基于高分辨率网络的人体姿态估计方法
2021-07-06任好盼王文明危德健高彦彦康智慧王全玉
任好盼,王文明,危德健,高彦彦,康智慧,王全玉
基于高分辨率网络的人体姿态估计方法
任好盼,王文明,危德健,高彦彦,康智慧,王全玉
(北京理工大学计算机学院,北京 100081)
人体姿态估计在人机交互和行为识别应用中起着至关重要的作用,但人体姿态估计方法在特征图尺度变化中难以预测正确的人体姿态。为了提高姿态估计的准确性,将并行网络多尺度融合方法和生成高质量特征图的方法结合进行人体姿态估计(RefinedHRNet)。在人体检测基础之上,采用并行网络多尺度融合方法在阶段内采用空洞卷积模块来扩大感受野,以保持上下文信息;在阶段之间采用反卷积模块和上采样模块生成高质量的特征图;然后并行子网络最高分辨率的特征图(输入图像尺寸的1/4)用于姿态估计;最后采用目标关键点相似度OKS来评价关键点识别的准确性。在COCO2017测试集上进行实验,该方法比HRNet网络模型姿态估计的准确度提高了0.4%。
姿态估计;多尺度融合;高质量特征图;人体检测;关键点相似度
1 研究背景
人体姿态估计就是从图像或视频中,提出多个人体的位置以及骨架上的稀疏关键点位置,其作为人类行为理解的基础,一直是计算机视觉领域具有挑战性的问题,因而备受关注。准确的关键点估计可以用在远程控制机器人进行危险作业、安保系统中监控人员行为、交通中检测行人动作辅助驾驶、影视业中不需要专业的数据采集设备就能采集人体运动参数等。人体姿态估计方法大致分为:自底向上(Bottom-Up)和自顶向下(Top-Down)的方法。
自底向上(Bottom-Up)的方法[1-3],首先通过人体关键点的热图来定位图像中所有的人体关键点,然后使用组合算法将其组合成不同个体。该方法只需提取一次有效的人体特征,速度快、实时性好,但准确度偏低。OpenPose[2-4]使用2分支多阶段的网络,分别用于热图估计和关键点组合。其使用关节点仿射场(part affinity fields,PAFs),通过计算2个关键点之间的线形积分来描述关键点之间的关联度,并与最大的得分进行关键点组合。文献[1]使用部件强度场(part intensity field,PIF)来定位人体关节点位置;部件关联场(part association field,PAF)将人体关节点连接起来形成人体姿态。总之,自底向上的方法可一次性检测图像中所有的人体部件,即使人体数目增加也不会重复进行卷积操作,一般模型小、效率高,但在不同的光照、背景、遮挡等情况下,会出现关键点聚类算法的匹配错误。
