基于Transformer层次预测的多星应急观测任务规划方法
2021-07-05罗棕杜春陈浩彭双李军
罗棕,杜春,陈浩,彭双,李军
国防科技大学 电子科学学院,长沙 410073
随着卫星观测技术不断发展,对地观测卫星已成为获取地震、洪涝、海啸等突发事件灾情的重要手段,观测信息可以帮助地面人员在第一时间掌握灾区受灾情况。当面临较为密集的观测请求时,单颗对地观测卫星往往效能不足,而多星协同观测能够有效响应观测需求。在应急条件下,多星任务规划不仅需要考虑复杂的约束因素(星载存储空间、星上能源消耗、侧摆角等),而且还应考虑观测任务的强时效性[1],任务必须在规定的时限内完成,否则任务就会失效。目前关于卫星应急任务规划的研究多是单独优先规划应急任务,虽然保证了应急任务的响应时间但牺牲了常规任务的完成度,使整体规划收益(简称收益)受到较大影响[2]。如何在兼顾收益与效率的前提下,完成多星应急观测任务规划成为当前亟需解决的问题。
为了提升多星任务规划的计算效率,Mirror等[3]提出任务分解的方法,将多星任务规划问题分解为任务分配主问题、单星任务规划子问题。但是作者并未对如何分配任务提出求解策略。对此,Yao等[4]提出采用自适应蚁群优化算法求解任务分配问题,选用启发式算法(HA)求解单星任务规划问题具有更好的规划收益,采用快速模拟退火算法(VFSA)求解单星任务规划问题具有更高的求解效率,实现了两种不同效果的求解算法。孙凯等[5]采用学习型遗传算法求解任务分解问题,在迭代过程中不断学习和提取知识,反馈并引导分配过程。白保存[6]、朱政霖[7]等将调度结果作为反馈信息用于调整任务分配过程,有效地提升了模型的求解效率,且取得相对较优的规划结果。当前基于优化分解的多星任务规划方法多采用启发式算法进行求解,在兼顾收益的同时,规划效率得到了很大地提升,但是启发式算法的优化方向具有一定程度的随机性,且算法的初始解通常采用随机方式生成,解的搜索空间较大,影响计算的效率。
近些年,为了帮助用户预测卫星观测任务是否执行,卫星规划领域提出了任务可调度性的概念。Li等[8]利用经典机器学习方法决策树和支持向量机实现了任务可调度性预测,证明了方法的有效性。随着机器学习的兴起,白国庆[9]、刘嵩[10]、邢立宁[11]等提出利用BP(Back Propagation)神经网络对卫星任务可调度性进行预测,实现了预测效果的提升,但是该方法忽略了观测任务时序特征的学习。对此,Peng等[12]提出了一种基于LSTM(Long Short-Term Memory)的任务可调度性预测方法,将任务序列作为输入,实现了任务时序特征的前后传递,预测准确率得到进一步提升,且计算过程快捷有效。任务可调度性的预测结果实质是对卫星规划结果的0/1预测,对初始卫星任务规划的快速预测具有很大的指导意义。
从机器学习角度分析,多星任务规划问题的输入是由多个观测任务组成的序列,输出也是由相应任务类别组成的等长序列,输入与输出之间存在一一对应的映射关系,因而多星任务规划问题是一个seq2seq问题[13]。当前解决seq2seq问题的主流架构有:卷积神经网络[14]、循环神经网络[13]。卷积神经网络易于并行化,却不适合捕捉变长序列内的依赖关系,循环神经网络适合捕捉长距离变长序列的依赖,但是却难以实现并行化处理序列[15]。为此,2017年谷歌提出了一种新的seq2seq模型——Transformer[15]。该模型采用与卷积神经网络、循环神经网络完全不同的结构,并且在机器翻译上表现出更优越的性能。2018年谷歌又提出用于语义理解的预训练模型BERT[16],一种基于Transformer的双向深层预训练模型。BERT在由斯坦福大学发起的国际权威机器阅读理解评测SQuAD1.1挑战赛中两个衡量指标上优于人类表现,此外还在11种不同自然语言处理测试中创出最优成绩。
