基于改进协同过滤算法的推荐系统设计与实现
2021-07-14白林锋古险峰
白林锋, 古险峰
(河南科技学院 信息工程学院, 河南 新乡 453003)
用户的个性化需求以及商品的多样性,导致信息过载,进而出现“信息迷失”,使得用户在选择商品时不能很好地进行比较[1]。推荐系统通过分析用户对不同商品的历史关注程度以及对项目的评价,找出其中的关联特征,从而在海量数据中将用户感兴趣的信息推荐出来,使用户能够花费较少的时间和精力,更加精准地找到符合自己预期的产品,提升用户满意度,因此推荐系统对电商平台以及用户购物体验都起着关键作用[2]。推荐算法作为推荐系统的核心,具有重要意义,可以基于内容、情境感知、关联规则、知识推荐和协同过滤等。传统算法往往仅考虑相似用户的兴趣偏好进行相似性计算,用户模型单一,且没有充分考虑时间因素以及项目属性对用户的影响,自身存在缺陷性,可扩展性不足[3]。针对这一现象,提出了改进协同滤波算法,在充分考虑项目属性特征以及用户兴趣爱好的基础上,引入自适应平衡因子综合考虑用户的需求,从而实现对用户兴趣爱好更深入地挖掘,解决传统算法规则提取困难、个性化程度低、数据稀疏的问题[4]。
1 推荐系统相关理论
随着信息化时代的到来,大量数据方便人们生活的同时,使得信息过载、海量数据不对等问题也日益凸显[5]。利用已知用户的浏览历史进行情境分析,挖掘潜在的关联规则,过滤掉大量无用信息,促成用户购买意愿,提高交叉销售的同时,提升用户的粘连性和满意度。因此,行为记录模块、规则分析模块、推荐算法模块构成了一套完整的个性化推荐系统[6]。其中,协同过滤技术以类聚群分原理,不需要对用户进行额外的跟踪,仅仅利用用户已有的浏览历史、评价行为,进行兴趣偏好的相似性计算,继而进行个性化推荐[7]。随着在线用户的增加以及大型Web的兴起,推荐系统也面临着模型服务、可扩展性、系统架构、冷启动和强壮性等问题的挑战[8]。推荐系统框架如图1所示。
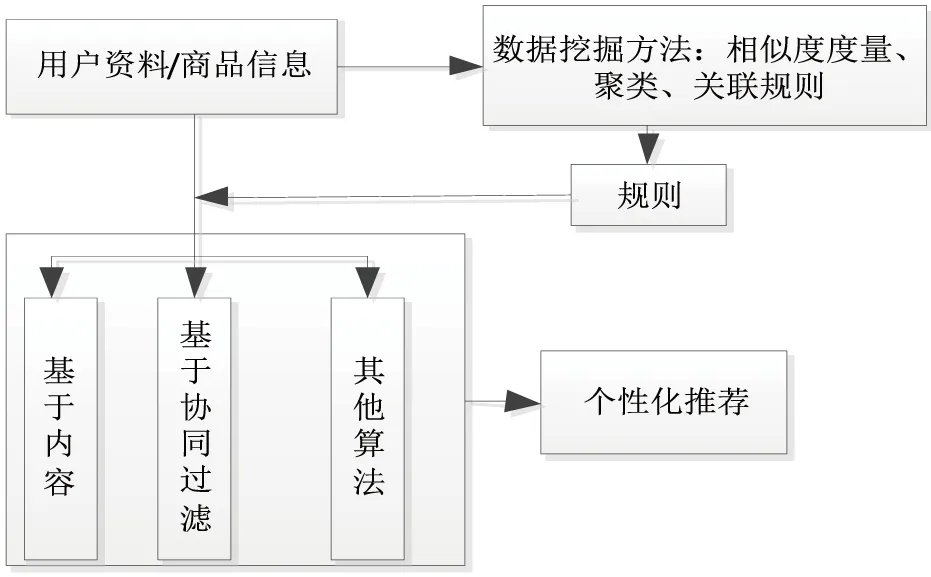
图1 推荐系统框架图
1.1 推荐技术及评价指标
协同过滤推荐:有基于项目和基于用户两种形式,具有适应性强、推荐资源范围广的特点。基于用户的算法流程为:利用已知用户兴趣数据挖掘与之匹配的相似度高的目标用户,进而通过对比分析,根据物以类聚人以群分现象,将商品推荐给疑似用户[9]。数学表达式为:
p(u,i)=∑v∈S(u,k)∩N(i)wuvrvi
(1)