自顶向下(Top-Down)的方法[5-8]主要是使用单个人体姿态检测器识别人体框之后,再对每个人体框进行关键点检测。其多次剪裁和调整边框,并多次提取有效特征信息,在多种人体姿态估计基准上通常高于自底向上的方法,但实时性偏低。文献[8]中网络模型Alphapose首先通过目标检测,得到人体框,然后输入到STN+SPPE模块中,自动检测人体姿态,再使用Pose-NMS得到最终的人体姿态。其中STN对称空间变换网络能在不准确的人体边框中提取人体区域。Pose-NMS参数姿态非最大化抑制能够解决冗余的人体姿态。文献[5]中网络模型CPN分为GlobalNet和RefineNet 2个阶段,其中GlobalNet负责检测容易检测和较难检测的关键点,对于较难检测的关键点,使用网络深层的更高层次的语义信息来解决。RefineNet主要解决遮挡、复杂背景和尺度不适等更难或不可见关键点检测,使用Hard Negative Mining策略界定关键点难易程度。虽然自顶向下的方法已经取得了不错的效果,但是姿态估计的准确度和实时性仍有待提高。
以往自顶向下的方法[5-6,9]主要是使用上采样和下采样的方法进行多尺度的融合,并且采用特征图的最高分辨率来预测关键点的热图。文献[6]中高分辨网络(high-resolution net,HRNet)模型的各个阶段采用多尺度的融合,生成高质量的热图,仅使用最高分辨率的热图来进行人体姿态的估计,但是通过上采样生成的热图的质量有待提高。文献[5]中网络模型CPN采用上采样的方法将低分辨率特征图逐渐融合到高分辨率特征图中,不断提高用于估计人体关键点热图的质量,但是忽略了并行网络多尺度的融合,即不同分辨率的特征图的融合。为了解决上述问题,本文提出了一种基于HRNet的人体姿态估计方法RefinedHRNet。
2 姿态估计方法
HRNet在计算机视觉领域取得了优秀的成绩,超越了所有的基于深度学习的人体姿态估计方法,但是仍然有提升的空间。本文首先分析了该模型,提出特征图的问题;然后引入本文的RefinedHRNet模型以及并行多尺度融合和生成高质量热图的方法。
2.1 HRNet模型
HRNet采用的是逐步增加高分辨率到低分辨率的子网形成更多的阶段和多分辨率子网并行连接的方法,并且在整个过程中保持高分辨率表征,取得较高的准确度,因此RefinedHRNet采用HRNet作为主干网络。
HRNet以高分辨率子网络作为第一阶段,在随后的每个阶段中,都会将一个与当前分支最低分辨率的1/2的新分支并行加入到当前分支中,逐步添加高分辨率到低分辨率的子网,形成新的阶段,且并行连接多分辨率子网,并自始至终保留先前阶段的分辨率,最后阶段采用融合后的最高分辨率进行姿态估计。
虽然HRNet具有较好的准确度,但是仅仅通过最紧邻上采样得到的特征图质量有待提高,因此本文提出了RefinedHRNet模型。
2.2 RefinedHRNet模型
本文采用与HRNet类似的方式实例化主干网络,网络包含4个阶段,主体为4个并行的子网,其分辨率依次降低一半,相应的通道数目增加一倍。网络从主干网络开始,由2个步长为2的3×3的卷积组成,将分辨率降低至输入图片的1/4。第1阶段包含4个残差单元,每个单元由一个宽度为64的bottleneck组成,然后是3×3卷积,将特征图的宽度降低到。第2~4阶段分辨包含1,4,3个多分辨率块,每个块由4个残差单元组成,其每个分辨率中的残差单元均有2个3×3卷积,以第4阶段为例,分辨率的卷积宽度分别为,2,4,8。总共有8个交换单元,需进行8次多尺度的融合。图1为本文提出的RefinedHRNet模型,黄色层叠方块为特征图,箭头为卷积操作。