为此,本文提出一种基于Transformer层次预测的多星应急观测任务规划方法(简称TTH)。TTH将多星观测任务规划问题的求解过程分解为任务可调度性预测、任务分配、优化调整。如图1 所示,首先利用基于Transformer的任务可调度性预测模型对待规划的任务集合进行预测,得到预执行任务集合与不执行任务集合,缩小任务分配的范围,使任务规划的收益接近最佳。然后基于Transformer的任务分配模型对预执行任务集合进行卫星分配,得到与最优解较为相似的初始规划方案。最后利用基于随机爬山的约束修正法消除任务可调度性预测模型和任务分配模型中因预测偏差引发的不合理问题(任务冲突、任务过饱和等),输出可执行的观测方案。TTH将机器学习方法与启发式算法相结合用于解决卫星观测任务快速规划问题,利用机器学习模型为启发式算法预测高价值的初始解,该步骤可以有效减少启发式算法的搜索计算量,在较短的时间内获取收益较高的可行解。相比于单独优先规划应急任务的优化算法[2],TTH可以在短时间内完成任务的重新规划,实现收益与计算效率的兼顾。
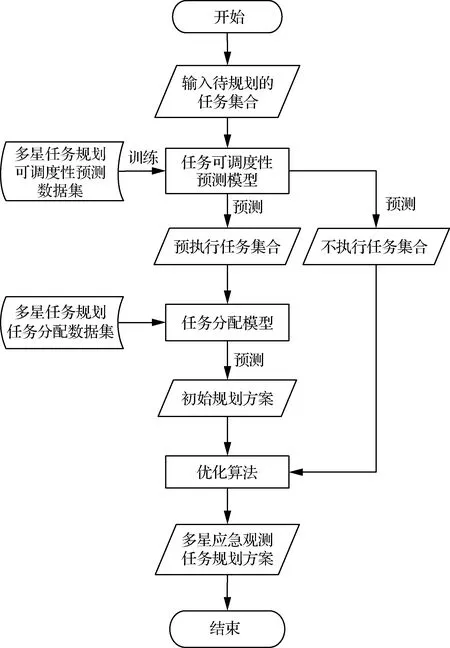
图1 所提方法流程图Fig.1 Flow chart of proposed method
论文组织如下:第1节构建多星观测任务规划的数学模型;第2节设计基于层次预测的规划算法;第3节是实验结果对比与分析;第4节是总结,并提出下一步研究方向。
1 多星观测任务规划问题建模
1.1 基本假设
本文研究的多星观测任务规划问题可描述为:在规定调度时间内,已知有若干组基于约束条件集合和观测卫星集合的多星对地观测历史任务规划数据,现对一组待规划的观测任务进行调度,要求在满足约束条件的前提下,安排卫星收益最大化地执行集合中的观测任务。为了便于后续研究,本文对该问题进行如下合理假设:
1) 每个观测任务只能执行一次,不允许重复执行。
2) 每个卫星同一时间只能执行一个观测任务。
3) 卫星执行的观测任务不允许拆分。
4) 假设调度时间的跨度较长,观测任务呈均匀分布,单颗卫星实际执行的任务数量较少,任务间的平均间隔时间远远大于任务转换所需时间,可忽略卫星观测任务间转换时间。
1.2 参数及决策变量定义
1) 观测任务集合X={x1,x2,…,xn},n为观测任务总数。
2) 成像卫星集合S={s1,s2,…,sm},m为成像卫星总数。
3) 观测任务收益pi,观测任务xi的收益越高,被执行的概率越高。此处定义观测任务xi的收益pi∈[1,10],最高收益为10。
4) 观测时长需求ti,用户对观测任务提出的观测时长要求。此处定义观测时长需求ti∈[10,59]。
8) 最长工作时间Tj,表示卫星sj在调度时间内观测总时长的最大值。
9) 最大存储消耗Bj,表示卫星sj在调度时间E内存储总消耗的最大值。
10) 观测任务可调度性决策变量yi,yi=0表示观测任务xi预测为不执行,yi=1表示观测任务xi预测为执行。
