水下预处理方法分为基于非物理模型的增强方法和基于物理模型的复原方法,并对这两类方法进行介绍。第3章主要阐述深度学习在水下图像预处理方面的研究应用进展,大致可以分为结合物理模型的方法和非物理模型的方法[13]。第4章主要介绍了深度学习方法的改进。第5章主要指出现有方法存在的问题,并对未来研究发展进行展望。
1 成像过程介绍及预处理方法分类
1.1 水下图像成像过程介绍
可见光具有选择吸收性,可见光在水下传播时,其中波长较长的红光部分相较于蓝光和绿光被海水吸收的更多,因此水下拍摄出来的图像总是呈蓝绿色,这样就造成了颜色失真。另一方面,水下图像的成像环境十分复杂,水体中漂浮着许多悬浮颗粒以及充满了大量的浮游生物,光线经过悬浮颗粒的散射,进入成像系统,会使得图像的边缘细节模糊。根据Jaffe-McGlamery的水下模型[14],水下图像的成像过程如图1 所示。水下图像可以分为三个分量的线性组合,即直接衰减分量、前向散射分量和后向散射分量。直接衰减分量是经过目标物体反射而没有发生散射直接进入相机的光;前向散射分量是经过目标物体反射,同时反射过程中由于水中悬浮颗粒的影响发生散射而进入到相机的光;后向散射分量是由周围环境反射,并且发生散射而进入相机的光[15]。

图1 水下成像过程
在真实的水下图像拍摄过程中,通常相机与目标物体的间隔距离比较小,所以常忽略前向散射分量造成的影响,因此,得出水下成像模型[8]:

其中,Ic(x,y)表示的是相机捕捉到的水下图像;Jc(x,y)表示的是原始的清晰水下图像;tc(x,y)表示的是水下光传输率;Bc表示的是水下环境反射的光。则Jc(x,y)tc(x,y)代表了直接衰减分量,Bc(1-tc(x,y))代表了后向散射分量,同时,c∈{R,G,B} 代表了不同的颜色通道。
1.2 水下图像预处理方法分类
传统的图像预处理方法可以分为基于物理模型的复原方法和基于非物理模型的增强方法[16]。随着深度学习的不断发展,其在图像预处理领域也发挥出了巨大的作用。根据是否与物理模型相结合,基于深度学习的水下图像预处理划分为两类:一类结合了物理模型,将成像模型和数据驱动结合,实现了图像的复原;一类是没有结合物理模型,仅仅依靠数据驱动对图像进行恢复。按照所采用的模型不同,结合物理模型的方法又可以分为基于卷积神经网络(Convolutional Neural Networks,CNN)的方法和基于生成对抗网络(Generative Adversarial Networks,GAN)的方法。同样的,非物理模型的方法也可以分为基于CNN 的方法和基于GAN的方法。如图2是水下图像预处理方法分类图。
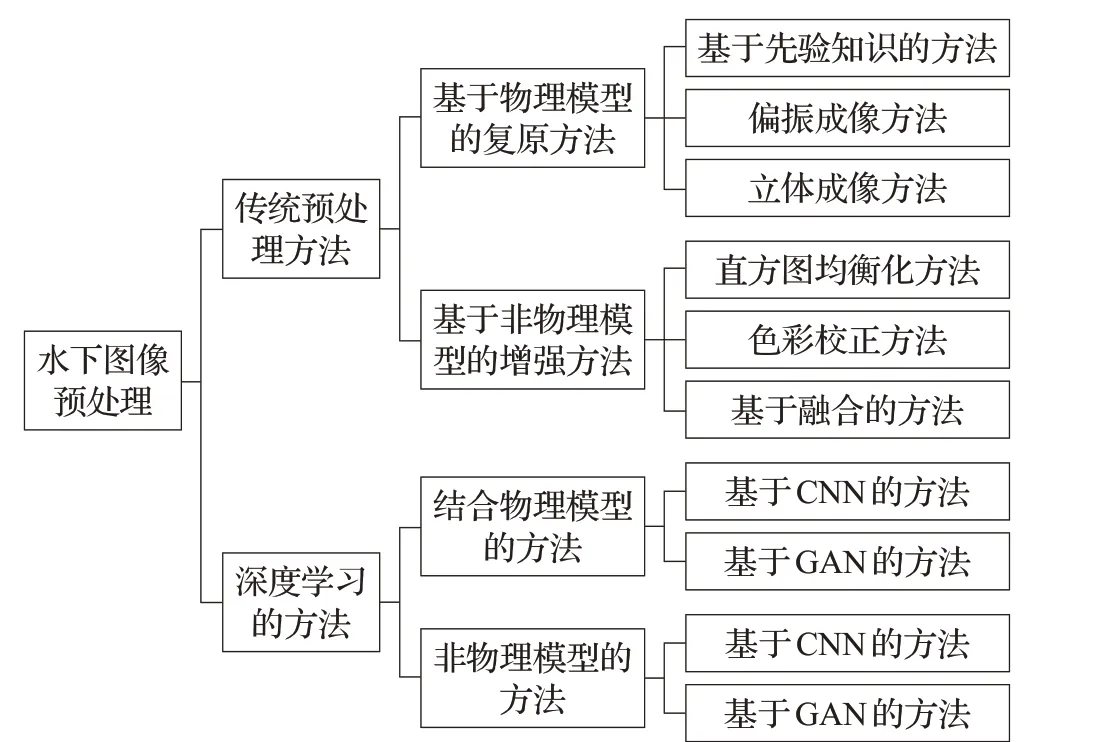
图2 水下图像预处理方法分类图
2 水下图像预处理传统方法介绍
2.1 基于物理模型的复原方法
基于物理模型的复原方法,需要考虑图像退化的过程。该方法需要对水下图像的退化过程进行数学建模,并估计模型的参数,即tc(x,y)和Bc,最后根据模型逆转水下图像的退化过程,得到清晰的水下图像Jc(x,y)。将复原方法进一步细分,又可以分为基于先验知识的方法、偏振成像方法和立体成像方法。基于先验知识的方法也被认为是软件的方法,该类方法投资成本低,并且易于使用[16]。偏振成像方法和立体成像方法属于硬件的方法,利用硬件设备对水下图像进行恢复,所用的硬件设备是传感器、偏振器和立体成像设备。
2.1.1 基于先验知识的方法
