精神分裂症和抑郁症患者静息态脑电分类
2021-07-14冯静雯赖虹宇张军鹏
罗 渠,冯静雯,赖虹宇,李 涛,邓 伟,刘 凯,张军鹏
1.四川大学 电气工程学院,成都610065
2.四川大学 华西医院心理健康中心,成都610065
精神类疾病给社会带来了相当大的经济负担,根据2015年的多国统计数据,精神分裂症病人每年的人均花费从泰国的5 818 美元到挪威的94 587 美元波动,其中在澳大利亚每个病人的终生花费可高达988 264 美元。根据2010 年的数据,欧洲每年在抑郁症治疗上的花费也高达919 亿欧元[1-2]。对于这两种耗费大量社会资源的精神疾病,及时准确的诊断将有助于它们的治疗。
精神分裂症是一组病因不明的重性精神疾病,临床上往往表现为症状各异的综合征,其涉及感知觉、思维、情感和行为等多方面的障碍以及精神活动的不协调[3]。多起病于青少年和成年早期,伴随有阳性症状(如幻听、妄想、思维紊乱、显著紧张和异常行为等)和阴性症状(如意志消沉、情感淡漠等)[4]。个体之间症状差异较大,其诊断往往采用精神量表和医学诊断手册或通过影像学检查[5]。抑郁症是一种在青少年中发病率很高的心理疾病,其特征是情绪消沉,缺乏自信,对于任何欢愉活动缺乏兴趣,自卑抑郁,甚至带有厌世情绪[6]。具有高发病率、高复发率、高自杀率和高自残率等特点,严重损坏患者的身心健康[7]。这两种疾病的发病机制至今没有明确的解释,而且两者常会有一些相似的临床表现,例如意志消沉、缺乏自信[8]。精神分裂症患者中抑郁症的患病率高达42.5%[9],在精神分裂症的治疗过程中,其预后效果不理想也与患者患抑郁症有很大关系[10]。研究表明[11],精神分裂症患者和抑郁症患者的EEG 信号在节律,波幅以及功率等方面均与正常人存在差异,因此本文试图通过采集两类患者静息态下的EEG 信号,通过深度学习的方法来对两者进行区分。
脑电图(EEG)是一种使用电生理指标记录大脑活动的方法,具有高时间分辨率,非侵入性,成本低的特点[12]。EEG数据的表示方法有很多,最主要的两种特征表示方法是频域特征和时域特征[13-14]。其分析方法也不尽相同,可以采用传统的机器学习的方法进行特征提取与分类[15],也可以利用深度学习进行处理[16]。其中深度学习是一种特殊的机器学习算法,它能够将特征提取和分类进行结合,同时从数据中进行学习[17]。
近年来,深度学习在计算机视觉、自然语言处理等方面取得众多前所未有的成果。从图像分类[18]到目标检测[19],从语音识别[20]到语义分割[21]等均有较大突破。并且深度学习在医疗诊断中的应用也日益广泛[22-23],本文根据数据的转换形式采用了深度学习中的卷积神经网络(CNN)来对两种疾病进行分类。卷积神经网络是计算机视觉领域中广泛使用的一种深度学习模型。它对于自然信号(如图像和音频)的处理具有显著的优势。通过多个卷积层的卷积和非线性组合,模型可以将高级的特征表示成更加抽象复杂的低级特征的组合,这使得模型可以学习到模式的空间层次结构。通过池化层,模型可以学习输入信号的局部模式,将输入信号用较为粗糙的形式进行表示,这使得卷积神经网络学到的模式具有平移不变性。