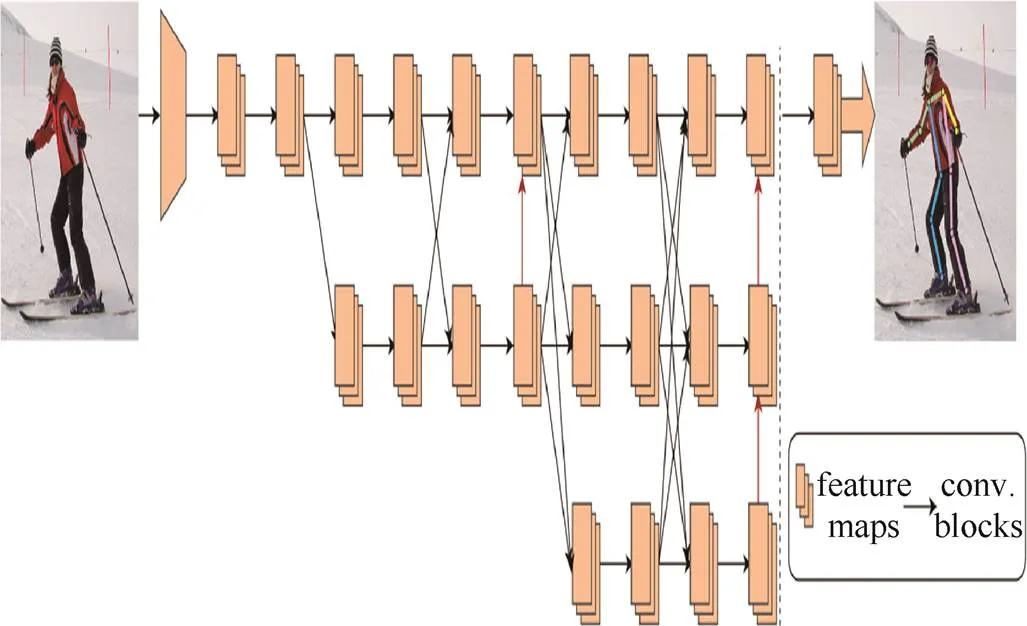
图1 RefinedHRNet模型结构图
2.3 并行多尺度融合
在多尺度融合中仍采用并行子网络的交换单元,使每个子网重复接受来自其他并行子网的信息。HRNet中,不同分辨率的特征图进行多尺度的融合时,采用步长为3×3的卷积做下采样,步长为1×1的卷积做最近邻上采样。虽然可以大幅度减少参数,但是会造成空间层级化信息丢失和小物体无法重建等问题。
文献[10-11]提出的空洞卷积能有效解决多尺度融合中信息丢失的问题。在不丢失分辨率的前提下,使用空洞卷积,能够有效扩大感受野。图2展示了并行网络多尺度融合过程。通过设置dilation rate,在卷积核中填充0,感受野随dilation rate发生变化,能够有效捕捉上下文信息。因此,本文采用空洞卷积来解决信息缺失的问题。多尺度融合公式为

其中,为在阶段s中第b块分辨率为r的卷积单元;为相对应的交换单元。式(1)与图3对应,均以RefinedHRNet网络第3阶段为例,第3阶段由3个并行的子网络组成,需要进行3次特征的融合,图3描述的过程为一次特征融合。
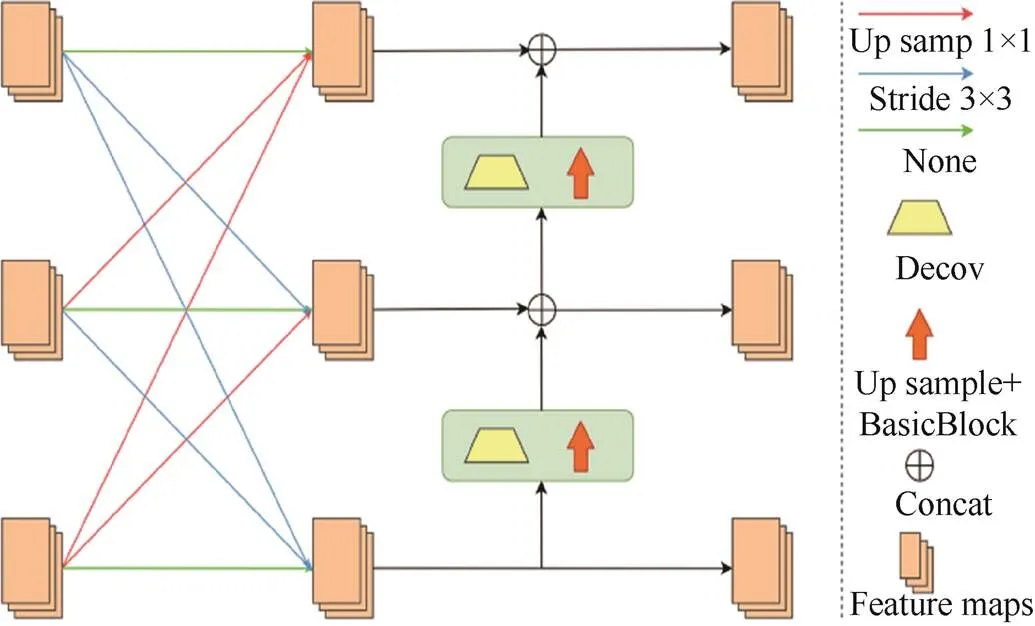
图3 从下到上特征融合
输入特征图的聚合输出为

其中,为采用最近邻上采样,将输入矩阵从分辨率提高到,其中dilation rate设置为4;为采用步长为2的3×3卷积进行下采样,将输入矩阵分辨率降低到;=为分辨率相同,为不采取任何操作,用于相同尺寸特征图的整合;上采样和下采样均可以通过连续卷积增加或降低特征图的尺寸。
各个阶段交换单元的额外输出特征图为

其中,{1,2,···,}为输入特征矩阵;{1,2,···,}为输出的特征矩阵,其分辨率和宽度与输入相同,为并行子网络数目。
2.4 生成高质量热图
使用反卷积模块有效生成高质量和高分辨率的特征图[9,12]如图3所示,在阶段之间添加了反卷积模块和上采样模块,使图像从低分辨率恢复到高分辨率,进而特征图包含更加丰富的特征信息。
在生成高质量的特征图时,在阶段之间采用从下到上特征融合方法,从低分辨率到高分辨率逐次添加反卷积模块和上采样模块。以第3阶段为例,从下到上进行特征融合时,使用反卷积和最近邻上采样提高分辨率(上采样)。图3中从上至下,特征图的通道数目为,2,4,通过连续的上采样可以将低层特征图宽度由4降低到,图像的分辨率提高至原来的4倍。从下到上的特征融合计算为
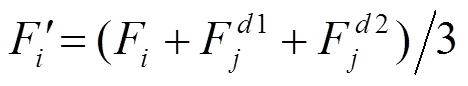

与HigherHRNet不同,本文仍然采用第4阶段产生的通道宽度为的特征图来预测关键点的位置,并未生成更高分辨率的热度图,反卷积模块和上采样模块的输入是并行子网络低分辨率的特征图,输出是高分辨率的特征图,用于后续阶段的特征融合。