基于先验知识的方法主要有暗通道先验方法(Dark Channel Prior,DCP)以及DCP 算法的一些变体。DCP算法是一种基于Jaffe-McGlamery 模型的算法,由He等[17]人于2009年提出,该算法的目的在于准确地估计传输图(Transmission Map,TM)和背景光(Background Light,BL)。DCP 算法一经提出便引起轰动,后续有许多研究人员在DCP 算法的基础上进行改进[18-22]。除了DCP 算法,还有一些其他的算法被用于水下图像的复原。Carlevaris 等[23]提出了最大强度先验(Maxmum Intensity Prior,MIP)算法;Peng 等[24]提出了模糊先验(Blurred Prior,BP)算法;Song 等[25]提出了水下光衰减先验(Underwater Light Attenuation Prior,ULAP)算法,这些算法都可以准确地估计TM和BL。当先验知识不准确时,基于先验知识的方法往往会导致较大的估计误差。水下图像缺乏可靠的先验知识,已经成为阻碍该方向研究的一大障碍。
2.1.2 偏振成像方法
偏振是指横波的振动矢量偏于某些方向的现象,是光的固有属性,它能提供比颜色和光强分布更具有价值的信息。通过在同一水下场景的不同偏振状态下收集偏振图像,水下偏振成像技术可以准确地估计偏振特征的反向散射光,因此在反相退化过程中,获取背景散射光强度和透射系数,提高图像的清晰度。Schechner等[26]人首先使用偏振成像方法对水下图像进行处理,后人在其基础上也做了大量相关的研究和改进[27-32]。偏振成像方法可以在不计算环境参数或自然光的情况下恢复场景的结构信息,提高图像的可见性,但对水下运动物体进行采集图像信息时,很难采集到相同的偏振图像。
2.1.3 立体成像方法
立体成像技术是在海床上放置立体摄像机来捕捉图像。近年来,3D图像技术发展迅速,但是使用立体图像技术对水下图像进行处理的研究还较少。Roser 等人[33]于2014 提出了用于自主水下航行器(Autonom-ous Underwater Vehicle,AUV)的立体成像方法,主要是通过估计能见度系数来恢复水下图像。Lee等人[34]提出了一种利用立体雾日图像提取去雾图像的新方法,主要是通过计算散射系数和深度信息来估计水下图像的TM。立体成像方法不需要先验知识,也不需要在不同时间拍摄大量图像,由于估计的视差层在远景物中表现为不连续现象,无法获得自然景物的结构信息。
三种复原方法其原理和属性的不同,则其适用的场景也有所不同。基于先验知识的方法其成本低廉,算法简单,但是需要估计大量参数,这些参数会随场景的变化而变化,因此可以嵌入至小型嵌入式设备中用于水产养殖监控。偏振成像方法和立体成像方法需要特殊的硬件设备,因此成本较高,由于偏振成像方法难以采集到运动物体的相同偏振图像,可以用于海底生态环境或者珊瑚群的监控。立体成像方法不需要在不同时间拍摄大量图像,可用于海洋军事领域[33]。
2.2 基于非物理模型的增强方法
水下图像的增强方法不考虑图像的成像过程,也无需考虑成像模型的一系列参数,直接运用图像处理的方法,通过主观去调整图像中的像素值,从而消除噪声,改善边缘模糊,加强目标物体的特征,削弱不相干环境特征对目标的影响。近年来,研究人员提出了许多水下图像的增强方法,如直方图均衡化方法、颜色校正方法、基于融合的方法等。
2.2.1 直方图均衡化方法
直方图表示图像的色调分布。直方图均衡化是一种典型的图像增强方法,常被用来解决低对比度问题。Hummel[35]于1977年提出通过改变直方图的分布来增强图像,自此直方图均衡化受到研究者广泛关注。在其基础上,Pizer 等[36]提出了自适应直方图均衡化(Adaptive Histogram Equalization,AHE);Kim 等[37]提出了局部直方图均衡化(Local Histogram Equalization,LHE);Reza等[38]提出了对比度受限自适应直方图均衡化(Contrast Limited Adaptive Histogram Equalization,CLAHE),还有一些相关的演变算法[39-42]。直方图均衡化方法虽然可以提高图像的对比度,但是由于没有考虑水下光学成像模型,会引入一些额外的噪声。在需要提高对比度的场景下,可作为复原方法的后处理使用。
