基于神经辐射场的视点合成算法综述
2021-07-06常远,盖孟
常 远,盖 孟
基于神经辐射场的视点合成算法综述
常 远1,2,盖 孟1,2
(1. 北京大学信息科学技术学院,北京 100871;2. 北京大学北京市虚拟仿真与可视化工程研究中心,北京 100871)
基于图像的视点合成技术在计算机图形学与计算机视觉领域均有广泛的应用,如何利用输入图像的信息对三维模型或者场景进行表达是其中的关键问题。最近,随着神经辐射场这一表示方式的提出,大量基于此表示方法的研究工作对该方法进行了进一步优化和扩展,在准确性、高效性等方面取得了良好的成果。该类研究工作可以根据研究目的大致分为两大类:对神经辐射场算法本身的分析以及优化,和基于神经辐射场框架的扩展及延伸。第一类研究工作对神经辐射场这一表示方法的理论性质和不足进行了分析,并提出了优化的策略,包括对合成精度的优化、对绘制效率的优化以及对模型泛用性的优化。第二类研究工作则以神经辐射场的框架为基础,对算法进行了扩展和延伸,使其能够解决更加复杂的问题,包括无约束拍摄条件下的视点合成、可进行重光照的视点合成以及对于动态场景的视点合成。在介绍了神经辐射场模型提出的背景之后,对以其为基础的其他相关工作按照上述分类进行了讨论和分析,最后总结了神经辐射场方法面对的挑战和对未来的展望。
基于图像的绘制;视点合成;神经辐射场;神经渲染;深度学习
基于图像的视点合成是计算机图形学与计算机视觉领域共同关注的重要问题。具体来说,基于图像的视点合成即为利用已知拍摄视点的若干图像作为输入,对这些图像所拍摄的三维物体或者场景进行几何、外观、光照等性质的表达,从而可以对其他未拍摄到的视点的图像进行合成,最终得到具有高真实感的绘制结果。相比传统的三维重建结合图形绘制的流程,此类方法能够得到照片级别真实感的合成结果。
多年来,研究者们针对该问题进行了大量的探索,获得了许多有价值的研究成果[1]。早期的方法一般采用“拼图”的形式实现此目的[2-4],但这类方法对于拍摄条件的限制较高,同时能够合成的视点也非常有限。后来研究者们开始尝试从输入图像中提取场景的三维信息,并以提取出的三维结构信息作为辅助,实现对不同视点的绘制,提高了自由视点合成的效果[5-7]。近些年来随着深度学习技术的飞速发展,许多基于深度学习的方法也被提出[8-10],通过数据驱动的方式,进一步提高了视点合成的准确性和真实感。
最近,随着神经渲染技术的兴起,类似方法也被扩展到了视点合成的领域中。文献[11]提出了使用神经辐射场表示三维场景或模型,并结合体绘制方法,将此表示方式成功地应用到了视点合成领域,取得了高质量的合成结果。这一研究成果获得了研究者们广泛的关注,并且引领了接下来的一系列针对该方法进行分析、优化、扩展的研究工作。其中,有些工作对神经辐射场的绘制效率和精度进行了优化提高[12-13],有些工作则是在可移植性上进行了探索[14-15],另外还有一些工作对该表示方法进行了扩展,以解决更加复杂的问题[16-17]。本文对以上基于神经辐射场的最新研究工作进行综述,对各种不同类型工作进行了介绍,也对各类方法的特点以及不足等进行分析和总结。
1 神经辐射场的提出
神经辐射场的提出得益于神经渲染领域取得的迅猛发展。该类技术可以将神经网络作为隐函数对三维模型进行表示,以达到不同的应用目的,如图像生成、视角生成以及重新光照等等。本节首先对采用神经网络作为场景几何的隐式表达的方法进行总结与介绍,以此引入神经辐射场的提出。
占位网络是一种典型的利用神经网络隐式表达三维几何的方法[18-19]。这种方法用神经网络对空间中每个点的二值占位情况进行预测,即对三维空间训练一个二分类网络,如图1所示。该方法的提出,主要意义在于使用连续函数对三维空间进行表达,相比于过去使用体素、网格等表达方式,可以在不增加任何空间存储的情况下描述各种复杂的几何形状。

图1 占位网络对空间进行二分类[18]
除了直接把空间按照是否存在模型划分为两类情况之外,还有一类隐式的表示方法是通过回归一个有符号的距离函数SDF对三维模型进行表示[20-21]。这类表示方式能够连续地对三维模型进行表示,即使是具有复杂拓扑的模型也能够进行建模,如图2所示。