1.3 约束条件定义
基于上述假设和参数定义,参考文献[17-19]中关于多星任务规划建模约束条件,本文主要考虑以下约束条件:
1) 优化目标:本文定义多星任务规划的优化目标是在满足所有约束条件的情况下,卫星集合S收益最大化地执行待观测任务集合X。计算公式为
(1)
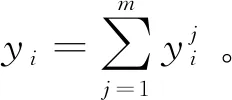
2) 观测时长需求:卫星执行观测任务的观测时长要与用户的观测时长需求一致,不允许任务拆分,表达式为
(2)
式中:i∈[1,n],j∈[1,m]。
3) 最长工作时间:卫星的观测活动存在间歇性,总的观测时间越长,星上的能耗越多,可用于能量补充、数据传输的时间越少。此外,卫星对地面目标进行观测时,星上能量的补充非常少,通常忽略不计。卫星sj在调度时间E内观测总时长不大于最长工作时间Tj,即
(3)
式中:j∈[1,m]。
4) 最大存储消耗:卫星对地面目标进行观测时会产生大量的观测数据,而星载存储空间是有限的,数据传输只能在有限窗口进行。为了简化问题,本文定义卫星sj在调度时间E内存储总消耗不大于最大存储消耗Bj:
(4)
式中:j∈[1,m]。
5) 观测时间窗:每颗卫星同一时间只能执行一个任务,相同卫星的观测时间窗不能重叠。表达式为
(5)
式中:i∈[1,n],j∈[1,n],k∈[1,m]。
考虑上述约束条件,本文选用观测任务的收益,观测时长需求,各星对应的观测时间窗起始、结束时间,各星对应的存储消耗,各星实际对应的观测时长,相同卫星中相邻任务时间窗的时间间隔作为观测任务集合X的特征属性。
2 基于层次预测的规划算法
本文选用基于注意力机制的Transformer来构建任务可调度性预测模型和任务分配模型,通过注意力机制去捕获观测任务与其他任务之间的依赖关系来实现对每个任务分类的预测,并且模型训练时可以进行并行化计算。
2.1 放缩点积注意力
点积的几何含义是计算两个向量之间的相似度,点积越大,相似度越高。Transformer采用放缩点积注意力[20](Scaled Dot-Product Attention)来计算注意力数值,有关公式为
(6)
式中:Q表示查询;K表示键;V表示值。当放缩点积注意力中Q=K=V时,放缩点积注意力机制也称为自注意力机制。式(6)中:dk表示Q与K矩阵的列数,作用是防止内积过大。
在多星任务规划问题中,Q、K、V由输入观测任务的特征矩阵线性变化所得,且存在Q=K=V的关系,矩阵中的每一行都代表着一个观测任务的特征向量。Q与K的点积运算实现了每一个观测任务与所有观测任务的相似度计算,经Softmax归一化之后即可获得单个观测任务与全部观测任务之间的关联性。最后将归一化后的注意力权重与V进行加权求和,实现了每一个观测任务的规划特征提取。
2.2 多头注意力机制
如图2所示,多头注意力机制[21](Multi-head Attention)首先由输入X经过线性变化得到h组不同的Qi、Ki、Vi,然后每组Qi、Ki、Vi均进行放缩点积注意力计算输出headi,最后headi将进行拼接,经过线性变化之后得到输出矩阵。
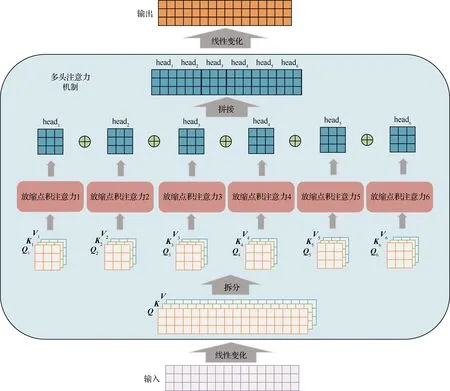
图2 多头注意力机制的结构模型Fig.2 Multi-head attention architecture