2.2.2 颜色校正方法
直方图均衡化方法可以解决水下图像对比度低的问题,但是不能解决颜色失真的问题,颜色校正方法中白平衡方法和Retinex 方法可以很好地解决该问题。白平衡方法的目的是为了消除可见光在水下的选择吸收性而引起的色移,常见的方法有MaxRGB[43]、灰度世界假设[44]、自动白平衡[45]以及一些其他的方法[46-48]。Retinex 方法在1963 年就被提出,该方法模拟了人类视觉的感知机制,通过对场景中光照的估计,实现色彩的恒定。常见的方法有单尺度Retinex 算法(Single Scale Retinex,SSR)[49]、多尺度加权平均Retinex 算法(Multi-Scale Retinex,MSR)[50]、带彩色恢复的多尺度Retinex算法(Multi-Scale Retinex with Color Restoration,MSRCR)[51]以及一些其他相关的方法[52-55]。
2.2.3 基于融合的方法
基于融合的方法采用融合策略将具有不同特征的图像进行融合。Ancuti 等[56]首先提出融合的方法对水下图像和视频进行增强,该方法可以很好地解决颜色失真的问题和提高对比度。近年来,有许多研究者在其基础上做了大量的改进[57-59]。基于融合的方法采用多尺度融合策略,可以有效避免线性融合造成的晕影,从而增强图像,但是该方法忽视了物理模型,在图像的不同区域会造成过饱和的现象。
增强方法可以方便快速地提高水下图像的视觉效果,但是由于没有考虑物理模型,不能完全解决图像的退化问题,噪声、颜色失真、晕影的问题依旧存在。三种增强方法由于其原理不同,适用的场景也有所不同。直方图均衡化方法常用在需要提高图像对比度的场景,比如水下考古[60]。颜色校正方法可以很好地解决颜色失真的问题,常被应用在水下堤坝裂缝检测[61]、河蟹[62]、海胆[63]等识别。基于融合的方法可以避免晕影的产生,常被应用于水下机器人[64]以及海参[65]识别。
3 深度学习在水下图像预处理中的应用
近些年来,深度学习方面的研究取得重大进展。由于深度学习强大的特征学习能力,常常被应用于各类视觉任务中,本章主要介绍基于深度学习的水下图像预处理方法。根据是否与物理模型相结合,可以分为物理模型的深度学习方法和非物理模型的深度学习方法。
3.1 物理模型的深度学习方法
通常在特定的数据集中,基于深度学习的方法具有强大的学习能力,其性能优于传统的基于物理模型的方法。但是,当测试图像和训练图像之间的域间隙较大时,性能会降低。此外,部分网络缺乏物理模型的约束,网络会生成意外的伪像,这对图像质量和后续的视觉任务有害;另一方面,对于基于物理模型的方法,估计模型中的图像衰减系数并非易事,其中神经网络可能是推断参数和学习潜在相关因素的重要工具。因此,将这些方法结合起来将具有显著的效果。
3.1.1 CNN与物理模型相结合的方法
CNN模型最早是由日本学者福岛邦彦于1982年提出[66-67]。经过多年的研究和发展,CNN模型逐渐发展成为深度学习的代表算法之一,常被应用于各类视觉任务之中。CNN 模型的主要结构是输入层、卷积层、池化层、全连接层和输出层。在输入层输入数据,通过卷积层和池化层提取数据中的特征,最后在输出层对不同特征进行分类输出,从而实现不同任务[68]。
CNN结合物理模型的方法也被称为基于CNN的复原方法。该方法主要是通过构建CNN 模型并训练,在输入层输入一张水下图像,输出层输出该水下图像的TM和BL,将TM和BL代入至水下成像模型中,经过反演得到真实清晰的水下图像。主要流程如图3所示。
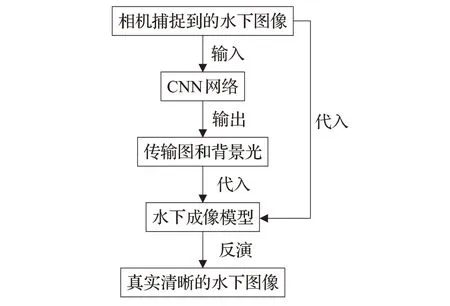
图3 基于CNN的复原方法
