一种基于变分模态分解和样本熵的MEMS陀螺去噪方法
2021-07-08张德彪冯凯强鲁正隆
刘 洋,李 杰,张德彪,冯凯强,鲁正隆
(中北大学仪器科学与动态测试教育部重点实验室,山西太原 030051)
0 引言
MEMS陀螺仪广泛应用于捷联惯导、工业控制和消费电子等领域。但由于受到MEMS敏感理论、工艺水平及使用环境的影响,噪声成为制约MEMS陀螺仪性能的主要因素。构建陀螺的误差模型并补偿对提高精度至关重要,然而真实信号和漂移通常都淹没在高斯白噪声中,且因为存在这种非线性非平稳的随机过程导致难以建立精确的误差补偿模型,所以研究适用于非平稳随机误差的去噪算法具有重要意义。目前许多学者都致力于解决相关问题,提出了采用例如卡尔曼滤波器(KF)[1]、经验模态分解(EMD)[2-3]和小波变换(WT)[4]等方法进行滤波,实验结果证实它们在处理陀螺输出信号时,都能提供良好的去噪效果,但也都存在各自的不足。KF方法需要在具有完整信号的统计特性下分别建立状态方程和量测方程,结构和初始参数的确认都较为复杂,且其本质上更适合处理稳态信号,滤除非线性非稳态信号噪声的能力相对较弱。基于WT的时频分析方法需要事先选定一个小波基,特定的小波基在全局可能是最佳的,但针对信号的某些局部特征却很难分离出来,即小波基的选取对整个分析的结果影响很大,缺乏灵活性的同时也存在滤波时延问题。EMD可以看作一种不需要构造任何先验基础的自适应滤波器[5],但其数学理论基础还不完善,且对噪声敏感,表现为在后期的分解中可能得到不准确的固有模态函数(IMF)分量,产生模态混叠等现象。受EMD思想的启发,K.Dragomiretskiy和D.Zosso提出了一种非递归的变分模态分解(VMD)方法,克服了EMD的很多缺点。该方法具备严谨的理论基础,复杂度低,不会造成模态混叠现象的发生。其假设复杂原始信号可以表示为几个单组分(IMF)震荡和趋势的线性叠加[6]。换句话说,它可以将一个信号f(t)分解为特定数量的具有不同中心频率和有限带宽的AM-FM信号,并且对噪声具有鲁棒性。因此有助于得到给定信号的有效分解成分,利于后续分析处理。目前多用于非平稳信号瞬时时频特征的提取。