输入观测任务特征矩阵的不同的线性变化可得到不同的[Qi,Ki,Vi],每组[Qi,Ki,Vi]所关注的细节不同,通过多次放缩点积注意力计算可实现不同子空间的规划特征提取,实现对不同约束条件的建模表达。有关公式为
[V1,V2,…,Vh]=XWV
(7)
[K1,K2,…,Kh]=XWK
(8)
[Q1,Q2,…,Qh]=XWQ
(9)
headi=Attention(Qi,Ki,Vi)
(10)
MultiHead(Q,K,V)=
Concat(head1,head2,…,headh)WO
(11)
式中:X∈Rn×d;WQ∈Rd×d;WK∈Rd×d;WV∈Rd×d,WO∈Rd×d;n表示观测任务数量;d表示观测任务的特征数量,d能被h整除。
2.3 预测模型
如图3 预测模型结构框图所示,预测模型由多层Transformer Layer和全连接层组成。Transformer Layer由多头注意力机制、求和与归一化、前馈神经网络3种结构组成,上一层的输出传递到下一层,总共叠加了M次。

图3 预测模型结构框图Fig.3 Block diagram of prediction model
1) 求和与归一化
求和与归一化(Add & Norm)由两部分组成:求和、归一化,有关计算公式为
Z=Norm(X+MultiHead(X))
(12)
Y=Norm(Z+FeedForward(Z))
(13)
式中:X表示模型输入;Z表示第1次求和与归一化输出,同理Y表示第2次求和与归一化输出。求和可以帮助网络提升训练效果,关注训练前后差异部分变化。对求和结果标准化的目的是对神经元输入进行标准化,使得均值方差一致,加快网络收敛。
2) 前馈神经网络
前馈(Feed Forward)神经网络由2个全连接层组成,有关公式为
FeedForward(Z)=ReLu(ZW1+b1)W2+b2
(14)
式中:Z表示输入,第1层全连接输出经过激活函数Relu的处理,第2层全连接输出未经非线性函数处理。
3) 全连接层及损失函数
输入数据经过多层Transformer Layer特征提取之后,输出被传输到全连接层,经过非线性处理之后,由Softmax函数输出相应类别的概率。
为了训练网络,本文选用交叉熵计算损失,在任务可调度性预测模型中,损失函数为

(15)
式中:c表示预测结果的种类,取值上限在任务可调度性预测模型中为1,在任务分配预测模型中为m;i为观测任务;yic表示模型预测结果;pic为Softmax的输出,表示观测任务xi在预测结果为c时的预测概率。
上述内容即为TTH中机器学习模型结构介绍。任务可调度性预测模型与任务分配模型运用了相同的网络结构,但是模型输入、输出不同。任务可调度性预测模型与任务分配模型均使用同一套训练数据集,但是数据集的标签不同,任务可调度性预测模型的标签属于[0,1],任务分配模型的标签属于[0,1,…,m],后者比前者更加精细。在输入特征方面,可调度预测模型输入为任务的特征(见1.3节);而任务分配模型输入同时包含任务可调度性预测模型的输入数据和标签数据。
在训练过程中,任务可调度性预测模型与任务分配模型均独立进行训练,使用同一套数据集,不存在相互影响。测试时,将两个网络串联在一起,任务分配模型输入数据中所需的任务可调度性特征由任务可调度性预测模型预测所得。
2.4 基于随机爬山的约束修正算法