传统的物理模型方法常常要基于一些先验知识,这种方法估计出来的TM以及BL会受到人为主观因素的干扰,并不是十分准确。由CNN 网络得出的TM 和BL具有更好的准确性,因此可以反演出更清晰真实的水下图像。为了解决水下图像颜色失真和雾化问题,Cao等人[69]提出了两种神经网络结构用以估计TM和BL,为了估计BL,采用了一个五层CNN,该网络前三层是卷积层,具有5×5、5×5和3×3的筛选器大小,每个层具有2×2的池化层和规范化层,最后两个图层完全连接,并输出BL。为了估计TM,提出了一个多比例架构,该架构堆叠了两个深度网络,分别是粗糙的全局网络和精炼网络。粗糙的全局网络首先具有五个卷积层,前两个卷积层具有2×2的池化层和规范化层,最后一个卷积层只有2×2的池化层。全局网络的最后两层是完全连接层,网络的输出与精炼网络第一层的输出进行串联。精炼网络有三个卷积层和一个上采样层,最后一个卷积层之前放置一个上采样层,期望上采样要素图,网络的最终输出是预测的TM。Cai 等[70]人提出了一种端到端的去雾模型(Dispel Haze Networks,DehazeNet),该模型以模糊图像作为输入,输出TM,并通过大气模型对水下图像进行恢复。该模型采用了深层次的CNN 架构,并提出了一个新的非线性激活函数,称为双侧校正线性单元(Bilateral Rectified Linear Unit,BReLU),以提高模型的收敛性。
结合残差学习,Hou等人[71]提出了水下残差卷积神经网络模型(Underwater Residual Convolutional Neural Neworks,URCNN)用于水下图像复原。该网络将水下图像复原任务分为了TM学习和场景残差学习,其模型结构包括了用于TM 估计的数据驱动残差架构和用于水下照明平衡的知识驱动场景残差公式。因此,该方法可以汇总先验知识和数据信息,推测出潜在的水下图像分布。将先验知识和数据信息整合在一起,旨在学习精确的传输图。在训练过程中,采用残差学习策略的制定和批次规范化以提高学习效果。最后基于灰度世界假设和多尺度局部最大饱和度的特征,提出了一种有效的照明平衡解决方案来矫正图像颜色。基于CNN 的复原方法考虑了图像的退化过程,使得模型更具解释性,但同时也受到物理模型的限制,其鲁棒性和适应性较差。
3.1.2 GAN与物理模型相结合的方法
GAN 被广泛认为是近年来最重要的想法之一[72]。在2016 年,Yann LeCun 甚至说这是“近十年来机器学习中最有趣的想法”。GAN主要由两个神经网络组成:一个试图生成看起来与训练数据相似的数据的生成器,另一个试图从虚假数据中分辨出真实数据的判别器。生成器和判别器之间相互博弈,生成器不断生成与训练数据相似的数据去“欺骗”判别器,判别器则判断该数据的真假,如果无法欺骗判别器,则继续训练生成器,直至判别器无法辨别数据的真假。
GAN与物理模型相结合的方法也被称为基于GAN的复原方法。该方法主要是将物理模型作为设计生成器的指导,通过生成器合成水下图像,并将合成的水下图像送入判别器中进行判断,最终得到复原后的图像,其主要流程如图4所示。
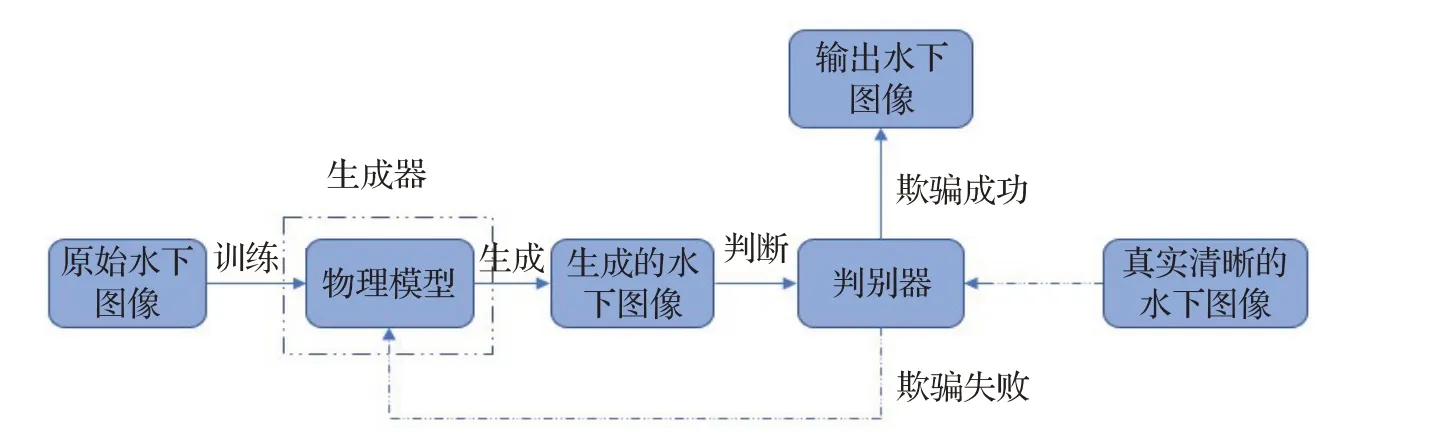
图4 基于GAN的复原方法
Li 等人[73]提出了一种基于学习的单目水下图像颜色校正生成对抗模型(Water Generative Advsarial Networks,Water-GAN),该模型使用了两阶段策略来最终消除水下图像中的颜色失真问题,并应用于水下岩石资源图片的颜色处理。首先,WaterGAN将空中的RGB-D图像和一组水下图像样本作为输入,WaterGAN 的生成器具有三个主要阶段,每个阶段都是以水下图像的物理形成过程进行建模:衰减(G-I)、散射(G-II)、相机模型(G-III),此结构的目的是确保生成的图像与输入的RGB-D图像的基础结构相同。通过生成器生成相应的合成水下图像作为输出。然后,将合成的水下图像和水下图像样本都输入到颜色校正网络中对图像色彩进行恢复。