本文探讨了VMD方法在陀螺随机噪声降噪方面的应用,首先详细分析了VMD的原理,并利用仿真信号验证了方法的可行性。然后对实际的MEMS陀螺静态输出数据进行预处理,将原始信号分解为IMF的集合,陀螺的真实信号主要集中在比较低的频率范围内,针对不同的固有模态序列建立基于样本熵理论的信号组分筛选标准,根据求解的各个IMF的样本熵值,判断并将其划分为低频有效信息IMFs、信息和噪声混合IMFs和高频噪声主导IMFs3个具有不同特征的部分。如果仅剔除高频噪声IMFs后重构会导致误差较大,所以后续利用软区间阈值降噪方法实现对混合分量的进一步处理,同时舍弃高频噪声分量,最后通过重构得到最终的信号。比较结果表明该算法的去噪性能优于同等条件下的EMD方法。
1 基本原理与分析
1.1 VMD原理
VMD的核心思路总体分为2部分:一是先构建变分问题;二是求解变分问题。该方法有一个重要假设,对于一个信号f,它都能够分解为K个具有不同中心频率和有限带宽的IMF,即每个IMF都紧凑的围绕在其中心频率ωk附近,具有窄带特性。如式(1)所示,此时重新定义IMF为一个调频调幅信号。
uk(t)=Akcos(φk(t))
(1)
式中:uk为第k个IMF(1≤k≤K);φk为相位;Ak为调制信号幅度的包络(Ak(t)≥0)。
根据式(1)和提出的假设,可以得出VMD方法分解的实质是一种有约束的优化过程,在所有IMF线性叠加等于给定原始信号的约束条件限制下,让这些具有不同中心频率的IMF带宽之和尽可能的小,理想状态下每个IMF只包含一个频率的函数分量。
为了评估其带宽,执行以下3个操作:
(1)对uk作Hlibert变换求解其分析信号以获得单边频谱。
(2)乘以调谐到对应ωk的指数谐波,从而把频谱转移至基带。
(3)利用Gauss平滑估计ωk的带宽(梯度的平方L2范数)。
由此产生的变分约束优化问题可以用式(2)表示:
(2)
式中:∂t为梯度;δ(t)为单位脉冲函数。