式中:p(u,i)表示目标用户u对商品i的兴趣度,k表示与已知用户相似的用户个数,w表示用户间的相似程度,v为相似用户,r为隐反馈信息。得到用户对商品的兴趣度后,进行降维选择,从而挑选出兴趣度最大的N个商品推荐给目标用户[10]。基于项目的过滤推荐原理和基于用户的过滤推荐相似,都存在扩展性差、冷启动以及数据稀疏性问题[11]。
关联规则推荐:从大量数据中寻找未知项目间存在的关联特征,进而进行推荐,从而得到意料之外情理之中的效果。数学表示为:假设存在商品数据库D,每一次交易用T表示,A为数据库D中的一个商品集合,商品集合A和商品集合B之间的关联规则A⟹B的置信度和支持度为:
(2)
(3)
通过式(2)和式(3)得出商品集合A和商品集合B之间的置信度和支持度函数,如果大于设置的阈值,则得出关联规则[12]。该算法需要重复扫描数据库,带来数据的高维性和稀疏性,个性化程度低,关联规则提取困难[13]。
一个好的推荐系统在获取用户资源的同时,能够提升用户的粘连性和满意度。合适的评价指标是评判推荐系统优劣的关键[14],常用的评价指标有:推荐准确率、评分预测。
推荐准确率
(4)
式中:T(u)为测试商品,P(u)为推荐商品。
评分预测
(5)
式中:rui为用户u对商品i的真实评价,lui为用户u对商品i的预测评价。
1.2 协同过滤算法的关键问题
传统的协同过滤推荐利用相似性度量关联近邻用户,然后通过最近邻(KNN)加权预测目标用户兴趣,最后进行个性化推荐[15],具体流程如图2所示。

图2 协同过滤推荐流程
评分矩阵:假设数据库中存在m个用户,n个商品,评分矩阵用m×n表示,Rij表示第i个用户u对第j个商品的评分,评分值通过1~5来表示用户的喜好程度。评分矩阵如表1所示。
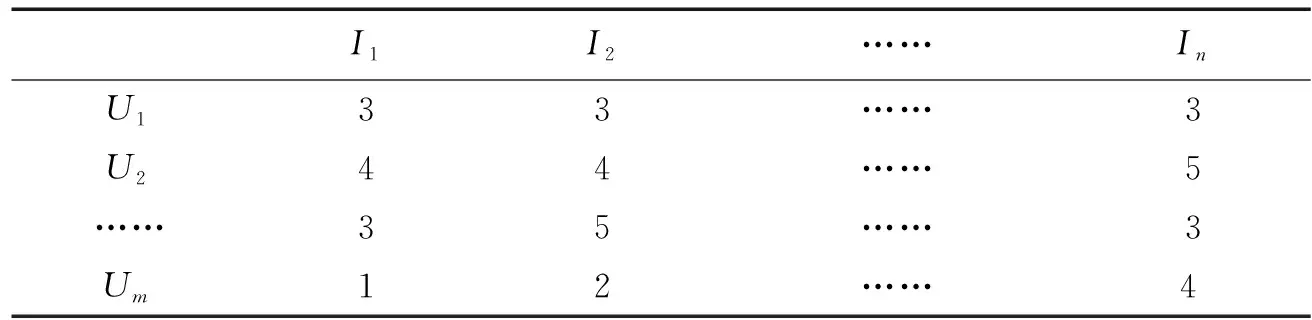
表1 评分矩阵
近邻选择:对目标用户预推荐进行项目间相似度查找,或者查找与目标用户相似的近邻用户,然后根据相似性进行排序,选取大于阈值的若干个组成最近邻集合。常用的相似度度量有余弦相似度量,其数学表示为:
(6)
式中:用户u、v对项目c的评分用R表示。皮尔逊相似度表示方式为:
(7)
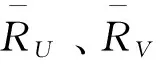
(8)
2 融合项目属性与兴趣信息的协同过滤推荐系统
2.1 系统模块设计