3 训练和测试
训练和测试采用COCO2017数据集,其包含了200 000张图片和250 000个带有17个关键点的人体实例。该数据集的训练集、验证集、测试集分别有57 k,5 k,20 k张图像。在训练集(train2017)上进行训练,在验证集(val2017)和测试集(test-dev2017)上评估本文方法,并且与其他最新方法进行了比较。
在训练和测试中,使用COCO官方提供的测试方法,按式(5)计算网络模型预测出的关键点坐标与标签中真实值坐标的误差,通过设置不同的阈值来确定关键点位置的置信度。关键点相似性为

其中,d为检测到的关键点与其对应的ground truth之间的欧式距离;v为ground truth的可见性标记;为目标尺度;k为控制衰减的每个关键点常数。

3.1 训练阶段
本文采用相同的设置与HRNet模型进行对比。使用随机旋转(–45°,45°),随机缩放规模(0.65,1.35),并且采用图片的翻转等数据的增强方式。使用Adam优化器,基本学习率为1e-3,在170和200遍训练中分别降低到1e-4和1e-5,总计对模型进行了210遍训练。并从数据集图像中裁剪出输入网络的图像,调整为固定比例,高﹕宽=4﹕3,输入图像的尺寸分别为128×96,192×128,256×192,320×224和384×288。在整个训练过程中,着重增强64×48热图的细节特征,用于最后阶段估计人体姿势的关键点。
3.2 测试阶段
本文采用与HRNet网络相同的人体检测器,检测人体框,然后使用网络估计人体关键点。检测到的人体框按照固定的比例(高﹕宽=4﹕3)输入到网络中。根据HRNet,对原始图像和反转后的图像进行平均来计算热度图。同时,采用可视化的工具,将估计出的人体关键点进行连接,得到如图4所示的人体姿态估计图。

图4 人体姿态估计图
4 实验与分析
4.1 实验平台
实验在ubuntu18.04操作系统、3.7 GHz的CPU、6核心12线程以及1个NVIDIA 1080Ti GPU组成的服务器上完成。采用COCO2017数据集和MPII数据集用来训练和测试,并在test-challenge2020 (keypoint)上与本文结果进行对比。
4.2 实验过程
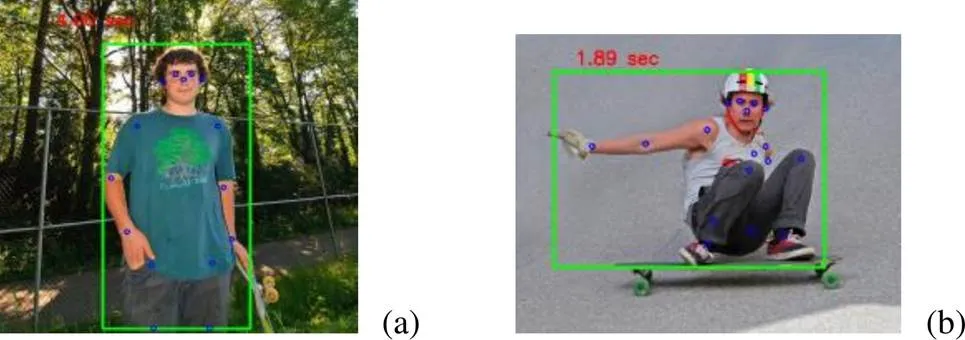
实验过程主要分为人体检测和关键点估计2个步骤。本文主要关注人体的关键点估计。在图5中绿框为人体检测模块检测到的人体边框,蓝空心圆为姿态估计模块定位的人体关键点。
4.3 实验数据对比
为了更好地说明算法的精确性,表1和表2分别在COCO2017验证集和测试集中进行实验对比,即自顶向下和自底向上2种方法对比以及网络中输入不同尺寸的图像进行对比。

图5 人体检测和姿态估计