考虑到精神分裂症患者脑电的复杂性,以及进行手动提取特征时的多样性,本文采用卷积神经网络来对脑电数据进行自动的特征提取和分类。为了对多个电极通道和频段进行分析,还提出了一种EEG 数据表示方法。通过采集精神分裂症和抑郁症患者的EEG 信号,经过数据预处理去除眼电、头动、工频干扰等伪迹。将转换后的EEG 频谱图转换为灰度图的形式,利用卷积神经网络进行分类。
1 材料
1.1 数据描述
本次研究的数据来源于四川大学华西医院第二门诊部心理卫生中心数据库,和该中心签署了合作协议和保密协议,已得到数据使用授权许可,且所有参与数据采集的患者均已签署知情同意书。实验收集了70例精神分裂症患者(SCZ)和70例抑郁症患者(DP)的脑电数据,患者年龄均在32岁到51岁之间且服从正态分布,患者年龄和性别差异均无统计学意义(P>0.05)。数据采集设备使用动态脑电图仪(NATION8128W,上海诺诚电气有限公司,中国),采样频率为128 Hz。采集涉及16 通道的脑电图帽(如图1),传感器按照10-20 电极放置标准[24]。

图1 采集EEG信号的电极分布图
实验数据采集时,患者处于一个安静封闭的室内进行。患者需保持安静、放松、清醒的状态。实验开始,患者闭眼并做深呼吸3 min,结束后睁眼给予被试10 s 缓冲时间。然后开始闭眼状态保持7 s,睁眼状态保持7 s,以此为一个闭眼睁眼数据采集周期,进行3个周期后结束数据采集。由于实际过程中存在操作误差,所以真实记录睁眼和闭眼状态数据时长为5~10 s。
1.2 数据预处理
用EEGLAB 对数据进行必要的预处理。(https://sccn.ucsd.edu/eeglab/index.php)首先根据睁眼闭眼的时间节点导入原始采样数据,进行电极定位,其次对数据进行滤波操作。具体分两次进行,采用1 408 阶FIR(Finite Impulse Response)滤波器进行0.3 Hz 的高通滤波,采用38 阶FIR 滤波器进行45 Hz 的低通滤波,最后设置50 Hz 陷波以减小工频干扰。显示波形后若发现坏导则去掉坏导并用周围的通道平均值进行替代。
然后根据实际通道数利用ICA(Independent Component Analysis)计算出16 个独立成分,进行眼电、头动、工频干扰等伪迹的去除。原始脑电数据一般是由各类伪迹与有效的脑电信号经过线性或近似线性混合得到。由于混合系统未知,因此伪迹和有效脑电信号均可视为未知隐藏变量,这些变量相互独立并且往往服从非高斯分布。利用ICA 可以找到各个独立成分。ICA 的一般线性模型如式(1):

其中z为原始脑电信号,s为有效脑电信号,B为混合矩阵。ICA的目的就是在已知z的情况下,找到一个混合矩阵W使y的各个分量相互独立(z=Wy),从而使y逼近于s,得到有效脑电信号。然后通过伪迹成分的特征就可以进行伪迹的剔除。
常见伪迹有眼动引起的眨眼、眼漂伪迹,头动引起的伪迹以及工频干扰产生伪迹。各个伪迹的特征可以根据地形图、时域Trials 色谱图、功率谱图进行辨别,具体如图2所示。
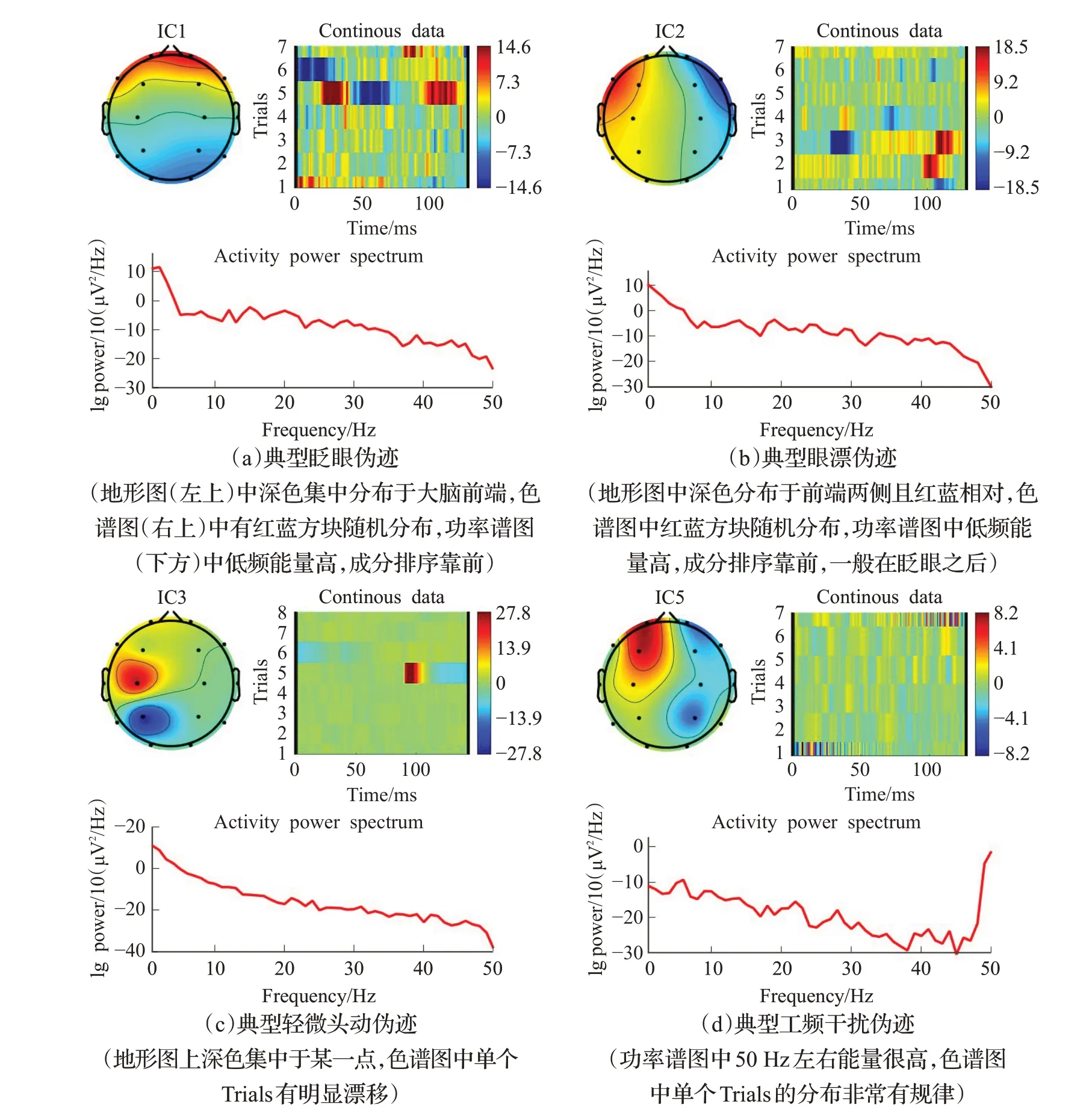
图2 各伪迹成分特征描述
最后平均所有电极以作为电极重参考。经过数据预处理后,每位患者得到3 段睁眼和3 段闭眼状态下的数据,每段数据时长为4~10 s,如图3(a)和(c)。