图2 用有符号距离函数来表示三维模型((a)用有符号距离函数隐式表示曲面;(b)有符号距离函数的二维剖面;(c)利用有符号距离函数绘制得到的三维曲面)[20]
以SDF方法为基础,研究者们对这类方法进一步进行了完善,将其应用到了对具有高度细节的模型表示中。例如,像素对齐隐式函数方法(pixel-aligned implicit function,PIFu)[21]通过将空间点投影到与像素对齐的特征空间,隐式地学习三维模型当中的细节,从而实现了对穿衣人体模型的高分辨率重建。
但上述方法往往要求已知的三维形状作为监督信息,而在许多应用中,人们无法轻易地获取到三维形状的真值。所以接下来的一系列工作开始尝试放宽这一条件,直接使用图像作为监督。为此,一些研究工作提出了可微的绘制技术,从而将绘制步骤加入到神经网络中,以实现由绘制图像的误差直接对网络进行训练。文献[22]采用占位网络作为表达三维模型几何的表示结构,并采用数值方法寻找每条光线与模型表面的交点。每个光线交点都作为神经网络的输入预测该点的颜色值。文献[23]则采用为每个三维空间坐标预测对应的颜色和特征向量,并提出了一个由循环神经网络组成的可微的绘制函数用于决定哪里存在着物体表面。然而,这些方法始终受限于处理仅具有低复杂度的几何结构的简单形状,导致过度平滑的绘制结果。
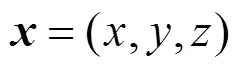
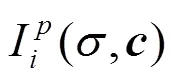


由于体绘制过程本身是可微的,所以可以加入到上述神经网络的训练,从而实现仅用图像的颜色值作为监督的训练过程。

图3 神经辐射场算法流程[11]
此外,为了避免合成图像中高频信息的丢失,NeRF还将输入变量首先进行了位置编码[25],将其映射到其傅里叶特征。实验表明,这一映射能够有效地解决高频信息难以拟合的问题。
表1展示了NeRF与早期基于神经网络的其他方法在2个数据集[11,26]上的量化对比结果。由表1可以看出,使用连续函数对场景进行表示的NeRF方法得到了更加高质量的视点合成结果。

表1 NeRF与早期基于神经网络方法的量化对比
2 关于神经辐射场的分析及优化
基于神经辐射场的方法NeRF提出之后,由于其结构简单、合成精度高的特点,迅速引起了研究者们的注意。部分研究工作开始对NeRF取得良好结果的原因进行理论和实验分析,同时,部分研究工作也开始针对NeRF存在的问题进行了优化和提升。
文献[28]对NeRF方法中的位置编码操作进行了更加深入的研究,以神经正切核理论[29]作为工具,从理论上论证了标准的多层感知机是难以对高频信息进行学习的。同时,其也通过不同应用场景下的实验结果验证了这一现象。为了解决这一问题,该方法提出将原始输入变量映射至傅里叶特征空间可以将有效的神经正切核变换为可调带宽的静态核,并且可以大幅地提升多层感知机处理计算机图形学和计算机视觉领域中低维回归问题的能力。如图4所示,在加入位置编码之后,对高频信息的拟合有了显著的提升。

图4 加入位置编码的效果((a)多层感知机网络示例;(b)图像回归任务;(c)三维形状回归任务;(d)核磁共振成像任务;(e)逆向绘制任务)[28]
文献[13]则对NeRF中理论上存在的歧义性进行了分析,并对采样过程进行了优化,使其能够适应无边界场景的视点合成。在NeRF中,为了对物体的外观颜色随观察角度变化而变化这一性质进行建模,其理论上实际出现了几何与颜色的歧义。具体来说,对于一个已知的场景或者模型,即使是一个完全错误的几何估计,也总存在一个合适的辐射场使得该辐射场与该错误的几何能够完美地对输入图像进行拟合。如图5所示,仅用一个球面模型代替正确的几何结构,只要对应的辐射场足够的精细,满足每条光线与球面相交的点沿光线方向发出的颜色为对应像素的颜色,即可使得预测的图像与输入图像完全吻合。然而由于对几何的错误估计,该神经辐射场在视点偏离输入视点时就会造成较大的畸变,从而无法用于正确的视点合成。而NeRF在实际实验中并没有出现上述严重的歧义现象,是因为对于一个有限大小的多层感知机,其表示的函数具有较高的平滑性,一般难以表达出错误的几何所需要的非常高频的辐射场函数,从而避免了这个问题。

图5 颜色和几何的歧义性[13]
除此之外,该文献还对光线采样过程进行了优化,通过在单位球的内外部分别采用不同的参数化方法,实现了对无边界场景的有效采样,完善了NeRF对无边界场景的处理能力。优化过后的采样过程如图6所示。