Lu 等人[74]提出使用多尺度循环生成对抗网络(Multi-scale Cycle Generative Adversarial Networks,MCycleGAN)对水下图像进行复原。该方法是将DCP算法与循环生成对抗网络(Cycle Generative Adversarial Networks,CycleGAN)结合,首先通过DCP 算法得到图像的TM,然后将TM送入到CycleGAN网络中进行多尺度计算,通过结构相似性指标度量值(Structural Similarity Index Measure,SSIM)损失可以使输入与输出的图像的内容与结构相似,得到更清晰的水下图像。
由于有条件信息,条件生成对抗网络(conditional Generative Adversarial Networks,cGAN)[75]比原始GAN具有更好的稳定性和更强大的表示能力,尤其是对于生成逼真图像的图像增强和恢复任务而言。在cGAN 模型框架基础下,Liu 等人[76]提出了一种用于水下图像复原的新型物理模型集成网络框架,并对水下ImageNet数据集中的鱼类及潜水员图片进行了处理,证明了该方法在实际应用中具有巨大发展前景。该框架基于Akkaynak-Treibitz物理模型[77]和最新的全局和局部特征融合网络[78]进行设计,此网络设计与当前现有的网络明显不同,Akkaynak-Treibitz 物理图像退化模型被认为是设计生成器的指导,通过生成器网络训练学习图像退化模型中的参数和系数,以重建清晰的水下图像,并将重建的水下图像送入判别器中进行判别,最终输出清晰的水下图像。基于GAN的复原方法可以很好地恢复图像的颜色特征,解决颜色失真的问题,但由于网络体系结构复杂,训练将耗费大量时间,实际使用时受到一定的限制。
3.2 非物理模型的深度学习方法
水下环境十分复杂,不同的水域其水下环境都有所不同,传统的基于物理模型的方法对不同水域的适应性极差。当深度学习与物理模型相结合时,会受到物理模型的约束,降低其适应性,非物理模型的深度学习方法则在适应性方面具有较好的表现。
3.2.1 非物理模型的CNN方法
非物理模型的CNN方法其主要核心是构建深度学习神经网络框架和损失函数,通过CNN 模型的强大学习能力,将相机捕获到的原始水下图像送入到网络模型中,在输出层输出真实清晰的水下图像。这种方法不需要建立数学模型,摆脱了各种先验知识和前提条件的限制,通过CNN 模型直接学习原始水下图像和真实水下图像的直接映射关系。非物理模型的CNN方法也被称为基于CNN的增强方法,其流程如图5所示。
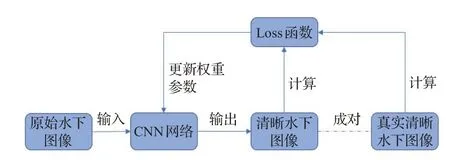
图5 基于CNN的增强方法
Sun 等人[79]提出了一个具有编码器-解码器结构的卷积神经网络(Encoder Decoder Alexnet,ED-Alex-net),ED-Alexnet 可以自发地学习低质量水下图像和高质量水下图像之间的映射规律,以端到端自适应的方式实现图像增强,而不考虑物理环境。该模型是一个编码解码对称的网络,主要由两个部分组成,分别是卷积层和去卷积层,卷积层作为编码,而去卷积层作为解码。在卷积层通过多对一的映射操作,过滤图像的噪声并保留了关键的特征,在去卷积层通过一对多的映射操作,恢复对应卷积层缺失的细节。Wang等人[80]提出了一个基于CNN的水下图像增强网络(Underwater Image Enhancement Networks,UIE-Net)。UIE-Net网络主要由两个子网络组成,分别是颜色校正子网络(Color Correction Networks,CC-Net)和去雾子网络(Haze Removal Networks,HR-Net),该网络利用像素中断策略显著提高了网络的收敛速度,通过统一训练的方式实现了水下图像的颜色矫正和去雾。