在进行模块设计前需要进行系统需求分析,由于推荐系统面向的用户特征和实现的功能属性并不一致,因此系统需求分析的优劣决定了设计的质量。本系统设计面向电商产品销售,需求分析主要有两部分组成,分别为功能性属性和非功能性属性。功能性属性包括用户管理、任务管理、数据分析、数据可视化,非功能性属性包括可靠性、可扩展性、便捷性。在系统需求的基础上,进行模块设计,融合项目属性与兴趣信息的协同过滤推荐系统主要有4个模块:数据管理模块、数据分析预测模块、个性化推荐模块以及结果显示模块。
数据管理模块主要进行数据存储以及商品数据和用户数据的管理;数据分析预测模块通过对数据进行预处理,过滤掉无用信息以及异常数据,对用户的访问数据进行清洗,为后续的个性化推荐模块做准备;个性化推荐模块根据数据分析预测模块得出的数据进行评分矩阵,通过自适应混合协同过滤,选择合适的推荐算法,根据用户的兴趣爱好更新商品属性特征,实现推荐结果的实时性和动态性,提高推荐准确率,最终在显示模块将商品推荐给用户。
2.2 融合项目属性与用户兴趣相似度计算
传统的协同过滤算法,通过研究相似用户的兴趣偏好进行相似性计算,忽略了时间因素以及项目属性对用户的影响,进而造成数据的稀疏性;而且,当引入新项目时无法及时的进行推荐,导致冷启动问题的产生,可扩展性不足。本设计提出一个将用户兴趣和项目属性混合进而计算相似度的方法,通过利用权重系数综合分析项目评分的相似性,其数学表示为:
sim(p,q)=αsimrate(p,q)+(1-α)simattr(p,q)
(8)
式中:simattr(p,q)为项目属性;simrate(p,q)为兴趣偏好;α为平衡因子,取值在0和1之间,决定了相似度拟合的权重系数。通过调节平衡因子α可以实现推荐精度的改变,最终实现精准的个性化推荐,α具体取值,通过实验仿真得出。但是现实中,这种相似度计算并不适用于所有情况,为了防止用户共同评分项目过少而出现的相关系数过大,需要根据情况加入权值因子即惩罚因子,改进后的相似度表示为:
(9)
式中:Npenalty为权值因子定值,大部分情况下取值50,Noverlap为目标用户与已知用户一起评分项目数量。
算法的具体步骤为:
(1)输入近邻数k,商品集合以及用户集合,并写出评分矩阵R;
(2)选取合适的数据库,抽取其中85%作为训练样本,15%作为测试样本,并读入训练样本中生成用户评分矩阵的数据;
(3)利用改进后的相似度表示式(9),得到融合项目属性与用户兴趣相似性,比较相似度结果,选取大于阈值的若干个组成最近邻集合;