图6 球面内外不同参数化[13]
表2展示了该方法在无边界场景数据集[30]上与原始NeRF方法的对比结果。可以看出,该方法有效地提升了网络对于无边界场景的表达能力,可以得到更准确的视点合成结果。

表2 文献[13]与NeRF在无边界场景上的量化对比
还有一类重要的研究工作则以绘制效率为出发点提出了优化策略[12,31-32]。如上文所述,通过神经辐射场绘制图像中的像素需要在其发出的光线上进行采样,并且对于每一个采样点,都需调用一次神经网络以得到对应的体密度和颜色值预测。这使得NeRF不仅在训练时需要消耗较多时间,在对新视点进行预测时同样需要消耗较多的时间。为此,文献[12]提出了一种新的场景表达方式:神经稀疏体素场(neural sparse voxel fields,NSVF),将空间进行稀疏的体素划分,并把辐射场定义在每个体素内部从而描述该局部空间的性质。在构造体素八叉树结构之后,就可以在绘制时跳过那些不存在任何内容的体素,从而大大提升绘制的速度。基于该稀疏体素结构的采样方式如图7所示。

图7 不同的采样方式((a)均匀采样;(b)重要区域采样; (c)稀疏体素采样)[12]
还有部分研究者们对该模型的泛用性进行了研究和优化[14-15,33]。传统的NeRF模型要求对每一个场景都要独立的进行训练,同时也需要较多的进行过相机标定的输入图像用于训练,这使得使用时的时间开销较大,大大降低了该模型的泛用能力。文献[14]首先利用卷积网络对图像进行特征提取,然后将提取到底特征加入到NeRF网络的输入中,以学习到场景的先验,如式(3)所示

优化之后的模型能够有效地学习到场景的先验知识,从而能够在一次训练过后,对于新的场景,仅通过少量的输入图像即可对未知视点进行预测。
另一种提高NeRF泛用性的方法则是利用元学习的思路。文献[15]利用标准的元学习算法对NeRF网络的初始参数进行学习,如图8所示。该研究表明,使用学习得到网络初始参数相比使用传统的参数初始化方法能够得到更快的收敛速度,同时这些学习到的初始参数值可以有效地作为场景的先验知识,使得当输入图像有限时,也能得到良好的合成结果。实际上,该方法不仅限于视点合成问题,对于用全连接神经网络表示信号的各种应用均可适用。

图8 学习得到的初始参数能够加快收敛速度也具有更好的泛用性[15]
3 对于神经辐射场的扩展及延伸
除了对NeRF方法本身进行分析和优化之外,还有许多的研究工作对该方法进行了扩展和延伸,将其扩展到了更加多样、复杂的应用场景中。
3.1 基于无约束图像的视点合成
为了能够利用互联网上采集到的同一场景的多视角照片进行自由视点的合成,文献[34]将NeRF扩展到了无约束拍摄条件下的视点合成,提出了无约束条件下的神经辐射场算法(NeRF in the wild,NeRF-W)。对于某些名胜景点,互联网上能够找到大量的游客拍摄的照片,如何通过这些照片对场景构建合适的表示结构,实现自由视点的漫游是一个非常有价值也具有挑战性的问题。由于照片的拍摄时间、天气、光照等条件可能存在着巨大的差异,同时还常常会有游客等前景出现在不同的照片中,使得传统的NeRF无法对这种情况构建出正确的神经辐射场。在这种条件下,即使是同一个位置、同一个角度,也可能对应着完全不同的拍摄图像。针对这一特点,该方法为每张输入图像进行外观编码[35],用于隐式地表示每幅输入图像所蕴含的拍摄条件。在加入这一编码操作之后,NeRF-W可以准确地学习到场景的几何结构,并可以对不同的输入图像的光照条件进行编码和解码。除此之外,为了处理不同照片中存在不同的前景等临时物体,NeRF-W将场景建模为各输入图像间共享的元素以及依赖于各输入图像的元素。这使得模型可以对场景中保持静态的内容与临时物体进行有效的区分,从而使得在合成新视点时,能够避免由于行人、车辆等临时前景所带来的视觉瑕疵。图9展示了NeRF-W处理互联网无约束拍摄图像的结果。