通过分析筛选出处理后伪迹仍然较多的数据,得到精神分裂症闭眼状态和睁眼状态下的数据各200段,抑郁症闭眼状态和睁眼状态下的数据各200段。
将上述EEGLAB 处理后的数据导入Brainstorm(https://neuroimage.usc.edu/brainstorm/),通过快速傅里叶变换,将时域下的每段数据(如图3(a)和(c)转换到频域(如图3(b)和(d)。以往也有将时域EEG数据直接输入深度学习模型中进行分析的研究[25],但要求对数据进行等长的截取,因此会损失部分数据信息。为了尽可能利用所采集的数据,本文尝试将4~10 s长度不一的时域数据转换到频域,将这些时长不同的EEG 数据转换成功率谱密度的形式,试图挖掘出数据中更多的潜在信息。通过人眼直观的观察,无论是在时域还是在频域下均很难发现两种疾病信号波形的明显差异。由于信号在高频部分衰减严重,因此在频域下仅截取1~50 Hz的数据,并导出为50行16列的功率矩阵(其中行数表示频率,列数表示导联数),以此作为后续分析的样本。

图3 患者闭眼状态下的数据形式
1.3 数据转换
利用CNN 对EEG 数据进行分析时,也有研究者对数据的形式进行了处理。如Tabar等人[16]采集人在想象左手和右手活动时,大脑C3、C4、CZ这3个通道的EEG信号。采用时频分析,将EEG信号转换成横轴为时间,纵轴为频率的图片样本,样本仅利用了Alpha、Beta频段的数据。这种方法所采用的电极和使用的数据频段均较少,考虑到精神病患者脑电的复杂性,该种对于EEG样本的表示方法可能不足以完全提取各个通道的特征。Emami等人[26]将整个时域下所有通道的EEG信号,用时间窗划分为EEG 时域图片,将整张图片输入到卷积神经网络中区分癫痫和非癫痫。但这种直接利用EEG的时域信息进行分析的方法,可能会引入过多噪声数据,并且可能由于图片尺寸不统一的问题而使模型学习到更多不属于信号本身的特征。
为了避免了分析时域数据时利用时间窗截取信号造成的部分数据丢失,同时避免直接输入数据截图引入其他不属于数据本身的信息。本文提出将时域下的EEG 数据转换成频谱图,得到每个电极通道下1~50 Hz的功率值,从而将每个样本转换为功率矩阵的形式。再将每个通道的功率进行max-min 归一化处理,如公式(2),然后转换为灰度图,如图4所示。图4中,10张灰度图代表10个闭眼状态下的样本,每张灰度图宽16,代表16个Channel,高为50,表示频率为50 Hz。每张灰度图下方的数字0和1为样本标签。0表示精神分裂症,1表示抑郁症。

图4 频谱图转换成灰度图的样本形式

式子中pmax、pmin分别表示单个电极通道下的最大功率和最小功率,p为该通道下对应频率的功率,p′为归一化后的值。为了将数组转换为灰度图像,需要在归一化后乘以像素值255,式中i即为转换后的像素值。通过频域的转换可以将长度不一的时域数据所包含的信息全部转移到固定频段信号中,同时进行脑电全通道和全频段的分析。灰度图的形式也适合数据增强的方法,更有利于使用CNN进行处理。
2 方法
2.1 模型构建与训练