一般情况下,很难获取到清晰的水下图像,为了使训练能正常进行,通常采用合成的图像,合成的图像与真实图像具有一定差别,所以此类方法具有一定局限性。Yeh等人[81]提出了一种基于色相保留的深度学习框架,该框架包含用于水下图像颜色恢复的三个卷积神经网络。首先,使用第一个CNN 网络将输入的水下图像转换为灰度图像,再通过第二个CNN 网络增强灰度水下图像,然后通过第三个CNN 网络对输入的水下图像进行颜色校正,最后通过色相保留对三个CNN 网络的输出进行融合,可以获得色彩校正的图像。用于水下图像处理的CNN网络其主要问题在于水下训练图像太少,并且缺少相应的地面真实图像,因此其使用CycleGAN来训练水下CNN网络,该方法将三个CycleGAN组合在一起,可以同时训练三个CNN 网络,以共享回归状态,使得三个CNN 网络互相支持,从而避免训练过拟合且没有约束。基于CNN的增强方法的主要目标是忠于原始图像,由于其完全依赖训练数据的特点,当面对不同水域类型或退化程度的图像时,性能会降低。
3.2.2 非物理模型的GAN方法
GAN 是一种数据驱动的训练方式,如今常被应用于图片生成和风格学习的任务中,在水下图像预处理领域也有广泛的应用。非物理模型的GAN方法也被称为基于GAN的增强方法,其与基于GAN的复原方法的主要区别是生成器:基于GAN 的复原方法的生成器是由物理模型指导设计的,受到物理模型的限制,基于GAN的增强方法其生成器一般是编码器-解码器结构。其流程图如图6所示。

图6 基于GAN的增强方法
水下环境复杂,获取水下成对的图像需要耗费大量的人力物力。Zhu 等人[82]基于端到端的思想,提出了CycleGAN 模型,该模型不需要配对数据即可进行训练。对于水下图像的增强任务,经过Fabbri等人[83]的实验验证,证明了CycleGAN在水下图像的增强任务中是有效的,因此解决了模型需要成对数据训练的难题。近年来,CycleGAN 已经被广泛地应用于水下图像预处理任务中。在CycleGAN 的基础上,Han 等人[84]提出了一种端到端的螺旋生成对抗模型(Spiral Generative Adversarial Networks,Spiral-GAN),用于水下图像增强任务以恢复水下图像。该模型具有许多卷积-去卷积块生成器,可以在原始的水下图像中保留更多有意义的细节。同时还采用了由均方误差和角度误差组成的像素级损失函数来稳定地训练模型,以克服过度曝光不足问题和避免颜色失真。Liu等人[85]提出了一种基于深度残差模型的水下图像增强解决方法,与其他基于深度学习的增强方法不同,该方法专注于生成对抗网络与弱监督学习网络之间的合作,旨在建立更深的网络并改善水下图像增强的性能。首先采取Cycle-GAN 网络生成大约4 000 张合成的水下图像,作为水下图像增强的训练集。其次,根据残差学习的思想提出了水下残差网络(Underwater Residual networks,UResnet)用于水下图像增强,同时提出了边缘差损失[86](Edge Difference Loss,EDL)以提高深度学习网络的细节增强能力。Li 等人[87]根据图像到图像转换网络的最新研究进展提出了一种弱监督的颜色传递方法,以纠正颜色失真。该方法的目标是学习源域(即水下)和目标域(即空气)之间的映射关系,模型包括了前向和后向两个映射,以及两个判别器。受CycleGAN 的启发,设计了一个多端损耗函数,包括对抗性损耗、周期一致性损耗和结构相似性指数测量损耗,这使得输出的内容和结构与输入相同,同时输出图像的颜色与陆地拍摄的图像颜色相似。