图9 通过互联网收集图像进行视点绘制[34]
3.2 基于神经辐射场的重光照技术
另一类重要的扩展应用为将神经辐射场进行增强使其能够表达不同的光照条件[36-38]。3.1节中介绍的NeRF-W虽然已经能够基于不同的光照条件下拍摄的图像进行图像合成,并且可以对合成的视点平滑地调整光照条件,但其只是隐式地对光照性质进行了描述,并不能显式地调整光照的各种物理量。
文献[37]提出了一种叫做神经反射场的表示方式,在NeRF能够对体密度信息进行编码的基础上,对空间中每一点的局部光照模型也进行了编码,包括法向和反射性质,如图10所示。该方法将这一表示模型与基于物理的可微光线步进算法进行结合,可以绘制出任意视点、任意光照条件下的图像。
然而,这种直接的方法局限于某些受限的光照设置,要求所有的输入图像都绘制于同一个单个的点光源。对此,文献[36]提出了神经辐射及可见性场(neural reflectance and visibility fields,NeRV)进行改进,改进的方式是使用一个额外的多层感知机学习空间中的可见性场,用于描述每一个点的可见性。在这种情况下,该神经网络的输入为空间中的三维位置坐标,输出则为:体密度、表面法向、材质参数、沿任意方向距离第一个相交表面的距离、沿任意方向对外部环境的可见性。增加了可见性表达之后,该模型降低了体绘制的时间复杂度,从而可以描述更加复杂的光照所产生的效果,如图11所示。

图10 神经反射场算法流程概览[37]