CNN 在许多领域发挥着强大的作用。如人脸识别[27]、x-ray医学图像分析[28]、视觉图像重建[29]、磁共振图像分析[30]、MEG 大脑状态分析[31]等。CNN 能够进行特征的自动提取和分类,由于样本实质为50×16 的数组,构建一个8 层的浅层卷积神经网络,具体结构见表1。整个卷积网络包含5 种不同类型的层,分别是卷积层(convolution layer)、池化层(pooling layer)、展开层(flatten layer),dropout层、全连接层(dense layer)。

表1 对模型进行评估的各项统计学指标 %
Convolution layer:由许多的隐藏单元(neurons)组成。每个隐藏单元是一个矩阵,可以对输入的数据进行卷积,每次卷积的步长(stride)为1。每个隐藏单元卷积后产生一张特征图(feature map)。
Pooling layer:用于数据的下采样,以减少卷积层输出后的数据维度,可以有效减小计算量,防止过拟合。最大池化层(max-pooling layer)是在2×2的窗口中选择最大的值输入到下一层。
Flatten layer:可以将最后卷积层的输出数据展成一列。
Dropout layer:可以在训练时暂时隐藏部分神经元,以达到减小过拟合的目的。经过多次实验,本模型将dropout rate设置为0.5。
Dense layer:可以将之前提取的特征全部关联起来,映射到输出空间中。
模型使用了两种激活函数(activation function),分别是Relu(Rectified linear unit)[32]和Sigmoid。Relu 可以增加模型的非线性,让模型同时学习输入数据的线性变换和非线性变换,使模型对于输入数据的噪声更加具有鲁棒性。式(3)即为Relu函数。

式中x为输入的数据,f(x)为对应的输出。最后一层的激活函数选择Sigmoid函数(式(4)),用于计算最后模型输出某一类别的概率值。

其中yc表示模型最后一层对于类别c的输出,pc表示输出该类别c的概率。所以模型的最后一层用于预测输入样本的类别。构建好模型的结构,开始对模型进行训练。本研究分别利用闭眼状态和睁眼状态下的数据进行训练和分类,最后对两种状态下的分类效果进行对比。首先将闭眼下的样本80%用于训练,20%用于验证,经过多次实验,模型训练时的参数设置如下:选择优化器为RMSProp[33],学习率设置为10−4,每次输入模型的样本批量为32,损失函数选择binary cross entropy[34]。模型的具体训练过程如图5 所示。图5 中,像输入模型后首先会经过卷积层,每一层会输出由多张特征图堆积而成的长方体。图片上的红色小方块代表一个卷积核(隐藏单元),旁边已标出核的大小。箭头上方的数字表示特征图的数量,也即是卷积核的数量。经过池化层,特征图数量不变,但是特征图的尺寸变小;经过dropout层,特征图尺寸不变,每一层的最下方已经标示出特征图的尺寸。通过连续地卷积池化,原始图像转换为更高维的特征,再由全连接层将所有的特征关联起来映射到输出空间。
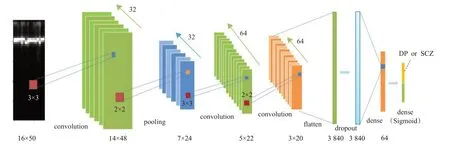
图5 模型训练流程图
2.2 评估