TTH优化调整的思想是在初始解的邻域范围内搜索最优解,在兼顾收益与计算耗时的同时,输出可行规划方案。相应的方法功能为任务冲突消除、任务分配优化、超限任务剔除、空缺任务补充。为此,本文选用基于随机爬山的约束修正算法作为优化算法。
随机爬山算法[22]是一种启发式算法,通过与周围相邻节点进行值的比对,如果优于当前节点取值,则替换当前节点,循环反复直至搜索到邻域最优节点,否则跳出搜索。由于完全循环的搜索优化会极大的消耗时间,所以TTH对随机爬山算法的终止条件进行了改进,通过不断的修正循环条件来获取最终的规划结果。优化调整过程中为衡量节点的状态,引导任务分配调整,本文定义节点的状态函数为各个卫星资源空余部分的乘积的总和,有关公式为
Jlack=
(16)
式(16)可以使得随机爬山算法在搜索过程中通过调整任务的分配使得资源的消耗更低,实现相同的观测任务占用更少的观测资源消耗,目的是为下一步观测任务补充腾出“空间”。基于随机爬山的约束修正算法具体计算步骤如图4所示。

图4 基于随机爬山的约束修正算法流程图Fig.4 Flow chart of constraint correction algorithm based on random hill climbing
步骤1在对邻域搜索之前,将相同卫星分组的任务进行统一编码,预测不执行的任务均编码为0,各个卫星所属任务按照卫星不同依次编码为1,2,…,m。
步骤2计算各个卫星所属任务与相邻任务的时间间隔、观测任务的实际观测时长。
步骤3判断观测任务时间窗是否满足约束条件。若否,则选择收益损失最小的优化方案,将不合理的观测任务移出至不执行观测任务集合;若是,则进入步骤4。
步骤4计算当前节点中各个卫星的观测总时长、存储总消耗,判断是否超出卫星最大负载。若是,则选择收益损失最小的优化方案,将部分观测任务移出至不执行观测任务集合,使得规划方案满足资源消耗的限制;若否,则进入步骤5。
步骤5计算当前各个卫星的观测总时长、存储总消耗,判断是否能够进行任务补充。若是,则在满足约束的前提条件下从不执行的任务集合中选取收益最大的补充方案;若否,则进入步骤6。
步骤6对当前节点的观测任务分配状况进行随机爬山算法优化。首先设定随机爬山算法的搜索次数,然后根据当前各个卫星的观测总时长、存储总消耗确定优化的目标卫星,对该卫星内观测任务进行邻域搜索,搜索范围为其他卫星内观测任务。重复随机爬山搜索优化直至满足搜索截至条件。任务分配调整之后从不执行观测任务中进行收益最大化补充。
步骤7输出当前节点的任务规划方案。
3 实验与分析
实验平台:实验计算机配置为Inter(R) Core(TM) i7-9750H CPU @2.60 GHz,运行内存8.0 GHz,操作系统为Windows10。
1) 数据准备:目前多星观测任务规划暂无公开的标准数据集。本次实验使用第1节描述的多星观测任务规划模型构建约束集合,设定2018年8月18日00:00:00—2018年8月18日23:59:59为调度时间,选用成像卫星SPOT-5、SPOT-6、SPOT-7、WORLDVIEW-1、WORLDVIEW-2、WORLDVIEW-3、WORLDVIEW-4组成卫星集合,并采用真实卫星轨道数据进行仿真。参照文献[23]中采用的观测目标构造方法,在纬度-70°~70°、 经度-180°~180°的范围内随机生成1 000个点目标组成观测目标集合,观测目标集合分布状态如图5所示。
图5 点目标分布图Fig.5 Point target distribution map