图11 神经可见性场降低了时间复杂度[36]
表3展示了在不同光照条件下上述2种方法在合成场景数据集上的量化对比结果。其中,“Single Point” 表示光照为随机分布的单一的白色点光源的光照条件。“Ambient+Point”表示单一点光源和一个暗灰色环境图的光照条件。可以看出,在简单的单一点光源条件下,2种方法并无显著差异,但是在复杂的光照条件下,NeRV具有明显的优势。
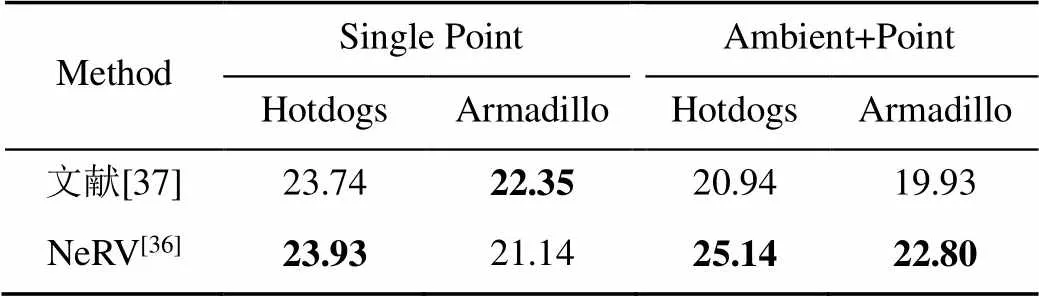
表3 文献[37]与NeRV在不同光照条件下的量化对比
3.3 基于神经辐射场的动态场景视点合成
由NeRF的原理可知,其本质上是依赖于多视图之间的几何一致性。然而,当场景中存在动态物体时,这种一致性便不再存在,导致NeRF无法对存在动态物体的场景进行表达。所以,另一类重要的研究方向即为将NeRF扩展到对于动态场景的表达。
动态场景的视点合成问题指的是输入一段视频,视频的拍摄过程中不仅相机发生移动,场景中的物体也存在运动。目标是通过这段视频合成得到任意时刻任意视点的图像。最直接的方法是将时间变量直接作为额外的输入加入到NeRF的训练中。但是,由于每个时刻,该场景中的每一点都只被一个视角观察到,所以理论上有无数种几何变化都可以符合输入视频中的观察。为此,一种直接的解决方式是利用现有的动态视频深度估计算法对每一帧的深度进行估计,以此对神经辐射场的优化进行约束[39]。这种方法由于需要显式的深度图进行约束,所以要首先训练得到动态场景深度估计的网络[40],并且其结果依赖于深度图估计的准确性。
另一种解决思路则是利用场景流的约束。文献[16]设计了神经场景流场用于动态场景的表达。具体来说,该网络在NeRF基础上加入时间变量作为额外输入,并且输出的变量也在传统NeRF的基础上增加了对相邻时刻场景流的预测。其中,该方法对预测的场景流进行了一致性的约束,以约束整体的优化过程。该约束要求相邻时刻的正向、反向场景流是一致的。图12展示了利用预测的场景流对图像进行形变的过程。
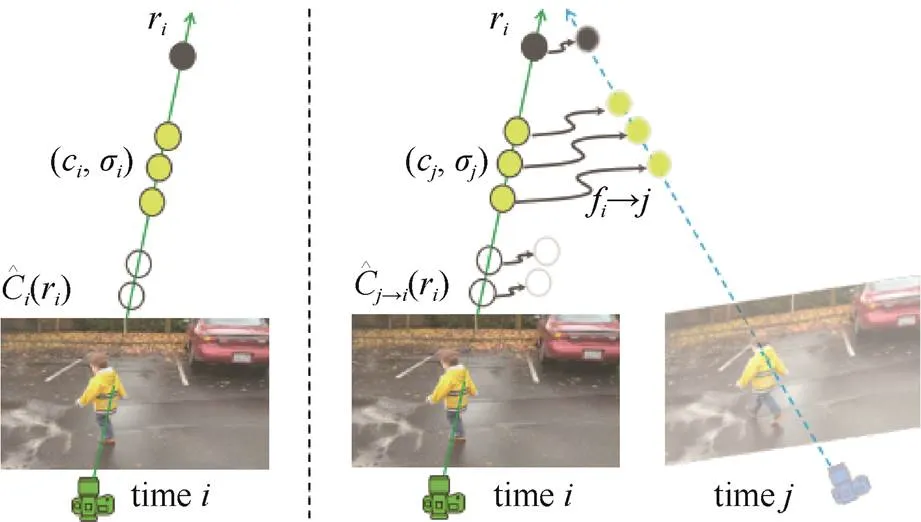
图12 利用场景流进行形变[11]
此外,文献[17]提出了一种可形变的神经辐射场(Deformable neural radiance fields,D-NeRF)对存在动态物体的场景进行表示。该方法的基本框架与NeRF-W模型类似,对每个输入图像进行外观编码,以调整图像之间的外观变化,例如曝光度、白平衡等。在此基础上,该方法用多层感知机表示一个空间坐标到正则空间坐标的变换,同时将场景每个时刻的状态编码为一个隐式的向量。通过对场景中的形变进行描述,该方法大大地提高了对于存在动态物体场景进行视点合成的鲁棒性。图13展示了该方法的网络结构。
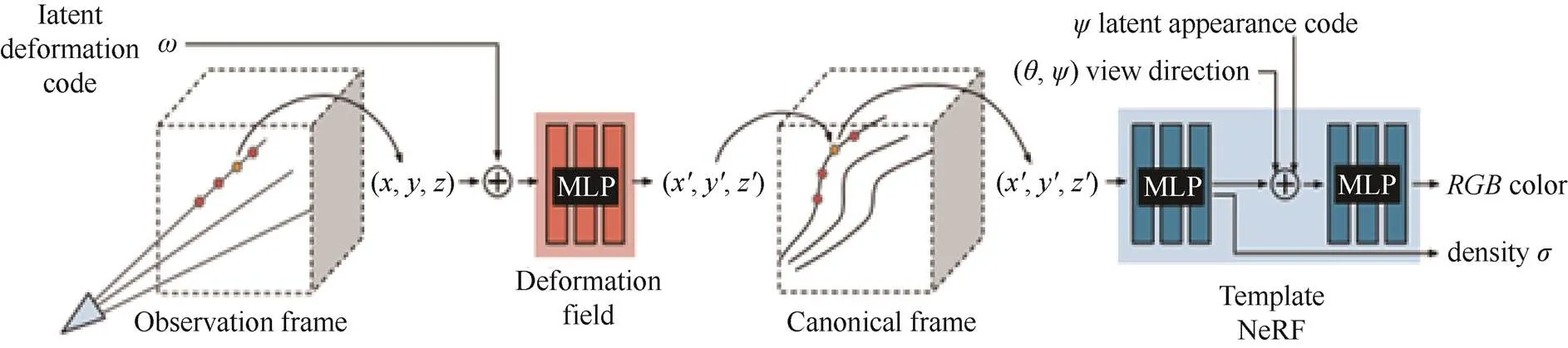
图13 D-NeRF的网络结构[17]
4 总 结
得益于可微绘制技术的发展,基于体绘制的神经渲染方法在近年来取得了飞快的发展,也促进了基于神经辐射场的视点合成算法的飞速发展。神经辐射场方法的提出具有2个重要的意义。首先,该方法可以获得高质量的视点合成结果。并且,不同于之前的算法采用离散的体素网格等结构对场景几何进行描述,该方法利用神经网络强大的表示能里,使用神经网络作为连续的隐函数对三维场景的几何和颜色性质进行表示。这使得该表示模型不会随着场景中几何分辨率的提高而显著变大。第二,该表示方法为研究者们提供了一种新的研究思路,促进了后续基于此表示模型的各种方法的蓬勃发展。
本文首先以用神经网络作为隐函数表达三维模型的早期方法作为背景,引入了神经辐射场方法的提出,也对该方法的理论模型进行了简单的介绍。然后将基于该模型的相关工作分为2类进行了总结和分析:
第一类方法为对传统神经辐射场方法的理论分析和性能优化。这类研究工作对神经辐射场方法的效率、精度、理论依据等方面进行了深入的探讨,也对算法本身的性能进行了优化提升。其中包括对模型表示能力的优化、对绘制效率的优化以及针对模型泛用性的优化。
第二类方法则为基于神经辐射场方法的推广和延伸。这类研究工作不再局限于原始方法所着眼的传统静态场景视点合成问题,而是以神经辐射场的思路为基础,为其他的复杂应用场景设计新的解决方案。有些方法将其推广至利用无约束的互联网图像进行视点合成,有些则将其推广至4维的动态场景的视点合成问题,还有一些方法则扩展了模型的表示能力,使其能够对场景光照进行显式表达,从而能够对合成的视点进行重光照。
基于图像的视点合成问题在近20余年始终是计算机图形学和计算机视觉领域的重要问题,对此,研究者们也已经进行了相当深入的研究。其中,如何从图像中提取场景的几何、外观、光照等信息是视点合成技术的关键问题,也是其难点和挑战。早期的方法受困于无法对场景的几何进行准确估计,使得仅能在苛刻的应用条件下进行视点合成。随着多视图立体几何的发展,研究者们利用对场景几何的重建结果,大大提升了合成视点的鲁棒性和准确性。然而,由于几何的重建误差以及并没有考虑到场景几何与外观的一致性问题,视点合成的质量仍然有所不足。近年来,研究者们考虑同时对场景的几何与外观信息进行估计,使得视点合成技术得到了显著的进步。深度学习的发展也深刻地影响到了这一领域。但是,由于这些方法均采用离散的方式来对三维空间进行描述,其合成质量受限于空间划分的粒度,这使得空间复杂度成了对于合成视点质量的一个重要制约因素。同时,采用多平面划分的方式,其对于场景中存在斜面的表示能力也存在着先天的劣势。神经辐射场方法利用了神经网络强大的表达能力,构造了一种连续的几何与外观表示方法来解决上述问题,在合成质量方面取得了显著的提升。神经辐射场方法提出至今仅仅一年左右的时间,基于该模型的相关研究工作已经得到了如此快速的发展,这体现出了这一模型具有强大的表示能力以及优秀的扩展性。而这一表示模型在其他应用领域的延伸将是重要的研究方向,例如基于神经辐射场的场景编辑、模型生成等等。同时,这类方法也存在着缺点与不足。首先,通过隐函数表示三维空间的方式需要在绘制时对空间中的每一个点都调用该隐函数一次,这相比于离散的表示方式大大地增加了时间开销,使得实时绘制难以实现。另外,该类方法的另一缺点为缺乏可解释性。采用体素或网格的离散表示形式的方法具有较高的解释性,能够对合成结果中出现失败或瑕疵的原因进行分析。而基于神经辐射场模型的方法将三维场景编码为神经网络的参数,难以从图形理论上分析该方法成功或者失败的具体原因。对该类方法的可解释性进行提升也将是未来重要的研究方向之一。本文通过对现有的工作进行分类总结,希望能对研究者们的研究工作起到参考和启发作用。
[1] CHANG Y, WANG GP. A review on image-based rendering[J]. Virtual Reality & Intelligent Hardware, 2019,1(1): 39-54.
[2] SHUM H-Y, HE LW. Rendering with concentric mosaics[C]//The 26th Annual Conference on Computer Graphics and Interactive Techniques. New York: ACM Press. 1999: 299-306.