cGAN 比原始的GAN 具有更强的表示能力,也被研究人员应用于水下图像的增强任务中。Yang 等人[88]提出了基于cGAN 的方法解决水下图像增强问题,该方法的cGAN 网络由多尺度生成器和双重判别器组成,多尺度生成器包括多尺度特征提取单元、特征细化单元和残差图估计单元,可以生成清晰的水下图像。双重判别器包括了两个子判别器,子判别器的网络结构相同但权值不同,目的是使判别器能够引导生成器生成全局语义级别和局部细节级别的真实图像。在训练阶段,将一批水下图像输入到多尺度生成器中可以输出相应的残差图,残差图添加至输入的水下图像后,可以获得潜在的清晰图像。将结果送至双重判别器,然后判别器在不同的尺度下判断生成的结果是真还是假。在推断阶段,通过多尺度生成器以端到端的方式增强输入的水下图像。基于GAN 的增强方法的主要目标是提高图像的感知质量,但由于未考虑水下图像退化过程,所以不能完全恢复图像的一些物理特征,噪声可能依旧存在。
传统算法及深度学习算法比较见如表1所示。

表1 各种算法比较
4 深度学习方法的改进
4.1 轻量化方法
深度学习方法为了提高水下图像的恢复质量,不断增加模型深度,WaterGAN[73]可以很好地复原图像,解决颜色失真问题,但其网络深度有42 层,模型结构复杂。该类方法在实验室取得了令人瞩目的成绩,但在实际应用中受到了一定的限制。小型嵌入式设备计算能力有限,但在实际应用中更为广泛,因此轻量化的深度学习方法也是研究的一大热点之一。
结合物理模型,Li等人[89]提出了水下图像增强卷积神经网络模型(Uderwater Convolutional Neural Neworks,UWCNN),该模型网络深度有10层,同时采用块结构和残差学习策略,可以有效地复原图像。候岷君[90]提出了一种数据与先验聚合的传输网络(Data-and-Prior-Aggregated Transmission Networks,DPAT-N),该网络利用了特定领域知识,从而获得更准确的TM,且该网络深度只有6层,是一个轻量级的模型。
不结合物理模型,Fu 等人[91]提出了全局-本地网络(Global-Local Networks,GLNet),该模型网络深度只有4层,与压缩直方图均衡化配合使用,可以有效地恢复水下图像。Sun等人[92]提出了像素到像素网络(Pixel to Pixel Networks,P2PNet),该模型网络深度有6 层,并采用了编码器-解码器的体系结构对水下图像进行增强。Fabbri等人[83]提出了一种水下生成对抗网络(Underwater Generative Adversarial Networks,UGAN),该模型的网络深度为9层,其生成器受CycleGAN启发设计,判别器是完全卷积的。Li 等[93]人提出了融合生成对抗网络(Fusion Generative Adversarial Networks,FGAN),该模型的网络深度有8 层,可以接受多个输入,并将其通过同一个网络的不同分支,其生成器是基本的块结构,判别器由采用频谱归一化的卷积层组成。
轻量化算法比较如表2所示。

表2 轻量化算法比较
4.2 鲁棒性和适应性改进
尽管现在深度学习的方法已经取得了较好的成果,但在实际情况中,这些方法的适应性和鲁棒性仍有很大的欠缺。由先验驱动的水下图像增强模型需要特定的领域知识,当其假设在该场景不匹配时,该方法可能会失效,另一方面,纯数据驱动的深度学习方法,其网络的性能与训练数据的质量和数量紧密相连,由于完全依靠数据驱动,当训练图像和测试图像的域间隙较大时,模型将在不同色偏,浑浊度的图像上失败。目前对深度学习方法鲁棒性和适应性改进的研究比较少,主要有两个改进方向:一是通过改进网络的结构,使模型能够适应各种水下环境;二是采用覆盖面更广的训练集。
