基于55 nm 工艺的MCU 低功耗物理设计
2021-07-13陈力颖刘宏伟吕英杰
陈力颖 ,罗 奎 ,王 浩 ,刘宏伟 ,吕英杰
(1.天津工业大学 电子与信息工程学院,天津 300387;2.天津工业大学 天津市光电检测技术与系统重点实验室,天津 300 387;3.天津鹏翔华夏科技有限公司,天津 300450)
随着集成电路制造工艺水平的提高,芯片的集成度越来越高,在芯片性能大幅提升、面积持续缩小的同时,低功耗设计成为无法回避的难题[1]。过高的功耗会降低芯片的性能和可靠性,额外增加芯片的封装成本,所以低功耗设计一直是芯片设计的主要方向[2]。在数字芯片的低功耗物理设计中,时钟信号是整个芯片中翻转频率最高、驱动负载最大和传输距离最远的信号[3],时钟网络功耗通常能占到芯片总功耗的30%~40%。所以,时钟树设计是低功耗物理设计的主要方向之一。好的时钟树设计是建立在合理的布局结果之上的,所以本文在布局和时钟树综合两个方面进行低功耗设计,在布局阶段采用SAIF 文件进行低功耗的协同优化,并在布局结果基础上,通过手动干预时钟单元摆放来减小缓冲单元插入的方式进行低功耗时钟树设计[4]。
本文以一个应用于低功耗物联网(IoT)领域的微控制单元(MCU)设计为例。设计采用台积电(TSMC)55 nm 工艺,芯片面积为2.13 mm ×2.22 mm,芯片规模约为300 万门,包含89 个宏单元,最高频率为120 MHz,借助新一代Innovus 布局布线工具,在传统低功耗物理设计流程基础上,研究新的低功耗设计方法。
1 MCU 低功耗物理设计
随着数字集成电路工艺制程的演进,对芯片功耗的要求越来越高[5]。MCU 低功耗设计可以分为3 个部分:第1 部分是系统与架构级的低功耗设计,比如多电压域设计技术、电源关断技术、动态电压频率调节(DVFS)技术等[6];第2 部分是RTL 编码和逻辑综合的低功耗设计,比如门控时钟和操作数隔离技术等[7];第3 部分是数字电路在物理设计阶段的低功耗设计,主要是基于门级电路的低功耗设计,比如多阈值电压和多沟道长度标准单元库的选用、多位寄存器优化、翻转率负载协同优化、低功耗时钟树设计等[8]。本文主要是在物理设计过程中进行低功耗的设计。完整的物理设计流程从布图规划(floorplan)、布局(placement)、时钟树综合(clock tree synthesis)、布线(route)到静态时序分析(static timing analysis)与物理验证(physical veri-fication)。时钟树功耗、处理器(CPU)和存储器功耗占了芯片总功耗的绝大部分[9],而CPU 功耗及存储器功耗取决于芯片的整体布局,所以在布局和时钟树综合阶段进行低功耗设计能最大程度地降低功耗。
数字电路的总功耗可表示为:
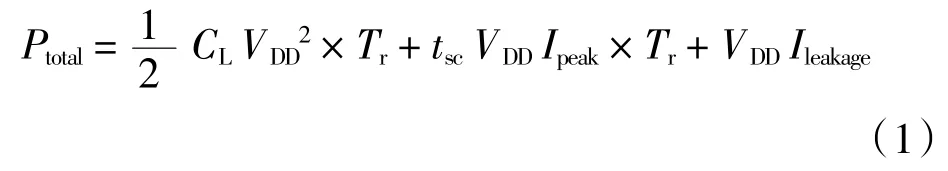
