基于混合机器学习优化的协同过滤算法
2021-07-13李金曈许鹏程
范 波,李金曈,白 天,许鹏程
(湖南理工学院 信息科学与工程学院,湖南 岳阳 414006)
机器学习的目的是从海量数据中找到一个规律,并将模型得到的规律应用到同类数据中,给出一个目标结论.这个思想与人们希望得到有价值信息的目的不谋而合,于是大数据个性化推荐出现在大众视野中.大数据个性化推荐算法在2012年由数据科学家提出,在2016年得到广泛应用,成为数据科学工作者的常用算法之一[1].大数据个性化推荐算法不仅使用户得到的信息质量明显提升,同时也让商户的推荐效率提高、成本降低.协同过滤算法作为个性化推荐领域中的经典算法之一,因其效率高、适用范围广、易调整等特点,长期位于主流算法之列[2].但传统的协同过滤算法存在冷启动、数据稀疏性等问题[3,4].为了对传统协同过滤算法进行优化,本文提出适用于协同过滤算法的混合机器学习分类模型,并应用该模型进行定性与定量分析,得到一个优化模型.
1 混合机器学习的协同过滤算法模型
1.1 模型改进
基于用户的协同过滤算法主要基于“人以群分”的理念.通过用户的各类行为信息,来挖掘出用户的喜好,然后参照喜好相似的人的偏好来进行信息推荐[3],其算法结构如图1所示.
传统的基于用户的协同过滤算法主要分为两个步骤:
(1)找到与目标用户兴趣相似的用户集合;
(2)找到该集合中用户喜欢的、同时并未了解过的物品推荐给目标用户.
在协同过滤算法中,第一个步骤极为重要,分类的效率将直接影响到模型对于用户喜好的推荐精度.本文主要针对该步骤进行优化.
传统的协同过滤算法对用户进行分类时,通常使用Jaccard 公式或余弦相似度计算两个用户之间的相似度[5].设ωab为用户a与b之间的相似度,S(a)、S(b)分别代表用户a、b喜欢的物品集合,两个相似度计算公式如下:
(1)Jaccard 公式

(2)余余弦相似度

根据上述公式,可以得到用户之间的相似度.但传统协同过滤算法存在一些缺陷,如冷启动问题、数据稀疏性问题等[6].
(1)系统冷启动:当用户量少、数据量少时,信息不足,推荐的精度较低.
(2)用户冷启动:对于一个行为数据较少的新用户,无法根据其有限的信息进行精准推荐.
(3)稀疏性:随着数据的不断增多、系统规模的扩大,系统的搜索空间将会线性扩充,每一次搜索的时间就会越来越长,不得不通过降低精度的方法来减少搜索时间.
在对基于用户的协同过滤算法优化的探索中,我们尝试使用机器学习中的分类算法作为用户分类的方法,以此提高协同过滤在复杂场景中的性能.通过实验发现,使用K 最近邻算法(KNN)[7]和支持向量机算法(SVM)[8,9]进行优化是有效的.
KNN是一种惰性的学习模型,不需要进行训练,每当有新样本加入的时候,它将新样本与原样本集进行比较,并在其中寻找到最接近新样本的k个最近邻居.该算法不需要训练,准确性高,很适合加入到协同过滤算法中来.
SVM是一种经典的二分类模型,本质是一种特征空间线性分类器,通过使间隔最大化进行高效分类,能够克服局部极小、过拟合等问题.SVM 算法特征空间的划分是最优的超平面,它避免了从归纳到演绎的传统过程,简化了通常的分类和回归问题,并具有良好的鲁棒性,在各种分类问题中运用广泛.同时,因其超平面的特性,可以组合多个二分类SVM 来构造多分类模型,从而实现对协同过滤算法中的用户进行多分类.
针对这些问题,我们通过组合多个SVM 二值分类器与KNN 模型,来替代相似度的计算,将用户进行多分类,随后判断分类的结果误差是否在可接受范围内,如不满足,则将其单独定为一类进行划分.这种做法不再需要计算用户的相似度,将用户的信息输入模型即可得到结果,不需要进行多余的补全等操作,仅需提供初期的数据集,即可得到较为精确的推荐,有效解决了传统方法存在的冷启动、稀疏性等问题.同时,由于使用了KNN 算法,在推荐的过程中,模型也可以进行自我学习,提升推荐的精度.
1.2 计算流程
设推荐系统中有n个用户的集合U={U1,U2,U3,…,Un},m个产品的集合S={S1,S2,S3,…,Sm},我们使用基于SVM 与KNN 的多分类模型.集合S由系统内已有的物品组成,每个用户Ui对每一个物品Sj都存在一个喜好程度.在本文中,由于各用途中针对某物品的喜好程度计算方式不同,我们采取随机打标喜好度的方式进行实验测试.
当用户信息加入系统时,根据用户对物品的喜爱得到一个分类值k,然后加入用户类别T集合,得到一个用户对每一个类别的距离值R=|Ti-k|,阈值D由管理员设置,并按照以下规则分类:
(1) 若存在R小于设定的阈值D,则选择R最小的分类作为该用户的类别.
(2) 若所有R均大于阈值D,则在集合T中加入一个新的分类,并将该用户插入.
阈值D越大,分类精度越低,效率越高;阈值D越小,分类精度越高,效率越低.综上所述,改进的模型使用SVM 与KNN 混合的分类模型代替用户相似度的计算,使传统协同过滤算法的一些缺陷得到了局部解决.
2 实验分析
2.1 数据集选择
本实验选择MovieLens 数据集(ml-100k.zip)进行训练.MovieLens 是推荐系统领域常用的一个数据集,在机器学习研究领域具有重要的地位.
数据集中,u.data 文件由943 位用户对1682 部电影的10000 条评论组成,每个用户至少评分20 部电影,用户和电影均从序号1 开始编号,数据是随机排列的;u.user 文件由u.data 中的用户的个人统计信息组成,信息已通过脱敏处理.我们将u.data 中的rating(评分)当作用户对电影的喜好程度,电影集合看作物品集合,根据u.user 对用户分类并进行推荐.
2.2 实验环境和参数
本实验在Intel Core i7-8750H 2.20 GHz,GPU NVIDIA RTX2060 6G RAM,Linux-Centos8 上执行.编程语言及版本为Python 3.8.1.在SVM 算法的选择上,使用了LIBSVM 算法[10].在数据验证上,使用了五折交叉验证法,并设置了KNN 算法和SVM 算法的参数范围,保证参数的有效性.
2.3 实验结果与分析
由于实验的随机性,我们分别对改进后的模型和传统使用余弦相似度、Jaccard 公式的模型,使用同样的参数进行20次训练再取平均值.实验结果如图2所示.在本实验中,使用了混合机器学习分类的模型,运行时间较传统计算分类更长,各分类方法平均计算时间见表1.