改进网络结构的方法主要有两种方式,一种是采用编码器-解码器结构,利用编码器学习与海水类型无关的图像特征,解码器通过这些特征还原清晰的水下图像。Chen 等人[94]提出了一种基于GAN 的复原方案(GANRecovery Scheme,GAN-RS),该方法的生成器采用了编码器-解码器结构,并开发了一个包括对抗分支和批评分支的多分支判别器,以同时去除水下噪声和保持图像内容,为了训练批评分支还提出了水下索引损失函数。除了对抗学习,通过一种新颖的暗通道先验损失也促使了生成器产生更真实的图像。张墨华[95]提出了一种判别式学习的水下图像复原模型,称为URM_AEDN,该模型基于结合对抗学习的编码器-解码器网络,采用了监督学习的方式。URM_AEDN 网络由三部分组成:编码器、解码器、判别器。编码器提取图像特征,解码器根据特征复原图像,判别器判别海水类型,编码器与判别器互相博弈进化,最终达到均衡。另一种是采用域自适应机制,通过将测试的水下图像和训练的数据集特征相结合,消除训练图像和测试图像之间的域间隙,提高模型的鲁棒性和适应性。Zhou 等人[96]提出了一种基于物理模型的反馈控制和域自适应机制的鲁棒对抗学习模型,该模型将物理模型和GAN 网络结合。通过域自适应机制消除测试图像和训练图像的域间隙,满足鲁棒性和适应性的要求,再通过反馈控制控制GAN的训练,使得复原的图像在物理上是正确的。域自适应机制可以很好地提高模型鲁棒性,但由于其复杂性,往往不满足轻量化的要求,Zhou等人[96]提出的方法其网络深度有29 层,在实际应用中具有一定局限。编码器-解码器结构不失为一种很好的选择,既满足鲁棒性和适应性的要求,又符合轻量化的要求,实际应用中使用的较为广泛。
采用覆盖面更广的训练集,模型可以学习不同类型水域的特征,从而以提高模型的鲁棒性和适应性。Li等人[89]提出将水下成像模型与水下场景的光学特征相结合,合成涵盖了不同水域类型和退化水平的水下图像退化数据集,通过该数据集训练轻量化模型UWCNN,通过在现实世界的水下图像和视频上进行实验表明,该方法可以很好地推广到不同水下场景。张墨华[95]通过水下图像生成模型合成包含十种类型的水下图像数据集,并使用该数据集训练URM_AEDN模型,以提高模型鲁棒性。想要获取大量的不同水域类型及退化水平的真实水下图像十分困难,所以一般采用物理模型合成水下图像,但合成的图像和真实图像往往具有一定差异,会对模型性能造成一定影响。
5 结语
随着国家对海洋资源的重视,水下图像预处理技术在海洋资源开发,水产养殖以及海洋灾害防治领域显得越发重要,受到国内外许多学者的广泛关注。深度学习经过多年的研究发展,在水下图像预处理领域中已经取得巨大进步,本文对现有基于深度学习的水下图像预处理方法进行了总结和归纳,并重点分析了这些方法的优缺点,还介绍了深度学习方法的相关改进。深度学习虽然在水下图像预处理领域中理论方面取得了巨大的进步,但是在水产养殖,海洋资源开发等实际应用情况下,依旧存在一些问题需要解决:
(1)提高水下图像预处理方法的实时性。基于深度学习的水下图像预处理方法往往网络结构复杂,需要耗费大量的时间进行计算,无法保证预处理的实时性,因此需要在保证预处理的效果的同时简化模型,设计一个高效的深度学习模型是未来的一大研究方向。
(2)提高水下图像预处理方法的鲁棒性和适应性。水下环境复杂多变,现有的方法不具备很好的鲁棒性和适应性,大部分预处理方法仅对某一类水下环境有效,无法对不同的水下环境做出自适应的调整,因此如何提高水下图像预处理方法的鲁棒性和适应性,还需要进一步的研究。
(3)深度学习需要与物理模型进行结合。现在大部分深度学习的方法没有结合物理模型,只是在视觉上对图像进行了增强,不能很好地反应真实水下环境。因此,深度学习需要和物理模型进行结合,才能复原真实原始的水下图像。深度学习与物理模型结合的方法,往往会受到物理模型的限制,因此如何设计一个合理的物理模型也是一大难题。
(4)建立预处理和识别一体化模型。水下图像预处理的目的是提高水下目标识别的准确率,因此,将水下图像预处理方法和水下目标识别方法结合,满足了实用性的要求。
(5)降低水下图像预处理模型的复杂度。现有的水下图像预处理模型比较复杂,在水产养殖监控和海洋资源勘探等情形下,往往要将复杂的模型载入一些小型的嵌入式设备,这些小型嵌入式设备的运算处理能力较弱,因此无法装载复杂度较高的模型。如何保证预处理效果的前提下,降低模型复杂度,是未来科研人员需要解决的一大难题。