式中:第1 个乘积项为开关功耗,由电路翻转对外部负载CL充放电产生的功耗;第2 个乘积项为短路功耗,为电路NMOS 和PMOS 同时导通形成的短路电流Ipeak产生的功耗,这两项为电路工作时产生的功耗,称为动态功耗,动态功耗往往能占到芯片总功耗的80%左右;第3 项为泄漏功耗,为晶体管的沟道、栅极、衬底等非理想漏电流Ileakage产生的功耗,也称静态功耗;Tr为信号单位时间的翻转次数,称为翻转率(toggle rate);tsc为短路电流的产生时间,其值取决于输入信号的静态概率,静态概率也称信号的占空比。所以数字电路功耗的计算跟电路的开关行为(switching activity)有关,即信号的翻转率和静态概率,在低功耗的物理设计中明确电路的开关行为是非常有必要的。
2 低功耗物理设计流程
低功耗设计需要在功耗和时序之间找到一个平衡点,即在时序能够收敛的情况下,使功耗尽可能降低[10]。在标准单元摆放和时钟树设计完成后,标准单元的位置基本不会有大的改动,后续优化过程中,为了不影响时序,一般不会大规模的修改时钟线,所以芯片功耗一般不会有大的增加。本文在传统物理设计流程基础上,重点在布局和时钟树综合阶段进行低功耗设计。在布局阶段采用翻转率负载协同优化的设计方法进行低功耗设计,并在布局之前将部分时钟单元进行优先手动摆放;在布局结果基础上,通过手动干预时钟单元摆放来降低缓冲单元插入的方法进行低功耗的时钟树设计。图1 为本文低功耗设计的流程,布局前将SAIF 文件读入,设置低功耗驱动命令,并进行部分时钟单元的手动摆放,布局后结合传统时钟树设计方法进行低功耗的时钟树设计。

图1 功耗优化流程Fig.1 Power consumption optimization process
3 布局阶段的低功耗设计
3.1 SAIF 协同优化
布局阶段主要进行标准单元的摆放,本文在布局阶段采用SAIF 翻转率协同优化的方式进行低功耗的设计。SAIF(switching activity inter change format)文件是一种记录电路开关行为的内部交换格式文件,记录了在某种工作场景下、一段时间内互连线和单元引脚上信号静态概率和翻转率的情况,由综合后经仿真得到。开关行为(switching activity)指的是设计中翻转率和静态概率的情况。本文在布局阶段利用Innovus 的功耗驱动优化命令与SAIF 文件进行低功耗的协同优化,将SAIF 文件在标准单元布局之前通过如下命令读入:
read_activity_file -format SAIF $inputSAIF -scope tbench/u_mcu/u_sys/verify_env/dut
并在布局阶段进行如下的功耗驱动优化设置:
setOptMode-powerEffort high
setPlaceMode-activity_power_driven true
setPlaceMode-activity_power_driven_effort high
SAIF 文件主要能起到两个效果:一是提高功耗计算的准确性,得到更为准确的功耗值。不管是动态功耗还是静态功耗的计算都与设计中信号翻转率和静态概率情况密切相关。二是结合功耗驱动命令进行功耗的协同优化,布局布线工具会结合SAIF 文件中开关行为的情况,将翻转率较高的时序单元进行聚拢配置,减小时序单元之间的配线长度,达到减小翻转功耗的目的。在布局前读入SAIF 文件要保证SAIF 中标注的开关行为覆盖率(annotation coverage)达到90%以上才能达到良好效果,通过查看布局阶段的log 文件,本设计中开关行为的覆盖率达到了98.5%,满足要求。