表1 各分类方法平均计算时间比较
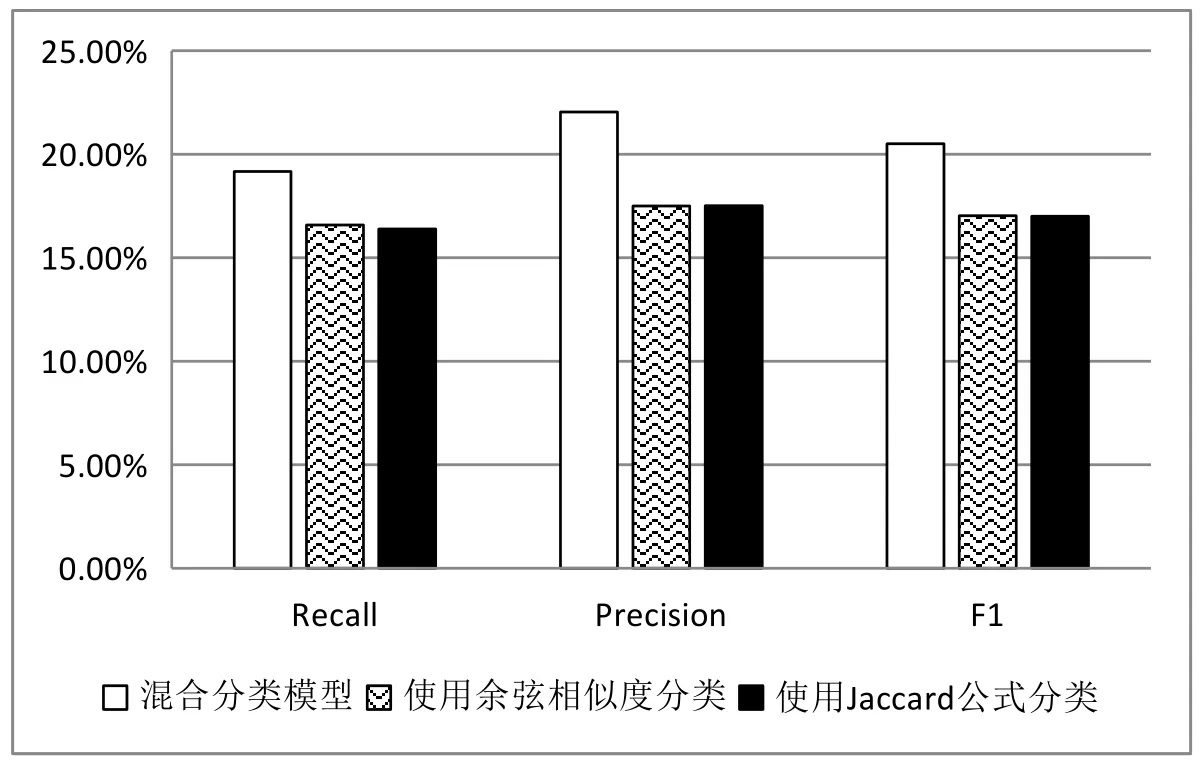
图2 实验结果对比
传统模型的时间复杂度为O(n2m),其中n表示用户人数,m表示物品数量.由于该集合数据量较小,改进的模型在时间效率上略低于传统方法,但是当用户数据越来越多时,矩阵的稀疏性将会使得传统算法的运行效率降低,而改进模型则可以保持一个较为稳定的计算效率.
可以看出,在推荐精度上,改进的混合机器学习优化的协同过滤模型,较传统的协同过滤模型,有很大提升,在运行效率上,对于小规模数据而言,算力消耗略大,但由于提供的推荐精度得到了很大的提升,故具有一定的实用价值.
3 结论
本文提出一种基于KNN 与SVM 混合的机器学习分类算法对传统的协同过滤算法进行优化,解决了传统模型存在的冷启动等缺陷,同时在推荐的精度上有显著提升.本模型可以应用于图书推荐、商品推荐等领域,通过采集用户的行为信息,向其推荐合适的商品.在传统的协同过滤算法基础上,优化了时间开销,提高了推荐精度.
本文并未进行模型的实际情景测试,在后续工作中,我们将通过微信小程序方式,推出图书智能推荐系统,采集用户的使用反馈,并对模型作进一步优化,设计出更加成熟实用的推荐系统.