[3] DEBEVEC P, DOWNING G, BOLAS M, et al. Spherical light field environment capture for virtual reality using a motorized pan/tilt head and offset camera[EB/OL]. [2021-01-20]. http://dx. doc.org/10.1145/2787626.2787648.
[4] SZELISKI R, SHUM HY, Creating full view panoramic image mosaics and environment maps[C]//The 24th Annual Conference on Computer Graphics and Interactive Techniques. New York: ACM Press, 1997: 251–258.
[5] CHAURASIA G, DUCHÊNE S, SORKINE-HORNUNG O, et al. Depth synthesis and local warps for plausible image-based navigation[J]. ACM Transaction on Graphics, 2013, 32(3): 30:1-30:12.
[6] HEDMAN P, KOPF J. Instant 3D photography[J]. ACM Transaction on Graphics, 2018, 37(4): 10:1-10:12.
[7] PENNER E, ZHANG L. Soft 3D reconstruction for view synthesis[J]. ACM Transaction on Graphics, 2017, 36(6): 235:1-235:11.
[8] HEDMAN P, PHILIP J, PRICE T, et al., Deep blending for free-viewpoint image-based rendering[J]. ACM Transaction on. Graphics, 2018, 37(6): 257:1-257:15.
[9] MILDENHALL B, SRINIVASAN PP, ORTIZ-CAYON R, et al. Local light field fusion: practical view synthesis with prescriptive sampling guidelines[J]. ACM Transaction on Graphics, 2019, 38(4): 29:1-29:14.
[10] CHOI I, GALLO O, TROCCOLI A J, et al. Extreme view synthesis[C]//2019 IEEE/CVF International Conference on Computer Vision. New York: IEEE Press, 2019: 7780-7789.
[11] MILDENHALL B, SRINIVASAN PP, TANCIK M, et al. NeRF: representing scenes as neural radiance fields for view synthesis[C]//2020 European Conference on Computer Vision. Heidelberg: Springer, 2020: 405-421.
[12] LIU L J, GU J T, LIN K Z, et al. Neural sparse voxel fields[C]//2020 Advances in Neural Information Processing Systems. Virtual: Curran Associates Inc, 2020: 15651-15663
[13] ZHANG K, RIEGLER G, SNAVELY N, et al. Nerf++: analyzing and improving neural radiance fields[EB/OL]. [2021-01-11]. https://arxiv.org/abs/2010.07492v2.
[14] YU A, YE V, TANCIK M, et alpixelNeRF: neural radiance fields from one or few images[EB/OL]. [2021-02-01]. https://arxiv.org/abs/2012.02190v1.
[15] TANCIK M, MILDENHALL B, WANG T, et al.Learned initializations for optimizing coordinate-based neural representations[EB/OL]. [2021-01-15]. https://arxiv.org/abs/2012. 02189v2.
[16] LI Z Q, NIKLAUS S, SNAVELY N, et al. Neural scene flow fields for space-time view synthesis of dynamic scenes[EB/OL]. [2021-02-15]. https://arxiv.org/abs/2011. 13084v1.
[17] PARK K, SINHA U, BARRON J T, et al. Deformable neural radiance fields[EB/OL]. [2021-01-29]. https://arxiv.org/abs/ 2011.12948.
[18] MESCHEDER L, OECHSLE M, NIEMEYER M, et al. Occupancy networks: learning 3D reconstruction in function space[C]//2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 4455-4465.
[19] CHEN Z Q, ZHANG H.Learning implicit fields for generative shape modeling[C]//2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 5932-5941.
[20] PARK J J, FLORENCE P, STRAUB J,NEWCOMBE R, et al. DeepSDF: learning continuous signed distance functions for shape representation[C]//2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 165-174.