要求获得的IMF带宽尽可能窄的同时要保证分解之后的IMF重构后不能严重失真。为了解决这个变分约束问题,在此使用能提升重构逼真度的二次惩罚项并引入使约束条件保持严格性的拉格朗日乘数λ(t)。如式(3)描述的扩展拉格朗日方程所示,将提出的有约束的优化问题转化成等效的无约束辅助函数最小化求解问题。其中α表示二次惩罚因子,此处可理解为调节数据保真度的平衡参数。
本组新生儿均执行产科常规护理,包括监测、记录新生儿体温、体重、皮肤与呼吸有无异常等,当发现新生儿存在患病表现时,应及时给予病情监护、生命体征监护、给药护理等。
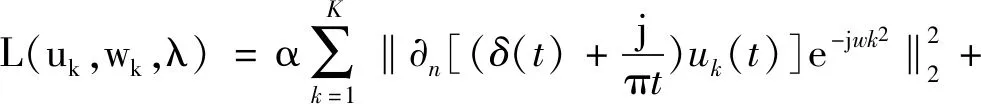
(3)
利用乘法算子交替方向法,结合Parseval/Plan-cherel傅里叶等距变换交替迭代得到子问题的解为:
(4)
式中:n为迭代次数;ωk为中心频率。
ωk可通过式(5)进行更新。拉格朗日乘数可通过式(6)进行更新。
(5)
(6)
式中τ为设定的噪声容限。
综上所述,获得模态分量和中心频率的迭代过程可简述为:
(4)根据式(7)判断是否符合精度要求(ε为设定的收敛阈值),若不符合则继续重复步骤(2)至步骤(4),若符合,退出迭代过程,输出K个模态分量。
(7)
1.2 仿真信号分析
为了验证VMD算法的有效性,构造仿真信号如下:
f(t)=sin(2πtf1)+0.4sin(2πtf2)+0.15sin(2πtf3)+η
式中:频率成分f1=2 Hz、f2=30 Hz和f3=100 Hz;η为高斯白噪声,η=15 dB。
VMD方法存在一个局限性,即使用前需根据经验确定分解IMF的数量K。针对此信号设定K=6,二次惩罚因子α=4 000,噪声容限τ=0.1,收敛阈值ε=10-7。图1为仿真原始信号。分解之后得到的模态分量及对应的频谱如图2所示。

图1 仿真原始信号
图2展示了信号中的几个频率成分可以通过VMD算法从低到高依次被分解提取出来。以便于进行后续分析处理。
1.3 样本熵与区间阈值滤波