图2 为SAIF 协同优化配置前后分布,图中黄色方框内为CPU 模块的分布。由图2 可以明显看出,采用SAIF 协同优化后,CPU 内核模块翻转率较高的D触发器相比原来聚拢效果明显,进而缩短了他们之间的布线长度,可以有效降低CPU 功耗,同时也有利于时序的收敛。结果表明,采用SAIF 文件进行协同优化的方案,功耗比原来降低5.2%。
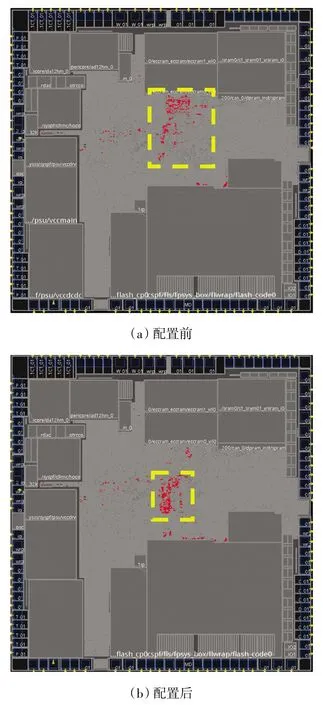
图2 配置前后CPU 模块分布Fig.2 Distribution of CPU module before and after configuration
3.2 SAIF 协同优化+动态功耗优化
SAIF 文件与低功耗命令的协同优化虽然能起到降低功耗的作用,但功耗优先的优化模式促使布局布线工具大量的使用了小尺寸单元进行时序优化,因为小尺寸优化单元的驱动能力较低,布局布线工具会插入大量的低驱动能力单元进行优化,使总体占有率增高,并最终导致时序的恶化,特别是建立时间总违例值变差。为了减小低驱动单元的大量使用,在布局阶段进行动态功耗优化的设定,让布局布线工具在进行布局优化时只进行动态功耗的优化,进行如下命令的设置:
setOptMode-leakageToDynamicRatio 0
图3 为两种优化方法和传统布局在插入的优化单元数量上的对比,优化单元包括缓冲器(buffer)和反相器(inverter),优化单元的驱动能力处于X02 到X90 之间。
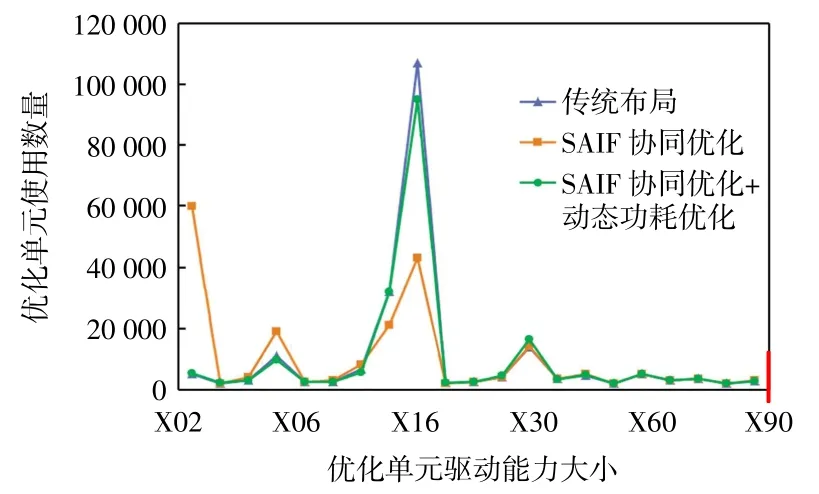
图3 优化后驱动单元使用数量对比Fig.3 Comparison of driving cell number after optimization
由图3 可以看出,采用SAIF 的协同优化后,在布局阶段插入的低驱动能力单元数量与传统布局相比大幅增加,这是导致时序恶化的主要原因。而在SAIF协同优化的基础上进行动态功耗优化后,低驱动单元的使用数量相比采用SAIF 协同优化明显降低。低驱动单元的使用数量降低,能使布局阶段整体的占有率降低,一定程度上能够遏制时序的恶化。
3.3 布局后结果对比
表1 为布局阶段2 种组合优化方式与传统布局的结果对比。
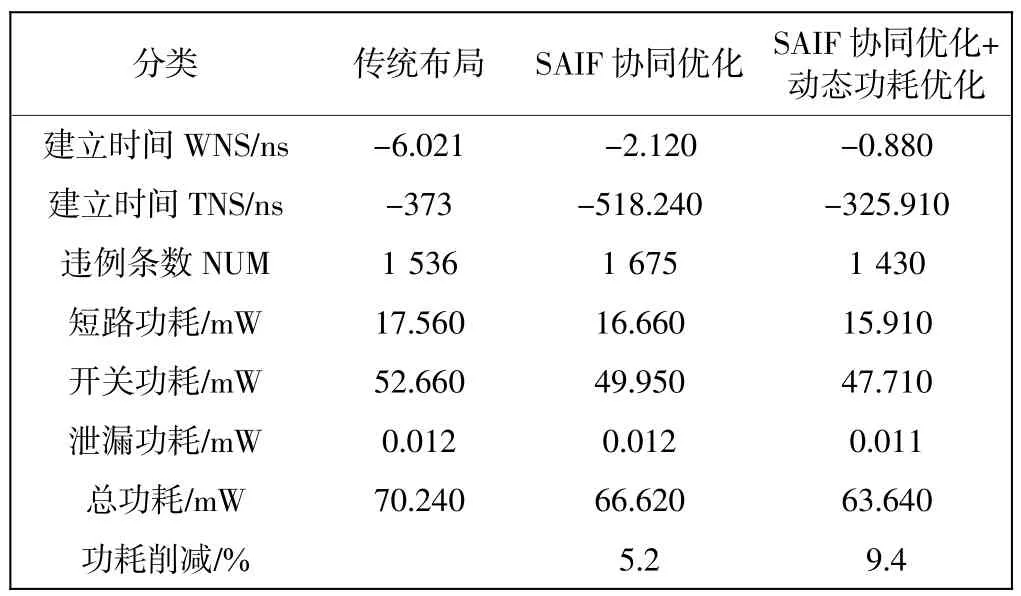
表1 布局后结果对比Tab.1 Comparison of results after placement
由表1 可以看出,采用基于SAIF 的协同优化和动态功耗优化(Dynamic)组合的总功耗比原来削减了9.4%,建立时序(setup)最差违例值从-6.021 优化为-0.880。由此说明,在布局阶段功耗得到了优化的同时,时序也得到了优化,这种优化方案在布局阶段起到的效果最好。
4 时钟树综合阶段的低功耗设计