对于模型的分类结果一般采用混淆矩阵(如图6(c))来表示。混淆矩阵是一个m×m的数表,其中m表示类别数,列表的行表示真实的样本类别,列表示预测的样本类别。例如对于一个二分类问题来说,其混淆矩阵则为2×2,通过这个矩阵可以得到其敏感度(sensitivity)、特异性(specificity)、查准率(precision)、查全率(recall)等指标,而不是仅仅计算模型的精度。因为对于不均衡样本来说,仅仅计算模型的精度并不能完整地衡量一个模型性能的好坏。例如对于样本比例为3∶7的测试集,全部预测为其中多数类的样本其精度便可以达到70%。因此常常利用sensitivity、specificity、F1_score、accuracy等指标来综合考量模型。具体的计算公式如下:


图6 数据增强(样本左右翻转)后模型的训练结果

公式中TP表示真阳性(预测和实际均为阳性),FP表示假阳性(预测为阳性,实际为阴性),TN 表示真阴性(预测和实际均为阴性),FN 表示假阴性(预测为阴性,实际为阳性)。具体可见图6(c),其中1 视为阳性,0 视为阴性。
2.3 交叉验证及数据增强
交叉验证是提高模型可信度的有效方法。本文采用五折交叉验证法无重复抽样地划分训练数据为训练集和验证集,将训练数据分成五部分,每次拿四部分进行训练,剩下一部分用来验证模型的精度;通过这种方法可以对模型进行五次独立的训练,最后取五次测试模型的精度平均值作为模型最后的验证精度。
由于学习样本较少,容易造成模型过拟合,导致训练出来的模型其泛化能力不足。如果训练的样本有很多,则过拟合问题就很容易解决。对于图像的分类尝试用数据增强进行处理,以此减小其过拟合。数据增强能够从原有的训练样本中生成更多的样本,其方法则是通过旋转、平移、翻转、缩放等手段来生成更多可信图像,以此让模型学到更多训练样本中的局部信息。对于每一种手段,实验过程中均按批次生成训练样本。具体操作为:对于旋转,计算机随机生成顺时针或逆时针旋转不超过36度的图像;平移分上下平移和左右平移,平移范围不超过图像移动方向尺寸的0.2 倍;翻转则分为水平翻转和纵向翻转,从而训练样本量可扩大一倍;而缩放为随机将图片放大或缩小,其变化范围不超过原来大小的0.2倍。
最后为了与文中方法进行比较,提取转换后的灰度图样本中的HOG[35](方向梯度直方图)特征,采用SVM(支持向量机)进行分类,并记录各项统计学指标。
3 结果
3.1 闭眼数据转换及分类
利用快速傅里叶变换将时域信号转换到频域,导出功率矩阵后转换为灰度图(如图4)。每张灰度图即代表一个信号样本。由于睁眼和闭眼下的数据分析方法相同,以下分类结果主要以闭眼状态下的数据为例进行介绍。
将上述转换后的样本分为训练集和验证集,其比例为4∶1,输入卷积神经网络中进行训练和测试。模型最终训练了150个轮次(epochs),最后验证精度为85%,损失值为0.32。对模型进一步评估,计算其各项统计学指标(表1)(以下统计学指标均以抑郁症为阳性,精神分裂症为阴性进行计算)。
为了进一步评估模型的性能,观察模型的泛化能力是否良好,采用交叉验证的方法对模型进行训练。每一折训练后计算模型的敏感度、特异性、查准率、精度、F1_score 以及最后各个指标的平均值,并绘制折线图(图7(a))。同时模型的平均训练损失和验证损失的差值变得更大,最后该模型的平均敏感度、特异性和精度分别为78.66%、77.83%、78.50%。