[21] SAITO S, HUANG Z, NATSUME R, et al. Pifu: pixel-aligned implicit function for high-resolution clothed human digitization[C]//2019 IEEE/CVF International Conference on Computer Vision. New York: IEEE Press, 2019: 2304-2314.
[22] NIEMEYER M, MESCHEDER L, OECHSLE M, et al. Differentiable volumetric rendering: learning implicit 3d representations without 3D supervision[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 3501-3512.
[23] SITZMANN V, ZOLLHöFER M, WETZSTEIN G.cene representation networks: Continuous 3d-structure-aware neural scene representations[EB/OL]. [2021-01-18]. https://arxiv.org/abs/1906.01618?context=cs.
[24] KAJIYA JT, VON HERZEN BP. Ray tracing volume densities[J]. Computer Graphics, 1984, 18(3): 165-174.
[25] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//The 31st International Conference on Neural Information Processing Systems. New York: ACM Press, 2017: 6000-6010.
[26] SITZMANN V, THIES J, HEIDE F, et al. Deepvoxels: learning persistent 3D feature embeddings[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition.New York: IEEE Press, 2019: 2432-2441.
[27] LOMBARDI S, SIMON T, SARAGIH J, et al., Neural volumes: learning dynamic renderable volumes from images[J]. ACM Transaction on Graphics, 2019, 38(4): 65:1-65:14.
[28] TANCIK M, SRINIVASAN P P, BEN MILDENHALL B, et al. Fourier features let networks learn high frequency functions in low dimensional domains[EB/OL]. [2021-01-09]. https://arxiv. org/abs/2006.10739.
[29] JACOT A, GABRIEL F, HONGLER C. Neural tangent kernel: convergence and generalization in neural networks[C]//The 32nd International Conference on Neural Information Processing Systems. New York: ACM Press, 2018: 8580-8589.
[30] KNAPITSCH A, PARK J, ZHOU QY, et al. Tanks and temples: benchmarking large-scale scene reconstruction[J]. ACM Transactions on Graphics (ToG), 2017, 36(4): 1-13.
[31] LINDELLD B, MARTEL J N P, WETZSTEIN G. Automatic integration for fast neural volume rendering[EB/OL]. [2021-02-03]. https://arxiv.org/abs/2012.01714.
[32] NEFF T, STADLBAUER P,PARGER M, et al. DONeRF: towards real-time rendering of neural radiance fields using depth oracle networks[EB/OL]. [2021-01-28]. https://arxiv.org/ abs/2103.03231.
[33] TREVITHICK A, YANG B.GRF: learning a general radiance field for 3D scene representation and rendering[EB/OL]. [2021-02-10]. https://arxiv.org/abs/2010.04595.
[34] MARTIN-BRUALLA R, RADWAN N, SAJJADI MS, et al., Nerf in the wild: neural radiance fields for unconstrained photo collections[EB/OL][2021-01-30]. https://arxiv.org/abs/2008.02268.
[35] BOJANOWSKI P, JOULIN A, LOPEZ-PAS D, et al.Optimizing the latent space of generative networks[C]//The 35th International Conference on Machine Learning.Princeton: International Machine Learning Society(IMLS), 2018:599-608.
[36] SRINIVASAN P P, DENG B Y,ZHANG X M, et al. NeRV: neural reflectance and visibility fields for relighting and view synthesis[EB/OL]. [2021-01-02]. https://arxiv.org/abs/2012.03927.