实际上,当VMD应用于真实的陀螺信号输出时,分解结果中必定包含有效信号与随机噪声混合的模态,且陀螺输出的有效信号主要集中在低频段,那么全部模态序列整体上可以用低频有效信息IMFs、信息和噪声混合IMFs和高频噪声主导IMFs3个具有不同特征的部分来概括。因此如果能建立相应的筛选标准,准确地划分归属范围,降噪过程就会更加的清晰具体。

(a)模态分量
在与VMD类似的EMD算法的应用过程中,文献[7]提出可以通过计算给定原始信号概率密度函数与IMF分量的2范数距离来度量两者之间的相似性,进而确定噪声分量,经过实验证明这种方案具有良好的效果。同样在EMD中,计算原始信号与IMF的相关系数来确认组分也是被广泛接受的一种解决办法,但是它受信噪比和信号中趋势项的影响比较大。本文提出应用样本熵理论来区分信号的组分。样本熵是度量非稳态时间序列复杂性的一种算法,熵值Se越低说明序列自似性越高,熵值越大说明序列越不规则、越复杂。Se可以通过文献[8]介绍的方法在指定相似度阈值r和嵌入维数m后获得。在获取分解结果后,分别计算每个IMF的样本熵值,对于近似高斯分布的高频噪声主导IMFs,Se较小且具有相近的值,随着低频成分在模态中占比的增加,Se逐渐增大。
在凭借上述方法确认信号组分后,对高频噪声主导的IMFs予以舍弃,并采用软区间阈值滤波方法对信息与噪声混合IMFs进行去噪,将小于阈值的部分置零,大于阈值的部分经过计算保留。相比于硬区间阈值去噪方法,经由软区间阈值滤波处理的信号能够保持连续性,可以有效提取混合分量中的有用信息。具体过程可参照式(8)完成[9]。
(8)
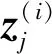
Ti可根据式(9)和式(10)确定。
(9)
(10)
式中:EL为最后一个高频噪声IMF的能量;N为数据长度;β和ρ为经验参数值,β=0.719,ρ=2.01[10]。
最后将混合分量去噪结果与低频有效信息IMFs进行信号重构得到最终信号。总体方案的流程可用图3表示。
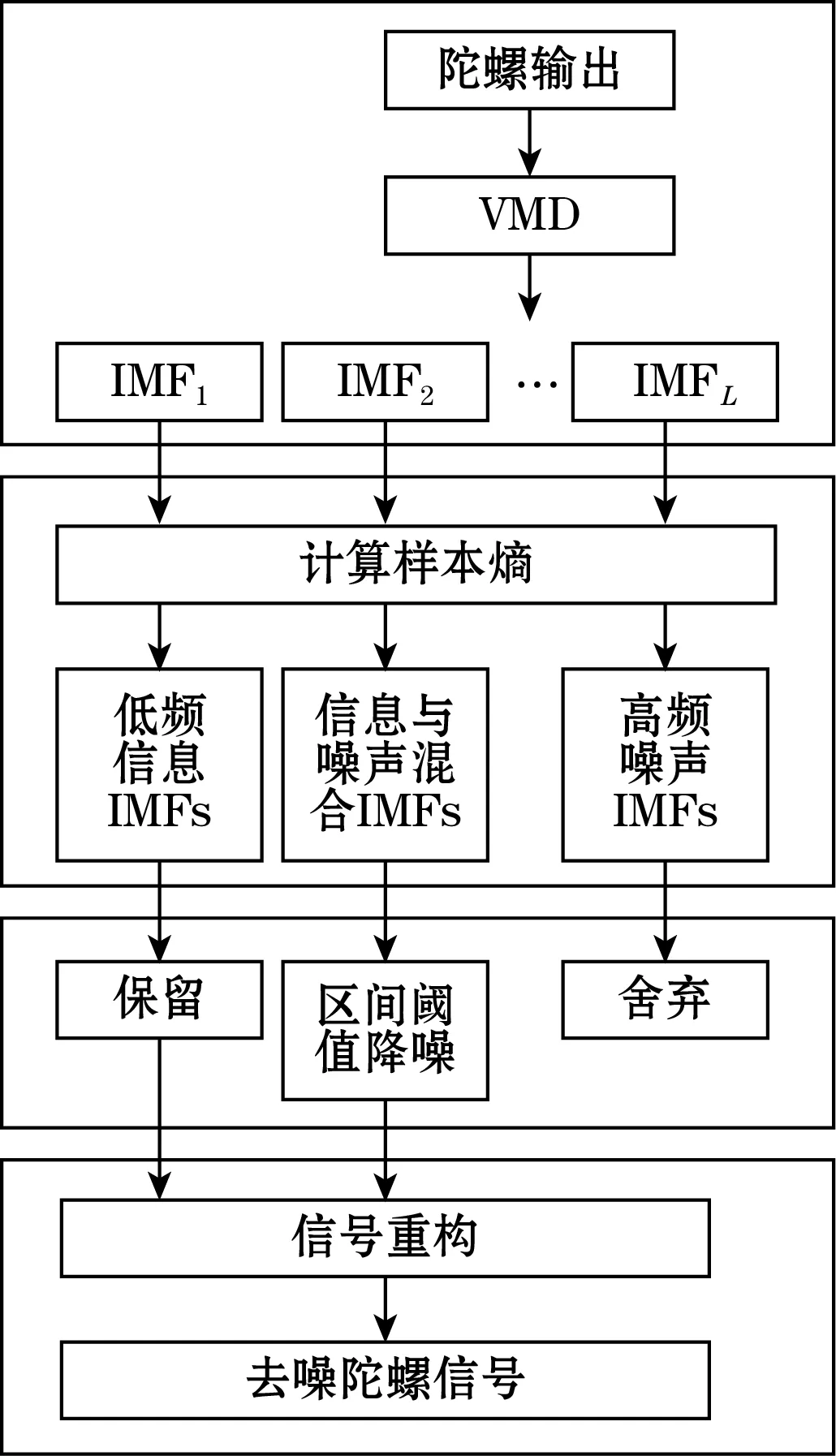