考虑到模型的复杂度较低,原始样本的区分度小,本文在进行数据增强时通过单一的变换手段对训练数据进行变换,并计算不同方式下模型的各项统计学指标(图7(a))。经过一系列的实验后发现仅对训练样本进行左右翻转,最后训练得到的模型其精度更高。样本左右翻转后,模型训练过程中训练精度和验证精度随着训练轮次增加的变化情况如图6(a),训练损失和验证损失随着训练轮次增加的变化情况如图6(b),其中模型的训练损失和验证损失相差越小表示模型的泛化能力越好,并绘制其混淆矩阵(图6(c)),0 表示精神分裂症,1表示抑郁症,最右边图例表示颜色越浅其预测的结果准确性越高。其敏感度、特异性和精度分别为84.09%、91.67%、87.50%。
3.2 睁眼数据下的分类结果及比较
采用同样的方法对睁眼状态下的数据进行处理。在相同的模型下对睁眼状态的样本进行训练和评估,通过五折交叉验证和不同数据增强方式训练后得到的结果如图7(b)所示。

图7 五折交叉验证和数据增强后的结果
为了验证算法的有效性,提取了灰度图样本中的HOG 特征,并采用SVM 进行分类;同时与过去工作中的方法[36]进行比较,即提取EEG 频谱图中的功率谱熵(信息熵,样本熵,近似熵)用SVM分类的方法进行了比较,不同方法下的精度见表2。

表2 不同方法下的分类精度%
4 讨论
本文采集了精神分裂症和抑郁症患者静息态下的EEG信号,试图通过这种非侵入性的诊断方式来对两种疾病进行区分,跳过传统模式识别的方法,不对样本进行手动的特征选择[16](如每个频段的相对功率谱密度,每个通道下的峰值、均值、方差等)。不同于以往对于EEG 信号的表示,本文提出将时域下的EEG 信号通过一系列变换,转换成灰度图。这些灰度图集成了每个信号样本不同电极和不同频率下的功率特征。从转换后的灰度图可看出多数样本在10 Hz左右的亮度较高,即功率值较大,这也跟实际频域下的波形图相吻合。说明两类患者的脑电Alpha 波的功率值均较高。从模型的初次分类结果看出,两种样本是具有可分性的,也说明这种数据表示方式是可行的。
模型训练过程中,影响训练效果的因素有很多。如在训练过程中将数据分为小批次的batch size 值,模型训练轮次的epochs 值,模型中每一层的隐藏单元数,优化器的种类,学习率等超参数。因此实验中需要对模型的结构和超参数不断进行调试,以使模型的各参数达到更优。由于本研究采用的数据样本较少,对模型的评估可能还具有一定的偶然性。如果样本在进行划分训练集和测试集时,将质量较差,较难区分的样本集中分到一起时,得到的结果曲线可能会出现较大的差异。为了得到更可靠的模型,需要对模型进行进一步的训练和评估。交叉验证是提高模型可信度的有效方法。经过五折交叉验证后模型的平均验证精度为78.50%,低于初次训练时达到的85%,其敏感度和特异性也均有所降低。而且训练损失和验证损失的差值变大,说明模型的泛化能力变差,还需采用其他手段进行优化。