表1为在COCO2017验证集下,与文献[5-6]在参数量、计算量以及准确度等方面的对比。其中文献[5]代表从上至下使用PN和CPN+OHKM(在线数据挖掘)网络模型;文献[12]代表从上至下分别使用ResNet-50,ResNet-101和ResNet-152作为主干网络的SimpleBaseline网络模型;文献[6]均采用hrnet_w32作为主干网络,仅输入图像的尺寸不同。实验结果表明,本文方法在中型和大型对象识别准确度方面均有一定提高,具有更高的准确度。
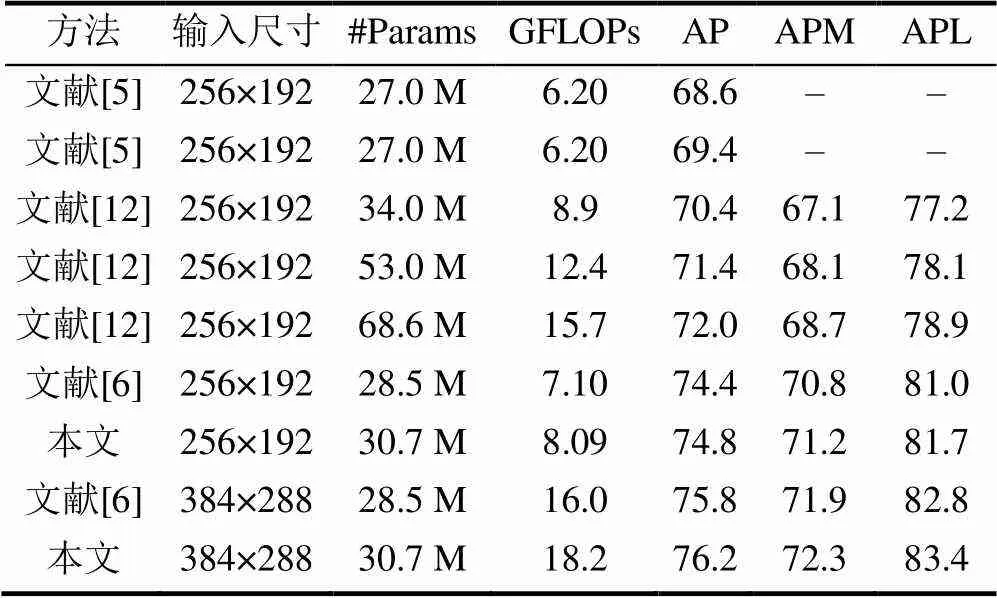
表1 COCO val2017中方法对比
表2为在COCO2017测试集下的与先进的方法进行对比。文献[4]和文献[7]为自底向上的方法,其余方法为自顶向下。从表2可看出,本文方法在准确度方面远远高于自底向上的方法。在使用相同的人体检测器和图像尺寸的前提下,本文RefinedHRNet网络超过文献[12]SimpleBaseline网络和文献[6]HRNet网络,具有更高的准确度。
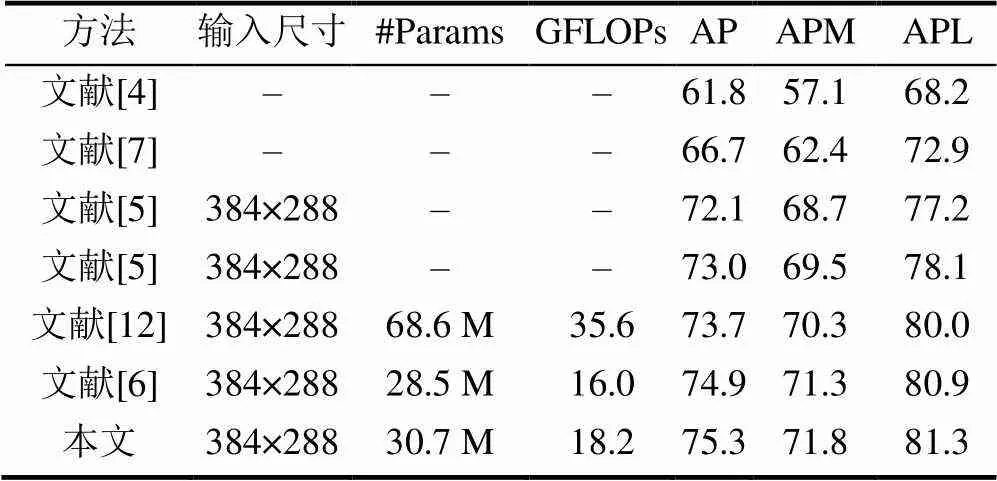
表2 COCO test-dev2017结果对比
为了对比多尺度融合方法和具有空洞卷积的多尺度融合方法(并行多尺度融合)以及生成高质量热图的方法对于网络模型的准确度的影响,本文进行了4种网络模型方法的实验:①多尺度融合方法;②具有空洞卷积的多尺度融合方法;③将多尺度融合和生成高质量热图方法(用上采样模块代替空洞卷积模块)的结合;④将具有空洞卷积的多尺度融合方法和生成高质量热图方法的结合;实验结果见表3。方法①与②对比,说明空洞卷积模块能提高网络模型的准确度(提高了0.2);②与④对比空洞卷积和反卷积模块能共同提高模型的准确度(相对HRNet提高了0.4);②和③对比,说明空洞卷积和反卷积模块都提高模型准确度的能力相同。

表3 不同方法对网络模型准确度的影响
表4为不同网络模型对于关键点估计的准确度实验结果。实验中模型的图像输入尺寸均为384×288,实验采用COCO2017验证集。通过计算关键点正确估计的比例PCK(计算检测的关键点与其对应的groundtruth间的归一化距离小于设定阈值的比例)来对比不同模型识别人体关键点的准确度。表4中头部、肩部、肘部、腕部、臀部、膝盖、脚裸分别代表头部5个关节点的平均值和肩部、肘部、腕部、臀部、膝盖、脚裸各2个关节点平均值及所有关节点的平均值。由表4可知,本文模型具有更高的平均准确度,在单个关节点识别的准确度上都有一定程度的提升,但膝盖关节点的识别准确度略低于HRNet_48。
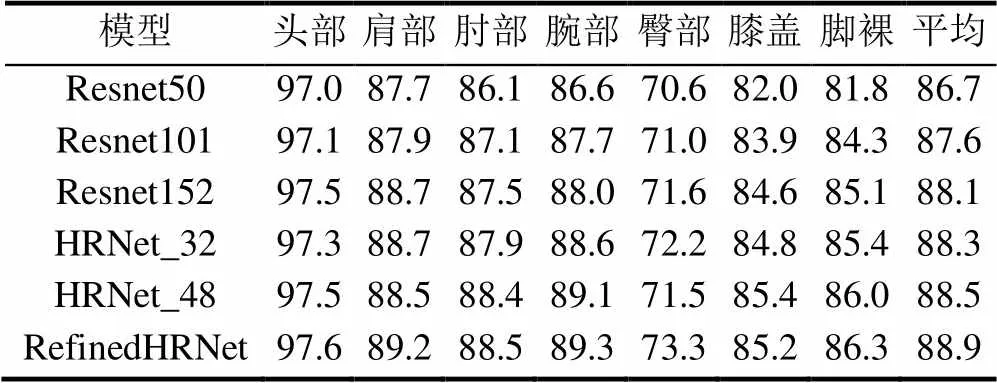
表4 不同网络模型对不同关键点检测PCK值比较
4.4 实验结果分析
表1采用相同的方法进行姿态估计,当输入图像的尺寸由256×192变为384×288时,HRNet网络和本文方法均提升1.4%,说明图像的输入尺寸对于准确度有一定的影响。参考文献[13-14]的实验平台设置,参考文献[15-16]对实验影响因素进行分析,考虑到基于RGB图像的姿态估计还会受到光照、遮挡等情况的影响,因此本文分别进行了不同图像分辨率和不同场景的实验。