时钟网络功耗通常能占到芯片总功耗的30%~40%,所以时钟树设计往往是低功耗物理设计的重要内容[11]。时钟树综合(CTS)就是建立一个合理的时钟网络,使时钟信号传递到每一个时序器件的延迟尽可能一致,做到时钟树的尽可能平齐。为了实现时钟结构的平齐,工具会插入大量缓冲器(buffer)和反相器(inverter)进行平衡,大量buffer 和inverter 的插入会导致功耗的恶化[12],所以低功耗的时钟树设计往往以降低缓冲单元的插入为目标。缓冲器在CTS 阶段主要起到两种作用:一种是为了平衡延迟;另一种是为了驱动负载[13]。所以,本文在布局阶段的低功耗设计基础上,在减少平衡缓冲器和驱动缓冲器两个方向上进行低功耗的时钟树设计。
4.1 传统时钟树设计方法
传统时钟树设计方法有:
(1)分析时钟结构,设计合理的时钟树方案[14]。
(2)根据时钟树方案,编写时钟树设计规范文件(clock spec),包括定义时钟根节点(root pin)和一些需要特殊处理的时钟节点,设置合理的时钟偏斜(clock skew)、转换时间(transition)、最大扇出值(max fanout)等[15]。Innovus 的CCOPT 引擎会根据该文件进行时钟树构建。
(3)指定缓冲单元、反相器和门控时钟单元的使用类型和大小。缓冲单元和反相器一般避免使用过大或过小尺寸的单元,多使用时钟缓冲器(CLKBUF)和反相器(CLKINV),这种类型单元的上升渡越时间和下降渡越时间基本一致,带来的延迟误差更小。门控时钟则尽可能使用小尺寸单元。
(4)设定时钟树的布线层,一般选用电阻电容较小的金属层,为了提高可靠性,多使用双孔(double cut)布线[16]。
(5)设定时钟布线的非默认规则(non-default rules),目的是为了减小时钟树电阻和耦合电容,避免串扰(crosstalk)的影响[17]。
4.2 低功耗设计方法
本文在Innovus 的CCOPT 引擎下,结合传统时钟树设计方法,采用一种新的低功耗时钟树设计方案,在布局之前将一些关键路径上的时钟单元进行手动摆放,在降低功耗的同时优化时序。本文采用了如下3种方法:
(1)时钟相关模块设置region 的物理约束,将其与时钟振荡器进行邻近配置,目的是为了尽量减小平衡缓冲器的插入。region 的物理约束能将模块内的标准单元约束在指定的区域内进行摆放,设置合理的模块利用率,让非该模块内的标准单元也能在该区域进行摆放,不至于影响整体的布局效果[18]。表2 为进行配置的模块。

表2 物理约束的设置对象Tab.2 Settings objects for physical constraint
(2)在时钟模块与邻近配置的前提下,依次进行部分时钟单元的手动插入,确保距离时钟振荡器足够近,尽可能地减小平衡缓冲器的插入。根据时钟结构,在时钟根节点进行分级。从时钟源(主振荡器HOCO等)到CPG 模块内的时钟选择器的路径定义为第0 级CTS 电路;从时钟选择器到时钟分频电路定义为第1级CTS 电路;从时钟分频电路到时钟叶节点(clock leaf)定义为第2 级CTS 电路。采用的方法是在布局之前将第1 级起点的时钟选择器和第2 级起点的时钟分频电路单元,用命令从振荡器旁开始依次进行提前摆放,再以DEF 格式文件将其输出,在布局前进行读入,提高设计的可重复性。时钟单元手动摆放的命令如下:
placeInstancecspf/sysp /vc_and_stop_selclkm4stp 562.30 458.40-fixed
(3)对第 1 段 CTS 电路的部分扇出(fanout)进行手动分割,减少多余驱动缓冲器的插入,避免时钟结构的冗余。与门selclk 后原本有21 个扇出,在传统CTS 设计下,工具进行了多余分割,导致了6 个多余缓冲器的插入。CTS 阶段设定的最大扇出(max fanout)为24,发现一个buffer 完全可以驱动21 个扇出,所以在CTS 之前进行手动分割,并对相应时钟线设置don′t touch 属性,确保CTS 阶段工具不会插入多余buffer 或者重新进行分割。
4.3 时钟树综合结果对比
时钟树的低功耗设计是将部分时钟单元进行手动摆放以优化时钟结构,避免性能冗余[19],尽可能少地插入缓冲单元和反相器,来达到降低时钟功耗和优化时序的目的[20]。表3 为时钟结构上插入的缓冲器和反相器数量对比,由表3 可知,与传统CTS 相比,手动配置CTS 时时钟树上插入的缓冲器单元和反相器数量分别降低了17.2%和22.2%。

表3 时钟缓冲器优化结果对比Tab.3 Comparison of clock buffer optimization results
表4 为本文采用的时钟树低功耗设计与传统CTS的功耗对比。由表4 可知,通过时钟单元的手动配置,时钟功耗下降为原来的73.1%,芯片总功耗下降为原来的86.2%,达到了明显降低功耗的效果。

表4 功耗结果对比Tab.4 Comparison of power consumption
表5、表6 为本文在时钟树综合后进行一遍时序优化后的时序结果对比。
由表5 可以看到,setup 的违例条数从112 降为14,总的违例值从-38.793 降为-1.154。由表6 可以看到,hold 的违例条数从445 降为177,总的违例值从-45.36 降为-3.42。由此说明,本文的时钟树设计对时序的优化效果明显,违例值的改善大大减轻了后续的逻辑优化,缩短了设计周期,使整体的占有率降低,从而降低了整体功耗。

表5 建立时间结果对比Tab.5 Comparison of setup timing

表6 保持时间结果对比Tab.6 Comparison of hold timing
5 结 论
本设计借助新一代布局布线工具Innovus,在传统MCU 物理设计流程基础上进行功耗优化,包括基于SAIF 文件协同优化的低功耗布局设计,并在布局结果基础上,进行手动配置部分时钟单元的低功耗时钟树设计。本文通过在布局和时钟树综合2 个阶段进行低功耗设计,能够达到优化功耗和时序的效果,缩短了设计周期,结果表明:
(1)在布局阶段,芯片功耗降为原来的90.6%,建立时间的最差违例值由-6.021 优化为-0.880;
(2)时钟树综合阶段,功耗优化的效果明显,时钟功耗降为原来的73.1%。时序得到改善,建立时间违例的总条数降为原来的12.5%,总违例值降为原来的3.0%,保持时间的违例总条数降为原来的39.8%,总违例值降为原来的7.5%。