当模型过训练,除了学习到样本中的数据特征,还学习了数据中所包含的噪声,从而造成过拟合的现象。而过拟合往往会导致模型在训练数据中表现很好的性能,而对于新的样本却没有预计的精度。特别是针对于模型结构复杂而样本量较少的情况,过拟合现象更加明显。为了解决这个问题,往往采用增加样本的数量,减少模型的复杂度,添加正则项等方法。后两种方法在模型的训练过程中已经进行了调整,因此如何增加样本量是需要考虑的问题。考虑到模型结构简单,过于复杂的变换反而导致模型的训练效果差强人意。因此文章采用单一的数据增强手段来训练模型,其结果说明,使用水平翻转的方式来增加样本量,得到的模型效果最好。模型的精度、敏感度、特异性分别达到了87.50%、84.09%、91.67%。其训练损失和验证损失的差值变小,与未进行数据增强前的模型相比性能有了显著提高。由此说明数据增强不仅可以应用于现实中的实物图像,也适用于生理信号的处理,这对于医学图像的处理是具有借鉴价值的。
对比睁眼状态和闭眼状态下的EEG 分类结果,在相同的模型下进行五折交叉验证,发现睁眼状态下的精度为70.75%,使用数据增强后的精度为72.50%,闭眼数据训练得到的模型的各项指标均优于睁眼状态。并且睁眼数据训练曲线损失差值也较大,说明利用睁眼数据训练出的模型的泛化能力要低于闭眼状态数据训练出的模型。这可能是由于睁眼状态下,病人视觉上容易受到外界景物的干扰,从而采集的EEG 数据包含更多的噪声,造成模型的分类效果不好。
最后为了验证本文EEG 灰度图表示的有效性,提取了闭眼数据灰度图HOG 特征进行分类,精度达到了86.25%,略低于直接使用CNN 进行分类的精度。并且睁眼数据的分类精度仍然较低。与直接使用频域数据提取功率谱熵的方法进行比较发现,用CNN 分类闭眼数据的灰度图精度更高。进一步证明文中提出的表示方法的有效性。
5 结束语
本文通过采集精神分裂症和抑郁症患者静息态下的脑电信号,通过卷积神经网络模型来对两种疾病进行分类。通过对EEG信号进行分析,提出将时域下的EEG信号转换成灰度图。利用深度卷积神经网络对两种疾病进行分类并采用交叉验证的方法对模型进行评估。文章通过对睁眼和闭眼下的数据分别进行训练分类,发现闭眼状态的数据分类效果更好。为了进一步提高模型的性能,采用数据增强的方法使模型的分类精度、敏感度、特异性分别达到87.50%、84.09%、91.67%,与未进行数据增强前的模型相比有了显著提高。
本文以静息态脑电信号为基础,利用卷积神经网络进行特征的自动提取和分类,所提出的这种EEG 数据的转换和分析方法是值的借鉴的。这些方法不仅适用于特定疾病的EEG 数据,同时也能应用于临床上其他电生理信号的分析。因为它可以将杂乱的EEG信号转换成卷积神经网络可以识别的图像形式,同时也可以通过数据增强的方法来进一步改善模型的性能,证明该方法除了可以用于现实中的实物图像分类,还适用于电生理信号的处理。但本文也存在着一些不足:深度学习需要大量的数据作为支撑,而本文所使用的数据是匮乏的,因此为了减小过拟合,本文尝试了多种方法。如果要投入到临床使用中,还需要尽可能扩大新的数据集,来训练更加可靠的模型。虽然EEG数据的图像形式方便分析处理,但该形式可能会导致通道之间的联系减弱,在分类时没有提取到有关于电极通道之间关联性的特征。因此,接下来如何探讨电极之间的关联性,实现脑网络的分析也将是今后研究的一个重点。