4.4.1 图像分辨率对实验的影响
本文RefinedHRNet方法主要是依靠图像进行学习,不同分辨率的图像进行训练得到的模型准确度不同。本文推测不同尺寸的图像包含的纹理信息和关键点之间特征信息不同,较大尺寸热图包含的特征信息相对较多,但是会造成模型参数较大。在图像分辨率对于实验影响的研究中,均采用开始使用的COCO2017训练集训练,训练得到的模型在COCO2017验证集上进行测试,最终得到网络模型的准确度。
为了证明本文的推测,在COCO2017数据集中进行5组实验与HRNet网络对比,图像分辨率分别设置为128×96,192×128,256×192,320×224和384×288。
图6为不同图像分辨率对于识别准确度和运算量的影响。由图6可知,在相同的网络模型基础下,增加输入图像的尺寸,一定程度上提高姿态估计的准确度,但是同时运算量也大幅度增加。表5的实验结果表明通过增加输入网络图像的分辨率,对于中型人体和大型人体姿态估计的准确度都有一定程度的提高。
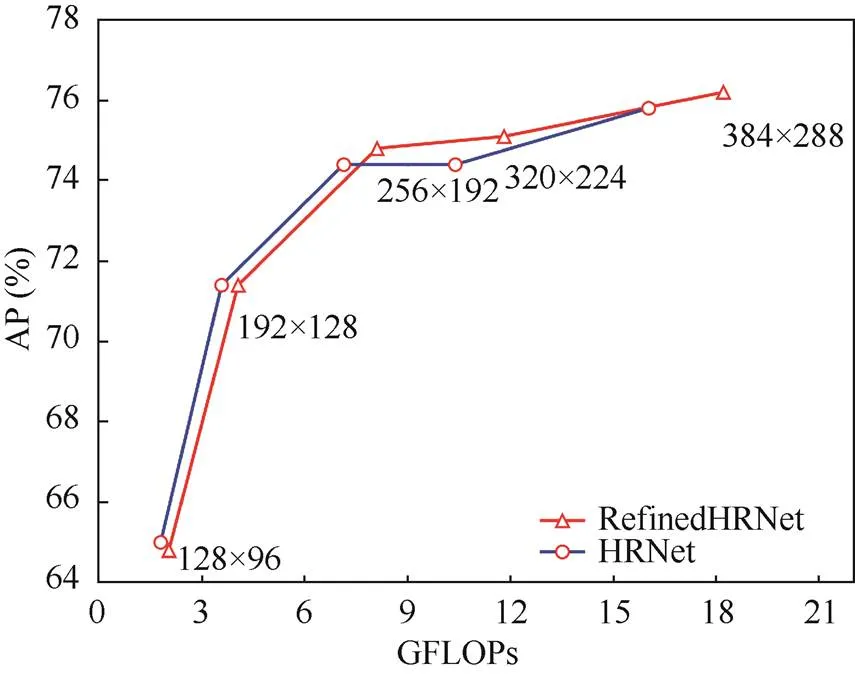
图6 输入图像分辨率与平均准确度的关系

表5 精确度与分辨率的关系
4.4.2 不同场景对实验的影响
为了验证本文方法的有效性,考虑到光照条件、人体遮挡对于实验结果的影响,本文从COCO2017验证集中根据光照条件随机选取400张具有人体标注的图片,进行了下述实验。
首先根据图像光照条件分为2组,每组200张,然后再根据图像中人体有、无遮挡情况分成2组,在各个实验条件下进行姿态估计。光照良好条件下,有遮挡和无遮挡图像数目分别为120和80;光照较差条件下,有遮挡和无遮挡图像数目各为100。并根据准确姿态估计的图像数目与该实验条件下图像总数的比值作为姿态估计的准确度,见表6。

表6 光照条件和人体遮挡对准确度的影响
图7(a)与图7(b)分别为在光照良好的条件下,人体有、无遮挡对于实验结果的影响。图7(c)与图7(d)分别为在光照条件较差的情况下,人体有、无遮挡对于实验结果的影响。由表6可知,在相同光照条件下,人体遮挡会导致姿态估计准确度降低;与人体遮挡相比,光照条件对姿态估计准确度影响更大。
以上实验表明,在不同光照条件、人体遮挡的情况下,本文方法具有一定的鲁棒性,能准确估计人体的姿态。
本文方法虽然取得了较好的实验结果,但是仍具有很大的提升空间。图7实验表明在人体遮挡条件下,人体检测器很难检测到遮挡的人体,因此无法进行姿态估计。该方法采用人体检测器检测人体,使用性能更好的人体检测器能够进一步提高姿态估计的准确度。其次是相对于从底向上的本文方法实时性较差,未来的工作将在保证网络准确度的同时减少参数量和计算量,提高实时性。
5 结束语