2) 实验数据:本文实验所用数据均为仿真数据,共收集了3种应用场景的非应急观测任务数据集:第1种场景下对地观测卫星数量为3,每组数据包含100个观测目标,共有5 350组多星观测任务规划数据;第2种场景下对地观测卫星数量为5,每组数据包含200个观测目标,共有5 350组多星观测任务规划数据;第3种场景下对地观测卫星数量为7,每组数据包含300个观测目标,共有5 350组多星观测任务规划数据。观测目标的观测时间窗由STK 11软件计算所得,标签由IBM公司的数学规划软件ILOG CPLEX Optimizer 12.6.3计算所得。由于观测任务具有多个时间窗,为此本文数据按照观测任务中SPOT-5观测时间窗的开始时间进行排序。每个观测任务数据由对应的特征数据组成,实验中用于机器学习的训练数据占比60%,验证数据占比20%,测试数据占比20%。
3.1 规划算法性能测试
为测试TTH的性能,此处选用CPLEX中的求解引擎CPLEX优化器和标准遗传算法(Genetic Algorithm,GA)作为比较对象,分别对不同场景下的100组观测任务序列进行计算,结果如表1所示。表中收益指算法最终规划方案的平均收益;耗时指算法最终规划方案的平均计算耗时;收益比值为算法平均收益与表1中最大收益的比值;耗时比值定义为算法平均耗时与表1中最小耗时的比值。耗时增幅为上一规模耗时与当前规模耗时的比值。对表1作如下分析:
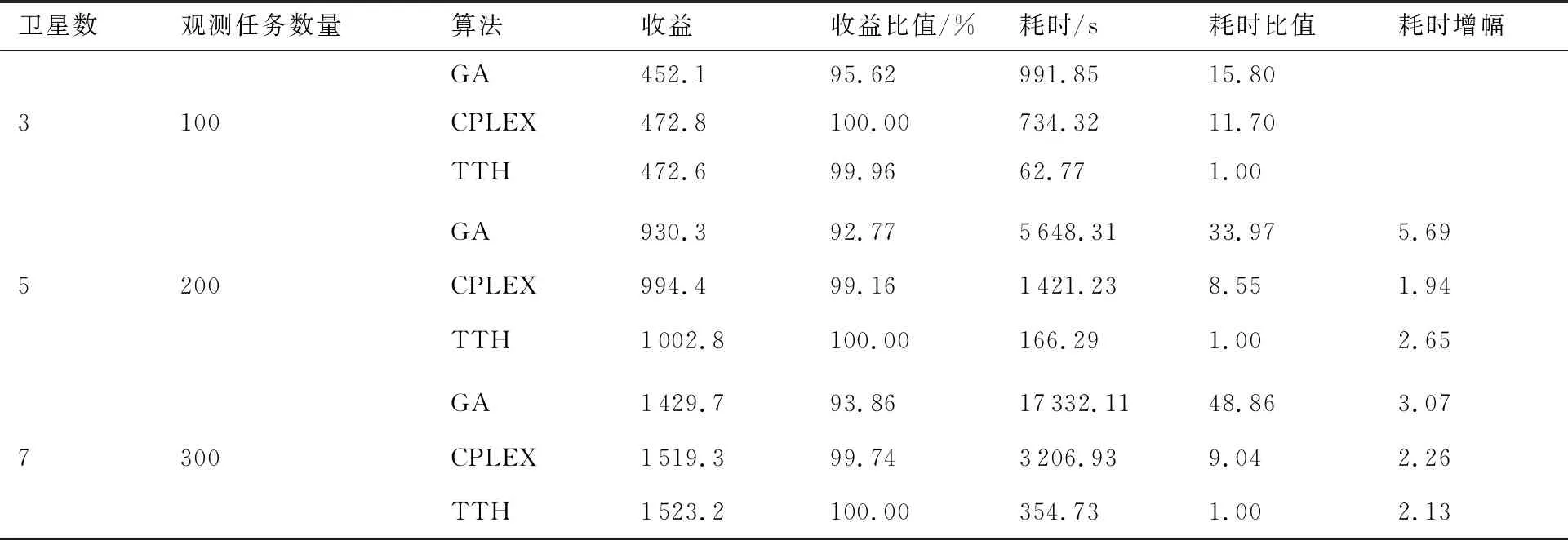
表1 规划算法性能比较Table 1 Performance comparison planning algorithms
1) 从表1中收益数据可以得出,与CPLEX相比,随着任务规划场景的变化,TTH收益比值与CPLEX收益比值相差均不超过1%。与GA相比,随着任务规划场景的复杂化,GA收益比值均低于TTH收益比值。这说明TTH的观测收益性能与CPLEX相当,优于GA。
2) 从表1耗时数据可以得出,随着任务规划规模的复杂化,TTH、CPLEX、GA耗时均在增加,TTH、CPLEX的增幅较小,GA的增幅最大,但是TTH的耗时远低于其他方法。所以,与CPLEX、GA相比,在不同的任务规划场景下,TTH的计算效率相对更优。
3) 综合算法的收益、耗时及相应的比值可得,TTH的任务规划性能优于CPLEX、GA。
3.2 模型有效性测试
为证明TTH子模型的有效性,此处在不同的场景下选取100组观测任务序列作为测试数据,采用不同的随机方式生成两种初始规划方案:
1) 1#随机算法(简称1#),对每组观测序列中观测任务进行随机任务可调度性预测,而后对预执行任务进行随机卫星分配。
2) 2#随机算法(简称2#),经TTH任务可调度性预测之后,采用随机分配的方式,对预执行任务进行随机卫星分配。
采用TTH的基于随机爬山的约束修正算法分别对1#、2#随机算法初始规划方案以及TTH的初始规划方案(简称TTH)进行优化,得到3种不同的最终规划方案,实验结果如表2所示。表中任务冲突度指在初始规划方案中各卫星观测时间窗口出现重叠的平均任务数。任务冲突比值指初始规划方案中任务冲突与表中任务最小冲突的比值。表中其他指标定义与3.1节相同。通过数据的分析,可以得出如下结论:

表2 模型有效性测试Table 2 Testing of validity of models