[37] BI S, XU Z X, SRINIVASAN P, et al., Neural reflectance fields for appearance acquisition[EB/OL]. [2021-01-19]. https://arxiv.org/abs/2008.03824v2.
[38] BOSS M, BRAUN R, JAMPANI V, et al. NeRD: neural reflectance decomposition from image collections[EB/OL]. [2021-02-04]. https://arxiv.org/abs/2012.03918.
[39] XIAN W Q, HUANG J B, KOPF J, et al. Space-time neural irradiance fields for free-viewpoint video[EB/OL]. [2021-02-03]. https://arxiv.org/abs/2011.12950.
[40] LUO X, HUANG J B, SZELISKI R, et al. Consistent video depth estimation[J]. ACM Transactions on Graphics (TOG), 2020, 39(4): 71:1-71:13.
A review on neural radiance fields based view synthesis
CHANG Yuan1,2, GAI Meng1,2
(1. School of Electronics Engineering and Computer Science, Peking University, Beijing 100871, China;2. Beijing Engineering Technology Research Center for Virtual Simulation and Visualization, Peking University, Beijing 100871, China)
Image-based view synthesis techniques are widely applied to both computer graphics and computer vision. One of the key issues is how to use the information from the input image to represent a 3D model or scene. Recently, with the proposal of neural radiance fields (NeRF), a large number of research works based on this representation have further enhanced and extended the method, and achieved the expected accuracy and efficiency. This type of research can be broadly classified into two categories by purposes: the analysis and improvement of NeRF itself, and the extensions based on the NeRF framework. Methods of the first category have analyzed the theoretical properties and shortcomings of the NeRF representation and proposed some strategies for performance improvement, including the synthesis accuracy, rendering efficiency, and model generalizability. The second type of works are based on the NeRF framework and have extended the algorithm to solve more complex problems, including view synthesis using unconstrained images, view synthesis with relighting, and view synthesis for dynamic scenes. After outlining the background of the proposal of NeRF, other related works based on it were discussed and analyzed in this paper according to the classification mentioned above. Finally, the challenges and prospects were presented concerning the development of NeRF-based approaches.
image-based rendering; view synthesis; neural radiance fields; neural rendering; deep learning
TP 391
10.11996/JG.j.2095-302X.2021030376
A
2095-302X(2021)03-0376-09
2021-03-15;
2021-04-19
15 March,2021;
19 April,2021
北大百度基金资助项目(2019BD007)
PKU-Baidu Fund (2019BD007)
常 远(1995-),男,河北邯郸人,博士研究生。主要研究方向为计算机图形学与计算机视觉。E-mail:changyuan@pku.edu.cn
CHANG Yuan (1995-), male, PhD candidate. His main research interests cover computer graphics and computer vision.E-mail: changyuan@pku.edu.cn
盖 孟(1988-),男,山东莱阳人,助理研究员,博士。主要研究方向为计算机图形学、虚拟仿真等。E-mail:gm@pku.org.cn
GAI Meng (1988-), male, research associate, Ph.D. His main research interests cover computer graphics, virtual reality and simulation, etc. E-mail: gm@pku.org.cn