本文提出了基于RGB图像人体姿态估计方法RefinedHRNet,将并行多尺度融合的方法和生成高质量热图的方法相结合,利用目标关键点相似度OKS来评价关键点识别的准确度。实验结果表明,该方法与其他采用深度学习的姿态估计方法相比,具有更高的准确度,并且对于光照条件、人群密度、人体遮挡等具有较好的鲁棒性。人体姿态估计不仅能在PC端实现,在未来还能更多应用在移动便携设备中,更应该关注模型的轻量化设计,在保证模型准确度的基础上提高模型的实时性。
[1] KREISS S, BERTONI L, ALAHI A. PifPaf: composite fields for human pose estimation [C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 11969-11978.
[2] CAO Z, SIMON T, WEI S E, et al. Realtime multi-person 2D pose estimation using part affinity fields[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 1302-1310.
[3] WEI S E, RAMAKRISHNA V, KANADE T, et al. Convolutional pose machines[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 4724-4732.
[4] CAO Z, HIDALGO G, SIMON T, et al. OpenPose: realtime multi-person 2D pose estimation using part affinity fields [EB/OL]. (2018-12-18) [2020-04-15]. https://arxiv.org/abs/1812.08008.
[5] CHEN Y L, WANG Z C, PENG Y X, et al. Cascaded pyramid network for multi-person pose estimation[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2018: 7103-7112.
[6] SUN K, XIAO B, LIU D, et al. Deep high-resolution representation learning for human pose estimation[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 5686-5696.
[7] LI J F, WANG C, ZHU H, et al. CrowdPose: efficient crowded scenes pose estimation and a new benchmark[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 10855-10864.