(4)最后通过15%测试样本,得出推荐准确率P、均方根误差R、绝对误差,验证算法的有效性。
3 实验与仿真
首先搭建所需硬件平台,电脑采用8核CPU、Intel i7@3.4 GHz、32 G内存、512 GB固态硬盘,软件配置为Microsoft Windows7操作系统,编程语言为Java,开发平台为Myeclipse10。数据集采用美国Minnesota大学GroupLens项目组开发并维护的数据库。该数据库包含3个数据集,为了便于比较验证,选取其中的一个MovieLens 100k数据集,该数据集里面含有1 682部影片、943位用户评价的100 000条评价。评分范围值为1~5之间,抽取其中85%作为训练样本,15%作为测试样本。评价推荐系统性能优劣的指标有召回率(recall)、覆盖率(coverage)、绝对误差(MAE)以及均方根偏差(RMSE)。本设计通过比较传统算法与改进协同过滤算法在绝对误差和均方根偏差的数值来验证算法的有效性。
本设计中相似度融合了项目属性与用户兴趣,平衡因子α决定了这两部分的比值。通过仿真观察得出平衡因子α与绝对误差(MAE)间的关系,如图3所示。
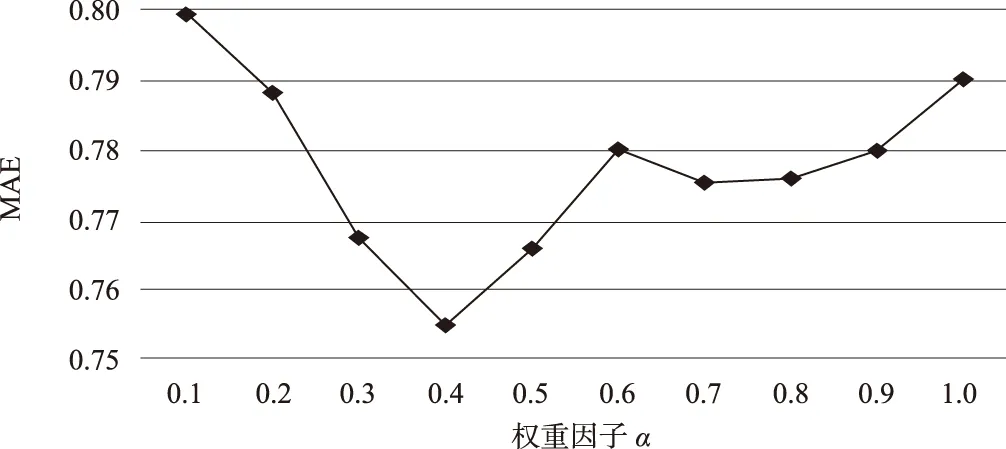
图3 绝对误差与平衡因子变化曲线
通过图3可知,当平衡因子α为0.4时,绝对误差最小,推荐精度达到最大值,所以后续仿真α采用0.4。在相同测试集以及数据稀疏度的环境下,通过与传统的以评分差异度和以项目类别偏好计算相似度的协同过滤算法进行对比来验证本文算法的精确度;同时为了验证本文算法的普遍适用性,针对不同的情况最近邻个数分别取10~60,实验结果如图4所示。
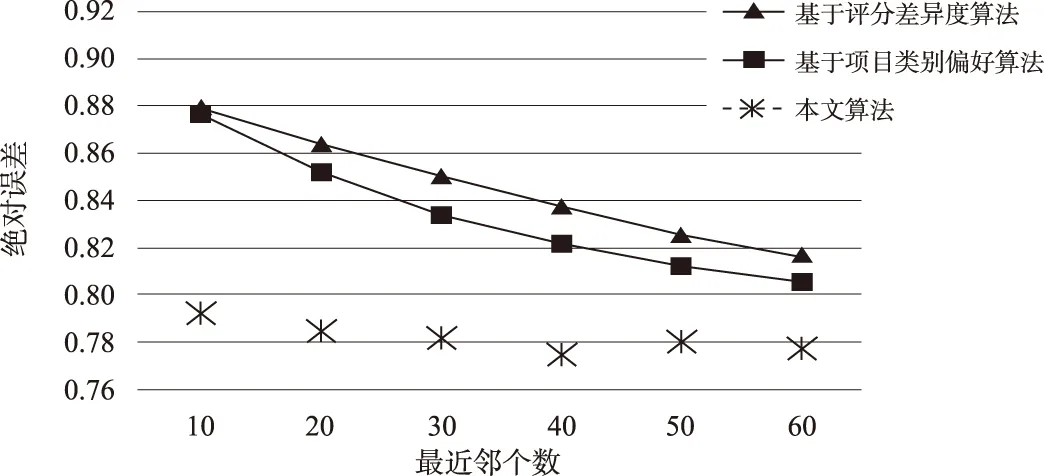
图4 不同算法绝对误差比较
由图4可知,基于改进的协同过滤算法相对于传统的协同过滤算法具有较高的精确度,且随着最近邻个数的增加,系统的精确度仍然优于其他算法,说明具有一定的鲁棒性和普遍适用性。
4 结 语
在信息爆炸时代,用户如何在大量冗余的信息中找到自己感兴趣的数据,电商网站如何推销商品并提高客户粘连度是近年来研究的重点。本文通过对推荐系统关键技术及评价指标进行分析,得出推荐系统的基础架构。在此基础上对协同过滤算法进行改进,通过引入权重因子以及惩罚函数,将用户兴趣和项目属性混合进而计算相似度,最终实现精准的个性化推荐,并通过实验仿真验证本设计具有一定的鲁棒性和普遍适用性。