1) 通过对相同规划场景下不同规划方法的分析可得,TTH的规划收益最高,其次为2#规划收益,1#规划收益最低。在不同规划场景下,1#收益始终低于TTH和2#收益,分析主要原因是任务规划可调度性预测较好地将预执行任务筛选出来,可以较好地保证后续规划计算的收益,任务可调度性预测准确率影响最终任务规划方案的收益。
2) 比较表2中任务冲突指标可以得出,1#、2#的任务冲突度随着任务规划规模的扩大而增加。从不同场景下任务冲突比值可以看出,TTH任务规划方案均能保持较低的任务冲突度,这表明对于不同规模的任务规划场景,TTH的分配预测模型均能较好地避免任务冲突。
3) 通过对相同场景下不同规划算法的耗时可以看出,1#、2#以及TTH均能够保持相近的计算耗时,耗时比值较为接近。这说明基于随机爬山的约束修正算法能够快速地对初始规划方案进行优化,搜索到可行解。
4) 上述结论验证了TTH中任务可调度性预测模型、任务分配模型和优化算法的有效性。
3.3 Transformer与LSTM的性能对比
为测试TTH预测模型的性能,本文选用长短期记忆网络(Long Short-Term Memory,LSTM)作为比较对象,采用控制变量的比较方式,构建对比模型LTH、TLH、LLH,比较模型的任务收益、收益比值、耗时、耗时比值。实验结果如表3所示,通过分析得出以下结论:
1) 从表3中的收益和收益比值可以看出,在相同的规划场景中,TTH的规划收益要高于LTH的规划收益,TLH的规划收益要高于LLH的规划收益,随着规划规模的复杂化,规划收益的差距变大。由此可以看出Transformer的任务可调度性预测性能优于LSTM。
2) 从表3中耗时可以得出,随着场景规模的增大,TTH模型优于TLH模型,LTH模型优于LLH模型。由此可见,随着任务规划规模的增加,Transformer模型在任务分配效果上优于LSTM模型。
3) 从表3任务冲突度可以看出,随着场景的增加,初始规划结果的任务冲突度增加,但是任务冲突度占任务规划总数的比例在1%左右,相对较低。但是整体上TTH模型优于TLH模型,LTH模型优于LLH模型。

表3 Transformer与LSTM性能比较Table 3 Performance comparison between Transformer and LSTM
4) 综合收益、耗时、任务冲突度的比较结果,Transformer在初始规划方案预测上效果优于LSTM。Transformer在注意力权重时不需要进行时序信息的前后传递,而LSTM需要受序列长度的制约,随着序列变长,时序信息的传递受到一定程度的影响。
注:表中TRAN表示Transformer。
4 结 论
本文提出了基于Transformer层次预测的多星应急观测任务规划方法,采用任务分解的方式将多星任务规划问题的求解过程分为:任务可调度性预测、任务分配和优化调整3个部分。在文中设定的任务规划条件下,与CPLEX优化器、标准遗传算法相比,TTH表现出耗时短,收益高的优点。通过与随机初始规划方案对比,证明了TTH中任务可调度性预测模型、任务分配模型和优化算法的有效性;与LSTM模型相比,Transformer任务可调度性预测和任务分配的性能相对更优。
随着卫星数量的增多和观测任务的增加,将对现有模型的学习能力带来更大的挑战,在下一步的研究工作中,需要构建更加适应问题的决策网络,或是结合深度强化学习等技术进行研究。