[8] FANG H S, XIE S Q, TAI Y W, et al. RMPE: regional multi-person pose estimation[C]//2017 IEEE International Conference on Computer Vision (ICCV). New York: IEEE Press, 2017: 2353-2362.
[9] CHENG B W, XIAO B, WANG J D, et al. HigherHRNet: scale-aware representation learning for bottom-up human pose estimation [EB/OL]. (2019-8-27) [2020-04-27]. https://arxiv.org/abs/1908.10357.
[10] YU F, KOLTUN V. Multi-Scale context aggregation by dilated convolutions [EB/OL]. (2016-4-30) [2020-04-15]. https://arxiv.org/abs/1511.07122.
[11] LIU C X, CHEN L C, SCHROFF F, et al. Auto-DeepLab: hierarchical neural architecture search for semantic image segmentation[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 82-92.
[12] XIAO B, WU H P, WEI Y C. Simple baselines for human pose estimation and tracking [EB/OL]. (2018-8-21) [2020-04-11]. https://arxiv.org/abs/1804.06208.
[13] 陈国军, 杨静, 程琰, 等. 基于RGBD的实时头部姿态估计[J]. 图学学报, 2019, 40(4): 681-688.
CHEN G J, YANG J, CHENG Y, et al. Real-time head pose estimation based on RGBD[J]. Journal of Graphics, 2019, 40(4): 681-688 (in Chinese).
[14] 刘瑜兴, 王淑侠, 徐光耀, 等. 基于Leap Motion的三维手势交互系统研究[J]. 图学学报, 2019, 40(3): 556-564.
LIU Y X, WANG S X, XU G Y, et al. Research on 3D gesture interaction system based on leap motion[J]. Journal of Graphics, 2019, 40(3): 556-564 (in Chinese).
[15] 李白萍, 韩新怡, 吴冬梅. 基于卷积神经网络的实时人群密度估计[J]. 图学学报, 2018, 39(4): 728-734.
LI B P, HAN X Y, WU D M. Real-time crowd density estimation based on convolutional neural networks[J]. Journal of Graphics, 2018, 39(4): 728-734 (in Chinese).
[16] 吴珍发, 赵皇进, 郑国磊. 人机任务仿真中虚拟人行为建模及仿真实现[J]. 图学学报, 2019, 40(2):200-205.
WU Z F, ZHAO H J, ZHENG G L. Modeling and simulation implementation of virtual human behavior for ergonomics simulation[J]. Journal of Graphics, 2019, 40(2):200-205 (in Chinese).
Human pose estimation based on high-resolution net
REN Hao-pan, WANG Wen-ming, WEI De-jian, GAO Yan-yan, KANG Zhi-hui, WANG Quan-yu
(School of Computer Science and Technology, Beijing Institute of Technology, Beijing 100081, China)
Human pose estimation plays a vital role in human-computer interaction and behavior recognition applications, but the changing scale of feature maps poses a challenge to the relevant methods in predicting the correct human poses. In order to heighten the accuracy of pose estimation, the method for the parallel network multi-scale fusion and that for generating high-quality feature maps were combined for human pose estimation. On the basis of human detection, RefinedHRNet adopted the method for parallel network multi-scale fusion to expand the receptive field in the stage using a dilated convolution module to maintain context information. In addition, RefinedHRNet employed a deconvolution module and an up-sampling module between stages to generate high-quality feature maps. Then, the parallel network feature maps with the highest resolution (1/4 of the input image size) were utilized for pose estimation. Finally, Object Keypoint Similarity (OKS) was used to evaluate the accuracy of keypoint recognition. Experimenting on the COCO2017 test set, the pose estimation accuracy of our proposed method RefinedHRNet is 0.4% higher than the HRNet network model.
pose estimation; multi-scale fusion; high-quality feature maps; human detection; object keypoint similarity
TP 391
10.11996/JG.j.2095-302X.2021030432
A
2095-302X(2021)03-0432-07
2020-07-09;
2020-08-23
9 July,2020;
23 August,2020
任好盼(1995-),男,河南许昌人,硕士研究生。主要研究方向为计算机视觉、姿态估计等。E-mail:1838817927@qq.com
REN Hao-pan (1995–), male, master student. His main research interests cover computer vision, pose estimation, etc.E-mail: 1838817927@qq.com
王文明(1967-),男,北京人,副教授,硕士。主要研究方向为信息安全、区块链技术等。E-mail:wenmingwang2004@aliyun.com
WANG Wen-ming (1967–), male, associate professor, master. His main research interests cover information security, blockchain technology, etc. E-mail: wenmingwang2004@aliyun.com
