基于支持向量机回归的豫南地区小麦蚜虫发生程度预测模型研究
2021-07-07高风昕
高风昕
(黄淮学院 数学与统计学院,河南 驻马店 463000)
麦芽虫又称腻虫,据统计,我国每年因为麦蚜虫的危害使小麦减产2×108~3×108t。目前,国内外对小麦蚜虫的预测模型主要采用统计的方法,如李文峰等[1]利用逐步回归的方法构建蚜虫预报预测模型,丁世飞等[2]用逐步判别方法构建麦蚜虫发生期的模型,Luo等[3]利用SPSS中的逻辑回归的方法给出蚜虫预报预测模型。支持向量机在小样本训练方面比其他方法更胜一筹,该方法的泛化能力非常强,而支持向量机大多运用在证券、金融、大气污染物浓度的预测中,在小麦蚜虫发生程度的预测模型的研究中国内外文献资料涉及的很少。本文运用支持向量机回归对豫南地区小麦蚜虫发生程度进行预测,以豫南地区2008年—2019年的麦芽发生情况、气象资料为依据,给出小麦蚜虫发生的17个影响因子,利用主成分分析的方法对输入因子降维,从而得到支持向量机的训练样本和测试样本,由此建立基于RBF核函数支持向量机回归的小麦发生程度的预测模型。经测试样本检验表明,该方法预测精度高、泛化能力和时效性强,具有良好的应用前景。
1 支持向量机基本原理
支持向量机(SVM)将每个样本数据表示为空间中的点,使不同类别的样本点尽可能明显地区分开。通过将样本的向量映射到高维空间中,寻找最优化区分两类数据的超平面,使各类到超平面的距离最大化,距离越大表示SVM的分类误差越小,即使数据集的边缘点到分界超平面的距离最大,称边缘点为支持向量。通过非线性映射将原始数据空间映射到高维特征空间并在新空间中求取最优化线性分类面。为权重向量,b为偏置常数。
把线性回归问题转化为求如下的最优化问题:

式中:C——惩罚参数,ξi,——松弛变量,ε——不敏感损失函数阈值。
模型(1)的对偶问题:


K(xi,x)为核函数,常用的核函数有线性核函数、多项核函数、径向基核函数、sigmod核函数,根据专家经验径向基核函数(KBF)能使支持向量机取得最好的效果,所以选择KBF作为核函数。
对支持向量机回归参数估计有多种,比较各种参数估计方法从预测精度上考虑常选择网格搜索法来确定惩罚因子C,核参数σ,损失函数中的参数ε。
2 SVR小麦蚜虫发生程度预测模型的构建
2.1 小麦蚜虫发生程度的影响因子
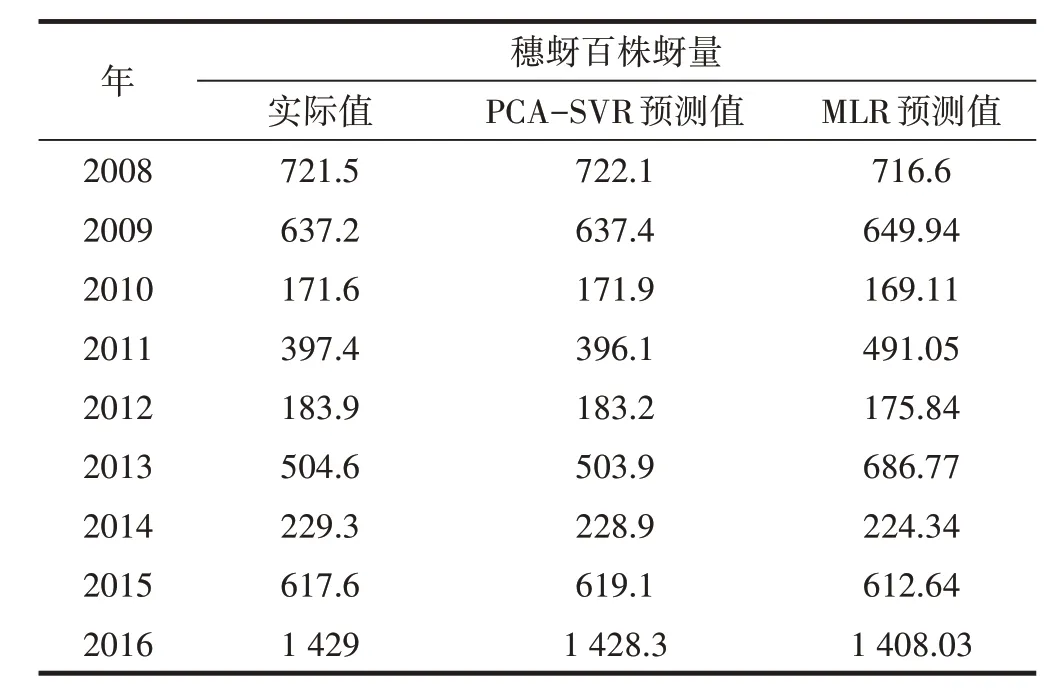
本文选取豫南地区驻马店市、信阳市、南阳市的2008年—2019年小麦种植区的气象和小麦蚜虫发生程度的数据资料,气象各因子资料来源于豫南地区逐日气象观测资料,小麦蚜虫的发生程度和天敌的数据资料来源于当地植保部门,气象资料采取每月每旬作为时间周期,小麦蚜虫的发生程度和天敌数据资料是指每个地市至少选择5个样本采集区,每5d采集1次样本,影响小麦发生程度的因子见表1。本文以2008年—2019年,每年2月1日—5月20日,以每旬作为时间周期,为了减少因子个数把天敌作为一个因子共17个因子187个解释变量。根据中华人民共和国农业行业标准(NY/T612-2002)《小麦蚜虫测报调查规范》,麦蚜发生程度根据百株蚜量(y,头)分为5级,分级标准为一级(y≤500)、二级(500 由影响小麦蚜虫发生程度的指标因子和小麦蚜虫发生程度数据组成的样本集,(xi,yi),i=1,2,…n,xi∈Rn,yi∈Rn来构建小麦蚜虫发生程度的SVR预测模型。由于各影响因子的量纲不尽相同,为了克服各因子由于量纲的不同对预测结果的影响,同时为了提高个各数据间的可比性和数据的收敛速度减少模型的训练时间所以先对原始数据进行归一化处理,利用公式(4)可将原始数据压缩到[0,1]上。 式中:xi——原始数据;x' i——归一化后的数据,xmax和xmin分别为原始数据的最大值和最小值。 影响麦蚜发生程度的解释变量有187个,指标因子维数过大,采用主成分分析的方法对指标因子降维得到主成分及得分,然后分别以所得主成分为自变量以麦蚜发生程度为因变量分别进行多元线性回归分析和支持向量机回归分析,根据以上分析可以确定PCA-SVR预测模型的流程图,见图1。 图1 PCA-SVR预测模型的流程Fig.1 Theflow chart of PCA-SVRprediction model 根据归一化后得到的数据利用SPSS25对各因子数据进行主成分分析从而获得主成分和主成分得分,分析结果由原来的187个指标因子缩减为6个主成分且方差贡献率达到98.57%,在原始变量的基本信息基本保持不变的条件下因子个数由187个减少了181个,所以用6个主成分代替187个原始变量进行多元线性回归分析。 以旬为单位收集了2008年—2019年12年的210个样本数据,其中选取2008年—2016年的样本数据作为训练样本,2017年—2019年样本数据作为测试样本。对于训练样本选取径向基核函数(KBF)构建(2)式的预测模型。同时利用170个训练样本使用LIBSVM3.22软件包,采用网络遍历法和K(K=10)折交叉验证法选择最优参数。结果:C=2257672.96512,g=0.000038896503529,p=0.0338。 以主成分分析所得到的6个主成分为解释变量,利用PCA-SVR模型和多元线性回归模型得到麦蚜发生程度的预测值与观测值之间的数据见表2,并且利用PCA-SVR模型得到麦蚜发生程度的预测值与实际值之间的相关系数接近于1,利用多元线性回归模型得到麦蚜发生程度的预测值与观测值之间的相关系数为0.97,这表明麦蚜发生程度实际观测值与预测值之间具有高度的相关性,并且通过PCA-SVR模型得到的训练样本的预测值与实际观测值相符合见表1,测试集样本数据的预测值与实际观测值相符合见表2。 表1 训练样本实际观测值与预测值对比Tab.1 The comparison of actual observation value and predicted value 表2 测试样本实际观测值与预测值对比Tab.2 The comparison of actual observation value and predicted value 为评价模型的质量,常用PCA-SVR模型的预测值与观测值的进行比较,通常采用以下统计量对PCA-SVR模型进行评价,比较结果见表3。 表3 训练和测试样本误差因子比较Tab.3 The comparison of error factors of training and testing samples MLRM 误差指标PCA-SVR SVR 0.21780.55420.06410.1568 MAPE RMSE MSE MAE 0.10430.11650.02630.11390.1110.42170.03630.1476 平均绝对误差MAE= 均方误差MSE= 均方根误差RMSE= 平均绝对百分比误差MAPE= 由表4可以得出PCA-SVR组合模型具有较高的预测精度,所以PCA-SVR组合模型的应用能够准确及时地发布豫南地区小麦蚜虫监测预警信息,有效地进行小麦蚜虫的科学防控。2.2 数据的归一化处理

2.3 PCA-SVR组合模型预测流程图
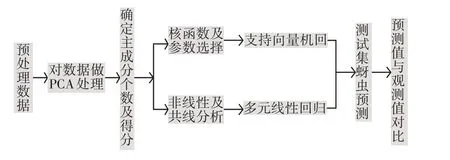
2.4 主成分回归分析
2.5 主成分SVR参数寻优
3 模型预测结果分析
3.1 预测值和实际值的比较分析

3.2 模型的评价


4 结论