图3 总体方案流程图
2 实验结果与分析
采集一段MEMS陀螺的静态漂移数据,系统采样率为1 000 Hz,为避免启动误差影响结果分析,在1 h后取50 s的数据利用本方案进行处理。设定分解模态个数K=8,二次惩罚因子α=5 000,噪声容限τ=0.1,收敛阈值ε=10-7。首先得到VMD分解结果如图4所示,为了有直观清晰的体现,仅展示其中的1 000个采样点。计算所得各模态样本熵Se的变化趋势如图5所示。可以看出基于样本熵的判定方法可以分辨出有关趋势项的特征拐点,所以定义IMF1和IMF2为低频信息分量。具有高频属性的第6、7和8个固有模态拥有相近且相对最小的Se的值,所以定义IMF6、IMF7和IMF8为高频噪声分量。第3~5个模态是混合分量,应用区间阈值滤波方法对该部分进行降噪处理,处理完成后IMF1与IMF2和叠加重构获得最终信号。
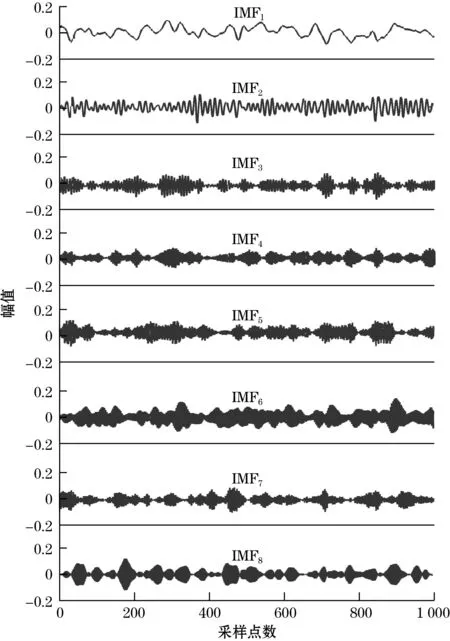
图4 陀螺数据VMD分解结果
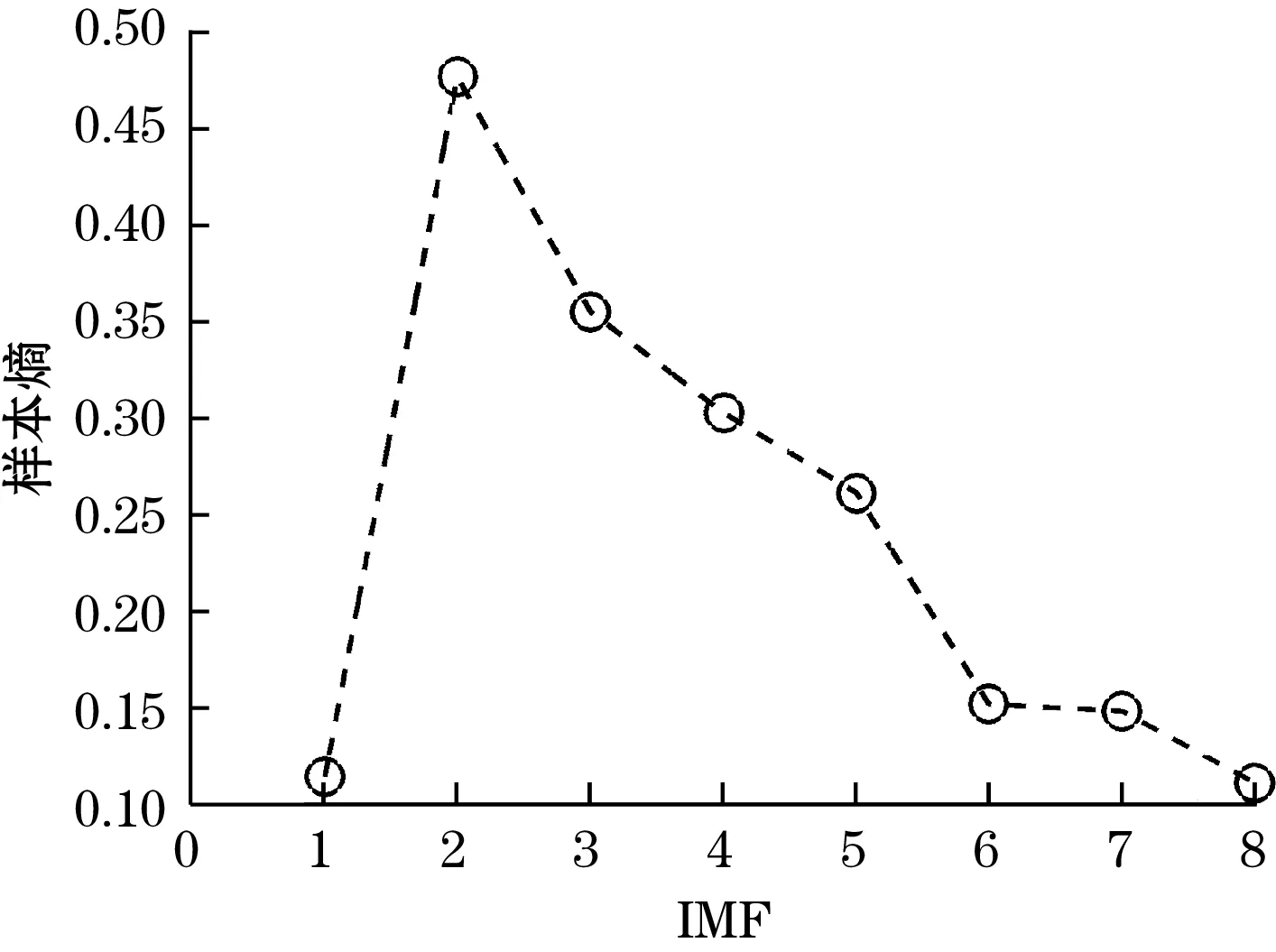
图5 各模态的样本熵值
在相同的实验条件下,该方案与同为模态分解去噪的EMD方法进行对比(EMD分解后舍弃高频噪声分量并重构),去噪结果如图6所示,其中噪声最大的原始信号显示为深灰色,经EMD处理的信号显示为黑色,经提出的方案处理的信号显示为浅灰色。计算其各自的均方差并列在表1中。通过均方差值的对比可以证明基于VMD和样本熵的去噪方案的性能显著优于EMD去噪方案。
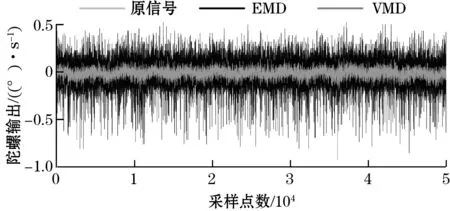
图6 去噪结果对比

表1 去噪结果均方差
3 结论
VMD可以自适应地把数据分解为包含不同频率成分的模态,样本熵能够有效地筛选评价模态信息。经过实验证实基于2种方法的去噪方案对MEMS陀螺的随机噪声有明显的抑制作用,同等条件下性能优于EMD方案。因此通过提出的方法对数据进行处理后,惯导系统的精度和可靠性可在一定程度上得到提升。
